
- 1无vga怎么装linux系统,无显卡安装Linux ,字符界面,没有显卡,串口,终端。 – 开源中国社区...
- 2CoT进阶:Self Consistency, Least-To-Most_self-consistency cot
- 3web前端月刊-30期(202010)
- 4量化感知训练_TensorFlow Lite量化方法介绍
- 5数据库面试题总结——DBA面试battle指南_dba 面经
- 6Security Onion(安全洋葱)开源入侵检测系统(ids)安装
- 7Anaconda自带的Spyder编辑器启动报错问题_anaconda的spyder报错qtpy.qtmodulenotinstallederror: t
- 8多输入通道和多输出通道_多输入多输出神经网络
- 9SpringBoot集成neo4j实战_springboot整合neo4j实战
- 10NLP:XLNet模型
Transformer(一)搞懂Transformer及Self-attention/Multi-head Self-attention中的Q、K、V_transformer的qkv维度可以自由设置吗
赞
踩
老师讲得真的很好,一听就懂了
李宏毅2020机器学习深度学习(完整版)国语_哔哩哔哩_bilibili
一、整体架构
Transformer是2017年Google发表的Attention Is All You Need,下载地址:https://arxiv.org/pdf/1706.03762.pdf
Transformer遵循编码器-解码器结构,编码器和解码器都分别如下图的左右两部分所示:
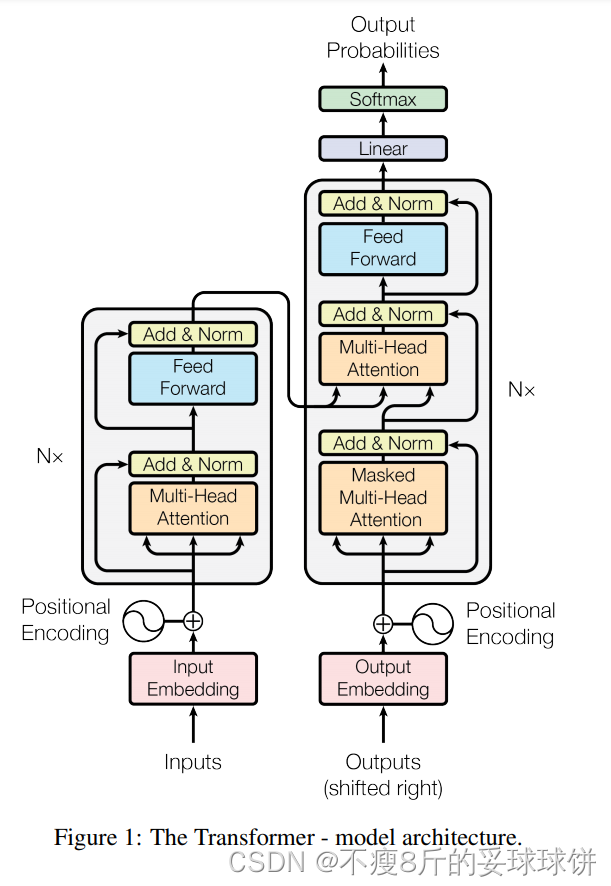
编码器:编码器由N = 6个相同的层组成。每一层有两个子层。第一种是多头自注意机构,第二种是简单的位置全连接网络。作者对两个子层使用残差连接,并加入层归一化(LN)。也就是说,每个子层的输出是:LayerNorm(x+ Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。
