
Kafka 3.0新特性 详解_kafka 3.4 新特性
赞
踩
Kafka 3.0新特性 详解
文章目录
- Kafka 3.0新特性 详解
- **参考资料:**
- 总结
- **参考资料:**
- 总结
导语 | kafka3.0的版本已经试推行去zk的kafka架构了,如果去掉了zk,那么在kafka新的版本当中使用什么技术来代替了zk的位置呢,接下来我们一起来一探究竟,了解kafka的内置共识机制和raft算法。
一、Kafka简介
Kafka是一款开源的消息引擎系统。一个典型的Kafka体系架构包括若干Producer、若干Broker、若干Consumer,以及一个ZooKeeper集群,如上图所示。其中ZooKeeper是Kafka用来负责集群元数据的管理、控制器的选举等操作的。Producer将消息发送到Broker,Broker负责将收到的消息存储到磁盘中,而Consumer负责从Broker订阅并消费消息。
(一)Kafka核心组件
-
producer:消息生产者,就是向broker发送消息的客户端。
-
consumer:消息消费者,就是从broker拉取数据的客户端。
-
consumer group:消费者组,由多个消费者consumer组成。消费者组内每个消费者负责消费不同的分区,一个分区只能由同一个消费者组内的一个消费者消费;消费者组之间相互独立,互不影响。所有的消费者都属于某个消费者组,即消费者组是一个逻辑上的订阅者。
-
broker:一台服务器就是一个broker,一个集群由多个broker组成,一个broker可以有多个topic。
-
topic:可以理解为一个队列,所有的生产者和消费者都是面向topic的。
-
partition:分区,kafka中的topic为了提高拓展性和实现高可用而将它分布到不同的broker中,一个topic可以分为多个partition,每个partition都是有序的,即消息发送到队列的顺序跟消费时拉取到的顺序是一致的。
-
replication:副本。一个topic对应的分区partition可以有多个副本,多个副本中只有一个为leader,其余的为follower。为了保证数据的高可用性,leader和follower会尽量均匀的分布在各个broker中,避免了leader所在的服务器宕机而导致topic不可用的问题。
(二)kafka2当中zk的作用
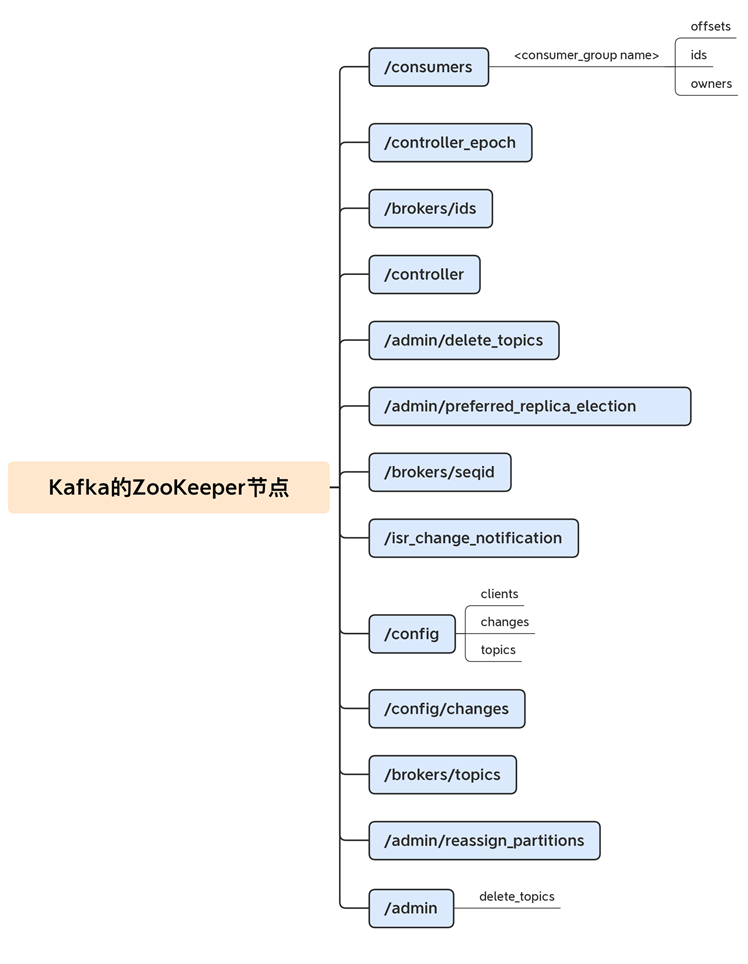
-
/admin:主要保存kafka当中的核心的重要信息,包括类似于已经删除的topic就会保存在这个路径下面。
-
/brokers:主要用于保存kafka集群当中的broker信息,以及没被删除的topic信息。
-
/cluster: 主要用于保存kafka集群的唯一id信息,每个kafka集群都会给分配要给唯一id,以及对应的版本号。
-
/config: 集群配置信息。
-
/controller:kafka集群当中的控制器信息,控制器组件(Controller),是Apache Kafka的核心组件。它的主要作用是在Apache ZooKeeper的帮助下管理和协调整个Kafka集群。
-
/controller_epoch:主要用于保存记录controller的选举的次数。
-
/isr_change_notification:isr列表发生变更时候的通知,在kafka当中由于存在ISR列表变更的情况发生,为了保证ISR列表更新的及时性,定义了isr_change_notification这个节点,主要用于通知Controller来及时将ISR列表进行变更。
-
/latest_producer_id_block:使用
/latest_producer_id_block节点来保存PID块,主要用于能够保证生产者的任意写入请求都能够得到响应。 -
/log_dir_event_notification:主要用于保存当broker当中某些LogDir出现异常时候,例如磁盘损坏,文件读写失败等异常时候,向ZK当中增加一个通知序号,controller监听到这个节点的变化之后,就会做出对应的处理操作。
以上就是kafka在zk当中保留的所有的所有的相关的元数据信息,这些元数据信息保证了kafka集群的正常运行。
二、kafka3的安装配置
在kafka3的版本当中已经彻底去掉了对zk的依赖,如果没有了zk集群,那么kafka当中是如何保存元数据信息的呢,这里我们通过kafka3的集群来一探究竟。
(一)kafka安装配置核心重要参数
- Controller服务器
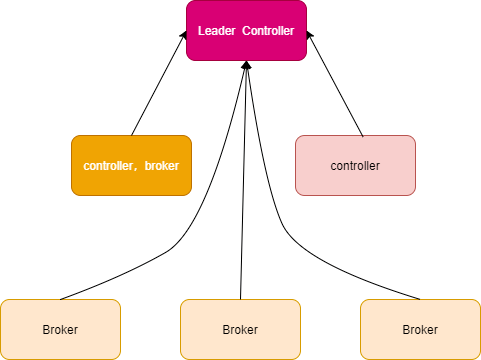
不管是kafka2还是kafka3当中,controller控制器都是必不可少的,通过controller控制器来维护kafka集群的正常运行,例如ISR列表的变更,broker的上线或者下线,topic的创建,分区的指定等等各种操作都需要依赖于Controller,在kafka2当中,controller的选举需要通过zk来实现,我们没法控制哪些机器选举成为Controller,而在kafka3当中,我们可以通过配置文件来自己指定哪些机器成为Controller,这样做的好处就是我们可以指定一些配置比较高的机器作为Controller节点,从而保证controller节点的稳健性。
被选中的controller节点参与元数据集群的选举,每个controller节点要么是Active状态,或者就是standBy状态。
使用KRaft模式来运行kafka集群的话,我们有一个配置叫做Process.Roles必须配置,这个参数有以下四个值可以进行配置:
-
Process.Roles=Broker, 服务器在KRaft模式中充当Broker。
-
Process.Roles=Controller, 服务器在KRaft模式下充当Controller。
-
Process.Roles=Broker,Controller,服务器在KRaft模式中同时充当Broker和Controller。
-
如果process.roles没有设置。那么集群就假定是运行在ZooKeeper模式下。
如果需要从zookeeper模式转换成为KRaft模式,那么需要进行重新格式化。如果一个节点同时是Broker和Controller节点,那么就称之为组合节点。
实际工作当中,如果有条件的话,尽量还是将Broker和Controller节点进行分离部署。避免由于服务器资源不够的情况导致OOM等一系列的问题
通过controller.quorum.voters配置来实习哪些节点是Quorum的投票节点,所有想要成为控制器的节点,都必须放到这个配置里面。
每个Broker和每个Controller都必须配置Controller.quorum.voters,该配置当中提供的节点ID必须与提供给服务器的节点ID保持一直。
每个Broker和每个Controller 都必须设置 controller.quorum.voters。需要注意的是,controller.quorum.voters 配置中提供的节点ID必须与提供给服务器的节点ID匹配。
比如在Controller1上,node.Id必须设置为1,以此类推。注意,控制器id不强制要求你从0或1开始。然而,分配节点ID的最简单和最不容易混淆的方法是给每个服务器一个数字ID,然后从0开始。
(二)下载并解压安装包
bigdata01下载kafka的安装包,并进行解压:
[hadoop@bigdata01 kraft]$ cd /opt/soft/[hadoop@bigdata01 soft]$ wget http://archive.apache.org/dist/kafka/3.1.0/kafka_2.12-3.1.0.tgz[hadoop@bigdata01 soft]$ tar -zxf kafka_2.12-3.1.0.tgz -C /opt/install/
- 1
修改kafka的配置文件broker.properties:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ cd /opt/install/kafka_2.12-3.1.0/config/kraft/[hadoop@bigdata01 kraft]$ vim broker.properties
- 1
修改编辑内容如下:
node.id=1controller.quorum.voters=1@bigdata01:9093listeners=PLAINTEXT://bigdata01:9092advertised.listeners=PLAINTEXT://bigdata01:9092log.dirs=/opt/install/kafka_2.12-3.1.0/kraftlogs
- 1
创建两个文件夹:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ mkdir -p /opt/install/kafka_2.12-3.1.0/kraftlogs[hadoop@bigdata01 kafka_2.12-3.1.0]$ mkdir -p /opt/install/kafka_2.12-3.1.0/topiclogs
- 1
同步安装包到其他机器上面去。
(三)服务器集群启动
启动kafka服务:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ ./bin/kafka-storage.sh random-uuidYkJwr6RESgSJv-sxa1R1mA[hadoop@bigdata01 kafka_2.12-3.1.0]$ ./bin/kafka-storage.sh format -t YkJwr6RESgSJv-sxa1R1mA -c ./config/kraft/server.propertiesFormatting /opt/install/kafka_2.12-3.1.0/topiclogs[hadoop@bigdata01 kafka_2.12-3.1.0]$ ./bin/kafka-server-start.sh ./config/kraft/server.properties
- 1
(四)创建kafka的topic
集群启动成功之后,就可以来创建kafka的topic了,使用以下命令来创建kafka的topic:
./bin/kafka-topics.sh --create --topic kafka_test --partitions 3 --replication-factor 2 --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092
- 1
(五)任意一台机器查看kafka的topic
组成集群之后,任意一台机器就可以通过以下命令来查看到刚才创建的topic了:
[hadoop@bigdata03 ~]$ cd /opt/install/kafka_2.12-3.1.0/[hadoop@bigdata03 kafka_2.12-3.1.0]$ bin/kafka-topics.sh --list --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092
- 1
(六)消息生产与消费
使用命令行来生产以及消费kafka当中的消息:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ bin/kafka-console-producer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic kafka_test
[hadoop@bigdata02 kafka_2.12-3.1.0]$ bin/kafka-console-consumer.sh --bootstrap-server bigdata01:9092,bigdata02:9092,bigdata03:9092 --topic kafka_test --from-beginning
- 1
- 2
三、Kafka当中Raft的介绍
(一)kafka强依赖zk所引发的问题
前面我们已经看到了kafka3集群在没有zk集群的依赖下,也可以正常运行,那么kafka2在zk当中保存的各种重要元数据信息,在kafka3当中如何实现保存的呢?
