
- 1python关键词大全_Python 批量获取Baidu关键词的排名并入库
- 220230508 DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Network
- 3计算机内存管理之虚拟内存_不同进程可以通过虚拟内存来共享物理内存
- 4在uView UI中扩展和使用自定义图标_uview 扩展图标
- 5【鸿蒙】鸿蒙App应用-《记账软件》开发步骤_鸿蒙记账软件开发
- 6Cesium:CesiumLab制作影像切片与切片加载_cesiumlab影像切片
- 7四川对口高职计算机一类可以填报哪些学校,四川对口高职可以考哪些大学?
- 8新增数据并发处理,避免重复数据插入
- 9零基础HTML教程(10)--写一个画龙点睛的标题_html网页制作小标题
- 10GFLOPS、GFLOPs 和 GMACs的区别与关系
Locust - API压测
赞
踩
概述:
在Locust测试框架中,测试场景是采用纯Python脚本进行描述的,对于最常见的HTTP(S)协议的系统,Locust采用Python的requests库作为客户端。
在模拟有效并发方面,Locust的优势在于其摒弃了进程和线程,完全基于事件驱动,使用gevent提供的非阻塞IO和coroutine来实现网络层的并发请求,因此即使是单台压力机也能产生数千并发请求数;再加上对分布式运行的支持,理论上来说,Locust能在使用较少压力机的前提下支持极高并发数的测试。
1.开源、使用python开发、基于事件、支持分布式、提供WEB UI、支持结果导出;
2.使用python第三方库gevent提供的非阻塞IO和协程Coroutine来实现网络层的并发请求;
3.采用python的requests库作为客户端;
locust虽然是基于协程请求,但由于locust是运行在python解析器上,所以存在GIL锁机制;默认的网络请求库是requests同步库,所以单进程下的并发不会很高,如果想用locust进行并发请求,必定要使用分布式+异步请求库(同步请求和异步请求)。
安装:
pip install locust

locust --help(查看locust命令帮助并验证是否安装成功)
locust -V (查看当前版本)

主要组成:
事实上,在Locust的测试脚本中,所有业务测试场景都是在Locust和TaskSet两个类的继承子类中进行描述的。
简单地说,Locust类就好比是一群蝗虫,而每一只蝗虫就是一个类的实例。相应的,TaskSet类就好比是蝗虫的大脑,控制着蝗虫的具体行为,即实际业务场景测试对应的任务集。
class httpLocust(locust)
对于常见的HTTP(S)协议,Locust已经实现了HttpLocust类,其client属性绑定了HttpSession类,而HttpSession又继承自requests.Session。
因此在测试HTTP(S)的Locust脚本中,我们可以通过client属性来使用Python requests库的所有方法,包括GET / POST / HEAD / PUT / DELETE / PATCH等,调用方式也与requests完全一致。
另外,由于requests.Session的使用,因此client的方法调用之间就自动具有了状态记忆的功能。
在Locust类中,除了client属性,还有几个属性需要关注下:
- task_set: 指向一个TaskSet类,TaskSet类定义了用户的任务信息,该属性为必填;
- max_wait/min_wait: 每个用户执行两个任务间隔时间的上下限(毫秒),具体数值在上下限中随机取值,若不指定则默认间隔时间固定为1秒;
- host:被测系统的host,当在终端中启动locust时没有指定--host参数时才会用到;
- weight:同时运行多个Locust类时会用到,用于控制不同类型任务的执行权重。
测试开始后,每个虚拟用户(Locust实例)的运行逻辑都会遵循如下规律:
- 先执行WebsiteTasks中的on_start(只执行一次),作为初始化;
- 从WebsiteTasks中随机挑选(如果定义了任务间的权重关系,那么就是按照权重关系随机挑选)一个任务执行;
- 根据Locust类中min_wait和max_wait定义的间隔时间范围(如果TaskSet类中也定义了min_wait或者max_wait,以TaskSet中的优先),在时间范围中随机取一个值,休眠等待;
- 重复2~3步骤,直至测试任务终止。
class HttpUser
