- 1中国异丁酸酐(CAS+97-72-3)行业市场供需与战略研究报告_异丁酸酐国内有卖吗
- 2深度学习系列38:Dalle2模型_dalle2代码安装
- 3第三十二课.脉冲神经网络SNN_脉冲神经网络事件驱动
- 4如何给鸿蒙 APP 签名
- 5map函数总结
- 6计算机系统常见故障及处理,电脑常见故障以及解决方案都在这里!
- 7UOS服务器操作系统部署Redis_uos安装redis
- 8govqq.com/post/12.html,GitHub - NotEnding/wenshu: 文书网cookie获取 2020-04-16 可行。现在文书网的反爬太激进,正常用户访问也受限。请考...
- 9OCR 基本知识_ocr 基础开发人才
- 10kafka迁移和扩容_kafka扩容为什么需要迁移数据
Hadoop伪分布式环境搭建_hadoop伪分布式搭建
赞
踩
什么是Hadoop伪分布式集群?
Hadoop 伪分布式集群是一种在单个节点上模拟分布式环境的配置,用于学习、开发和测试 Hadoop 的功能和特性。它提供了一个简化的方式来体验和熟悉 Hadoop 的各个组件,而无需配置和管理一个真正的多节点集群。
在 Hadoop 伪分布式集群中,各个 Hadoop 组件(如 NameNode、DataNode、ResourceManager、NodeManager 等)在同一台机器上运行,并通过配置文件进行连接和通信。通过使用 Hadoop 伪分布式集群,你可以在单个节点上进行开发和测试,而无需配置和管理一个真正的多节点集群。这对于学习和熟悉 Hadoop 的基本概念、调试代码、运行作业和验证配置非常有用。
然而,需要注意的是,伪分布式集群并不能提供真正的分布式计算和数据处理能力,因为所有的组件都在同一台机器上运行。因此,在进行性能测试、负载均衡和规模扩展方面,它与真实的分布式集群可能存在一些差异。
也就是说,Hadoop可以在单节点上以伪分布的方式运行,Hadoop进程以分离的Java进程来运行,节点既是NameNode又是DataNode,并且读取的是HDFS中的文件。
一、基本环境配置
基本环境配置的 所有步骤与博主上一篇博客一致
1.修改主机名和设置固定IP
2.关闭防火墙和新建安装目录
3.安装配置JDK
4.配置主机映射(修改hosts文件)
5.配置SSH免密登录本地节点(hadoop0)
二、安装配置Hadoop
1.安装和解压
步骤与博主上一篇博客一致
接着进入“/opt/programs/hadoop-3.3.6/etc/hadoop”目录,依次修改配置文件 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves(又一个坑,Hadoop3.x版本之后,slaves文件更名为workers,所以很多同学会找不到这个文件)、hadoop-env.sh。
①修改配置文件core-site.xml
# vim core-site.xml
将 <configuration> 和 </configuration> 标签的内容修改如下:
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://hadoop0:9000</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/opt/programs/hadoop-3.3.6/tmp</value>
- </property>
- </configuration>
②修改配置文件hdfs-site.xml
# vim hdfs-site.xml
将 <configuration> 和 </configuration> 标签的内容修改如下:
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
③修改配置文件mapred-site.xml
# vim mapred-site.xml
将 <configuration> 和 </configuration> 标签的内容修改如下:
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>dfs.permissions</name>
- <value>false</value>
- </property>
- </configuration>
④修改配置文件yarn-site.xml
# vim yarn-site.xml
将 <configuration> 和 </configuration> 标签的内容修改如下:
- <configuration>
- <property>
- <name>yarn.resourcemanager.hostname</name>
- <value>hadoop0</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
⑤修改配置文件slaves(Hadoop3.x改名为workers)
将“localhost”修改为以下内容:
hadoop0
⑥修改配置文件hadoop-env.sh
将’expHADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}”一行改为:
export HADOOP_CONF_DIR=/opt/programs/hadoop-3.3.6/etc/hadoop
并在文件末尾加入JAVA_HOME环境变量:
export JAVA_HOME=/opt/programs/jdk1.8.0_371
然后执行以下命令,刷新hadoop-env.sh文件,使修改生效:
# source hadoop-env.sh
2.配置Hadoop环境变量
接修改“ /etc/profile ”,配置Hadoop环境变量
# vim /etc/profile
在文件末尾加入以下内容:
export HADOOP_HOME=/opt/programs/hadoop-3.3.6
export PATH=$PATH:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后刷新profile文件,是修改生效:
# source /etc/profile
三、格式化HDFS
执行以下命令,格式化HDFS:
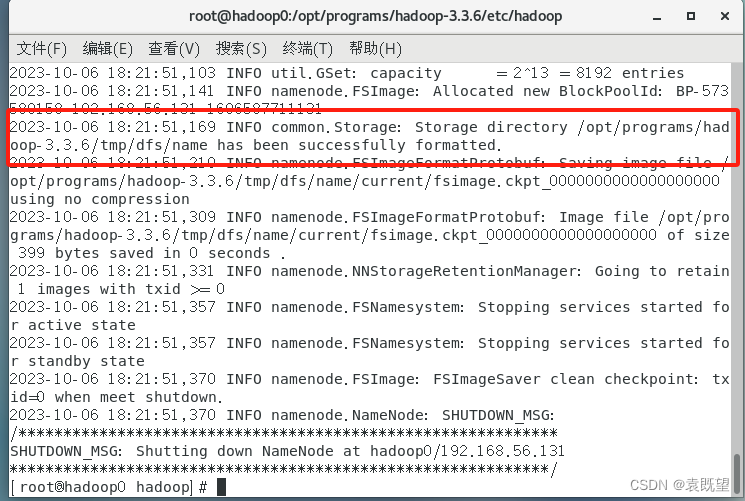
