
- 1android.intent.action.view设置,Android开发中Intent.Action各种常见的作用汇总
- 2安装APK时INSTALL_FAILED_ALREADY_EXISTS的解决办法
- 3NLP实践三-----特征选择_pmi点互信息算法特征选择
- 4利用 jQuery-photoClip插件 实现移动端裁剪功能并以Blob对象上传
- 5【AI实战】手把手教你深度学习文字识别(文字检测篇:基于MSER, CTPN, SegLink, EAST等方法)...
- 6ArkTS调用Native函数的方法_cannot get sourcemap info, dump raw stack
- 7vector中删除某个指定元素_vector移除一个
- 8自动化构建vue页面_vue可视化自动生成页面以及绑定接口
- 9axios封装处理(含携带token请求,token过期处理,请求数据中的大数处理问题)_在地址栏上写携带token的请求路径怎么写格式
- 10安装LLVM+Clang教程_clang安装
基于深度学习LSTM+NLP情感分析电影数据爬虫可视化分析推荐系统(深度学习LSTM+机器学习双推荐算法+scrapy爬虫+NLP情感分析+数据分析可视化)
赞
踩
基于深度学习LSTM+NLP情感分析电影数据爬虫可视化分析推荐系统(深度学习LSTM+机器学习双推荐算法+scrapy爬虫+NLP情感分析+数据分析可视化)
项目概述
本项目旨在基于深度学习LSTM(Long Short-Term Memory)模型,基于python编程语言,Vue框架进行前后端分离,结合机器学习双推荐算法、scrapy爬虫技术、PaddleNLP情感分析以及可视化技术,构建一个综合的电影数据爬虫可视化+NLP情感分析推荐系统。通过该系统,用户可以获取电影数据、进行情感分析,并获得个性化的电影推荐,从而提升用户体验和满足用户需求。
首先,项目将利用scrapy爬虫框架从多个电影网站上爬取丰富的电影数据,包括电影名称、类型、演员信息、剧情简介等。这些数据将被存储并用于后续的分析和推荐。接着,使用PaddleNLP情感分析技术对用户评论和评分数据进行情感倾向性分析,帮助用户更全面地了解电影的受欢迎程度和评价。