HttpUser类是 Locust 1.x 版本中代替以前老版本中的HttpLocust类,是 User 类的子类,用来定义虚拟用户,让虚拟用户作为客户端具备请求能力。
class TaskSet
TaskSet类实现了虚拟用户所执行任务的调度算法,包括规划任务执行顺序(schedule_task)、挑选下一个任务(execute_next_task)、执行任务(execute_task)、休眠等待(wait)、中断控制(interrupt)等等。
在TaskSet子类中定义任务信息时,可以采取两种方式,@task装饰器和tasks属性。
@task装饰器
采用@task装饰器定义任务时,描述形式如下:
装饰的方法@task是 locust 文件的核心。对于每个正在运行的用户,Locust 创建一个 greenlet(微线程),它将调用这些方法。
- @task(1)
- def demo(self):
- self.client.get('/api1')
-
- @task(2)
- def demo2(self):
- self.client.get('/api2')
该self.client属性可以进行由 Locust 记录的 HTTP 调用。
self.client.get("/hello")tasks属性
采用task属性定义任务信息时,描述形式如下:
- class jokerDemo(SequentialTaskSet):
- @task(1)
- def demo(self):
- self.client.get('/api1')
-
- class WebSiteUser(HttpUser):
-
- tasks=[jokerDemo]
on_start 与 on_stop
用户(TaskSets)可以声明一个on_start方法或 on_stop方法。
每次在开始任务时,先执行on_start方法,只执行一次,再执行具体的任务,执行完任务后去执行on_stop
on_start方法:每个模拟用户启动时都会调用具有此名称的方法。
- def on_start(self):
- log.info("on start...")
on_stop方法:每个模拟用户销毁时都会调用具有此名称的方法。
- def on_stop(self):
- log.info("on stop...")
脚本示例:
locustTest.py 例子:
- import time
- from locust import HttpUser, task, between, SequentialTaskSet
- import logging as log
- import json
-
- class jokerDemo(SequentialTaskSet):
- wait_time = between(1,3)
-
-
- @task
- def api1(self):
- url="/http/xxx/v1.0/xxx"
- headers = {'content-type': "application/json"}
- data = {}
- res = self.client.post(url, headers = headers, data = json.dumps(data))
- log.info("api1 res :"+str(res.json()))
-
- @task
- def api2(self):
- url="/http/xxx/v1.0/xxx"
- headers = {'content-type': "application/json"}
- data = {}
- res = self.client.post(url, headers = headers, data = json.dumps(data))
- log.info("api2 res :"+str(res.json()))
-
- @task
- def api3(self):
- url="/http/xxx/v1.0/xxx"
- headers = {'content-type': "application/json"}
- data = {}
- res = self.client.post(url, headers = headers, data = json.dumps(data))
- log.info("api3 res :"+str(res.json()))
-
-
- def on_start(self):
- log.info("on start...")
-
- def on_stop(self):
- log.info("on stop...")
