
- 1Unity灯光(light)
- 2毕业设计项目 python小游戏设计 吃豆人小游戏
- 3python 基于django协同过滤的旅游推荐系统_基于python的django旅游
- 4openstack 计算节点连接error: [Errno 111] ECONNREFUSED_error oslo.messaging._drivers.impl_rabbit [-] conn
- 5【计算机网络】应用层——HTTP 协议(一)
- 6Ubuntu18.04安装NVIDIA显卡驱动后设置桌面显示不占用GPU内存的方法_ubuntu18.04显卡驱动,gpu
- 7SocketException: 由于目标计算机积极拒绝,无法连接。 127.0.0.1:10000_由于目标计算机积极拒绝 127.0.0.1
- 8Ubuntu server 18.04安装nvidia显卡驱动_服务器ubuntu 18.04 安装nvidia 470.57.02
- 9【JavaScript笔记 · 拓展篇(二)】Object.defineProperty()方法详细解读 —— 为对象添加自定义属性或修改已有属性_object.defineproperty添加的属性
- 10echarts水波球特效(附带外边框进度条)_水波球插件
第2章:数据结构【AcWing】
赞
踩
虽然是基础课,但并不代表它是容易的,本文默认读者已经了解基本数据结构。
为了方便读者学习,每一小节的最后都会分享我看过的除了yxc之外的视频或博客,希望对你们有帮助。
单链表
在工程中常常使用结构体指针定义的结点构成的链表,但是频繁申请内存会大幅降低效率,因此在算法题中常常用数组模拟链表、下标模拟指针。
定义
首先要定义4个东西:
- head:记录头结点的下标;
- 数组
val[i]:存储结点的值; - 数组
ne[i]:存储结点的下一个结点的下标。 - 下标
idx:记录数组val[]未被使用的最新位置。
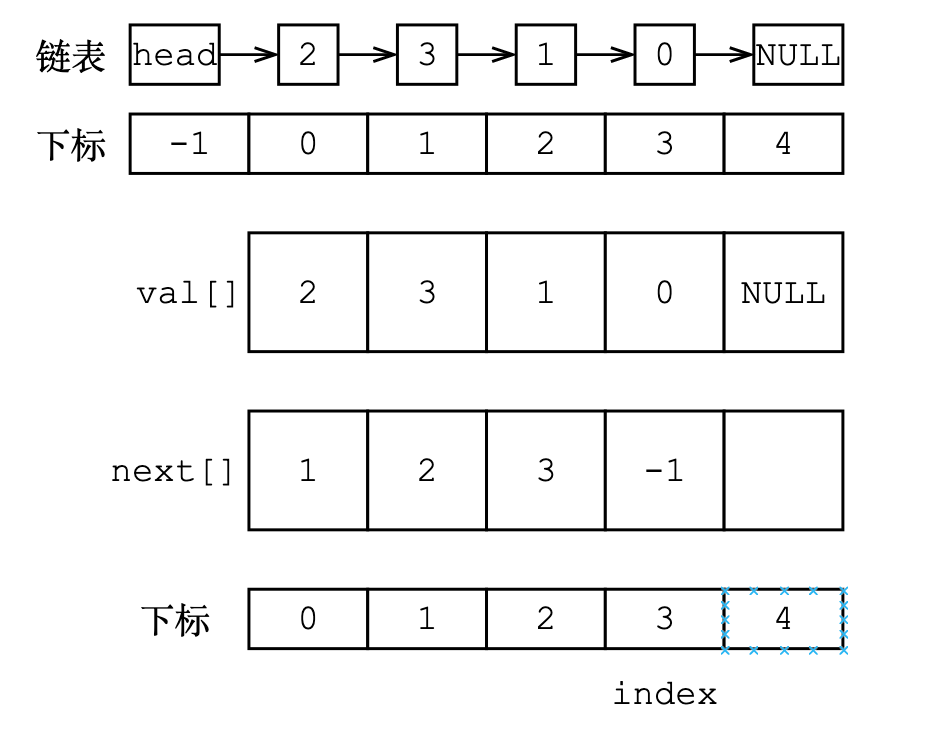
虽然从物理上用数组实现,但是从逻辑上仍然可以用常规的链式链表理解并实现它。从图中可见,使用数组存储结点的值和下标,都是以逻辑上的结点的下标为基准的,因为只有这样才能由索引找到对应位置存储的值。
const int N = 100010;
int val[N], ne[N];
int idx, head;
- 1
- 2
- 3
初始化
值得注意的是,head是作为逻辑上的哨兵位头结点(Dummy Node),它可以方便后续的操作,是可选的。
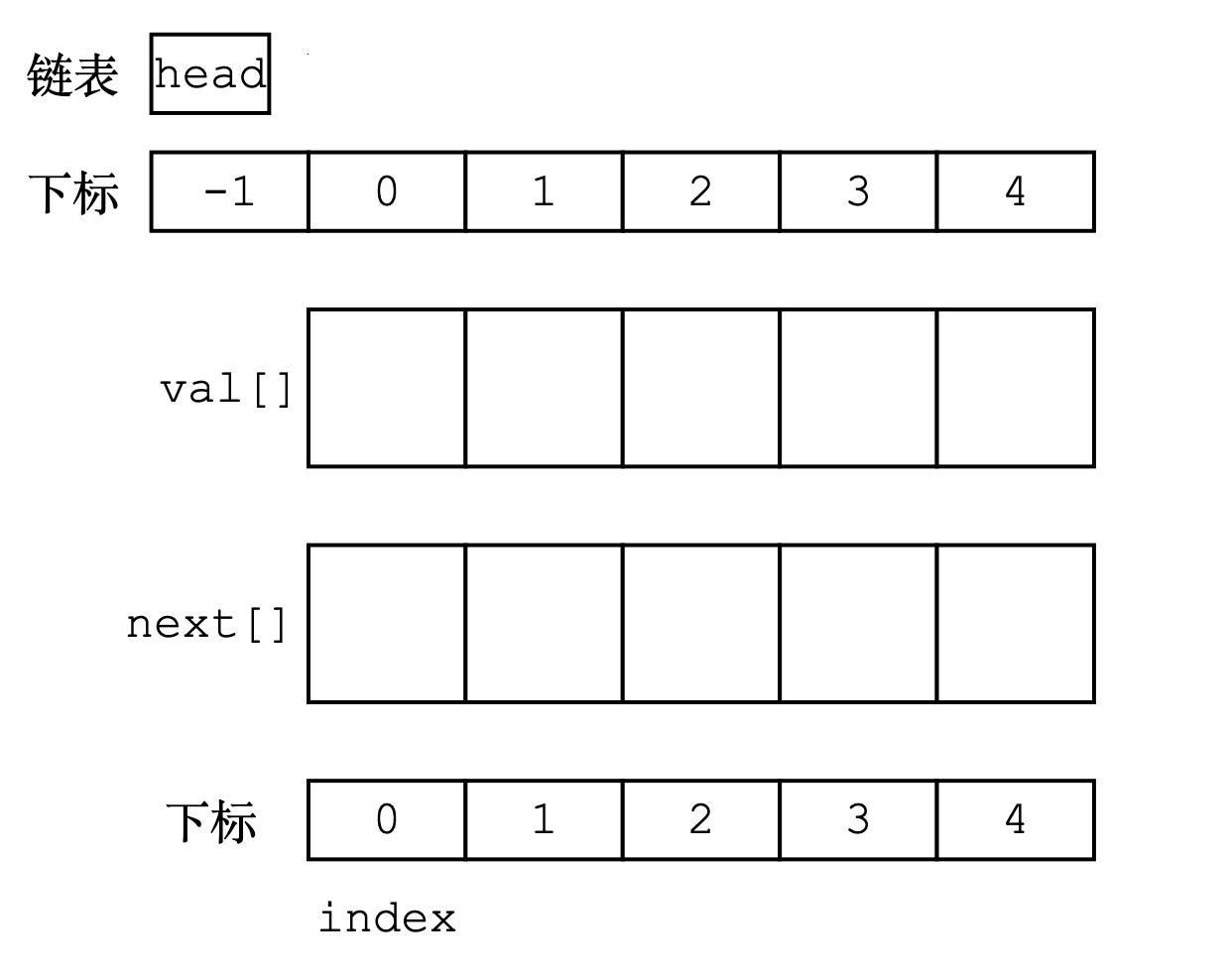
在初始情况,它的值被赋值为-1,下一个结点的下标为真正的第一个结点,但是由于初始情况数组中没有数据,所以head将在add_to_head()中更新。
void init()
{
head = -1;
idx = 0;
}
- 1
- 2
- 3
- 4
- 5
可以将head看作next[]数组中下标为-1的位置:
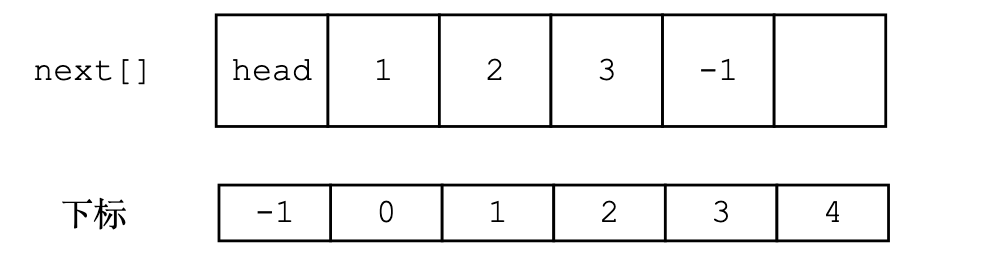
头插
在逻辑上头插是这样的,但是从在数组中不应该将新结点插入到下标为0的位置上,因为这会造成数据挪动,idx就是为了解决这个问题而设计的,这个下标映射了两个数组。
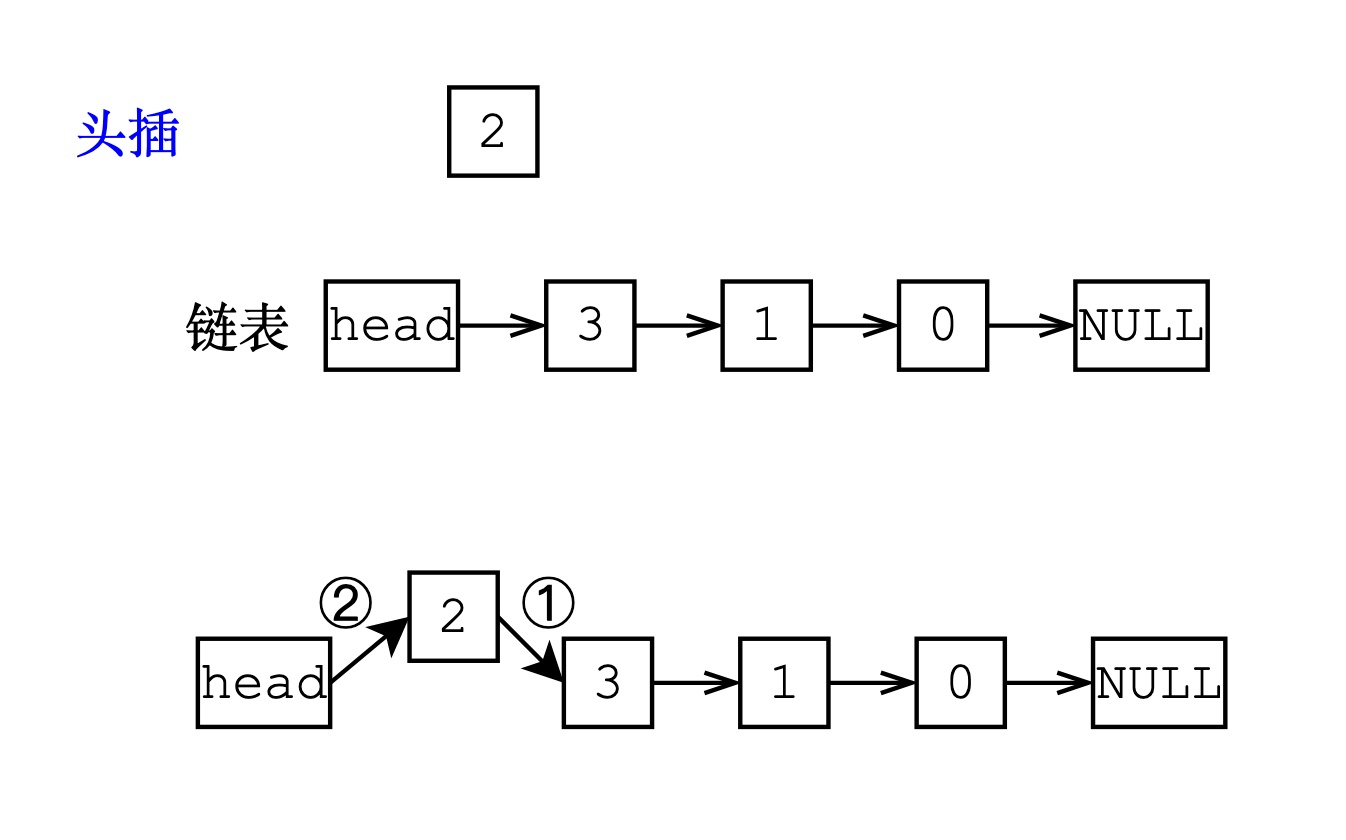
void add_to_head(int x)
{
val[idx] = x; // 插入新结点的值
ne[idx] = head; // 更新新结点的next指针
head = idx; // 更新头结点的next指针
idx++;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
对于第一个被头插的元素,逻辑上它要接管head->next,也就是NULL,这里用-1代替,实际上NULL的结点的值并不存在,只是记录它的next指针是-1,因此ne[]数组比val[]数组多一个元素。
在下标为pos位置后插入
- 将pos位置的next指针给新结点
- 更新pos的next指针
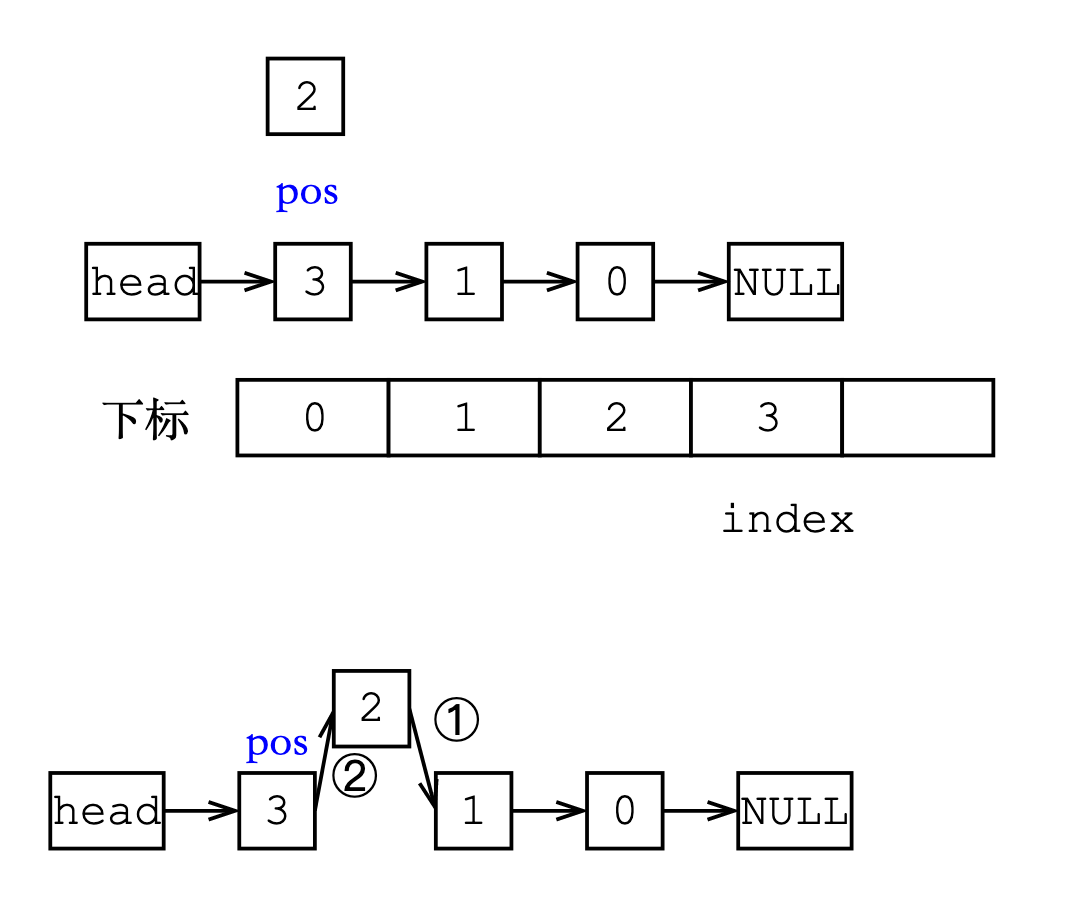
void add(int pos, int x)
{
val[idx] = x;
ne[idx] = ne[pos];
ne[pos] = idx;
idx++;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
删除下标为pos后的结点
正常操作是删除这个结点,但是这里直接忽略,让pos位置的结点跳两步。
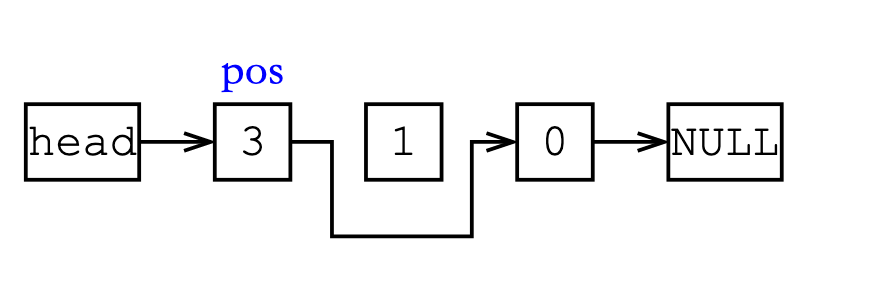
void remove(int pos)
{
ne[pos] = ne[ne[pos]];
}
- 1
- 2
- 3
- 4
遍历
for(int i = head; i != -1; i = ne[i])
cout << val[i] << " ";
- 1
- 2
双链表
定义
val[i]数组保存结点的值;l[i]数组保存当前结点的左边结点的下标;r[i]数组保存当前结点的右边结点的下标;idx表示数组中未被使用的最新位置。
初始化
初始情况有两个结点,左端点head的下标为0,右端点的下标为1。
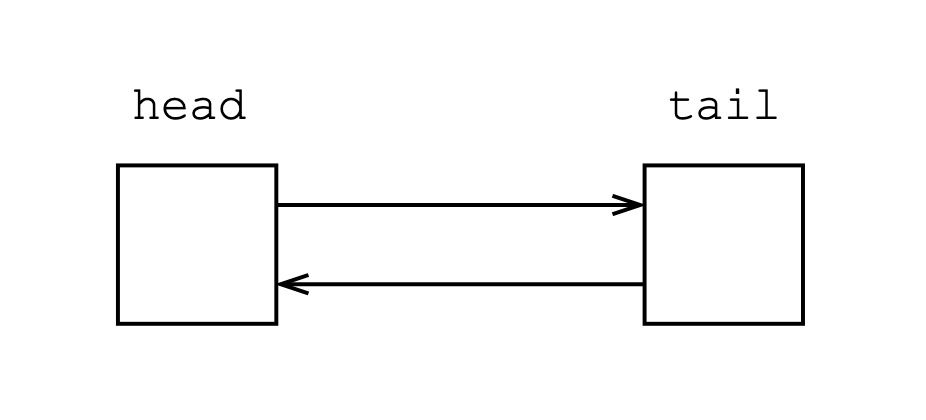
void init()
{
l[0] = 0, r[0] = 1;
idx = 2;
}
- 1
- 2
- 3
- 4
- 5
在下标为pos后插入
- 先创建结点;
- 先将pos位置的右指针赋值给新结点的右指针;
- 再将pos位置的下标赋值给新结点的左指针;
- 更新原先pos位置的结点的左右指针。
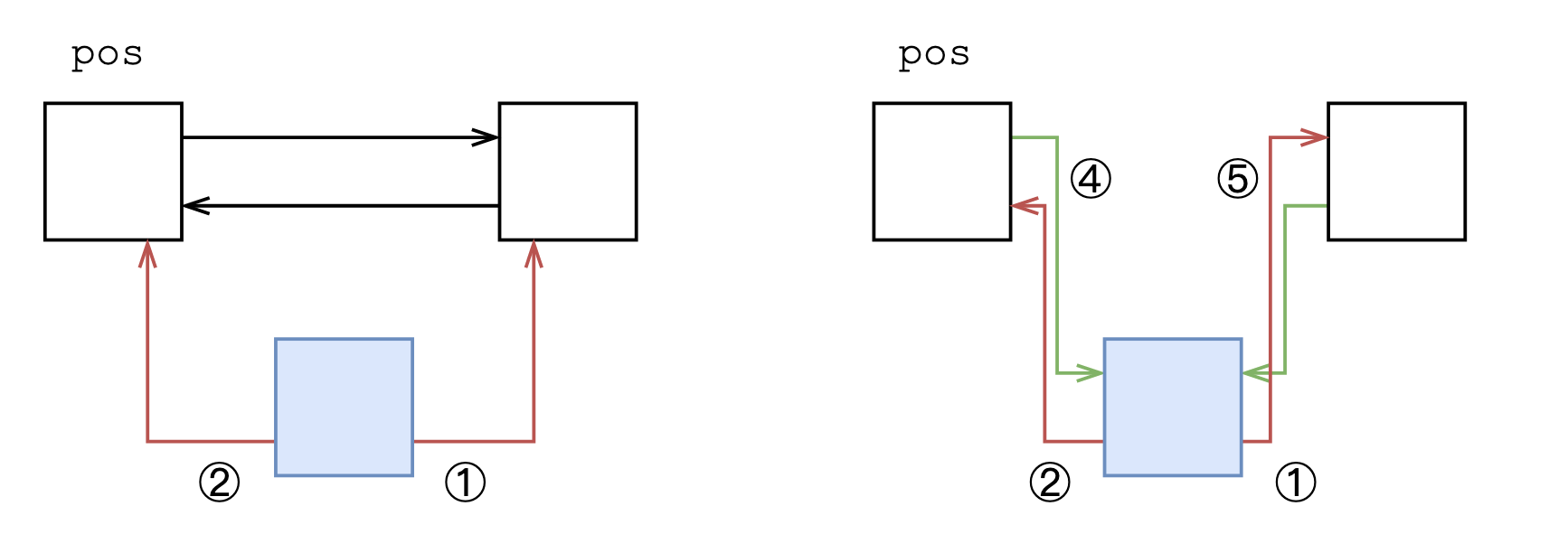
void add(int pos, int x)
{
val[idx] = x;
r[idx] = r[pos];
l[idx] = pos;
l[r[pos]] = idx;
r[pos] = idx;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果要在下标为pos前面插入,那么可以复用这个函数,相当于插在pos的左边。也就是在pos前一个位置的后面插入。
删除下标为pos的位置
和单链表一样,直接忽略:
void remove(int pos)
{
r[l[pos]] = r[pos];
l[r[pos] = l[pos]];
}
- 1
- 2
- 3
- 4
- 5
栈和队列
栈和队列使用数组非常容易实现,只要在一端操作即可。
栈
定义
- 定义一个数组
stk[]保存栈中元素; - 定义一个下标
tt表示栈顶元素的位置。
示例代码
