
- 1git 创建group_gitlab新建用户、组、分支以及为项目分配相应权限
- 2golang适配GBase8s(南大通用)数据库_gorm 适配南大通用
- 3Coze在手,GPTs&DALLE免费用_coze账户
- 4TCP 连接状态及相关命令学习_network tcp connection state
- 5理解维度数据仓库——事实表、维度表、聚合表_数据仓库 维度 事实 指标 汇总概念
- 6【Hive】SQL 数据结构 & 常用函数_hive tostring
- 7连接web3出现不是构造constructor错误 const web3 = new Web3(ethereumNodeUrl);TypeError:Web3 is not a constructor_typeerror: web3 is not a constructor
- 8AndroidStudio升级Gradle之坑_android studio grade报错
- 9基于FPGA的数字信号处理(9)--定点数据的两种溢出处理模式:饱和(Saturate)和绕回(Wrap)_数据截位的溢出模式,wrap around方式
- 10【DevOps】深入理解 Nginx Location 块:配置示例与应用场景详解
MySQL字符集和排序规则详解
赞
踩
本篇博客主要记录mysql当中关于创建数据库时候选择:字符集、排序规则等相关知识。通过示例直观的看出其真正作用。
1、前言
在创建数据库的时候会让我们去选择字符集和排序规则,有很多人对这方面不是很了解,包括我,在此也查阅了很多资料,总结一下,不然每次创建的时候都感觉很疑惑,感兴趣的跟着小编一块学习。
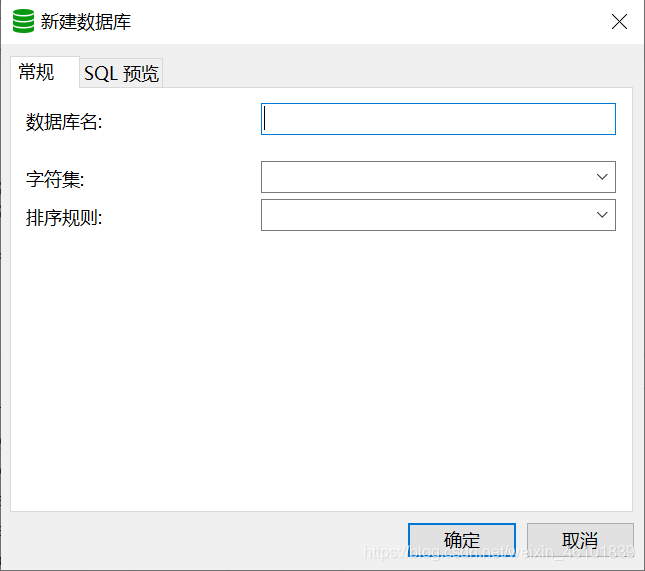
2、mysql字符集
一般选择utf8.下面介绍一下utf8与utfmb4的区别。
utf8mb4兼容utf8,且比utf8能表示更多的字符。至于什么时候用,看你的做什么项目了,到 http://blog.csdn.net/leelyliu/article/details/52879685 看unicode编码区从1 ~ 126就属于传统utf8区,当然utf8mb4也兼容这个区,126行以下就是utf8mb4扩充区,什么时候你需要存储那些字符,你才用utf8mb4,否则只是浪费空间。
2、排序规则
2.1、排序规则作用
排序规则概念:是指对指定字符集下不同字符的比较规则。排序规则有以下特征:
它和字符集(CHARSET)相关
每种字符集都有多种它支持的排序规则
每种字符集都会默认指定一种排序规则为默认值。
排序规则作用:排序规则指定后,它会影响我们使用 ORDER BY语句查询的结果顺序,会影响到 WHERE条件中大于小于号的筛选结果,会影响 DISTINCT、GROUP BY、HAVING 语句的查询结果。另外,mysql 建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都和排序规则有关。
在MySQL数据库中,可以使用show collation;来查看支持的各种排序呢规则

2.2、排序测试
排序常用如下:
utf8_general_ci :不区分大小写,这个你在注册用户名和邮箱的时候就要使用。校对速度快,但准确度稍差。 (准确度够用,一般建库选择这个)
utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容
utf8_unicode_ci:它和utf8_general_ci对中、英文来说没有实质的差别。准确度高,但校对速度稍慢。
2.2.1、utf8_bin示例
bin 是二进制, a 和 A 会别区别对待
use test;
drop table if EXISTS test;
create table test(
a varchar(1) not null
)COLLATE utf8_bin;
insert into test select 'a';
insert into test select 'A';
select * from test where a ='a';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这时候查出来的是只有一条,证明是区分大小写的。

2.2.2、utf8_general_ci示例
use test;
drop table if EXISTS test;
create table test(
a varchar(1) not null
)COLLATE utf8_general_ci;
insert into test select 'a';
insert into test select 'A';
select * from test where a ='a';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

2.3、排序规则设置及优先级
排序规则设置可以分为:MySQL实例级别、库级别、表级别、列级别以及SQL指定。
优先级顺序是 SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 实例级别设置
也就是说,如果SQL语句中指定了排序规则,则以其指定为准,否则以下一级为准(也就是列级别),如果列级别没有指定,默认是继承表级别的设置,以此类推。
2.3.1、MySQL实例级别设置
实例级别的排序规则设置就是 MySQL 配置文件或启动指令中的 collation_connection 系统变量。
可以通过修改mysql的配置文件 my.ini来修改相应的排序规则,修改好后,重启mysql服务。
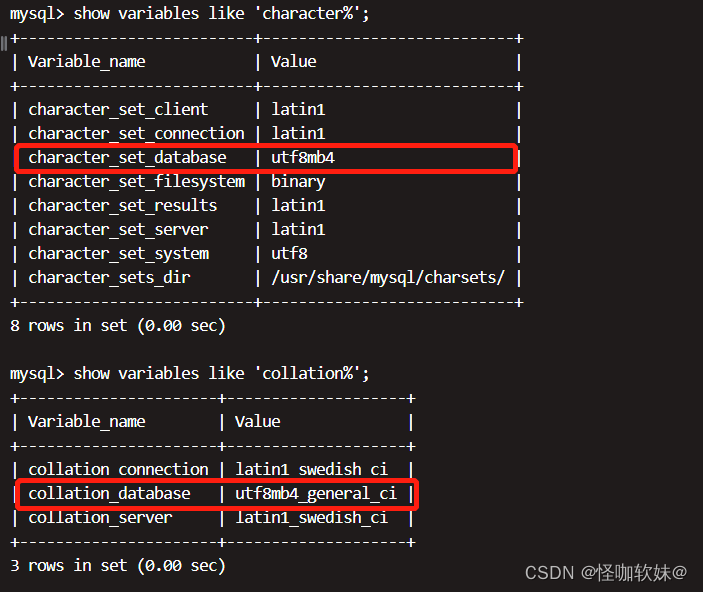
查看MySQL实例级别的字符集
show variables like '%character%';
- 1

查看MySQL实例级别的排序规则
show variables like '%collation%';
- 1
2.3.2、库级别设置
在创建数据库的时候指定数据集和排序规则,指定完之后创建表的时候就可以不指定了,如果不指定就是跟随库的默认设置。
CREATE DATABASE TESTDB
DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
- 1
- 2
查看数据库编码:show create database 数据库名;
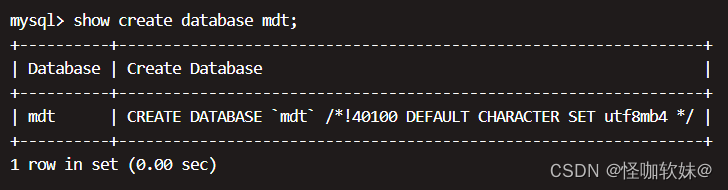
查看数据库编码(这是第二种方式):show variables like 'character%';
查看数据库排序规则:show variables like 'collation%';
注意:如要要查数据库的,一定要先use 数据库;
修改test数据库为gbk编码和gbk_chinese_ci排序规则: alter database test charset=gbk collate=gbk_chinese_ci;
2.3.3、表级别设置
在创建表的时候指定表的数据集和排序规则
use testdb;
CREATE TABLE user(
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
查看表级别排序规则
show table status from 数据库名 like '表名';
-- testdb 为数据库名, user 为要查看的表名
- 1
- 2
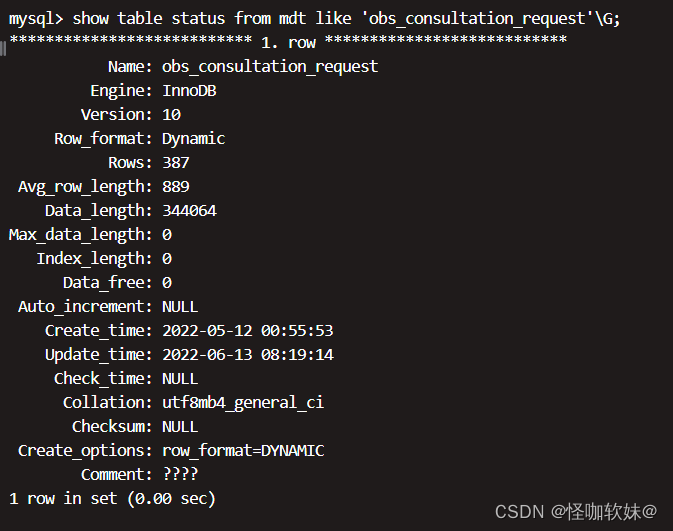
navcat客户端当中也可以在这个地方查看。

修改某个表为gbk编码和gbk_chinese_ci排序规则:
ALTER TABLE table_name CONVERT TO CHARACTER SET gbk COLLATE gbk_chinese_ci;
- 1
2.3.4、列级别设置
在创建表的时候指定列的数据集和排序规则。
只有在字符才有,也就是字符类型,char、varchar、tinytext等等。。。
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
);
- 1
- 2
- 3
- 4
- 5
查看列级别排序规则
show full columns from test;
- 1

navcat客户端当中可以点击指定列进行查看列的属性。

修改某个表的某个字段为utf8mb4编码和utf8mb4_general_ci排序规则:
ALTER TABLE table_name MODIFY `xxx` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
- 1
2.3.5、SQL指定设置
SQL语句中指定排序规则,当然不能乱设置,假如表用的utf8的,你设置utf8mb4_unicode_ci,他是会直接查询报错的。
SELECT
id,
name
FROM
test
ORDER BY
name COLLATE utf8_unicode_ci;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
看完动动您的发财小手给小编点个赞!

