
- 1使用VMware 16 安装CentOS 8_centos-stream-8-x86_64-latest
- 2TypeError [ERR_INVALID_CALLBACK]: Callback must be a function. Received 29
- 3SIM900A、GPRS、GSM 基础知识_有gsm模块之后还需要gps吗
- 4【LLM系列之GLM】GLM: General Language Model Pretraining with Autoregressive Blank Infilling_glm llm
- 5bp算法的理解_bp神经网络w7w8
- 6苹果审核团队_苹果审核力度加强,不止警告直接下架!
- 7第十节HarmonyOS 常用容器组件3-GridRow
- 8CentOS7 安装 gcc-4.9.0_centos7离线安装gcc4.9.0
- 9[Java 探索者之路] 一个大厂都在用的分布式任务调度平台
- 10TCP/IP协议解析与进阶_tcpip公式
transformer系列之时间复杂度_transformer复杂度如何计算
赞
踩
一、矩阵运算的复杂度
假设我们有两个矩阵,A的维度为
(
m
∗
n
)
(m * n)
(m∗n),B的维度为
(
n
∗
p
)
(n * p)
(n∗p),则结果矩阵C的维度为
(
m
∗
p
)
(m * p)
(m∗p)
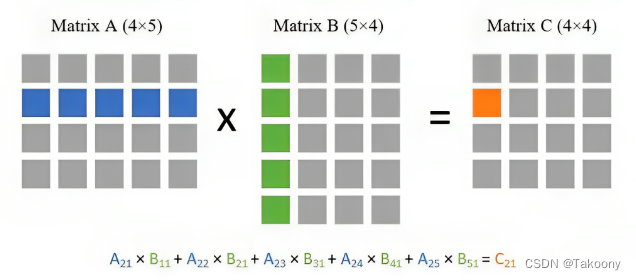
对于结果矩阵C中的每个元素,我们需要计算矩阵A中的一行和矩阵B中的一列的点积。这个点积涉及到对应元素的乘积和求和。
为了计算C中的每个元素,我们需要执行n次乘法和n-1次加法,如果再加上偏置项,刚好就是2*n
由于结果矩阵C中有m x p个元素,因此所需的总操作数为 ( m ∗ p ) ∗ 2 ∗ n (m * p) * 2 * n (m∗p)∗2∗n。但为了表述简洁性,忽略细节,可以写成 m ∗ p ∗ 2 ∗ n m*p*2*n m∗p∗2∗n
因此,矩阵乘法的总体复杂度为 O ( m ∗ n ∗ p ) O(m * n * p) O(m∗n∗p)。
二、transformer时间复杂度计算
transformer分为自注意力层与MLP层; 假设当前输入序列长度为 N N N 时,只一个头且头的形状为 [ d , d ] [d, d] [d,d]时,计算复杂度如下:
2.1、自注意力复杂度
首先,我们知道transformer模型由
l
l
l个相同的层组成,每个层分为两部分:self-attention块和MLP块,结构如下:
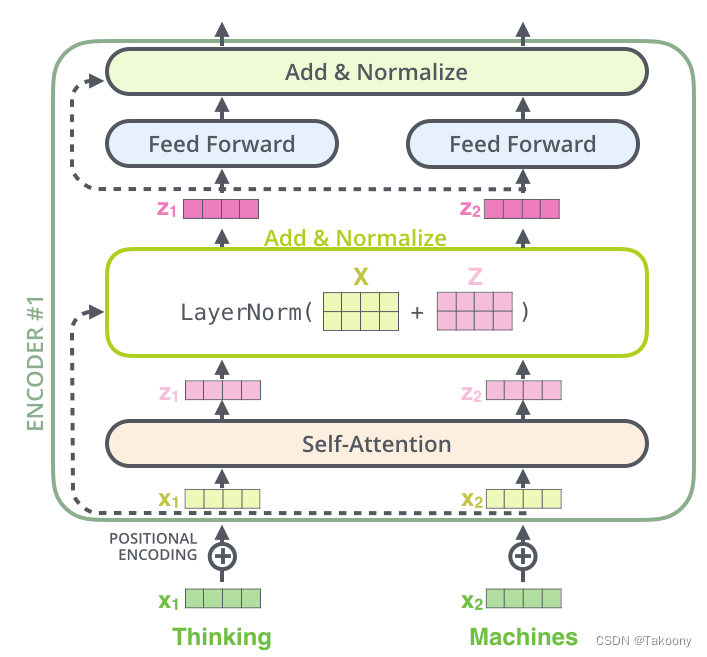
self.attention模块的结构如下:
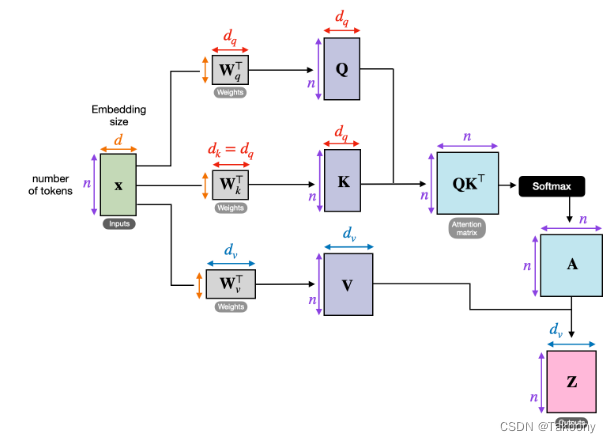
而self-attention层的模型参数有两部分,一部分是
Q
、
K
、
V
Q、K、V
Q、K、V的权重矩阵
W
Q
W_Q
WQ、
W
K
W_K
WK、
W
V
W_V
WV和偏置,另一部分是输出权重矩阵
W
O
W_O
WO和偏置,最终为:8
N
d
2
Nd^2
Nd2 + 4
N
2
N^2
N2d
具体计算步骤如下:
计算
Q
K
V
QKV
QKV:
即
Q
=
x
W
Q
,
K
=
x
W
k
,
V
=
x
W
v
Q=xW_Q, K=xW_k,V=xW_v
Q=xWQ,K=xWk,V=xWv
该矩阵乘法的输入和输出形状为
[
N
,
d
]
∗
[
d
,
d
]
[N,d] * [d,d]
[N,d]∗[d,d] -->
[
N
,
d
]
[N,d]
[N,d]
计算量为:
3
∗
2
N
d
2
3 * 2Nd^2
3∗2Nd2
计算
Q
K
T
QK^T
QKT
该部分的输入和输出形状为[N,d]*[d, N]
计算量为:2
N
2
N^2
N2d
计算score *
V
V
V
该部分计算的核心在于加法,输入和输出形状为
[
N
,
d
]
∗
[
d
,
N
]
[N,d]*[d, N]
