
- 1GPT2模型源码阅读系列(二)一GPT2Model
- 2Ubuntu20.04 编译替换kernel内核记录_ubuntu kernel source
- 3vue3+vite+ChimeePlayer 视频播放器使用el-slider自定义播放进度条_el-slider做进度条
- 4opencv3.4.0在ubuntu16.04上的安装_linux 安装 videodev2.h
- 5【Rust blog】Rust + Flutter 高性能的跨端尝试
- 6Liunx shell编程及自动化运维实现--第五章三剑客
- 7TSINGSEE青犀视频太阳能监控助力野外安防建设
- 8使用PCReg.PyTorch项目训练自己的数据集&进行点云配准_点云配准 深度学习 软件
- 9vue中根据用户昵称首字母生成头像和颜色_vue-avatar
- 10k8s网络插件-calico
[NLP] LLM---<训练中文LLama2(三)>对LLama2进行中文预料预训练_llama 预训练
赞
踩
预训练
预训练部分可以为两个阶段:
- 第一阶段:冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量。
- 第二阶段:使用 LoRA 技术,为模型添加LoRA权重(adapter),训练embedding的同时也更新LoRA参数。
第一阶段预训练
由于第一阶段预训练会冻结transformer参数,仅训练embedding模型,因此,收敛速度较慢,如果不是有特别充裕的时间和计算资源,建议跳过该阶段。
第二阶段预训练
第二阶段预训练使用LoRA技术,为模型添加LoRA权重(adapter),训练embedding的同时也更新LoRA参数。
本文将分享Chinese-LLaMA-Alpaca Chinese-LLaMA-Alpaca-2是如何从0到1进行中文词表扩充、模型预训练和微调的整个过程
代码、模型、数据集准备
代码准备
下载代码。
- git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
