
- 1JVM 详细解读
- 2Debezium日常分享系列之:Debezium2.5稳定版本之Oracle连接器的工作原理
- 3头歌实验4:Linux系统的进程控制(编程实验)_编程要求 通过提示,在右侧编辑器中补充代码,完成在指定文件中添加内容,具体要求如
- 4图神经网络与计算机视觉的融合:挖掘潜力、探索前沿_图神经网络 计算机视觉
- 5彻底理解DDS(信号发生器)的fpga实现(verilog设计代码)_dds信号发生器
- 6加载更多功能的实现
- 7chatgpt赋能python:Python中的mid函数
- 8[自然语言处理] 自然语言处理库spaCy使用指北_spacy里面的nlp用法
- 9自定义神经网络二之模型训练推理_模型推理 训练
- 10UEC++学习(十一)AI行为树
ElasticSearch_jieba和es那个好
赞
踩
ES概述
ElasticSearch是一个分布式,高性能、高可用、可伸缩、RESTful 风格的搜索和数据分析引擎。
底层使用的是Lucene。
倒排索引
- 将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
- 当用户去查询数据时,会将用户的查询关键字进行分词。
- 然后去分词库中匹配内容,最终得到数据的id标识。根据id标识去存放数据的位置拉取到指定的数据。
ES的使用场景
