
- 1Python爬虫贵州贵阳景点数据可视化和景点推荐系统 开题报告
- 2408计算机网络错题知识点拾遗_计算机网络试题
- 3linux内核源码分析之虚拟内存_64 位 riscv linux系统虚拟空间永久映射区和固定映射区
- 4区块链课程:python实现交易
- 5Android 实现菜单拖拽排序_attachtorecyclerview
- 6瞎聊机器学习——全方位理解支持向量机(SVM)_支持向量机的概念图
- 7NXP iMX8平台上使用imx-gpu-sdk开发_imx8 open cl
- 8机器学习之特征选择_基于树的特征选择
- 9Stable Diffusion WebUI 生成参数:宽度/高度/生成批次/每批数量/提示词相关性/随机种子
- 10ChatGPT是什么?其本质是什么?
Kubernetes 健康检查之 livenessProbe/readinessProbe_kubernetes livenessprobe
赞
踩

健康检查

一个pod启动了之后,它有可能还在做初始化,这就意味着在初始化的应用进程还不能接受网络流量,所以要去控制一下pod的状态,也就是我还没有就绪,我还不能够接受流量。
有些应用跑着跑着没有响应,出现大量的503,应用实例以及不能够正常工作了,是否需要帮你重启。
tcp stocket 查看某个端口,比如某个应用跑在80端口上面,你只需要去看80端口是否是活着的,你就能够知道它是否就绪了。
但是有时候80端口启动了并不代表我业务正常了,可能应用已经死掉了,那么可以通过HTTP,任何的微服务里面都要开放healthz的健康检查的uri,我们就可以针对uri去做健康检查。

如果这个文件存在,那么会返回code为0,这样就认为健康检查是通过的,如果这个文件不存在,那么这个return code为非0,也就是这次健康检查会失败。

Kubernetes三种探针
k8s支持存活livenessProbe和就绪readinessProbe两种探针,两种探针都支持以下三种方式
一、exec
通过执行shell命令的方式,判断退出状态码是否是0,示例:
- exec:
- command:
- - cat
- - /tmp/healthy
二、tcp
通过TCP请求的方式,是否能建立tcp连接,示例:
- tcpSocket:
- port: 8080
- initialDelaySeconds: 15
- periodSeconds: 20
三、httpGet
通过发起http请求,判断返回结果是否符合预期,示例:
- ...
- livenessProbe:
- httpGet:
- path: /healthz
- port: 8080
- httpHeaders:
- - name: X-Custom-Header
- value: Awesome
- initialDelaySeconds: 3
- periodSeconds: 3
- initialDelaySeconds指定了容器启动后多少秒后进行探测
- periodSeconds指定每隔多少秒进行探测
Liveness 探测
Liveness 探测让用户可以自定义判断容器是否健康的条件。如果探测失败,Kubernetes 就会重启容器。还是举例说明,创建如下 Pod:启动进程首先创建文件 /tmp/healthy,30 秒后删除,在我们的设定中,如果 /tmp/healthy 文件存在,则认为容器处于正常状态,反正则发生故障。
- [root@k8s-master ~]# cat liveness.yml
- apiVersion: v1
- kind: Pod
- metadata:
- name: liveness-pod
- namespace: default
- spec:
- restartPolicy: OnFailure
- containers:
- - name: myapp
- image: busybox
- imagePullPolicy: IfNotPresent
- command: ["/bin/sh","-c","touch /tmp/healthy;sleep 30;rm -rf /tmp/healthy;sleep 3600"]
- livenessProbe:
- exec:
- command: ["test","-e","/tmp/healthy"]
- initialDelaySeconds: 5
- periodSeconds: 5

livenessProbe 部分定义如何执行 Liveness 探测:
-
探测的方法是:通过 test命令检查
/tmp/healthy文件是否存在。如果命令执行成功,返回值为零,Kubernetes 则认为本次 Liveness 探测成功;如果命令返回值非零,本次 Liveness 探测失败。 -
initialDelaySeconds:5指定容器启动 5s之后开始执行 Liveness 探测,我们一般会根据应用启动的准备时间来设置。比如某个应用正常启动要花 30 秒,那么initialDelaySeconds的值就应该大于 30。 -
periodSeconds: 5指定每 5 秒执行一次 Liveness 探测。Kubernetes 如果连续执行 3 次 Liveness 探测均失败,则会杀掉并重启容器。
下面创建 Pod liveness:
- [root@k8s-master ~]# kubectl apply -f liveness.yml
- pod/liveness-pod created
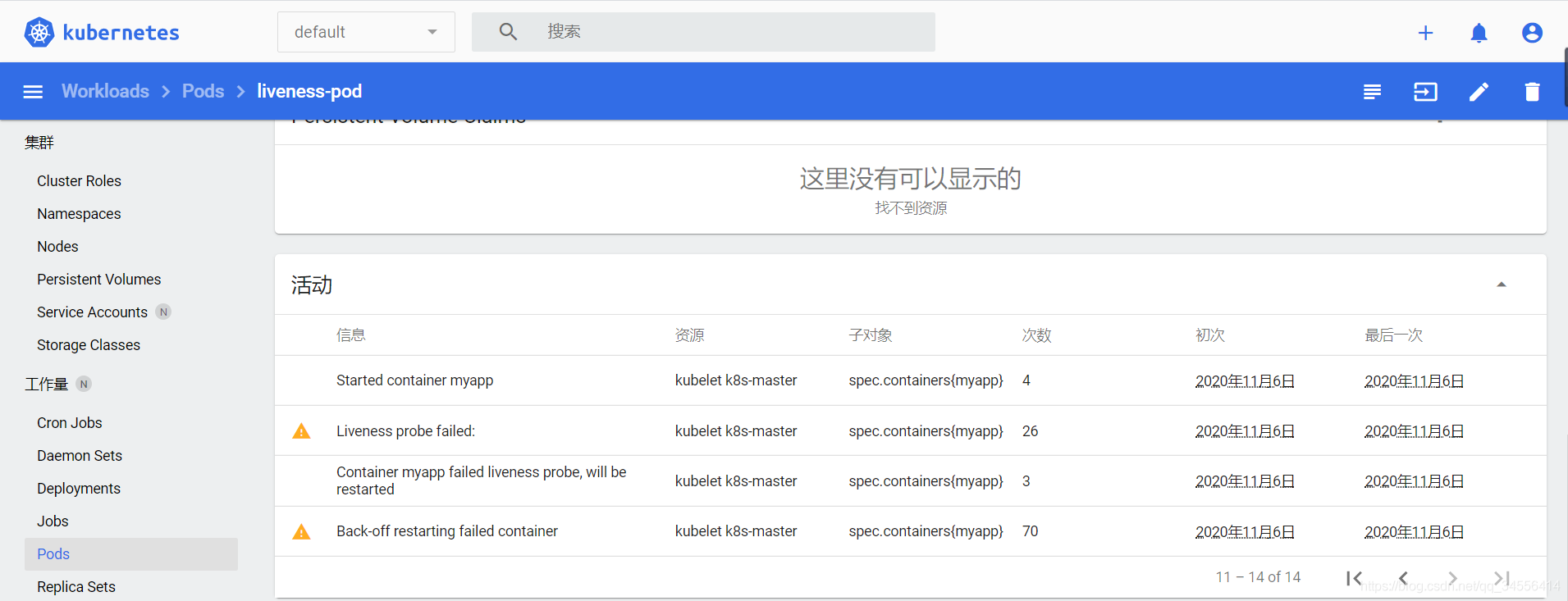
从配置文件可知,最开始的 30 秒,/tmp/healthy 存在,test 命令返回 0,Liveness 探测成功,这段时间 kubectl describe pod liveness 的 Events部分会显示正常的日志。
- [root@k8s-master ~]# kubectl describe pod liveness-pod
- Events:
- Type Reason Age From Message
- ---- ------ ---- ---- -------
- Normal Scheduled <unknown> default-scheduler Successfully assigned default/liveness-pod to k8s-master
- Normal Pulled 12s kubelet, k8s-master Container image "busybox" already present on machine
- Normal Created 11s kubelet, k8s-master Created container myapp
- Normal Started 11s kubelet, k8s-master Started container myapp
35 秒之后,日志会显示 /tmp/healthy 已经不存在,Liveness 探测失败。再过几十秒,几次探测都失败后,容器会被重启。
- [root@k8s-master ~]# kubectl describe pod liveness-pod
- Command:
- /bin/sh
- -c
- touch /tmp/healthy;sleep 30;rm -rf /tmp/healthy;sleep 3600
- State: Running