-
-
- class WebSiteUser(HttpUser):
- tasks=[jokerDemo]

locust 启动
命令启动:
locust -f locustTest.py --host=http://localhost:8025 --headless -u 5 -r 5 --run-time 10s
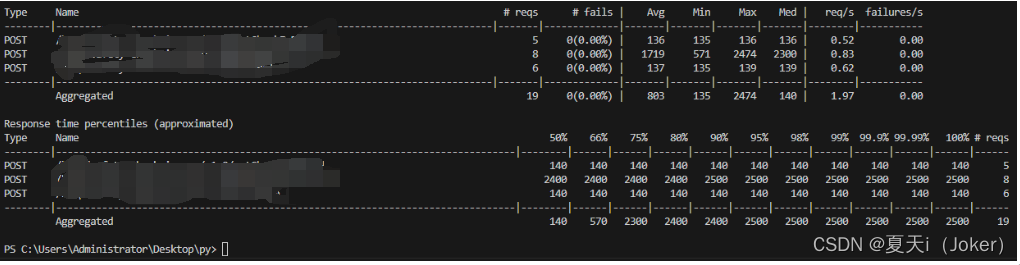
日志文件
增加输出日志文件:
--logfile=''Html报告
增加输出html报告
--html=''结合启动命令为:
locust -f locustTest.py --host=http://localhost:8025 --headless -u 5 -r 5 --run-time 10s --logfile='C:\Users\Administrator\Desktop\py\locustTest.log' --html='C:\Users\Administrator\Desktop\py\locustTest.html'![]()
打开locustTest.log
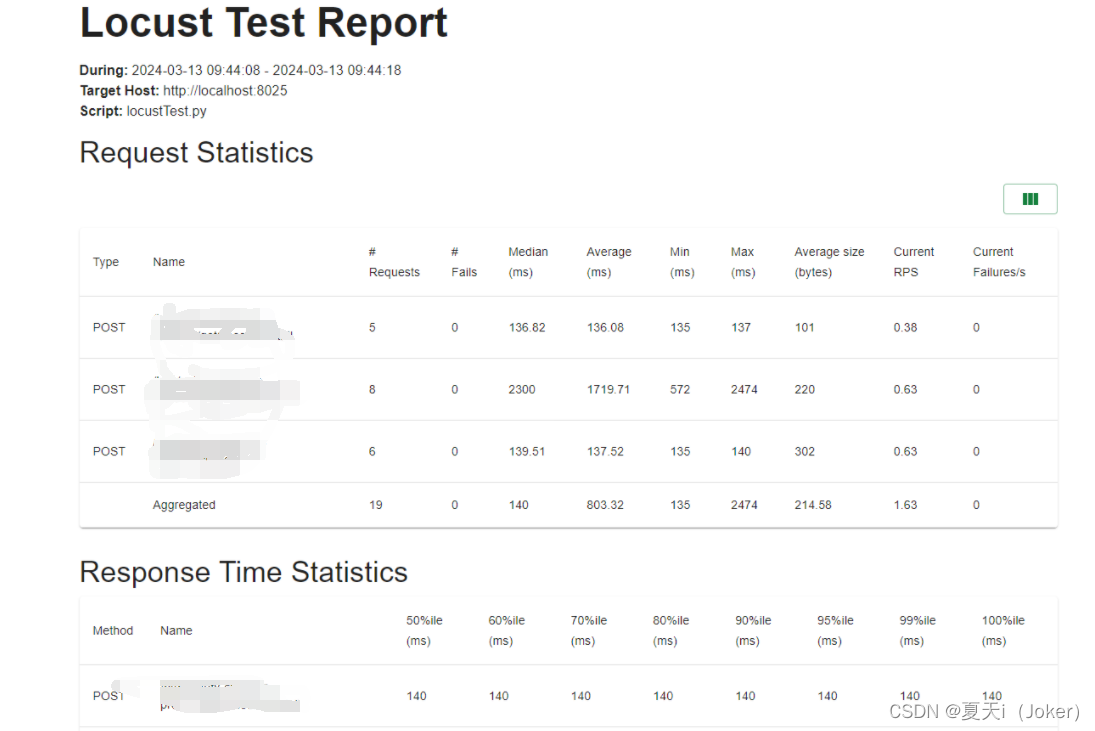
打开locustTest.html
网页启动:
启动的locust文件名为locustfile.py并位于当前工作目录中,可以在编译器中直接运行该文件:
locust -f locustfile.py
访问http://localhost:8089/ 进入网页界面
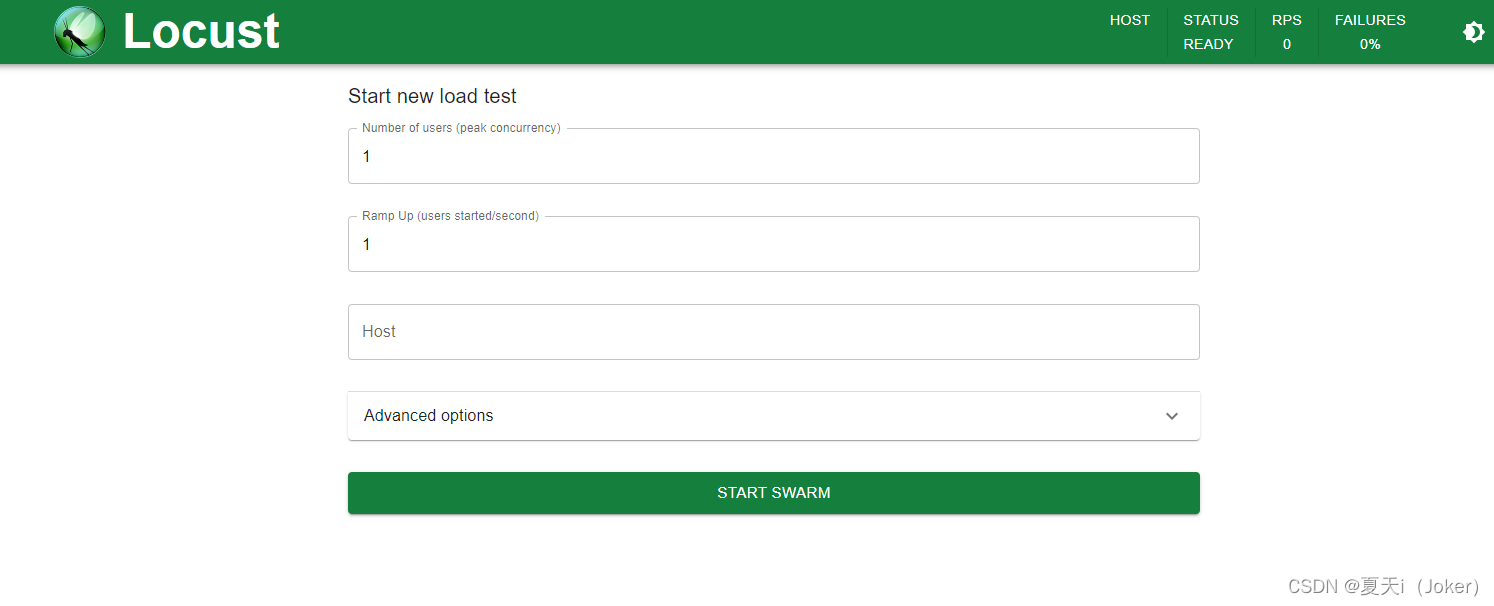
启动界面
Number of users to simulate:设置模拟的用户总数
Hatch rate (users spawned/second):每秒启动的虚拟用户数
Host:填写自己实际需要测试的目标系统host
Start swarming:执行locust脚本