kafka一直都是使用zk来管理集群以及所有的topic的元数据,并且使用了zk的强一致性来选举集群的controller,controller对整个集群的管理至关重要,包括分区的新增,ISR列表的维护,等等很多功能都需要靠controller来实现,然后使用zk来维护kafka的元数据也存在很多的问题以及存在性能瓶颈。
以下是kafka将元数据保存在zk当中的诸多问题。
- 元数据存取困难
元数据的存取过于困难,每次重新选举的controller需要把整个集群的元数据重新restore,非常的耗时且影响集群的可用性。
- 元数据更新网络开销大
整个元数据的更新操作也是以全量推的方式进行,网络的开销也会非常大。
- 强耦合违背软件设计原则
Zookeeper对于运维来说,维护Zookeeper也需要一定的开销,并且kafka强耦合与zk也并不好,还得时刻担心zk的宕机问题,违背软件设计的高内聚,低耦合的原则。
- 网络分区复杂度高
Zookeeper本身并不能兼顾到broker与broker之间通信的状态,这就会导致网络分区的复杂度成几何倍数增长。
- zk本身不适合做消息队列
zookeeper不适合做消息队列,因为zookeeper有1M的消息大小限制 zookeeper的children太多会极大的影响性能znode太大也会影响性能 znode太大会导致重启zkserver耗时10-15分钟 zookeeper仅使用内存作为存储,所以不能存储太多东西。
- 并发访问zk问题多
最好单线程操作zk客户端,不要并发,临界、竞态问题太多。
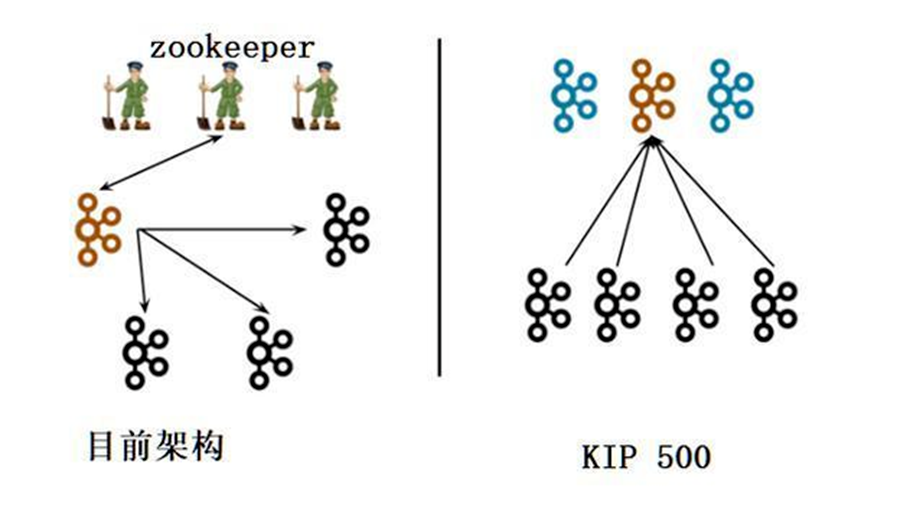
基于以上各种问题,所以提出了脱离zk的方案,转向自助研发强一致性的元数据解决方案,也就是KIP-500。
KIP-500议案提出了在Kafka中处理元数据的更好方法。基本思想是"Kafka on Kafka",将Kafka的元数据存储在Kafka本身中,无需增加额外的外部存储比如ZooKeeper等。
去zookeeper之后的kafka新的架构
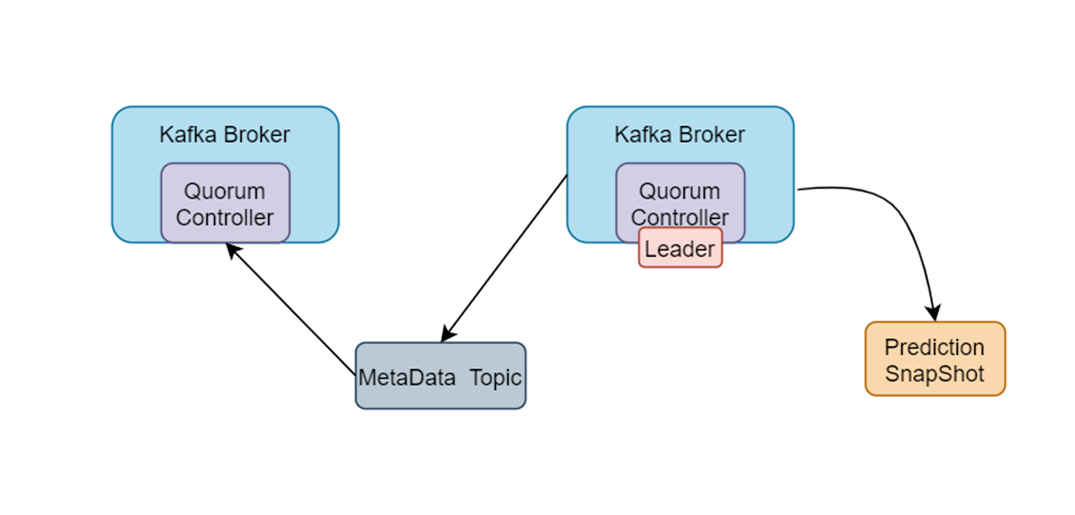
在KIP-500中,Kafka控制器会将其元数据存储在Kafka分区中,而不是存储在ZooKeeper中。但是,由于控制器依赖于该分区,因此分区本身不能依赖控制器来进行领导者选举之类的事情。而是,管理该分区的节点必须实现自我管理的Raft仲裁。
在kafka3.0的新的版本当中,使用了新的KRaft协议,使用该协议来保证在元数据仲裁中准确的复制元数据,这个协议类似于zk当中的zab协议以及类似于Raft协议,但是KRaft协议使用的是基于事件驱动的模式,与ZAB协议和Raft协议还有点不一样
在kafka3.0之前的的版本当中,主要是借助于controller来进行leader partition的选举,而在3.0协议当中,使用了KRaft来实现自己选择leader,并最终令所有节点达成共识,这样简化了controller的选举过程,效果更加高效。
(二)kakfa3 Raft
前面我们已经知道了在kafka3当中可以不用再依赖于zk来保存kafka当中的元数据了,转而使用Kafka Raft来实现元数据的一致性,简称KRaft,并且将元数据保存在kafka自己的服务器当中,大大提高了kafka的元数据管理的性能。
KRaft运行模式的Kafka集群,不会将元数据存储在Apache ZooKeeper中。即部署新集群的时候,无需部署ZooKeeper集群,因为Kafka将元数据存储在Controller节点的KRaft Quorum中。KRaft可以带来很多好处,比如可以支持更多的分区,更快速的切换Controller,也可以避免Controller缓存的元数据和Zookeeper存储的数据不一致带来的一系列问题。
在新的版本当中,控制器Controller节点我们可以自己进行指定,这样最大的好处就是我们可以自己选择一些配置比较好的机器成为Controller节点,而不像在之前的版本当中,我们无法指定哪台机器成为Controller节点,而且controller节点与broker节点可以运行在同一台机器上,并且控制器controller节点不再向broker推送更新消息,而是让Broker从这个Controller Leader节点进行拉去元数据的更新。
(三)如何查看kafka3当中的元数据信息
在kafka3当中,不再使用zk来保存元数据信息了,那么在kafka3当中如何查看元数据信息呢,我们也可以通过kafka自带的命令来进行查看元数据信息,在KRaft中,有两个命令常用命令脚本,kafka-dump-log.sh和kakfa-metadata-shell.sh需要我们来进行关注,因为我们可以通过这两个脚本来查看kafka当中保存的元数据信息。
KRaft模式下,所有的元数据信息都保存到了一个内部的topic上面,叫做@metadata,例如Broker的信息,Topic的信息等,我们都可以去到这个topic上面进行查看,我们可以通过kafka-dump-log.sh这个脚本来进行查看该topic的信息。
Kafka-dump-log.sh是一个之前就有的工具,用来查看Topic的的文件内容。这工具加了一个参数–cluster-metadata-decoder用来,查看元数据日志,如下所示:
[hadoop@bigdata01 kafka_2.12-3.1.0]$ cd /opt/install/kafka_2.12-3.1.0[hadoop@bigdata01 kafka_2.12-3.1.0]$ bin/kafka-dump-log.sh --cluster-metadata-decoder --skip-record-metadata --files /opt/install/kafka_2.12-3.1.0/topiclogs/__cluster_metadata-0/00000000000000000000.index,/opt/install/kafka_2.12-3.1.0/topiclogs/__cluster_metadata-0/00000000000000000000.log >>/opt/metadata.txt
- 1
平时我们用zk的时候,习惯了用zk命令行查看数据,简单快捷。bin目录下自带了kafka-metadata-shell.sh工具,可以允许你像zk一样方便的查看数据。
使用kafka-metadata-shell.sh脚本进入kafka的元数据客户端
[hadoop@bigdata01 kafka_2.12-3.1.0]$ bin/kafka-metadata-shell.sh --snapshot /opt/install/kafka_2.12-3.1.0/topiclogs/__cluster_metadata-0/00000000000000000000.log
- 1
四、Raft算法介绍
raft算法中文版本翻译介绍:
https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
