
- 1Python 解码 Unicode 转义字符串
- 2奇富科技跻身国际AI学术顶级会议ICASSP 2024,AI智能感知能力迈入新纪元_icassp2024
- 3基于Java+SpringBoot+Vue前后端分离智能停车计费系统设计和实现_前后端分离停车场申请车位功能怎么写
- 4Docker file 搭建 Django镜像。-bash: django-admin: command not found,Invalid HTTP_HOST header:You may need_docker invalid host header
- 5程序员赚钱的六种方式:技术实力和市场分析能力是关键_稳定挣钱项目程序员
- 6特殊符号大全!_∴′
- 7Visual Studio 调试系列7 查看变量占用的内存(使用内存窗口)
- 8记录 | KMS工具激活Office报错 Error Code: 0x80080005_visio2019 激活 0x80080005
- 9win10系统激活遇到的问题_windows系统激活报错:错误 0xc004e028 在运行 microsoft windows
- 10如何理解三大微分中值定理
基于神经辐射场NeRF的SLAM方法_plenoctrees
赞
踩
随着2020年NeRF[1]的横空出世,神经辐射场方法(Neural Radiance Fields)如雨后春笋般铺天盖地卷来。NeRF最初用来进行图像渲染,即给定相机视角,渲染出该视角下的图像。NeRF是建立在已有相机位姿的情况下,但在大多数的机器人应用中,相机的位姿是未知的。所以随后,越来越多的工作应用NeRF的技术同时估计相机位姿和对环境建模,即NeRF-based SLAM (Simultaneously localization and mapping)。
将深度学习与传统几何融合是SLAM发展的趋势。过去我们看到SLAM中一些单点的模块,被神经网络所替代,比如特征提取(super point), 特征匹配(super glue),回环(NetVlad)和深度估计(mono-depth)等。相比较单点的替代,NeRF-based方法是一套全新的框架,可以端到端的替代传统SLAM,无论是在设计方法还是实现架构上。