ES是一个近实时(NRT)的搜索引擎,一般从添加数据到能被搜索到只有很少的延迟(大约是1s),而查询数据是实时的。一般我们可以把ES配合logstash,kibana来做日志分析系统,或者是搜索方面的系统功能,比如在网上商城系统里实现搜索商品的功能。
疑问一:搜索商品的时候为啥要用ES呢?用sql的like进行模糊查询,它不香吗?
我们假设一个场景:我们要买苹果吃,咱们想买天水特产的花牛苹果,然后在搜索框输入天水花牛苹果,这时候咱们希望搜索到所有的售卖天水花牛苹果的商家,但是如果咱们技术上根据这个天水花牛苹果使用sql的like模糊查询,是不能匹配到诸如天水特产花牛苹果,天水正宗,果园直送精品花牛苹果这类的不连续的店铺的。所以sql的like进行模糊查询来搜索商品还真不香!
ES和Solr
-
Solr在查询死数据时,速度相对ES更快一些。但是数据如果是实时改变的,Solr的查询速度会降低很多,ES的查询的效率基本没有变化。
-
Solr搭建基于需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入。
-
ES对现在云计算和大数据支持的特别好。
ElasticSearch安装
咱们如果想很爽的使用ES,需要安装3个东西:ES、Kibana、ElasticSearch Head。通过Kibana可以对ES进行便捷的可视化操作,通过ElasticSearch Head可以查看ES的状态及数据,可以理解为ES的图形化界面。