著名的CAP原则又称CAP定理的提出,真正奠基了分布式系统的诞生,CAP定理指的是在一个分布式系统中,[一致性]、[可用性](Availability)、[分区容错性](Partition tolerance),这三个要素最多只能同时实现两点,不可能三者兼顾(nosql)。
分布式系统为了提高系统的可靠性,一般都会选择使用多副本的方式来进行实现,例如hdfs当中数据的多副本,kafka集群当中分区的多副本等,但是一旦有了多副本的话,那么久面临副本之间一致性的问题,而一致性算法就是 用于解决分布式环境下多副本的数据一致性的问题。业界最著名的一致性算法就是大名鼎鼎的Paxos,但是Paxos比较晦涩难懂,不太容易理解,所以还有一种叫做Raft的算法,更加简单容易理解的实现了一致性算法。
(一)Raft协议的工作原理
Raft协议将分布式系统当中的角色分为Leader(领导者),Follower(跟从者)以及Candidate(候选者)
-
Leader:主节点的角色,主要是接收客户端请求,并向Follower同步日志,当日志同步到过半及以上节点之后,告诉follower进行提交日志。
-
Follower:从节点的角色,接受并持久化Leader同步的日志,在Leader通知可以提交日志之后,进行提交保存的日志。
-
Candidate:Leader选举过程中的临时角色。
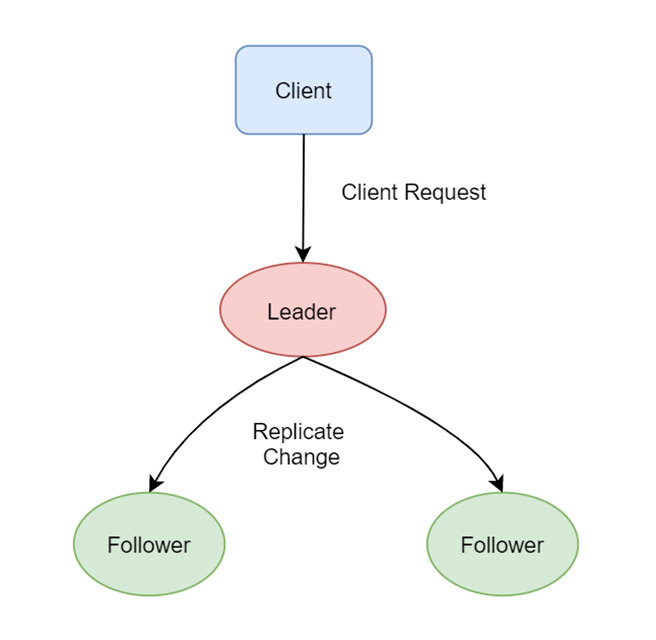
Raft协议当中会选举出Leader节点,Leader作为主节点,完全负责replicate log的管理。Leader负责接受所有客户端的请求,然后复制到Follower节点,如果leader故障,那么follower会重新选举leader,Raft协议的一致性,概括主要可以分为以下三个重要部分:
-
Leader选举
-
日志复制
-
安全性
其中Leader选举和日志复制是Raft协议当中最为重要的。
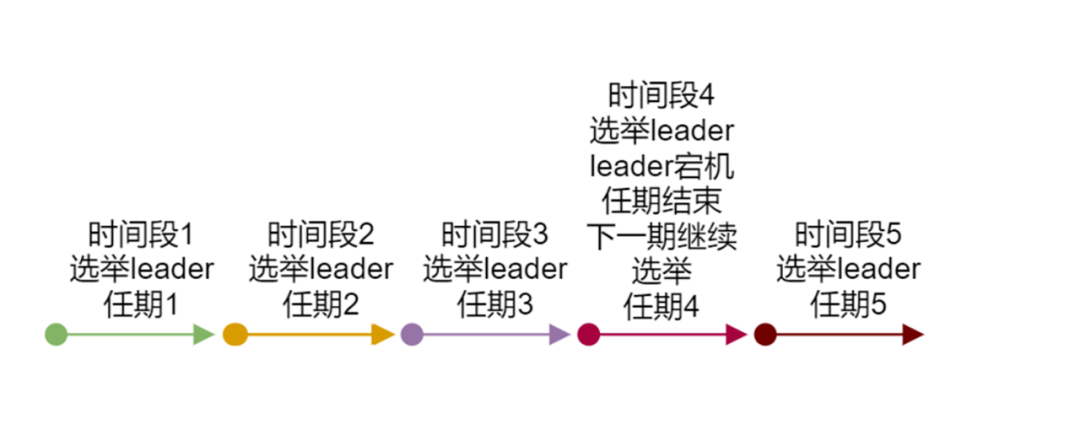
Raft协议要求系统当中,任意一个时刻,只有一个leader,正常工作期间,只有Leader和Follower角色,并且Raft协议采用了类似网络租期的方式来进行管理维护整个集群,Raft协议将时间分为一个个的时间段(term),也叫作任期,每一个任期都会选举一个Leader来管理维护整个集群,如果这个时间段的Leader宕机,那么这一个任期结束,继续重新选举leader。
Raft算法将时间划分成为任意不同长度的任期(term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft算法保证在给定的一个任期最多只有一个领导人。
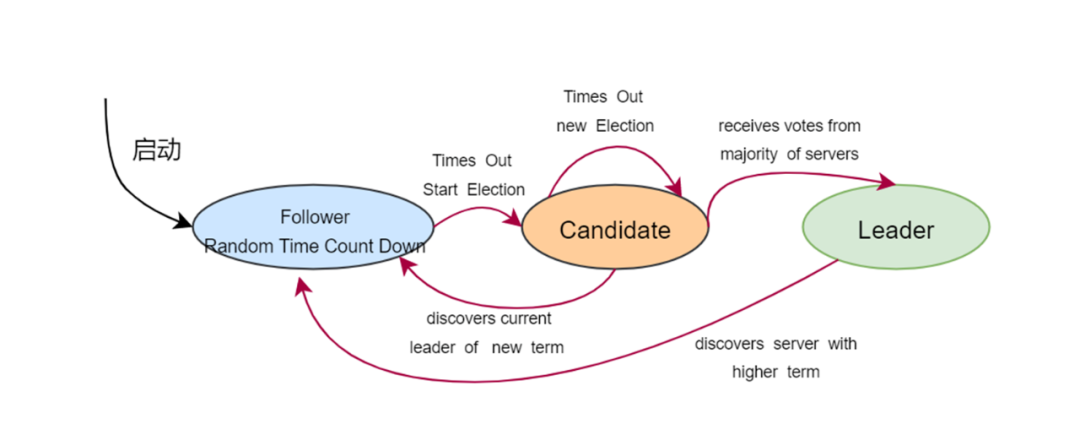
Raft使用心跳来进行触发leader选举,当服务器启动时,初始化为follower角色。leader向所有Follower发送周期性心跳,如果Follower在选举超时间内没有收到Leader的心跳,就会认为leader宕机,稍后发起leader的选举。
每个Follower都会有一个倒计时时钟,是一个随机的值,表示的是Follower等待成为Leader的时间,倒计时时钟先跑完,就会当选成为Leader,这样做得好处就是每一个节点都有机会成为Leader。
当满足以下三个条件之一时,Quorum中的某个节点就会触发选举:
-
向Leader发送Fetch请求后,在超时阈值quorum.fetch.timeout.ms之后仍然没有得到Fetch响应,表示Leader疑似失败。
-
从当前Leader收到了EndQuorumEpoch请求,表示Leader已退位。
-
Candidate状态下,在超时阈值quorum.election.timeout.ms之后仍然没有收到多数票,也没有Candidate赢得选举,表示此次选举作废,重新进行选举。
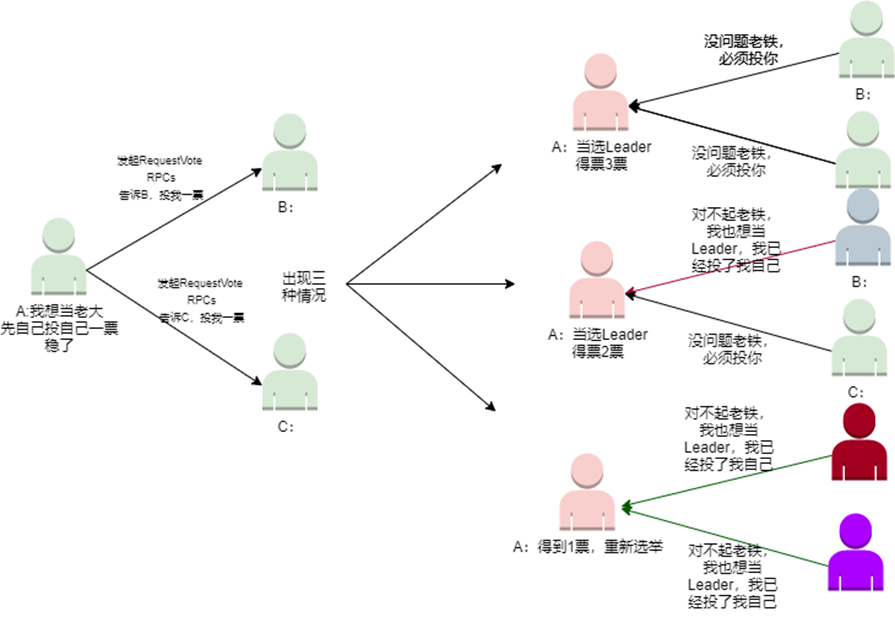
具体详细过程实现描述如下:
-
增加节点本地的current term,切换到candidate状态。
-
自己给自己投一票。
-
给其他节点发送RequestVote RPCs,要求其他节点也投自己一票。
-
等待其他节点的投票回复。
整个过程中的投票过程可以用下图进行表述。
leader节点选举的限制
-
每个节点只能投一票,投给自己或者投给别人。
-
候选人所知道的日志信息,一定不能比自己的更少,即能被选举成为leader节点,一定包含了所有已经提交的日志。
-
先到先得的原则
-
数据一致性保证(日志复制机制)
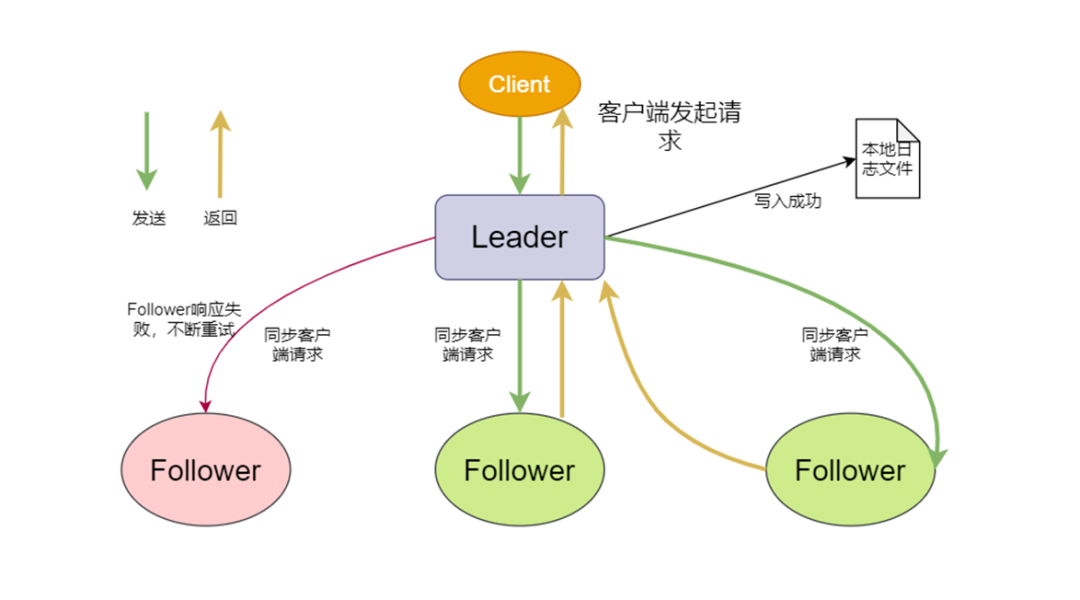
前面通过选举机制之后,选举出来了leader节点,然后leader节点对外提供服务,所有的客户端的请求都会发送到leader节点,由leader节点来调度这些并发请求的处理顺序,保证所有节点的状态一致,leader会把请求作为日志条目(Log entries)加入到他的日志当中,然后并行的向其他服务器发起AppendEntries RPC复制日志条目。当这条请求日志被成功复制到大多数服务器上面之后,Leader将这条日志应用到它的状态机并向客户端返回执行结果。
-
客户端的每个请求都包含被复制状态机执行的指令
-
leader将客户端请求作为一条心得日志添加到日志文件中,然后并行发起RPC给其他的服务器,让他们复制这条信息到自己的日志文件中保存。
-
如果这条日志被成功复制,也就是大部分的follower都保存好了执行指令日志,leader就应用这条日志到自己的状态机中,并返回给客户端。
-
如果follower宕机或者运行缓慢或者数据丢失,leader会不断地进行重试,直至所有在线的follower都成功复制了所有的日志条目。
与维护Consumer offset的方式类似,脱离ZK之后的Kafka集群将元数据视为日志,保存在一个内置的Topic中,且该Topic只有一个Partition。
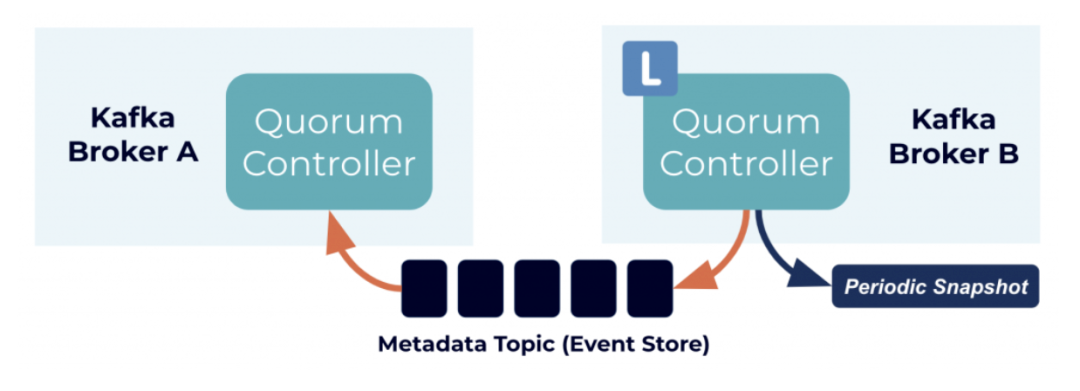
元数据日志的消息格式与普通消息没有太大不同,但必须携带Leader的纪元值(即之前的Controller epoch):
Record => Offset LeaderEpoch ControlType Key Value Timestamp
- 1
这样,Follower以拉模式复制Leader日志,就相当于以Consumer角色消费元数据Topic,符合Kafka原生的语义。
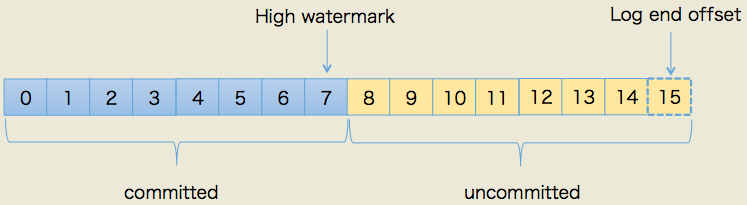
那么在KRaft协议中,是如何维护哪些元数据日志已经提交——即已经成功复制到多数的Follower节点上的呢?Kafka仍然借用了原生副本机制中的概念——high watermark(HW,高水位线)保证日志不会丢失,HW的示意图如下。
状态机说明:
要让所有节点达成一致性的状态,大部分都是基于复制状态机来实现的(Replicated state machine)
简单来说就是:初始相同的状态+相同的输入过程=相同的结束状态,这个其实也好理解,就类似于一对双胞胎,出生时候就长得一样,然后吃的喝的用的穿的都一样,你自然很难分辨。其中最重要的就是一定要注意中间的相同输入过程,各个不同节点要以相同且确定性的函数来处理输入,而不要引入一个不确定的值。使用replicated log来实现每个节点都顺序的写入客户端请求,然后顺序的处理客户端请求,最终就一定能够达到最终一致性。
