
[Python爬虫实战2]爬取济南安居客网站上所需街区的二手房平均房价数据_安居客二手房爬取
赞
踩
一、项目简介
有20w的济南用户地址信息(所在区县+街道),用济南市安居客网站(https://jinan.anjuke.com/sale/)查找每个用户所在街道的二手房房源信息,并求出该街道下的所有二手房的平均房价,即xxx元/㎡。
最终输出按用户地址文件的原顺序(不要过滤也不要打乱顺序)
输出格式:工作地经度,工作地纬度,居住地经度,居住地纬度,区县,街道,房价
二、安居客网页分析
以“山东省济南市历城区东风街道”中的“东风街道”搜索为例,提示:在安居客想要按照街道名搜索房源时最好不要加区县名,因为会弹出整个区的所有信息,与街道没多大关系,影响数据质量
1、整体分析
观察下面图片,可以看到搜索结果的第一页链接为https://jinan.anjuke.com/sale/rd1/?q=搜索内容
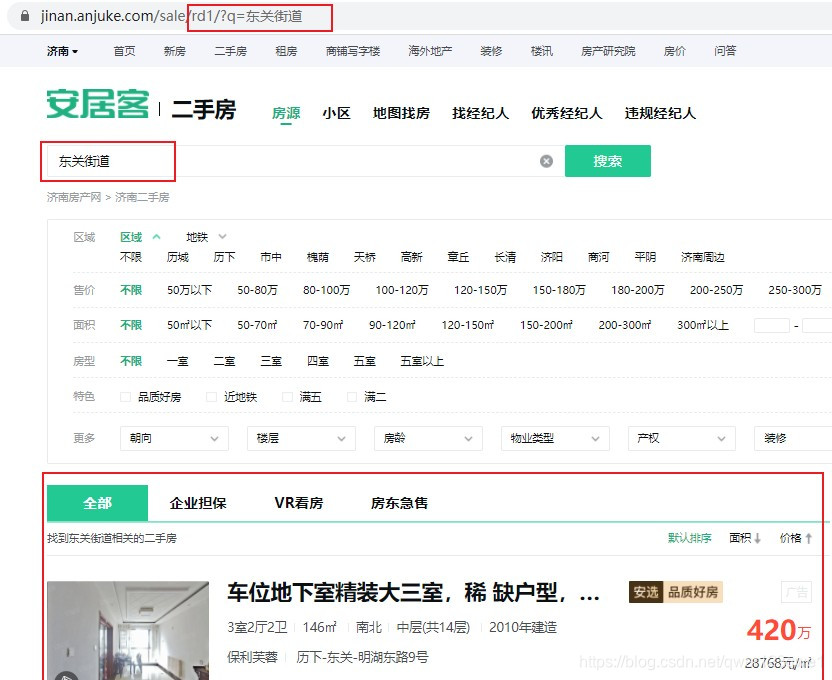
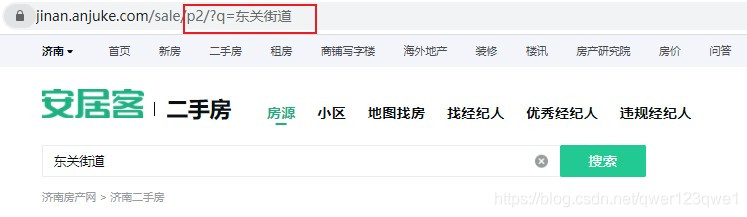
第二页开始就有规律:https://jinan.anjuke.com/sale/p页数/?q=搜索内容
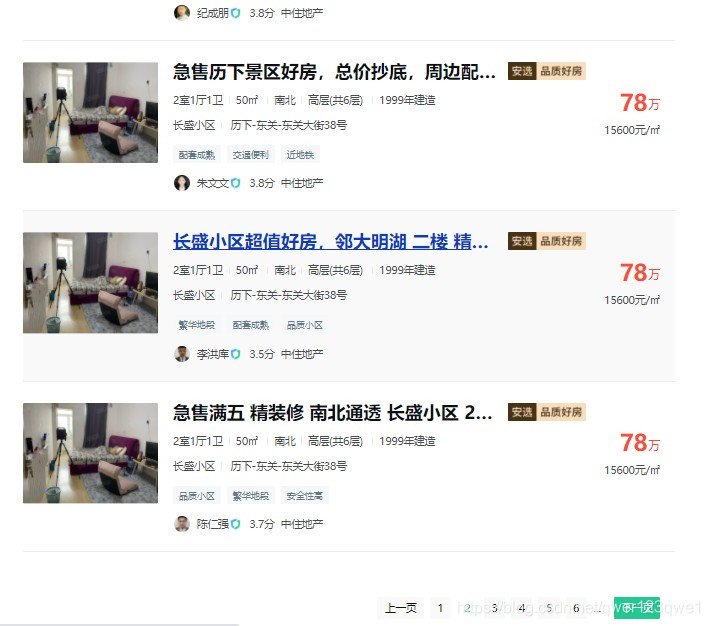
每一个结果页面最多可以存放60个房源信息,可以点击’下一页’查看剩下的搜索结果
2、细节分析
2.1提取一个页面所有的房源信息
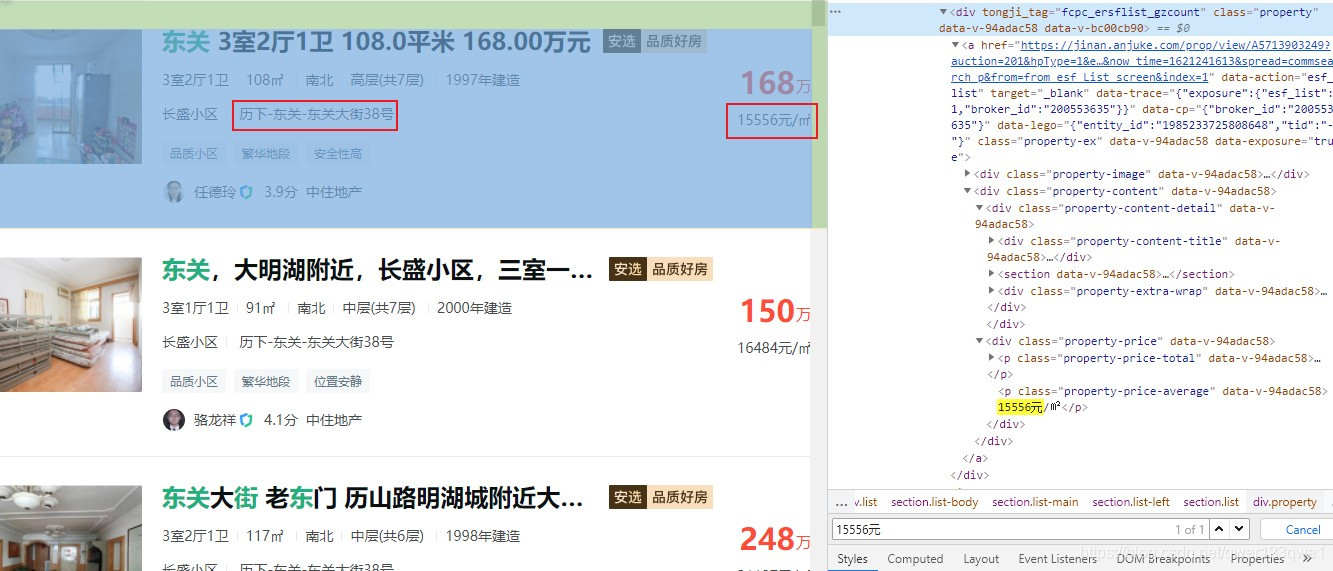
查看源代码,发现每个房源信息是以div class="property"标签包装的,所以我们可以使用BeautifulSoup中的find_all方法来获取一个页面中的所有房源信息
bs = BeautifulSoup(response.text, 'html.parser')
houses = bs.find_all('div', class_="property")
- 1
- 2
2.2提取每个房源信息中的信息
根据需求,我们需要爬取每个房源的平均价格和具体地址,这里爬取地址是为了检查使用街道名搜索出来的房源信息是否是该区县的,因为其他区县也可能有这个街道名。
查看源代码,可以在源代码中使用Ctrl+F搜索关键字快速定位到我们需要的标签位置
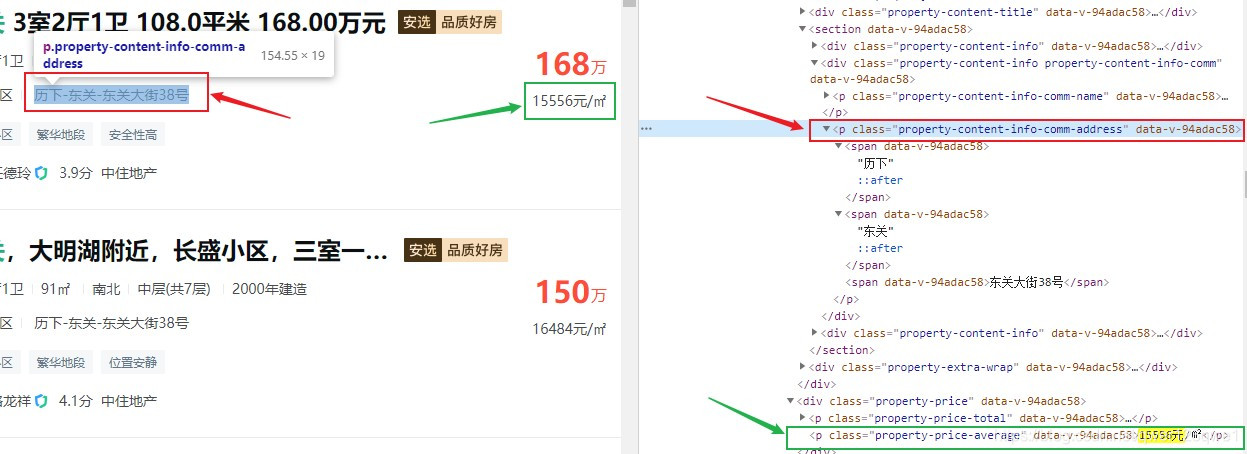
为了从class="property"标签只取出我们需要的信息,我使用正则表达式查找每个item中指定的字符串(平均价格和所在地址)
# 平均价格
findAveragePrice = re.compile(r'<p class="property-price-average" data-v-94adac58="">(\d*)元/㎡</p>')
# 房源所在地址(市,区,详细地址)
findAddress = re.compile(r'<p class="property-content-info-comm-address" data-v-94adac58="">(.*?)</p>')