这里我们安装在windows下,如果安装在linux下建议使用docker安装,方便、快捷且不易出错。
ElasticSearch安装
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
ELK都是下载完后解压即用的,解压后找到bin/elasticsearch.bat文件双击启动ElasticSearch。
验证ES:打开浏览器,输入http://127.0.0.1:9200/,
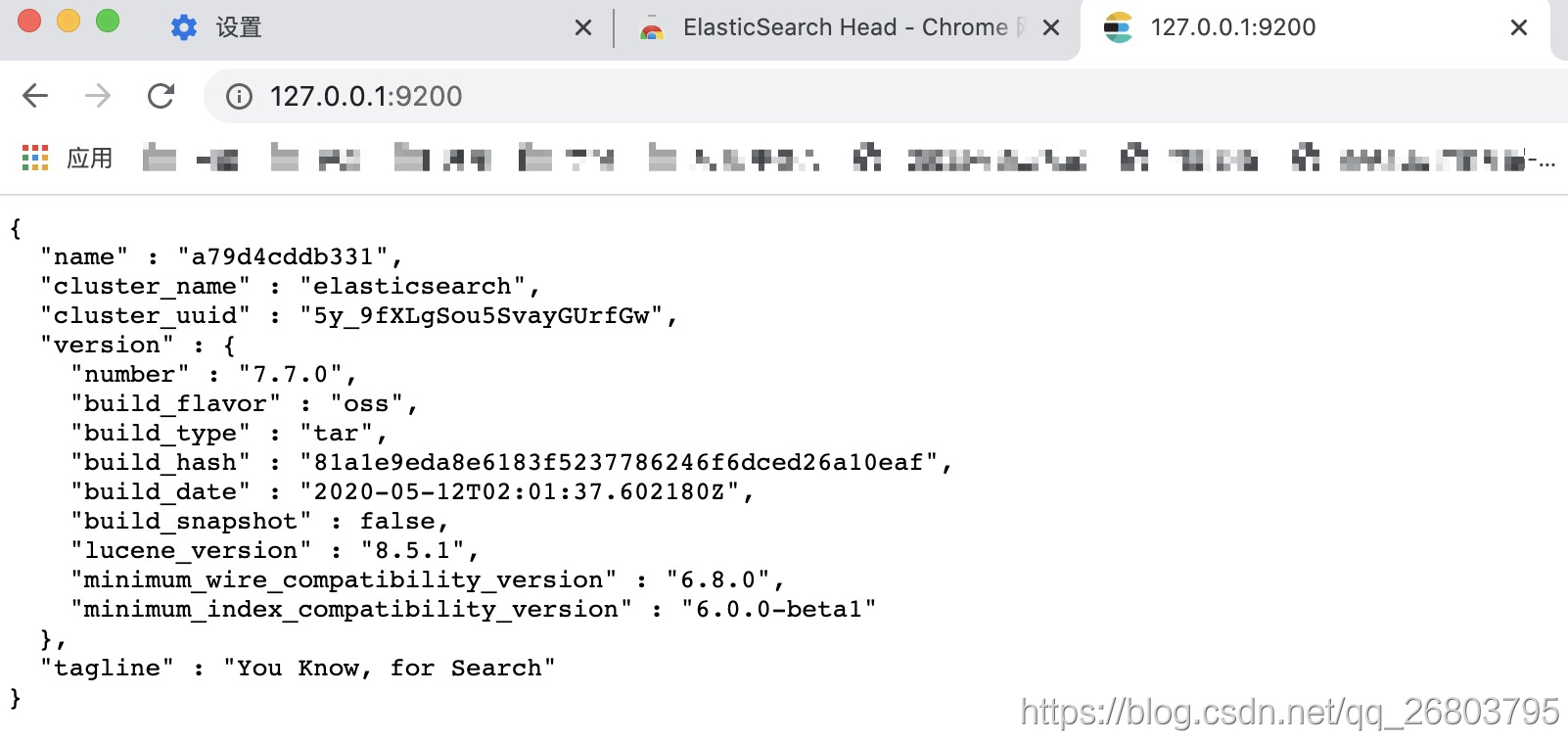
然后就看到了那句经典的:You Know, for Search:就安装成功了。
Kibana安装
下载地址:https://www.elastic.co/cn/downloads/kibana
与ElasticSearch一样,下载后解压,找到bin/kibana.bat文件双击启动kibana。(注意:需要版本对应)
验证Kibana:打开浏览器,输入http://127.0.0.1:5601/,(前提需要先启动ElasticSearch)
看到如下界面安装成功
这里面可以提供很多模拟数据,感兴趣的可以自己玩玩,咱们学习期间只要使用左下角Dev Tools(开发工具)就可以了,点击后,会出现如下界面:
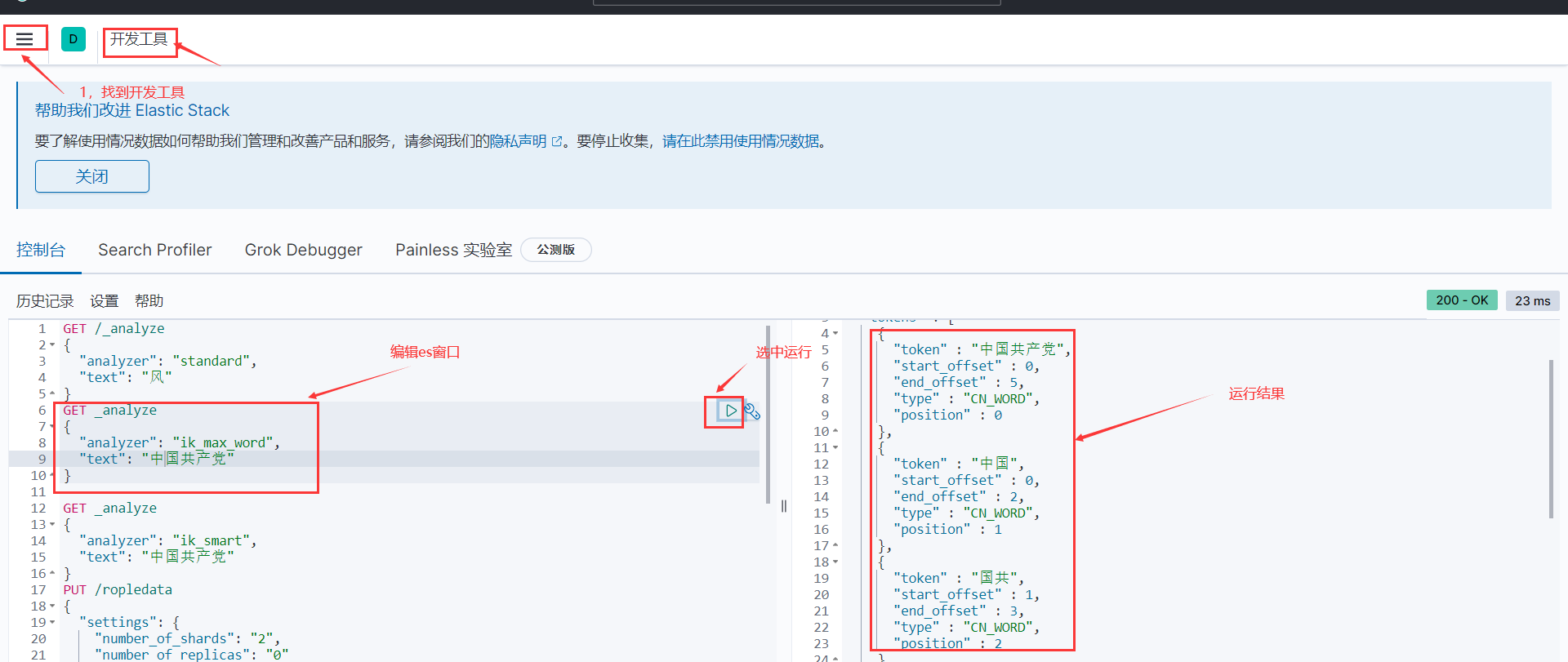
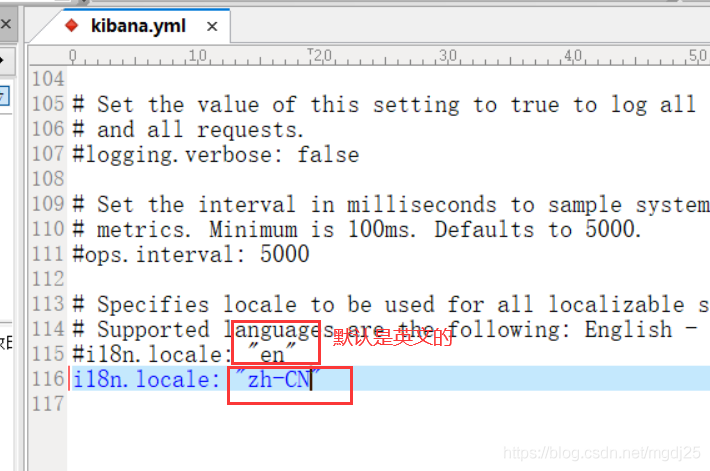
