
- 1【区块链-前端交互】第六篇:以太测试网转账和Gas计算_sepolia测试网怎么自动批量转账
- 2SEU东南大学电子夏令营暨预推免面经8.25
- 3【云原生】kubernetes中的认证、权限设置--RBAC授权原理分析与应用实战
- 4C#常用数据结构:数组,ArrayList,List<>,链表,Queue,Stack,Dictionary_c# queue快还是list快
- 5腾讯,干掉Redis项目,正式开源Tendis,太牛皮啦
- 6Linux篇:开发工具yum/vim/gcc/g++/Makefile/gdb_linux yum gcc10
- 7《计算机视觉》习题解答(三)第4章_计算机视觉教程第三版章毓晋答案
- 8axios学习笔记
- 9大数据技术Hadoop+Spark_hadoop+spark 入门
- 10系统集成项目管理工程师考试案例分析历年试题考点分布荟萃
深度学习目标检测项目实战(一)—基于深度学习框架yolov的交通标志检测_基于深度学习的交通标志检测
赞
踩
深度学习目标检测项目实战——基于深度学习框架yolov的交通标志检测
目前目标检测算法有很多,流行的就有faster-rnn和yolov,本文使用了几年前的yolov3框架进行训练,效果还是很好,当然也可以使用更高版本的Yolov进行实战。本代码使用的是keras框架,pytorch的yolov如何对数据集进行训练,可以参考我之前的文章:
工业缺陷检测项目实战(二)——基于深度学习框架yolov5的钢铁表面缺陷检测
跑工程的原理步骤都是一样的,都可以学习。
Yolov3原理
很多大佬都写得很详细,比如:
YOLOv3原理详解(绝对通俗易懂)2021-07-01
YOLOv3详解
数据集准备
使用gtsrb交通标志数据集,下载链接:
https://www.kaggle.com/datasets/meowmeowmeowmeowmeow/gtsrb-german-traffic-sign
https://aistudio.baidu.com/aistudio/datasetdetail/97069
以上两个链接都可以下载,文件夹里面是这样:
Meta没什么用,主要是Test和Train,Test作为验证集使用。
基础代码准备
本工程基于开源githubkeras-yolov代码进行修改。
环境
tensorflow==1.15.0
keras==2.3.1
- 1
- 2
前提是电脑或者服务器有cuda10.0,如果没有,只能安装tensorflow 1.14版本及以下,keras 2.2.4版本及以下,本人建议使用gpu训练,因为训练速度快很多。其他看着来,缺什么pip install什么。
使用步骤
1.将数据集放在工程文件夹
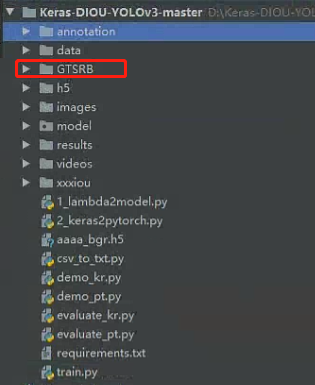
2.生成train和test的txt文件
我这里写了一个csv转txt的代码:
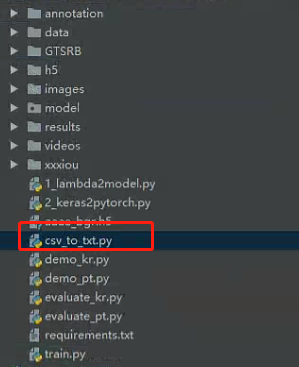
代码如下:
import numpy as np import pickle import re import os from PIL import Image # Create raw data pickle file data_raw = {} class_list = [] box_coords_list = [] image_file_list = [] with open('GTSRB/Test.csv', 'r') as f: next(f) # skip header line for line in f: # 遍历每一行 line = line[:-1] # 去掉换行符 fields = line.split(',') image_file = fields[7] class_list.append(int(fields[6])) image_file_list.append(image_file) # Find box coordinates for all signs in this image box_coords = np.array([int(x) for x in fields[2:6]]) box_coords_list.append(box_coords) # 写入txt内容 with open("GTSRB/val.txt", 'w+', encoding='utf-8') as f: for i in range(len(box_coords_list)): box_coord = "" box_coord += str(box_coords_list[i][0]) + ',' box_coord += str(box_coords_list[i][1]) + ',' box_coord += str(box_coords_list[i][2]) + ',' box_coord += str(box_coords_list[i][3]) d = image_file_list[i] + ' ' + box_coord + ',' + str(class_list[i]) f.write(d + '\n')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
路径根据自己的去修改即可。生成的txt放在annotation文件夹下。
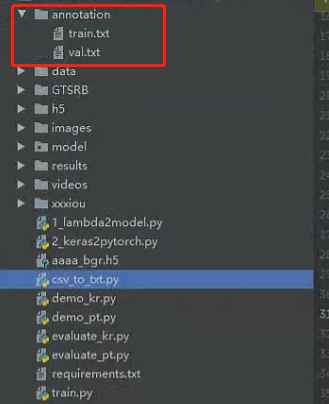
txt文件格式如下:
xxx/xxx.jpg 18.19,6.32,424.13,421.83,20 323.86,2.65,640.0,421.94,20
xxx/xxx.jpg 48,240,195,371,11 8,12,352,498,14
# image_path x_min, y_min, x_max, y_max, class_id x_min, y_min ,..., class_id
# make sure that x_max < width and y_max < height
- 1
- 2
- 3
- 4
3.生成标签的类别txt文件
在data文件夹下,生成txt的文件来表示类名:
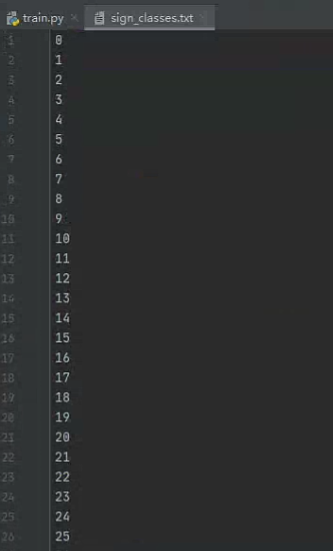
比如这里有43个类,则我们可以先用数字字符表示,等检测完再转回对于的类名:
一行表示一个类名,注意此处类名不能有空格,比如以下是错误的例子:
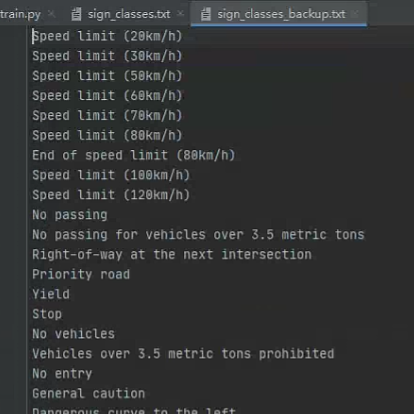
每一行都存在空格,这样在计算mAP的时候会报错。
数据已准备完毕。
4.修改文件路径
主要是修改train.py文件里面的这三个路径:
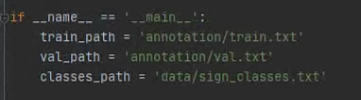
5.训练
运行
python train.py
- 1
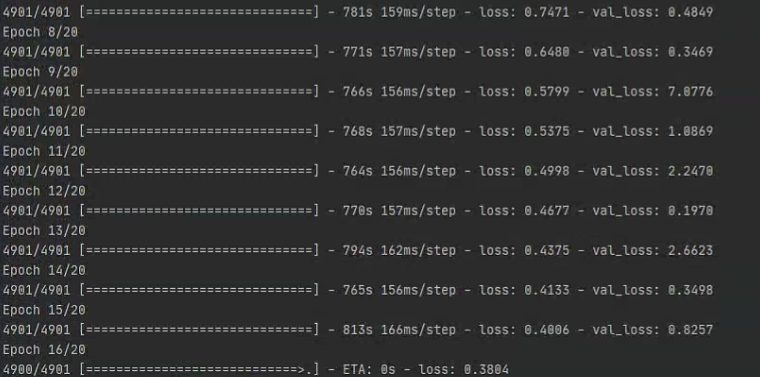
6.注意
引用github源码大佬的话:
(1)本仓库有pattern=0、pattern=1、pattern=2这3种训练模式。 0-从头训练,1-读取model_body继续训练(包括解冻,但需要先运行1_lambda2model.py脚本取得model_body),2-读取coco预训练模型训练 你只需要修改pattern的值即可指定训练模式。 然后在这3种模式的if-else分支下,你再指定批大小batch_size、学习率lr等超参数。
(2)如果你决定从头训练一个模型(即pattern=0),而且你的显卡显存比较小,比如说只有6G。 又或者说你想训练一个小模型,因为你的数据集比较小。 那么你可以设置initial_filters为一个比较小的值,比如说8。 initial_filters会影响到后面的卷积层的卷积核个数(除了最后面3个卷积层的卷积核个数不受影响)。 yolov3的initial_filters默认是32,你调小initial_filters会使得模型变小,运算量减少,适合在小数据集上训练。
7.训练完之后,可以得到以下h5文件:
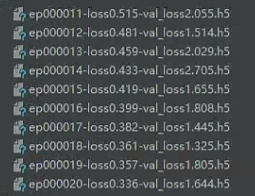
运行
python 1_lambda2model.py
- 1
将训练模型中yolov3的所有部分提取出来。我这里得到aaaa_bgr.h5
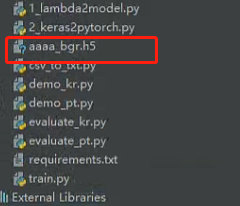
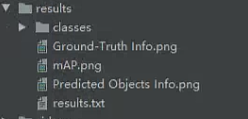
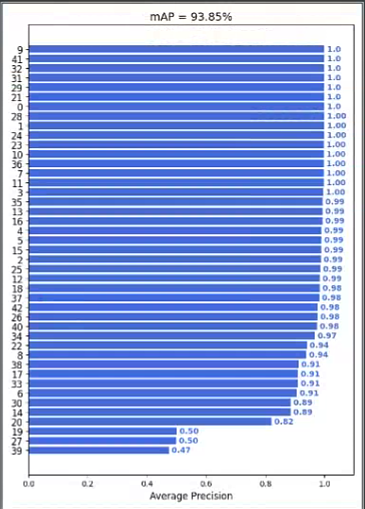
8.mAP评估
运行evaluate_kr.py对keras模型(1_lambda2model.py提取出来的模型)评估,跑完这个脚本后需要再跑mAP/main.py进行mAP的计算。计算完之后会保持结果图:
9.测试
在images/test里面放置要检测的图片:
运行
python demo_kr.py
- 1
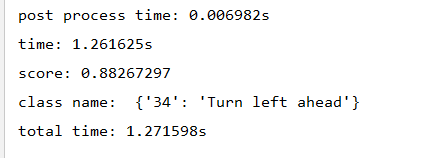
比如识别:

识别结果:

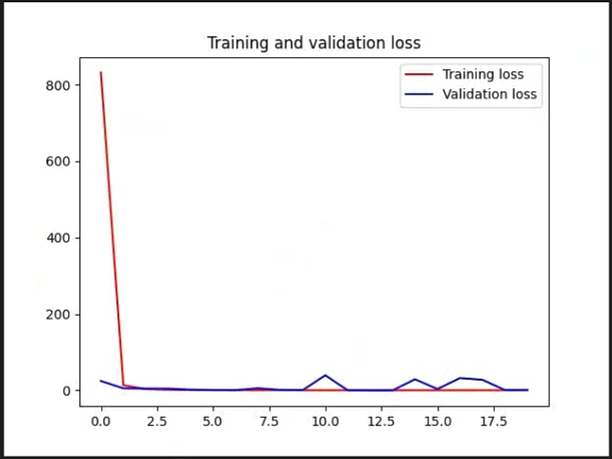
另外,我使用了两次训练,第一次tarin.py里面pattern=0,即从头训练,第二次pattern=1,即加载第一次的模型作为预训练模型进行训练。同时添加了绘制acc和loss的曲线图,也对过滤了识别分数地的框。
两次训练Loss的对比:
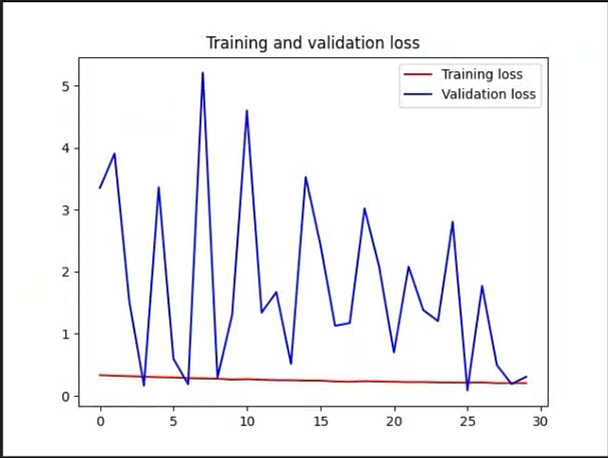
需要整体代码的可私信我,如果想训练其他数据集的也可以私。