#include <iostream> using namespace std; const int N = 100010; int stk[N], tt; void push(int x) { stk[++tt] = x; } int pop() { return stk[tt--]; } bool empty() { return tt > 0; } int main() { push(1); push(2); push(3); push(4); while(empty()) { printf("%d ", pop()); } return 0; } // 4 3 2 1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
队列
定义
- 定义一个数组
q[]保存元素; - 定义一个下标
hh表示队列头部元素的位置。
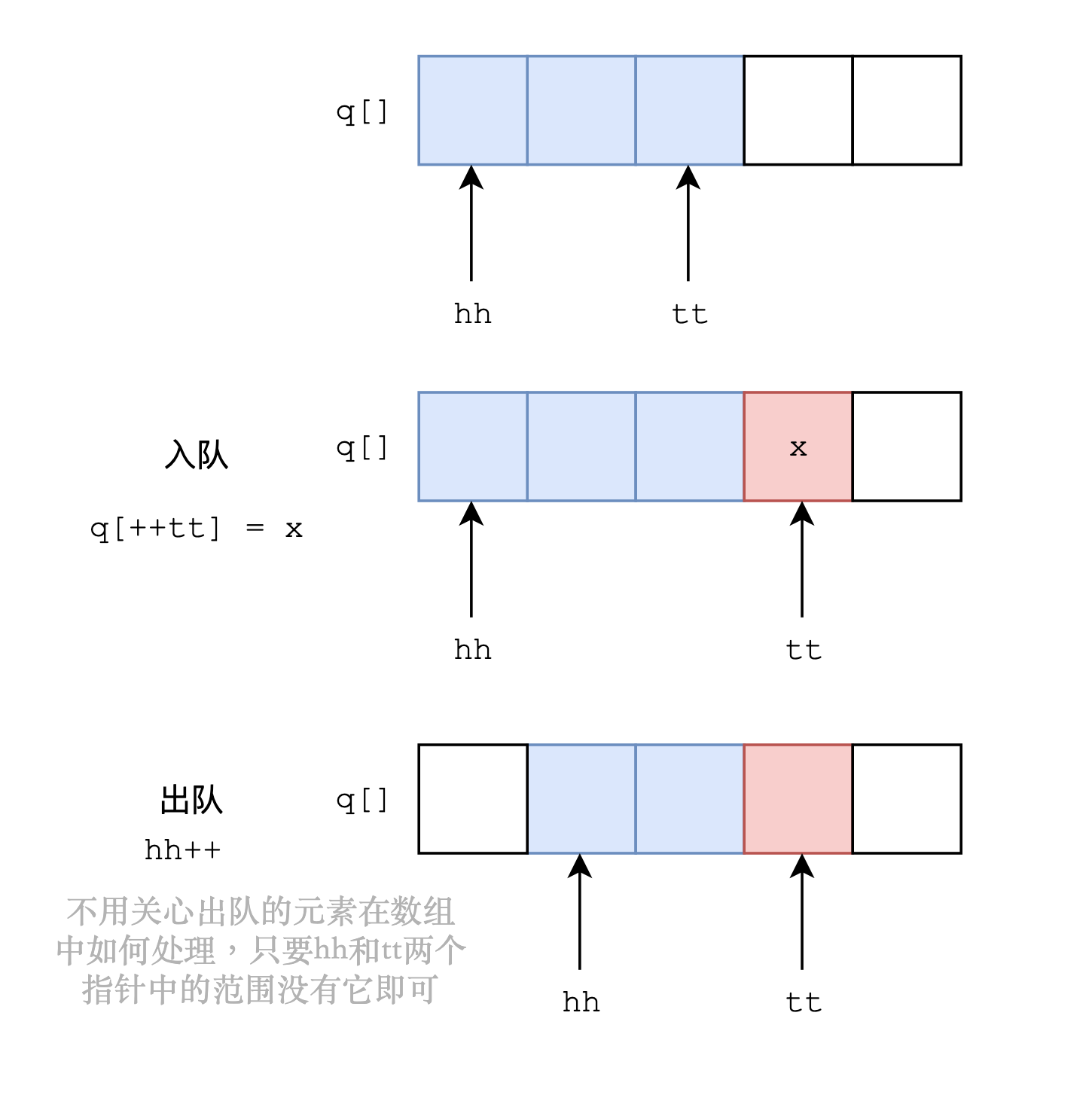
只要对元素的操作满足队列的要求即可,两个指针划定的范围就是队列中的元素,将元素弹出队列直接将该元素移出这个范围即可。需要注意的是,用数组模拟队列下标较小的hh是在左边的(假如数组是横向增长的话),下标较大的tt表示的是队列尾部。
示例代码
#include <iostream> using namespace std; const int N = 100010; int q[N], hh, tt = -1; void push(int x) { q[++tt] = x; } int pop() { return q[hh++]; } bool empty() { return hh <= tt; } int main() { push(1); push(2); push(3); push(4); while(empty()) { printf("%d ", pop()); } return 0; } // 1 2 3 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
循环队列
定义
当队尾指针 tt 或队头指针 hh 等于数组长度 N 时,它们会被重置为 0,以实现循环。hh 和 tt 分别表示队头和队尾。当 hh 等于 tt 时,队列为空。
示例代码
#include <iostream> using namespace std; const int N = 100010; int q[N], hh = 0, tt = 0; void push(int x) { q[tt++] = x; if(tt == N) tt = 0; } int pop() { return q[hh++]; if(hh == N) hh = 0; } bool empty() { return hh != tt; } int main() { push(1); push(2); push(3); push(4); while(empty()) { cout << pop() << " "; } return 0; } // 1 2 3 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
单调栈和单调队列
单调栈是一种和单调队列类似的数据结构。单调队列主要用于 O(n) 解决滑动窗口问题,单调栈则主要用于 O(n) 解决 NGE问题 (Next Greater Element),也就是对序列中每个元素,找到下一个比它大/小的元素。
单调栈
单调栈中的元素是严格单调递增或者递减的,也就是说:从栈底到栈顶,元素的值逐渐增大或者减小。虽然单调栈的性质很简单,但是其用处很大,可以用于求解元素的左右大小边界问题。
例如:找一个序列中每一个数左边(右边)离它最近且比它小的数的位置(不存在则为-1)。
arr 3 4 2 7 5
ans-1 0 -1 2 2
- 1
- 2
朴素方法 O ( n 2 ) O(n^2) O(n2)
两重循环:
- 第一重:枚举序列中每一个元素
a[i]; - 第二重:从
i - 1位置开始往左走,当a[j] < a[i]时j就是要找的位置。如果走到尽头(下标0)没找到那就下一个a[i],如此往复。
找性质:
如果将指针i左边的位置用一个容器装起来,例如栈,那么对于真正要找的元素,栈顶就不会作为答案输出,那么它对于此次查询就是无用的,因此可以直接将它弹出。举个例子,例如在i遍历到最后一个元素时,栈中的元素是这样的:
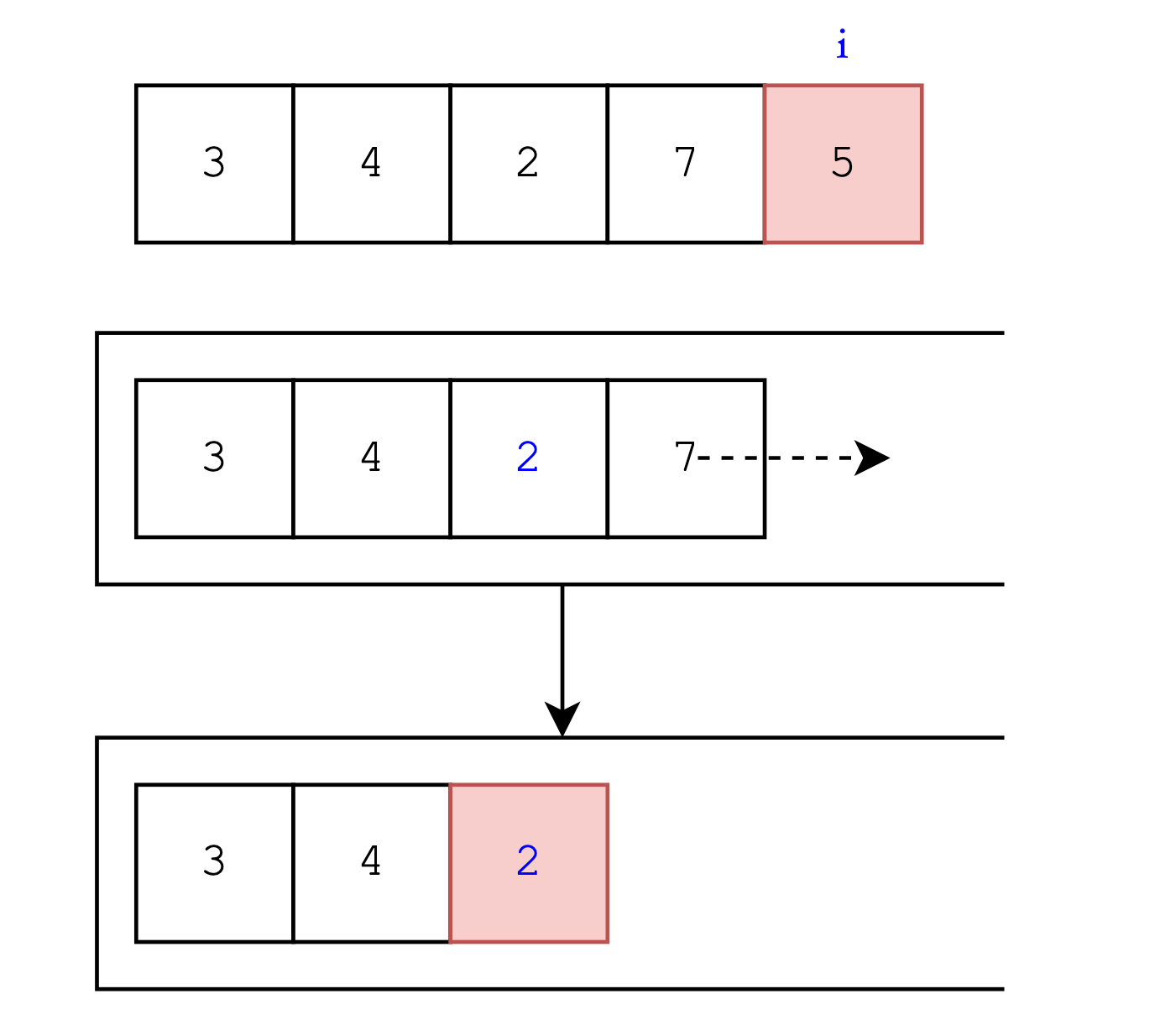
把栈横着放,出口对着核心元素的左边比较好理解。如果在i枚举时,j将i之前的所有元素都放到栈中,而要从栈中取出元素只能出栈。所以要保证栈顶元素满足一定条件,这样才能在i枚举时就能直接取出响应栈顶元素与之对应。
此处先不谈以何种方式将元素存入栈中,首先看图中的栈的初始状态和序列中i的位置,也就是元素5。由于栈保存了原先枚举的先后顺序,只不过是相反的,而恰好我们要找的是元素5左边比他小的最近位置,因此只要栈顶开始往下找,只要找到的是比5小的就是目标元素。这是栈先进先出的特性保证我们一定不会先找到一个虽然满足大小关系但是更远的,因为这里讨论的“远近”是相对于目标元素5而言的,更远的位置在更早的时候就已经入栈了。
优化 O ( n ) O(n) O(n)
既然不满足(和目标元素arr[i])大小关系的元素本来就要在查找时弹出,那么在入栈时何不作出限制,就过滤掉不可能是答案的元素了。
对于可能存在的答案而言,例如arr[x]和arr[y],如果arr[y]更小,且下标y更大,也就是在右边,那么这个arr[x]一定不是答案。因为本例中要找的是一个序列中每个元素左边离它最近且更小的元素的位置。
实际上,我们为了维护这个序列中的这个性质,最后得到的栈中元素将会是有序的,因为在构造栈的过程中不断消除了逆序对中的一个元素。
示例代码
#include <iostream> using namespace std; const int N = 100010; int tt, stk[N]; int main() { int n; cin >> n; for (int i = 0; i < n; i++) { int x; cin >> x; // 栈不空&&不满足要求 删除栈顶元素 while(tt && stk[tt] >= x) tt--; // 栈不空 找到正确答案,输出 if(tt) cout << stk[tt] << " "; // 找不到 else cout << -1 << " "; stk[++t] = x; } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
注意事项
- 注意分析问题的视角,可以用横着的栈开口面向目标元素思考,因此根据要求不同,入栈的顺序可能不一样。例如本题是找每个元素左边的xx元素,那么就应该从下标为0开始入栈;假如找的是右边的元素,那么就应该从后面开始入栈(例如下面的题目)。
- 注意在遍历时,每次操作完毕以后要将新元素入栈。
- 在单调栈的相关题目中,题目要求的可能是下标索引,也可能是元素的值本身。
- 使用数组模拟栈和队列不仅操作比STL更简单,而且在算法题中数组模拟会更快。
相关
单调队列
和单调栈类似,单调队列中的元素具有单调性,但一顿操作之后的结果,我们需要知道它是用来干嘛的。
一个最经典的应用就是求「滑动窗口」内的最值。(请首先到本节的最后观看视频)
窗口在现实中大小是不能变化的,那么对于一个序列而言,一个长度固定,而且能移动的范围,就是滑动窗口。
举个例子,对于序列:
1 2 3 4 5
- 1
那么长度为3的[滑动窗口]可以是:
[1 2 3] 4 5
- 1
1 [2 3 4] 5
- 1
1 2 [3 4 5]
- 1
朴素方法 O ( k ∗ n ) O(k*n) O(k∗n)
两重循环:
- 第一重:遍历长度为 n n n的序列(以窗口的右端点遍历);
- 第二重:遍历长度为 k k k的窗口。
优化 O ( n ) O(n) O(n)
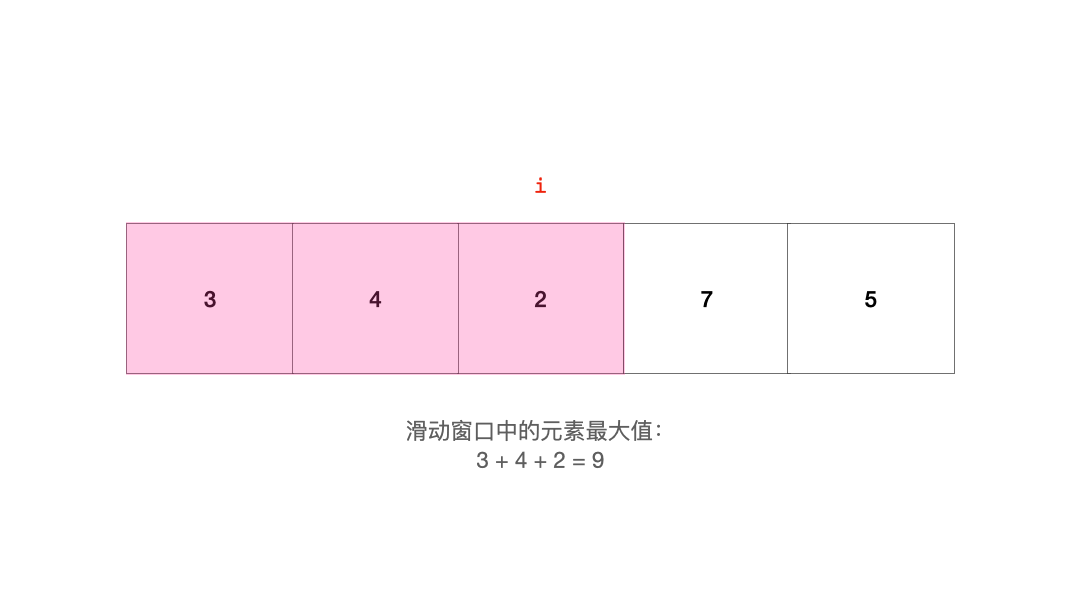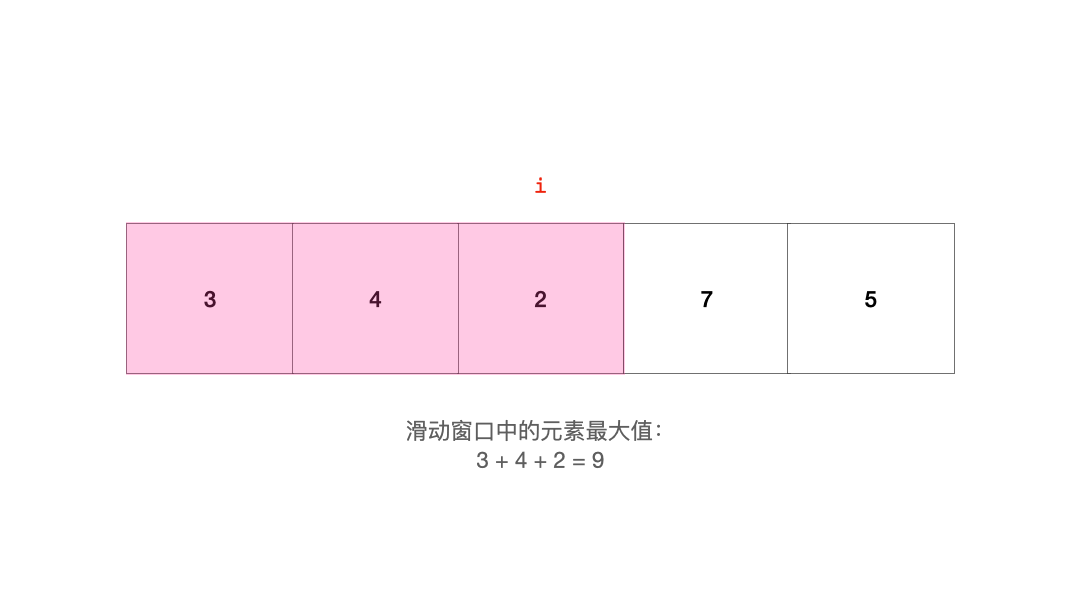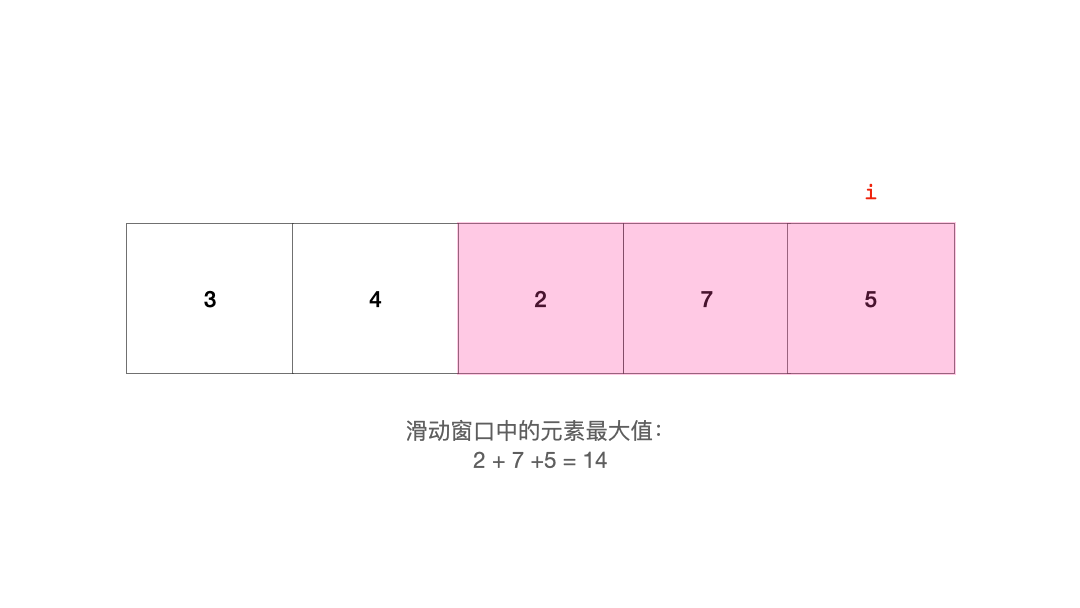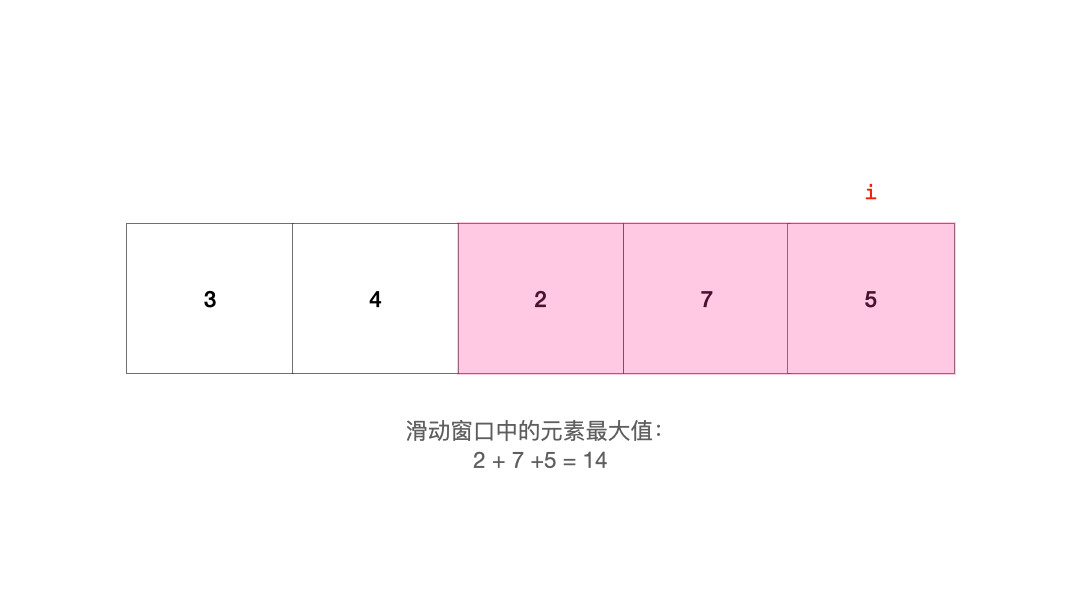
对于滑动窗口,由于它的长度是固定的,在移动的过程中,它的一端不断有新元素进入,另一端不断弹出旧元素。处于滑动窗口的元素可能会因为它和其他元素的大小关系而影响其他元素。例如这个序列(假如我们要求的是滑动窗口中元素之和的最小值):
1 3 -1 -3 5
- 1
当滑动窗口移动到这里时:
1 [3 -1 -3] 5
- 1
由于元素-3的存在,即将被弹出窗口的元素3就显得对求最小值不是那么重要。只要-3在,那么前面的3,对于查找和的最小值这件事的帮助就相比于-3的贡献更小,-1也是类似的。也就是说,只要窗口右边的元素中有一个是最小的,那么左边的元素对于『找最小值』这件事就是没有贡献的。反之也一样。
问题泛化:
窗口的右边的元素更小,也就是说下标大的反而值更小,保留小的元素,删去大的元素,剩下的元素之间就会有单调性。队列中的最小值就是队列头部元素。
如果用一个队列描述滑动窗口,那么它不是一个普通的队列,而是头部push,尾部push和pop。
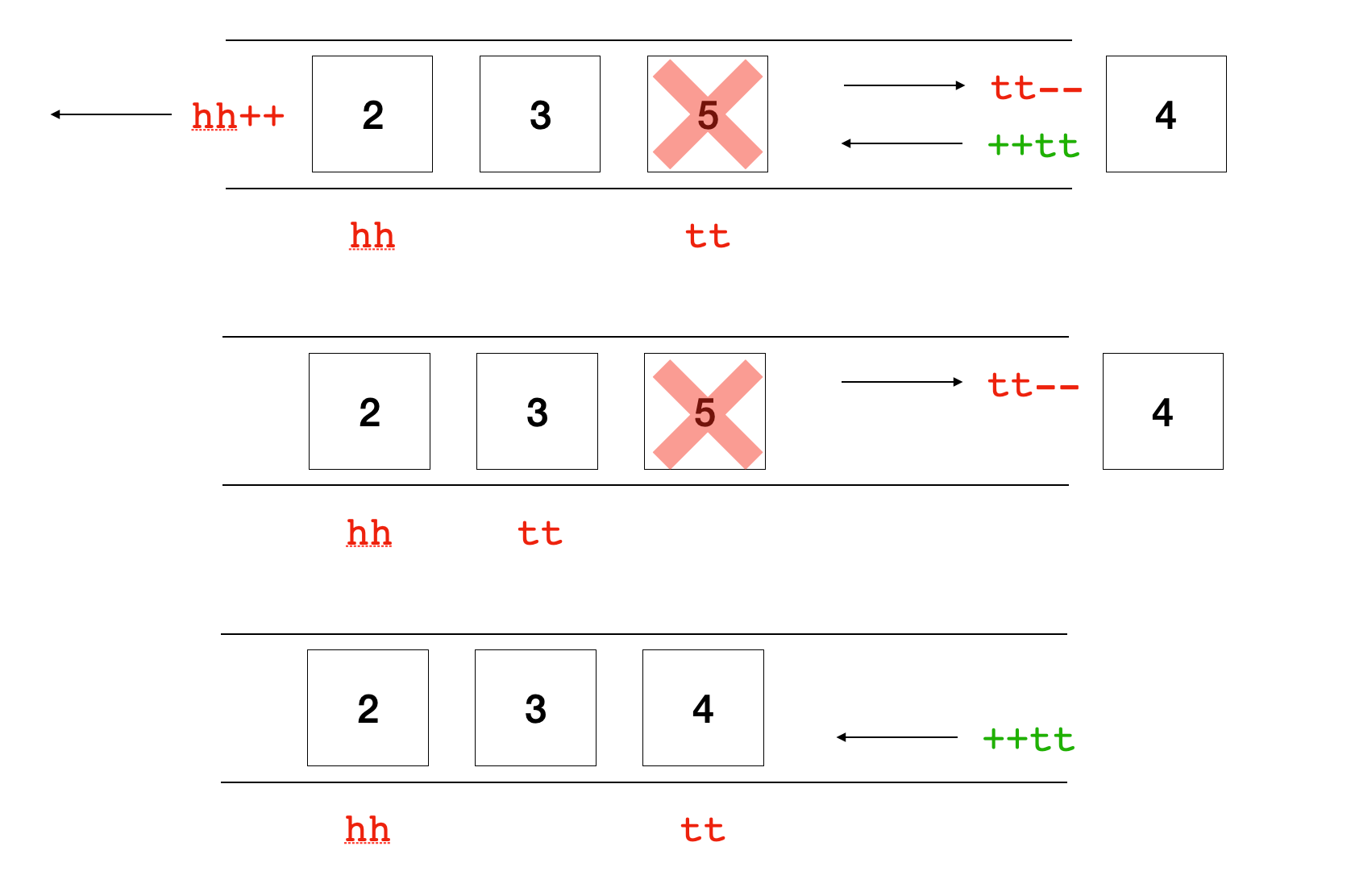
例如上面插入元素4的示例,由于是用数组模拟队列,因此出队和入队并不是真正的删除和插入。出队就是将hh指针往后移动,入队就是让tt指针往后移动,然后将新元素的值赋值到这个位置上。
一个残酷但容易理解的例子(来源于网络):
后进队的比先进队的年轻,如果后进队的还比先进队的强或者一样强,前面的就只能去死了。而就算先进队的是最强的,也得在寿命到了之后死。
值得注意的是,队列中存储的是下标而不是元素的值(例子中是值)。这是因为单调队列执行插入的时候,一定是从队尾进行插入,所以单调队列中的数据,从队首到队尾的顺序,一定是和原序列严格保序的。由于下标存储在单调队列中,根据保序性,存储的下标一定是单调递增的。这样做的好处是,下标不仅仅能够表示元素,还能表示元素在数组中的位置,携带的信息更多。
简单地说,存储数组的主要目的是方便判断队头出队。
在遍历过程中,我们已知滑动窗口的长度k,还知道当前窗口的右端点i,那么只要当队列头部元素存储的下标超出了窗口长度,即i - k + 1~i这个范围,就删除队列头部元素。
小结:
- 队尾出队条件:队列不为空且新元素更优。
- 队头出队条件:队头元素滑出了窗口。只要队头元素的下标(
q[hh])小于窗口左边界的的下标(i - k + 1),那就说明队头元素滑出了窗口。
示例代码
/* 滑动窗口求最小值 */
// 1. 遍历
for (int i = 0; i < n; i++)
{
// 2. 队列不为空且新元素更优
while (hh <= tt && a[q[tt]] >= a[i]) tt--;
// 3. 新元素下标入队
q[++tt] = i;
// 4. 队头元素滑出窗口
if (hh <= tt && q[hh] < i - k + 1) hh++; // 使用小于符号符合区间位置
// 5. 输出最小值
if (i >= k - 1) printf("%d ", a[q[hh]]);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意事项
-
hh和tt分别表示队列头部和尾部的指针。初始状态分别是0和-1。hh <= tt表示队列不为空。两个指针的初始状态会影响第5步的判断,这取决于循环的起始位置。如果
hh和tt分别从1和0开始,那么循环的起始下标是1,输出最小值的条件就是i >= k。 -
通过上面的分析,我们知道队头中存储的是当前遍历到的最小元素的下标。每次迭代都要判断队头存储的下标是否滑出了窗口,我们可以通过下标来判断。由于当前窗口的右端点的下标就是第一层循环
i,窗口长度已知为m,那么左端点的位置就是i - k + 1。如果窗口左端点的下标大于队头保存的下标,说明后者已经出了窗口的范围了,将它从队列前段删除,即hh++。hh++可以删除队列头部元素,因为它将队列头部索引hh的值增加了 1。在这段代码中,队列是用一个数组q来实现的,其中q[hh]表示队列头部元素的索引,而q[tt]表示队列尾部元素的索引。当hh的值增加 1 时,队列头部元素的索引也会增加 1,从而删除了原来的队列头部元素。 -
上面使用
if操作的原因是窗口每次只会移动一个单位。 -
在滑动过程中,如果新元素
a[i]比队头元素索引的值更小,那么就从队列后端删除大于或等于a[i]的元素。使用while的原因是可能不止一个元素满足这种情况。 -
将当前元素
a[i]的下标从队尾入队。 -
在窗口大小为
k的情况下,当当前索引i大于或等于k-1时,表示窗口已经完全覆盖了序列a[]中的前k个元素。此时,窗口中的最小值就是队列头部元素对应的值,即a[q[hh]],输出当前窗口中的最小值。
注意,将当前元素a[i]下标从队尾入队(第五步)的操作必须在输出答案之前进行,因为a[i]可能比原来队头索引的元素值更小,那么a[i]就是答案本身。
滑动窗口求最大值的操作只要更改while中的逻辑就好:
/* 滑动窗口求最大值 */
// 重置队头和队尾指针
hh = 0, tt = -1;
for (int i = 0; i < n; i++)
{
while (hh <= tt && a[q[tt]] <= a[i]) tt--;
if (hh <= tt && i - k + 1 > q[hh]) hh++;
q[++tt] = i;
if (i >= k - 1) printf("%d ", a[q[hh]]);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
理解单调队列代码的前提是理解用数组模拟队列的代码,通过在队列中提供的图示记忆两个指针的相对位置对理解代码非常有帮助。
时间复杂度
每个元素最多入队和出队各一次,时间复杂度为 O ( n ) O(n) O(n)。
记忆
- 窗口维护的是最小值,那么新元素
a[i]越小越优。如果a[i]越优,q[]出队,直到它非优。 - 窗口的范围在不断变化,但是长度不变:[i - k + 1 ~ i]
i:枚举序列中的每个字符。a[i]就是新元素;入队的是下标。i - k + 1就是窗口的左边界。
- 队列不空才能进行操作:
hh <= tt。 - 只要队头元素保存的下标比左边界小,就是滑出了窗口。
- 只有当枚举元素的下标
i(从0开始)大于等于窗口的长度k时才开始输出队列头部元素(窗口左端元素)。
相关题目
参考资料
- 视频:411 单调队列 【模板】滑动窗口最值(强烈建议观看)
字符串匹配