# hdfs namenode -format
出现以下信息则说明格式化成功:
四、启动HDFS和YARN
依次执行以下命令,启动HDFS和YARN:
# start-dfs.sh
# start-yarn.sh
若出现以下报错:
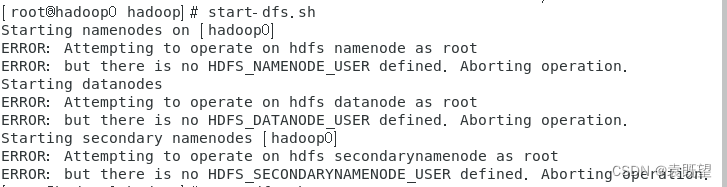
则需要在“ /etc/profile/ "文件中加入以下内容:
- export HDFS_NAMENODE_USER=root
- export HDFS_DATANODE_USER=root
- export HDFS_SECONDARYNAMENODE_USER=root
- export YARN_RESOURCEMANAGER_USER=root
- export YARN_NODEMANAGER_USER=root
- export HDFS_JOURNALNODE_USER=root
- export HDFS_ZKFC_USER=root
更改完成后一定要刷新profile文件!
然后重启HDFS和YARN:
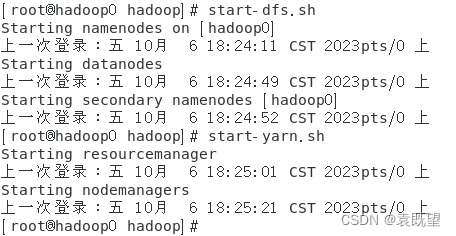
即可发现正常启动。
启动后可执行“ jps ”命令,查看启动的Hadoop相关进程:
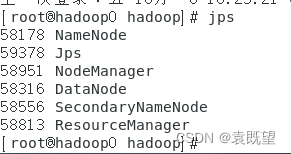
除去jps外,共有五个进程:NameNode、SecondaryNameNode、DataNode、ResourceManager和NodeManager。如果发现有进程没有启动,可以先停止Hadoop集群(依次执行” stop-dfs.sh ”、“stop-yarn.sh”),然后重新格式化HDFS。
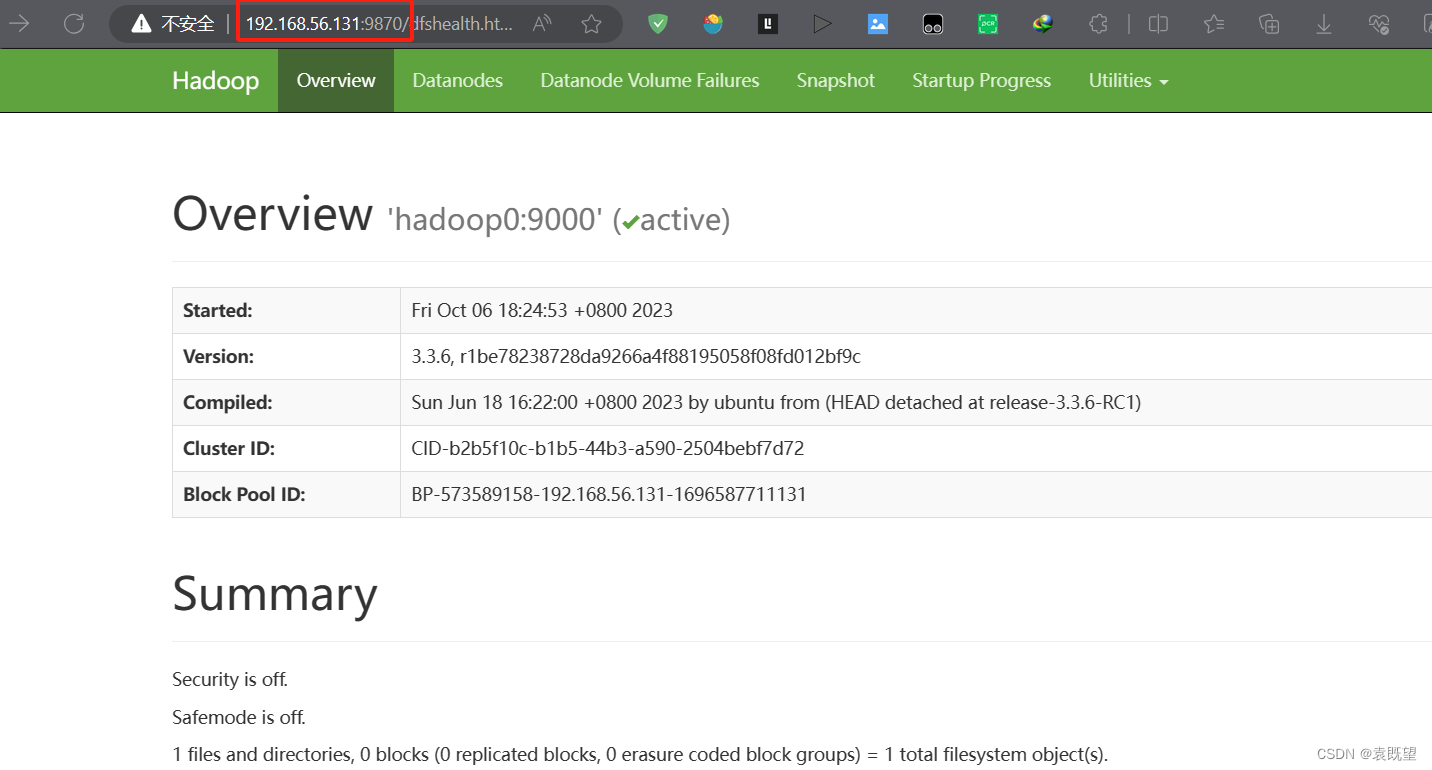
启动后在宿主机访问“ http://hadoop0的ip地址:9870/ ”,页面会显示“hadoo0:9000(active)”
(有小伙伴可能访问50070访问不了,那么不妨改为9870试试!)
对于Hadoop高可用集群和伪分布式集群,它们在配置上有一些差异,这可能导致了不同的端口配置。
在Hadoop高可用集群中,通常会使用Hadoop的HA(High Availability)功能来确保集群的可用性。HA集群中有多个NameNode实例,其中一个是Active状态的主NameNode,负责处理客户端请求。默认情况下,Active主NameNode的HTTP端口是50070,用于访问Web界面。
而在Hadoop伪分布式集群中,只有一个节点模拟了整个分布式环境,包括NameNode、DataNode、ResourceManager等。为了避免与默认的单节点模式端口冲突,Hadoop在伪分布式模式下将NameNode的HTTP端口更改为9870。
因此,当你搭建正常的Hadoop高可用集群时,可以通过50070端口访问NameNode的Web界面。而在伪分布式集群中,由于端口冲突的考虑,NameNode的HTTP端口被更改为9870。
这是Hadoop在不同配置下为了避免端口冲突而进行的默认设置。我们也可以通过相应的配置文件修改端口号,来满足需求。