
- 1城市交通大数据及智能应用
- 2设置 Ubuntu 系统自动关机小工具 EasyShutdown
- 3python使用时间戳计算运行时间_python timestamp时间计算
- 4蓝桥杯基础练习~报时助手&回形取数&龟兔赛跑预测_请你写一个程序,对于输入的一场比赛的数据v1,v2,t,s,l,预测该场比赛的结果。java
- 5java集合类库学习记录———ArrayList_java类库学习
- 6RT-Thread studio使用(持续更新)
- 7Java中实现使用EasyExcel和hutool导入导出功能_easyexcel 图片 hutool
- 8linux 查看内存占用率和占用前10的应用_linux查看内存占用前十
- 92023高频前端面试题(含答案)
- 10yolov--9--YOLO v3的稀疏化剪枝微调--优化细节流程_yolov9
Transformer(self attention)超详解&示例代码_transfomer attention例子
赞
踩
目录
说明
attention(注意力机制)有效解决了RNN网络对长序列编码效果差的问题。但是attention机制通常用在encoder-decoder结构中,首先通过encoder得到编码后的特征序列,然后进行打分。如果输入序列长度是30(即输入30个原始特征序列),则encoder会编码出30个编码后的特征。在解码时,每解码一次,都会对这30个编码后的特征进行打分求和,然后输入到解码器。
既然每次都是对全部编码后的特征进行打分,即每次解码都使用了全部信息,那么可不可以不使用编码后的特征,直接对原始特征进行打分呢,答案是可以的,即self attention。这样可以去掉encoder中的RNN网络,在训练时,encoder和decoder都可以一次就求出结果,而不是像RNN一样需要计算T次;在使用模型时,encoder可以直接求出结果。从而加速了训练和计算。
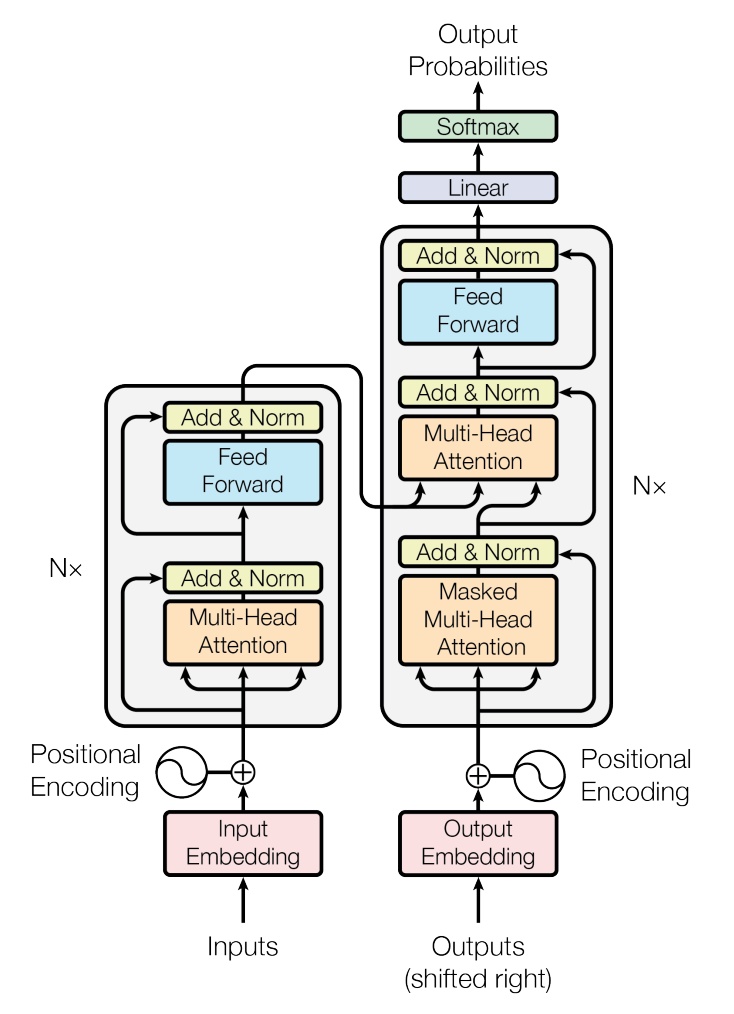
论文《Attention Is All You Need》提出了基于self attention的Transformer结构,如下图所示。接下来详细介绍Transformer并给出pytorch demo,demo的功能是使用transformer实现日期格式的转换,即:把任意格式的日期(human readable)转为固定格式(machine readable);比如把sunday november 30 1997转为1997-11-30,或者把20 july 2009转为2009-07-20等。
数据集介绍
这个demo用的数据集来自吴恩达老师的日期格式转换。输入是任意格式的日期(human readable),输出是固定格式(machine readable)。
词汇表使用单个char,因此对于Monday、July这样的单词,是被看做多个字符序列,而不是独立的单词。
输入数据的词汇表长度是37,包括一部分小写字母、数字、空格和<pad>、<unk>字符。
输出数据的词汇表长度是12,包括数字、减号和<pad>字符。
Encoder
上图的左边是encoder。接下来按图详细介绍encoder结构。
Input Embedding
Inputs是一个序列,如20 july 2009(长度是12),通过Input Embedding转为词向量。Input Embedding和Transformer结构无关,这里直接使用一层全连接把onehot向量转为长64的特征向量,即(N, T, 37)转为(N, T, 64)。
注意:N是batch size,T是N个序列中最大的长度,对于长度小于T的序列,要在末尾补充<pad>字符。不同的batch对应的T的长度不一定相同。
Positional Encoding
Transformer不包含RNN网络和卷积网络,只有全连接网络,因此无法获取输入序列的顺序信息。因此需要加入点东西,即Position Encoding。按照论文中的公式,生成一个(T, 64)维度的正余弦表,和上一层输出的(N, T, 64)相加即可(batch中所有的序列都加一样的正余弦表)。详情可参考demo代码。
输出尺寸依旧是(N, T, 64)。
Multi-Head Attention