解码器:解码器也由N = 6个相同层组成。除每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器的输出执行多头注意。与编码器类似,作者对每个子层使用残差连接,然后进行层归一化(LN)。并且在解码器中的自注意子层中加入mask并将输出被位置偏移,以确保位置 i 的预测只依赖于小于 i 位置的已知输出。
二、注意力机制
Transformer在以下三处使用多头注意力:
- 在编码器自注意层中,所有的键、值和查询都来自前一层的输出。编码器中的每个位置都可以对应上一层的所有位置。
- 在编码器-解码器注意层中,查询前面的解码器层,而内存键和值来自编码器的输出。这使得译码器中的每个位置都可以参加输入序列中的所有位置。
- 在解码器中自注意层中,同样允许解码器中的每个位置关注解码器中之前的所有位置。
Self-attention
注意函数可以描述为将查询键和一组键值对映射到输出,其中查询Q、键K、值V和输出都是向量。输出是作为值V的加权和计算的,其中分配给每个值V的权重是通过查询Q与相应键K的兼容性函数计算的。不懂的话建议大家看篇首提到的李宏毅老师的视频。
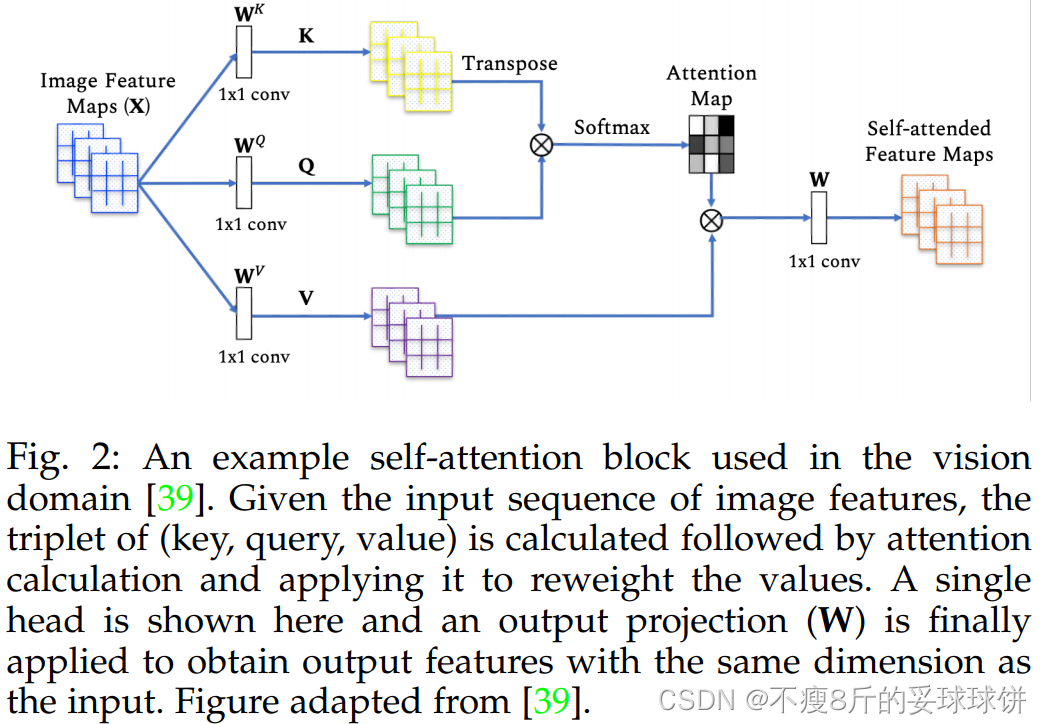
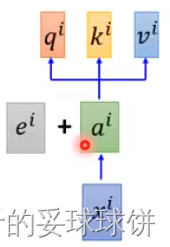
- q:query(to match others)
- k:key(to be matched)
- v:value(information to be extracted)
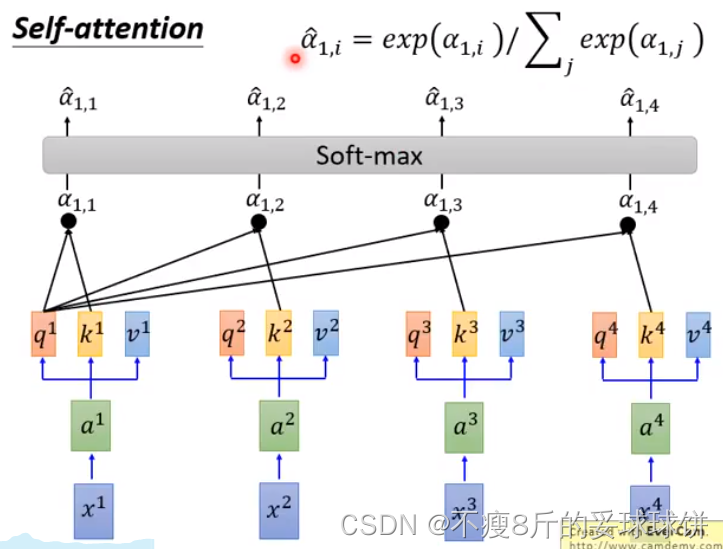
首先,拿每个query q去对每个key k做attention。下面3页PPT讲的是:计算查询Q与所有键K的点积,每个键除以 (d是维度),并应用softmax函数处理,最后与值V的权重相乘。我们计算输出矩阵为:


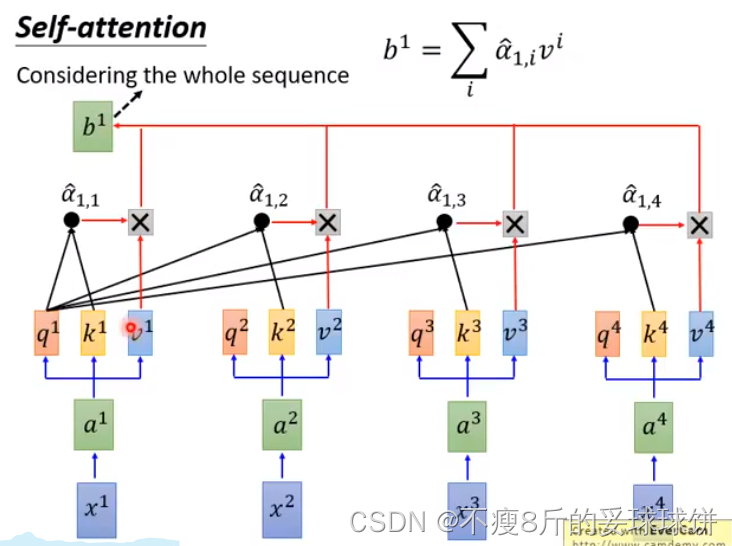
同理可求b2...

