
- 1Mybatis实体类属性与数据库字段的对应关系_mybatisplus 实体属性是对象 数据库是id 如何对应
- 2VM虚拟机增加磁盘空间的扩容操作(little by little)_vm中的utilities在哪
- 3「大数据集群的搭建和使用」背景知识:大数据Hadoop生态圈介绍
- 4MongoDB分布式部署方式
- 512个python超强学习网站!加python书籍推荐!( 入门python自学推荐!建议收藏!)
- 6FPGA工作原理与简介_简述 fpga 基于门阵列的逻辑实现以及基于查找表的逻辑实现的原理
- 7HCIA笔记总结_hcia资料
- 8经典面试题之顺序表和链表的优缺点
- 9CISCO HSRP
- 10【论文解读】语义分割&医学图像分割论文合集_cs-net: channel and spatial attention network for
HNSW&NSG-基于图的ANN近邻搜索
赞
踩
HNSW&NSG-基于图的ANN近邻搜索
ANN近邻搜索有KDTree,HNSW,NSG,PQ,IVF-PQ等等,依次介绍ANN的各个算法
基于空间切分的向量检索算法的缺点:
空间切分类算法的劣势。所有类似的哈希或者树结构的方法都免不了对空间进行切分再索引,那么,他们为什么会随着维度提升而性能急剧下降呢?因为它们的算法逻辑都是首先定位一个最有可能出现答案的区域(被分割线/面包裹的区域),如果没找到或没找到足够的答案,就要去检查与当前区域相邻的区域,在二维空间中似乎没有那么糟糕,但在上百的高维空间,这些候选区域的数字会指数级膨胀,大家可以想象一下高维空间中多面体的面的数目如何变化。因此,往往为了提高搜索精度,它们这些方法需要扫描几乎整个数据集!
