
- 1Subscriber class xxx.xxx.xxx and its super classes have no public methods with the@Subscribe annotat_subscriber class com.topdon.tool.mainactivity and
- 2PyQt5快速开发与实战 4.13 菜单栏、工具栏与状态栏 and 4.14 QPrinter_qprinter qml
- 3tensorflow中prefetch最合适的用法_dataset prefetch
- 4MNE-Python | 开源生理信号分析神器(一)_python mne
- 5INT4和INT8_int4和int8区别
- 6Kubernetes 健康检查之 livenessProbe/readinessProbe_kubernetes livenessprobe
- 7HTTP常见状态码_.getrequest( code:1000
- 8搭建私有Nuget服务器(.Net Core框架)_nuget.server core
- 9各种假设检验用法汇总_假设检验的八种情况的公式
- 10再生资源回收系统 毕业设计 JAVA+Vue+SpringBoot+MySQL
【目标检测】YOLO系列Anchor标签分配、边框回归(坐标预测)方式、LOSS计算方式_yolov1每个grid多少个anchor
赞
踩
1、YOLOv1
标签分配:GT的中心落在哪个grid,那个grid对应的两个bbox中与GT的IOU最大的bbox为正样本,其余为负样本,(由于是回归模型,不是分类模型,其解决类别不平衡的方式为各项loss采取不同的权重),即虽然一个grid分配两个bbox,但是只有一个bbox负责预测一个目标(边框和类别),这样导致YOLOv1最终只能预测7*7=49个目标。
边框回归方式:直接预测(x, y, w, h),而不是像rcnn系列那样预测偏移量(tx, ty, tw, th),其中心点的预测是相对于gird左上角的位置。
摘自原文:
Each bounding box consists of 5 predictions:x,y,w,h,and confidence. The(x,y)coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally the confidence prediction represents the IOU between the predicted box and any ground truth box.
物体框中心相对其所在网格单元格边界的位置(一般是相对于单元格左上角坐标点的位置,以下用x,y表示)和检测框真实宽高相对于整幅图像的比例(注意这里w,h不是实际的边界框宽和高),(x, y, w, h)都是归一化之后的数值。
LOSS计算:

- 由于相同的位置误差对大目标和小目标的影响是不同的,相同的偏差对于小目标来说影响要比大目标大,故作者选择将预测的bbox的w,h先取其平方根,再求均方差损失。
- 一个网格预测2个bbox,在计算损失函数的时候,只取与ground truth box中IoU大的那个预测框来计算损失。
- 分类误差,只有当单元格中含有目标时才计算,没有目标的单元格的分类误差不计算在内。
由于每个单元格预测2个边界框,但是其对应类别只有一个,那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU最大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,坐标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。
这种标签分配方式和边框回归方式产生两个问题:
(1)边框回归不准
(2)漏检很多
参考链接:
https://zhuanlan.zhihu.com/p/32525231 (bbox选择)
https://blog.csdn.net/u014380165/article/details/72616238 (bbox选择)
2、YOLOv2
标签分配:(1)由YOLOv1的7*7个grid变为13*13个grid,划分的grid越多,多个目标中心落在一个grid的情况越少,越不容易漏检;(2)一个grid分配由训练集聚类得来的5个anchor(bbox);(3)对于一个GT,首先确定其中心落在哪个grid,然后与该grid对应的5个bbox计算IOU,选择IOU最大的bbox负责该GT的预测,即该bbox为正样本;将每一个bbox与所有的GT计算IOU,若Max_IOU小于IOU阈值,则该bbox为负样本,其余的bbox忽略。
边框回归方式:预测基于grid的偏移量(tx, ty, tw, th)和基于anchor的偏移量(tx, ty, tw, th),具体体现在loss函数中。
基于anchor的偏移量的意思是,anchor的位置是固定的,偏移量=目标位置-anchor的位置。
基于grid的偏移量的意思是,grid的位置是固定的,偏移量=目标位置-grid的位置。
摘自原文:
The network predicts 5 coordinatesfor each bounding box, tx,ty,tw,th, and to.