测试结果界面
PS:点击STOP可以停止locust脚本运行:
Type:请求类型,即接口的请求方法;
Name:请求路径;
requests:当前已完成的请求数量;
fails:当前失败的数量;
Median:响应时间的中间值,即50%的响应时间在这个数值范围内,单位为毫秒;
Average:平均响应时间,单位为毫秒;
Min:最小响应时间,单位为毫秒;
Max:最大响应时间,单位为毫秒;
Content Size:所有请求的数据量,单位为字节;
reqs/sec:每秒钟处理请求的数量,即QPS;
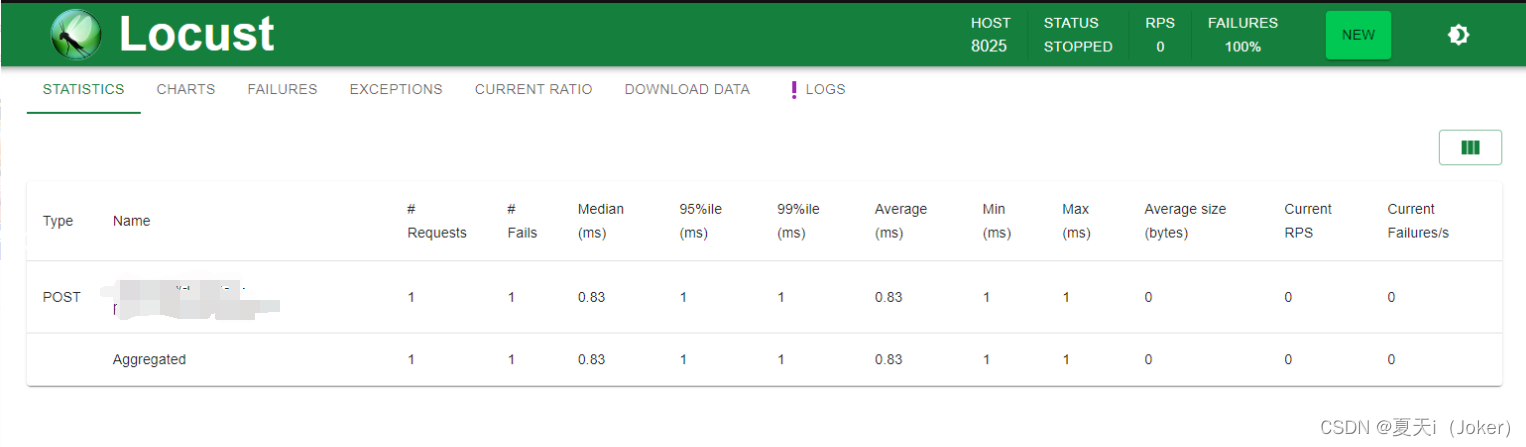
各模块说明
New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑;
Statistics:类似于jmeter中Listen的聚合报告;
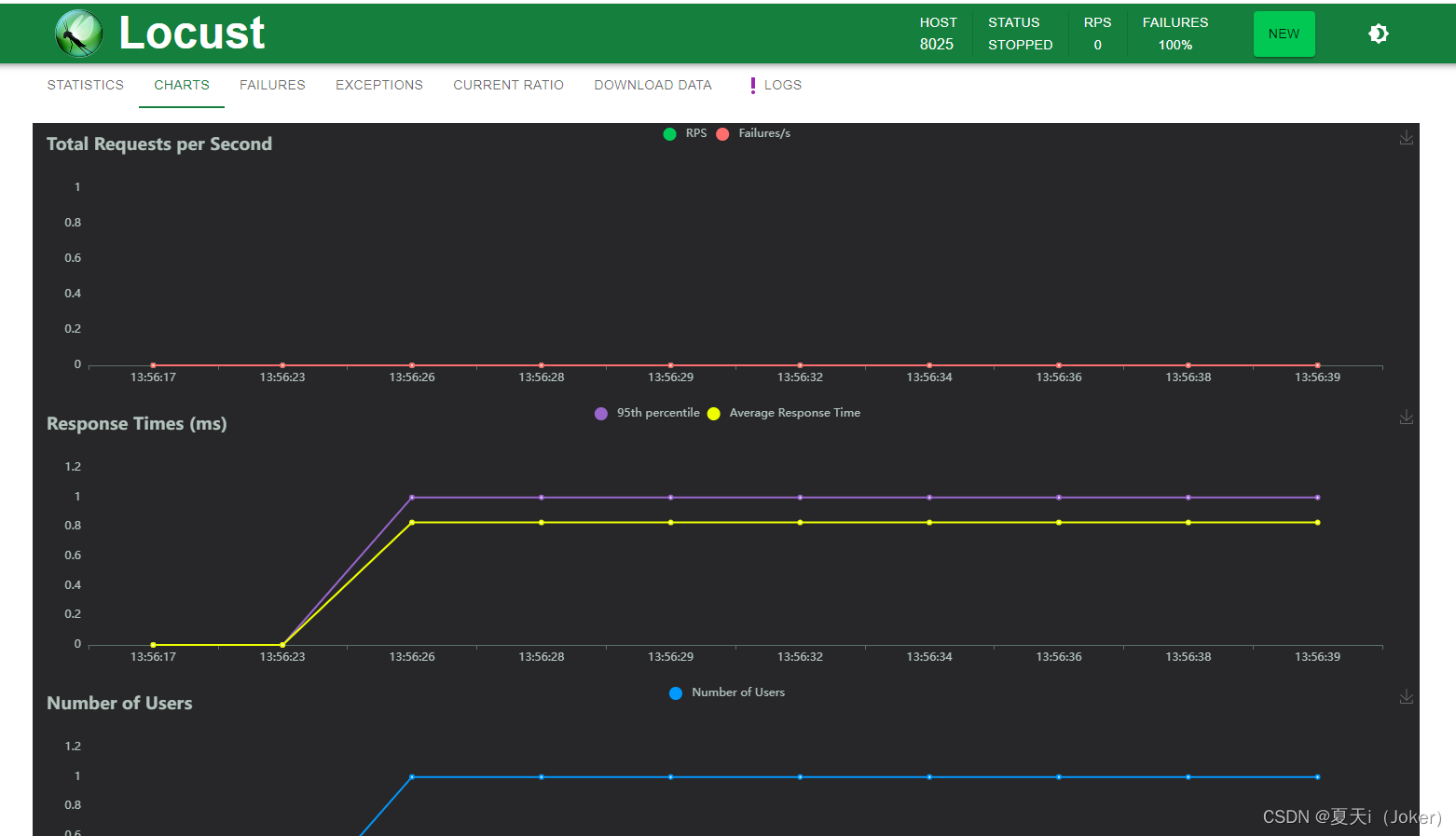
Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数;
Failures:失败请求的展示界面;

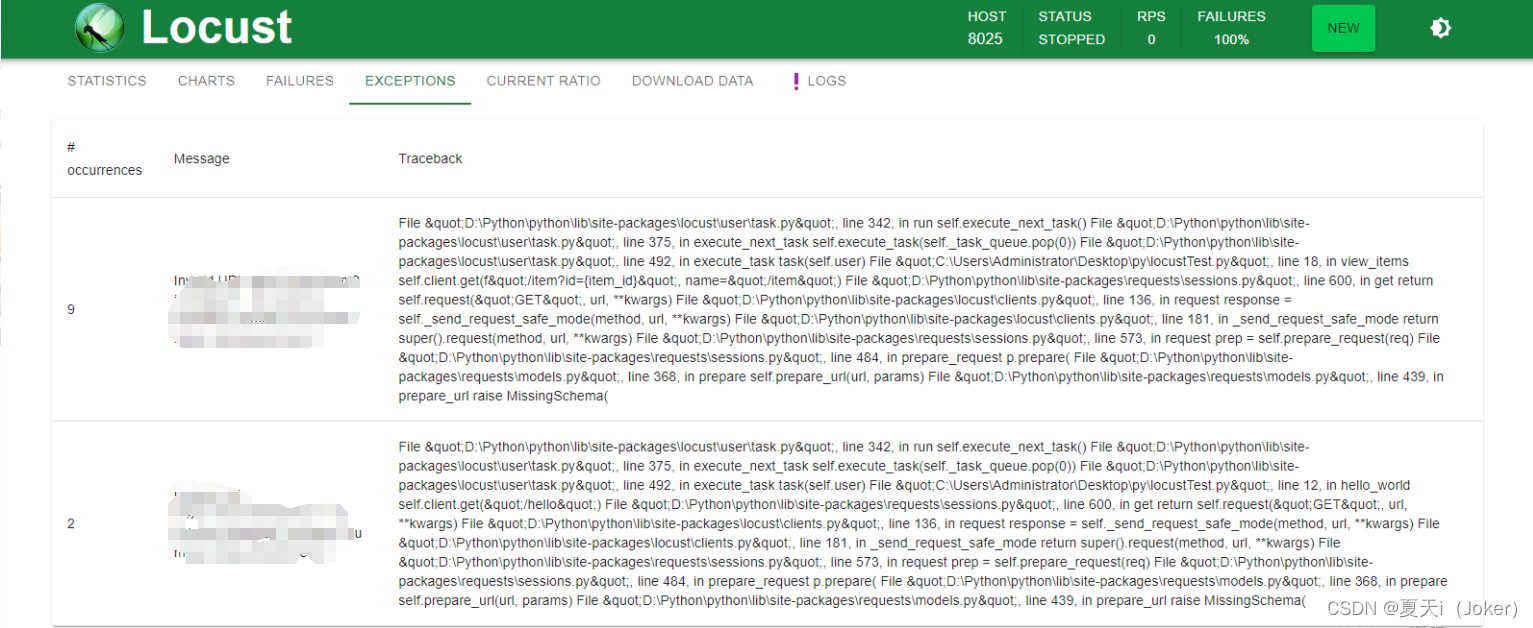
Exceptions:异常请求的展示界面;
Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions;
所有参数项:
| 命令行 | 环境 | 配置文件 | 描述 |
| -f, --locustfile | LOCUST_LOCUSTFILE | locustfile | 要导入的Python模块文件,例如'../other.py'。默认值:locustfile |
| -H, --host | LOCUST_HOST | host | 主机以以下格式加载测试:http : //10.21.32.33 |