在推荐系统方面,项目将结合深度学习LSTM模型和机器学习双推荐算法,实现个性化的电影推荐。LSTM模型将用于捕捉用户的浏览和评分行为序列,从而预测用户的兴趣和喜好;双推荐算法则综合考虑用户的历史行为和电影内容特征,为用户提供更精准的推荐结果。
此外,项目还将注重可视化展示,通过图表、图形等形式展示电影数据的统计信息和情感分析结果,让用户直观地了解电影市场趋势和用户情感倾向。同时,用户也可以通过可视化界面进行电影搜索、查看详情、评论互动等操作,提升用户交互体验。
综上所述,本项目将集成多种技术手段,构建一个功能强大的电影数据爬虫可视化+NLP情感分析推荐系统,为用户提供全方位的电影信息服务和个性化推荐体验。通过深度学习、机器学习和数据挖掘等技术的应用,该系统有望成为电影爱好者和观众们的理想选择,为电影产业的发展和推广起到积极的推动作用。
深度学习长短时记忆网络(Long Short-Term Memory,LSTM)
深度学习长短时记忆网络(Long Short-Term Memory,LSTM)是一种常用于处理时序数据和序列建模的深度学习模型。它在解决传统循环神经网络(RNN)中存在的梯度消失和梯度爆炸等问题上具有显著优势,能够更好地捕捉数据中的长期依赖关系和时间相关性。
LSTM网络由一系列特殊设计的单元组成,每个单元内部包含输入门、遗忘门、输出门等关键组件,通过这些门的开关控制信息的流动,从而实现对数据的长期记忆和短期记忆。相比于传统的RNN,LSTM能够更有效地存储和提取长期记忆信息,同时能够更好地避免梯度消失和梯度爆炸的问题,使得其在处理长序列数据时表现更加出色。
在LSTM中,每个时间步的计算都涉及三个关键部分:遗忘门、输入门和输出门。遗忘门用于控制上一个时间步的记忆是否保留到当前时间步,输入门用于控制当前时间步的输入是否被添加到记忆中,输出门则用于控制当前时间步的记忆如何被输出。这种机制使得LSTM网络能够有效地处理时间序列中的长期依赖关系,适用于语言建模、机器翻译、时间序列预测等多个领域。
除了基本的LSTM结构外,还衍生出了多种变体模型,如双向LSTM(Bidirectional LSTM)、多层LSTM(Multilayer LSTM)等,以适应不同任务的需求。同时,LSTM也常与其他深度学习模型相结合,如卷积神经网络(CNN)和注意力机制(Attention),共同完成更复杂的任务。
深度学习长短时记忆网络(LSTM)作为一种强大的序列建模工具,通过其独特的门控机制和记忆单元结构,能够有效地处理时序数据,具有广泛的应用前景,对于解决时间序列数据分析、自然语言处理和其他时序信息处理任务具有重要意义。
机器学习协同过滤算法(UserCF+ItemCF)
机器学习中的协同过滤算法是一种常用于推荐系统中的算法,旨在根据用户和物品之间的历史交互行为,预测用户对未知物品的兴趣度。主要有两种类型:基于用户的协同过滤和基于物品的协同过滤。
基于用户的协同过滤算法通过计算用户之间的相似度,推荐给某个用户与其相似用户喜欢的物品。而基于物品的协同过滤算法则是通过计算物品之间的相似度,向用户推荐与其已喜欢物品相似的其他物品。这些算法通常依赖于用户-物品交互矩阵,利用用户对物品的评分或点击等信息进行计算。
协同过滤算法不需要事先对物品进行特征提取,能够发现用户和物品之间的隐藏关系,因此在个性化推荐领域应用广泛。然而,协同过滤算法也存在数据稀疏、冷启动等问题,需要通过增加数据量、引入正则化等手段来提高推荐效果。随着深度学习和神经网络的发展,协同过滤算法也逐渐与深度学习相结合,提升了推荐系统的性能和准确度。
大数据scrapy爬虫
Scrapy是一个基于Python的开源网络爬虫框架,用于快速、高效地抓取和提取网页数据。它提供了一套强大的工具和机制,使得开发者能够轻松地编写和运行爬虫程序。
Scrapy的核心组件包括引擎(Engine)、调度器(Scheduler)、下载器(Downloader)、解析器(Parser)和管道(Pipeline)。引擎负责控制整个爬虫的流程和协调各个组件之间的工作;调度器负责管理待抓取的URL队列,并根据优先级和调度策略分配给下载器;下载器负责发送HTTP请求并接收响应;解析器负责解析下载的网页内容,提取出感兴趣的数据;管道负责处理解析出的数据,如存储到数据库或导出到文件等。
Scrapy的特点包括:
- 高性能:Scrapy采用异步非阻塞的方式处理并发请求,通过多线程和多进程技术,实现高效的爬取速度。
- 可扩展性:Scrapy提供了丰富的扩展接口和中间件机制,开发者可以方便地定制和扩展功能。
- 分布式支持:Scrapy可以通过分布式框架进行部署,实现分布式的并发爬取,提高效率。
- 数据提取方便:Scrapy提供了灵活、强大的数据提取工具,如XPath和CSS选择器,能够方便地从网页中提取目标数据。
- 支持代理和登录:Scrapy支持设置代理IP和处理登录认证等功能,可以应对一些需要身份验证或访问限制的网站。
- 丰富的生态系统:Scrapy有庞大的开源社区支持,提供了各种插件、扩展和文档资源,方便开发者使用和学习。
NLP情感分析
自然语言处理(NLP)情感分析是一种利用计算机自动识别和理解文本中所包含情感倾向的技术。该技术可以帮助分析文本内容中的情绪、态度和情感倾向,对用户评论、社交媒体内容、新闻文章等进行情感分类,从而实现对大规模文本数据的情感挖掘和分析。
情感分析通常包括情感识别和情感分类两个方面。情感识别旨在识别文本中所包含的情感,如喜怒哀乐等;情感分类则是将识别到的情感分为积极、消极或中性等类别。情感分析技术通常基于机器学习和深度学习算法,通过构建情感词典、训练情感分类模型等方式来实现。
在情感分析中,常用的技术包括词袋模型(Bag of Words)、词嵌入(Word Embedding)、循环神经网络(RNN)、长短期记忆网络(LSTM)、卷积神经网络(CNN)等。这些技术能够有效地捕捉文本中的语义信息和上下文关联,从而实现对情感的准确识别和分类。
情感分析技术在商业领域具有广泛应用,如舆情监控、产品评论分析、市场调研等方面。通过情感分析,企业可以了解用户对其产品和服务的态度和情感倾向,及时发现和解决问题,改进产品设计和营销策略。此外,在社交媒体舆情监控中,情感分析也能够帮助政府和组织了解公众情绪,及时回应和处理热点事件,为决策提供参考依据。
NLP情感分析技术以其在舆情监控、用户评论分析等领域的应用前景,成为当今自然语言处理领域中备受关注的研究和应用方向。
部分数据展示
数据爬取流程
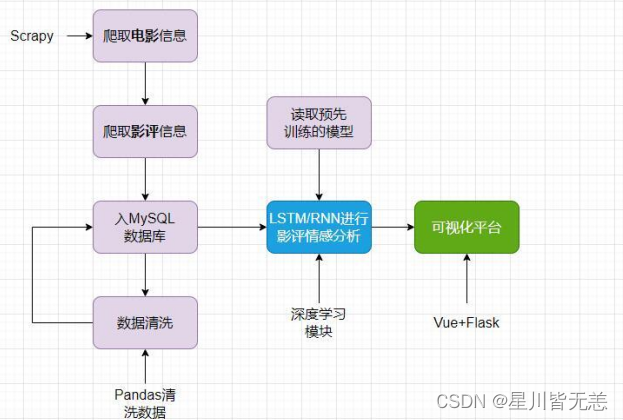
其他表就不一一截图了。
部分核心代码展示
PaddlePaddle飞桨深度学习NLP+ LSTM模型。
from functools import partial import argparse import os import random import numpy as np import paddle import paddlenlp as ppnlp from paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab from paddlenlp.datasets import load_dataset from model import BoWModel, BiLSTMAttentionModel, CNNModel, LSTMModel, GRUModel, RNNModel, SelfInteractiveAttention from utils import convert_example, build_vocab # yapf: disable parser = argparse.ArgumentParser(__doc__) parser.add_argument("--epochs", type=int, default=15, help="Number of epoches for training.") parser.add_argument('--device', choices=['cpu', 'gpu', 'xpu', 'npu'], default="gpu", help="Select which device to train model, defaults to gpu.") parser.add_argument("--lr", type=float, default=5e-5, help="Learning rate used to train.") parser.add_argument("--save_dir", type=str, default='checkpoints/', help="Directory to save model checkpoint") parser.add_argument("--batch_size", type=int, default=64, help="Total examples' number of a batch for training.") parser.add_argument("--vocab_path", type=str, default="./vocab.json", help="The file path to save vocabulary.") parser.add_argument('--network', choices=['bow', 'lstm', 'bilstm', 'gru', 'bigru', 'rnn', 'birnn', 'bilstm_attn', 'cnn'], default="bilstm", help="Select which network to train, defaults to bilstm.") parser.add_argument("--init_from_ckpt", type=str, default=None, help="The path of checkpoint to be loaded.") args = parser.parse_args() # yapf: enable def set_seed(seed=1000): """sets random seed""" random.seed(seed) np.random.seed(seed) paddle.seed(seed) def create_dataloader(dataset, trans_fn=None, mode='train', batch_size=1, batchify_fn=None): if trans_fn: dataset = dataset.map(trans_fn) shuffle = True if mode == 'train' else False if mode == "train": sampler = paddle.io.DistributedBatchSampler( dataset=dataset, batch_size=batch_size, shuffle=shuffle) else: sampler = paddle.io.BatchSampler( dataset=dataset, batch_size=batch_size, shuffle=shuffle) dataloader = paddle.io.DataLoader( dataset, batch_sampler=sampler, collate_fn=batchify_fn) return dataloader if __name__ == "__main__": paddle.set_device(args.device) set_seed(1000) # Loads dataset. train_ds, dev_ds = load_dataset("chnsenticorp", splits=["train", "dev"]) texts = [] for data in train_ds: texts.append(data["text"]) for data in dev_ds: texts.append(data["text"]) .............

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
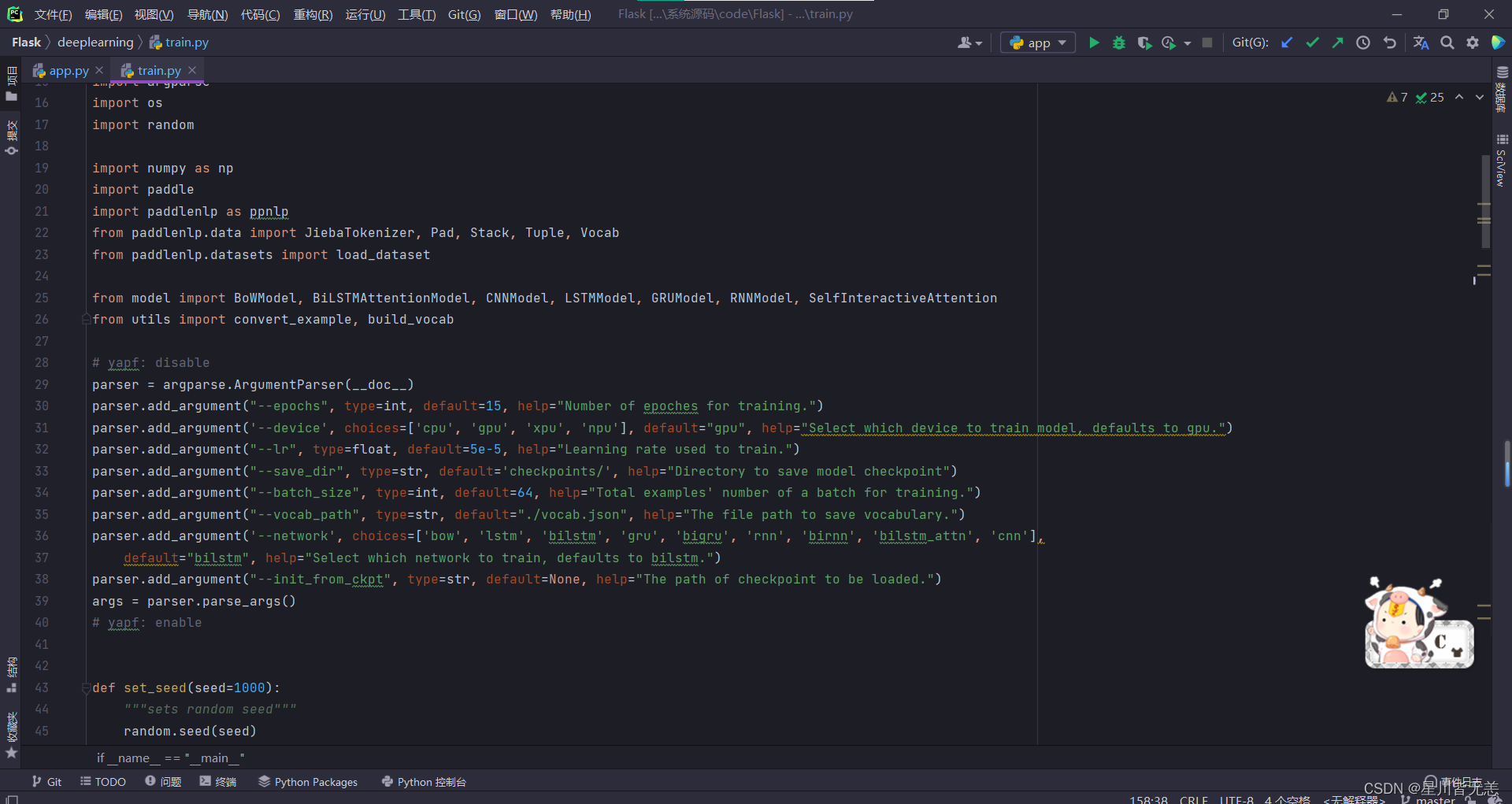
这里是一个基于 PaddlePaddle 深度学习框架实现的文本分类模型训练代码。思路给大家讲解一下:
1、导入必要的库和模块,包括 PaddlePaddle、PaddleNLP、数据预处理模块等。
2、定义命令行参数,用于控制模型训练的一些参数,包含epochs(训练轮数)、device(设备选择)、lr(学习率)、network(网络选择)等。
3、设置随机种子,保证训练的可复现性。
4、创建数据加载器函数,用于加载数据集并生成 mini-batches。
5、加载数据集,包括训练集和验证集,并进行词汇表的构建。
6、构建文本分类模型,根据选择的网络类型构建不同的模型,这里具体包含了 BoW 模型(Bag of Words 模型)、BiLSTM 模型(双向 LSTM 模型)和 CNN 模型(卷积神经网络模型)的实现部分。
根据 args.network 参数的选择,可以构建不同类型的文本分类模型,具体包括如下:
BoW 模型:使用 BoWModel 类来构建基于Bag of Words 的文本分类模型。
BiLSTM 模型:使用 LSTMModel 类来构建双向 LSTM 模型。
CNN 模型:使用CNNModel 类来构建卷积神经网络模型。
7、对数据进行预处理,包括分词、转换为序列、标签编码等操作。
8、设置优化器、损失函数和评估指标。
9、开始模型的训练和评估,同时支持加载预训练参数进行 fine-tuning。
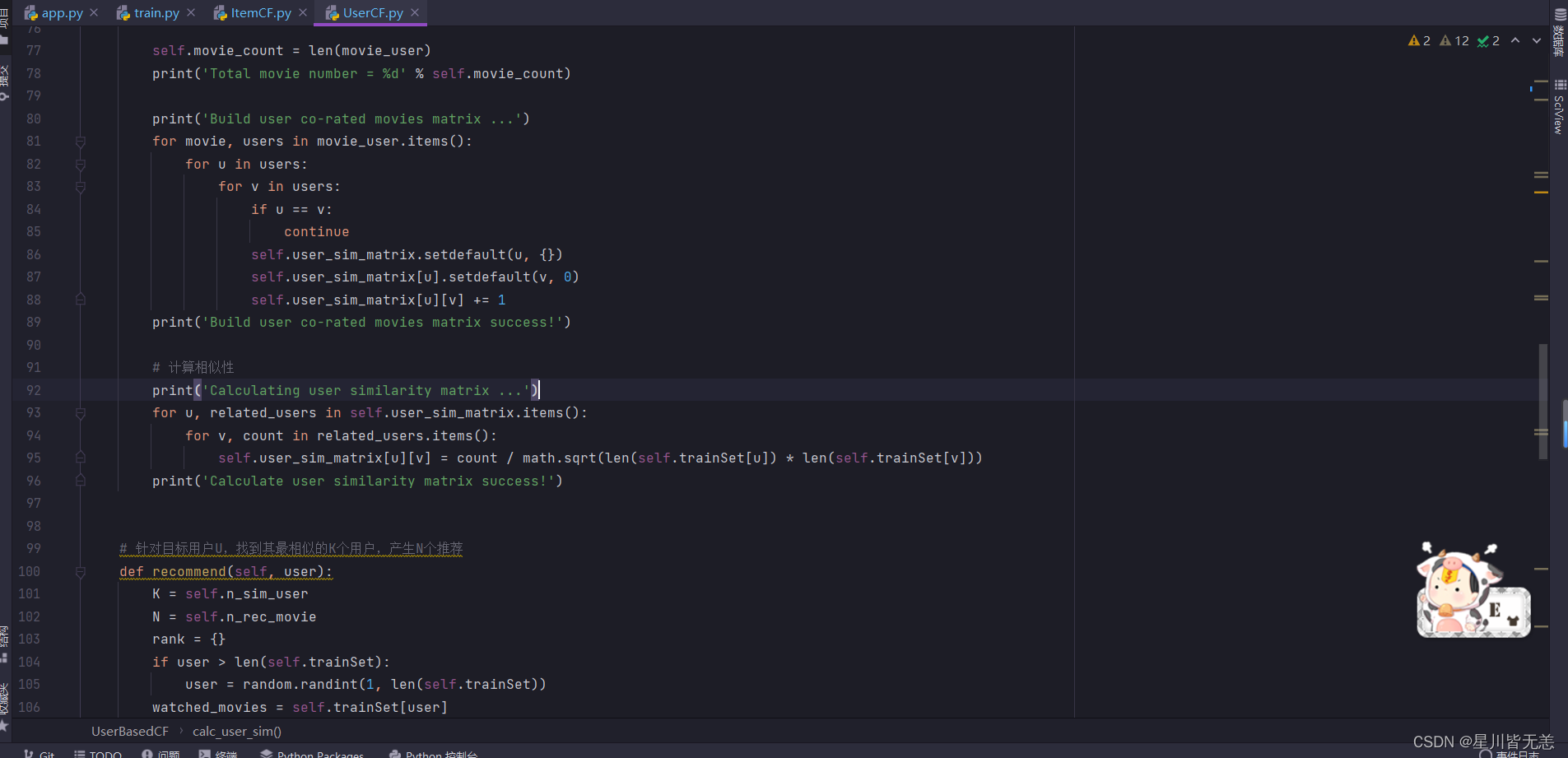
基于用户的协同过滤推荐算法实现部分代码截图
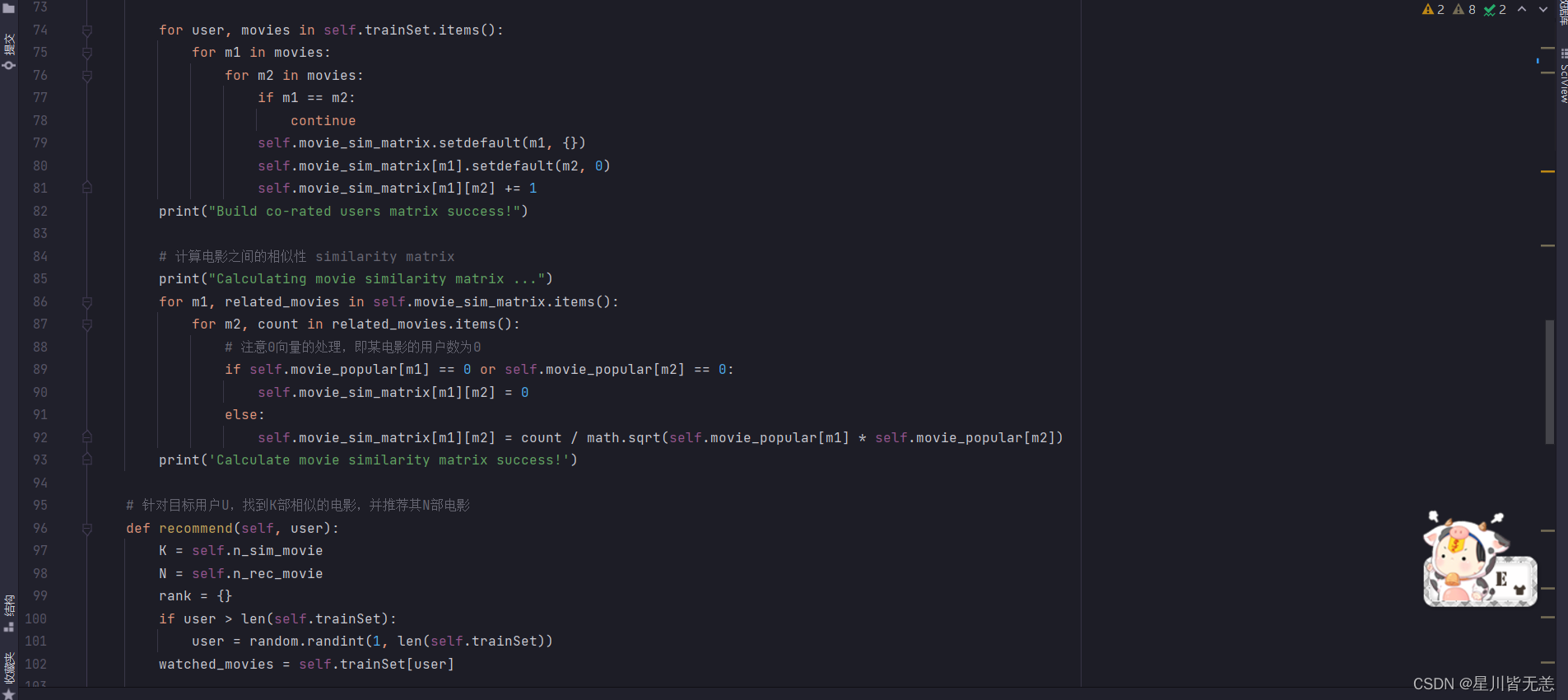
基于物品的协同过滤推荐算法实现部分代码截图
系统实现
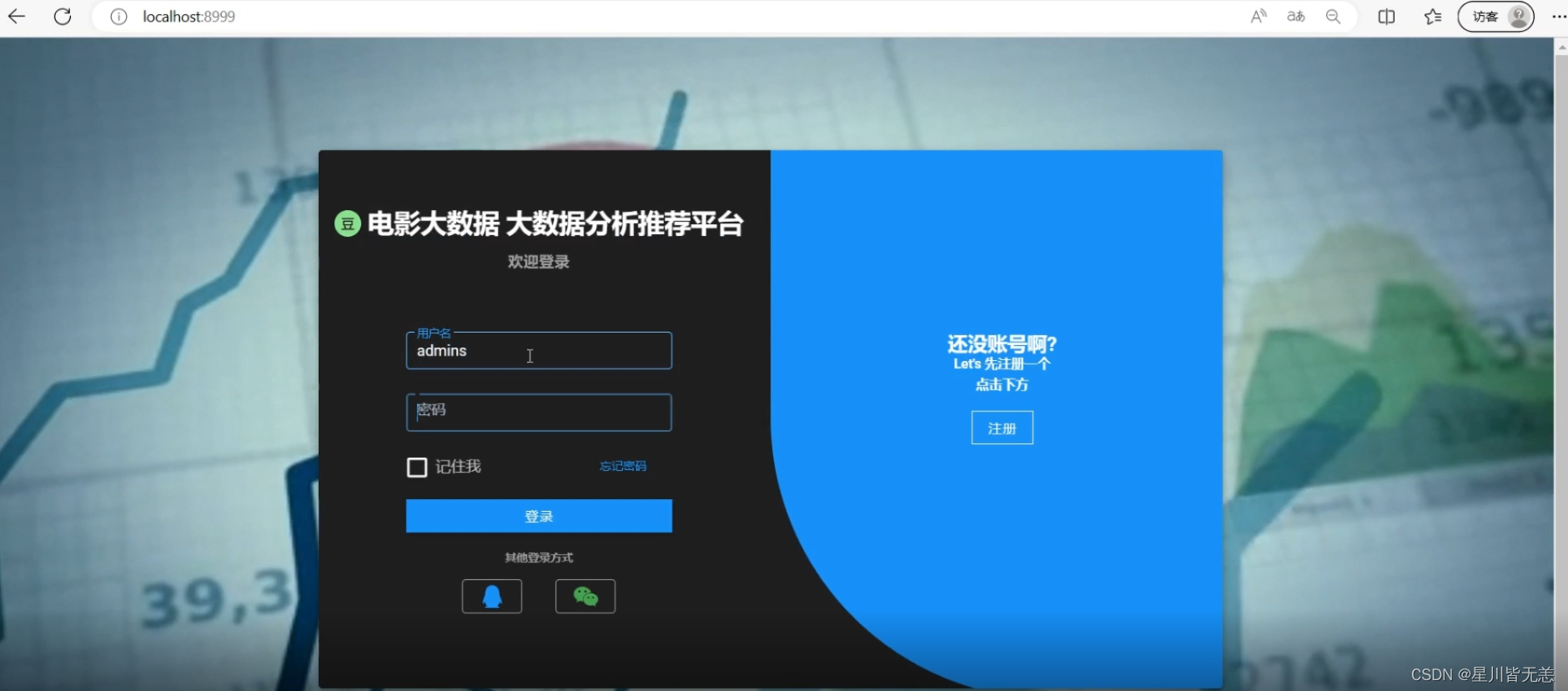
用户登录注册
系统主页
导航栏——电影库
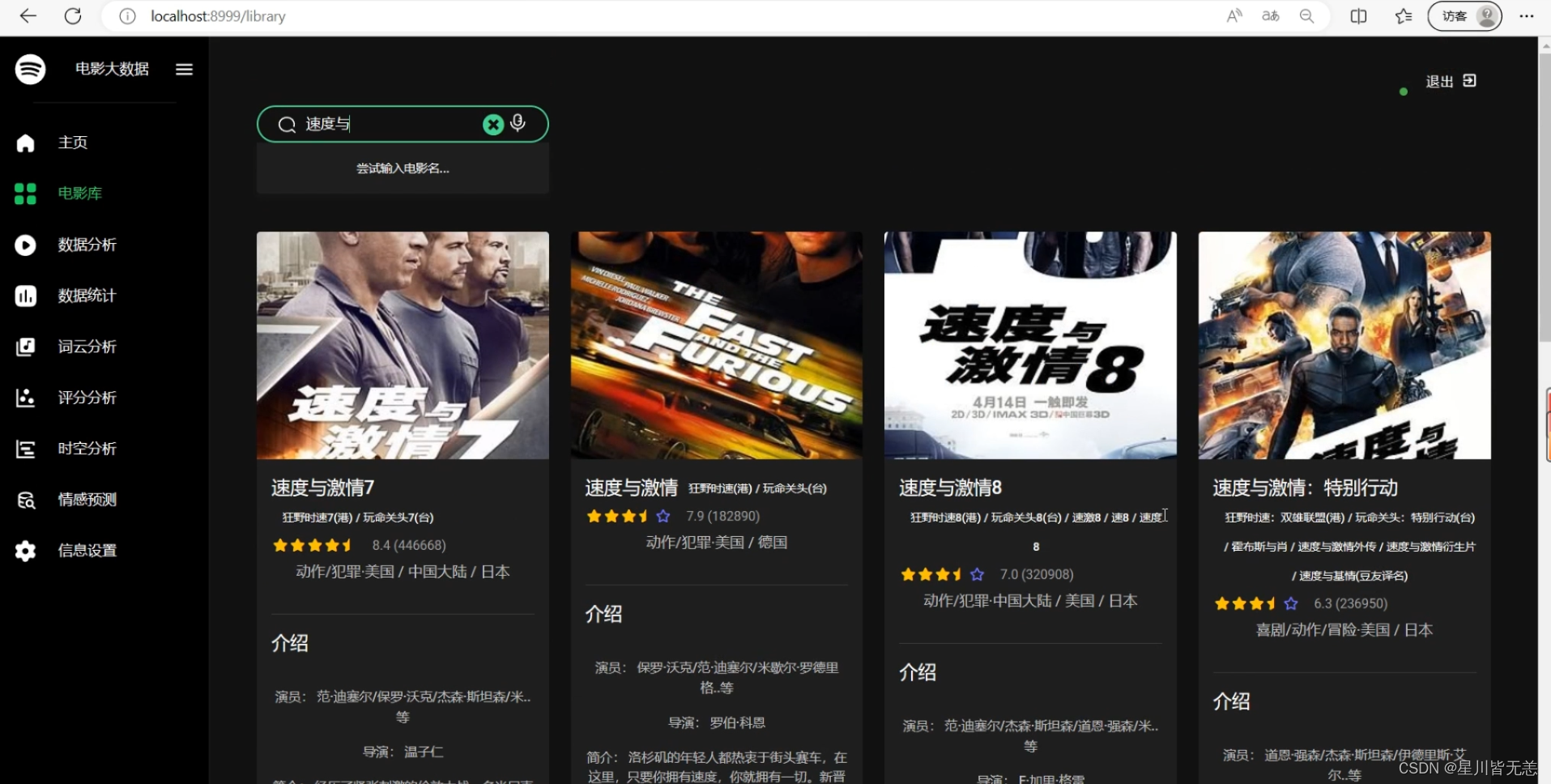
输入电影名进行电影搜索,查看电影评论情感分析
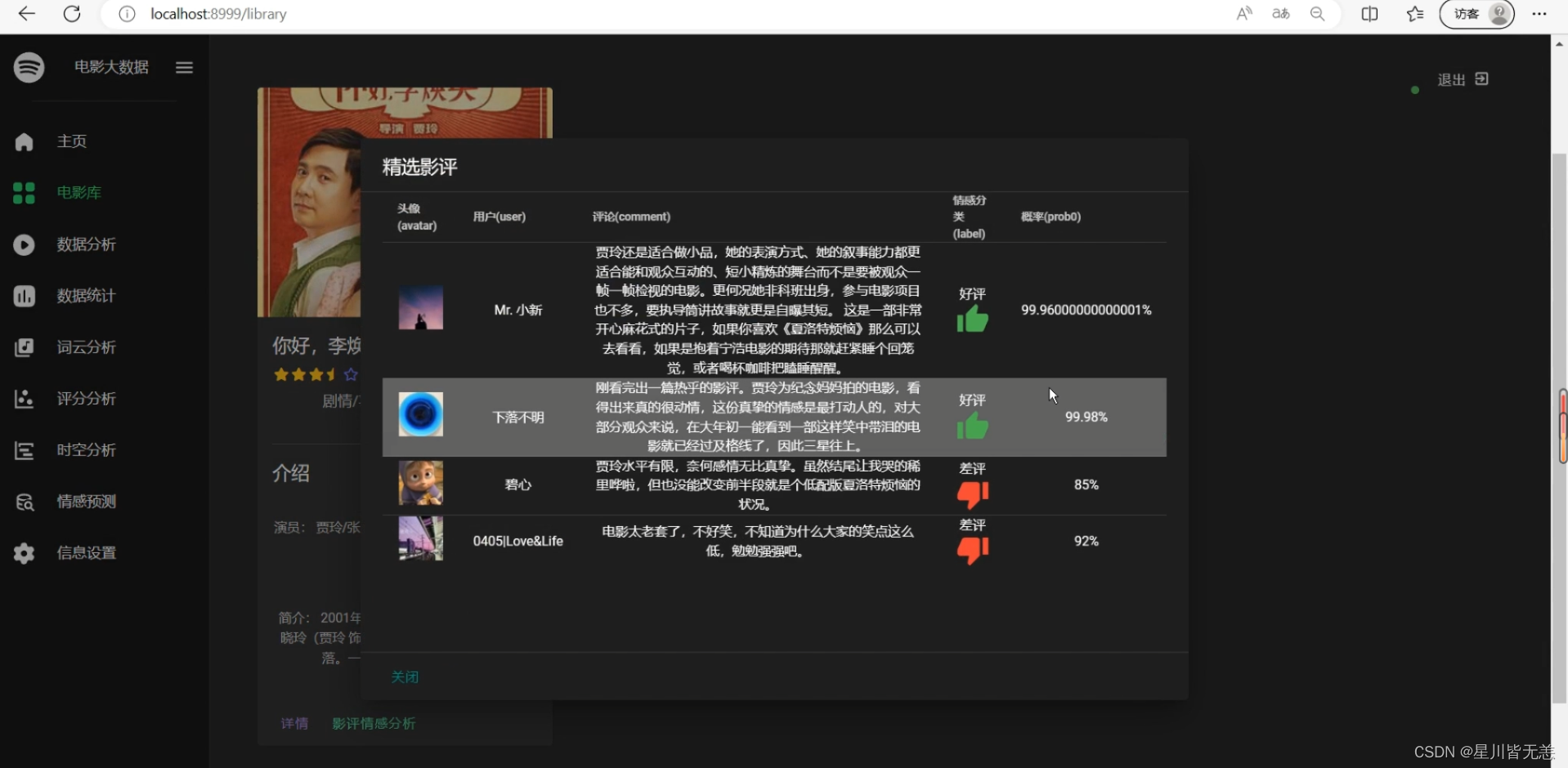
电影查询
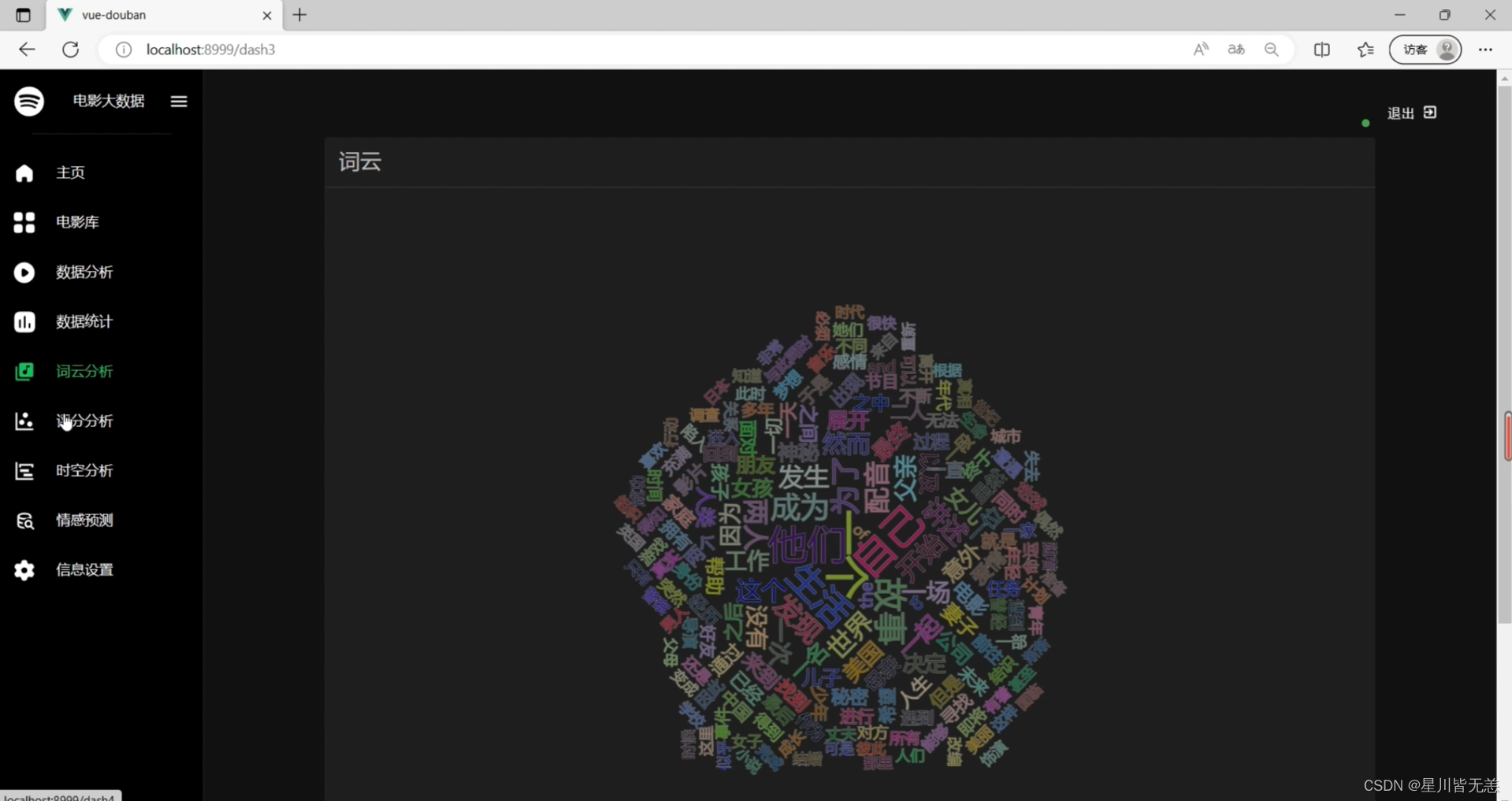
电影数据词云可视化分析
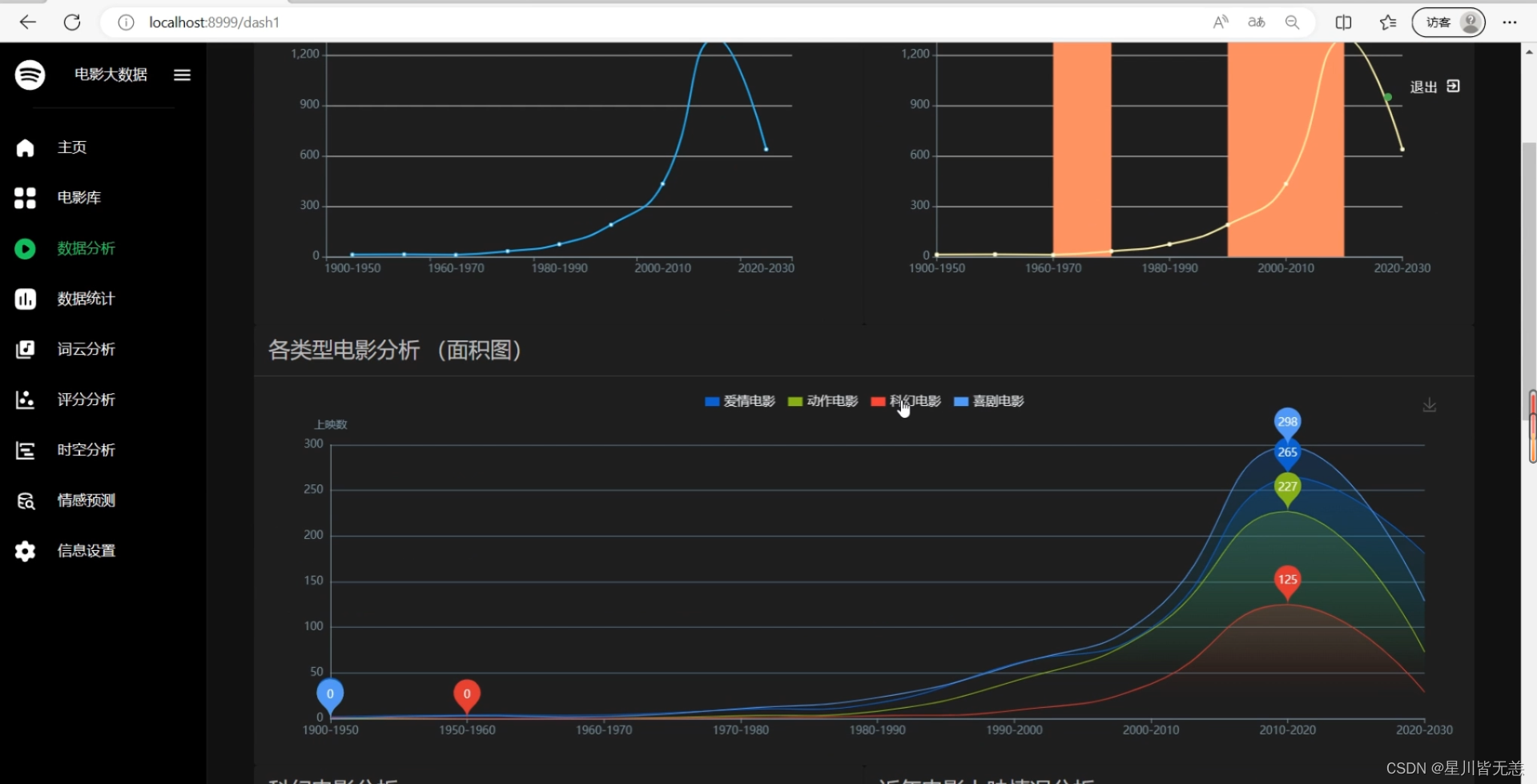
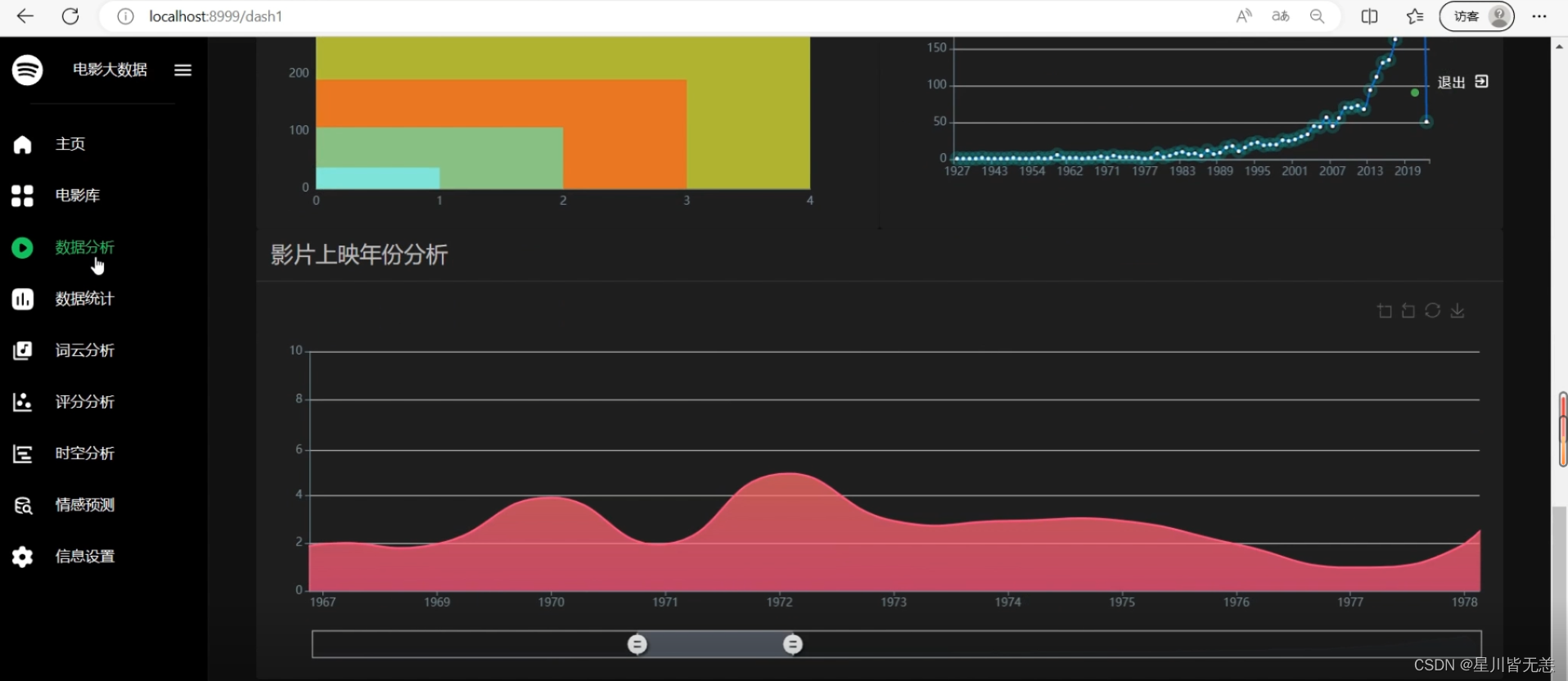
电影数据可视化分析
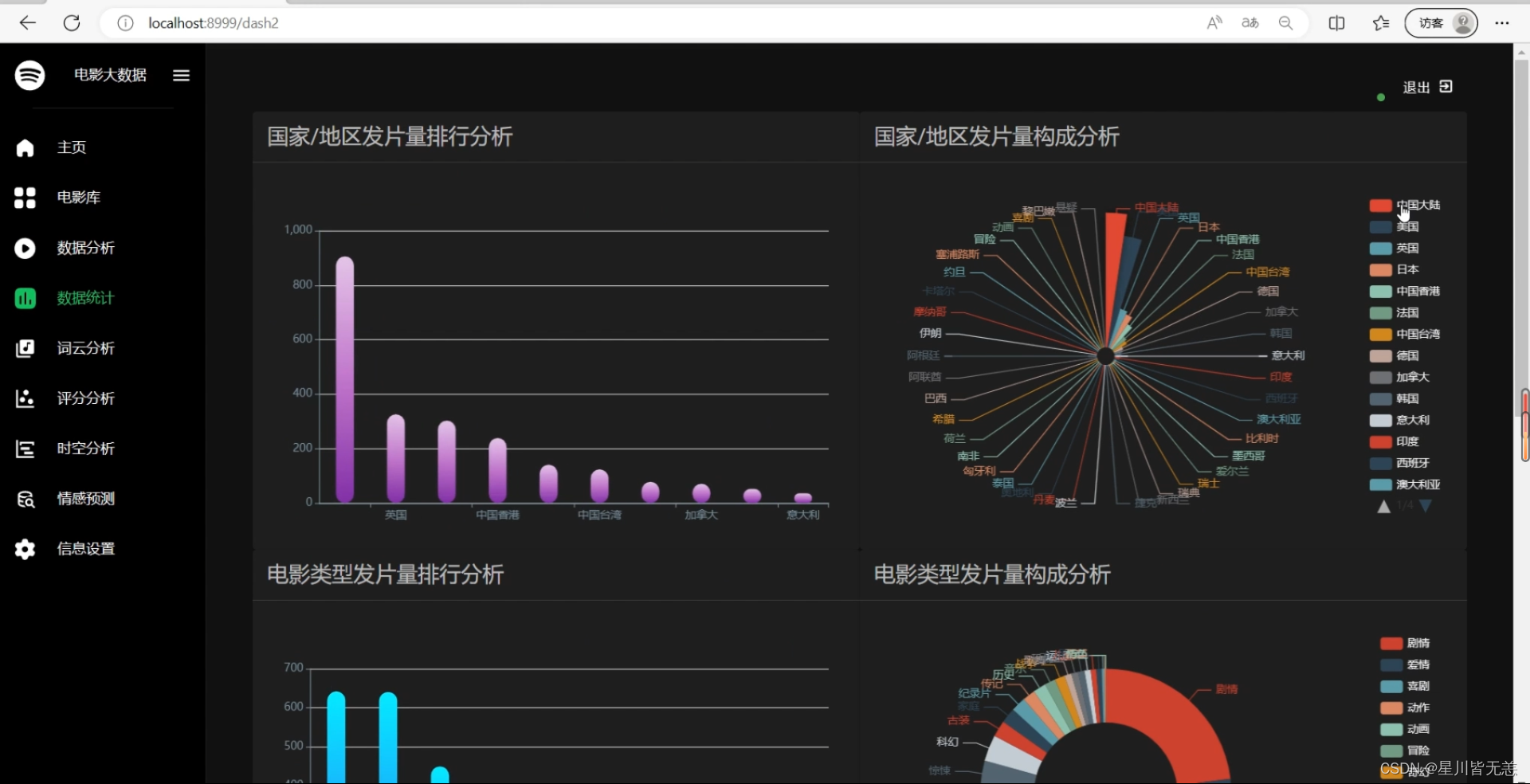
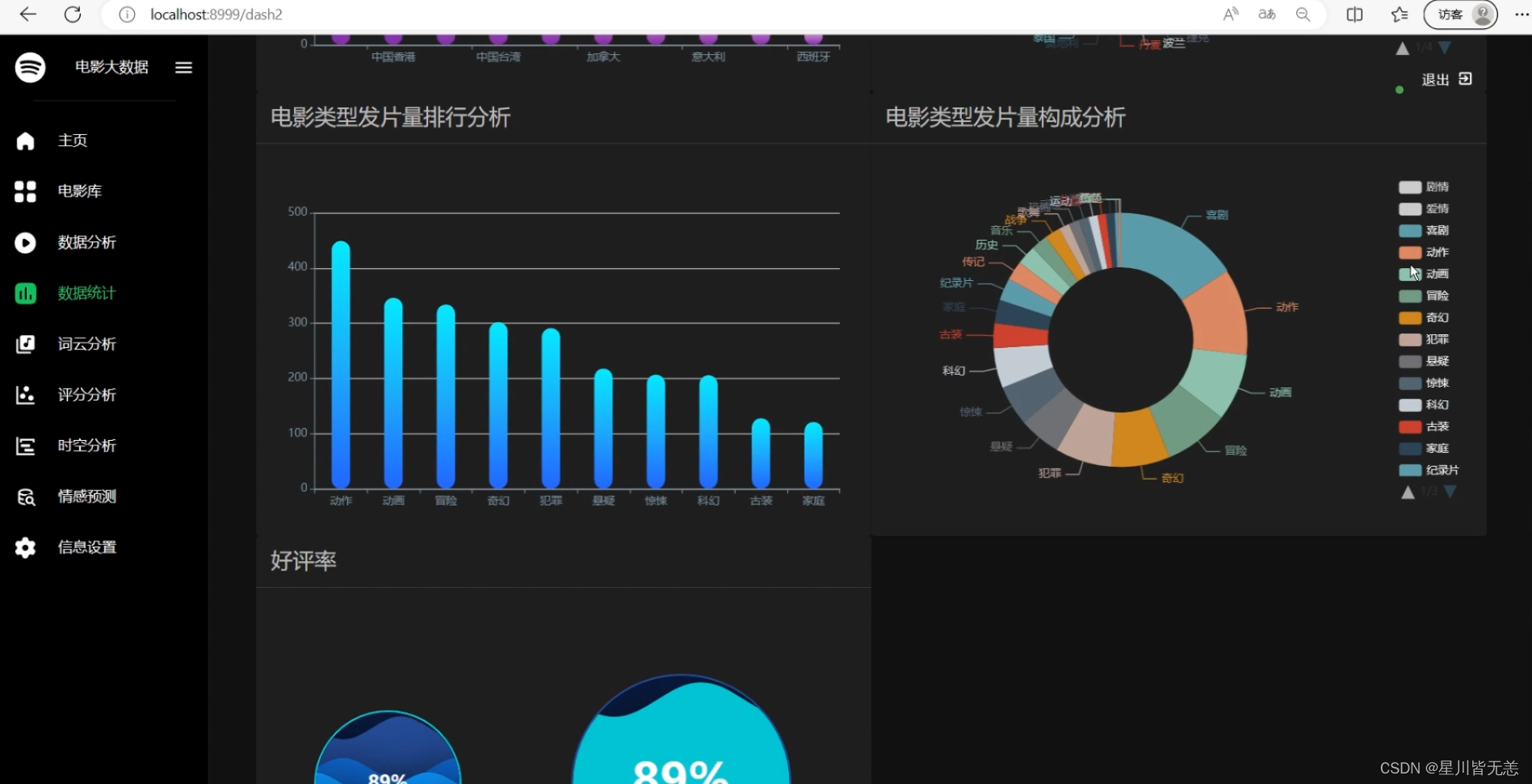
系统用户个人信息
电影数据分析——不同国家地区可视化

电影数据爬虫
这里我们把爬虫脚本接口直接封装到run.py里面,直接运行该脚本就可以直接调用scrapy爬虫,非常方便。
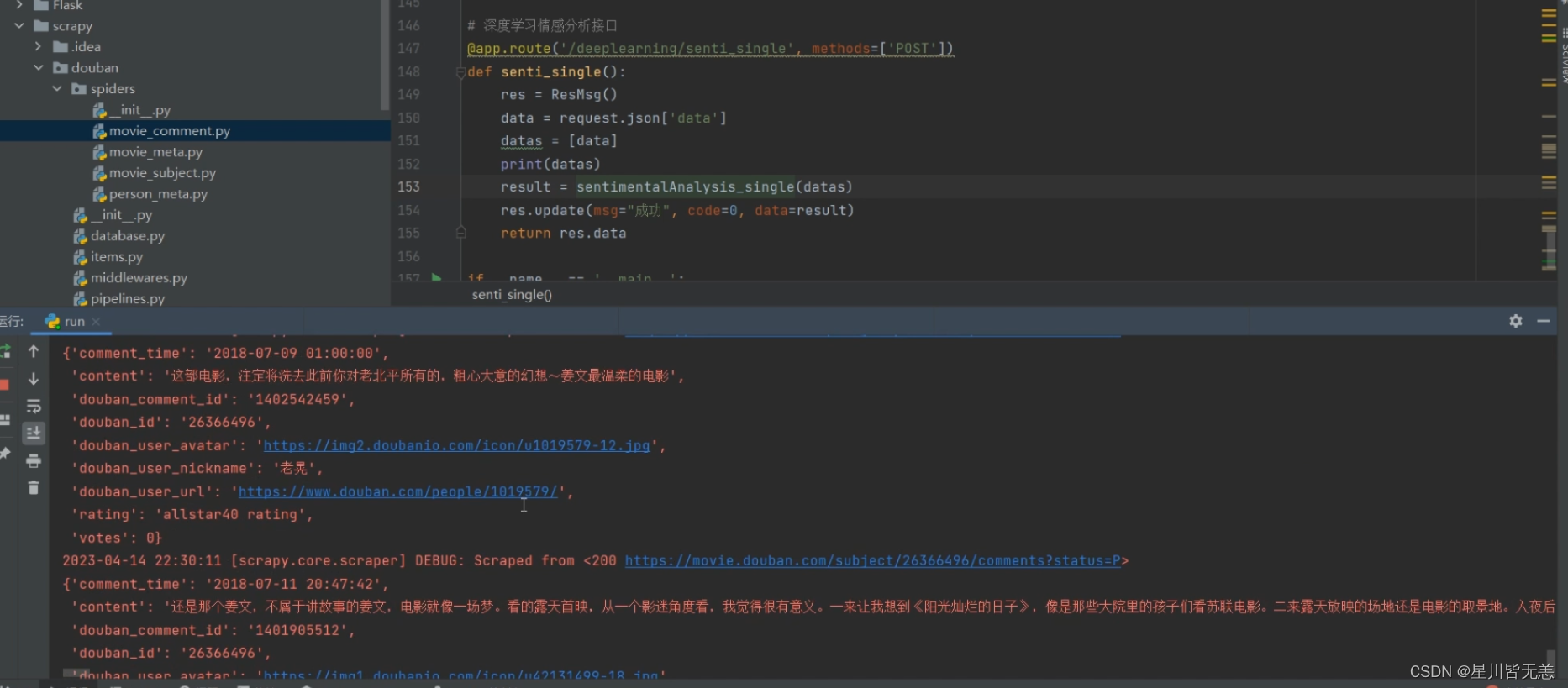
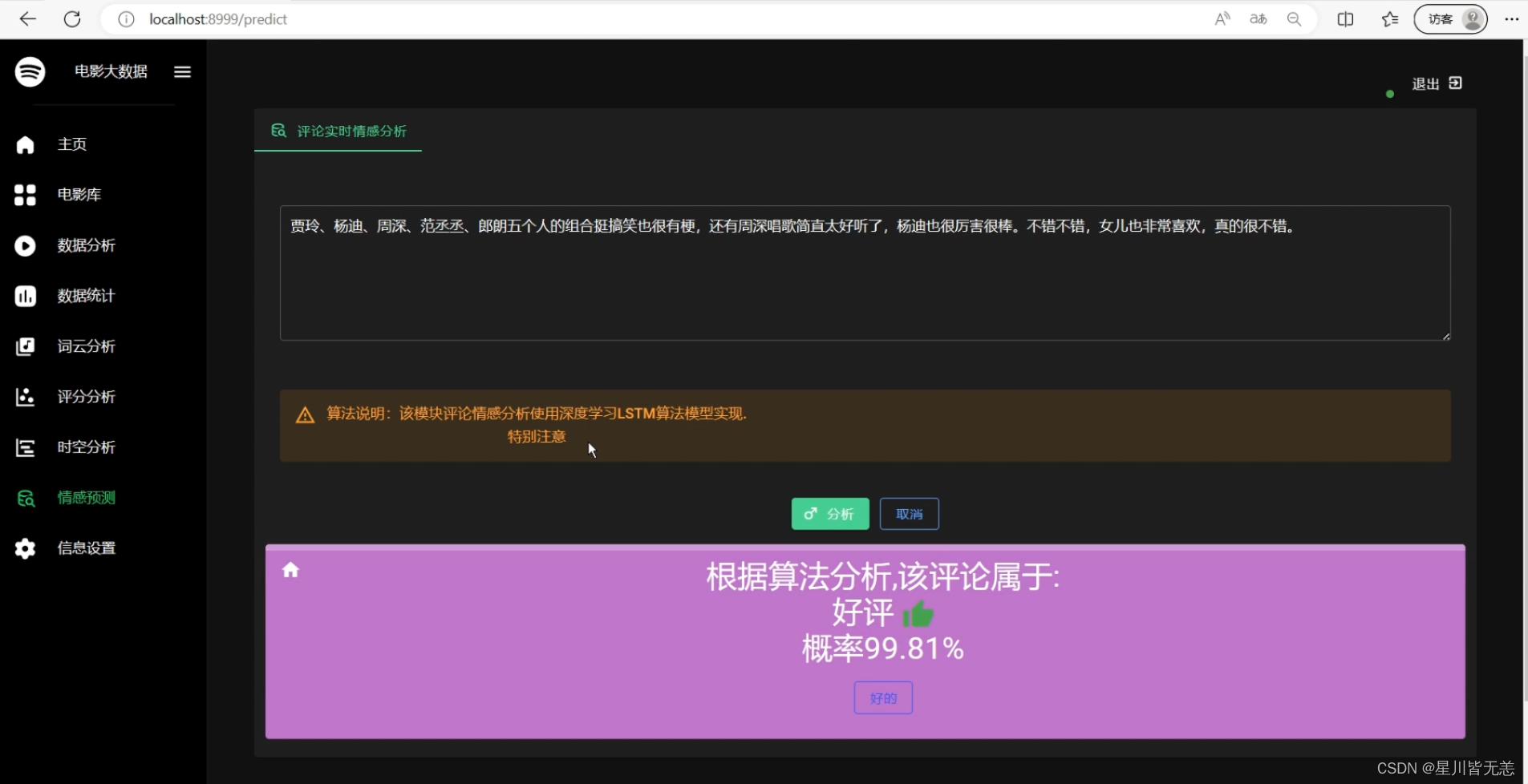
情感分析
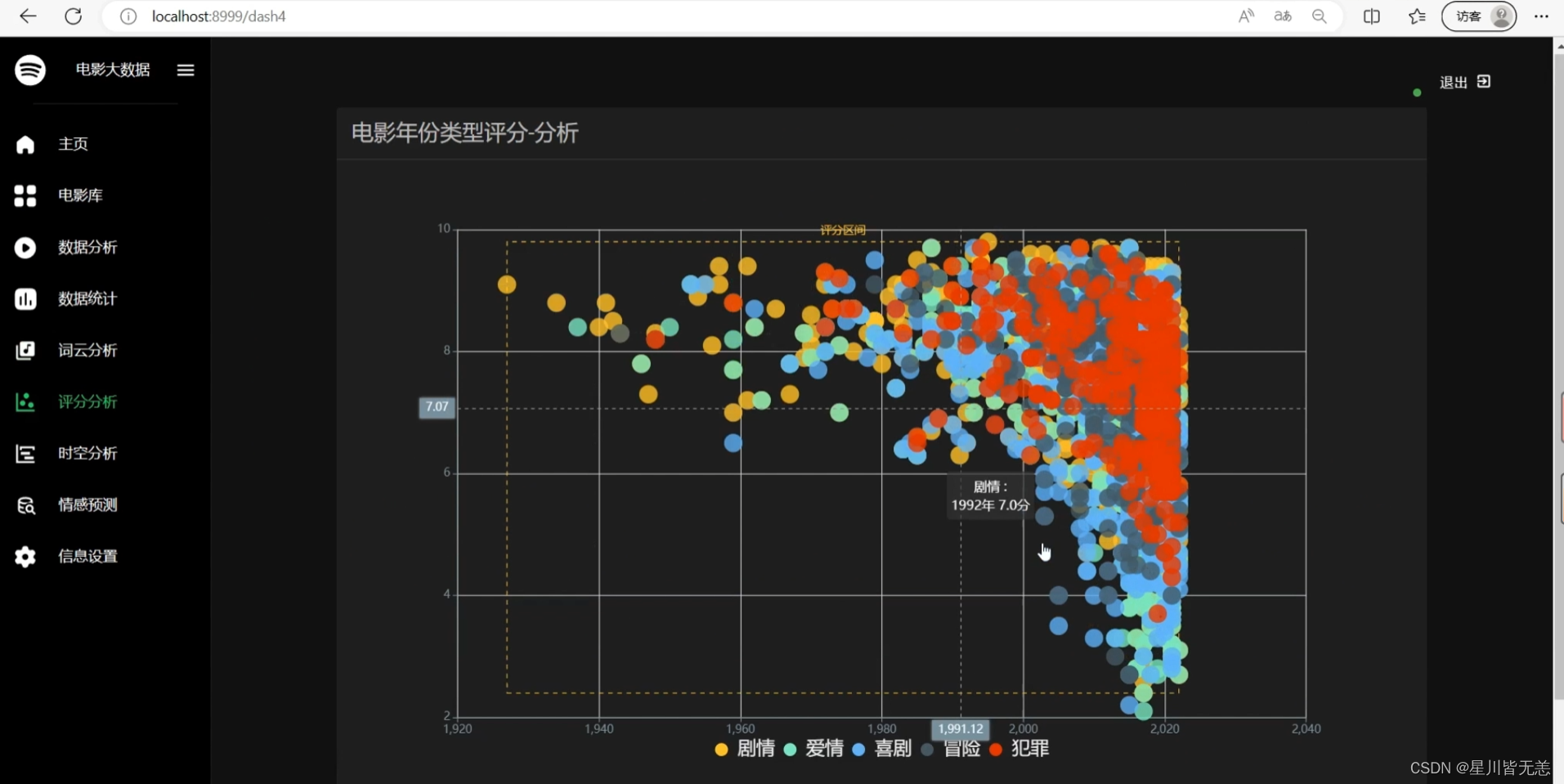
电影评分可视化分析
结语
需项目资料/商业合作/交流探讨等可以添加下面个人名片,后续有时间会持续更新更多优质项目内容,感谢各位的喜欢与支持!