与YOLOv1的不同:
- 网络输出:YOLOv1是(x, y, w, h),YOLOv2是(tx, ty, tw, th),这就决定了GT也是这种表示形式;
- loss计算:YOLOv1是直接拿(x, y, w, h)来计算的,YOLOv2是拿(tx, ty, tw, th)来计算的,这就决定了YOLOv1是直接回归,YOLOv2是回归偏移量(offset);
对于边界框的预测在沿袭YOLOv1的同时借鉴了Faster R-CNN的思想,其实,对于中心点(x,y)的预测跟YOLOv1原理相同,都是预测相对于grid的位置,只不过其经过了sigmoid函数公式变换,将中心点约束在一个grid内;对于宽高的预测,跟Faster R-CNN的思想一致,学习目标是anchor和GT之间的偏移量(而不直接是GT的宽和高,参考RCNN的计算过程);
在YOLOv2中引入anchor思想,主要的贡献是优化了宽高尺度的学习,使宽高有一个更好的先验;而对于中心点的学习不是anchor的贡献,其跟YOLOv1思想一致,不过sigmoid变换的出现,使一开始的训练更稳定;对中心点的计算,没有用到anchor信息。
LOSS计算:
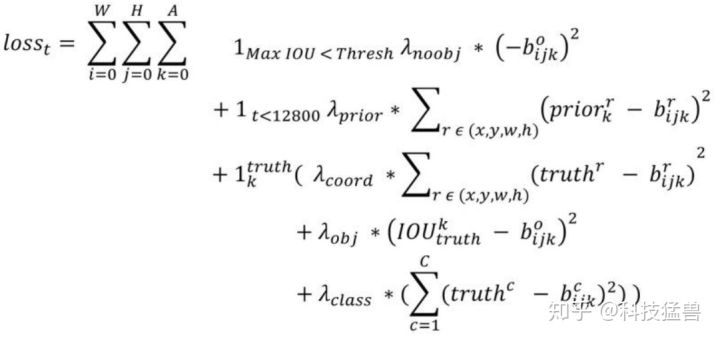
- 第1,4行是confidence_loss,注意这里的真值为0和IoU(GT, anchor)的值(与v1一致),在v2中confidence的预测值施加了sigmoid函数;
- 第2,3行:t是迭代次数,即前12800步我们计算这个损失,后面不计算了。这部分意义何在?意思是:前12800步我们会优化预测的(x,y,w,h)与anchor的(x,y,w,h)的距离+预测的(x,y,w,h)与GT的(x,y,w,h)的距离,12800步之后就只优化预测的(x,y,w,h)与GT的(x,y,w,h)的距离,也就是刚开始除了对GT的学习还会加一项对于anchor位置的学习,这么做的意义是在一开始预测不准的时候,用上anchor可以加速训练。
第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。
第二项是计算先验框与预测框的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。
第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,在YOLOv1中target=1,而YOLOv2增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。
v2与v1的主要区别:
- 在v1中,一个grid(两个bbox)只对应预测一个类别,在训练是两个bbox中只有与GT的IOU最大的那个参与学习,即在训练时只有49个bbox在学习(另外49个bbox被当做背景,confidence为0),在测试时虽然两个bbox都输出,但是可想而知只有一个confidence很大,可以被留下,另一个confidence很小,通过阈值就删掉了;
- 在v2中,一个grid中的5个bbox可以分别预测不同的类别,可以说,对于类别的预测,YOLOv1是以grid为单位的,YOLOv2是以bbox(anchor)为单位的,(看loss的差别就知道了)。若两个GT的中心同时落在了一个grid中,每个GT都可以找到一个bbox(anchor)来负责该GT的预测,两个bbox(anchor)可以输出不同的类别,而不是像v1中一个grid只能预测一个目标(类别)。(这里还有一个问题,如果两个GT找到的是同一个anchor该怎么办,作者应该是默认这种极端情况应该几乎不会出现。)
- YOLOv2中Anchor的概念主要体现在先验框的生成,边框回归中对宽高的回归,以及类别的预测。
v2与v1的相同点:
- 同样都是一套回归算法的流程,全部采用回归loss;
- 同样都是“负责”的概念,找到负责GT的bbox;
参考链接:
https://blog.csdn.net/weixin_31866177/article/details/86662856 (bbox选择)
3、YOLOv3
标签分配:三个特征图一共 8 × 8 × 3 + 16 × 16 × 3 + 32 × 32 × 3 = 4032 个anchor。