相较于传统SLAM,NeRF-based 的方法,优点在于:
-
没有特征提取,直接操作原始像素值。误差回归到了像素本身,信息传递更加直接,优化过程所见即所得。
-
无论是隐式还是显式的map表达都可以进行微分,即可以对map进行full-dense优化 (传统SLAM基本无法优化dense map,通常只能优化有限数量的特征点或者对map进行覆盖更新)
由此可见,NeRF-based的方法上限极高,可以对map进行非常细致的优化。但这类方法缺点也很明显:
-
计算开销较大,优化时间长,难以实时。
但无法实时也只是暂时性的问题,后续会有大量的工作,来解决NeRF-based SLAM实时性的问题。
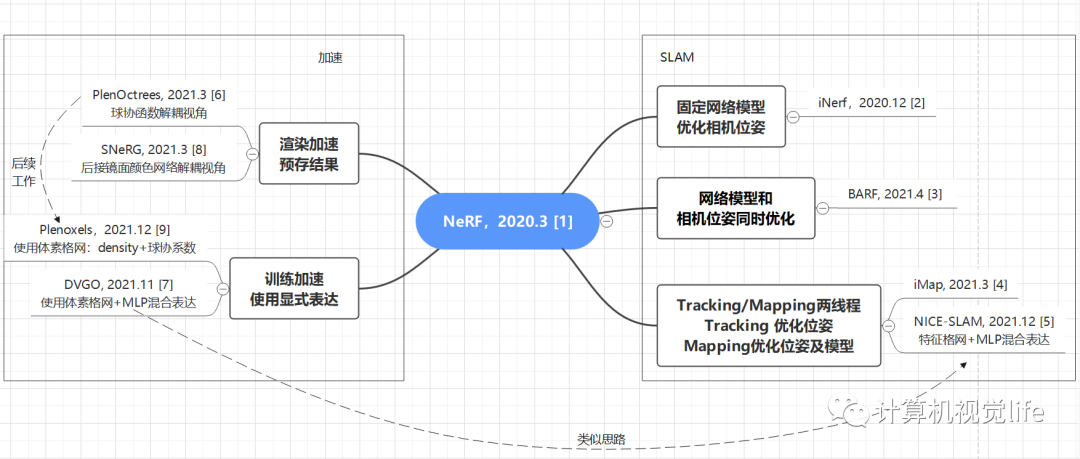
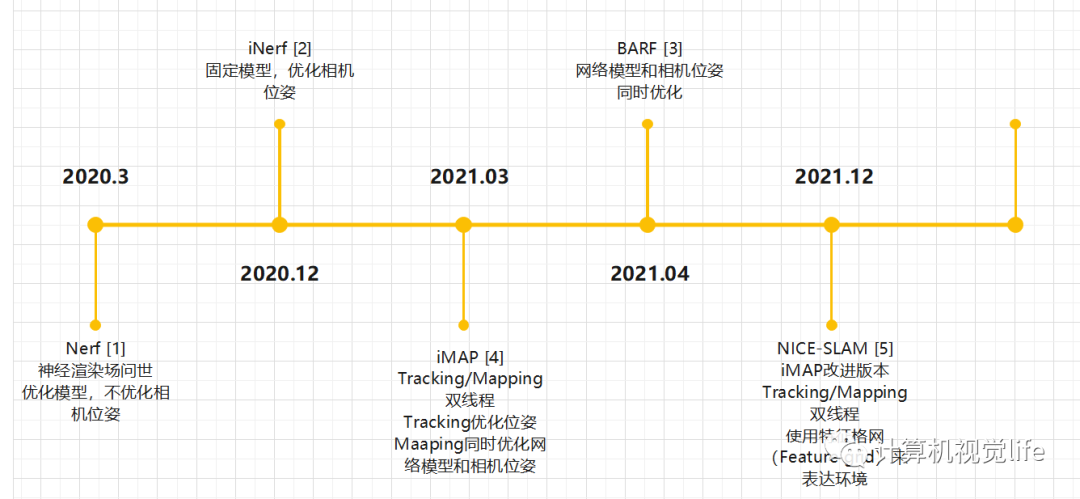
几篇Nerf-based SLAM工作的时间线:
1. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis

首先还是回顾一下经典的NeRF。NeRF选取一系列图片,这些图片的位姿已知。对像素射线上的点进行采样,每条射线采样几十个点(x,y,z,theta,phi),送入MLP网络(F_theta)。网络预测出该采样点的RGB和density(sigma)。再对射线上的点做辐射积分,得到该像素点的RGB值,和真值计算loss,梯度反传训练网络(F_theta)。该方法的优化的变量是MLP网络参数(F_theta),即场景表达隐含在网络当中。对相机的位姿不进行优化调整。
2. iNeRF: Inverting Neural Radiance Fields for Pose Estimation