| -u, --users | LOCUST_USERS | users | 并发蝗虫用户数。主要与–headless一起使用。可以在测试期间通过输入w,W(生成1,10个用户)和s,S(停止1,10个用户)来更改 |
| -r, --spawn-rate | LOCUST_SPAWN_RATE | spawn-rate | 产生用户的每秒速率。主要与–headless一起使用 |
| --hatch-rate | LOCUST_HATCH_RATE | hatch-rate | ==抑制== |
| -t, --run-time | LOCUST_RUN_TIME | run-time | 在指定的时间段后停止,例如(300s,20m,3h,1h30m等)。仅与–headless一起使用。默认为永久运行。 |
| --web-host | LOCUST_WEB_HOST | web-host | 将Web界面绑定到的主机。默认为“ *”(所有接口) |
| --web-port, -P | LOCUST_WEB_PORT | web-port | 运行虚拟主机的端口 |
| --headless | LOCUST_HEADLESS | headless | 禁用Web界面,而是立即开始负载测试。需要指定-u和-t。 |
| --headful | LOCUST_HEADFUL | headful | ==抑制== |
| --web-auth | LOCUST_WEB_AUTH | web-auth | 打开Web界面的基本身份验证。应该以以下格式提供:username:password |
| --tls-cert | LOCUST_TLS_CERT | tls-cert | 用于通过HTTPS服务的TLS证书的可选路径 |
| --tls-key | LOCUST_TLS_KEY | tls-key | 用于通过HTTPS服务的TLS私钥的可选路径 |