- 正例:任取一个ground truth,与4032个anchor全部计算IOU,IOU最大的anchor,即为正例。并且一个anchor,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例anchor,那么下一个ground truth,就在余下的4031个anchor中,寻找IOU最大的anchor作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。标签为对应的ground truth标签(需要反向编码,使用真实的(x, y, w, h)计算出(tx, ty, tw, th) );类别标签对应类别为1,其余为0;置信度标签为1。
- 负例:正例除外(特殊情况:与ground truth计算后IOU最大的anchor,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5)的anchor,则为负例。负例只有置信度产生loss,置信度标签为0。
- 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5)的anchor,则为忽略样例。忽略样例不产生任何loss。
这样产生的问题是:一个GT只分配一个anchor来进行预测,存在正样本太少的问题,在后面的工作中例如FCOS已经证明了,增加高质量的正样本数量,有利于检测模型的学习。
边框回归方式:与YOLOv2一致
LOSS计算:
特征图1的Yolov3的损失函数抽象表达式如下:

Yolov3 Loss为三个特征图Loss之和:
![]()
λ 为权重常数,控制检测框Loss、obj置信度Loss、noobj置信度Loss之间的比例,通常负例的个数是正例的几十倍以上,可以通过权重超参控制检测效果。1obji,j 若是正例则输出1,否则为0;1noobji,j 若是负例则输出1,否则为0。- (x, y, w, h)使用MSE作为损失函数,也可以使用smooth L1 loss(出自Faster R-CNN)作为损失函数。smooth L1可以使训练更加平滑。置信度、类别标签由于是0,1二分类,所以使用交叉熵作为损失函数(sigmoid作为激活函数)。
关于多尺度特征图的标签分配:
ground truth为什么不按照中心点分配对应的anchor?(YOLOv1和YOLOv2中“负责”那种思想)
(1)在Yolov3的训练策略中,不再像Yolov1那样,每个grid负责中心落在该grid中的ground truth。原因是Yolov3一共产生3个特征图,3个特征图上的grid,中心是有重合的。如果按照YOLOv1和YOLOv2的方式,一个GT的中心点有可能会落在不同尺度上的不同grid中,但是与该GT大小匹配的尺度大多数情况下只有一个。所以Yolov3的训练,不再按照ground truth中心点,严格分配指定grid,而是在所有anchor中寻找与GT的IOU最大的anchor作为正例。
(2)在多尺度特征图的标签分配问题中有两种思路,第一种,先根据GT的大小,将GT分配到某个尺度上,然后在该尺度上选IOU最大的作为正例(貌似FCOS是这种思路,具体哪篇论文记不清了)。第二种,直接将GT在3种尺度上,选IOU最大的anchor为正例。总结来说,可以先确定在哪个尺度上选先验,也可以直接在所有尺度上选先验。(论文往往不会把所有的细节都写清楚,但是合理的做法可能有多种,具体是怎么实现的还是以代码为准)
关于置信度标签分配:
YOLOv1和YOLOv2中的置信度标签,就是bbox与GT的IOU,YOLOv3为什么是1?(实际上在YOLOv1和YOLOv2的第三方实现中,有些也是1)
(1)置信度意味着该预测框是或者不是一个真实物体,是一个二分类,所以标签是1、0更加合理。
(2)YOLO系列中出现了两种方式:第一种:置信度标签取预测框与真实框的IOU;第二种:置信度标签取1。第一种的结果是,在训练时,有些预测框与真实框的IOU极限值就是0.7左右,置信度以0.7作为标签,置信度学习有一些偏差,最后学到的数值是0.5,0.6,那么假设推理时的激活阈值为0.7,这个检测框就被过滤掉了。但是IOU为0.7的预测框,其实已经是比较好的学习样例了。尤其是coco中的小像素物体,几个像素就可能很大程度影响IOU,所以第一种训练方法中,置信度的标签始终很小,无法有效学习,导致检测召回率不高。而检测框趋于收敛,IOU收敛至1,置信度就可以学习到1,这样的设想太过理想化。而使用第二种方法,召回率明显提升了很高。