状态机安全性保证:
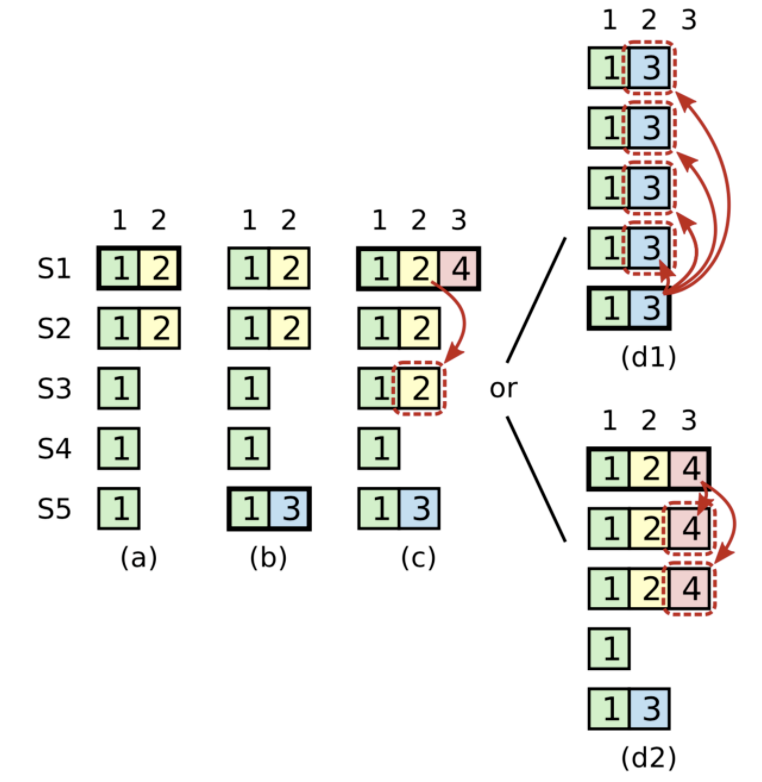
在安全性方面,KRaft与传统Raft的选举安全性、领导者只追加、日志匹配和领导者完全性保证都是几乎相同的。下面只简单看看状态机安全性是如何保证的,仍然举论文中的极端例子:
-
在时刻a,节点S1是Leader,epoch=2的日志只复制给了S2就崩溃了。
-
在时刻b,S5被选举为Leader,epoch=3的日志还没来得及复制,也崩溃了。
-
在时刻c,S1又被选举为Leader,继续复制日志,将epoch=2的日志给了S3。此时该日志复制给了多数节点,但还未提交。
-
在时刻d,S1又崩溃,并且S5重新被选举为领导者,将epoch=3的日志复制给S0~S4。
此时日志与新Leader S5的日志发生了冲突,如果按上图中d1的方式处理,消息2就会丢失。传统Raft协议的处理方式是:在Leader任期开始时,立刻提交一条空的日志,所以上图中时刻c的情况不会发生,而是如同d2一样先提交epoch=4的日志,连带提交epoch=2的日志。
与传统Raft不同,KRaft附加了一个较强的约束:当新的Leader被选举出来,但还没有成功提交属于它的epoch的日志时,不会向前推进HW。也就是说,即使上图中时刻c的情况发生了,消息2也被视为没有成功提交,所以按照d1方式处理是安全的。
日志格式说明:
所有节点持久化保存在本地的日志,大概就是类似于这个样子:
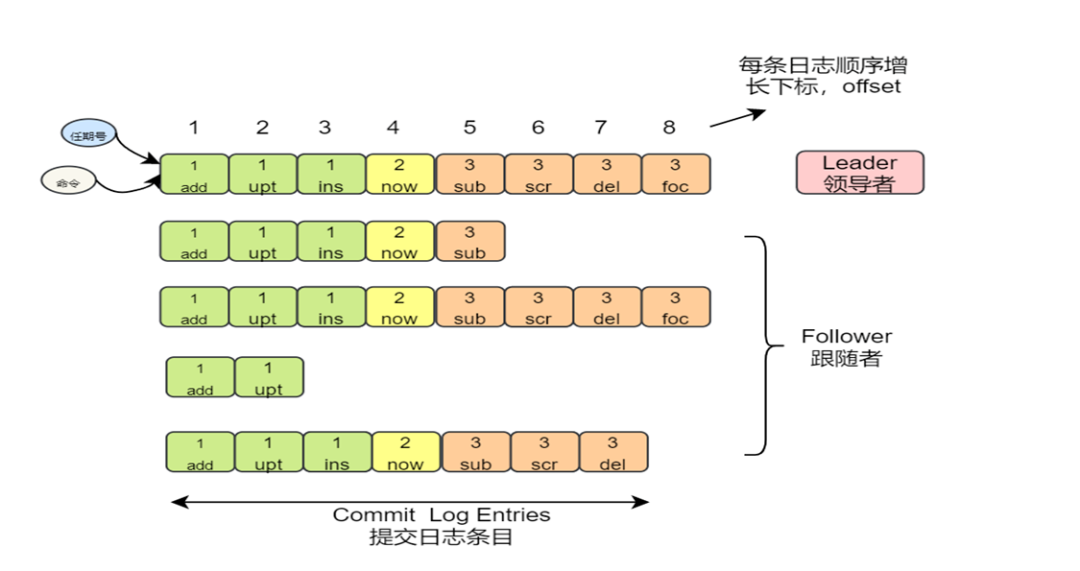
上图显示,共有八条日志数据,其中已经提交了7条,提交的日志都将通过状态机持久化到本地磁盘当中,防止宕机。
日志复制的保证机制
如果两个节点不同的日志文件当中存储着相同的索引和任期号,那么他们所存储的命令是相同的。(原因:leader最多在一个任期里的一个日志索引位置创建一条日志条目,日志条目所在的日志位置从来不会改变)。
如果不同日志中两个条目有着相同的索引和任期号,那么他们之前的所有条目都是一样的(原因:每次RPC发送附加日志时,leader会把这条日志前面的日志下标和任期号一起发送给follower,如果follower发现和自己的日志不匹配,那么就拒绝接受这条日志,这个称之为一致性检查)
日志的不正常情况
一般情况下,Leader和Followers的日志保持一致,因此Append Entries一致性检查通常不会失败。然而,Leader崩溃可能会导致日志不一致:旧的Leader可能没有完全复制完日志中的所有条目。
下图阐述了一些Followers可能和新的Leader日志不同的情况。一个Follower可能会丢失掉Leader上的一些条目,也有可能包含一些Leader没有的条目,也有可能两者都会发生。丢失的或者多出来的条目可能会持续多个任期。
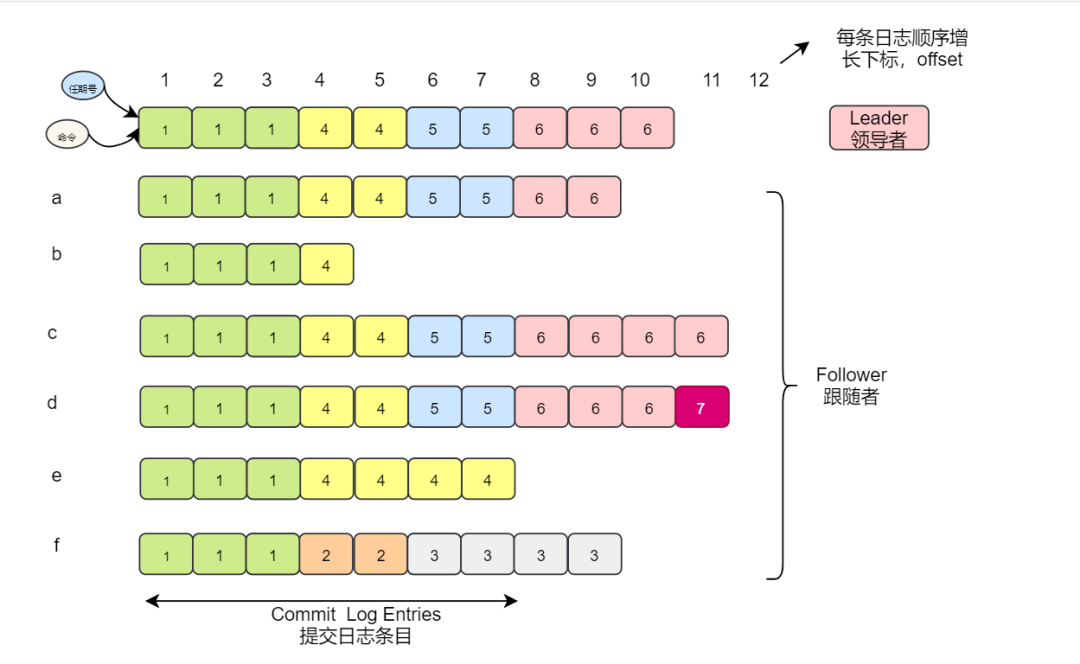
如何保证日志的正常复制
如果出现了上述leader宕机,导致follower与leader日志不一致的情况,那么就需要进行处理,保证follower上的日志与leader上的日志保持一致,leader通过强制follower复制它的日志来处理不一致的问题,follower与leader不一致的日志会被强制覆盖。leader为了最大程度的保证日志的一致性,且保证日志最大量,leader会寻找follower与他日志一致的地方,然后覆盖follower之后的所有日志条目,从而实现日志数据的一致性。
具体的操作就是:leader会从后往前不断对比,每次Append Entries失败后尝试前一个日志条目,直到成功找到每个Follower的日志一致的位置点,然后向该Follower所在位置之后的条目进行覆盖。
详细过程如下:
-
Leader维护了每个Follower节点下一次要接收的日志的索引,即nextIndex。
-
Leader选举成功后将所有Follower的nextIndex设置为自己的最后一个日志条目+1。
-
Leader将数据推送给Follower,如果Follower验证失败(nextIndex不匹配),则在下一次推送日志时缩小nextIndex,直到nextIndex验证通过。
总结一下就是:当leader和follower日志冲突的时候,leader将校验 follower最后一条日志是否和leader匹配,如果不匹配,将递减查询,直到匹配,匹配后,删除冲突的日志。这样就实现了主从日志的一致性。
(二)Raft协议算法代码实现
前面我们已经大致了解了Raft协议算法的实现原理,如果我们要自己实现一个Raft协议的算法,其实就是将我们讲到的理论知识给翻译成为代码的过程,具体的开发需要考虑的细节比较多,代码量肯定也比较大,好在有人已经实现了Raft协议的算法了,我们可以直接拿过来使用。
创建maven工程并导入jar包地址如下:
<dependencies>
<dependency> <groupId>com.github.wenweihu86.raft</groupId> <artifactId>raft-java-core</artifactId> <version>1.8.0</version> </dependency>
<dependency> <groupId>com.github.wenweihu86.rpc</groupId> <artifactId>rpc-java</artifactId> <version>1.8.0</version> </dependency>
<dependency> <groupId>org.rocksdb</groupId> <artifactId>rocksdbjni</artifactId> <version>5.1.4</version> </dependency>
</dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build>
- 1
- 2
- 3
- 4
- 5
定义Server端代码实现:
public class Server1 { public static void main(String[] args) { // parse args // peers, format is "host:port:serverId,host2:port2:serverId2"
//localhost:16010:1,localhost:16020:2,localhost:16030:3 localhost:16010:1 String servers = "localhost:16010:1,localhost:16020:2,localhost:16030:3";
// local server RaftMessage.Server localServer = parseServer("localhost:16010:1");