for item in houses:
# 根据正则表达式求出房源的地址
find_Address = re.findall(findAddress, str(item))[0]
# 为避免模糊查询的可能,还判断所查找的街区是否与房源地址一致,若一致,则加入价格
prices = []
if street in find_Address:
price = re.findall(findAveragePrice, str(item))[0]
print(find_Address, price)
prices.append(float(price))
average_price = np.mean(prices)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.3如何爬取下一页的房源信息
我们可以发现,安居客搜索结果页面不会显示出一共检索出了多少页面或者检索出了多少条信息。这样我们在写url时有难度,不好判断一共需要多少个url链接,是一大难点
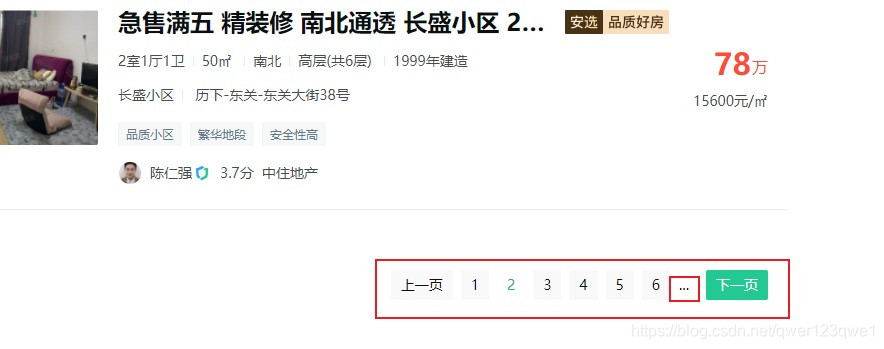
那我们就先对比看看有没有下一页的源代码对比

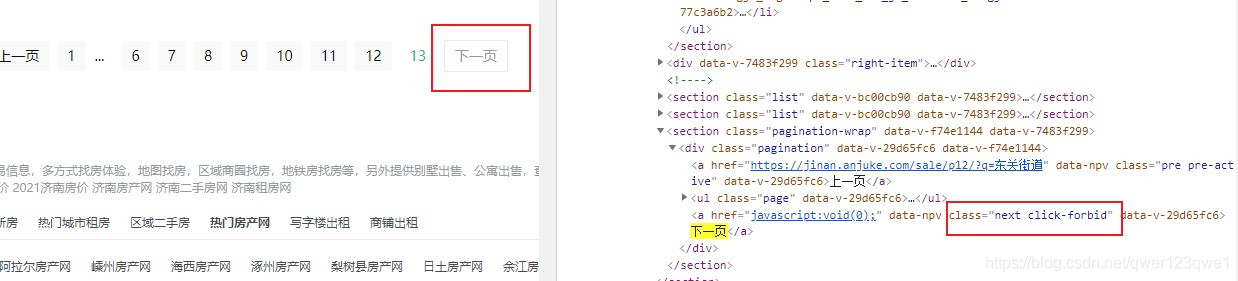
可以发现,如果还有下一页,那么下一页按钮对应的class=“next next-active”;如果当前页面是最后一页,即没有下一页时,此时下一页按钮对应的class=“next click-forbid”,所以我们只需要判断class是什么即可知道有无下一页,是否请求对应的url
# 判断是否还有下一页
next_page = bs.find_all('a', class_='next next-active')
if len(next_page) != 0:
# 若还有下一页,递归调用
getData(page+1,street,i)
- 1
- 2
- 3
- 4
- 5
三、程序编写
1、数据去重
文件中的数据格式如下截图
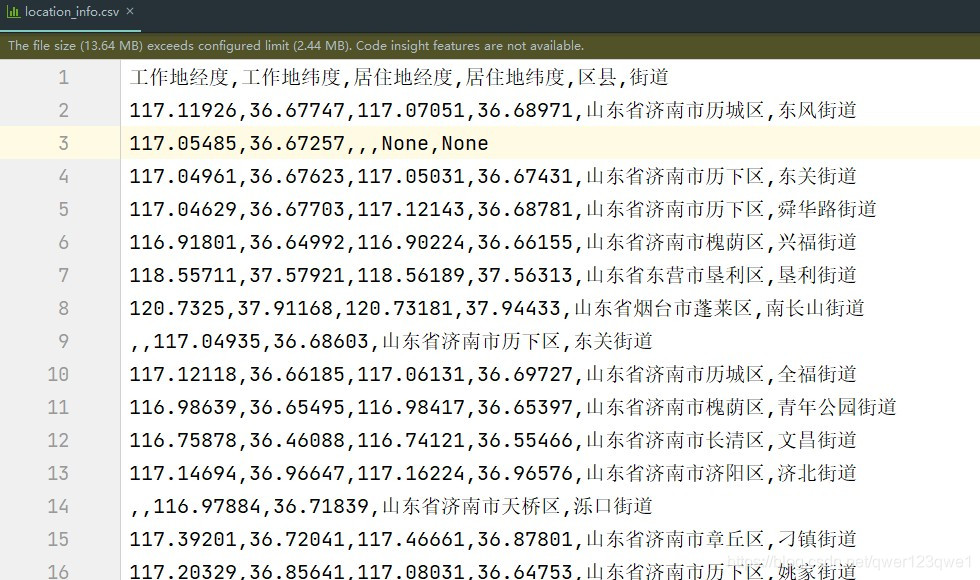
因为20w的济南市用户(里面有部分非济南市居民,不做处理)数据量比较大,而安居客的反扒机制比较厉害(比如过几分钟就会出现滑动二维码);且这20w用户肯定有居住在同一个区县+街道的情况,所以我先对数据进行去重,把去重后的数据存储在一个新的文件中,再根据新文件中的数据爬取每条街道的平均房价(用pandas中的drop_duplicates方法进行去重)
import pandas as pd
info = pd.read_csv('location_info.csv',dtype=str)# 若不加dtype=str,如果文件有数字数据段,有可能会按浮点型处理
df = pd.DataFrame(info)
# 用pd中的drop_duplicates方法进行去重,最好数据都是字符串类型,浮点类型可能会出现小问题
df = df.drop_duplicates(subset=['区县','街道'], keep='first')