如上图所示,Multi-Head Attention和Feed Forward是真正组成Encoder模块的单元。
Position Encoding输出的tensor维度是(N, T, 64),复制为3份,分别叫做Q、K和V,含义分别是query、key和value。然后Q、K和V输入到Multi-Head Attention中,如下图。注意:只有Linear部分是含有可学习参数的。

Multi-Head意思是多个head,即h个head,每个head都是一个self attention。在实际代码中,h个head是合并起来计算的,这样可以加速运算。
先看左下角接收V的Linear,假设Linear的输出是64,则我们把并列的h个Linear合并为一个矩阵,则此时左下角的h个Linear变成一个大的Linear,权重矩阵的尺寸是(64, h*64)(忽略bias),则V的维度从(N, T, 64)变为(N, T, h*64)。Q和K也是一样的。
此时Q、K和V的尺寸都是(N, T, h*64)。我们需要通过函数torch.tensor.view()把维度变成(N, T, h, 64),然后再通过函数torch.tensor.transpose()再把尺寸变成(N, h, T, 64),目的方便处理。
接下来Q、K和V输入到Scaled Dot-Product Attention(不含有可学习参数)。为了方便理解,我们只关心(N, h, T, 64)的后边两个尺寸(T, 64),即假设batch size和h都是1。
简化后Q和K的尺寸都是(T, 64),由于在解码时也有Scaled Dot-Product Attention结构,且存在Q和K尺寸不同的情况(但是K和V的尺寸一直相同),因此这里用两个T来表示,即Q是(T1, 64),K和V是(T2, 64)。这里T1和T2分别是原始序列长度和目标序列长度,在中英翻译任务中,分别是中文句子长度和英文句子长度。
Scaled Dot-Product Attention的第一步是使用Q和K进行打分,即下图红框部分。

让Q和K的转置进行矩阵乘法,即(T1, 64)*(64, T2)。如何理解呢:我们取Q的第0行和K的转置做乘法,即(1, 64)*(64, T2),这个含义是Q的第0次query(即第0次打分,对应t=0时刻),需要query全部key,即T2个key,因此打分的结果是一个长为T2的分数向量,每个key对应一个分数。
接着取出第1行,进行同样的操作。
最终得到T1个分数向量,每个分数向量长度为T2,即(T1, T2)尺寸的分数矩阵,记为Scores。此时可能Scores中的数值都很大,因此做一下scale,即除以
Mask在encoder中可以不使用,在decoder中讲述。打分的最后一步就是softmax。
第二步是将分数矩阵作用到V上,即下图的红框部分。
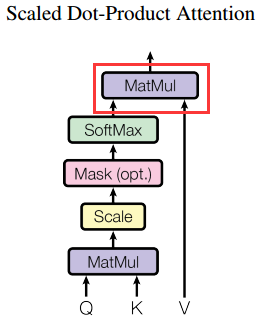
让Scores和V做矩阵乘法,即(T1, T2)*(T2, 64)。如何理解呢:我们取Scores的第0行,即第0个分数向量(对应t=0时刻),和全部value(T2个value)相乘,即(1, T2)*(T2, 64),得到第0时刻的V的加权和,即把V中的全部value向量都乘以对应的分数后加起来,尺寸是(1, 64)。
同样把其余行(t=1, 2, 3...T-1时刻)的分数向量作用到V,就得到T1个V的加权和。最终是(T1, 64)的尺寸。
至此Scaled Dot-Product Attention结束了。对于h!=1时,也是一样的操作,我们不需要关心前边的(N, h)两个维度。
然后是concat操作,只需要把尺寸从(N, h, T1, 64)调整回原来的(N, T1, h, 64),再调整为(N, T1, h*64)即可。即上文红色字的反向过程。
最后是一个全连接模块Linear,其权重矩阵尺寸是(h*64, 64),则最终输出的维度是(N, T1, 64)。我们设置合理的Linear权重尺寸,使得Multi-Head Attention的输入tensor和输出tensor的尺寸一致。
第一个Add&Norm
我们设置合理的Linear权重尺寸,使得Multi-Head Attention的输入tensor和输出tensor的尺寸一致。那么把输入和输出相加,即残差结构,然后经过LayerNorm,就是这部分内容。LayerNorm不含有可学习参数。