String[] splitArray = servers.split(","); List<RaftMessage.Server> serverList = new ArrayList<>(); for (String serverString : splitArray) { RaftMessage.Server server = parseServer(serverString); serverList.add(server); }
// 初始化RPCServer RPCServer server = new RPCServer(localServer.getEndPoint().getPort()); // 设置Raft选项,比如: // just for test snapshot RaftOptions raftOptions = new RaftOptions(); /* raftOptions.setSnapshotMinLogSize(10 * 1024); raftOptions.setSnapshotPeriodSeconds(30); raftOptions.setMaxSegmentFileSize(1024 * 1024);*/ // 应用状态机 ExampleStateMachine stateMachine = new ExampleStateMachine(raftOptions.getDataDir()); // 初始化RaftNode RaftNode raftNode = new RaftNode(raftOptions, serverList, localServer, stateMachine); raftNode.getLeaderId(); // 注册Raft节点之间相互调用的服务 RaftConsensusService raftConsensusService = new RaftConsensusServiceImpl(raftNode); server.registerService(raftConsensusService); // 注册给Client调用的Raft服务 RaftClientService raftClientService = new RaftClientServiceImpl(raftNode); server.registerService(raftClientService); // 注册应用自己提供的服务 ExampleService exampleService = new ExampleServiceImpl(raftNode, stateMachine); server.registerService(exampleService); // 启动RPCServer,初始化Raft节点 server.start(); raftNode.init(); }
private static RaftMessage.Server parseServer(String serverString) { String[] splitServer = serverString.split(":"); String host = splitServer[0]; Integer port = Integer.parseInt(splitServer[1]); Integer serverId = Integer.parseInt(splitServer[2]); RaftMessage.EndPoint endPoint = RaftMessage.EndPoint.newBuilder() .setHost(host).setPort(port).build(); RaftMessage.Server.Builder serverBuilder = RaftMessage.Server.newBuilder(); RaftMessage.Server server = serverBuilder.setServerId(serverId).setEndPoint(endPoint).build(); return server; }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
定义客户端代码实现如下:
public class ClientMain { public static void main(String[] args) { // parse args String ipPorts = args[0]; String key = args[1]; String value = null; if (args.length > 2) { value = args[2]; } // init rpc client RPCClient rpcClient = new RPCClient(ipPorts); ExampleService exampleService = RPCProxy.getProxy(rpcClient, ExampleService.class); final JsonFormat.Printer printer = JsonFormat.printer().omittingInsignificantWhitespace(); // set if (value != null) { ExampleMessage.SetRequest setRequest = ExampleMessage.SetRequest.newBuilder() .setKey(key).setValue(value).build(); ExampleMessage.SetResponse setResponse = exampleService.set(setRequest); try { System.out.printf("set request, key=%s value=%s response=%s\n", key, value, printer.print(setResponse)); } catch (Exception ex) { ex.printStackTrace(); } } else { // get ExampleMessage.GetRequest getRequest = ExampleMessage.GetRequest.newBuilder().setKey(key).build(); ExampleMessage.GetResponse getResponse = exampleService.get(getRequest); try { String value1 = getResponse.getValue(); System.out.println(value1); System.out.printf("get request, key=%s, response=%s\n", key, printer.print(getResponse)); } catch (Exception ex) { ex.printStackTrace(); } }
rpcClient.stop(); }}
- 1
- 2
先启动服务端,然后启动客户端,就可以将实现客户端向服务端发送消息,并且服务端会向三台机器进行保存消息了。
五、Kafka常见问题
(一)消息队列模型知道吗?Kafka是怎么做到支持这两种模型的?
