
- 1Mybatis查询数据返回多条_mybatis查询前10条数据
- 2鸿蒙ArsTS项目创建打包发布流程_鸿蒙打包教程
- 3CVPR‘2023 | Cross-modal Adaptation: 基于 CLIP 的微调新范式_clip做微调
- 4内存溢出的多种原因及优化方法_改善内存溢出导致系统频繁宕机的问题
- 5安科瑞智慧安全用电云平台【无人化数据监控 远程控制 运维管理】
- 6Android/iOS APP备案:遇到的问题汇总指南!
- 7[Qt 教程之Widgets模块] —— QDialogButtonBox按钮框
- 8开发者进阶宝典,HarmonyOS 职业认证全奉上
- 9通过sql获取数据库表设计信息_sql 获取设计页面注释
- 10使用DrawerLayout,FragmentTabHost实现测滑式底部菜单栏界面_drawerlayout 底部滑动
目标检测算法(二)Fast RCNN_faster rcnn训练速度
赞
踩
Fast RCNN解决了RCNN的三个问题:
测试速度慢,训练速度慢,训练所需空间大。训练测试速度慢是因为一张图片候选框之间大量重叠,提取特征操作冗余。训练需要空间大是因为独立的分类器和位置回归器需要大量特征作为样本。
Fast RCNN概述:
算法主网络基于VGG16,训练的步骤:
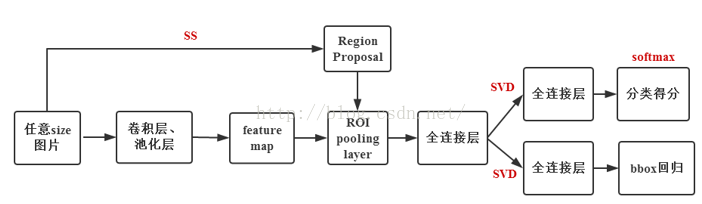
可参考:https://blog.csdn.net/xiaoye5606/article/details/71191429
输入图像→卷积层→降采样→卷积层(卷积层conv5输出+P个候选区域)→ROI pooling→2个output相同全连接→outputN的全连接和output4N的全连接(N为类别数目,第一个为分类,第二个用于边框回归)→两个损失层

ROI Pooling实际是SPP Net的精简版,接下来先介绍一下SPP Net:
SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》
此前CNN需要输入固定大小图片,因为CNN一般含有卷积与全连接。固定图片大小主要是受限于全连接层。因为卷积池化后的feature map(w*h*n)需要经过resize成为一个固定长度的特征向量。输入给全连接。全连接神经元固定,就要求feature map 大小固定,即图片大小固定。
SPP-Net在卷积与全连接之间加入了金字塔池化。金字塔池化层使得输入任意大小图片,经过该层生成 固定大小输出。
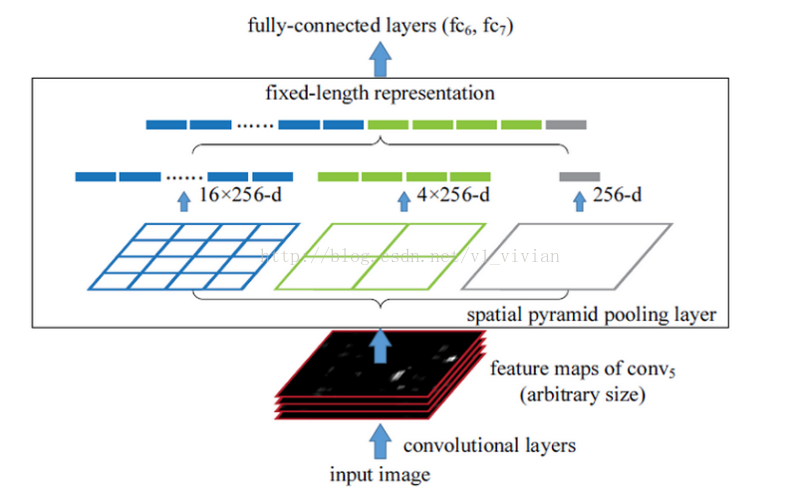
黑色图片代表卷积之后的特征图,接着我们以不同大小的块来提取特征,分别是4*4,2*2,1*1,将这三张网格放到下面这张特征图上,就可以得到16+4+1=21种不同的块(Spatial bins),我们从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。这种以不同的大小格子的组合方式来池化的过程就是空间金字塔池化(SPP)。比如,要进行空间金字塔最大池化,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出单元,最终得到一个21维特征的输出。所以Conv5计算出的feature map也是任意大小的,现在经过SPP之后,就可以变成固定大小的输出了,以上图为例,一共可以输出(16+4+1)*256的特征。(SPP-Net详解请参考https://blog.csdn.net/v1_vivian/article/details/73275259)
接着说回ROI Pooling:
在RCNN中,因为每个region proposal大小不一样,所以为了适应全连接,要进行wrap/crop,成为统一大小再输入给CNN这样会拉伸变形或者物体不全失真。
如果feature map上的ROI大小h*w(忽略通道数),将feature map 划分成h/H*w/W个网格,每个网格大小H*W,对每个网格做maxpooling,Pooling后大小H*W,论文中使用W=H=7,所以最后ROI Pooling输出7*7。这里就是SPP Net的特例。上边提到SPP Net使用 不同大小的块来提取特征,分别是4*4,2*2,1*1。这里只用了一层W*H.
Fast RCNN VS RCNN :
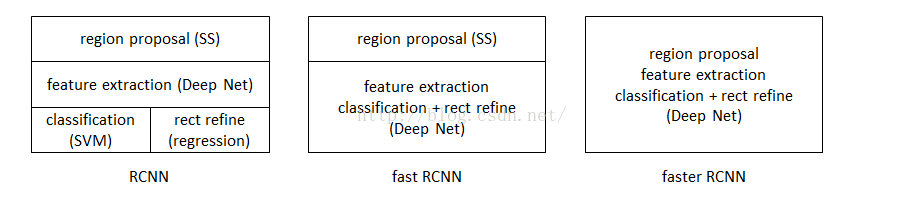
三者比较:参考https://blog.csdn.net/xiaoye5606/article/details/71191429
|
| 使用方法 | 缺点 | 改进 |
| R-CNN (Region-based Convolutional Neural Networks) | 1、SS提取RP; 2、CNN提取特征; 3、SVM分类; 4、BB盒回归。 | 1、 训练步骤繁琐(微调网络+训练SVM+训练bbox); 2、 训练、测试均速度慢 ; 3、 训练占空间 | 1、 从DPM HSC的34.3%直接提升到了66%(mAP); 2、 引入RP+CNN |
| Fast R-CNN (Fast Region-based Convolutional Neural Networks) | 1、SS提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 | 1、 依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s); 2、 无法满足实时应用,没有真正实现端到端训练测试; 3、 利用了GPU,但是区域建议方法是在CPU上实现的。 | 1、 由66.9%提升到70%; 2、 每张图像耗时约为3s。 |
| Faster R-CNN (Fast Region-based Convolutional Neural Networks) | 1、RPN提取RP; 2、CNN提取特征; 3、softmax分类; 4、多任务损失函数边框回归。 | 1、 还是无法达到实时检测目标; 2、 获取region proposal,再对每个proposal分类计算量还是比较大。 | 1、 提高了检测精度和速度; 2、 真正实现端到端的目标检测框架; 3、 生成建议框仅需约10ms。 |
Fast RCNN 当前不足之处:
区域建议还是使用SS算法。其他部分可以在GPU中运行,这部分只能在CPU中运行。FasterRCNN有解决这个问题。