输出tensor的尺寸依旧是(N, T1, 64)。
Feed Forward
接下来是Feed Forward结构,这里就用一个普通的2层全连接网络即可,输出tensor依旧是(N, T1, 64)。
第二个Add&Norm
与第一个残差和Norm没有区别,输出尺寸依旧是(N, T1, 64)。
至此,encoder部分结束。我们设置合理的Linear权重尺寸,让下图红色箭头所指的两个位置(输入和输出)的tensor尺寸一致,两个箭头之间的部分我们记为Encoder模块。然后看图中左侧的N×,即表示有N个Encoder模块收尾相连。最后一个Encoder模块的输出传给Decoder。

Decoder
Decoder和Encoder几乎一样。
Output Embdeeing
我们解码的时候,需要使用当前已经解码出来的序列,因此Decoder的输入有两个来源,一个是Encoder输出的序列,另一个是已输出序列;对于已输出序列,可以是真实序列,也可以是Decoder自己输出的序列。在训练时我们使用真实序列,而Decoder自己输出的序列只用来计算loss。
但是不能简单地将真实序列全部都传给Decoder,因为我们在解码第3个字符时,只能使用真实序列中的0、1、2这三个字符。因此Decoder的第一个self attention模块是Masked Multi-Head Attention。这里Mask的作用是将真实序列中不能使用的部分对应的打分置零,详见后文。
至于Embedding,这里处理方式和Input Embedding相同。
Positional Encoding
和encoder的相同。
Masked Multi-Head Attention
Positional Encoding输出的tensor维度是(N, T, 64),复制为3份,分别叫做Q、K和V,含义分别是query、key和value。然后Q、K和V输入到Masked Multi-Head Attention中。
这里和Encoder唯一的区别就是多了个Mask。原因是:假设我们现在解码的是第3个字符,那么我们只能使用真实序列中的0、1、2这三个字符,因此我们需要一个长度为T的mask,其内容是[1, 1, 1, 0, 0....0],即前三个是1,后面都是0,表示我们要忽略真实序列中后边的字符。再看一次下图,粉红色区域的操作是把mask中为0的位置的打分置为一个绝对值很大的负数(
除了mask,其余的部分和Encoder中的都一样。最终的输出尺寸依旧是(N, T, 64),这里的T是输出序列的长度。
第一个Add&Norm
和Encoder里的没有区别,输出尺寸依旧是(N, T, 64)。
Multi-Head Attention
和Encoder里的没有区别,只是这里输入的Q和K、V不同,Q是从Masked Multi-Head Attention输出,在经过第一个Add&Norm得到的。而K和V是一样的,来自Encoder。
其余都是一样的,对于Q和K、V尺寸不同,就是T不同,已经在上文分析过了。
这里输出尺寸依旧是(N, T, 64)。
第二个Add&Norm
和Encoder里的没有区别,输出尺寸依旧是(N, T, 64)。
Linear
显然Linear是要做分类了,我们现在有T个长为64的特征向量,需要通过Linear把长度改为12(因为输出序列的词汇表长为12)。则这里Linear的权重尺寸是(64, 12)。
Softmax
分类任务的激活函数。
至此,Transformer就完成了。同样的,在Decoder部分也有一个N,即框中的部分有N个,首尾相连。不过要注意,来自Encoder部分的K和V复制了N次,分别输入给了N个Decoder模块。
Demo链接
https://github.com/zcsxll/date_trans_with_transformer
这里给出Decoder中第二个Multi-head attention模块中的分数热图,其中n_head=2,因此有两个热图。拿上边第0个self attention的分数热图来说明:纵轴是目标序列,从上往下,每一行对应一次解码,每次解码有T2个分数,颜色越深说明分数越大。
由于任务比较简单,因此两个热图比较像。