df.to_csv('去重后的location.csv', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
2、反爬虫策略
添加随机的user-agent头,还可以设置延迟随机时间
# 35个user-agent user_agent_list = [ \ 'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', \ 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', \ 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)', \ 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', \ 'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1', \ 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11', \ 'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11', \ 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)', \ 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)', \ 'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0', \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", \ "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \ "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \ "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \ "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/535.24", \ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3、使用requests请求网页
# 得到指定一个URL的网页内容
def askURL(url,i):
global Flag
# 模拟浏览器头部信息,向安居客服务器发送消息
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9',
'user-agent': user_agent_list[i % 35]}
try:
print(url)
response = requests.get(url, headers=headers, timeout=30)
return response
except requests.RequestException:
print('请求url返回错误异常')
Flag = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4、爬取并解析网页
根据street字段搜素并爬取内容,page表示爬取去第几个页面了,用于url中,i表示第i条数据使用第i%35个user-agent。除此之外,对askURL函数返回的网页进行解析
def getData(page, street, i): global Flag, prices if page == 1: # 街道的第一页 url = 'https://jinan.anjuke.com/sale/rd1/?q=' + street else: # 街道查询的后续页面 url = 'https://jinan.anjuke.com/sale/p' + str(page) + '/?q=' + street # 请求网页 print("第%d页" % page) response = askURL(url,i) if Flag == 0: if response.status_code == 200: bs = BeautifulSoup(response.text, 'html.parser') # 创建正则表达式对象,表示规则(字符串的模式) # 平均价格 findAveragePrice = re.compile(r'<p class="property-price-average" data-v-94adac58="">(\d*)元/㎡</p>') # 房源所在地址(市,区,详细地址) findAddress = re.compile(r'<p class="property-content-info-comm-address" data-v-94adac58="">(.*?)</p>') # re库用来通过正则表达式查找每个item中指定的字符串(平均价格) houses = bs.find_all('div', class_="property") print(len(houses)) if len(houses) > 0: for item in houses: # 根据正则表达式求出房源的地址 find_Address = re.findall(findAddress, str(item))[0] # price = re.findall(findAveragePrice, str(item))[0] # print(find_Address, price) # prices.append(float(price)) # 为避免模糊查询的可能,还判断所查找的街区是否与房源地址一致,若一致,则加入价格 if street in find_Address: price = re.findall(findAveragePrice, str(item))[0] print(find_Address, price) prices.append(float(price)) else: # 若一个都没有匹配到,说明检索的只是附近的,那么只能显示对应区县 