| --master | LOCUST_MODE_MASTER | master | 将蝗虫设置为以该进程为主的分布式模式下运行 |
| --master-bind-host | LOCUST_MASTER_BIND_HOST | master-bind-host | 蝗虫主机应绑定的接口(主机名,ip)。仅在与–master一起运行时使用。默认为*(所有可用接口)。 |
| --master-bind-port | LOCUST_MASTER_BIND_PORT | master-bind-port | 蝗虫主应该绑定的端口。仅在与–master一起运行时使用。默认为5557 |
| --expect-workers | LOCUST_EXPECT_WORKERS | expect-workers | 主机在开始测试之前应该期望连接多少工人(仅当使用–headless时)。 |
| --worker | LOCUST_MODE_WORKER | worker | 将蝗虫设置为以分布式模式运行,并以该进程作为工作进程 |
| --master-host | LOCUST_MASTER_NODE_HOST | master-host | 用于分布式负载测试的蝗虫主服务器的主机或IP地址。仅在与–worker一起运行时使用。默认为127.0.0.1。 |
| --master-port | LOCUST_MASTER_NODE_PORT | master-port | 蝗虫主服务器使用与之连接的端口进行分布式负载测试。仅在与–worker一起运行时使用。默认为5557 |
| -T, --tags | LOCUST_TAGS | tags | 测试中要包含的标签列表,因此仅执行具有任何匹配标签的任务 |
| -E, --exclude-tags | LOCUST_EXCLUDE_TAGS | exclude-tags | 要从测试中排除的标签列表,因此仅执行没有匹配标签的任务 |