整体计算流程如下所示:

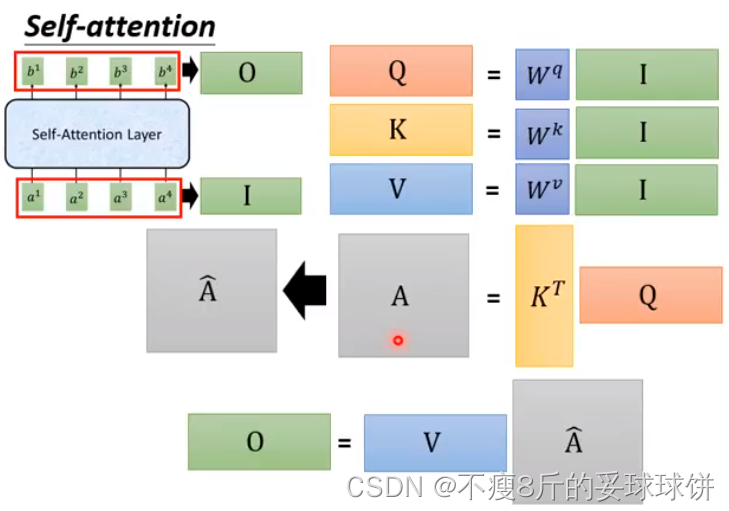
反正就是一串矩阵乘法,用GPU可以加速。
Multi-head Self-attention
不同head可能关注的点不一样。

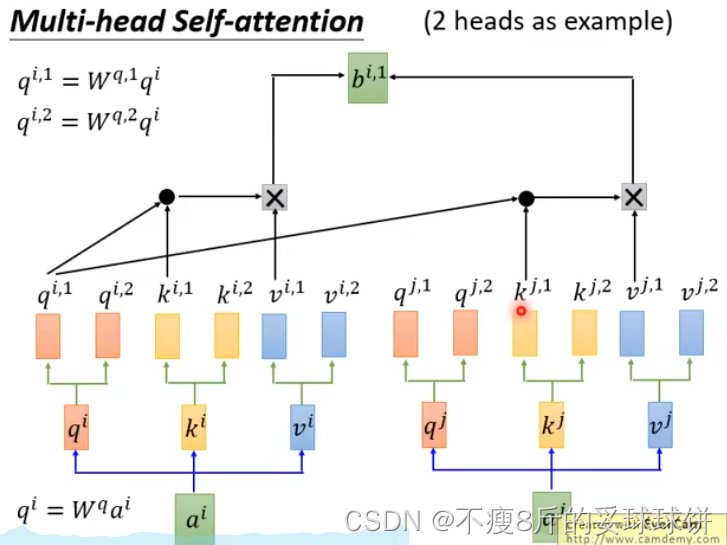
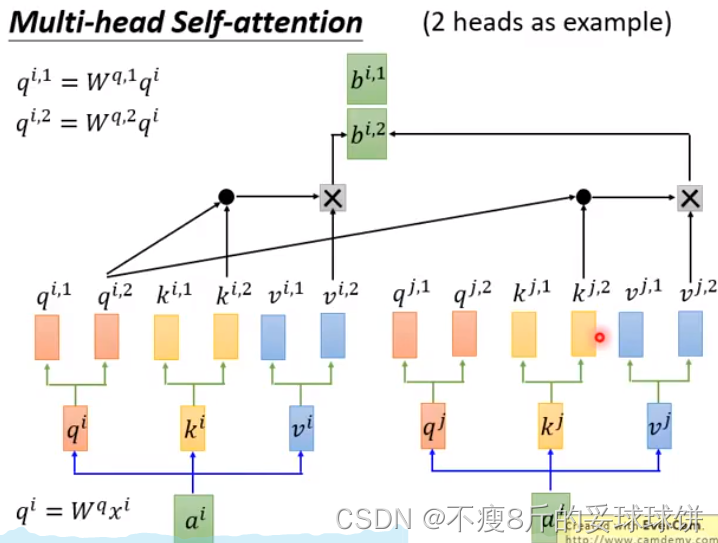
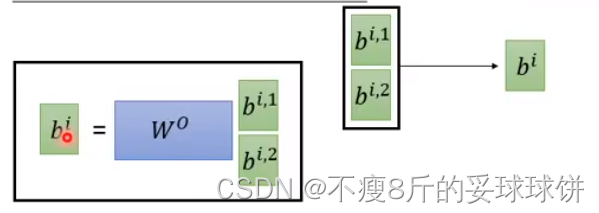
- no position information in self-attention -- input sequence的顺序不重要
- origin paper: each position has a unique position vector
(not learned from data)
参考链接:
Transformer论文解读一(Transformer)_蓝鲸鱼BlueWhale的博客-CSDN博客_transformer论文