Flag = 2 else: # 如果没有检索到关于此街道的信息,则返回该街道对应区县的房价并做标记 Flag = 2 # 判断是否还有下一页 # 有,则class="next next-active";没有,则class="next click-forbid" next_page = bs.find_all('a', class_='next next-active') if len(next_page) != 0: # 若还有下一页,递归调用 getData(page+1,street,i) else: Flag = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
5、计算每个区县的平均房价
因为有些街道在安居客网站上搜索不到,所以只能显示该街道所在区县的平均房价,即需要提前计算出济南市每个区县的平均房价,这个平均房价不需要求区县的全部房源,求前120个房源信息(每个区一共只能显示50个页面,一页显示60个,这里只取前两页房源的平均值)的平均值即可存储在字典中。
#每个区的url district_url = ['https://jinan.anjuke.com/sale/licheng/', 'https://jinan.anjuke.com/sale/lixia/', 'https://jinan.anjuke.com/sale/shizhong/', 'https://jinan.anjuke.com/sale/huaiyin/', 'https://jinan.anjuke.com/sale/tianqiao/', 'https://jinan.anjuke.com/sale/gaoxind/', 'https://jinan.anjuke.com/sale/zhangqjn/', 'https://jinan.anjuke.com/sale/changqingb/', 'https://jinan.anjuke.com/sale/jiyang/', 'https://jinan.anjuke.com/sale/shanghe/', 'https://jinan.anjuke.com/sale/pingyin/'] district_name =["历城", "历下", "市中", "槐荫", "天桥", "高新", "章丘", "长清", "济阳", "商河", "平阴"] # 使用存储每个市对应的平均房价 district_price = {'钢城': 'None','莱芜': 'None'} # 求每个区的平均房价(取每个区前60*2个的房源的平均房价) def districtPrice(): for i in range(len(district_url)): list_price = [] response1 = askURL(district_url[i]) # 第一页 response2 = askURL(district_url[i]+'p2/') # 第二页 if response1.status_code == 200 and response1.status_code == 