KMP算法是字符串中的模式匹配算法。简单地说就是以 O ( n ) O(n) O(n)的时间复杂度在一个长串中查找一个短串,如果存在的话返回短串在长串中的起始位置。
朴素算法 O ( n ∗ m ) O(n*m) O(n∗m)
在一个字符串中查找子串的朴素做法不涉及KMP算法,不难想到:
从主串的第一个字符起与子串的第一个字符进行比较,若相等,则继续逐对字符进行后续的比较;若不相等,则从主串第二个字符起与子串的第一个字符重新比较,以此类推,直到子串中每个字符依次和主串中的一个连续的字符序列相等为止,此时称为匹配成功。如果不能在主串中找到与子串相同的字符序列,则匹配失败。
下面用一个例子示范:


其时间复杂度为 O ( n m ) O(nm) O(nm),其中 n n n为主串长度, m m m为子串长度。由于这种算法需要对每个字符进行比较,所以时间复杂度较高。
在查找子串的朴素算法中,i和j指针分别维护的是长串s[]和短串p[](文本串和模式串),它们的处理有所区别:
- 第一层循环:
i枚举长串的每一个字符s[i]。 - 循环中的匹配逻辑:
j枚举可能是子串的字符(s[i] == p[j])。
匹配成功(s[i] == p[j]):
i和j都往后走一步。
匹配失败(s[i] != p[j]):
i(长串)移动到本次起始位置的下一个位置。j(短串)重新回到短串的起始位置重新匹配。
KMP算法 O ( n ) O(n) O(n)
实际上,在朴素做法中,没必要每次s[i] != p[j]失败时就让短串指针i回到开头,可以利用一下之前已经匹配过的字符。
KMP算法一般有两个版本,字符串下标从0或1开始,重要的是理解思想。下面两图示以0为起始下标,不影响理解。
例如:
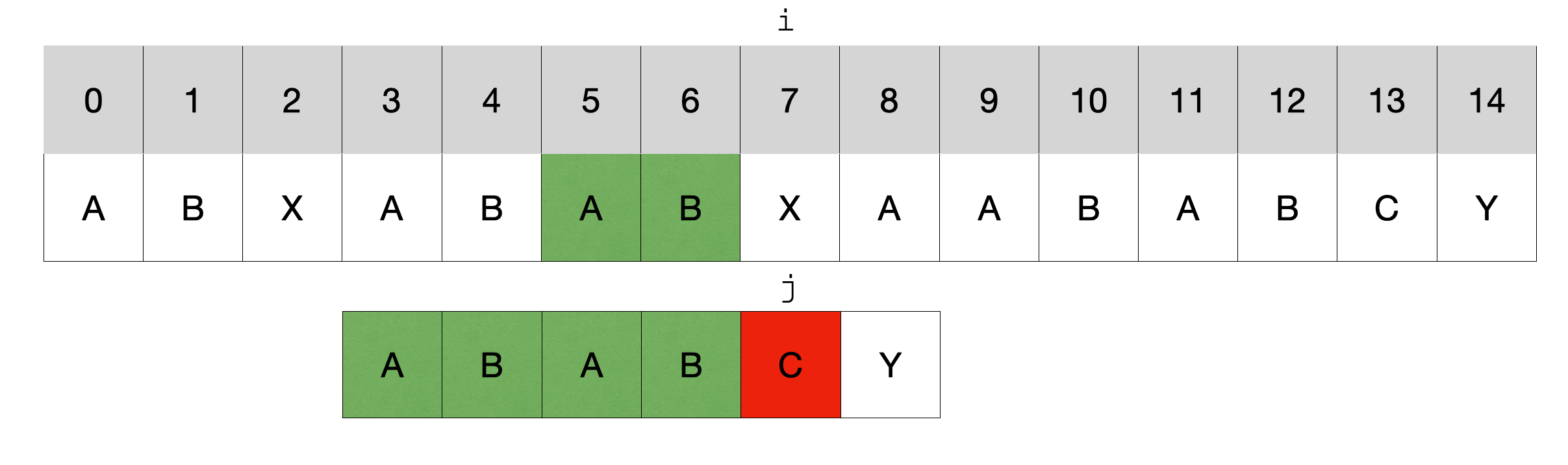
在这个例子中,模式串匹配到字符C就停止了,本应该回到开头重新匹配,但是发现模式串匹配失败的字符前面这个子串(绿色)中的前缀和后缀是相同的,都是AB,长度是2,那么这时就能直接将指针j移动到下标为2的位置,然后继续开始匹配,这样就能把之前模式串中已经匹配的字符利用起来。实际上,绿色部分的字符一定是被匹配过的,所以可以安全地利用它们。
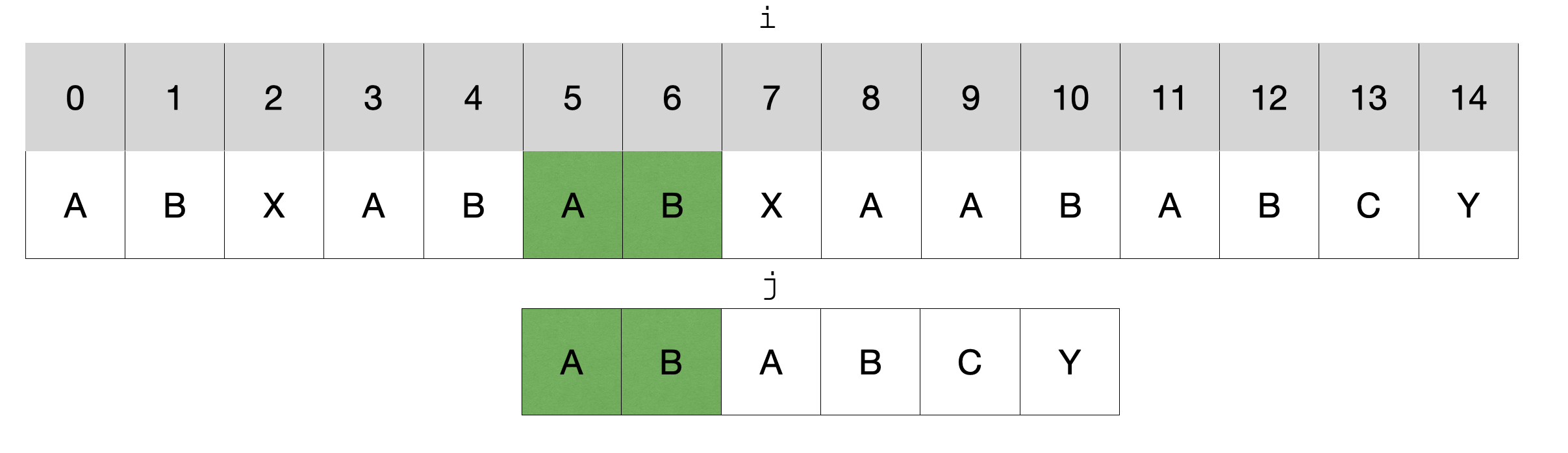
注意:这里指的是是真前缀和真后缀,意思就是长度必须小于原字符串,而不能是本身。而且是前缀和后缀,而不是任意位置的子串,即:从下标为0开始的前缀,以最后一个字符结束的后缀。
下面介绍这个方法的原理,为了泛化问题,下面用颜色区分各种字符。
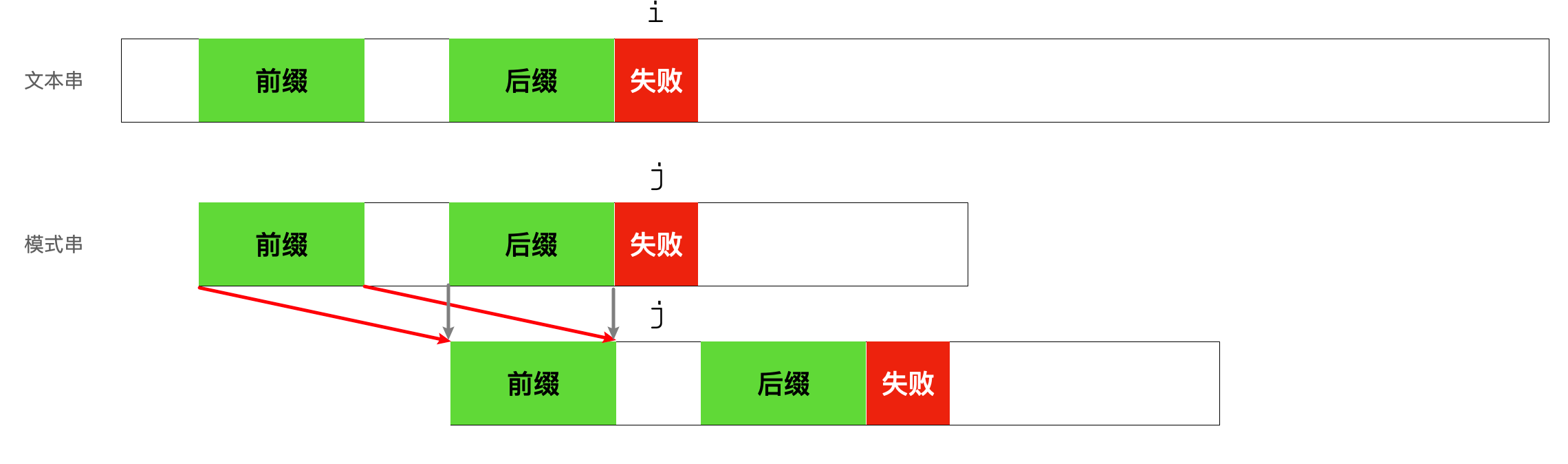
KMP算法的核心思想是在模式串的失配位置前面的子串中(如指针j前面的子串)找到一个后缀,使得它和前缀相等,那么下次再重新比较时就能直接将模式串对齐到后缀,从失配的地方开始比较。
只要我们找到了失败字符前面子串的相同前后缀,正因为前后缀是一样的,所以就能让下一次指针j的位置避免再次比较已经被匹配的前缀了。在已经失败的旧模式串中(图中第一个模式串),起作用的是后缀;在调整指针j以后的新模式串中(图中第二个模式串),起作用的是前缀,后缀相当于一个基准,使得前缀能够对齐。
可以设想:如果在模式串的失配字符之前的子串中使得前缀和后缀长度相同且最大,那么就能让维护模式串的指针j回退到它离前面最近(也就是离字符串起始位置最远)的位置,也就是说能够最大限度地利用已经匹配成功的前缀这一信息,从最近的起点开始重新匹配,这样剩下未匹配的字符就尽可能少了。
构造next数组
注意:字符串的起始下标从1开始。
next[i]表示模式串p[1~i]中相等真前后缀的最大长度[背过]。也就是说,求解next数组的过程是为了确定当模式串中某个字符与文本串中的字符不匹配时,模式串下一步应该移动到哪里。
暴力构造
以一个例子为例,演示暴力构造next数组:
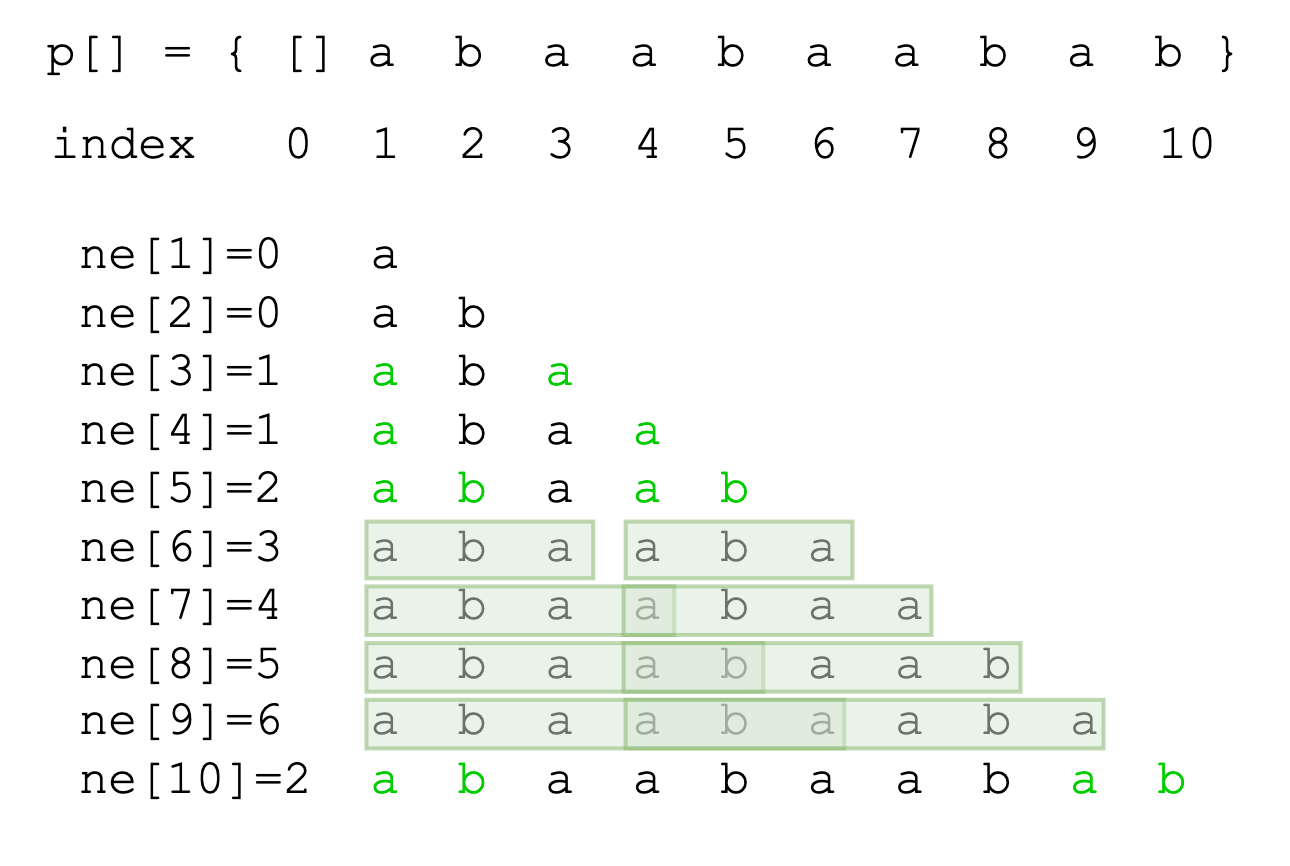
next数组就是给失配位置j打的表,只要j位置失配了,那就跳转到next[j]指定的位置,换句话说,next数组的构造是通过查找最长公共前后缀的长度自动实现的。例如图示中的next[5]表示模式串在下标为5时与文本串失配,那么就跳转到最大公共前后缀的长度对应的下标位置。
next[i]数组随着i增大,公共前后缀的长度有以下规律规律:
-
增大:最多只会增加1,如例子中的next[3~9]。
-
减小:当找不到比上一次匹配的更长公共前后缀时,可以复用之前匹配的结果。如例子中的next[10] = next[5] = 2:
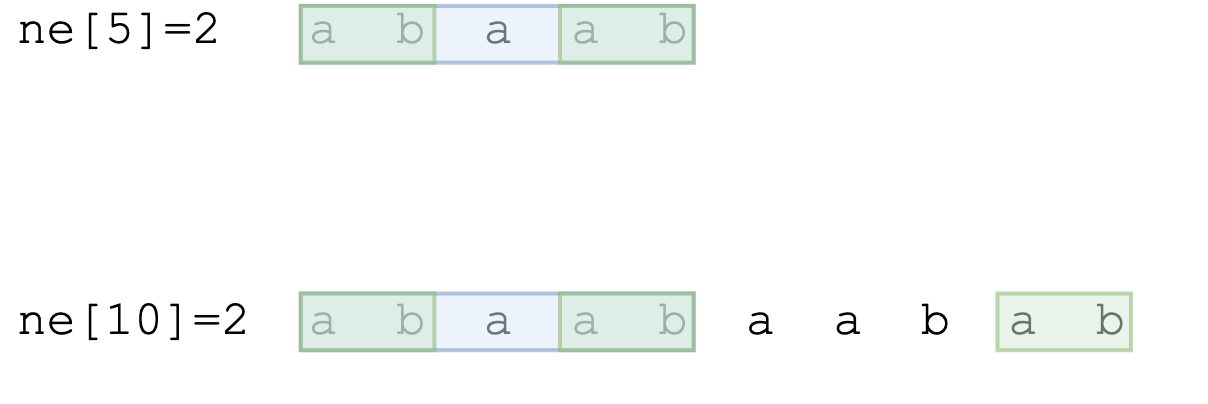
自动构造
-
思路:双指针:
-
外层循环指针
i:枚举模式串的每个字符。 -
内层指针
j:扫描前缀。
-
-
初始化:
- next[1] = 0
- i = 2, j = 0
每轮循环i只往后走一步:
- 如果
p[i] != p[j + 1],说明失配,让j指针回退,位置能否匹配:- 能:
j = next[j]。i指针一定比j指针走的快,因为前者每次循环都会走一步,后者可能还会回退,那么next[j]的结果一定被保存了(第三步)。 - 不能:
j回到前缀的起始位置,即0。
- 能:
- 如果
p[i] = p[j + 1],说明匹配,j指针往后走1步。即j指针指向了前缀的末尾。 - 记录前缀末尾的位置,即
next[i] = j。
下面先给出代码,然后再结合思路理解:
ne[1] = 0;
for (int i = 2, j = 0; i <= n; i++)
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
理解:
-
注意:用图示理解时,两个指针分别维护两个一样的序列更好理解,实际上代码中两个指针对同一个序列维护,只是维护的区间不同。常常把上面的序列看作文本串,下面的看作模式串。
-
ne[1] = 0,表示长度为1的子串没有前缀,所以第一个字符也就没有比较的必要,那么前缀的长度就是0。对于文本串,那就相当于执行了一次循环(i从0到1);对于模式串,无影响,相当于从头开始重新匹配。 -
初始状态:
i == 2, j == 0:
在这个状态时,前面的while分支一定不会执行,因为
j == 0。第二个if分支执行与否取决于具体情况,在例子中的初始状态下,它不会被执行,那么只会记录i位置上的前缀长度,即ab的前缀长度为0。 -
中间状态:
i == 3, j == 0:
-
中间状态:
注意被
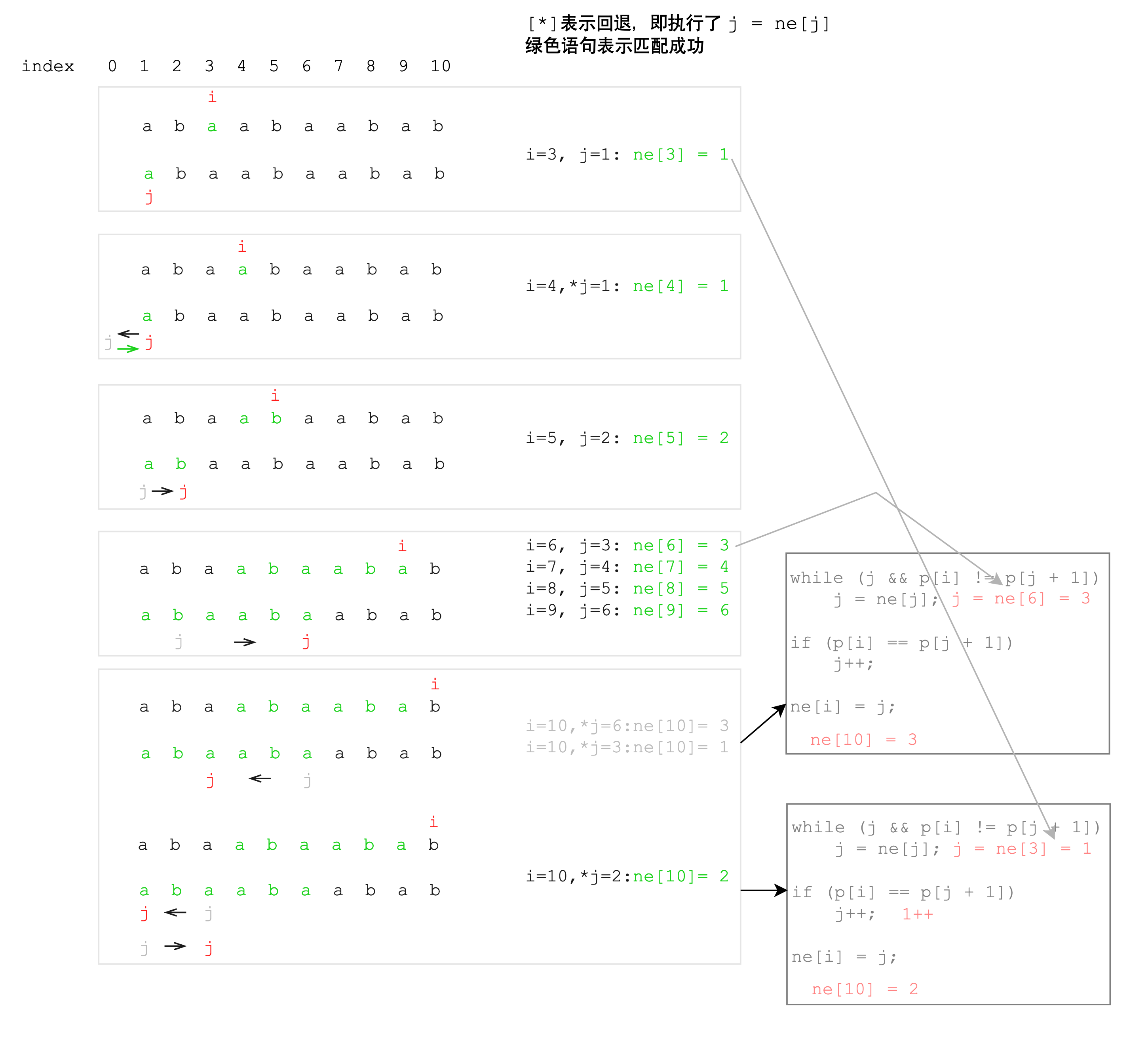
*标记的语句,表示进行了回退的过程。前面的i:1~9很好匹配,着重理解最后一个i == 9, j == 6的情况。回退了不止一次:首先j从6回退到3,p[9]和p[3+1]不匹配,接着回退到1,这下就匹配了,j++,移动到2,那么最后next[9]的值就是最后的2。强烈建议对照着代码按图走一遍,加深理解。
值得注意的是,回退的操作就如刚才所说,指针
i一定走的比指针j快,所以可以放心地执行j = ne[j],因为ne[j]已经被i遍历时记录了。图示中的灰色箭头也体现了这一点。
注意事项
理解语句
p[i] != p[j + 1]:为什么要用i位置的元素和j下一个位置的元素比较呢?