- git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca-2.git
模型权重 及 Tokenizer 准备
下载LLaMA2原始权重HF
数据集准备
本文预训练数据集使用一些开源书籍,需预先执行下载其中一部分数据用于预训练或者使用其进行词表扩充训练。下载完之后,对其中的数据进行数据清洗,去除一些空行等。
词表扩充
可以参考
[NLP] LLM---<训练中文LLama2(二)>扩充LLama2词表构建中文tokenization_舒克与贝克的博客-CSDN博客
训练开始
首先,修改运行脚本run_pt.sh,需要修改的部分参数如下:
--model_name_or_path: 原版HF格式的LLaMA模型所在目录--tokenizer_name_or_path: Chinese-LLaMA tokenizer所在的目录--dataset_dir: 预训练数据的目录,可包含多个以txt结尾的纯文本文件--data_cache_dir: 指定一个存放数据缓存文件的目录--output_dir: 模型权重输出路径
其他参数(如:per_device_train_batch_size、training_steps等)是否修改视自身情况而定。
- # 运行脚本前请仔细阅读wiki(https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/pt_scripts_zh)
- # Read the wiki(https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/pt_scripts_zh) carefully before running the script
- lr=2e-4
- lora_rank=64
- lora_alpha=128
- lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
- modules_to_save="embed_tokens,lm_head"
