
热门标签
热门文章
- 1apk开发文档!面试完腾讯我才发现这些知识点竟然没掌握全,已开源_apk问价如何查看开发作者(2)
- 2Git报错解决:git@gitee.com: Permission denied (publickey)_gitee permission denied (publickey)
- 3应用层防火墙(WAF)规则设置未能有效防御针对应用的攻击_web应用防火墙无法有效保护
- 4MySQL并发控制_mysql 并发
- 520届华为勇敢星实习面试记录_华为勇敢星计划,什么时间面试
- 6MAC M2下安装Java及maven环境变量_mac m2 安装jdk
- 7【Spring Boot】掌握Spring Boot:深入解析配置文件的使用与管理_springboot如何解析properties文件的
- 8推荐项目:Tiktokenizer - 精确的OpenAI提示令牌计算器
- 9STM32调试MIPI RFFE协议_stm32 mipi
- 10Git报错解决:git@gitee.com: Permission denied (publickey)._gitee 你的访问权限受限
当前位置: article > 正文
pytorch深度学习一机多显卡训练设置,流程_两张显卡,深度学习训练的时候怎么设置cuda
作者:AllinToyou | 2024-06-12 12:35:51
赞
踩
两张显卡,深度学习训练的时候怎么设置cuda
最近在学习在服务器的ubuntu环境上配置用多个显卡训练,之前只用一个显卡训练实在是太慢了点
先看看服务器上有几个显卡:
nvidia-smi
- 1
即可得到具体的显卡信息:
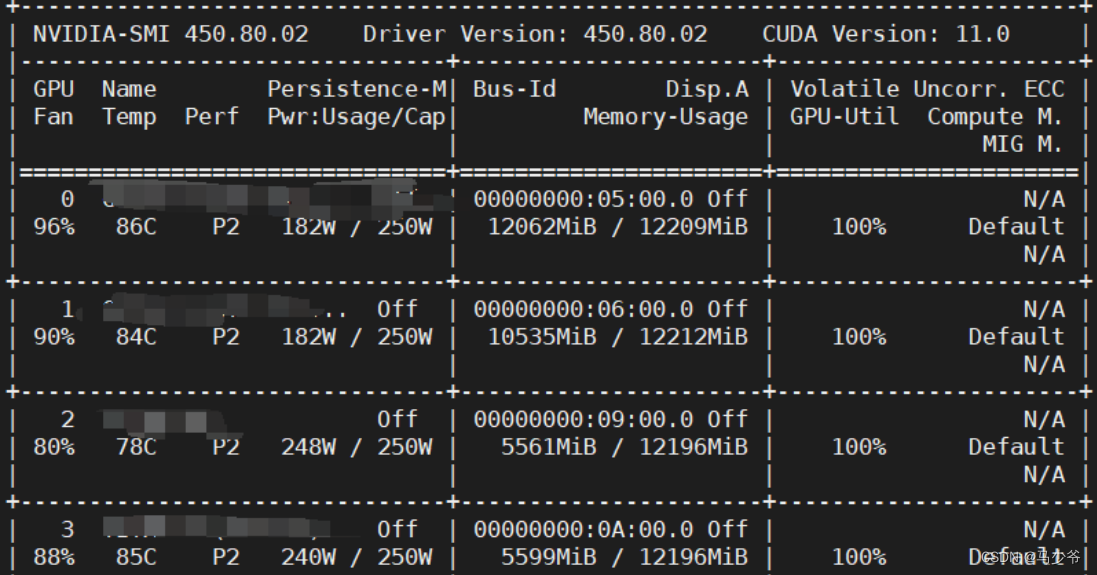
每个显卡之前有对应的编号。
然后得知自己服务器上总共有多少显卡后,插入以下代码:
#一机多卡设置
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'#设置所有可以使用的显卡,共计四块
device_ids = [0,1]#选中其中两块
model = nn.DataParallel(model, device_ids=device_ids)#并行使用两块
#net = torch.nn.Dataparallel(model) # 默认使用所有的device_ids
model = model.cuda()
- 1
- 2
- 3
- 4
- 5
- 6
有两个注意点:
(1)笔者自己使用该代码时,虽然device_ids中选择的是0/1两块显卡,但是实际上却是在2/3两块显卡上运行的,这个可能是显示问题,大家可以运行之后再使用nvidia-smi命令查看到底是在哪两块显卡上训练的
(2)这个代码是要写在模型装载之后,比如说举例
model = CANNet2s()
- 1
在这后加上图示代码,才可以将model分配到硬件上,此处我使用的是model.cuda()函数,大家也可以用todevice。
对比一下只使用一张显卡:
#一机单卡设置
model = model.cuda()
- 1
- 2
将会自动选择一张可以用的显卡进行训练。
参考文献:https://blog.csdn.net/qq_45860671/article/details/122413798
修改cycleGan中的代码如下
原代码
disc_H = Discriminator(in_channels=3).to(config.DEVICE)
disc_Z = Discriminator(in_channels=3).to(config.DEVICE)
gen_Z = Generator(img_channels=3, num_residuals=9).to(config.DEVICE)
gen_H = Generator(img_channels=3, num_residuals=9).to(config.DEVICE)
- 1
- 2
- 3
- 4
修改后的代码:
disc_H = Discriminator(in_channels=3)
disc_Z = Discriminator(in_channels=3)
gen_Z = Generator(img_channels=3, num_residuals=9)
gen_H = Generator(img_channels=3, num_residuals=9)
#使用多gpu加速
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
disc_H = nn.DataParallel(disc_H, device_ids=[0,1])
disc_Z = nn.DataParallel(disc_Z, device_ids=[0,1])
gen_Z = nn.DataParallel(gen_Z, device_ids=[0,1])
gen_H = nn.DataParallel(gen_H, device_ids=[0,1])
disc_H.to(config.DEVICE)
disc_Z.to(config.DEVICE)
gen_Z.to(config.DEVICE)
gen_H.to(config.DEVICE)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
参考文献:
https://blog.csdn.net/qq_34904125/article/details/118725862
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/708094
推荐阅读
相关标签