对于传统的消息队列系统支持两个模型:
-
点对点:也就是消息只能被一个消费者消费,消费完后消息删除。
-
发布订阅:相当于广播模式,消息可以被所有消费者消费。
kafka其实就是通过Consumer Group同时支持了这两个模型。如果说所有消费者都属于一个Group,消息只能被同一个Group内的一个消费者消费,那就是点对点模式。如果每个消费者都是一个单独的Group,那么就是发布订阅模式。
(二)说说Kafka通信过程原理吗?
首先kafka broker启动的时候,会去向Zookeeper注册自己的ID(创建临时节点),这个ID可以配置也可以自动生成,同时会去订阅Zookeeper的brokers/ids路径,当有新的broker加入或者退出时,可以得到当前所有broker信。
生产者启动的时候会指定bootstrap.servers,通过指定的broker地址,Kafka就会和这些broker创建TCP连接(通常我们不用配置所有的broker服务器地址,否则kafka会和配置的所有broker都建立TCP连接)
随便连接到任何一台broker之后,然后再发送请求获取元数据信息(包含有哪些主题、主题都有哪些分区、分区有哪些副本,分区的Leader副本等信息)
接着就会创建和所有broker的TCP连接。
之后就是发送消息的过程。
消费者和生产者一样,也会指定bootstrap.servers属性,然后选择一台broker创建TCP连接,发送请求找到协调者所在的broker。
然后再和协调者broker创建TCP连接,获取元数据。
根据分区Leader节点所在的broker节点,和这些broker分别创建连接。
最后开始消费消息。
(三)发送消息时如何选择分区的?
主要有两种方式:
-
轮询,按照顺序消息依次发送到不同的分区。
-
随机,随机发送到某个分区。
如果消息指定key,那么会根据消息的key进行hash,然后对partition分区数量取模,决定落在哪个分区上,所以,对于相同key的消息来说,总是会发送到同一个分区上,也是我们常说的消息分区有序性。
很常见的场景就是我们希望下单、支付消息有顺序,这样以订单ID作为key发送消息就达到了分区有序性的目的。
如果没有指定key,会执行默认的轮询负载均衡策略,比如第一条消息落在P0,第二条消息落在P1,然后第三条又在P1。
除此之外,对于一些特定的业务场景和需求,还可以通过实现Partitioner接口,重写configure和partition方法来达到自定义分区的效果。
(四)为什么需要分区?有什么好处?
这个问题很简单,如果说不分区的话,我们发消息写数据都只能保存到一个节点上,这样的话就算这个服务器节点性能再好最终也支撑不住。
实际上分布式系统都面临这个问题,要么收到消息之后进行数据切分,要么提前切分,kafka正是选择了前者,通过分区可以把数据均匀地分布到不同的节点。
分区带来了负载均衡和横向扩展的能力。
发送消息时可以根据分区的数量落在不同的Kafka服务器节点上,提升了并发写消息的性能,消费消息的时候又和消费者绑定了关系,可以从不同节点的不同分区消费消息,提高了读消息的能力。
另外一个就是分区又引入了副本,冗余的副本保证了Kafka的高可用和高持久性。
(五)详细说说消费者组和消费者重平衡?
Kafka中的消费者组订阅topic主题的消息,一般来说消费者的数量最好要和所有主题分区的数量保持一致最好(举例子用一个主题,实际上当然是可以订阅多个主题)。
当消费者数量小于分区数量的时候,那么必然会有一个消费者消费多个分区的消息。
而消费者数量超过分区的数量的时候,那么必然会有消费者没有分区可以消费。
所以,消费者组的好处一方面在上面说到过,可以支持多种消息模型,另外的话根据消费者和分区的消费关系,支撑横向扩容伸缩。
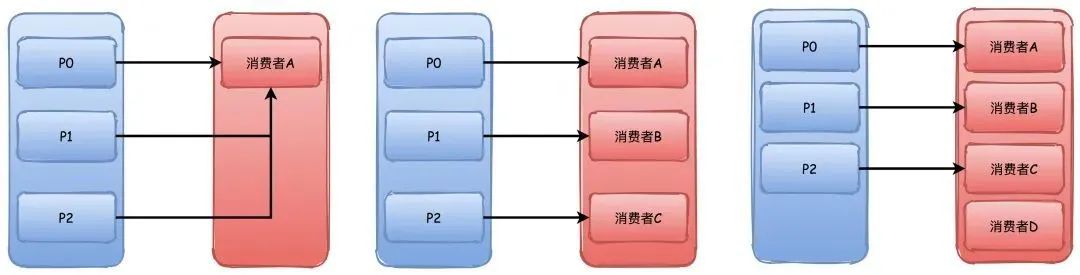
当我们知道消费者如何消费分区的时候,就显然会有一个问题出现了,消费者消费的分区是怎么分配的,有先加入的消费者时候怎么办?
旧版本的重平衡过程主要通过ZK监听器的方式来触发,每个消费者客户端自己去执行分区分配算法。
新版本则是通过协调者来完成,每一次新的消费者加入都会发送请求给协调者去获取分区的分配,这个分区分配的算法逻辑由协调者来完成。
而重平衡Rebalance就是指的有新消费者加入的情况,比如刚开始我们只有消费者A在消费消息,过了一段时间消费者B和C加入了,这时候分区就需要重新分配,这就是重平衡,也可以叫做再平衡,但是重平衡的过程和我们的GC时候STW很像,会导致整个消费群组停止工作,重平衡期间都无法消息消息。
另外,发生重平衡并不是只有这一种情况,因为消费者和分区总数是存在绑定关系的,上面也说了,消费者数量最好和所有主题的分区总数一样。
那只要消费者数量、主题数量(比如用的正则订阅的主题)、分区数量任何一个发生改变,都会触发重平衡。
下面说说重平衡的过程。