- lora_dropout=0.05
-
- pretrained_model=../llama-2-7b
- chinese_tokenizer_path=./llama2_chinese3
- dataset_dir=./pt_dataset
- data_cache=./pt_dataset_cache
- per_device_train_batch_size=1
- gradient_accumulation_steps=8
- block_size=512
- output_dir=./output_dir
-
- deepspeed_config_file=ds_zero2_no_offload.json
-
- torchrun --nnodes 1 --nproc_per_node 1 run_clm_pt_with_peft.py \
- --deepspeed ${deepspeed_config_file} \
- --model_name_or_path ${pretrained_model} \
- --tokenizer_name_or_path ${chinese_tokenizer_path} \
- --dataset_dir ${dataset_dir} \
- --data_cache_dir ${data_cache} \
- --validation_split_percentage 0.001 \
- --per_device_train_batch_size ${per_device_train_batch_size} \
- --do_train \
- --seed $RANDOM \
- --fp16 \
- --num_train_epochs 1 \
- --lr_scheduler_type cosine \
- --learning_rate ${lr} \
- --warmup_ratio 0.05 \
- --weight_decay 0.01 \
- --logging_strategy steps \
- --logging_steps 10 \
- --save_strategy steps \
- --save_total_limit 3 \
- --save_steps 200 \
- --gradient_accumulation_steps ${gradient_accumulation_steps} \
- --preprocessing_num_workers 8 \
- --block_size ${block_size} \
- --output_dir ${output_dir} \
- --overwrite_output_dir \
- --ddp_timeout 30000 \
- --logging_first_step True \
- --lora_rank ${lora_rank} \
- --lora_alpha ${lora_alpha} \
- --trainable ${lora_trainable} \
- --lora_dropout ${lora_dropout} \
- --modules_to_save ${modules_to_save} \
- --torch_dtype float16 \
- --load_in_kbits 16 \
- --gradient_checkpointing \
- --ddp_find_unused_parameters False

这里为了测试:只在pt_dataset下放了一个只有5000行的文本语料
root@llm:/home/work/training-llama2# wc -l pt_dataset/*
5000 pt_dataset/corpus.txt
具体执行过程如下所示:



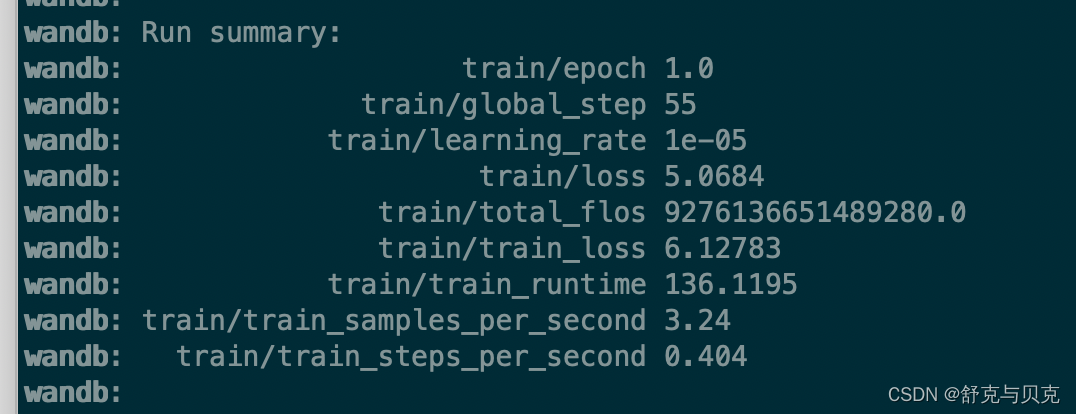
模型输出文件:
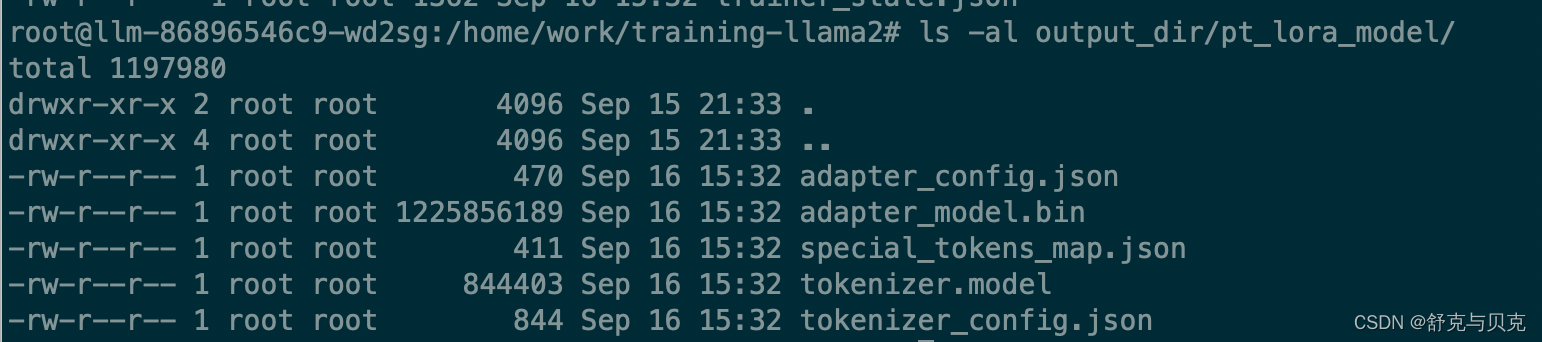
将 LoRA 权重与基础模型合并
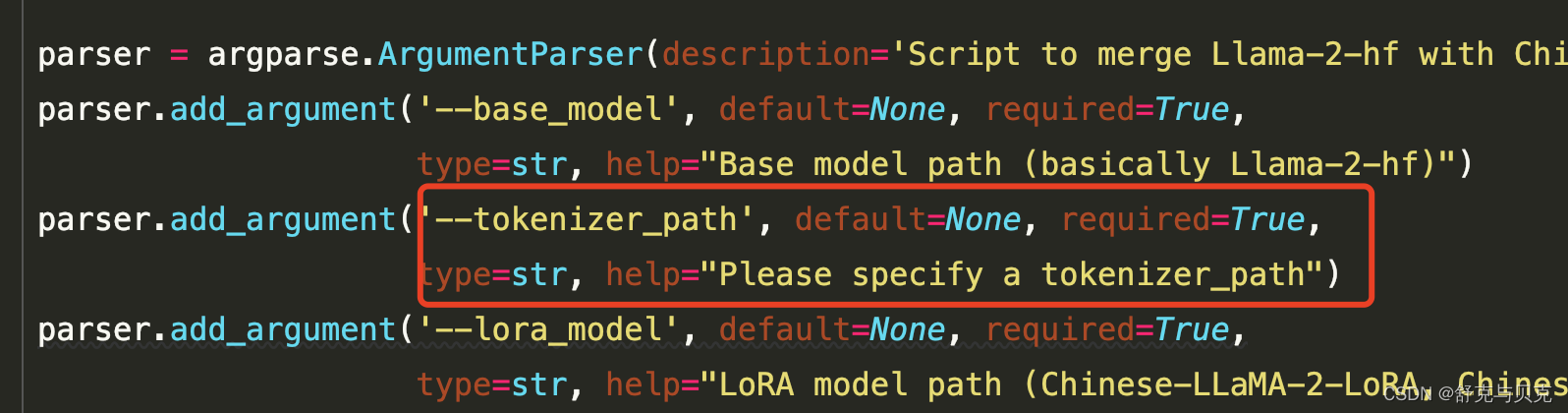
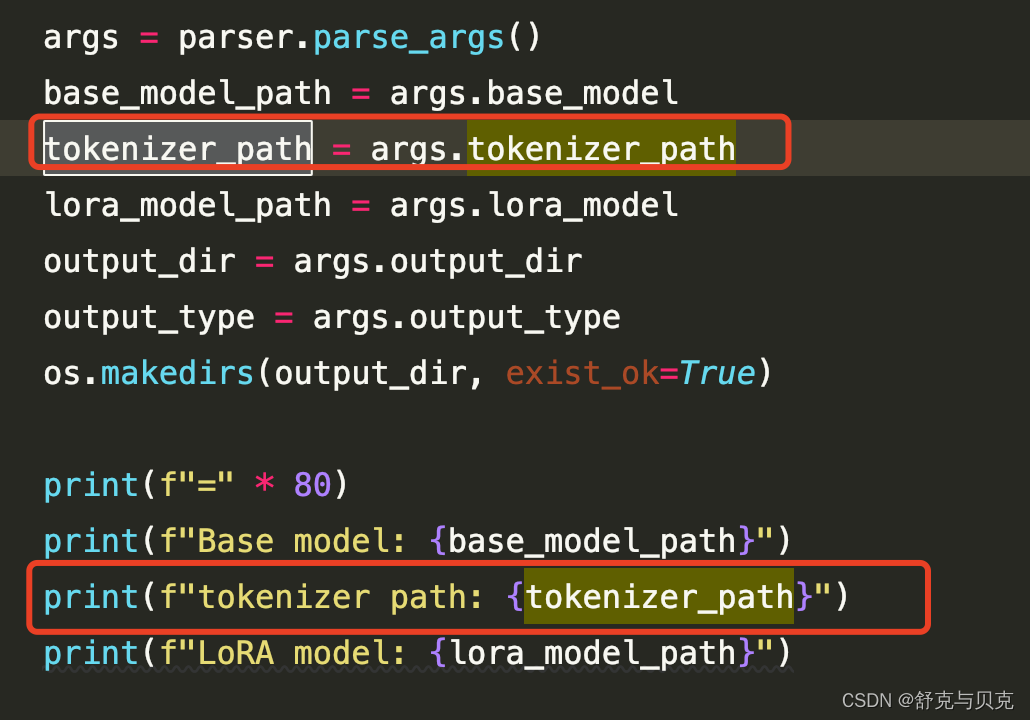
修改权重合并脚本merge_llama2_with_chinese_lora_low_mem.py,新增一个tokenizer_path参数接收分词器目录,同lora_model一样可以传入多个目录,中间用逗号,分割。
run_merge_pt_chinese.sh
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录--lora_model:中文LLaMA/Alpaca LoRA解压后文件所在目录--tokenizer_path:分词器所在目录--output_type: 指定输出格式,可为pth或huggingface。若不指定,默认为pth--output_dir:指定保存全量模型权重的目录,默认为./
- pretrained_model=../llama-2-7b
- chinese_tokenizer_path=./llama2_chinese3
- lora_model=./output_dir/pt_lora_model
- output_dir=./merged_output_dir
-
- python merge_llama2_with_chinese_lora_low_mem.py \
- --base_model ${pretrained_model} \
- --tokenizer_path ${chinese_tokenizer_path} \
- --lora_model ${lora_model} \
- --output_type huggingface \
- --output_dir ${output_dir}
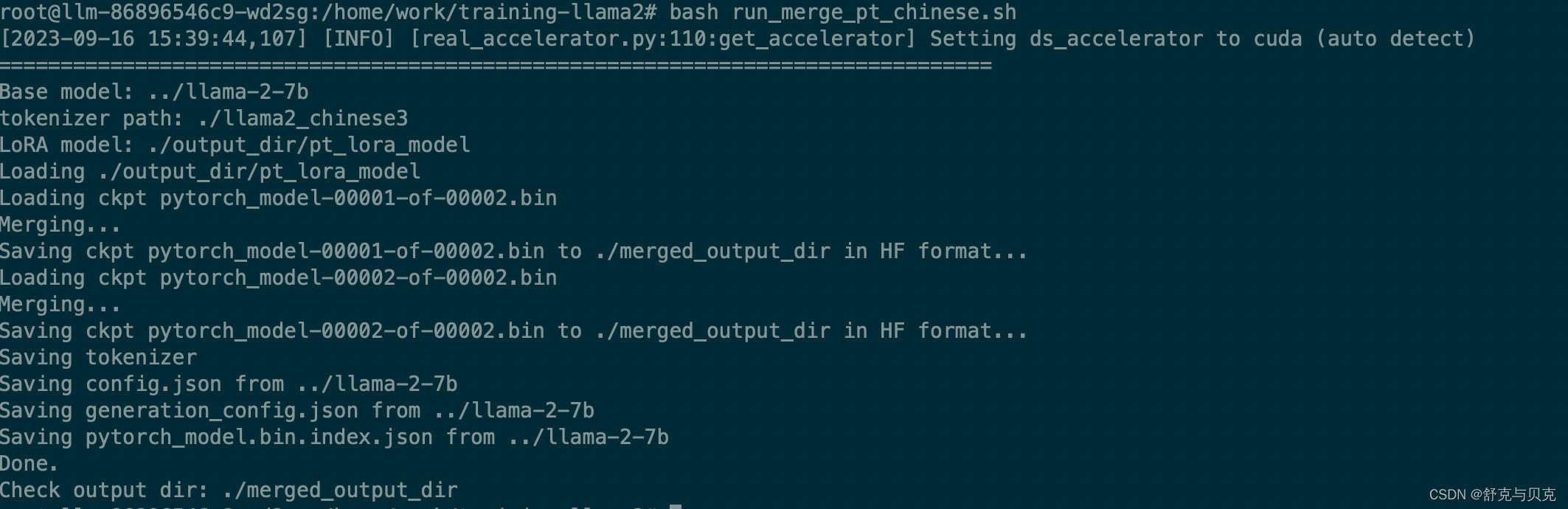
合并输出如下:
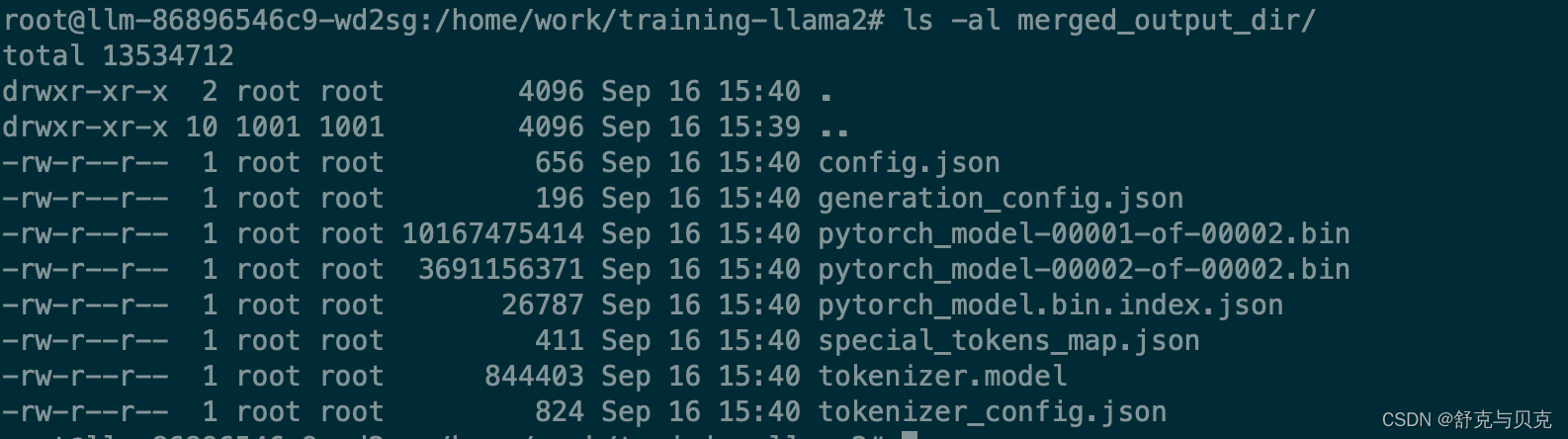
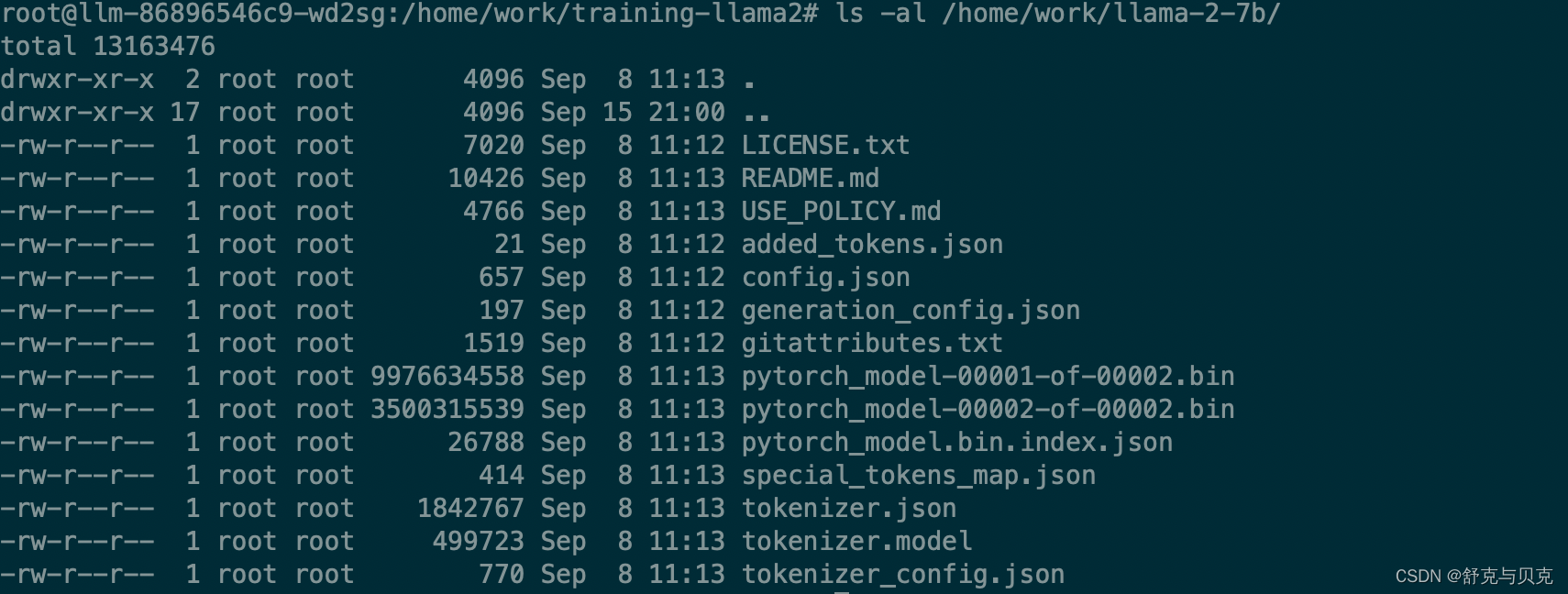
权重合并前后的对比:
1.合并后的
2.原始的
到现在已经使用扩充的中文词表,对LLama2进行了预训练,生成lora模型,并合并成最后的hf模型