200: bs1 = BeautifulSoup(response1.text, 'html.parser') bs2 = BeautifulSoup(response2.text, 'html.parser') # 创建正则表达式对象,表示规则(字符串的模式) # 平均价格 findAveragePrice = re.compile(r'<p class="property-price-average" data-v-94adac58="">(\d*)元/㎡</p>') # re库用来通过正则表达式查找每个item中指定的字符串(平均价格) houses1 = bs1.find_all('div', class_="property") houses2 = bs2.find_all('div', class_="property") for item in houses1: price = re.findall(findAveragePrice, str(item))[0] print(price) list_price.append(float(price)) for item in houses2: price = re.findall(findAveragePrice, str(item))[0] print(price) list_price.append(float(price)) mean_price = np.mean(list_price) mean_price = round(mean_price, 2) # 保留两位小数 district_price[district_name[i]] = mean_price
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
6、引入的文件库,以及一些之前代码没申明的全局变量
from bs4 import BeautifulSoup
import requests
import numpy as np
import pandas as pd
import time
import random
import re
Flag = 0 # 判断在递归时是否出现各种异常
# 若Flag=0,则数据正常,
# Falg=1,则可能是请求异常或者返回的网页数据异常,最终写入表的房价数据为“数据异常”
#Flag=2,则是说明没有检索到这一街道的信息,使用对应区县的房价信息, 最终写入表的房价数据为“该区县房价为“+具体价格
prices = []
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
7、主函数