iNeRF是第一个提出用NeRF model来做位姿估计的工作。iNeRF依赖一个已经提前建好的NeRF模型,F_theta。所以iNeRF并不算SLAM,而是一个已有模型下的重定位问题。和NeRF的区别在与,NeRF固定位姿,优化模型,loss反传到F_theta(如图红线所示);iNeRF固定模型,优化位姿,loss反传到pose 。
3. BARF : Bundle-Adjusting Neural Radiance Fields
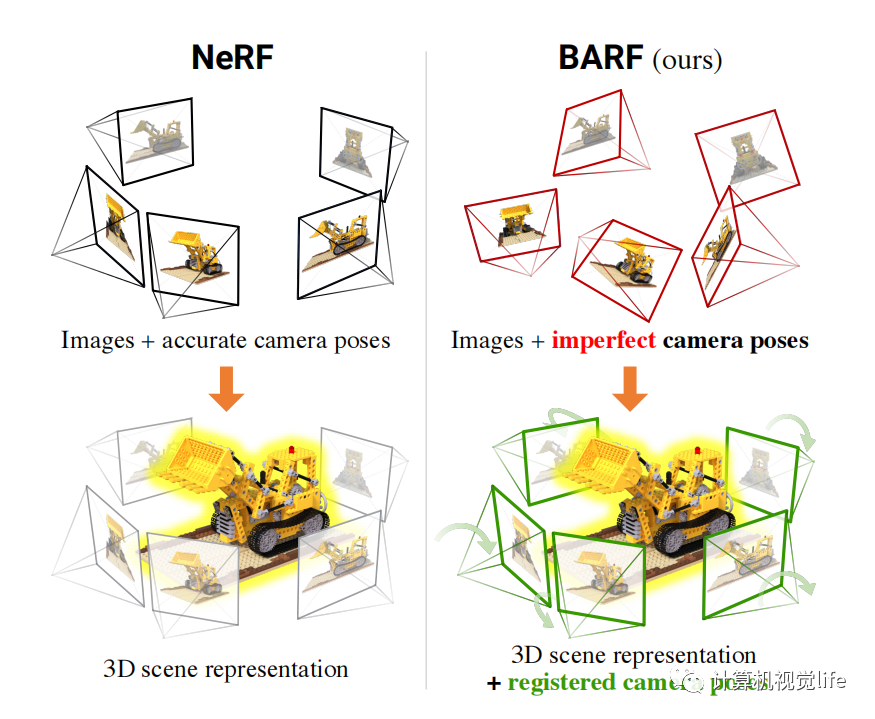
BARF这边篇文章同时优化网络模型和相机位姿,用神经渲染网络的方法实现了Bundle Adjustment。确切的说,该方法解决的是SfM (structure from motion)问题。该方法依赖一个粗糙的相机初始位姿,这个位姿可以通过col map等方法获得。通过网络迭代对模型和相机位姿进行精修。如果引入时序和帧间tracking,这将是一个不错的slam工作。
4. iMAP: Implicit Mapping and Positioning in Real-Time
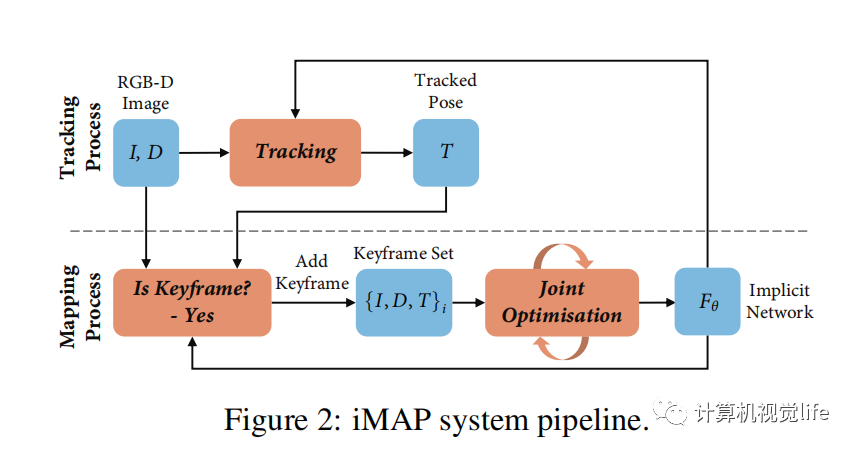
iMAP是真正意义上第一个NeRF-based SLAM 工作。iMAP使用的RGB-D图片,分为Tracking和Mapping两个线程。Tracking线程使用当前的模型,F_theta, 优化当前的相机位姿;判断该帧是不是关键帧,如果是关键帧,则关键帧的位姿和模型F_theta一同优化。iMAP的框架和传统SLAM类似,但核心的tracking和联合优化都有神经网络优化来完成。遗憾的是iMAP并未开源,但好消息是后面的工作nice-slam把iMAP的实现一同开源出来了。
5. NICE-SLAM: Neural Implicit Scalable Encoding for SLAM
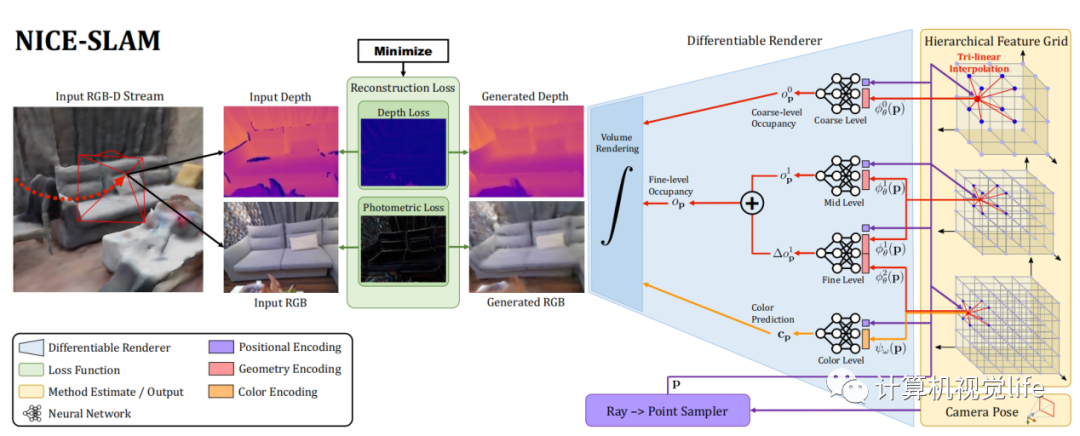