- Started: Fri, 06 Nov 2020 15:40:59 +0800
- Last State: Terminated
- Reason: Error
- Exit Code: 137 #可以看到退出了,OnFailure : 容器终止运行且退出码不为0时重启
- Started: Fri, 06 Nov 2020 15:39:45 +0800
- Finished: Fri, 06 Nov 2020 15:40:59 +0800
- Ready: True
- Restart Count: 1 #容器重启了1次
- Liveness: exec [test -e /tmp/healthy] delay=5s timeout=1s period=5s #success=1 #failure=3
- Environment: <none>
- Mounts:
- /var/run/secrets/kubernetes.io/serviceaccount from default-token-dfmvc (ro)
- Events:
- Type Reason Age From Message
- ---- ------ ---- ---- -------
- Normal Scheduled <unknown> default-scheduler Successfully assigned default/liveness-pod to k8s-master
- Warning Unhealthy 55s (x3 over 65s) kubelet, k8s-master Liveness probe failed:
- Normal Killing 55s kubelet, k8s-master Container myapp failed liveness probe, will be restarted #可以看到健康检查失败
- Normal Pulled 25s (x2 over 100s) kubelet, k8s-master Container image "busybox" already present on machine
- Normal Created 25s (x2 over 99s) kubelet, k8s-master Created container myapp
- Normal Started 25s (x2 over 99s) kubelet, k8s-master Started container myapp
-
-
- [root@k8s-master ~]# kubectl get pod -o wide
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
- liveness-pod 1/1 Running 3 4m20s 10.244.0.27 k8s-master <none> <none>
除了 Liveness 探测,Kubernetes Health Check 机制还包括 Readiness 探测,下篇博客见。
Pod 健康检查失败
Kubernetes 健康检查包含就绪检查(readinessProbe)和存活检查(livenessProbe) pod 如果就绪检查失败会将此 pod ip 从 service 中摘除,通过 service 访问,流量将不会被转发给就绪检查失败的 pod ,pod 如果存活检查失败,kubelet 将会杀死容器并尝试重启。
节点负载过高
容器内进程端口监听挂掉
SYN backlog 设置过小
健康检查的类型
Kubernetes 为您提供两种健康检查,了解两者之间的差异及其用途非常重要。
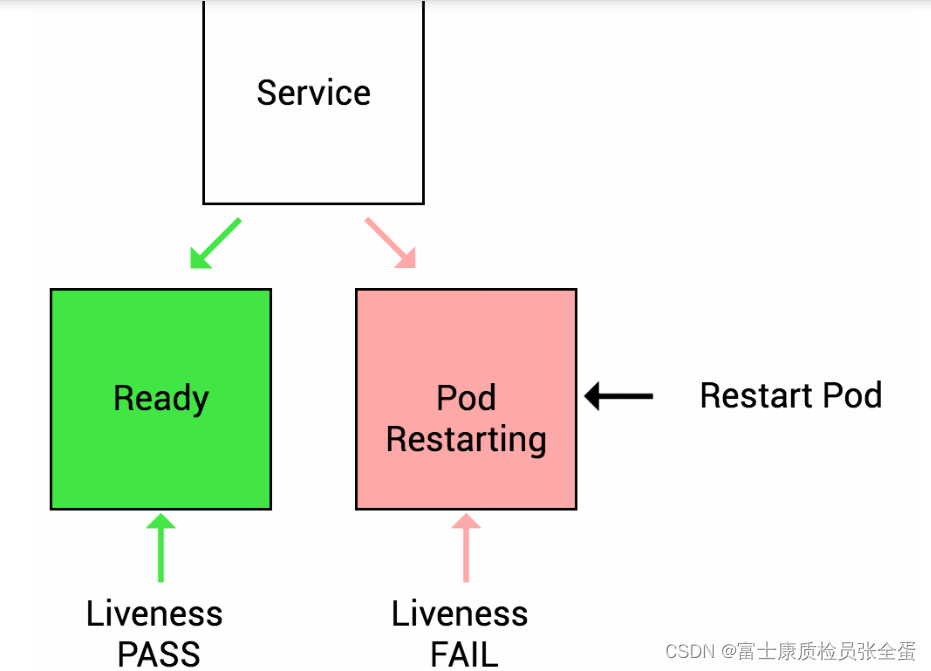
准备就绪