| --csv | LOCUST_CSV | csv | 将当前请求统计信息以CSV格式存储到文件中。设置此选项将生成三个文件:[CSV_PREFIX] _stats.csv,[CSV_PREFIX] _stats_history.csv和[CSV_PREFIX] _failures.csv |
| --csv-full-history | LOCUST_CSV_FULL_HISTORY | csv-full-history | 将每个统计信息条目以CSV格式存储到_stats_history.csv文件中。您还必须指定“ –csv”参数以启用此功能。 |
| --print-stats | LOCUST_PRINT_STATS | print-stats | 在控制台中打印统计信息 |
| --only-summary | LOCUST_ONLY_SUMMARY | only-summary | 仅打印摘要统计信息 |
| --reset-stats | LOCUST_RESET_STATS | reset-stats | 产卵完成后重置统计信息。在分布式模式下运行时,应同时在master和worker上设置 |
| --html | LOCUST_HTML | html | 存储HTML报告文件 |
| --skip-log-setup | LOCUST_SKIP_LOG_SETUP | skip-log-setup | 禁用蝗虫的日志记录设置。而是由Locust测试或Python默认设置提供配置。 |
| --loglevel, -L | LOCUST_LOGLEVEL | loglevel | 在DEBUG / INFO / WARNING / ERROR / CRITICAL之间进行选择。默认值为INFO。 |
| --logfile | LOCUST_LOGFILE | logfile | 日志文件的路径。如果未设置,日志将转到stdout / stderr |