[N,d]∗[d,N],每个token都是N个V相加,计算量是
N
∗
2
d
N * 2d
N∗2d,
N
N
N个token计算量为2
N
2
N^2
N2d
计算量为:2
N
2
N^2
N2d
attention后的线性映射,矩阵乘法的输入和输出形状为
[
N
,
d
]
∗
[
d
,
d
]
[N,d] * [d, d]
[N,d]∗[d,d]
计算量为:2
N
d
2
Nd^2
Nd2
2.2、MLP的复杂度
MLP块由2个线性层组成,维度为
[
d
,
4
d
]
[
4
d
,
d
]
[d, 4d] [4d, d]
[d,4d][4d,d]
计算量:
N
∗
(
2
∗
d
∗
4
d
+
2
∗
d
∗
4
d
)
,
即
16
N
d
2
N * (2*d * 4d + 2 * d * 4d),即16Nd^2
N∗(2∗d∗4d+2∗d∗4d),即16Nd2
将上述所有表粗所示的计算量相加,得到每个transformer层的计算量大约为:24 N d 2 + 4 d N 2 Nd^2+4dN^2 Nd2+4dN2
三、换个角度研究transformer计算复杂度
假设向量的维度是 1 ∗ d 1 * d 1∗d,单独看它的计算量:
Q K V QKV QKV的计算
Q K V QKV QKV的矩阵维度假设为 d ∗ d d * d d∗d,那么计算量为:2 d 2 d^2 d2 * 3,得到三个 1 ∗ d 1 * d 1∗d的向量
注意力权重的计算
Q 需要与 N 个 K 相乘,计算量为: 2 d ∗ N Q需要与N个K相乘,计算量为:2d * N Q需要与N个K相乘,计算量为:2d∗N
加权注意力的得到新向量
注意力权重 ∗ V + 偏转向量, [ 1 , d ] ∗ [ d , N ] + 偏转项 , 计算量为 : 2 d ∗ N 注意力权重 * V + 偏转向量, [1, d] * [d, N] + 偏转项, 计算量为:2d * N 注意力权重∗V+偏转向量,[1,d]∗[d,N]+偏转项,计算量为:2d∗N
线性映射 与 MLP层
得到新向量后需要线性映射,再通过MLP层,其计算量:
[
1
,
d
]
∗
[
d
,
d
]
[1, d] * [d, d]
[1,d]∗[d,d] 得到2
d
2
d^2
d2
MLP层的维度
[
d
,
4
d
]
,
[
4
d
,
d
]
[d, 4d], [4d, d]
[d,4d],[4d,d],其计算量:
2
d
∗
4
d
∗
2
2d * 4d * 2
2d∗4d∗2,得到16
d
2
d^2
d2
汇总所有token在block的计算量
N ∗ ( 2 d 2 ∗ 3 + 2 d ∗ N + 2 d ∗ N + 2 d 2 + 16 d 2 ) = 24 d 2 N + 4 d N 2 N*(2d^2* 3 + 2d * N + 2d * N + 2d^2 + 16d^2) = 24d^2N + 4dN^2 N∗(2d2∗3+2d∗N+2d∗N+2d2+16d2)=24d2N+4dN2
四、logits的计算量
词嵌入矩阵的参数量为vocab_size × hidden_size,其中vocab_size是词表的大小,hidden_size是隐藏层的维度。词嵌入矩阵用于将输入的词索引映射为对应的词向量。
而输出层的权重矩阵通常与词嵌入矩阵共享参数。这意味着输出层的权重矩阵的维度也是hidden_size × vocab_size,其中hidden_size是隐藏层的维度,vocab_size是词表的大小。通过共享参数,可以减小模型的参数量,提高模型的效率。
计算量为: 2 d v N 2dvN 2dvN
五、结论
embedding维度 [ 1 , d ] [1,d ] [1,d], Q K V QKV QKV的维度 [ d , d ] [d, d] [d,d],注意力Head数为1,最终得到的计算复杂度: l ∗ ( 24 d 2 N + 4 d N 2 ) + 2 d v N l* (24d^2N + 4dN^2) + 2dvN l∗(24d2N+4dN2)+2dvN