NICE-SLAM在iMAP的基础上做改动,作者不仅开源了自己这部分,也把iMAP的实现开源了出来。作者的主要改动是使用了特征格网(Feature Grid)+MLP这种显式+隐式混合的方法来表达环境。环境信息放在体素特征格网内,MLP作为decorder,将特征格网内蕴含的信息解码成occupancy和rgb。同时,作者还用了course-to-fine的思想,将特征格网分成粗、中和精细,以便更细致的表达。该方法比iMAP快了2-3倍,虽然具备了一定的实时性,但真正用起来还是离实时有一些距离。这是当前看到的最好、最完善的NeRF-based SLAM工作。
6. PlenOctrees for Real-time Rendering of Neural Radiance Fields
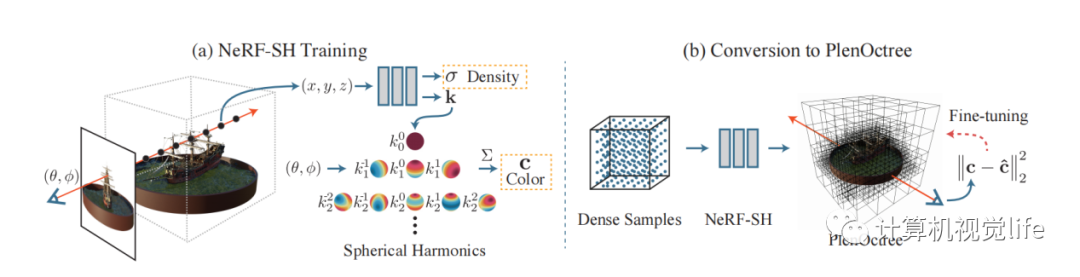
PlenOctrees是一种对渲染加速的方法。加速的方法是训练好mlp这种隐式表达之后,将空间中所有点以及所有视角观察都放到网络中推理,保存记录下来。这样下次使用时,就不必在线使用网络推理,查找表即可,加快渲染速度。但由于网络输入有x,y,z,theta,phi五个自由度,穷举起来数量爆炸。所以作者改造网络,将视角theta,phi从网络输入中解耦出来。网络只输入x,y,z,输出density和球协系数。颜色通过视角乘以球协函数得到。这样网络变量的自由度从5下降到3,可以进行穷举保存。
7. SNeRG:Baking Neural Radiance Fields for Real-Time View Synthesis
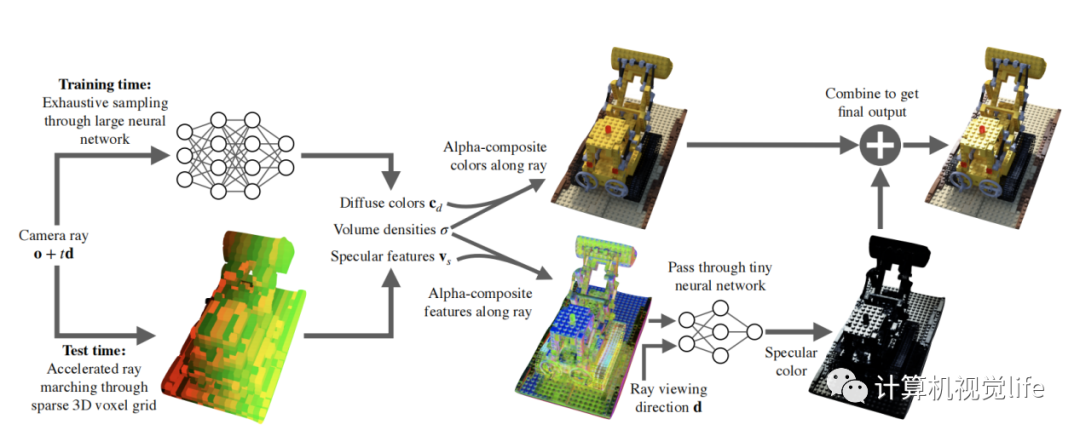
SNeRG和PlenOctrees类似,都是一种加速渲染的方法。Mlp训练好后,把与视角独立的信息存入3D体素格网内。在这篇文章中,作者把颜色分成固有颜色和镜面颜色,固有颜色与观察视角无关。网络输入3d坐标位置,输出体素密度,固有颜色,和镜面颜色特征向量。镜面颜色特征向量在通过一个小的网络,结合视角,解码成镜面颜色,加到最终的颜色上。与PlenOctrees一样,主干mlp网络都与视角解耦。PlenOctrees通过球协函数恢复视角颜色,SNeRG通过后接一个小网络恢复镜面颜色,在叠加到固有颜色上。
8. DVGO: Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction
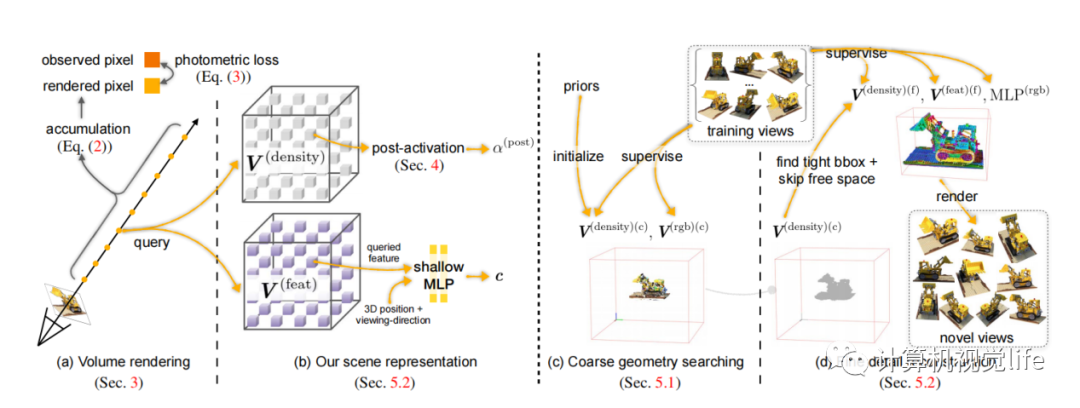
DVGO提出了对网络训练进行加速的方法。作者发现,使用MLP这种隐式表达,训练速度慢但效果好;使用体素格网这种显式表达,速度快但效果差。所以DVGO提出了混合的体素格网的表示方法。对于占据密度(density),直接使用体素格网,插值就可以得到任何位置的占据密度;对于颜色,体素格网里面存储多维向量,多维向量先经过插值,后经过MLP解码成rgb值。这样网络在训练过程中,用到MLP的次数减少;MLP只翻译颜色,也可以做的很轻量化,所以训练速度大幅提升。
9. Plenoxels: Radiance Fields without Neural Networks
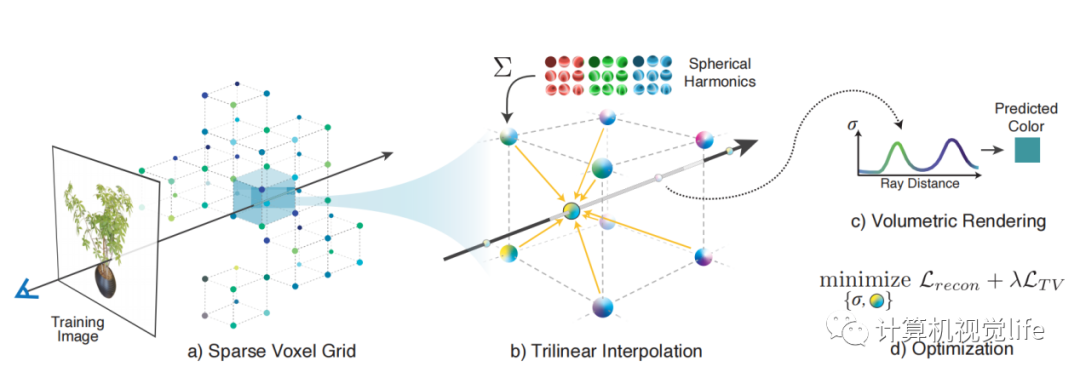
Plenoxels 是PlenOCtrees的后续工作。作者使用显式的格网来代替MLP。格网里面存储一维的density和球协系数。当有光线经过时,光线上的采样点的density和球协系数可由三线性插值得到。这样整个过程就摆脱了对神经网络的依赖,变成了完全显式的表达。由于去掉了神经网络MLP部分,训练速度大幅增加。作者强调神经辐射场的关键不是在于神经网络,而是在于可微分的渲染过程。
10. NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields
第一个结合稠密单目SLAM和层次化体素神经辐射场(hierarchical volumetric neural radiance fields)的3D场景重建算法,能实时地用图像序列实现准确的辐射场构建,并且不需要位姿或深度输入。
核心思想是,使用一个稠密单目SLAM pipeline来估计相机位姿和稠密深度图以及它们的不确定度,用上述信息作为监督信号来训练NeRF场景表征。

