
- 1C语言基础5指针专题一_分析下面代码,理解指针与二维数组 #include
int main(){ int - 2DNS协议及域名解析过程(每个域名服务器都负责管理下一级域名服务器,保证域名的唯一性)_客户机下级的域名服务器的地址
- 3富文本新手使用手册_tinymce 获取目录
- 4《深入理解Java虚拟机》(第3版) 学习笔记,涵盖全书精髓_深入理解 java虚拟机第三版 mobi
- 5java期末考试中比较坑人的点_可以为互斥锁设置一个属性对象
- 6Qt 自定义动画属性 QPropertyAnimation
- 7Linux:fork是什么、使用方法、缓冲区问题、frok使用实例_fork 算法
- 8Android build.gradle文件_build.gradle.kts和build.gradle
- 9全网最全stable diffusion模型讲解!快来!!小白必收藏!!_stable diffusion 模型只能出动画吗
- 10聚观早报 | 追觅科技亮相AWE2024;三星家电举办发布会
java中文分词工具_【分词】从why到how的中文分词详解,从算法原理到开源工具...
赞
踩
点击上方,选择星标或置顶,每天给你送干货 !
!
阅读大概需要24分钟
跟随小博主,每天进步一丢丢


来自:夕小瑶的卖萌屋
作者:QvQ,夕小瑶,小鹿鹿鹿
前言 分词(word tokenization) ,也叫切词,即通过某种方式将句子中的各个词语识别并分离开来,使得文本从“字序列”的表示升级为“词序列”表示。分词技术不仅仅适用于中文,对于英文、日文、韩文等语言也同样适用。虽然英文中有天然的单词分隔符(空格),但是常有单词与其他标点黏滞的情况,比如"Hey, how are you."中的"Hey"和"you"是需要与身后的标点分隔开的
目录
为什么需要分词?
能不能不分词?
中文分词难在哪?
从古至今的分词算法:词典到预训练
从中到外的分词工具
为什么需要分词?
对于中文来说,如果不进行分词,那么神经网络将直接基于原始的汉字序列进行处理和学习。然而我们知道一个字在不同的词语中可能含义迥然不同,比如 “哈哈” 与 “哈士奇” 中 “哈” 的含义相去甚远,如果模型在训练阶段没见过 “哈士奇” ,那么预测的时候就有可能以为“哈士奇”所在的句子在表达欢快的气氛了╮( ̄▽ ̄"")╭ 显然,要解决上述问题的话,分词就是了,分词之后,最小的输入单位就不再是字了,而是词,由于“哈哈”与“哈士奇”是两个不同的词,自然就不会有前面这个问题啦。因此可以认为,分词缓解了“一字多义”的问题。 除此之外,从特征(feature)与NLP任务的角度来说,字相比词来说,是更原始和低级的特征,往往与任务目标的关联比较小;而到了词级别后,往往与任务目标能发生很强的关联。比如对于情感分类任务, “我今天走狗屎运了” 这句中的每个字都跟正向情感关系不大,甚至“狗”这个字还往往跟负面情感密切相关,但是“狗屎运”这个词却表达了 “幸运”、“开心”、“惊喜” 的正向情感,因此,分词可以看作是给模型提供了更high-level、更直接的feature,丢给模型后自然容易获得更佳的表现。能不能不分词?
答案是,当然可以。从前面分词的目的可以看出,只要模型本身能够学习到字的多义性,并且自己学到由字组词的规律,那么就相当于隐含的内置了一个分词器在模型内部,这时候这个内置的分词器是与解决目标任务的网络部分一起“端到端训练”的,因此甚至可能获得更佳的性能。 然而,从上面这段的描述也能看出,要满足这个条件,是很难得的。这需要训练语料非常丰富,且模型足够大(可以有额外容量来内置一个隐含的分词模型),才有可能获得比“分词器+词级模型“更好的表现。这也是为什么BERT等大型预训练模型往往是字级别的,完全不需要使用分词器。 此外,分词也并不是百利而无一害的,一旦分词器的精度不够高,或者语料本身就噪声很大(错字多、句式杂乱、各种不规范用语),这时强行分词反而容易使得模型更难学习。比如模型终于学会了 “哈士奇” 这个词,却有人把哈士奇打成了“蛤士奇”,结果分词器没认出来,把它分成了 “蛤”、“士”、“奇” 这三个字,这样我们这个已经训练好的“word level模型”就看不到 “哈士奇” 了(毕竟模型训练的时候,“哈士奇”是基本单位)。中文分词难在哪?