| --exit-code-on-error | LOCUST_EXIT_CODE_ON_ERROR | exit-code-on-error | 设置流程退出代码以在测试结果包含任何故障或错误时使用 |
| -s, --stop-timeout | LOCUST_STOP_TIMEOUT | stop-timeout | 退出之前等待模拟用户完成任何正在执行的任务的秒数。默认为立即终止。仅在运行Locust分布式时才需要为主进程指定此参数。 |
locust运行模式:
单进程运行:
Locust所有的虚拟并发用户均运行在单个Python进程中。具体从使用形式上,又分为no_web和web两种形式。该模式由于单进程的原因,并不能完全发挥压力机所有处理器的能力,因此主要用于调试脚本和小并发压测的情况。
分布式运行:
分布式运行(通过多进程负载来生成并发压力)多机负载(多台压力机同时运行,每台压力机分担负载一部分的压力生成)、单机多进程(在同一台压力机上开启多个slave的情况,因为当前阶段大多数计算机的CPU都是多处理器)。
说明:
1)关于单机多进程:单进程运行模式下只能用到一个处理器的能力。而通过在一台压力机上运行多个slave,就能调用多个处理器的能力了。比较好的做法是,如果一台压力机有N个处理器内核,那就在这台压力机上先启动一个master,然后开多个窗口逐一启动N个slave(我们也可以启动N的倍数个slave,但是根据试验数据经验,效果和N个差不多,因此只需启动N个slave即可)。
2)关于多机负载:需要在主机中使用--master标记来启用一个locust实例,但是master节点的机器不会发起请求,只会收集数据展示;然后在从机使用--worker标记启动一条到多台locust salve的机器节点,与标记----master-host一起使用(指出master机器的ip/hostname)
整理自:

