
- 1《Hadoop权威指南》第三章 Hadoop分布式文件系统_httpfs 性能瓶颈
- 2python 实现批量抠图_python一键抠图
- 3java时钟程序报告,Java小时钟程序
- 4计算机网络冲刺串讲,计算机应用基础串讲冲刺讲义(二)
- 5面试季:如何在面试中介绍自己的项目经验,如何快速得到提升?_开发面试问做这个项目得到了什么提升
- 6安装 Az PowerShell,连接管理 Azure_install the az powershell module
- 7HarmonyOS DevEco SDK 无法下载问题的解决方案_hvigor error: sdk download failed.
- 8Linux计划任务中cron--anacron--logrotate的关系_/bin/sh /etc/cron.hourly/0anacron
- 9EM算法,超全解释_em算法是什么意思
- 10用贪心算法编程求解任务安排问题_swust oj: 71:task scheduling 一个单位时间任务是恰好需要一个单位时间完成
【滑动窗口算法思维】数组类题目
赞
踩
声明:博主是基于
labuladong微信公众号文章模板驱动刷题,进行的自我刷题感悟和记录在此。
模板详情见labuladong微信公众号文章文末;原创于自己在此基础上的笔记、感悟、整合其它文献和自己的code。
今天在滑动窗口算法框架中,我再次编写一首小诗来歌颂滑动窗口算法的伟大:
》
以上记忆方法修改为好记的:
链表子串数组题,用双指针别犹豫。双指针家三兄弟,个个都是万人迷。
快慢指针最神奇,链表操作无压力。归并排序找中点,链表成环搞判定。
左右指针最常见,翻转数组要靠他。左右两端相向行,二分搜索是弟弟。
滑动窗口最 n b ,子串问题全靠它。左右指针滑窗口,一前一后搞判定。
关于双指针的快慢指针和左右指针的用法,可以参见前文 双指针技巧汇总,本文就解决一类最难掌握的双指针技巧:滑动窗口技巧,并总结出一套框架,可以保你闭着眼直接套出答案。
注意虽然滑动窗口的框架很诱人,但是容易陷入 思维定势——即容易造成【基于lcT3来看】:
1. 造成左闭右开的定势,但是我们思考时容易使用左闭右闭——指的操作都完成之后 最后才加加窗口/滑动窗口;
2. 容易造成一直需要while()的定势;
3. 容易造成不习惯于考虑边界的定势。 —— 即算法另一面。
hhh,以上划掉重来——缘由还是因为自己没能了解透彻 这套滑动窗口的本质【同志还是需要不断做题来巩固和透彻题目本质啊!】;
具体领悟见文末的——lcT3。
说起滑动窗口算法,很多读者都会头疼。这个算法技巧的思路非常简单,就是维护一个窗口,不断滑动,然后更新答案么。LeetCode 上有起码 10 道运用滑动窗口算法的题目,难度都是中等和困难。该算法的大致逻辑如下:
int left = 0, right = 0;
while (right < s.size()) {
// 增大窗口
window.add(s[right]);
right++;
while (window needs shrink) {
// 缩小窗口
window.remove(s[left]);
left++;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个算法技巧的时间复杂度是 O(N),比一般的字符串暴力算法要高效得多。
其实困扰大家的,不是算法的思路,而是各种细节问题。 比如说如何向窗口中添加新元素,如何缩小窗口,在窗口滑动的哪个阶段更新结果。即便你明白了这些细节,也容易出 bug,找 bug 还不知道怎么找,真的挺让人心烦的。
所以今天我就写一套滑动窗口算法的代码框架,我连在哪里做输出 debug 都给你写好了,以后遇到相关的问题,你就默写出来如下框架然后改三个地方就行,还不会出边界问题:
/* 滑动窗口算法框架 */ void slidingWindow(string s, string t) { unordered_map<char, int> need, window; for (char c : t) need[c]++; int left = 0, right = 0; int valid = 0; while (right < s.size()) { // c 是将移入窗口的字符 char c = s[right]; // 右移窗口 right++; // 进行窗口内数据的一系列更新 ... /*** debug 输出的位置 ***/ printf("window: [%d, %d)\n", left, right); /********************/ // 判断左侧窗口是否要收缩 while (window needs shrink) { // d 是将移出窗口的字符 char d = s[left]; // 左移窗口 left++; // 进行窗口内数据的一系列更新 ... } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
其中两处…表示的更新窗口数据的地方,到时候你直接往里面填就行了。
而且,这两个…处的操作分别是右移和左移窗口更新操作,等会你会发现它们操作是完全对称的。
说句题外话,其实有很多人喜欢执着于表象,不喜欢探求问题的本质。比如说有很多人评论我这个框架,说什么散列表速度慢,不如用数组代替散列表;还有很多人喜欢把代码写得特别短小,说我这样代码太多余,影响编译速度,LeetCode 上速度不够快。
我也是服了,算法看的是时间复杂度,你能确保自己的时间复杂度最优就行了。至于 LeetCode 所谓的运行速度,那个都是玄学,只要不是慢的离谱就没啥问题,根本不值得你从编译层面优化,不要舍本逐末……
labuladong 公众号的重点在于算法思想,你把框架思维了然于心套出解法,然后随你再魔改代码好吧,你高兴就好。
言归正传,下面就直接上四道 LeetCode 原题来套这个框架,其中第一道题会详细说明其原理,后面四道就直接闭眼睛秒杀了。
本文代码为 C++ 实现,不会用到什么编程方面的奇技淫巧,但是还是简单介绍一下一些用到的数据结构,以免有的读者因为语言的细节问题阻碍对算法思想的理解:
unordered_map就是哈希表(字典),它的一个方法count(key)相当于 Java 的containsKey(key)可以判断键 key 是否存在。
可以使用方括号访问键对应的值map[key]。需要注意的是,如果该key不存在,C++ 会自动创建这个 key,并把map[key]赋值为 0。
所以代码中多次出现的map[key]++相当于 Java 的map.put(key, map.getOrDefault(key, 0) + 1)。
一、最小覆盖子串
LeetCode 76 题,Minimum Window Substring,难度 Hard,我带大家看看它到底有多 Hard:

就是说要在S(source) 中找到包含T(target) 中全部字母的一个子串,且这个子串一定是所有可能子串中最短的。
如果我们使用暴力解法,代码大概是这样的:
for (int i = 0; i < s.size(); i++)
for (int j = i + 1; j < s.size(); j++)
if s[i:j] 包含 t 的所有字母:
更新答案
- 1
- 2
- 3
- 4
思路很直接,但是显然,这个算法的复杂度肯定大于 O(N^2) 了,不好。
滑动窗口算法的思路是这样:
1、我们在字符串S中使用双指针中的左右指针技巧,初始化left = right = 0,把索引左闭右开区间[left, right)称为一个「窗口」。
2、我们先不断地增加right指针扩大窗口[left, right),直到窗口中的字符串符合要求(包含了T中的所有字符)。
3、此时,我们停止增加right,转而不断增加left指针缩小窗口[left, right),直到窗口中的字符串不再符合要求(不包含T中的所有字符了)。同时,每次增加left,我们都要更新一轮结果。
4、重复第 2 和第 3 步,直到right到达字符串S的尽头。
这个思路其实也不难,第 2 步相当于在寻找一个「可行解」,然后第 3 步在优化这个「可行解」,最终找到最优解,也就是最短的覆盖子串。左右指针轮流前进,窗口大小增增减减,窗口不断向右滑动,这就是「滑动窗口」这个名字的来历。
下面画图理解一下,needs和window相当于计数器,分别记录T中字符出现次数和「窗口」中的相应字符的出现次数。
初始状态:
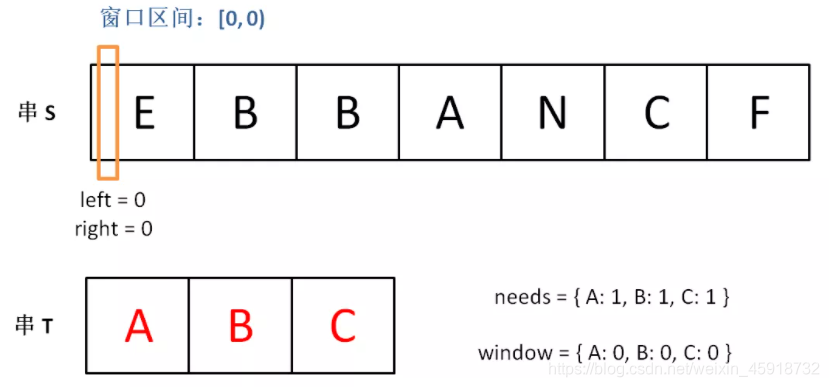
增加right,直到窗口[left, right)包含了T中所有字符:
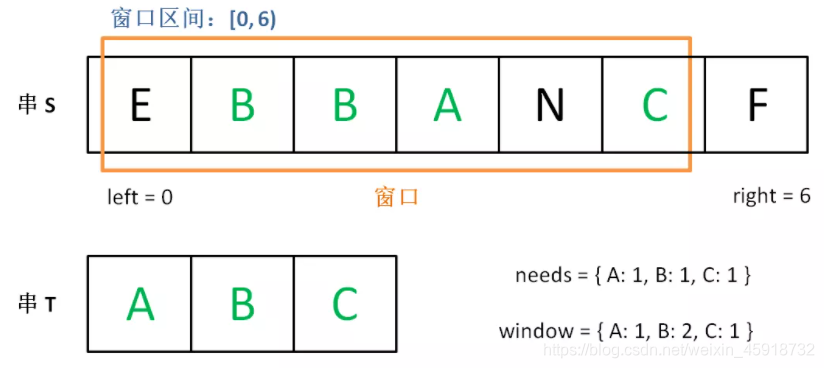
现在开始增加left,缩小窗口[left, right)。
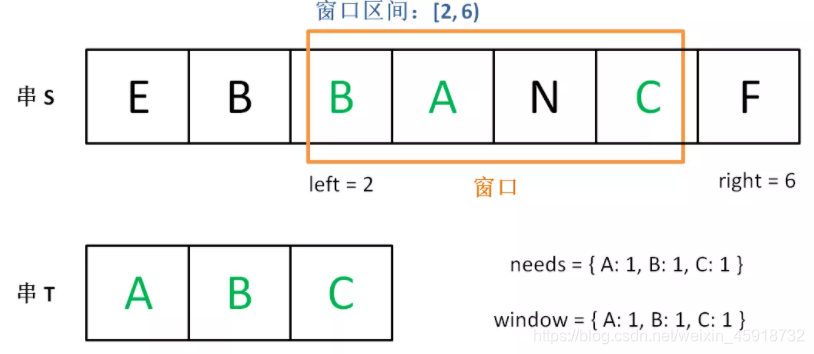
直到窗口中的字符串不再符合要求,left不再继续移动。
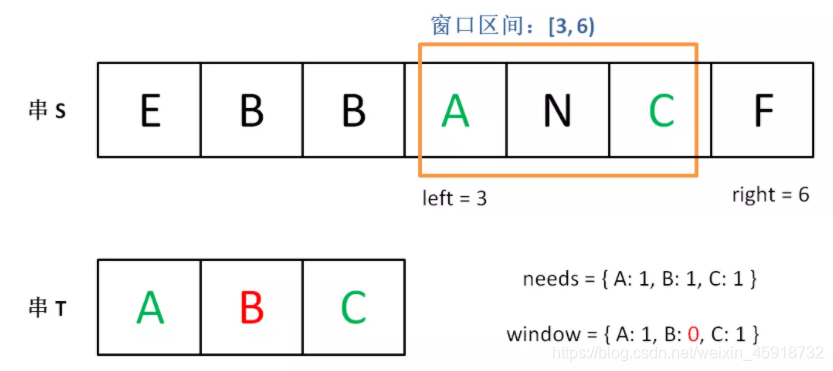
之后重复上述过程,先移动right,再移动left…… 直到right指针到达字符串S的末端,算法结束。
如果你能够理解上述过程,恭喜,你已经完全掌握了滑动窗口算法思想。现在我们来看看这个滑动窗口代码框架怎么用:
首先,初始化window和need两个哈希表,记录窗口中的字符和需要凑齐的字符:
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
- 1
- 2
然后,使用left和right变量初始化窗口的两端,不要忘了,区间[left, right)是左闭右开的,所以初始情况下窗口没有包含任何元素:
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// 开始滑动
}
- 1
- 2
- 3
- 4
- 5
其中valid变量表示窗口中满足need条件的字符个数,如果valid和need.size的大小相同,则说明窗口已满足条件,已经完全覆盖了串T。
现在开始套模板,只需要思考以下四个问题:
1、当移动right扩大窗口,即加入字符时,应该更新哪些数据?
2、什么条件下,窗口应该暂停扩大,开始移动left缩小窗口?
3、当移动left缩小窗口,即移出字符时,应该更新哪些数据?
4、我们要的结果应该在扩大窗口时还是缩小窗口时进行更新?
如果一个字符进入窗口,应该增加window计数器;如果一个字符将移出窗口的时候,应该减少window计数器;当valid满足need时应该收缩窗口;应该在收缩窗口的时候更新最终结果。
下面是完整代码:
string minWindow(string s, string t) { unordered_map<char, int> need, window; for (char c : t) need[c]++; int left = 0, right = 0; int valid = 0; // 记录最小覆盖子串的起始索引及长度 int start = 0, len = INT_MAX; while (right < s.size()) { // c 是将移入窗口的字符 char c = s[right]; // 右移窗口 right++; // 进行窗口内数据的一系列更新 if (need.count(c)) { window[c]++; if (window[c] == need[c]) valid++; } // 判断左侧窗口是否要收缩 while (valid == need.size()) { // 在这里更新最小覆盖子串 if (right - left < len) { start = left; len = right - left; } // d 是将移出窗口的字符 char d = s[left]; // 左移窗口 left++; // 进行窗口内数据的一系列更新 if (need.count(d)) { if (window[d] == need[d]) valid--; window[d]--; } } } // 返回最小覆盖子串 return len == INT_MAX ? "" : s.substr(start, len); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
注意关键是:1.valid在扩张和收缩窗口时操作条件;2.window,need 结构理解——它们是输入<char,int>的,所以可以计数且 只存放有用的字符数目!!!;3.更新len 或 最小子串要求——注意要 左闭右开;4.基于<2.>我们有 左右窗口通过[左右指针实现,窗口window只是为了找最小子串而存放最小字符。]
if( window[r] == need[r]) // 关键 因为:重点理解了 这样才能使用 valid == need.size() —— 即直接用size 表示 收缩的条件的原因/本质。
需要注意的是,当我们发现某个字符在window的数量满足了need的需要,就要更新valid,表示有一个字符已经满足要求。而且,你能发现,两次对窗口内数据的更新操作是完全对称的。
当valid == need.size()时,说明T中所有字符已经被覆盖,已经得到一个可行的覆盖子串,现在应该开始收缩窗口了,以便得到「最小覆盖子串」。
移动left收缩窗口时,窗口内的字符都是可行解,所以应该在收缩窗口的阶段进行最小覆盖子串的更新,以便从可行解中找到长度最短的最终结果。
至此,应该可以完全理解这套框架了,滑动窗口算法又不难,就是细节问题让人烦得很。 以后遇到滑动窗口算法,你就按照这框架写代码,保准没有 bug,还省事儿。
下面就直接利用这套框架秒杀几道题吧,你基本上一眼就能看出思路了。
二、字符串排列
LeetCode 567 题,Permutation in String,难度 Medium:

注意哦,输入的s1是可以包含重复字符的,所以这个题难度不小。
这种题目,是明显的滑动窗口算法,相当给你一个S和一个T,请问你S中是否存在一个子串,包含T中所有字符且不包含其他字符?
首先,先复制粘贴之前的算法框架代码,然后明确刚才提出的 4 个问题,即可写出这道题的答案:
// 判断 s 中是否存在 t 的排列 bool checkInclusion(string t, string s) { unordered_map<char, int> need, window; for (char c : t) need[c]++; int left = 0, right = 0; int valid = 0; while (right < s.size()) { char c = s[right]; right++; // 进行窗口内数据的一系列更新 if (need.count(c)) { window[c]++; if (window[c] == need[c]) valid++; } // 判断左侧窗口是否要收缩 while (right - left >= t.size()) { // 我的实现在下面 不一样. // 在这里判断是否找到了合法的子串 if (valid == need.size()) return true; char d = s[left]; left++; // 进行窗口内数据的一系列更新 if (need.count(d)) { if (window[d] == need[d]) valid--; window[d]--; } } } // 未找到符合条件的子串 return false; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
对于这道题的解法代码,基本上和最小覆盖子串一模一样,只需要改变两个地方:
1、本题移动left缩小窗口的时机是窗口大小大于t.size()时,因为排列嘛,显然长度应该是一样的。
2、当发现valid == need.size()时,就说明窗口中就是一个合法的排列,所以立即返回true。
至于如何处理窗口的扩大和缩小,和最小覆盖子串完全相同。
下面为我的 本题完整实现。
#include <iostream> #include <map> #include <vector> #include <windows.h> #include <unordered_map> using namespace std; class Solution { public: bool checkInclusion(string s1, string s2) { unordered_map<char, int> need, window; // need最小子串有效字符,window也是有效最小子串字符;左右窗口大小由 [left, right)控制 int left=0, right=0, valid=0; for(char c:s1) need[c]++; int start = 0, len = INT_MAX; while( right < s2.size() ){ // 右边的添加到窗口 扩大窗口 char r = s2[right]; // window[s[right]]++; right++; // 所以数据集是左闭右开的 // 进行窗口内数据的一系列更新 if(need.count(r) > 0){ window[r]++; if( window[r] == need[r]) // 关键 valid++; } /*** debug 输出的位置 ***/ printf("window: [%d, %d)\n", left, right); /********************/ while( valid == need.size() ){ len = right-left;//diff if( len == s1.size() ){//diff return true; } // window[s[left]]--; char l = s2[left]; left++; // 更新窗口 以及 最终结果判定 if(need.count(l) > 0){ window[l]--; if(window[l] < need[l]) valid--; } } } return false; } }; int main() { string s1 = "ab", s2 = "eidbaooo"; Solution s; bool bo = s.checkInclusion(s1,s2); cout<<"是否包含最小子串:" << bo << endl; system("pause"); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
三、找所有字母异位词
这是 LeetCode 第 438 题,Find All Anagrams in a String,难度 Medium:

呵呵,这个所谓的字母异位词,不就是排列吗,搞个高端的说法就能糊弄人了吗?相当于,输入一个串S,一个串T,找到S中所有T的排列,返回它们的起始索引。
直接默写一下框架,明确刚才讲的 4 个问题,即可秒杀这道题:
vector<int> findAnagrams(string s, string t) { unordered_map<char, int> need, window; for (char c : t) need[c]++; int left = 0, right = 0; int valid = 0; vector<int> res; // 记录结果 while (right < s.size()) { char c = s[right]; right++; // 进行窗口内数据的一系列更新 if (need.count(c)) { window[c]++; if (window[c] == need[c]) valid++; } // 判断左侧窗口是否要收缩 while (right - left >= t.size()) { // 当窗口符合条件时,把起始索引加入 res if (valid == need.size()) res.push_back(left); char d = s[left]; left++; // 进行窗口内数据的一系列更新 if (need.count(d)) { if (window[d] == need[d]) valid--; window[d]--; } } } return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
跟寻找字符串的排列一样,只是找到一个合法异位词(排列)之后将起始索引加入res即可。
四、最长无重复子串
这是 LeetCode 第 3 题,Longest Substring Without Repeating Characters,难度 Medium:

这个题终于有了点新意,不是一套框架就出答案,不过反而更简单了,稍微改一改框架就行了:
int lengthOfLongestSubstring(string s) { unordered_map<char, int> window; int left = 0, right = 0; int res = 0; // 记录结果 while (right < s.size()) { char c = s[right]; right++; // 进行窗口内数据的一系列更新 window[c]++; // 判断左侧窗口是否要收缩 while (window[c] > 1) { char d = s[left]; left++; // 进行窗口内数据的一系列更新 window[d]--; } // 在这里更新答案 res = max(res, right - left); } return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这就是变简单了,连need和valid都不需要,而且更新窗口内数据也只需要简单的更新计数器window即可。
当window[c]值大于 1 时,说明窗口中存在重复字符,不符合条件,就该移动left缩小窗口了嘛。
唯一需要注意的是,在哪里更新结果res呢?我们要的是最长无重复子串,哪一个阶段可以保证窗口中的字符串是没有重复的呢?
这里和之前不一样,要在收缩窗口完成后更新res,因为窗口收缩的 while 条件是存在重复元素,换句话说收缩完成后一定保证窗口中没有重复嘛。
我的解法有点没有理解透彻——滑动窗口了:【可以对比一下 加深理解】
class Solution { public: int lengthOfLongestSubstring(string s) { unordered_map<char, int> need, window; // need最小子串有效字符,window也是有效最小子串字符;左右窗口大小由 [left, right)控制 int left=0, right=0, valid=0; // for(char c:s1) need[c]++; int start = 0, max_len = 0; while( right < s.size() ){ // 右边的添加到窗口 扩大窗口 char r = s[right]; // window[s[right]]++; // 所以数据集是左闭右开的 /*** debug 输出的位置 ***/ printf("window: [%d, %d]\n", left, right); /********************/ window[r]++; //边界还没有重复的就结束了 if(window[r]==1){ max_len = right+1-left>max_len?right+1-left:max_len; } // 进行窗口内数据的一系列更新 if(window[r] > 1){ // 如果字符存在,缩小窗口并 移动到找到字符的下一个 // 首先记录 max_len = right-left>max_len?right-left:max_len; // 然后循环更新窗口 char l = s[left]; while( l != r ){ window[l]--; left++; l = s[left]; cout << "in circle window[l]" << window[l] << endl; } window[l]--; left++; } right++; } return max_len; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
即:我没有彻底领悟——①滑动窗口的左闭右开的意味——使得我用了左闭右闭 且 未能理清对用上整体的max(max_size,right-left)从而饶了思维的弯路;②未能领悟 while(窗口缩减)的本质—— left,right, window[str] 三者之间的循环滑动和融合的特点。
五、最后总结
建议背诵并默写这套框架,顺便背诵一下文章开头的那首诗。以后就再也不怕子串、子数组问题了。
我觉得吧,能够看到这的都是高手,要么就是在成为高手的路上。有了框架,任他窗口怎么滑,本文这波车开得依然稳如老狗。( • ̀ω•́ )✧