这样做的目的是减少不必要的比较次数,提高匹配效率(需要结合上文「最长公共前后缀」的作用理解,脑子里要有一个i和j的相对位置,可以画图)。是一种预判机制:
- 进可攻:如果
p[i]和p[j+1]匹配,那么两个指针都往后走一步,表示匹配成功。简单地说:如果i位置的元素和j位置的元素相等,那么i+1位置的元素和j+1位置的元素也有可能相等,这样就可以继续比较下去。 - 退可守:如果
p[i]和p[j+1]不匹配,那么指针j往回退,直到找到匹配的位置,否则退回前缀的起始位置,即下标为0的位置。简单地说:如果i位置的元素和j位置的元素不相等,那么就要根据next数组来回溯j的位置,找到一个更短的相等前后缀,然后再用i位置的元素和j下一个位置的元素比较。
「回退」是一种退而求其次的过程,因此回退的次数可能不止一次。
时间复杂度
i指针遍历一遍序列,时间复杂度是
O
(
n
)
O(n)
O(n),因此总体的时间复杂度取决于j指针走的步数。对于每次循环指针j最多加1,总共至多走
n
n
n步;如果j至多往后走
n
n
n步,那么回退的总步数不超过
n
n
n,否则j就超出了下标0的,为负数。
因此指针j的总步数不超过
2
n
2n
2n,总体代价不超过
O
(
3
n
)
O(3n)
O(3n),总体时间复杂度为
O
(
n
)
O(n)
O(n)。
模式匹配
在文本串中匹配模式串的操作和构造next数组的操作非常类似,还记得在构造数组时要用两个一样的序列分别对应两个指针的操作吗?在模式匹配的过程中,其中一个序列就是文本串,大致操作类似,只有小部分细节需要修正。
模式串与文本串匹配的过程:
-
思路:双指针:
-
外层循环指针
i:枚举文本串的每个字符s[i]。 -
内层指针
j:扫描模式串p[]。
-
-
初始化:
- i = 1, j = 0
每轮循环i只往后走一步:
- 如果
s[i] != p[j + 1],说明失配,让j指针回退,位置能否匹配:- 能:
j = next[j]。i指针一定比j指针走的快,因为前者每次循环都会走一步,后者可能还会回退,那么next[j]的结果一定被保存了(第三步)。 - 不能:
j回到前缀的起始位置,即0。实际上,如果真的不能回退的话,执行到最后下标就是0,而不是一开始就知道它不能回退到0下标处。
- 能:
- 如果
s[i] = p[j + 1],说明匹配,j指针往后走1步。 - 如果匹配成功,输出匹配的位置。
下面先给出代码,然后再结合思路理解:
// m - 文本串, n - 模式串
for (int i = 1, j = 0; i <= m; i++)
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j++;
if (j == n) printf("%d ", i - n + 1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
理解(仅解释不同的地方):
- 指针的初始状态:
i = 1, j = 0,这么做的原因是:- 两个指针维护的是不同序列,因此它们的第一个字符一定要比较一次。
- 由于while循环的条件是
j && _,那么初始状态一定不会走这个分支,此时i == 0,即使第一个字符没有匹配,不论如何i指针每轮循环都会加1,那么总会走到if分支,使得j++(假如可以的话),那么下一次循环就可能进入while分支…使得匹配的逻辑运行起来。
- 当指针
j的值等于模式串的长度时,就执行对应逻辑,比如打印。这还是因为匹配的对象是文本串的第i个位置和模式串的第j个的下一个位置,最后需要控制j的范围,否则可能会越界,因为文本串的长度可能大于模式串。
下面是一个简单的例子(虽然图很大,但是设置了一个简单的例子,建议手动完成练习):

这个例子中模式串是在求next数组时已经得到了,在这里直接使用。
匹配与回退的过程和求next数组的过程十分类似,其中当i分别为11和12时(红色语句警示的),充分体现了最大公共前后缀分别在模式串和文本串中的作用。
其中,在右侧被标记为红色的语句是回退的操作,通过这些情况,可以很鲜明地体会回退和匹配的过程。
时间复杂度
和构造next数组类似,j指针走的总步数决定了整体的时间复杂度。对于每次循环指针j最多加1,总共至多走
n
n
n步;如果j至多往后走
m
m
m步,那么回退的总步数不超
m
m
m,否则j就超出了下标0的,为负数。
因此指针j的总步数不超过
2
m
2m
2m,总体代价不超过
O
(
2
m
+
n
)
O(2m+n)
O(2m+n),总体时间复杂度为
O
(
m
)
O(m)
O(m)。
参考资料
相关题目
Trie
Trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。–Trie
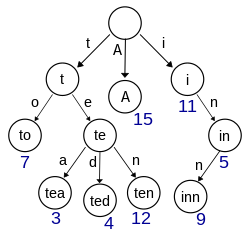
这是一个字典树,它把字符串看成字符序列,根据字符串中字符序列的先后顺序构造从上到下的树结构,树结构中的每一条边都对应着一个字符。自根节点而下,它存储了若干个字符串:“A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”。字典树存储字符串是为了方便地查询,因此在每个单词结束的位置,都要标记一下,以表示单词的末尾,方便查询。
从这个例子中可以看到,字典树是一种能够快速插入和查询字符串的多叉树结构。之所以说快速,是因为它可以利用之前插入的节点从最近的位置插入,例如"tea", “ted”,和"ten"共享了前缀"tn"分支,这是“前缀树”的由来。由此可见,插入的过程也是查找的过程。
节点的编号各不相同,无特殊需要,定义根节点的编号为0,其他节点用来标识查找的路径(看图),字典树维护的是一个二元关系:
- 节点:用来标识字符串的结束位置,还能维护一个数组
cnt[],来记录这个路径对应的字符串插入的次数。 - 边:用来表示字符,即维护字符串的是边。
字典树维护的字符串集合,支持插入和查询两种操作。
字典树的用途有:
- 统计、排序和保存大量的字符串,比如搜索引擎系统用于文本词频统计。
- 实现自动补全、拼写检查等功能,比如在搜索框输入部分单词下面会有一些相关的搜索内容。
- 实现字符串匹配、前缀匹配等操作,比如判断某个字符串是否在字典树中,或者是否有以某个前缀开头的字符串。
- 是AC自动机的一部分。
建树 O ( n ) O(n) O(n)
需要使用的变量:
-
孩子数组
ch[p][j]:存储从节点p沿着j对应的字符这条边走到的子节点。-
边假设为26个小写字母对应的映射值0~25。(这取决于字符集合)
-
每个节点最多有26个孩子。
-
例如:
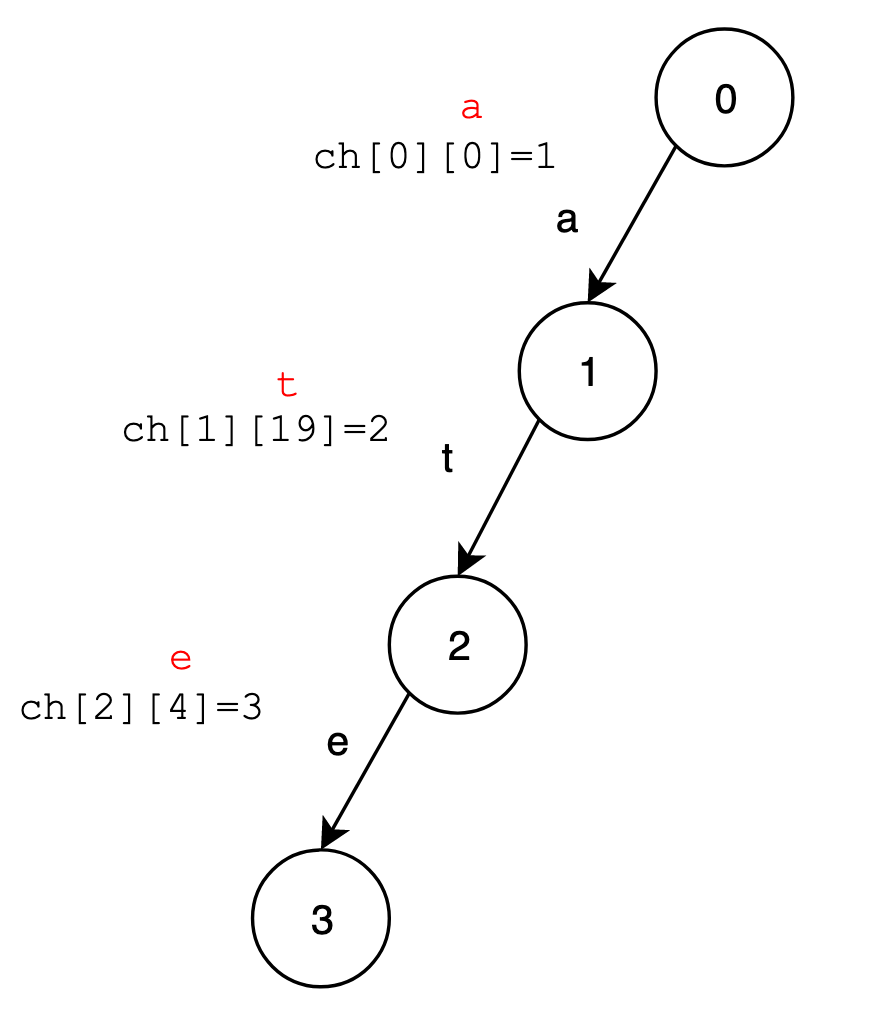
其中:
ch[0]][0]=1表示编号为0的结点通过边为字符a的映射值0指向编号为1的结点;ch[1]][19]=2表示编号1的结点通过边为字符t的映射值19指向编号为2的结点;以此类推。
-
-
计数数组
cnt[p]:保存以节点p结尾的字符串插入的次数。 -
节点编号
idx:用数组保存结点,给每个新结点编号。
建立字典树的基本思路是:
-
定义一个字典树的根节点,初始化为空,编号为0。
-
对于每个要插入的字符串,从根节点开始,枚举字符串的每个字符,是否有孩子节点:
- 有孩子节点:
p指针走到孩子节点处。 - 没有孩子节点:先创建新儿子节点,让
p指针走到新节点处。
- 有孩子节点:
-
在字符串遍历结束时更新插入次数。
下面先给出代码,然后再结合思路理解:
char s[N];
int ch[N][26], cnt[N], idx;
void insert(char *s)
{
int p = 0;
for (int i = 0; s[i]; i++)
{
int j = s[i] - 'a'; // 字符--映射-->整数
if (!ch[p][j]) ch[p][j] = ++idx; // 不存在孩子, 创建之
p = ch[p][j]; // 插入
}
cnt[p]++; // 更新以p结尾的字符串次数
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
理解:
- for循环的终止条件是遇到字符串末尾的
\0,它的ASCII值为0。 j = s[i] - 'a'的意思是取到字符相对于字母a的相对位置,也就是字母表中的位置。用j保存映射值。- 由于
ch[][]通常定义在全局,因此它的每个元素的值都是0,如果在插入时发现p位置沿着j对应的字符的位置的值是0,说明这个位置没有被“开发”,也就是说它没有孩子节点,所以要创建。创建的方法就是在数组中放开一个位置以供存储。然后插入。 cnt[p]++表示更新以p对应的字符为结尾的字符串插入的次数。
下面这个例子中插入了3个字符串:“cat”,“car”,“bus”。
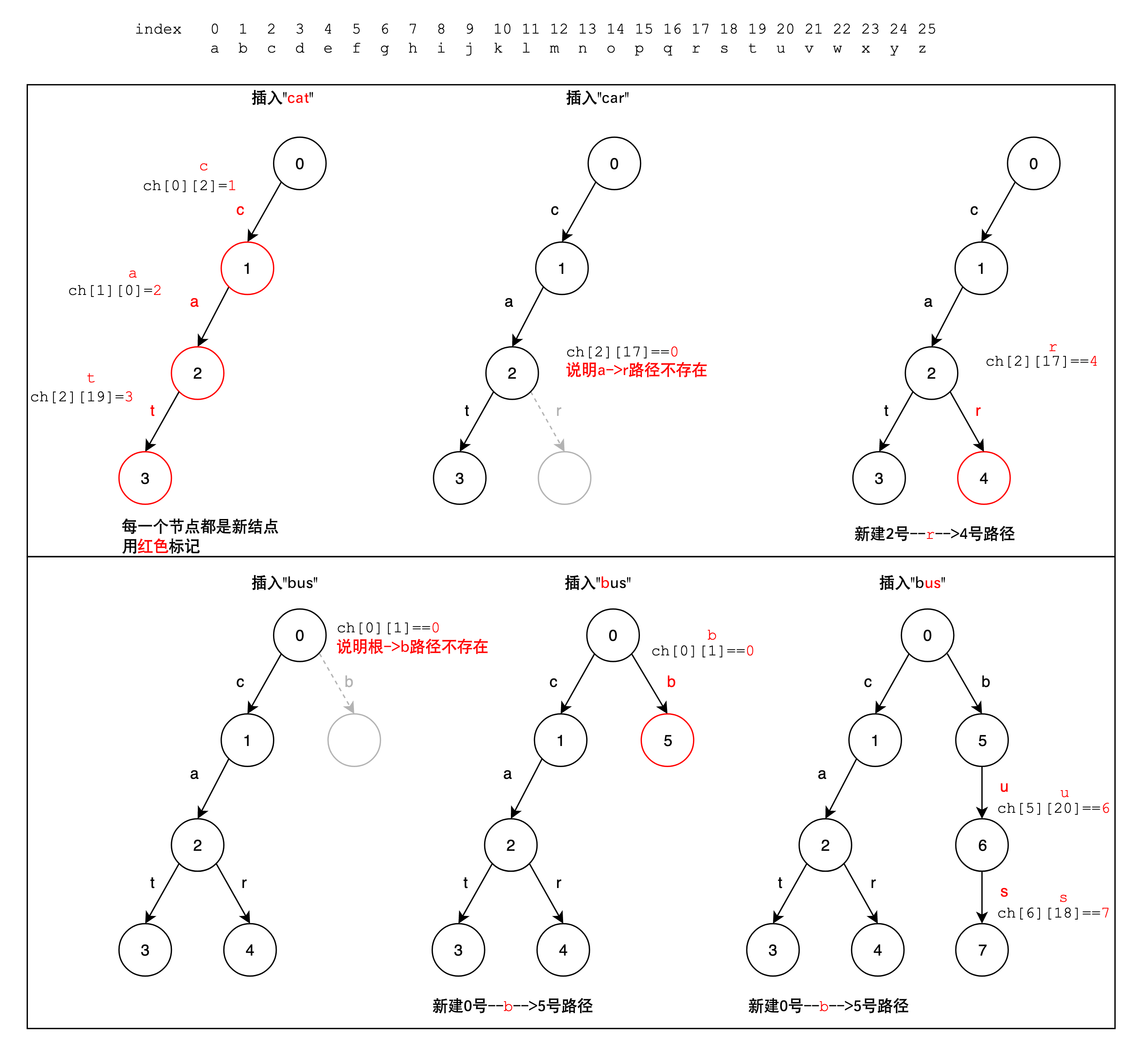
其中最重要的步骤是当路径不存在时,应该创建一个新节点,然后建立路径。
查询 O ( n ) O(n) O(n)
和建树的步骤类似,甚至还更简单,步骤如下:
- 从字典树的根节点开始查找,扫描字符串中的每个字符。
- 如果在字典树向下查找的过程中边对应的字符总是和字符串中的字符匹配,那么就能走到字符串的末尾,最后返回插入的次数。
- 否则说明没有匹配的字符串,返回0。
实现:
int find(char *s)
{
int p = 0;
for (int i = 0; s[i]; i++)
{
int j = s[i] - 'a';
if (!ch[p][j]) return 0;
p = ch[p][j];
}
return cnt[p];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
时间复杂度
插入和查询操作的时间复杂度都是 O ( n ) O(n) O(n)。
参考资料
相关题目
并查集
并查集(Disjoint-set data structure,不交集数据结构)是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。 并查集的思想是用一个数组表示了整片森林(parent),树的根节点唯一标识了一个集合,我们只要找到了某个元素的的树根,就能确定它在哪个集合里。 并查集支持两种操作:
- 合并(Union):把两个不相交的集合合并为一个集合。
- 查询(Find):查询两个元素是否在同一个集合中。
例如,下面就是一个并查集:
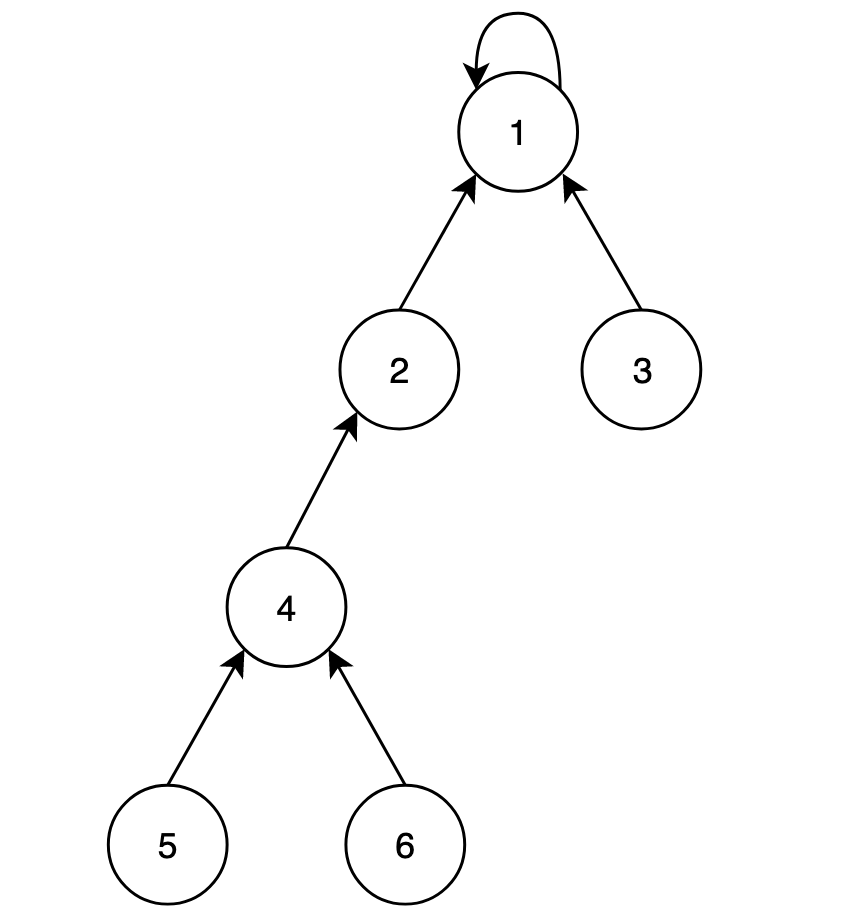
我们用一个数组p[x]存储节点x的父节点,在上图中:
p[1] = 1
p[2] = 1
p[3] = 1
p[4] = 2
p[5] = 4
p[6] = 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
默认根节点的父节点是它本身。
初始化f[]:每子树都是一个集合,每个节点的父节点都是它自己:
for (int i = 1; i <= n; i++) f[i] = i;
- 1
查找
每一个节点代表的子树都是一个集合,查找元素在此集合中,就是查找元素集合的根节点。
- 如果父结点等于元素本身,即找到了根节点,返回。
- 否则说明没有找到根节点,继续递归地查找。
例如要查找上图中的6节点是否在此集合中(find(6)):
- 首先从6进入树
- 找到6的父节点4,不是根节点1,继续向上递归查找
- 找到4的父节点2,不是根节点1,继续向上递归查找
- 找到2的父节点1,是根节点1,查找成功,返回根节点的值。
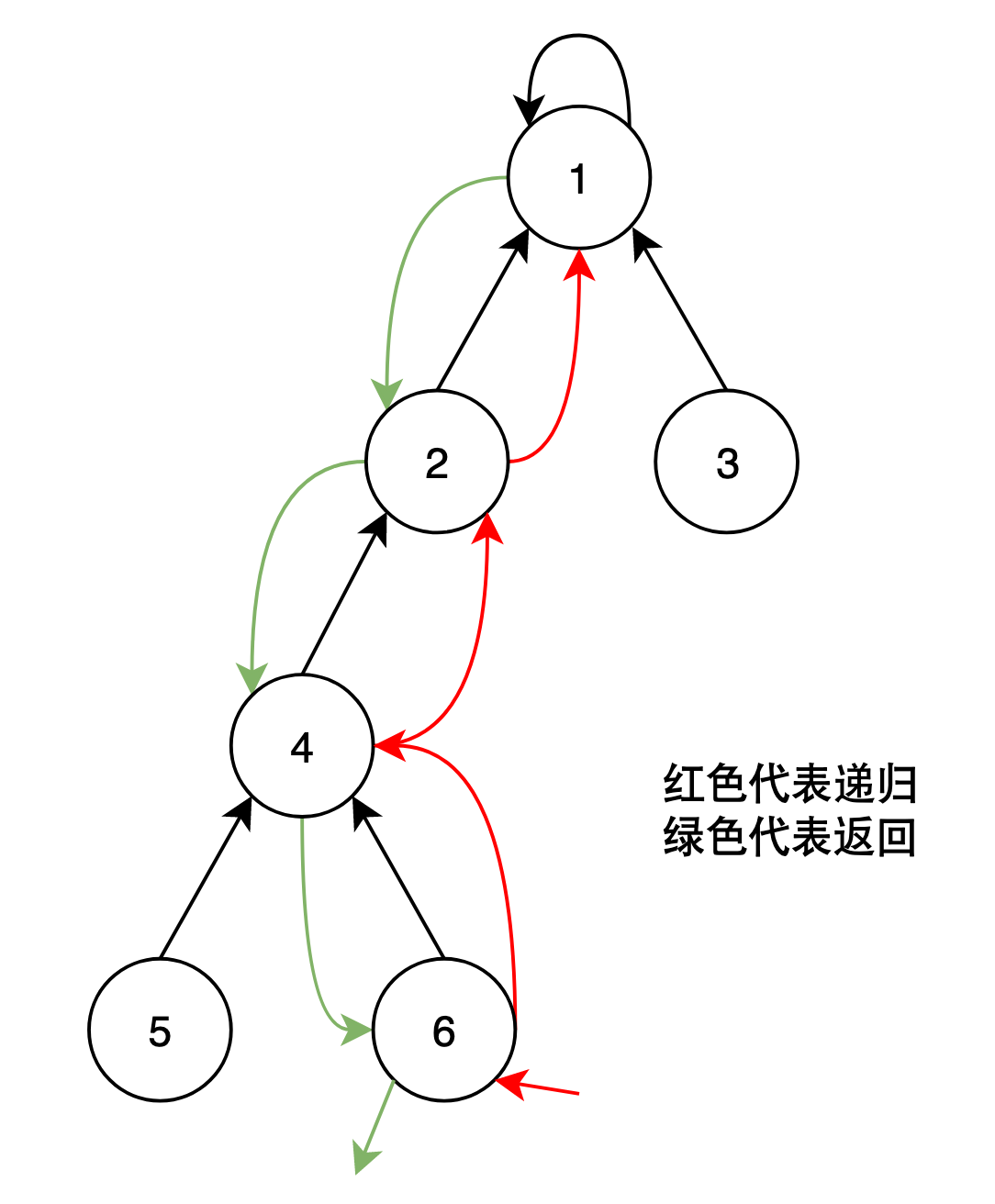
代码示例:
int find(int x)
{
if(f[x] == x) return x;
return find(f[x]);
}
- 1
- 2
- 3
- 4
- 5
路径压缩
可见,这样查找的效率是很低的,每次查找都要不断地递归。对于节点6,执行查找的过程中,将信息利用起来,这样下次查找6节点时就能直接得到答案,从而降低整体时间复杂度。
做法是这样的:在不断向上查找父节点的过程中,同时将各个节点的父节点改为根节点。如上例:
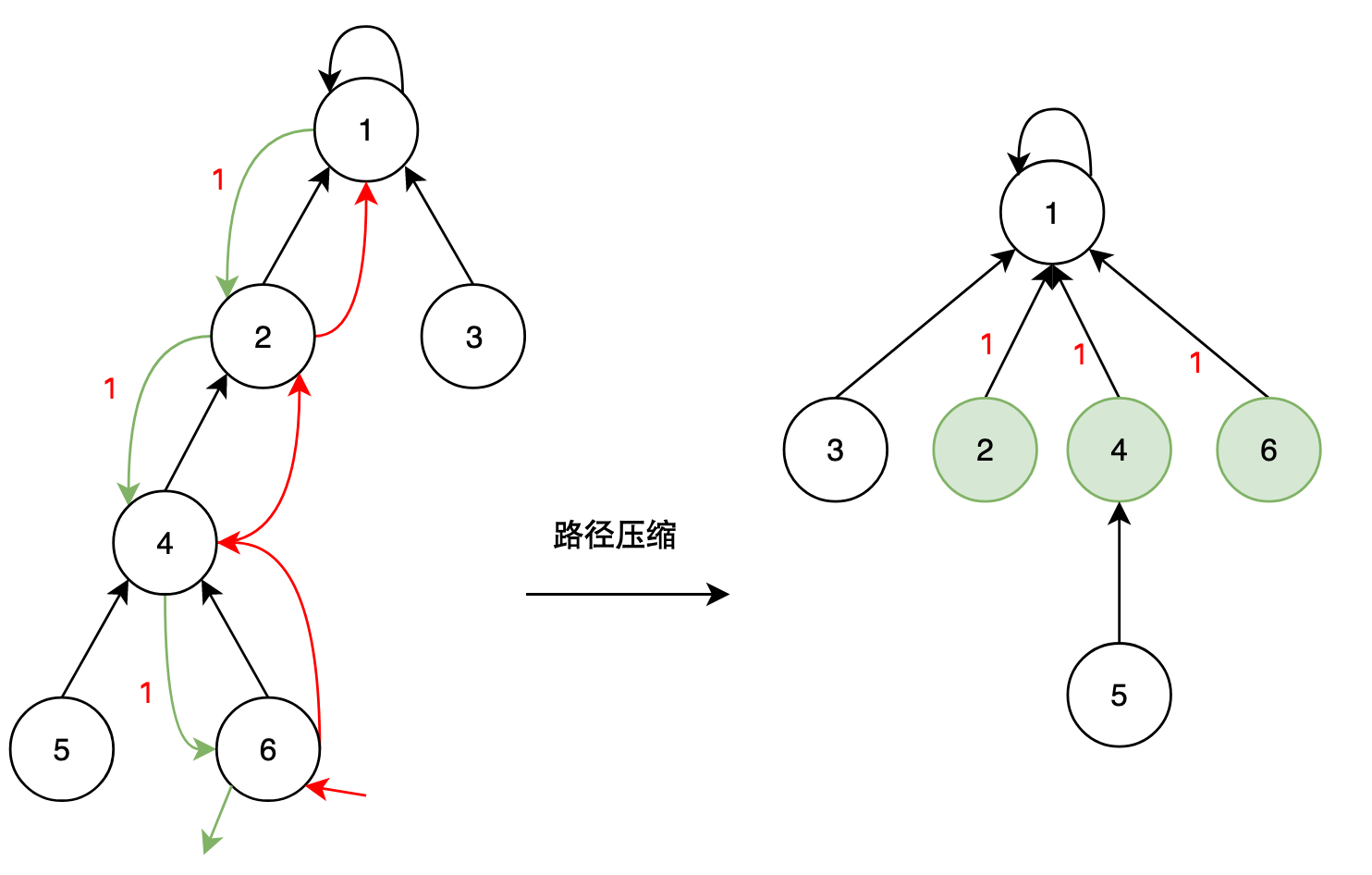
流程是这样的:
[递归过程]
从6节点进入,找到父节点4
从4节点进入,找到父节点2
从2节点进入,找到父节点1
从1节点进入,返回
[返回过程]
从1节点回到2节点,修改f[2]=1,返回1
从2节点回到4节点,修改f[4]=1,返回1
从4节点回到6节点,修改f[6]=1,返回1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
代码如下:
// 路径压缩
int find(int x)
{
if(f[x] == x) return f[x] = x;
return find(f[x]);
}
- 1
- 2
- 3
- 4
- 5
- 6
相比于原本递归的代码,只增加了终止条件的赋值语句,表示在返回的同时更新节点的父节点为根节点。这就能直接对应上并查集中“查”的那一部分,赋值体现了“同时”。
因此现在find()对于未被查找过的元素还有压缩的功能。
合并
每个子树都是一个集合,那么每个并查集的也是一个集合,要将集合合并,也就是将一个并查集的根节点的父节点不再指向它本身,而是指向另外一个并查集的根节点。
void unionset(int x, int y)
{
f[find(x)] = find(y);
}
- 1
- 2
- 3
- 4
例如:
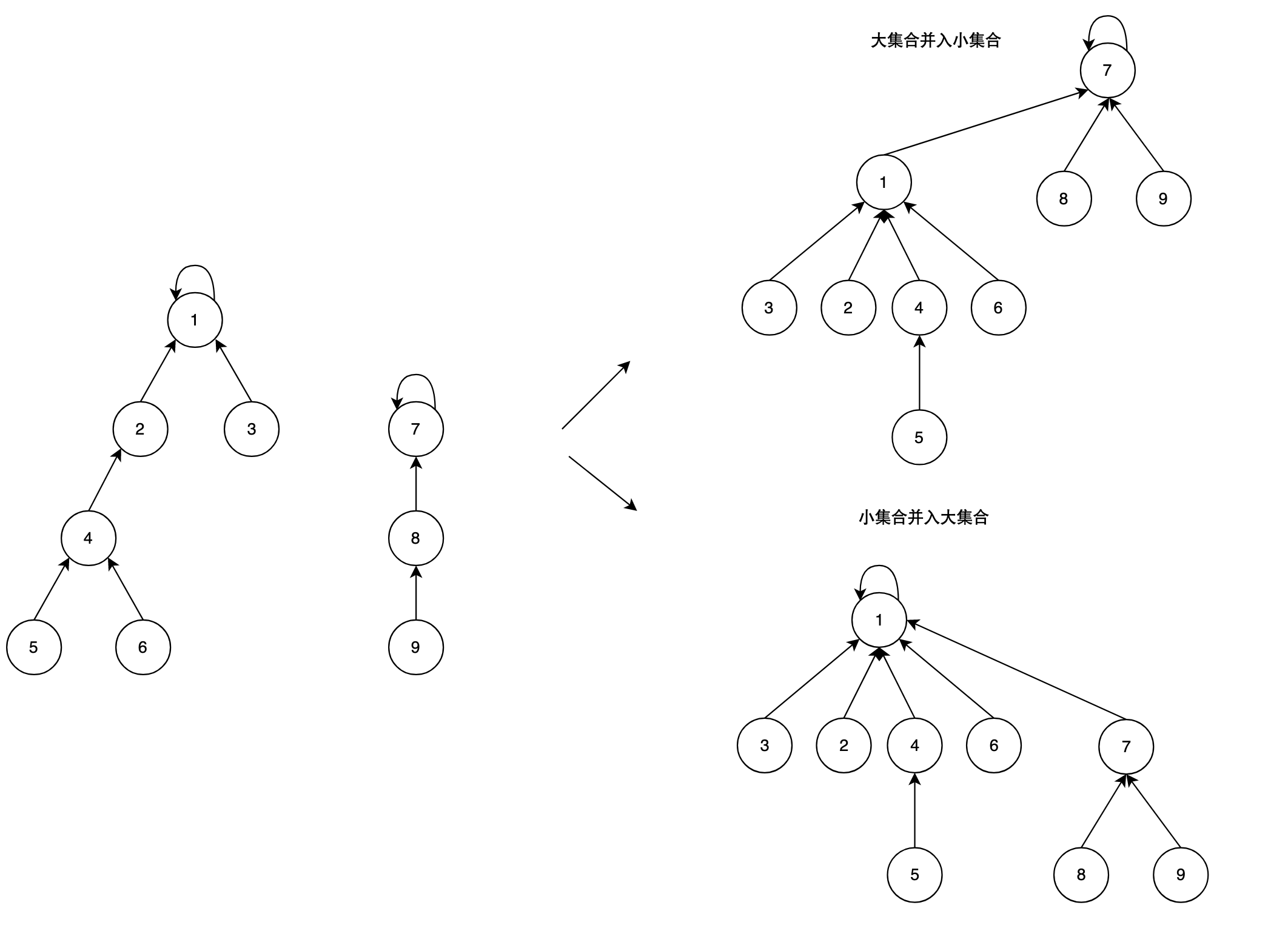
这两种不一样的合并结果会造成效率上的差异。例如大集合并入小集合,大于等于3层的节点个数是5个;小集合并入大集合,大于等于3层的节点个数是3个。明显后者合并后的集合查找效率更高。
按秩合并
按秩合并就是将小集合并入大集合(高度)。
步骤:
- 用一个数组
size[i]存储值为i的节点对应的子树中的元素个数。- 默认将
x并入y,也就是说默认x中的元素数量更小。
- 默认将
- 初始化:将
size[]元素置为1,因为每个节点都是一个集合,元素个数是1。 - 用
find()得到两个集合的根节点的值x和y。- 如果相等,则说明
x在y的集合中,则无需合并。 - 否则就要合并。
- 如果相等,则说明
- 合并步骤:
- 如果
x中的元素数量更多,即size[x]>size[y],那么将x和y的值交换,以符合预先设定。 - 将
x并入y,即f[x] = y。 - 更新大集合
y的size,即size[y] += size[x]。
- 如果
代码:
memset(size, 1, sizeof(size));
void unionset(int x, int y)
{
x = find(x), y = find(y);
if (x == y) return;
if (size[x] > size[y]) swap(x, y);
f[x] = y;
size[y] += size[x];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
实际上,只要对一个集合中的所有元素查找一遍,那么这个树就只有2层,这样再对两个集合合并时,最多也只有2层,即使不严格地满足,只要大部分节点执行了路径压缩,那么按秩合并就没有很大的意义。
按秩合并和路径压缩都是优化并查集的方法,它们的目的都是减少查询时的路径长度,提高查询效率。但是它们也有一些缺点:
- 按秩合并会增加合并时的判断和赋值操作,可能会降低合并的效率。
- 路径压缩会破坏树的结构,导致秩不再准确反映树的高度,可能会影响按秩合并的正确性。
- 路径压缩和按秩合并同时使用时,时间复杂度接近O(1),但是实现起来比较复杂,需要维护额外的数组来记录秩。
因此,在选择使用哪种优化方法时,需要根据具体的问题和数据规模进行权衡。
时间复杂度
接近 O ( 1 ) O(1) O(1)。
如上所述,只要大部分节点执行了路径压缩操作,那么后续再对其查找时,时间复杂度是 O ( 1 ) O(1) O(1)。
参考资料
相关题目
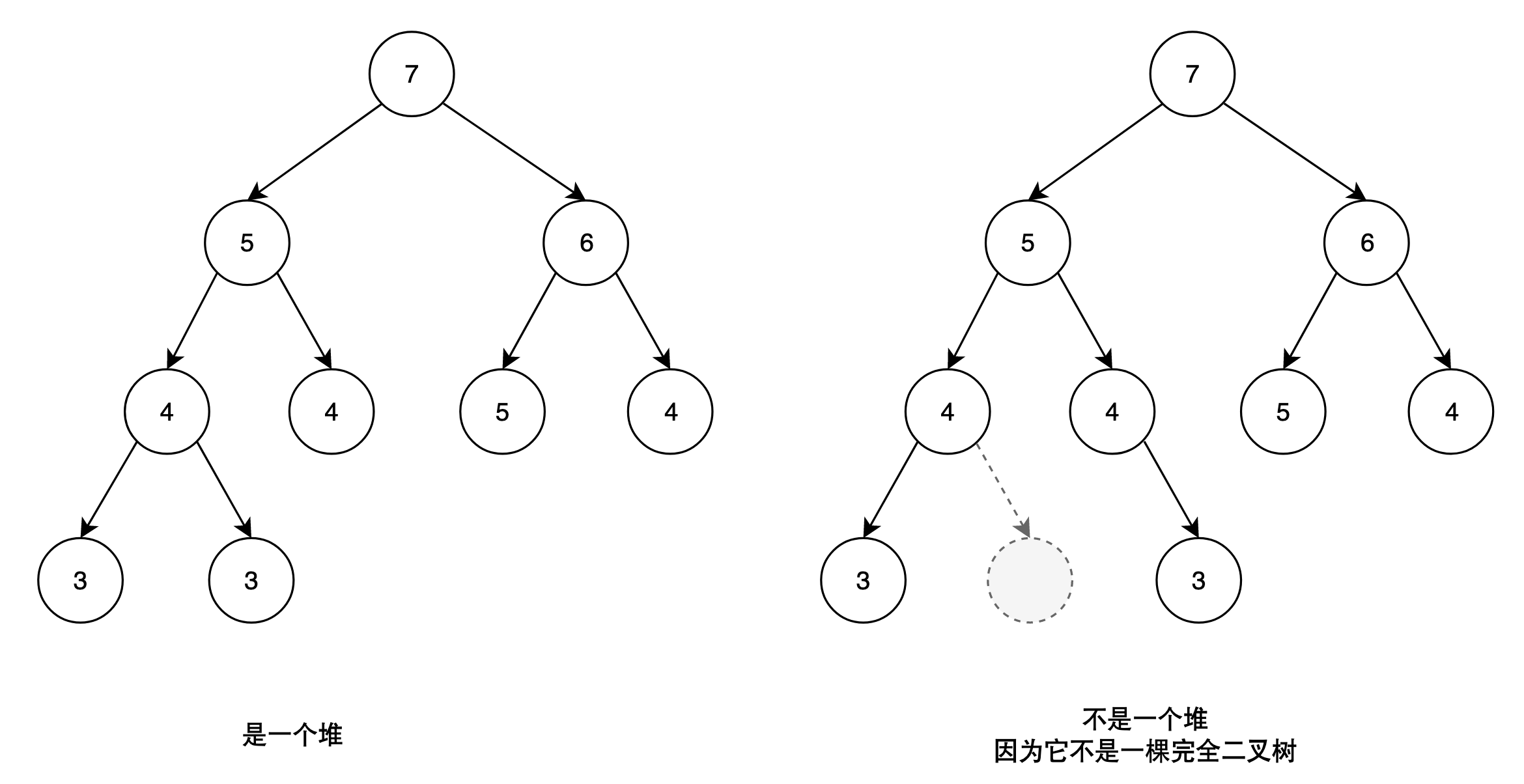
堆
堆是一种用数组存储的数据结构,它是一棵完全二叉树。
默认以大根堆为例。
稍后请注意“完全二叉树”带来的巨大力量。
堆的性质
-
结构特性:满足完全二叉树的性质:底层节点可能铺不满,但一定是从左到右依次排列的。(这个性质是修复堆至关重要的依据)
-
偏序特性:每个元素的父节点的值总是比它的所有子节点的值更大。则根结点的值是所有元素中最大的。注意:并未要求同一层的节点具有大小关系。
从上面这句话可以推出:大堆的堆顶元素(下标为0)一定是所有元素中值最大的。
注意:堆中的元素并不一定是有序的,只要满足第一个性质则为小/大堆
堆的特点能让我们快速找到这个集合中的最值,只要直接取出堆顶元素,即下标为0的元素即可。
-
在物理结构上,堆是用数组存储的。
-
在逻辑结构上(如何写代码和记忆步骤),堆是用完全二叉树存储的。
堆存在的意义?
有一类算法问题的共性特征在于需要将一组数据维护好,以高效地支持针对这批数据的各种操作。针对这类问题,算法设计的核心就是将数据维护成某种精心设计的结构。设计优良的数据结构不仅能高效支持针对数据的查询和更新操作,而且在数据持续进入和离开的情况下,仍然能够以较低的代价维护其特定的结构,以高效支持后续的数据查询和更新操作。–《算法设计与分析》 黄宇
言外之意,堆的实现能够使得数据的查询和插入都能以很低的代价完成,即使破坏了原有的部分结构,也能以很低的代价修复。
堆的抽象(逻辑)维护
查询、删除和插入元素,会破坏堆的两个特性,而堆的两个性质恰好能使得它的性质能够快速修复。
堆的修复
堆的偏序特性使得堆顶一定是这个集合中的最大值,当最值被取走之后,堆的偏序特性和结构特性都被破坏。这两个特性是两个独立的概念,它们之间没有相互影响。也就是说,修复结构特性不会破坏偏序特性,反之亦然。
一般来说,先修复结构特性比较容易,因为只需要把堆顶的元素和最后一个元素交换,然后删除最后一个元素,就可以恢复堆的完全二叉树的形状。而修复偏序特性需要进行下沉操作,即把堆顶的元素和它的较大的子节点交换,直到它不再小于任何子节点。这个过程可能需要多次比较和交换,而且要考虑左右子节点的大小关系。
修复结构特性:
只要将底层最右边的元素取出,放在堆顶即可完成堆结构特性的修复。因为堆是一棵完全二叉树,底层元素是从左到右依次排列的,取出最右边的元素后它依然是一棵完全二叉树。
修复偏序特性:
修复了结构特性后,现在面对的就是一棵满足堆结构的二叉树,它的左右子树都是一个合法的堆,但是它的根节点和它的孩子的值可能不满足偏序特性(即父节点值更大),因为现在的根节点是原本底层最右侧的元素。
- 比较父节点和孩子节点的值。
- 如果父节点的值更大,满足偏序特性,不用处理了。
- 如果某一个孩子节点的值更大,交换孩子节点和父节点的位置,则满足偏序特性。
- 由于“交换操作”可能会将原本的父节点下沉到它的子树,对于这棵子树而言,原本的父节点就是新元素,它可能不满足偏序特性,则递归地执行上述修复过程,直至修复到根节点为止。
时间复杂度
由步骤的描述可知,每修复一次,操作的对象都会下沉一层,而堆是一棵完全二叉树,那么能够较为精准地以树的高度描述时间复杂度:高度为 l o g n logn logn,每层最多修复2次,为 O ( 1 ) O(1) O(1),整体堆的修复时间复杂度是 O ( l o g n ) O(logn) O(logn)
堆的构建
将集合中的元素组织成一棵满足堆结构特性的二叉树是很容易的,所以堆的构建大部分成本在于维护堆的偏序特性。
作为一个计算机专业学生,或者看到这篇文章,已经说明读者已经具备计算机的基本素养,那么对于若干个规模不断缩小但性质不变的子问题,应该立刻想到用递归解决。
假设我们眼前的完全二叉树中的每个节点都是杂乱无章的,对于每棵子树,我们都要根据根结点和孩子节点值的大小关系调整位置。
- 从堆顶,也就是根节点开始构建堆。一个堆结构的左右子树必然是堆结构。如果堆的左右子树均为一个合法的堆,那么最多只是根结点局部不满足偏序特性。只要进行一次修复堆的操作,即可完成堆的构建。
- 构建堆结构的左右子树,方法是利用递归以它们为根结点构建为一个合法的堆。
递归往往能在思维上简化理解和定义数据的成本,因为问题规模不断缩小且性质不变,对于人而言可能非常繁杂,但是代码往往很简洁,剩下的就交给机器吧。