存在以下疑问:(可能这两种方式在不同的实现中都有使用)
(1)标签分配时,IOU的计算使用预设anchor值还是网络预测值(预设anchor值叠加offset)
(2)标签分配时,GT先分配到某个尺度(IOU计算只考虑尺度不考虑位置,将预设anchor与GT对齐再计算IOU),再找正样本,还是直接在3个尺度上找正样本。
(3)边框回归loss使用的是MSE loss还是Smooth L1 loss;
(4)置信度loss使用的是MSE loss还是CE loss(-Log loss)。
参考链接:
4、YOLOv4
标签分配:YOLOv3是1个anchor负责一个GT,YOLO v4中用多个anchor去负责一个GT。
对于某个GT来说,计算其与所有anchor的IOU,IOU大于一定阈值(MAX_thresh=0.7)的anchor都设为正样本;如果该GT与所有anchor的IOU都小于阈值(MAX_thresh=0.7),选择IOU最大的为正样本,保持每个GT至少有一个anchor负责预测;如果一个anchor与所有的GT的IOU都小于(MIN_thresh=0.3),则该anchor为负样本;其余的anchor都忽略。
边框回归方式:与YOLOv2、YOLOv3一致,都是预测(tx, ty, tw, th)
LOSS计算:边框回归loss变为CIOU loss,边框回归loss演进:MSE loss/Smooth L1 loss —— IOU loss —— GIOU loss —— DIOU loss —— CIOU loss (参考https://zhuanlan.zhihu.com/p/143747206中对回归loss的讲解)
置信度loss采用MSE loss;分类loss采用BCE loss。
5、YOLOv5
标签分配:考虑邻域的正样本anchor匹配策略,增加了正样本,参考https://zhuanlan.zhihu.com/p/183838757中loss计算部分。
边框回归方式:与之前一致,预测(tx, ty, tw, th)
LOSS计算:cls和conf分支都是BCE loss,回归分支采用CIOU loss。
6、总结
- 由于原始论文很多细节没有明确写出来,很多文章的说法也有不一致的地方,不同的代码实现也有不一样的地方,所以还需要进一步调研学习;
- 对于正样本分配来说,可以确定的是,一个GT只对应一个anchor肯定不是最优的,增加正样本的数量可以有效提高目标的学习;
- 对于边框回归/坐标预测来说,可以确定的是,预测偏移量比直接预测坐标要好,将中心点的位置用sigmoid约束在一个grid中可以加速学习;
- 对于loss计算来说,可以确定的是,CIOU loss是目前回归loss最合理的设计,置信度loss可以用MSE loss或者-Log loss,我认为-Log loss更好(可能差距不大),分类loss用BCE loss要优于softmax loss,可以解决多标签的问题。
后续要进一步整理:IOU loss、NMS、数据增强、anchor-free系列等。
参考:
科技猛兽:你一定从未看过如此通俗易懂的YOLO系列(从v1到v5)模型解读 (上)https://zhuanlan.zhihu.com/p/183261974(中)https://zhuanlan.zhihu.com/p/183781646(下)https://zhuanlan.zhihu.com/p/186014243
江大白:深入浅出Yolo系列之Yolov3&Yolov4&Yolov5核心基础知识完整讲解(上)https://zhuanlan.zhihu.com/p/143747206(下)https://zhuanlan.zhihu.com/p/172121380
深度眸:想读懂YOLOV4,你需要先了解下列技术(一)https://zhuanlan.zhihu.com/p/139764729(二)https://zhuanlan.zhihu.com/p/141533907
深度眸:进击的后浪yolov5深度可视化解析https://zhuanlan.zhihu.com/p/183838757
深度眸:目标检测正负样本区分策略和平衡策略总结(一)https://zhuanlan.zhihu.com/p/138824387(二)https://zhuanlan.zhihu.com/p/138828372(三)https://zhuanlan.zhihu.com/p/144659734