if __name__ == '__main__': # 先计算出每个区的平均房价 districtPrice() df = pd.DataFrame(columns=['工作地经度', '工作地纬度', '居住地经度', '居住地纬度', '区县', '街道', '平均房价']) # 读取数据到列表 locations = parse() i = 0 for location in locations: # 先把全局变量重新初始化 Flag, prices prices = [] Flag = 0 page = 1 average_price = 0 street = location[5] district = location[4] if 'None' in district: # 区县为None average_price = "None" elif 'None' in street: # 区县不为None,但是街道为None if '济南市' in district: average_price = "该区县房价为" + str(district_price[district[6:8]]) else: average_price = "非济南市" elif '济南市' in district: # 区县和街道都不为None,且是济南市的 if 'None' in street: average_price = "None" else: if '街道' in street: # 取街道的名字即可,加大搜索范围 street = street.split('街道')[0] getData(page, street, i) if Flag == 0: # 数据正常 average_price = np.mean(prices) average_price = round(average_price, 2) # 保留两位小数 elif Flag ==2: # 查询不到该街区的房源,用所在区的房价代替并标记 # district为山东省济南市历下区,则district[6,8]表示 历下 #print(district[6: 8]) average_price = "该区县房价为"+str(district_price[district[6:8]]) else: average_price = "数据异常!!!" else: average_price = "非济南市" df.loc[i] = [location[0], location[1], location[2], location[3], location[4], location[5], str(average_price)] i = i + 1 print("第%d条数据已完成" % i) print("休息%d秒,防止被封ip" % DOWNLOAD_DELAY) time.sleep(DOWNLOAD_DELAY) df.to_csv('part_price.csv', index=False) print("写入完成")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
8、程序运行过程截图和最终文件截图
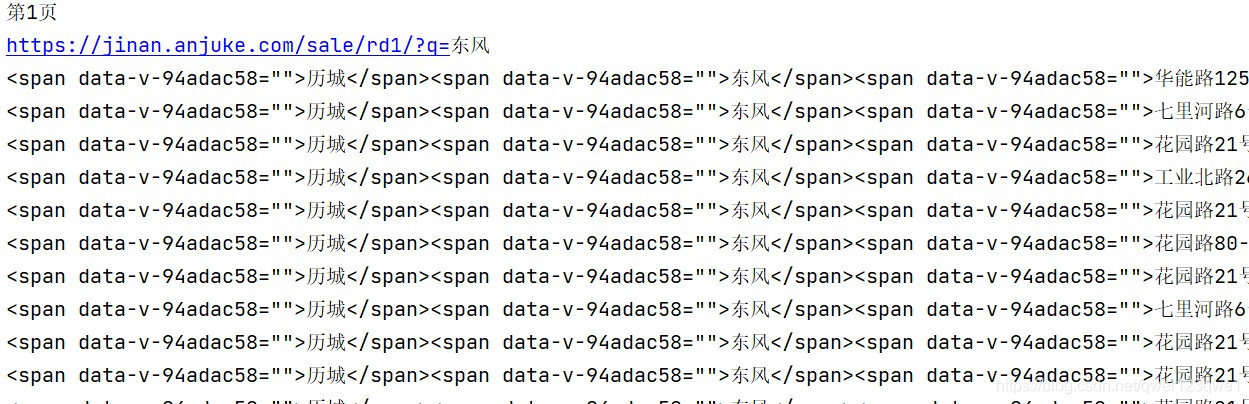
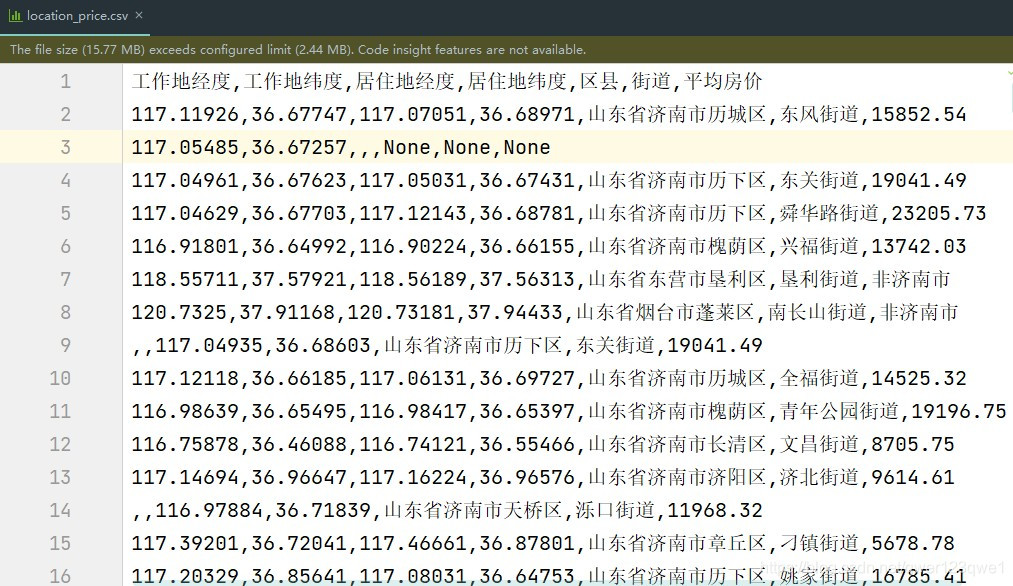
四、后记
本来要学习使用代理ip的,但是发现用了多个user-agent和设置延迟时间以后,跑数据时没有出现验证码的过程,就把买代理ip的钱买下来了,以后有需求了再尝试吧。