就绪探测旨在让 Kubernetes 知道您的应用何时准备好为流量提供服务。Kubernetes 在允许服务向 Pod 发送流量之前确保就绪探测通过。如果就绪探测开始失败,Kubernetes 会停止向 pod 发送流量,直到它通过。
活力
Liveness probes 让 Kubernetes 知道你的应用程序是活着还是死了。如果你的应用程序还活着,那么 Kubernetes 就不会管它了。如果你的应用已经死了,Kubernetes 会移除 Pod 并启动一个新的来替换它。
健康检查如何提供帮助
让我们看一下准备情况和活跃度探针可以帮助您构建更强大的应用程序的两种情况。
准备就绪
让我们假设您的应用程序需要一分钟来预热和启动。您的服务在启动并运行之前将无法工作,即使该过程已经开始。如果您想扩展此部署以拥有多个副本,您也会遇到问题。新副本在完全准备好之前不应接收流量,但默认情况下,Kubernetes 会在容器内的进程启动后立即开始向其发送流量。通过使用就绪探测,Kubernetes 会等到应用程序完全启动后才允许服务将流量发送到新副本。

活力
让我们想象另一种情况,您的应用程序有一个令人讨厌的死锁情况,导致它无限期挂起并停止服务请求。因为进程继续运行,默认情况下 Kubernetes 认为一切正常,并继续向损坏的 Pod 发送请求。通过使用活跃度探测,Kubernetes 检测到应用程序不再为请求提供服务并重新启动有问题的 pod。
探头类型
下一步是定义测试就绪和活跃度的探针。有三种类型的探测:HTTP、命令和 TCP。您可以使用它们中的任何一个进行活跃度和就绪性检查。
HTTP
HTTP 探针可能是最常见的自定义活性探针类型。即使您的应用程序不是 HTTP 服务器,您也可以在应用程序内部创建一个轻量级 HTTP 服务器来响应活动探测。Kubernetes ping 一条路径,如果它收到 200 或 300 范围内的 HTTP 响应,它会将应用程序标记为健康。否则它被标记为不健康。
您可以在此处阅读有关 HTTP 探测的更多信息。
命令
对于命令探测,Kubernetes 在您的容器内运行命令。如果命令返回退出代码 0,则容器被标记为健康。否则,它被标记为不健康。当您不能或不想运行 HTTP 服务器时,这种类型的探测很有用,但可以运行可以检查您的应用程序是否健康的命令。
您可以在此处阅读有关命令探针的更多信息。
TCP
最后一种探测类型是 TCP 探测,Kubernetes 尝试在指定端口上建立 TCP 连接。如果能够建立连接,则认为容器是健康的;如果不能,则被认为是不健康的。
如果您遇到 HTTP 探测或命令探测无法正常工作的情况,TCP 探测会派上用场。例如,gRPC或 FTP 服务是此类探测的主要候选对象。
您可以在此处阅读有关 TCP 探测的更多信息。
配置初始探测延迟
可以通过多种方式配置探头。您可以指定它们应该运行的频率、成功和失败阈值是多少以及等待响应的时间。有关配置探针的文档非常清楚地说明了不同的选项及其作用。
但是,使用 liveness probe 时需要配置一项非常重要的设置。这是 initialDelaySeconds 设置。
正如我上面提到的,活动探测失败会导致 pod 重新启动。您需要确保在应用程序准备好之前不会启动探测。否则,应用程序将不断重启,永远不会准备好!
我建议使用p99启动时间作为 initialDelaySeconds,或者只取平均启动时间并添加缓冲区。随着您应用的启动时间变快或变慢,请务必更新此数字。
结论
大多数人会告诉你,健康检查是任何分布式系统的要求,Kubernetes 也不例外。使用运行状况检查可为您的 Kubernetes 服务提供坚实的基础、更好的可靠性和更长的正常运行时间。值得庆幸的是,Kubernetes 让这一切变得容易!