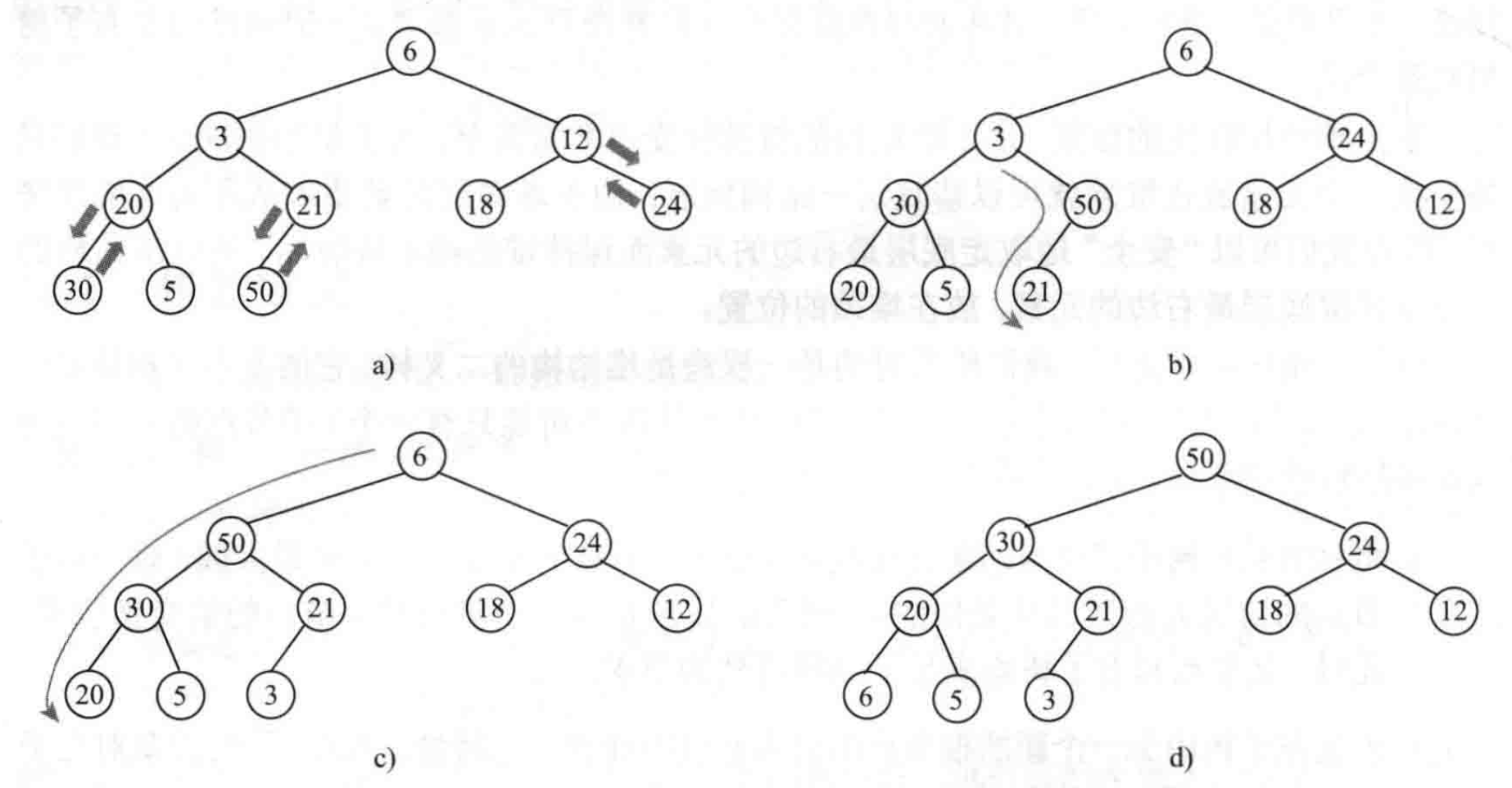
for (int i = n / 2; i; i--) down(i);
- 1
时间复杂度

如果不清楚Master定理,可以暂时不用关心。

图片和复杂度分析过程来源于《算法设计与分析 第二版》 第14章 --黄宇
我们在分析递归算法的时间复杂度时,常常用「决策树」来表示递归的过程,恰好堆的结构特性天然支持了良好的数据处理方式,即决策树。这样我们就能在逻辑上以二叉树同时分析时间复杂度和各种操作的流程。
堆的实现
由于使用数组实现堆(完全二叉树),那么父子节点下标有如下关系:
- Parent = i
- L_CHILD = 2*i
- R_CHILD = 2*i+1
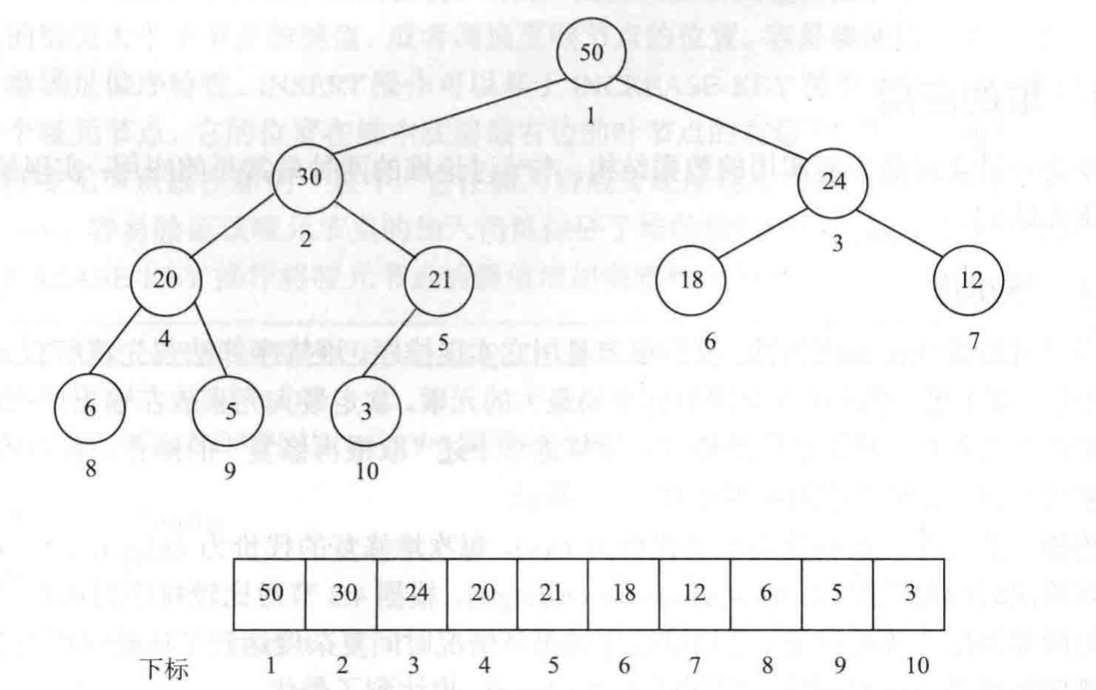
- 数组
h[N]保存元素。 size记录元素个数。
堆的操作:
- 向下调整(down)
- 向上调整(up)
- 以下操作都可以用down和up组合完成:
- 求最值
- 删除堆顶元素
- 插入元素
- 删除任意元素
- 修改任意元素
向下调整(down)
在上一小节「堆的构建」中提到,在将元素组织为一棵完全二叉树之后,使用递归从根节点开始向下修复堆的偏序特性。在每一次修复过程中,最多比较2次,即父节点和两个孩子节点之间比较,将三者较大的元素放在父节点的位置上,这一次修复就算完成了。但是父子节点之间的交换可能会影响下一层子树的偏序关系,因此继续递归地处理下一层。
maxi表示三者中的最大值的下标。x表示当前父节点的下标。
步骤如下:
- 将父节点的下标赋值给
maxi。 - 在保证孩子存在的前提下,分别判断左右孩子的值,将较大值的下标赋值给
maxi。 - 判断父节点的下标和
maxi是否相等:- 相等:说明父节点一直是最大的,到此为止,不用再调整了。
- 不相等:说明孩子节点更大,交换父子节点的位置。
void down(int f)
{
int maxi = f; // 父节点的下标
if (f * 2 <= size && h[f * 2] > h[f]) // 若左节点存在且值比父节点大
maxi = f * 2;
if (f * 2 + 1 <= size && h[f * 2 + 1] > h[f]) // 若右节点存在且值比父节点大
maxi = f * 2 + 1;
if (maxi != f) // 如果执行了if,则max会被改变,说明要交换
{
// swap(h[f], h[maxi]);
heap_swap(f, maxi); // 交换后,max的位置就是下一层根节点
down(maxi); // 递归地向下调整
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
当堆顶元素是一个新放进来的元素时,例如取出了堆顶,为了修复堆的结构特性,将堆的最后一个元素放在了堆顶,这个新的根节点的大小可能不满足堆的偏序特性。因此对它向下调整。
简单地说,向下调整就是子树根节点位置的值被上一层交换了,然后变的比原来更小了,那么它的位置应该是在更下边的位置。
向上调整(up)
向上调整的方法同向上,如果子节点的值更大,那么它正确的位置应该在更上边,在保证父节点存在的前提下,将子节点和它的父节点交换。这个过程使用迭代实现更简单。
void up(c)
{
while (c / 2 && h[c] > h[c / 2]) // 父节点存在且子节点值更大
{
// swap(h[c], h[c / 2]);
heap_swap(c, c / 2);
c >>= 1; // 向上迭代
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当然down用迭代实现也是非常简单的,只不过这里用递归更能体会到从根结点往下不断调整,规模缩小的过程。
时间复杂度
向上调整和向下调整的次数都取决于二叉树的高度,而每次调整都会跨越一层,那么它们的时间复杂度都是 O ( l o g n ) O(logn) O(logn)。
带映射的堆
平常的堆相关的题目只要使用上面的swap(被注释)直接交换即可,这里预先学习一下带映射关系的堆,以便后续实现堆优化的Dijkstra算法。
- 数组
ph[k]存储第k个插入的点在堆中的位置(数组的下标)。 - 数组
hp[k]存储堆中下标是k的元素是第几个插入的。
如何记忆:根据描述,"堆"在后面,"h"就在后面。
堆优化的Dijkstra算法需要维护两个相互映射的数组,一个是dist[],用来存储每个节点到起点的最短距离,另一个是heap[],用来存储每个节点在堆中的位置。这和hp[]与ph[]的含义是一样的。
在图中,ph[k]和hp[k]表示的是同一条边的不同方向:
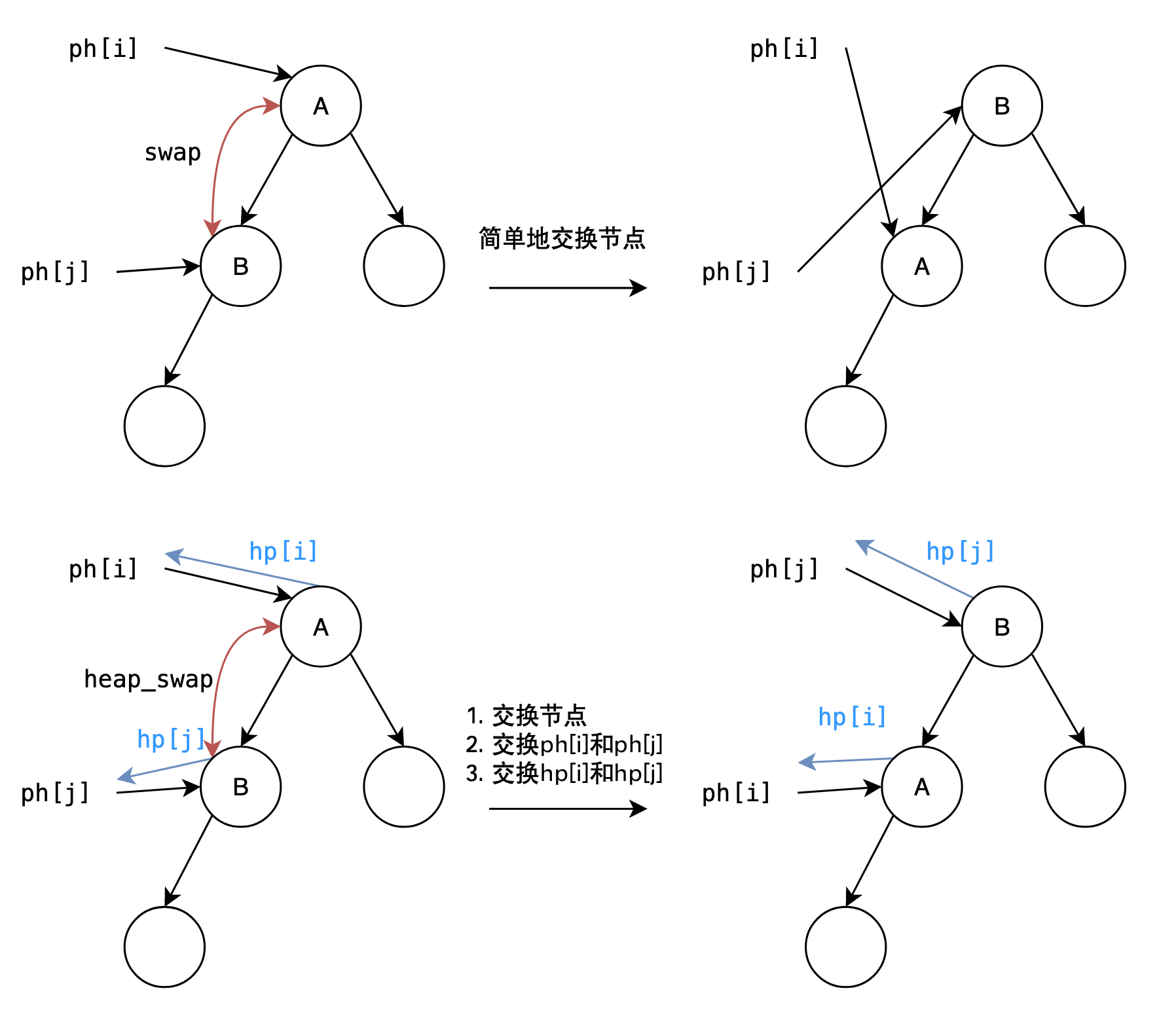
void heap_swap(int a, int b)
{
swap(ph[hp[a]], ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
- 1
- 2
- 3
- 4
- 5
- 6
通过图示可以简单地将ph[]和hp[]认为是一对互相找回对方的过程,例如第一条语句ph[hp[a]]的意思是通过hp[a]找回ph[a](是图中蓝色的箭头)。
插入
- size+1。
- ph[]和hp[]建立一个新的映射关系,下标使用
k保存,表示第k个插入的元素。 - 插入。
- 从插入的位置向上调整。
void insert(int x)
{
size++;k++;
ph[k] = size, hp[size] = k;
h[size] = x;
up(size);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
获取和删除最值
- 将二叉树最后一个位置和堆顶元素交换。
- size-1。
- 从根结点向下调整。
int getMax()
{
return h[1];
}
void removeMax()
{
heap_swap(1, size);
size--;
down(1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
删除或修改第k个元素
删除或修改某个元素,首先要找到这个元素在堆中(数组)的位置。然后再删除或修改。
删除:
- 通过
ph[k]找到元素在数组中的下标idx。 - 交换
k位置和最后一个元素的位置。 - size-1。
k位置可能在树的中间,删除后它可能会影响它上面或下面集合的偏序结构,这里分别进行了向上和向下调整,实际上只会进行一个操作。
修改:
- 通过
ph[k]找到元素在数组中的下标idx。 - 将该位置的值改为
x。 k位置可能在树的中间,修改后它可能会影响它上面或下面集合的偏序结构,这里分别进行了向上和向下调整,实际上只会进行一个操作。
void remove(int k, int x)
{
int idx = ph[k];
heap_swap(idx, size);
size--;
down(k), up(k);
}
void change(int k, int x)
{
int idx = ph[k];
h[idx] = x;
down(k), up(k);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
相关题目
参考资料
-
《算法设计与分析 第二版》黄宇
哈希表
哈希表是一种以键值对形式存储数据的结构。
使用场景:把一堆范围比较大的数据映射到 0 0 0~ 1 0 5 / 1 0 6 10^5/10^6 105/106范围中。一个极端的例子:一个集合中只有两个元素1和 1 0 9 10^9 109,但如果要用数组对应下标地存储,数组要开很大很大,却只用到了2个有效空间,哈希表的一个作用就是使映射位置能相对集中。
算法题中哈希表一般只有添加和查找,若要删除,可以用标志位标记。
范围被缩小以后,有可能会造成若干个原始值通过哈希函数映射到相同的位置,因此要处理这种冲突情况。
开散列法
开散列法(open hashing)即拉链法,在新范围对应的数组中并不存储元素,而是链接一个链表存储元素,一旦发生哈希冲突,就将元素链接到链表中,作为“同一类”,那么链表的头部作为数组元素,可以记录这一类元素的信息。
主要有两个操作:
- 计算哈希值。
- 在哈希值对应的链表中依次遍历、比较。
不论是查找元素是都存在于集合中,还是插入新元素,都要基于这两个操作实现。
其中,哈希思想体现在:建立一个大小等于新范围的数组进行映射。
离散化是一种特殊的哈希思想,它特殊在“保序”,且要使得哈希值单调递增。
哈希函数
哈希函数是计算哈希值,也就是映射位置的方法。例如在学校拿外卖通常用尾号来映射同学的身份,尾号本身范围很大,但映射到某一栋楼的人数,范围就缩小了。
既然哈希函数一般具有范围缩小的性质,那么这个函数的值域就不应该超过这个范围。因此一般使用模运算作为哈希函数,例如范围是
N
N
N,那么哈希函数就是:
f
(
x
)
=
x
m
o
d
N
f(x) = x \ mod\ N
f(x)=x mod N
对于这个模运算,它的值域是
[
0
,
N
−
1
]
[0, N - 1]
[0,N−1]。
h[N]:存储哈希值映射(槽),它储存着这个链表中的元素个数。e[N]:存储链表元素。ne[N]:存储链表元素的next指针。idx:记录链表元素最新位置。
插入
- 计算哈希值。
- 头插到链表中,插入步骤同链表。
void insert(int x)
{
int pos = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[pos];
h[pos] = idx++;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
值得注意的是,C/C++中的模运算可能是负数,但是数学上模运算一定是非负数。例如10%-3在C++中的结果是-1,但正确结果是2,因此这里在模N之前加上了N,这对于正数是不影响的,模运算满足分配律:
(x % N + N) % N