重平衡的机制依赖消费者和协调者之间的心跳来维持,消费者会有一个独立的线程去定时发送心跳给协调者,这个可以通过参数heartbeat.interval.ms来控制发送心跳的间隔时间。
每个消费者第一次加入组的时候都会向协调者发送JoinGroup请求,第一个发送这个请求的消费者会成为“群主”,协调者会返回组成员列表给群主。
群主执行分区分配策略,然后把分配结果通过SyncGroup请求发送给协调者,协调者收到分区分配结果。
其他组内成员也向协调者发送SyncGroup,协调者把每个消费者的分区分配分别响应给他们。
(六)具体讲讲分区分配策略?
主要有3种分配策略
Range
对分区进行排序,排序越靠前的分区能够分配到更多的分区。
比如有3个分区,消费者A排序更靠前,所以能够分配到P0\P1两个分区,消费者B就只能分配到一个P2。
如果是4个分区的话,那么他们会刚好都是分配到2个。
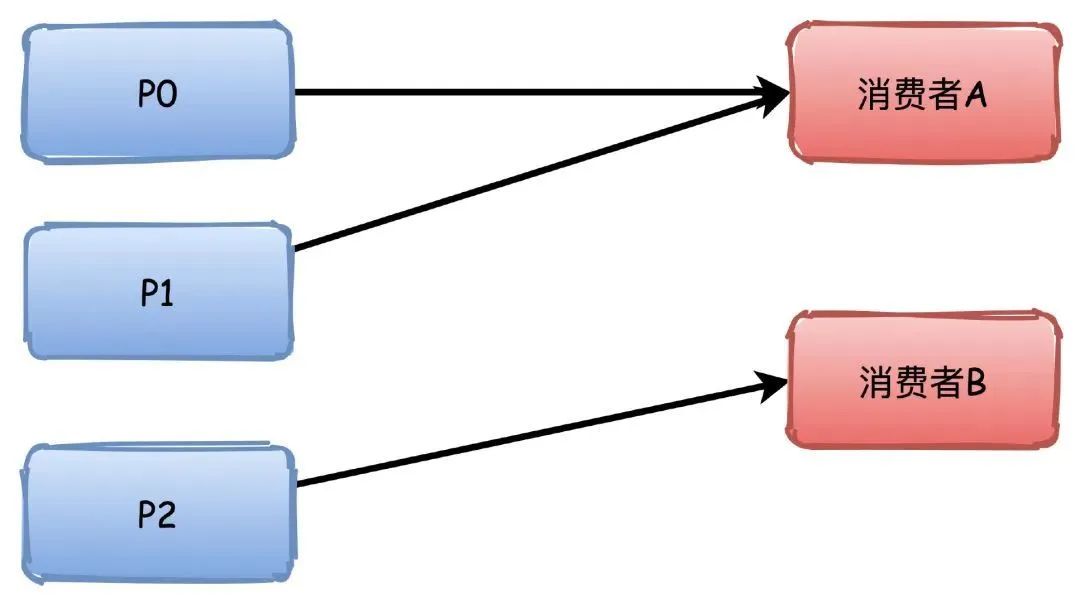
但是这个分配策略会有点小问题,他是根据主题进行分配,所以如果消费者组订阅了多个主题,那就有可能导致分区分配不均衡。
比如下图中两个主题的P0\P1都被分配给了A,这样A有4个分区,而B只有2个,如果这样的主题数量越多,那么不均衡就越严重。
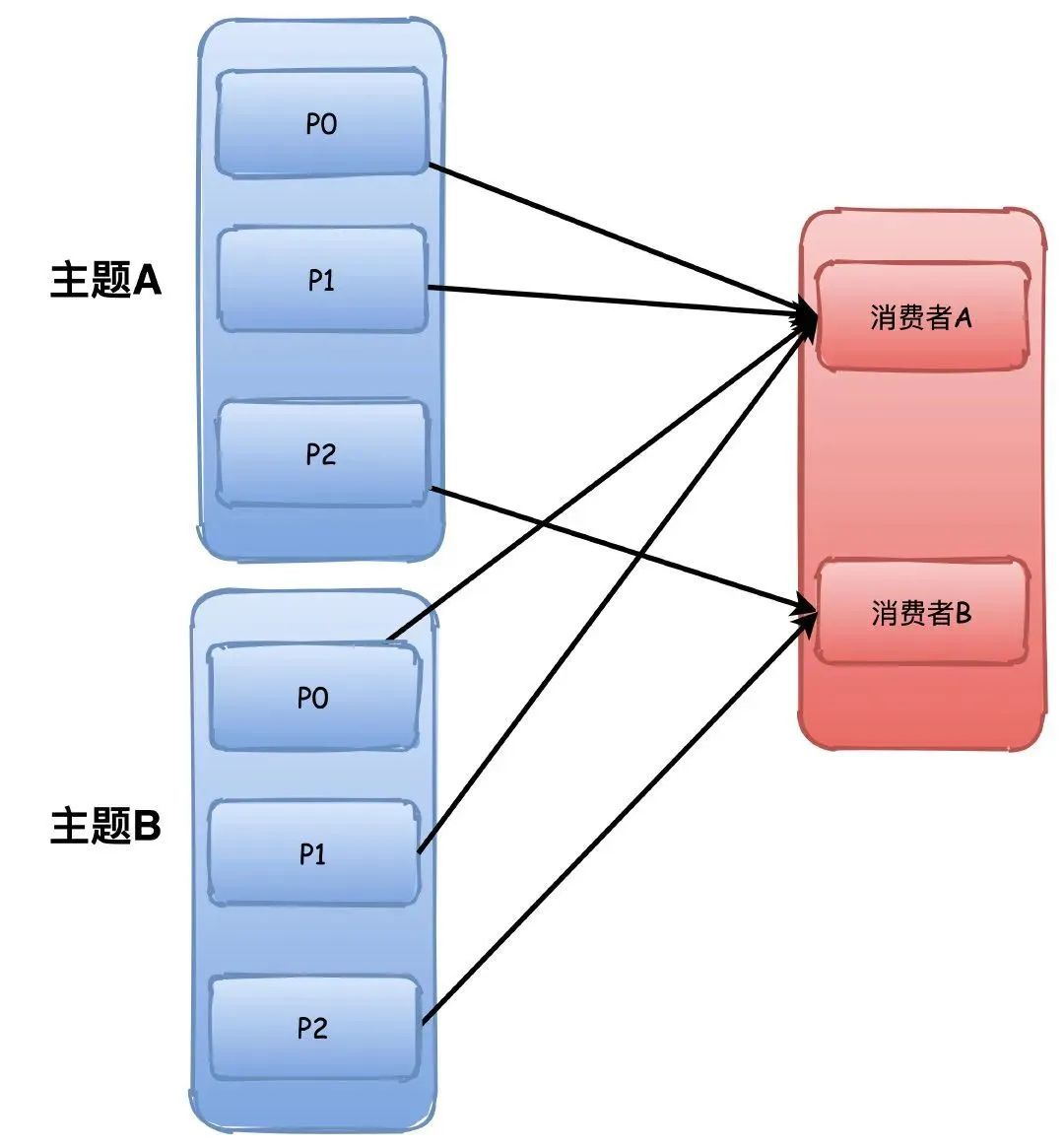
RoundRobin
也就是我们常说的轮询了,这个就比较简单了,不画图你也能很容易理解。
这个会根据所有的主题进行轮询分配,不会出现Range那种主题越多可能导致分区分配不均衡的问题。
P0->A,P1->B,P1->A。。。以此类推
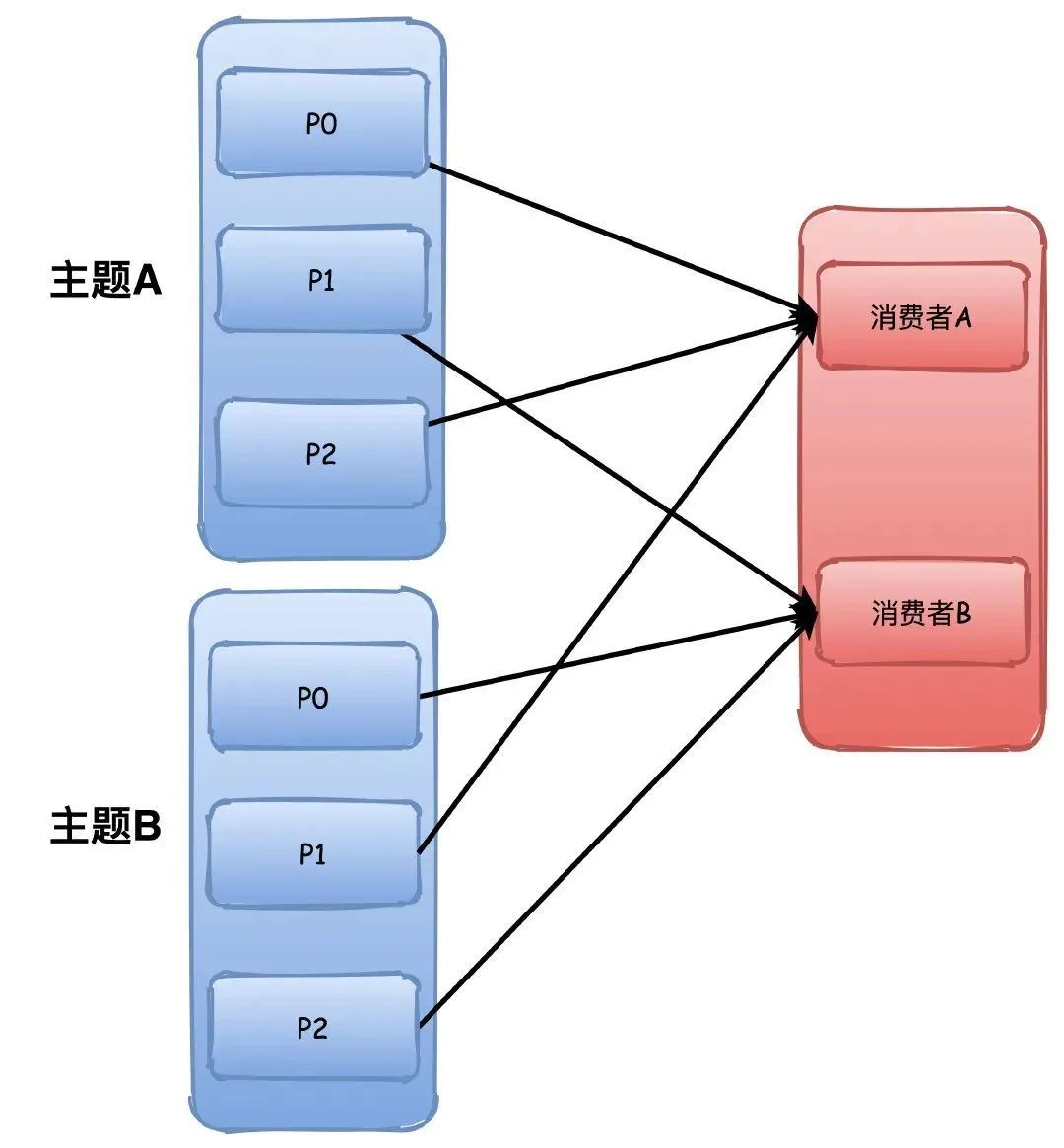
Sticky
这个从字面看来意思就是粘性策略,大概是这个意思。主要考虑的是在分配均衡的前提下,让分区的分配更小的改动。
比如之前P0\P1分配给消费者A,那么下一次尽量还是分配给A。
这样的好处就是连接可以复用,要消费消息总是要和broker去连接的,如果能够保持上一次分配的分区的话,那么就不用频繁的销毁创建连接了。
(七)如何保证消息可靠性?
- 生产者发送消息丢失
kafka支持3种方式发送消息,这也是常规的3种方式,发送后不管结果、同步发送、异步发送,基本上所有的消息队列都是这样玩的。
-
发送并忘记,直接调用发送send方法,不管结果,虽然可以开启自动重试,但是肯定会有消息丢失的可能。
-
同步发送,同步发送返回Future对象,我们可以知道发送结果,然后进行处理。
-
异步发送,发送消息,同时指定一个回调函数,根据结果进行相应的处理。
为了保险起见,一般我们都会使用异步发送带有回调的方式进行发送消息,再设置参数为发送消息失败不停地重试。
acks=all,这个参数有可以配置0|1|all。
0表示生产者写入消息不管服务器的响应,可能消息还在网络缓冲区,服务器根本没有收到消息,当然会丢失消息。
1表示至少有一个副本收到消息才认为成功,一个副本那肯定就是集群的Leader副本了,但是如果刚好Leader副本所在的节点挂了,Follower没有同步这条消息,消息仍然丢失了。
配置all的话表示所有ISR都写入成功才算成功,那除非所有ISR里的副本全挂了,消息才会丢失。
retries=N,设置一个非常大的值,可以让生产者发送消息失败后不停重试
Kafka 自身消息丢失。
kafka因为消息写入是通过PageCache异步写入磁盘的,因此仍然存在丢失消息的可能。
因此针对kafka自身丢失的可能设置参数:
replication.factor=N,设置一个比较大的值,保证至少有2个或者以上的副本。
min.insync.replicas=N,代表消息如何才能被认为是写入成功,设置大于1的数,保证至少写入1个或者以上的副本才算写入消息成功。
unclean.leader.election.enable=false,这个设置意味着没有完全同步的分区副本不能成为Leader副本,如果是true的话,那些没有完全同步Leader的副本成为Leader之后,就会有消息丢失的风险。
- 消费者消息丢失
消费者丢失的可能就比较简单,关闭自动提交位移即可,改为业务处理成功手动提交。
因为重平衡发生的时候,消费者会去读取上一次提交的偏移量,自动提交默认是每5秒一次,这会导致重复消费或者丢失消息。
enable.auto.commit=false,设置为手动提交。
还有一个参数我们可能也需要考虑进去的:
auto.offset.reset=earliest,这个参数代表没有偏移量可以提交或者broker上不存在偏移量的时候,消费者如何处理。earliest代表从分区的开始位置读取,可能会重复读取消息,但是不会丢失,消费方一般我们肯定要自己保证幂等,另外一种latest表示从分区末尾读取,那就会有概率丢失消息。
综合这几个参数设置,我们就能保证消息不会丢失,保证了可靠性。
(八)聊聊副本和它的同步原理吧?