1 歧义问题
首先,前面提到分词可以缓解“一字多义”的问题,但是分词本身又会面临“切分歧义”的问题。 例如,切分书名 《无线电法国别研究》 
2 未登录词问题
此外,中文词典也是与时俱进的,例如“青青草原”、“累觉不爱”等网络词在10年前是没有的,今天训练的分词器也一定会在不久的将来遇到不认识的词(即“未登录词”,out-of-vocabulary word),那个时候分词器很容易因为“落伍”而出现切分错误。3 规范问题
最后,分词时的切分边界也一直没有一个确定的规范。尽管在 1992 年国家颁布了《信息处理用现代词汉语分词规范》,但是这种规范很容易受主观因素影响,在实际场景中也难免遇到有所不及的问题。算法篇
1 基于词典
对于中文分词问题,最简单的算法就是基于词典直接进行greedy匹配。比如,我们可以直接从句子开头的第一个字开始查字典,找出字典中以该字开头的最长的单词,然后就得到了第一个切分好的词。比如这句“夕小瑶正在讲NLP”,查字典发现“夕小瑶”是最长的词了,于是得到
夕小瑶/正在讲NLP
然后从下一个词的开头开始继续匹配字典,发现“正在”就是最长的词了,于是
夕小瑶/正在/讲NLP
依此类推,最终得到
夕小瑶/正在/讲/NLP
这种简单的算法即为前向最大匹配法(FMM)
虽然做法很朴素,但是名字听起来还有点高端╮(╯▽╰)╭不过,由于中文句子本身具有重要信息后置的特点,从后往前匹配的分词正确率往往要高于从前往后,于是就有了反向进行的“后向最大匹配法(BMM)”。 当然了,无论是FMM还是BMM,都一定存在不少切分错误,因此一种考虑更周到的方法是“双向最大匹配”。 双向最大匹配算法是指对待切分句子分别使用FMM和RMM进行分词,然后对切分结果不重合的歧义句进行进一步的处理。通常可对两种方法得到的词汇数目进行比较,根据数目的相同与否采取相应的措施,以此来降低歧义句的分词错误率.
2 基于统计
2.1 基于语言模型
基于词典的方法虽然简单,但是明显能看出来太!不!智!能!了!稍微复杂一些的句子,例如“没关系,除夕小瑶在家做饭。”,这时候如果使用后向最大匹配法,就会切分成“没关系/,/除/夕小瑶/在家/做饭/。”,这明显错的很不可原谅。 犯这种错误的根本原因在于,基于词典的方法在切分时是没有考虑词语所在的上下文的,没有从全局出发找最优解。其实上面这个句子无非就是在纠结两种切分方式: a. 没关系/,/除/夕小瑶/在家/做饭/。 b. 没关系/,/除夕/小瑶/在家/做饭/。我们日常说话中很少会有人说出“没关系/,/除/xxxx/做饭/。”这种句子,而第二个句子出现的频率则会非常高,比如里面的“小瑶”可以替换成“我”、“老王”等。显然给定一个句子,各种切分组合是数量有限的,如果有一个东西可以评估出任何一个组合的存在合理性的分值,那么不就找到了最佳的分词组合嘛!
所以,这种方法的本质就是在各种切词组合中找出那个最合理的组合,这个过程就可以看作在切分词图中找出一条概率最大的路径: 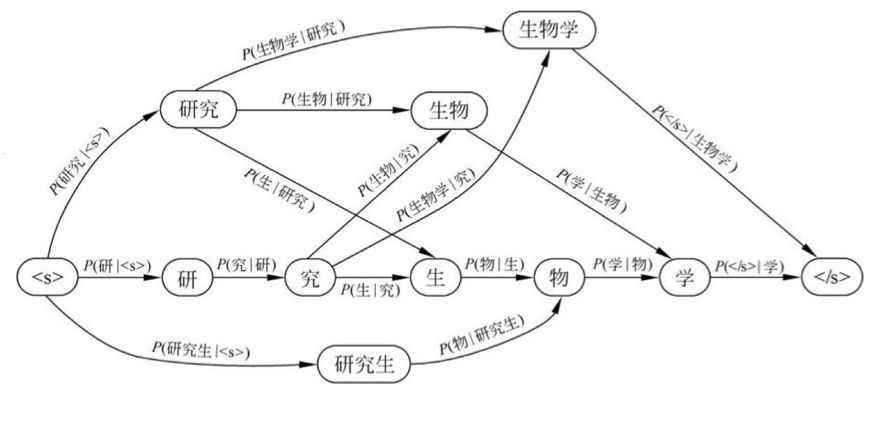
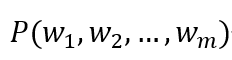
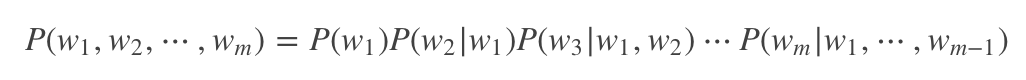 显然,当m取值稍微一大,乘法链的后面几项会变得非常难计算(估计出这几项的概率需要依赖极其庞大的语料才能保证估计误差可接受)。计算困难怎么办?当然是用合理的假设来简化计算,比如我们可以假设当前位置取什么词仅取决于相邻的前面n个位置,即
显然,当m取值稍微一大,乘法链的后面几项会变得非常难计算(估计出这几项的概率需要依赖极其庞大的语料才能保证估计误差可接受)。计算困难怎么办?当然是用合理的假设来简化计算,比如我们可以假设当前位置取什么词仅取决于相邻的前面n个位置,即
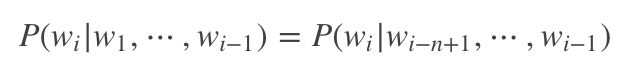 这种简化的语言模型就称为n-gram语言模型。这样乘法链中的每个乘子都可以在已经完成人工标注的分词语料中计算得到啦。当然了,在实际计算中可能还会引入一些平滑技巧,来弥补分词语料规模有限导致的估计误差,这里就不展开讲啦。
这种简化的语言模型就称为n-gram语言模型。这样乘法链中的每个乘子都可以在已经完成人工标注的分词语料中计算得到啦。当然了,在实际计算中可能还会引入一些平滑技巧,来弥补分词语料规模有限导致的估计误差,这里就不展开讲啦。
2.2 基于统计机器学习
NLP是一门跟机器学习强绑定的学科,分词问题自然也不例外。中文分词同样可以建模成一个“序列标注”问题,即一个考虑上下文的字分类问题。因此可以先通过带标签的分词语料来训练一个序列标注模型,再用这个模型对无标签的语料进行分词。样本标签
一般用{B:begin, M:middle, E:end, S:single}这4个类别来描述一个分词样本中每个字所属的类别。它们代表的是该字在词语中的位置。其中,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。 一个样本如下所示: 人/b 们/e 常/s 说/s 生/b 活/e 是/s 一/s 部/s 教/b 科/m 书/e 之后我们就可以直接套用统计机器学习模型来训练出一个分词器啦。统计序列标注模型的代表就是生成式模型的代表——隐马尔可夫模型(HMM),和判别式模型的代表——(线性链)条件随机场(CRF)。已经对这两个模型很熟悉的小伙伴可以跳过。隐马尔可夫模型(HMM)
HMM模型的详细介绍见
《如果你跟夕小瑶恋爱了... (上)》 / 《下》
在了解了HMM模型的基本概念之后,我们来看看HMM模型是如何进行分词的吧~ 基本思路:将分词问题转换为给每个位置的字进行分类的问题,即序列标注问题。其中,类别有4个(前面讲到的B、M、E、S)。给所有的位置分类完成后,便可以根据类别序列得到分词结果啦。举个栗子!
我们的输入是一个句子:小Q硕士毕业于中国科学院BEBEBMEBEBMEBE/BE/BME/BE/BME小Q/硕士/毕业于/中国/科学院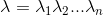 代表输入的句子,n为句子长度,
代表输入的句子,n为句子长度,
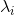 表示字,
表示字,
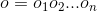 代表输出的标签,那么理想的输出即为:
代表输出的标签,那么理想的输出即为:
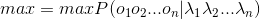
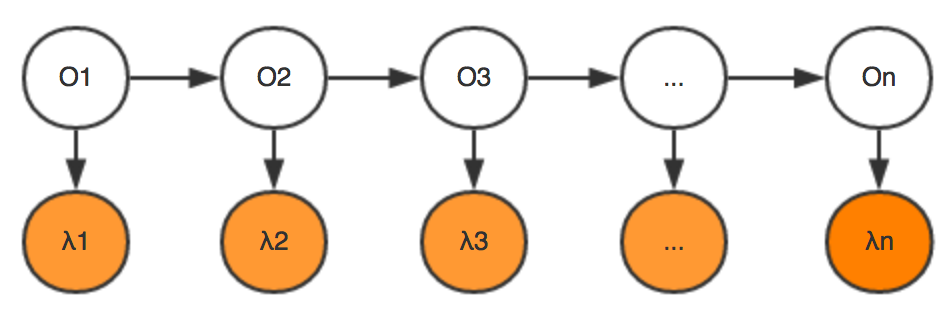
我们的理想输出的是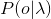 ,通过贝叶斯公式能够得到:
,通过贝叶斯公式能够得到:
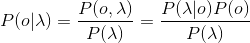
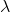 为给定的输入,因此
为给定的输入,因此
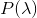 计算为常数,可以忽略,因此最大化
等价于最大化
计算为常数,可以忽略,因此最大化
等价于最大化
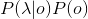 .
可是,上面这个式子也太难算了吧!!!为此,聪明的科学家们引入了两个可以简化计算的假说:
观测独立性假设:每个字的输出仅仅与当前字有关,即每个λ的值只依赖于其对应的O值,即
.
可是,上面这个式子也太难算了吧!!!为此,聪明的科学家们引入了两个可以简化计算的假说:
观测独立性假设:每个字的输出仅仅与当前字有关,即每个λ的值只依赖于其对应的O值,即
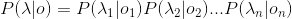 齐次马尔可夫假设:每个输出仅仅与上一个输出有关,即Oi的值只依赖于Oi-1,即
齐次马尔可夫假设:每个输出仅仅与上一个输出有关,即Oi的值只依赖于Oi-1,即
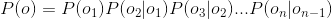 综合上面两个式子,我们得到:
综合上面两个式子,我们得到:
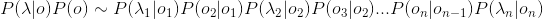 在HMM中,将
在HMM中,将
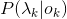 称为观测概率,
称为观测概率,
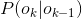 称为转移概率。通过设置某些
称为转移概率。通过设置某些
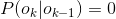 ,可以排除类似BBB、EM等不合理的组合。
最后,求解
,可以排除类似BBB、EM等不合理的组合。
最后,求解
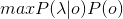 的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个
的常用方法是Veterbi算法。它是一种动态规划方法,核心思想是:如果最终的最优路径经过某个
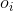 ,那么从初始节点到
,那么从初始节点到
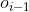 点的路径必然也是一个最优路径。当然啦,这一切的前提是HMM中的模型参数都已经被训练好了,而训练这些模型参数可以通过万能的极大似然估计来从有标签的分词语料中学习得到,这里就不展开赘述啦,对细节不清楚的小伙伴可参考本小节开头给出的两篇文章。
点的路径必然也是一个最优路径。当然啦,这一切的前提是HMM中的模型参数都已经被训练好了,而训练这些模型参数可以通过万能的极大似然估计来从有标签的分词语料中学习得到,这里就不展开赘述啦,对细节不清楚的小伙伴可参考本小节开头给出的两篇文章。
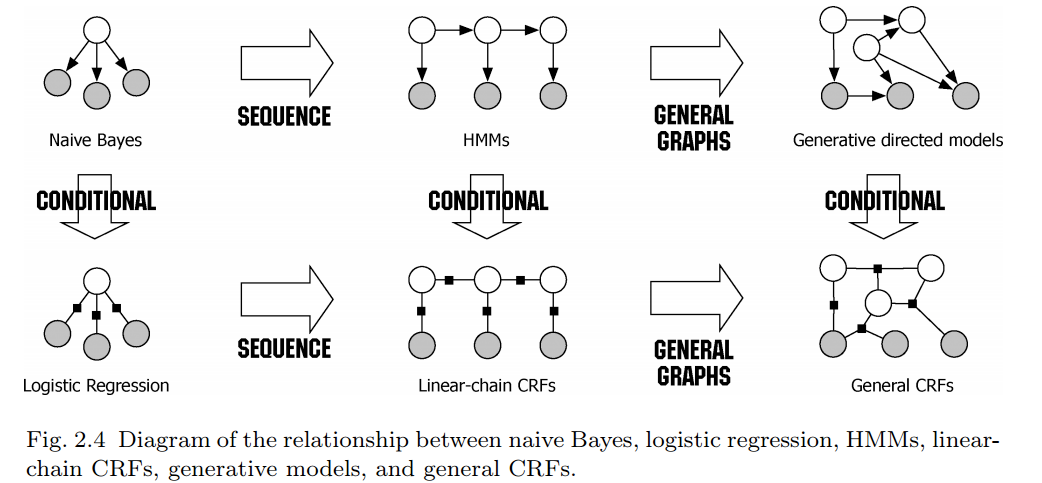
条件随机场 (CRF)
HMM隐马模型有一个非常大的缺点,就是其存在输出独立性假设,导致其不能将上下文纳入特征设计,大大限制了特征的可用范围。CRF则没有这个限制,它不对单独的节点进行归一化,而是对所有特征进行全局归一化,进而全局的最优值。因此,在分词问题上,显然作为判别式模型的CRF相比HMM更具优越性。
关于CRF的详细介绍可以看小夕之前写的这篇推文: 《逻辑回归到条件随机场》 这里再来简单回顾一下。HMM模型围绕的是一个关于序列X和Y的联合概率分布?(?,?),而条件随机场则围绕条件概率分布模型?(?|?)展开。
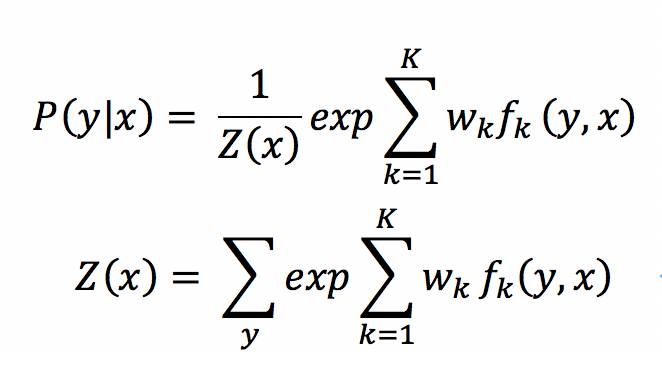 Z(x)就是概率图模型中的配分函数,目的就是提供一个归一化因子,将各个类别的值求和,为计算每个类别的概率提供一个分母,对这个思想还不清楚的小伙伴请移步本节开头的推荐文章哦,这里不再赘述其背后的数学思想了。K为设计的特征(函数)的数量,w_k为每个特征函数待学习的权重。
而这里的f_k就是能够帮助CRF完成分词的特征啦,确切的说是特征函数。特征函数可以看作一个比较复杂的特征,特征值取决于多个输入变量的取值。当然啦,这里只给出了简化形式,特征函数又分为转移特征和状态特征,其中转移特征会考虑历史时刻的输出,而状态特征仅考虑当前时刻。
举个特征函数的栗子:
f(y_1, x_1, x) = {1 if y_1 == 'I' and x_1 == '小' and x=='瑶'; else 0}
这里即表示如果当前位置的字(观测值)是
‘瑶’
,且上个位置的字是
‘小’
,且上个位置的预测标签是类别
‘I’
,那么该特征函数会输出
1
,也就是说该特征的特征值为
1
,其余情况均为
0
。显然这个特征一旦取值为
1
,则是一个很强的特征来指示
‘瑶’
这个字的位置的预测标签为
‘E’
。
与HMM一样,训练CRF中的参数依然是通过万能的极大似然估计,具体算法形式如梯度下降法、IIS、拟牛顿法等。训练好CRF分词模型后,跟HMM一样, 可以通过Viterbi算法来进行全局的推理,从而得到最优的分词序列。这里同样不展开讲啦。
总结一下,与HMM比,使用CRF进行分词有以下优点:
Z(x)就是概率图模型中的配分函数,目的就是提供一个归一化因子,将各个类别的值求和,为计算每个类别的概率提供一个分母,对这个思想还不清楚的小伙伴请移步本节开头的推荐文章哦,这里不再赘述其背后的数学思想了。K为设计的特征(函数)的数量,w_k为每个特征函数待学习的权重。
而这里的f_k就是能够帮助CRF完成分词的特征啦,确切的说是特征函数。特征函数可以看作一个比较复杂的特征,特征值取决于多个输入变量的取值。当然啦,这里只给出了简化形式,特征函数又分为转移特征和状态特征,其中转移特征会考虑历史时刻的输出,而状态特征仅考虑当前时刻。
举个特征函数的栗子:
f(y_1, x_1, x) = {1 if y_1 == 'I' and x_1 == '小' and x=='瑶'; else 0}
这里即表示如果当前位置的字(观测值)是
‘瑶’
,且上个位置的字是
‘小’
,且上个位置的预测标签是类别
‘I’
,那么该特征函数会输出
1
,也就是说该特征的特征值为
1
,其余情况均为
0
。显然这个特征一旦取值为
1
,则是一个很强的特征来指示
‘瑶’
这个字的位置的预测标签为
‘E’
。
与HMM一样,训练CRF中的参数依然是通过万能的极大似然估计,具体算法形式如梯度下降法、IIS、拟牛顿法等。训练好CRF分词模型后,跟HMM一样, 可以通过Viterbi算法来进行全局的推理,从而得到最优的分词序列。这里同样不展开讲啦。
总结一下,与HMM比,使用CRF进行分词有以下优点:
- CRF可以使用输入文本的全局特征,而HMM只能看到输入文本在当前位置的局部特征
- CRF是判别式模型,直接对序列标注建模;HMM则引入了不必要的先验信息
3 基于神经网络
众所周知,深度学习已经成功占领NLP,席卷了NLP中的分类、序列标注和生成问题。如前所述,分词也可以建模为序列标注问题,那么擅长处理序列数据的 LSTM(长短时记忆网络+超链接到历史推文)和最近超级火的预训练模型同样可以用于中文分词。3.1 基于(Bi-)LSTM
对LSTM模型还不熟悉的小伙伴见小夕以前写的这篇的《step-by-step to LSTM》,本文对lstm的基本理论不再赘述啦。
如前面语言模型一节中所述,字的上下文信息对于排解切分歧义来说非常重要,能考虑的上下文越长,自然排解歧义的能力就越强。而前面的n-gram语言模型也只能做到考虑一定距离的上下文,那么有没有在理论上能考虑无限长上下文距离的分词模型呢? 答案就是基于LSTM来做。 当然啦,LSTM是有方向的,为了让每个位置的字分类时既能考虑全部历史信息(左边的所有的字),又能考虑全部未来信息(右边所有的字),我们可以使用双向LSTM(Bi-LSTM)来充当序列标注的骨架模型,如图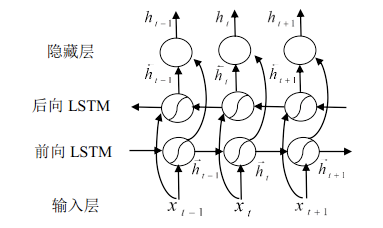
3.2 基于预训练模型+知识蒸馏
最近的一年多的时间里,BERT、ERNIE、XLNet等大型预训练席卷了NLP的绝大部分领域,在分词问题上也有显著的优越性。 
工具篇
下面列了几个较为主流的分词工具(排名不分先后,大家自行试用),相关的paper请在订阅号后台回复【中文分词】领取。1 Jieba
说到分词工具第一个想到的肯定是家喻户晓的“结巴”中文分词,主要算法是前面讲到的基于统计的最短路径词图切分,近期还内置了百度飞桨的预训练模型+大规模蒸馏的前沿分词模型。 github项目地址:https://github.com/fxsjy/jieba 使用示例:#encoding=utf-8#Jieba#pip install jiebaimport jiebasentence = "不会讲课的程序员不是一名好的算法工程师"tokens = jieba.cut(sentence)print("jieba: " + " ".join(tokens))#output#Building prefix dict from the default dictionary ...#Loading model from cache /tmp/jieba.cache#Loading model cost 0.266 seconds.#Prefix dict has been built successfully.#jieba: 不会 讲课 的 程序员 不是 一名 好 的 算法 工程2 THULAC(THU Lexical Analyzer for Chinese)
由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。该工具所采用的分词模型为结构化感知机。更多算法细节请参考github项目和阅读论文原文。
github项目地址:https://github.com/thunlp/THULAC
论文链接:https://www.mitpressjournals.org/doi/pdf/10.1162/coli.2009.35.4.35403
使用示例:
#THULAC#pip install thulacimport thulacsentence = "不会讲课的程序员不是一名好的算法工程师"thu1 = thulac.thulac(seg_only=True) #只分词text = thu1.cut(sentence, text=True) #进行一句话分词print("THULAC: " + text)#output#Model loaded succeed#THULAC: 不 会 讲课 的 程序员 不 是 一 名 好 的 算法 工程师3 NLPIR-ICTCLAS汉语分词系统
北京理工大学海量语言信息处理与云计算工程研究中心大数据搜索与挖掘实验室( Big Data Search and Mining Lab.BDSM@BIT)发布。是基于层次HMM的分词库,将分词、POS、NER等都纳入到了一个层次HMM的框架之下联合训练得到。 主页:http://ictclas.nlpir.org/ github项目地址:https://github.com/tsroten/pynlpir 使用示例:#NLPIR-ICTCLAS#pip install pynlpirimport pynlpirsentence = "不会讲课的程序员不是一名好的算法工程师"pynlpir.open()tokens = [x[0] for x in pynlpir.segment(sentence)]print("NLPIR-TCTCLAS: " + " ".join(tokens))pynlpir.close()#output#NLPIR-TCTCLAS: 不 会 讲课 的 程序员 不 是 一 名 好 的 算法 工程4 LTP
哈工大出品,同THULAC一样,LTP也是基于结构化感知器(Structured Perceptron, SP),以最大熵准则学习的分词模型。 项目主页:https://www.ltp-cloud.com/ github项目地址:https://github.com/HIT-SCIR/ltp 论文链接:http://jcip.cipsc.org.cn/CN/abstract/abstract1579.shtml 使用示例:使用前需下载分词模型(http://ltp.ai/download.html)#LTP#pip install pyltpfrom pyltp import Segmentorsentence = "不会讲课的程序员不是一名好的算法工程师"segmentor = Segmentor()#segmentor.load("/path/to/your/cws/model")segmentor.load("ltp_data_v3.4.0/cws.model")tokens = segmentor.segment(sentence)print("LTP: " + " ".join(tokens))segmentor.release()#output#LTP: 不 会 讲课 的 程序员 不 是 一 名 好 的 算法 工程5 HanLP
HanLP是随《自然语言处理入门》配套开源的一系列NLP算法库。除了经典的1.x版本在不断迭代更新以外,今年还全新推出了2.0版本。1.x版本有有基于词典的分词工具和基于CRF的切词模型。2.0版本开源了基于深度学习算法的分词工具。 1.x版本 github项目地址: https://github.com/hankcs/pyhanlp 使用示例:#HanLP#v1.x#pip install pyhanlpfrom pyhanlp import *sentence = "不会讲课的程序员不是一名好的算法工程师"print(HanLP.segment(sentence))#HanLP#v2.0#pip install hanlpimport hanlpsentence = "不会讲课的程序员不是一名好的算法工程师"tokenizer = hanlp.load('PKU_NAME_MERGED_SIX_MONTHS_CONVSEG')tokens = tokenizer(sentence)print("hanlp 2.0: " + " ".join(tokens))#output#hanlp 2.0: 不 会 讲课 的 程序员 不 是 一 名 好 的 算法 工程6 Stanford CoreNLP
斯坦福推出的切词工具,可以支持多种语言。算法核心是基于CRF模型。 github项目地址: https://github.com/Lynten/stanford-corenlp 论文链接: https://nlp.stanford.edu/pubs/sighan2005.pdf 使用示例:需要先从stanford官网下载中文切词模型( https://stanfordnlp.github.io/CoreNLP/ )###stanford CoreNLP#pip install stanfordcorenlpfrom stanfordcorenlp import StanfordCoreNLPsentence = "不会讲课的程序员不是一名好的算法工程师"with StanfordCoreNLP(r'stanford-chinese-corenlp-2018-10-05-models', lang='zh') as nlp: print("stanford: " + " ".join(nlp.word_tokenize(sentence)))投稿或交流学习,备注: 昵称-学校(公司)-方向,进入DL&NLP交流群。 方向有很多: 机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
 记得备注呦
推荐阅读:
【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器
经验 | 初入NLP领域的一些小建议
学术 | 如何写一篇合格的NLP论文
干货 | 那些高产的学者都是怎样工作的?
一个简单有效的联合模型
近年来NLP在法律领域的相关研究工作
记得备注呦
推荐阅读:
【ACL 2019】腾讯AI Lab解读三大前沿方向及20篇入选论文
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器
经验 | 初入NLP领域的一些小建议
学术 | 如何写一篇合格的NLP论文
干货 | 那些高产的学者都是怎样工作的?
一个简单有效的联合模型
近年来NLP在法律领域的相关研究工作
 让更多的人知道你“在看”
让更多的人知道你“在看”