LSH 算法必须要建立大量的 Hash 表,这会使得索引大小膨胀数倍。不仅如此,树和 LSH 都属于空间切分类算法,此类算法有一个无法避免的缺陷,即为了提高搜索精度,只能增大搜索空间
基于图的向量搜索的朴素想法
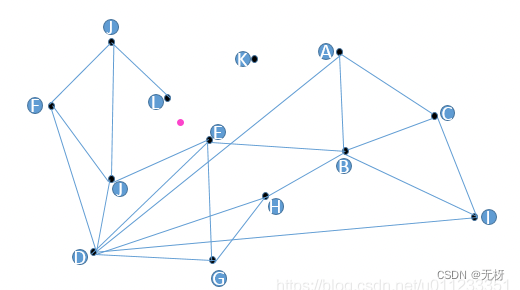
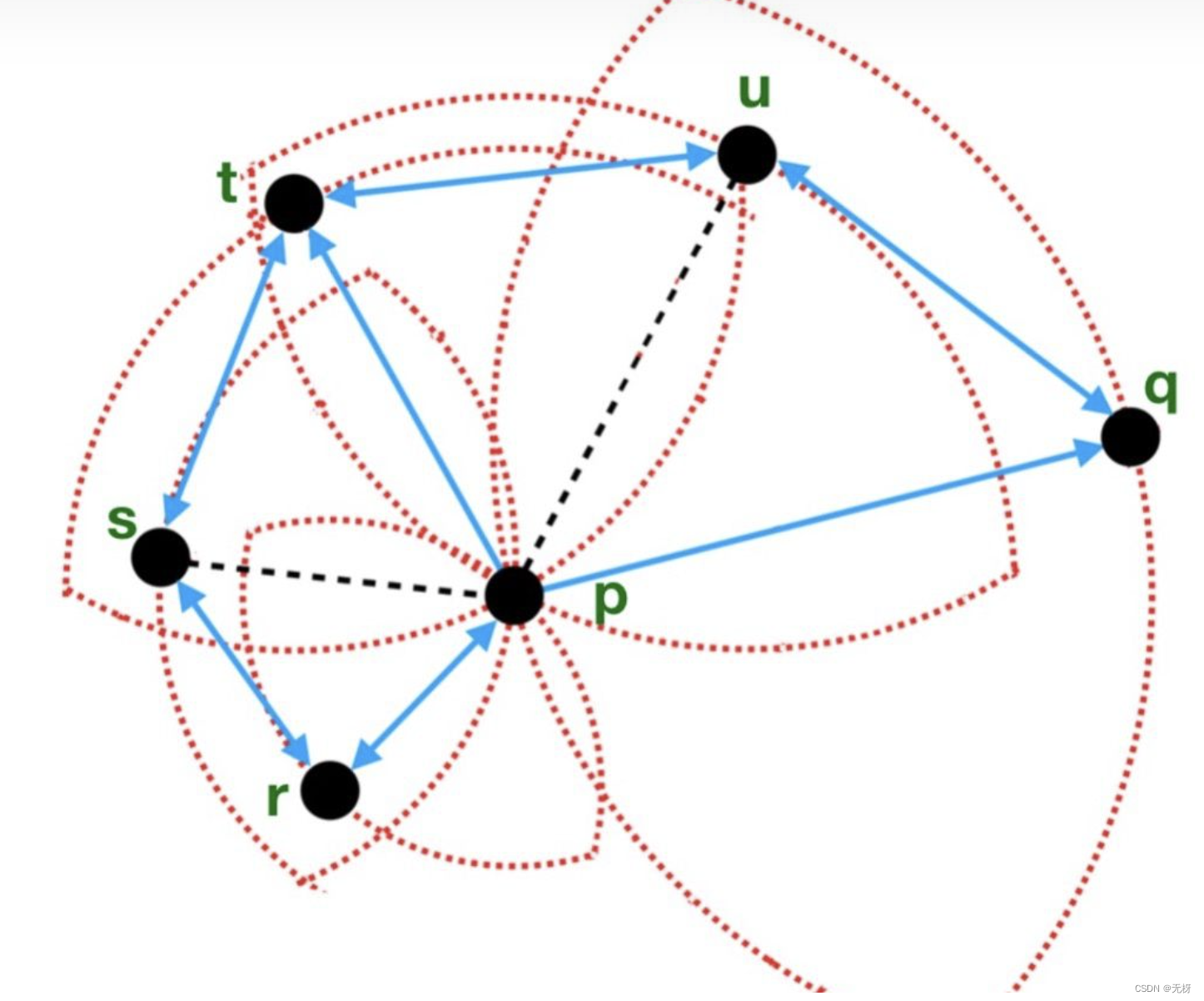
如果我们有13个向量在嵌入空间中,每两两之间的向量距离可以用欧式距离算出,如果我们来了一个query,我们怎么搜到与这个query粉点最近的向量呢?
我们可以考虑一种思路,随机选一个C点计算C到粉色节点的距离,然后存下来,继续从C的友点(C链接的邻居节点)ABI三个中,继续计算ABI到粉色点的距离,发现B最近,并且B也比A更近,因此从B的友点出发,持续下去,最后找到E点,且E点的所有友点到粉色节点的距离都没有E点更近,因此终止
缺点:
我们发现:
- K点没有被搜到,因为它没有连任何节点
- L和E两个点都离粉色点很近,但是他们不会同时被搜到
- D点的邻居节点太多,要算的友点也最多
因此我们的改进思路: - K这种节点没必要存在,构图的时候强制每个节点必须有友点
- 所有距离相近的点必须互为友点,防止到了决赛圈结果只在某些点搜的情况
- 尽量减少每个节点的邻居数量
NSW算法是?
首先针对上述问题,我们有图论中的经典算法可以解决,所有三角形的外接圆均满足空圆性质的三角剖分,称为一个Delaunay三角剖分。
大概的思路就是每当插入一个新的顶点时,将其与附近的旧顶点连接会加入一些新的边,我们只要用翻转边算法来修正其中的“坏边”,就可以将其重新“修复”为Delaunay三角剖分。
这样会满足:
1,图中每个点都有“友点”。2,相近的点都互为“友点”。3,图中所有连接(线段)的数量最少
这三个性质。
但NSW没有采用德劳内三角剖分法来构成德劳内三角网图,原因之一是德劳内三角剖分构图算法时间复杂度太高,换句话说,构图太耗时。原因之二是德劳内三角形的查找效率并不一定最高,如果初始点和查找点距离很远的话我们需要进行多次跳转才能查到其临近点,需要“高速公路”机制(Expressway mechanism, 这里指部分远点之间拥有线段连接,以便于快速查找)。在理想状态下,我们的算法不仅要满足上面三条需求,还要算法复杂度低,同时配有高速公路机制的构图法。
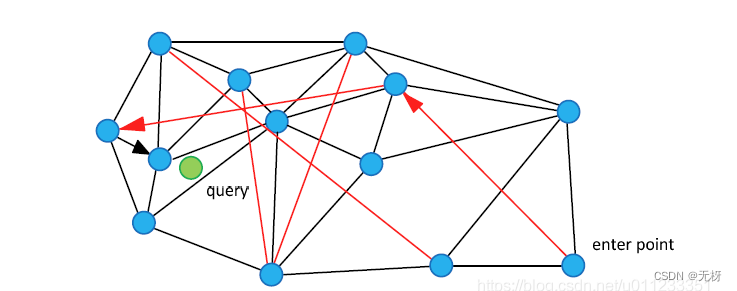
NSW论文中配了这样一张图,黑色是近邻点的连线,红色线就是“高速公路机制”了。我们从enter point点进入查找,查找绿色点临近节点的时候,就可以用过红色连线“高速公路机制”快速查找到结果。
NSW朴素构图算法在这里:向图中逐个插入点,插图一个全新点时,通过朴素想法中的朴素查找法(通过计算“友点”和待插入点的距离来判断下一个进入点是哪个点)查找到与这个全新点最近的m个点(m由用户设置),连接全新点到m个点的连线。
关于NSW算法的朴素构思就讲到这里了,下面我们来说说优化。
一.在查找的过程中,为了提高效率,我们可以建立一个废弃列表,在一次查找任务中遍历过的点不再遍历。在一次查找中,已经计算过这个点的所有友点距离查找点的距离,并且已经知道正确的跳转方向了,这些结果是唯一的,没有必要再去做走这个路径,因为这个路径会带给我们同样的重复结果,没有意义。建立废弃表
二.在查找过程中,为了提高准确度,我们可以建立一个动态列表,把距离查找点最近的n个点存储在表中,并行地对这n个点进行同时计算“友点”和待查找点的距离,在这些“友点”中选择n个点与动态列中的n个点进行并集操作,在并集中选出n个最近的友点,更新动态列表。
注意,插入过程之前会先进行查找,所以优化查找过程就是在优化插入过程。以下给出NSW查找步骤也同样是建图步骤。设待查找q点的m个近邻点。
1.随机选一个点作为初始进入点,建立空废弃表g和动态列表c,g是变长的列表,c是定长为s的列表(s>m),将初始点放入动态列表c(附上初始点和待查找q的距离信息),制作动态列表的影子列表c’。
2.对动态列表c中的所有点并行找出其“友点”,查看这些“友点”是否存储在废弃表g中,如果存在,则丢弃,如不存在,将这些 剩余“友点”记录在废弃列表g中(以免后续重复查找,走冤枉路)。
3.并行计算这些剩余“友点”距离待查找点q的距离,将这些点及其各自的距离信息放入c。
4.对动态列表c去重,然后按距离排序(升序),储存前s个点及其距离信息。
5.查看动态列表c和c’是否一样,如果一样,结束本次查找,返回动态列表中前m个结果。如果不一样,将c’的内容更新为c的 内容,执行第2步。
插入算法更简单了,插入算法就是先用查找算法查找到m个(用户设置)与待插入点最近的点,连接它们,完了。
二、跳表
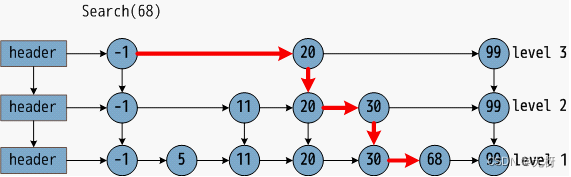
跳表怎么构建呢?三个字,抛硬币。对于sorted_link链表中的每个节点进行抛硬币,如抛正,则该节点进入上一层有序链 表,每个sorted_link中的节点有50%的概率进入上一层有序链表。将上一层有序链表中和sorted_link链表中相同的元素做一一对应的指针链接。再从sorted_link上一层链表中再抛硬币,sorted_link上一层链表中的节点有50%的可能进入最表层,相当于sorted_link中的每个节点有25%的概率进入最表层。以此类推。
表层是“高速通道”,底层是精细查找
HNSW用的就是这个思想:
三、HNSW
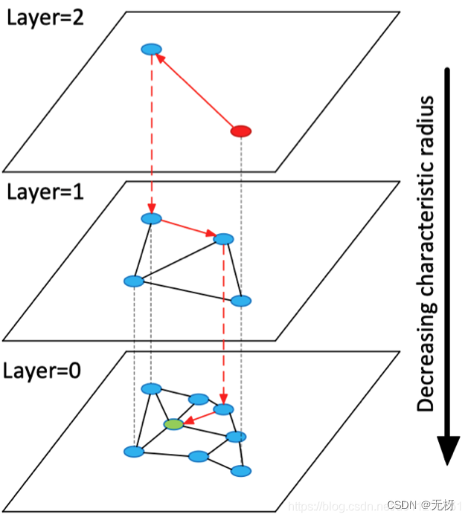
与NSW不同的是,HNSW构建的图是分层级的,具体来说,先随机选择一部分点进行第一层的构建,之后再从剩余节点中选择一部分点添加至图中与第一层的节点构成第二层…,以此类推,直到构建完最后一层,使得这一层涵盖所有节点。
然后每一层的查找方式和NSW相同
查看动态列表c和c’是否一样,如果一样,结束本次查找,返回动态列表中前m个结果。如果不一样,将c’的内容更新为c的内容,接着在下一层查找
插入新节点:先确定新节点最多能到哪一层,在每层找到t个最近邻节点并连接。
优点:
NSW 通过设计出一个具有导航性的图来解决近邻图发散搜索的问题,但其搜索复杂度仍然过高,达到多重对数的级别,并且整体性能极易被图的大小所影响
HNSW 从结构入手, 利用分层图提高图的导航性减少无效计算从而降低搜索时间 ,达到优化的目的。
NSG-淘宝
基于图的检索方法要想高效获得ANN,要做到确保图的连通性、降低图的平均出度、缩短搜索路径长度和减少索引个数。因此作者提出了一种新的图结构MRNG。
本论文发现不是所有的近邻点对检索效率都有同等贡献。这几年不同的剪枝策略被提出,但都是经验式的尝试。到底什么样的连边策略是最优的呢?在尝试中发现一种新的构图策略

效果超越facebook的ivf-pq
但是不支持向途中动态增加向量,目前只支持离线从大规模离线向量中建立图
推荐场景是从上亿级别数据量内做召回同时需要很低的响应时间和高精度,faiss适合百万级规模,我们尝试更大规模的时候faiss的性能已经不足以支撑了。
Faiss内存小是优点,缺点是检索慢太多,精度有上限
fanng和hnsw的裁边用的是rng的策略,同时不保证最短边存在于图中,此外,fanng和hnsw建立索引,是从随机初始化的图开始边搜边裁,因此最终得到的图,其边分布不具备我们证明的检索复杂度的性质。我们对我们的图结构以及裁边方法在英文原文中有明确定义,同时在这个定义上才能推理证明出我们的检索时间复杂度的性质,而对于基于rng的策略的行为会产生绕路现象,原文中也给出了例子和对比。鉴于你知道这两种方法,那你应该也是理解已经很深入了,建议你去原文看一下细节上的东西吧。
基于图的KNN检索,需要构建图网络。这步应该会比faiss这种基于PQ量化更耗内存,但是整体来看topk accuracy的指标会好点。不过工业界里面,数据库一般需要动态增删,这块基于PQ量化应该更容易一点,基于图的方法可能会比较麻烦。
优点:
HNSW 和 NSG 的比较 HNSW 从结构入手, 利用分层图提高图的导航性减少无效计算从而降低搜索时间 ,达到优化的目的。 而 NSG 选择将图的整体度数控制在尽可能小的情况下,提高导航性, 缩短搜索路径 来提高搜索效率。
总结
HNSW算法主要就是图上的ANN近邻搜索算法,思想主要是利用高速公路和友点这样的搜索方式,之后我们将介绍基于树的近邻搜索KD tree 和基于量化的IVF-PQ