Kafka副本的之前提到过,分为Leader副本和Follower副本,也就是主副本和从副本,和其他的比如Mysql不一样的是,Kafka中只有Leader副本会对外提供服务,Follower副本只是单纯地和Leader保持数据同步,作为数据冗余容灾的作用。
在Kafka中我们把所有副本的集合统称为AR(Assigned Replicas),和Leader副本保持同步的副本集合称为ISR(InSyncReplicas)。
ISR是一个动态的集合,维持这个集合会通过replica.lag.time.max.ms参数来控制,这个代表落后Leader副本的最长时间,默认值10秒,所以只要Follower副本没有落后Leader副本超过10秒以上,就可以认为是和Leader同步的(简单可以认为就是同步时间差)。
另外还有两个关键的概念用于副本之间的同步:
HW(High Watermark):高水位,也叫做复制点,表示副本间同步的位置。如下图所示,04绿色表示已经提交的消息,这些消息已经在副本之间进行同步,消费者可以看见这些消息并且进行消费,46黄色的则是表示未提交的消息,可能还没有在副本间同步,这些消息对于消费者是不可见的。
LEO(Log End Offset):下一条待写入消息的位移
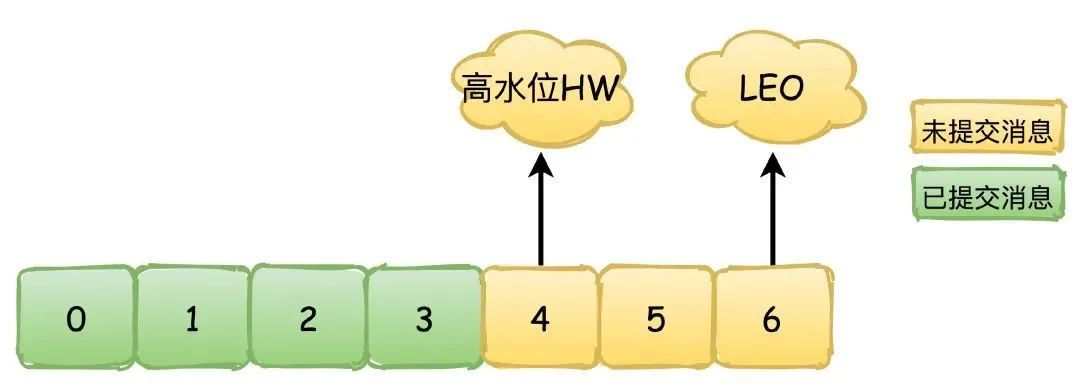
副本间同步的过程依赖的就是HW和LEO的更新,以他们的值变化来演示副本同步消息的过程,绿色表示Leader副本,黄色表示Follower副本。
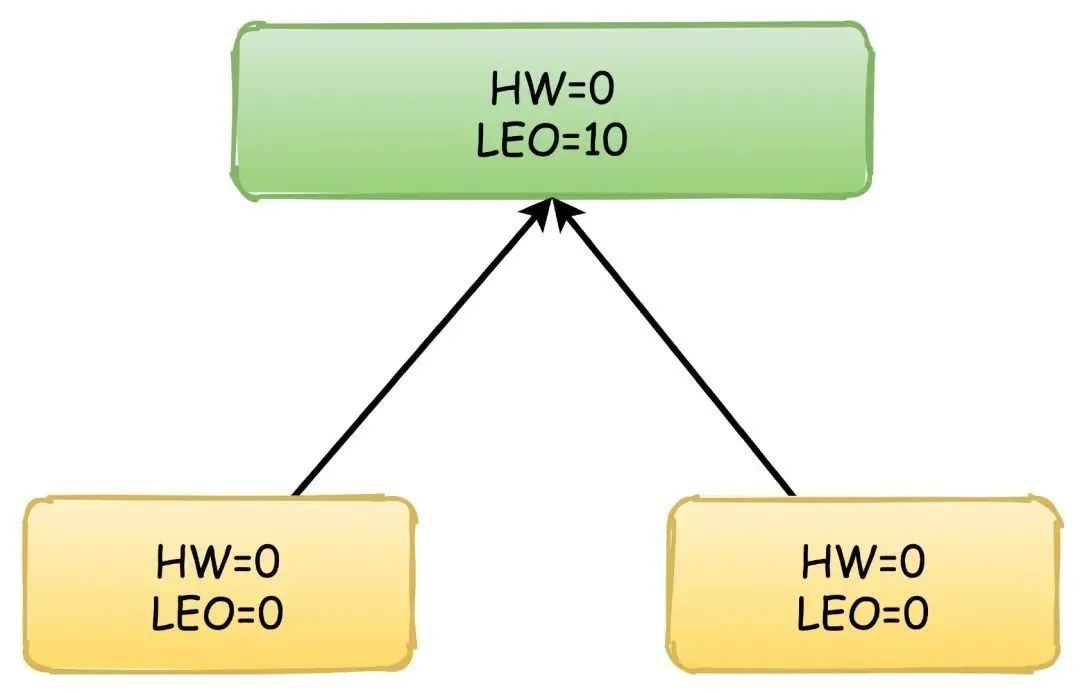
首先,生产者不停地向Leader写入数据,这时候Leader的LEO可能已经达到了10,但是HW依然是0,两个Follower向Leader请求同步数据,他们的值都是0。
此时,Follower再次向Leader拉取数据,这时候Leader会更新自己的HW值,取Follower中的最小的LEO值来更新。
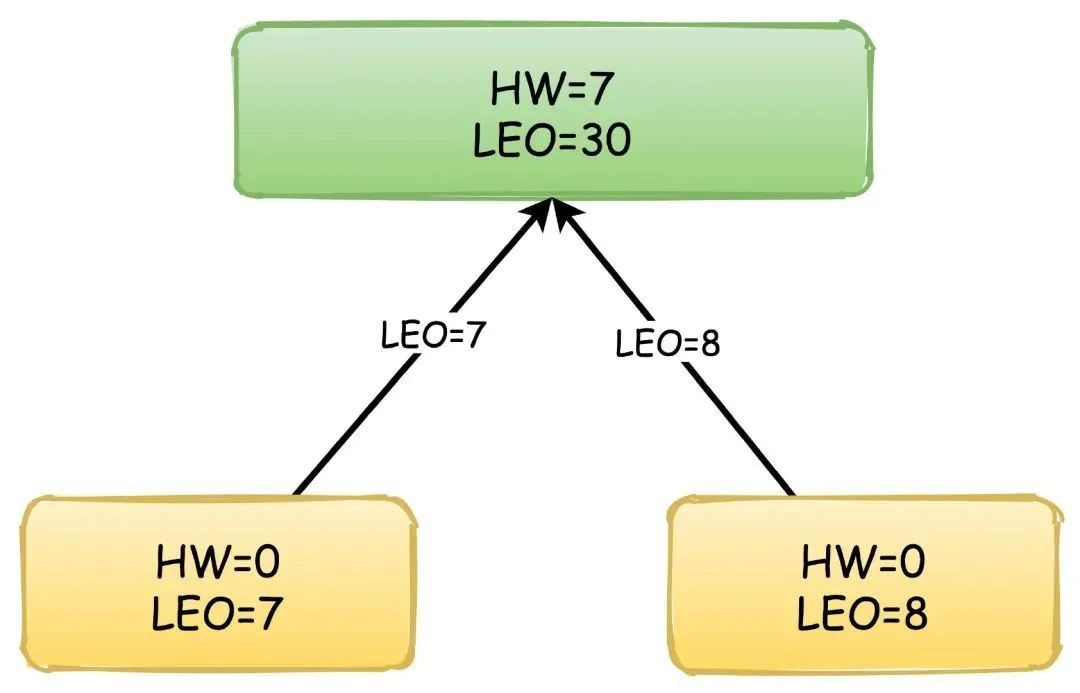
之后,Leader响应自己的HW给Follower,Follower更新自己的HW值,因为又拉取到了消息,所以再次更新LEO,流程以此类推。

(九)Kafka为什么快?
主要是3个方面:
- 顺序IO
kafka写消息到分区采用追加的方式,也就是顺序写入磁盘,不是随机写入,这个速度比普通的随机IO快非常多,几乎可以和网络IO的速度相媲美。
- Page Cache和零拷贝
kafka在写入消息数据的时候通过mmap内存映射的方式,不是真正立刻写入磁盘,而是利用操作系统的文件缓存PageCache异步写入,提高了写入消息的性能,另外在消费消息的时候又通过sendfile实现了零拷贝。
- 批量处理和压缩
Kafka在发送消息的时候不是一条条的发送的,而是会把多条消息合并成一个批次进行处理发送,消费消息也是一个道理,一次拉取一批次的消息进行消费。
并且Producer、Broker、Consumer都使用了优化后的压缩算法,发送和消息消息使用压缩节省了网络传输的开销,Broker存储使用压缩则降低了磁盘存储的空间。
参考资料:
1.《深入理解Kafka:核心设计实践原理》
2.状态机程序设计套路
3.raft算法源码
4.https://www.bbsmax.com/A/QW5Y3kaBzm/
总结
认为就是同步时间差)。
另外还有两个关键的概念用于副本之间的同步:
HW(High Watermark):高水位,也叫做复制点,表示副本间同步的位置。如下图所示,04绿色表示已经提交的消息,这些消息已经在副本之间进行同步,消费者可以看见这些消息并且进行消费,46黄色的则是表示未提交的消息,可能还没有在副本间同步,这些消息对于消费者是不可见的。
LEO(Log End Offset):下一条待写入消息的位移
[外链图片转存中…(img-xSblaHHK-1650934432034)]
副本间同步的过程依赖的就是HW和LEO的更新,以他们的值变化来演示副本同步消息的过程,绿色表示Leader副本,黄色表示Follower副本。
首先,生产者不停地向Leader写入数据,这时候Leader的LEO可能已经达到了10,但是HW依然是0,两个Follower向Leader请求同步数据,他们的值都是0。
[外链图片转存中…(img-pLogNcDZ-1650934432035)]
此时,Follower再次向Leader拉取数据,这时候Leader会更新自己的HW值,取Follower中的最小的LEO值来更新。
[外链图片转存中…(img-hV0shtYL-1650934432035)]
之后,Leader响应自己的HW给Follower,Follower更新自己的HW值,因为又拉取到了消息,所以再次更新LEO,流程以此类推。
[外链图片转存中…(img-xdjmej3f-1650934432036)]
(九)Kafka为什么快?
主要是3个方面:
- 顺序IO
kafka写消息到分区采用追加的方式,也就是顺序写入磁盘,不是随机写入,这个速度比普通的随机IO快非常多,几乎可以和网络IO的速度相媲美。
- Page Cache和零拷贝
kafka在写入消息数据的时候通过mmap内存映射的方式,不是真正立刻写入磁盘,而是利用操作系统的文件缓存PageCache异步写入,提高了写入消息的性能,另外在消费消息的时候又通过sendfile实现了零拷贝。
- 批量处理和压缩
Kafka在发送消息的时候不是一条条的发送的,而是会把多条消息合并成一个批次进行处理发送,消费消息也是一个道理,一次拉取一批次的消息进行消费。
并且Producer、Broker、Consumer都使用了优化后的压缩算法,发送和消息消息使用压缩节省了网络传输的开销,Broker存储使用压缩则降低了磁盘存储的空间。
参考资料:
1.《深入理解Kafka:核心设计实践原理》
2.状态机程序设计套路
3.raft算法源码
4.https://www.bbsmax.com/A/QW5Y3kaBzm/
总结
如果这篇文章对您有所帮助,或者有所启发的话,求一键三连:点赞、转发、在看,您的支持是我坚持写作最大的动力。