= (x % N) % N + N % N
= x % N + N % N + N % N
= x % N + 0 + 0
= x % N
- 1
- 2
- 3
- 4
- 5
诸如Python等语言,x % N的结果就是正确的。
对于负数,一定要先模再加再模,模运算本身是一个「轮回」的过程,不管数据如何变化,它的值始终会落到值域 [ 0 , N − 1 ] [0, N - 1] [0,N−1]中。
实现循环队列时,就使用了模运算,这就是一种“轮回”的感觉。
查找
- 计算哈希值
pos。 - 遍历以
pos位置为头的链表,查找元素是否存在。
memset(h, sizeof(h), -1);
bool find(int x)
{
int pos = (x % N + N) % N;
for (int i = h[pos]; i != -1; i = ne[i])
if(e[i] == x) return true;
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意,ne[]数组在初始化时将所有元素置为-1,表示NULL。
闭散列法
将所有被映射的元素直接存储在哈希表数组中,若发生冲突,则向后继续探测,直到找到一个未被使用的位置。
线性探测:例如在某元素的哈希值pos的位置上已经被占用了,那么它继续向后探测,pos+1,pos+2…直到找到一个新位置。
显然,这么做会造成冲突率很高,而且会互相影响。经验上的办法是修改哈希函数,也就是让哈希表的长度是提给长度的2~3倍,冲突率就会下降。
查找
假如x的范围是
−
1
0
9
-10^9
−109~
1
0
9
10^9
109,那么定义一个null=0x3f3f3f3f(它比
1
0
9
10^9
109大),表示这个位置未被占用。
-
计算哈希值
pos。 -
如果
pos位置已经被占用且它的值不等于要查找的x。 -
向后探测:pos+1。
- 如果探测到哈希表的最后一个元素,说明已经走到了末尾,此时就要从哈希表的起始位置探测。
-
返回
pos:x元素在哈希表中:返回的是x在哈希表中的下标。x元素不在哈希表中:返回的是x在哈希表插入的下标(应该存储的位置)。
const int N = 200010, null = 0x3f3f3f3f; int h[N]; memset(h, sizeof(h), 3f); int find(int x) { int pos = (x % N + N) % N; while (h[pos] != null && h[pos] != x) // pos位置被占且这个位置不是x { pos++; // 向后探测 if (pos == N) N = 0; // 遇到结尾,回到开头继续探测 } return pos; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
插入
- 计算哈希值。
- 复用find函数,假如插入的元素不存在,那么find函数返回的值这个新元素子在哈希表中的位置,那么直接用返回值插入。
void insert(int x)
{
int pos = (x % N + N) % N;
int newpos = find(pos);
h[newpos] = x;
}
- 1
- 2
- 3
- 4
- 5
- 6
字符串前缀哈希
字符串前缀哈希函数可以把任意长度的字符串映射成一个非负整数,并且发生冲突的概率几乎为零。
回忆:我们使用的任意十进制数字都能用一个关于 1 0 n 10^n 10n的多项式表示,例如 ( 123 ) 10 = 1 × 1 0 2 + 2 × 1 0 1 + 3 × 1 0 0 (123)_{10}=1×10^2+2×10^1+3×10^0 (123)10=1×102+2×101+3×100。
哈希函数
前缀和
字符串前缀哈希是这么做的:取一固定值
P
P
P,将字符串看作一个
P
P
P进制数,字符串的ASCII值是天然的系数,每个字符的
系数
×
权值
系数×权值
系数×权值之和就是字符串的值,即
P
P
P进制数。这个
P
P
P进制数可能很大很大,所以另外取一个较小的固定值
M
M
M,将
P
m
o
d
M
P\ mod \ M
P mod M作为字符串的哈希值。这样就将字符串通过哈希函数映射到了整数。哈希函数:
f
(
s
)
=
∑
i
=
1
n
s
[
i
]
×
P
n
−
i
(
m
o
d
M
)
f(s) = \sum_{i=1}^{n} s[i] \times P^{n-i} \pmod M
f(s)=i=1∑ns[i]×Pn−i(modM)
例如字符串
a
b
c
abc
abc,其哈希函数值(十进制)为
a
P
2
+
b
P
1
+
c
P
0
aP^2+bP^1+cP^0
aP2+bP1+cP0,字符用ASCII码替代,即为
97
×
13
1
2
+
98
×
13
1
1
+
99
×
1
97×131^2+98×131^1+99×1
97×1312+98×1311+99×1。
假设我们有一个字符串"abcde",我们想要计算它的前缀哈希值。我们可以选择一个 P P P进制数,比如p=131,然后把每个字符的ASCII码乘以 P P P的相应次方,然后对 2 64 2^{64} 264取模。这样,我们可以得到:
h[0] = 0
a h[1] = a
ab h[2] = a * p^1 + b
abc h[3] = a * p^2 + b * p^1 + c
abcd h[4] = a * p^3 + b * p^2 + c * p^1 + d
abcde h[5] = a * p^4 + b * p^3 + c * p^2 + d * p^1 + e
- 1
- 2
- 3
- 4
- 5
- 6
这样,我们就得到了所有字符串的哈希值。
p[i]:保存前缀和,在预处理中初始化。默认p[0]的值为1,因为它是乘数不能为0。h[i]:保存以s[i]字符结尾的字符串的哈希值。s[i]:存储字符串。
对于每一个以s[i]字符结尾的字符串,它的P进制数依赖于以s[i-1]字符结尾的字符串的哈希值,它已经被处理过,查表可得。例如"abc"依赖于"ab":
ab h[2] = a * p^1 + b
abc h[3] = a * p^2 + b * p^1 + c
后者相比前者只需加 p^1 + c
- 1
- 2
- 3
有以下递推关系:
h
[
i
]
=
h
[
i
−
1
]
×
P
+
s
[
i
]
h[i] \ = \ h[i-1]\ ×\ P\ +\ s[i]
h[i] = h[i−1] × P + s[i]
typedef unsigned long long ULL;
const int P = 131, N = 100010;
ULL p[N], h[N], s[N];
int n;
// 预处理 哈希值的前缀和
void init()
{
p[0] = 1, h[0] = 0;
for (int i = 1; i <= n; i++)
{
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + s[i];
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意:
- 特别地,将h[0]设置为0,不作为有效值。因为使用它会造成哈希冲突,例如x字符的哈希值是0,那么字符串"xx"、“xxx”、“xxxx”…这些字符串的哈希值都是0。
- P进制多项式中的 P n P^n Pn项(权值)通过迭代累乘可以实现。
区间和
如果我们想要计算某个子串的哈希值,比如"bcd",我们只需要用h[4]-h[1]*p^(4-2+1):
a h[1]*p^3 = a * p^3
abcd h[4] = a * p^3 + b * p^2 + c * p^1 + d
- 1
- 2
得到:
b * p^2 + c * p^1 + d
- 1
恰好是"bcd"子串的哈希值。
于是得到区间和公式:
h
[
l
,
r
]
=
h
[
r
]
−
h
[
l
−
1
]
×
P
r
−
l
+
1
h[l,r] = h[r] - h[l-1] × P^{r-l+1}
h[l,r]=h[r]−h[l−1]×Pr−l+1
其中l和r是子串的起始和结束位置。所以,对于"bcd",我们有:
h[2,4] = h[4] - h[1] * p^(4-1+1)
= h[4] - h[1] * p^4
- 1
- 2
这就是"bcd"的哈希值。可以看到,这个方法很快就可以计算出任意子串的哈希值,而不需要遍历整个字符串。
// 子串s[l, r]的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
- 1
- 2
- 3
- 4
- 5
由于 P P P的值可能是131或13331,字符串的 P P P进制数的十进制表示起来可能含有数个个 P P P的若干次幂的和,它会是一个很大很大的数,然后对 2 64 2^{64} 264(这就是那个较小的数 M M M)取模。 M M M的大小对应着C++中
unsigned long long,那么使用它存储这个很大的哈希值时就不用担心溢出问题,因为unsigned long long数据的溢出相当于对 2 64 2^{64} 264取模。因此使用了
unsigned long long存储数据,就默认执行了取模操作。
时间复杂度
计算前缀和: O ( N ) O(N) O(N)
查询区间和: O ( 1 ) O(1) O(1)
哈希冲突
当不同字符串通过哈希函数得到相同的哈希值,就是哈希冲突(哈希碰撞)。
解决哈希冲突的方法(上述已实现):
- 保证 P P P和 M M M互质。
- 通常情况下,
P
P
P是一个质数,它的值一般是
131或者13331可以使得哈希值的分布更均匀,避免一些特殊的输入导致哈希值重复。 P P P的大小也要根据字符串的长度和字符集来选择,一般来说, P P P越大,哈希值越分散,冲突越少。131和13331是一些经验上比较好的选择,但并不是唯一的选择。 -
M
M
M通常取大整数
2
64
2^{64}
264,哈希值设置为
unsigned long long,超出范围则自动溢出,等价于取模。