大家可以看到我的界面是中文的,但默认是英文的。这个是可以自己更改的。
找到kibana下面的config/kibana.yml文件

在文件末追加i18n.locale: “zh-CN”,保存后,重启kibana。就可以看到汉化后的界面了
ES Head安装
这个更简单,它是一个浏览器的扩展程序,直接在chrome浏览器扩展程序里下载安装即可:(当然也可以下载ES Head然后安装)
- 打开chrome浏览器,在扩展程序chrome应用商店那里,搜索elasticsearch:
- 选择ElasticSearch Head,点击
添加至Chrome,进行扩展程序的安装即可:
验证ES Head:
这个更简单,只需要点击之前咱们安装的那个扩展程序图标就可以了:
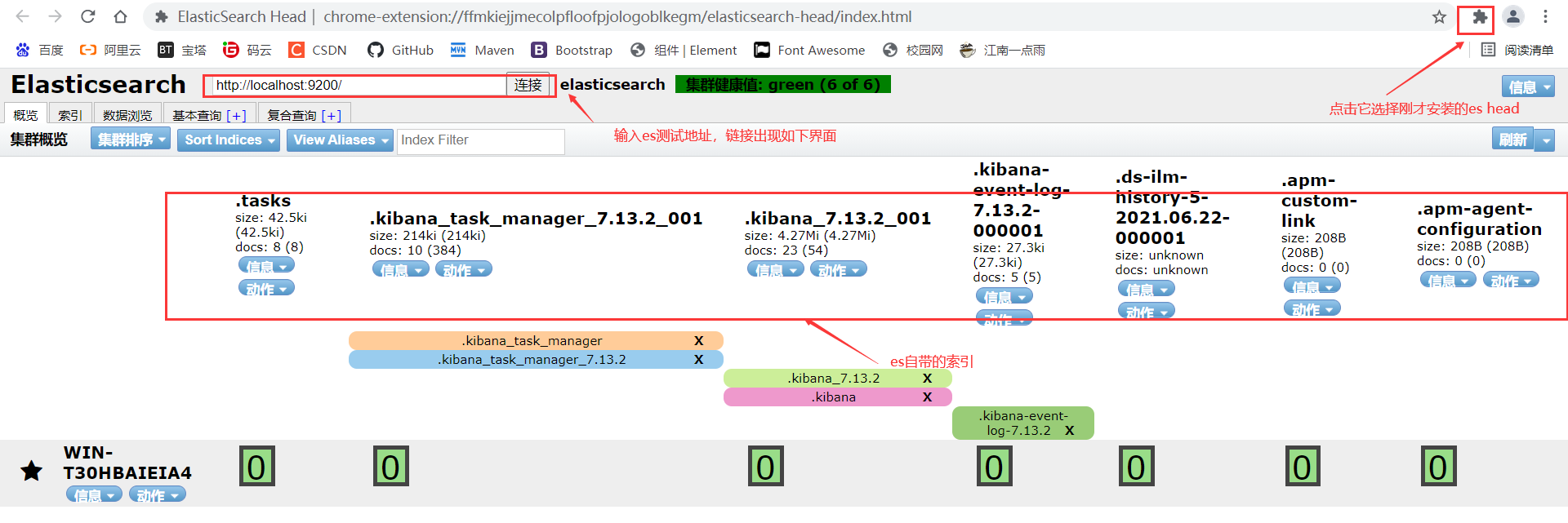
通过验证,我们已经全部安装配置成功了。
ES内置分词器
咱们知道Elasticsearch之所以模糊查询这么快,是因为采用了倒排索引,而倒排索引的核心就是分词,把text格式的字段按照分词器进行分词并编排索引。为了发挥自己的优势,Elasticsearch已经提供了多种功能强大的内置分词器,它们的作用都是怎样的呢?能处理中文吗?
首先咱们可以对Elasticsearch提供的内置分词器的作用进行如下总结:
| 分词器 | 作用 | |
|---|---|---|
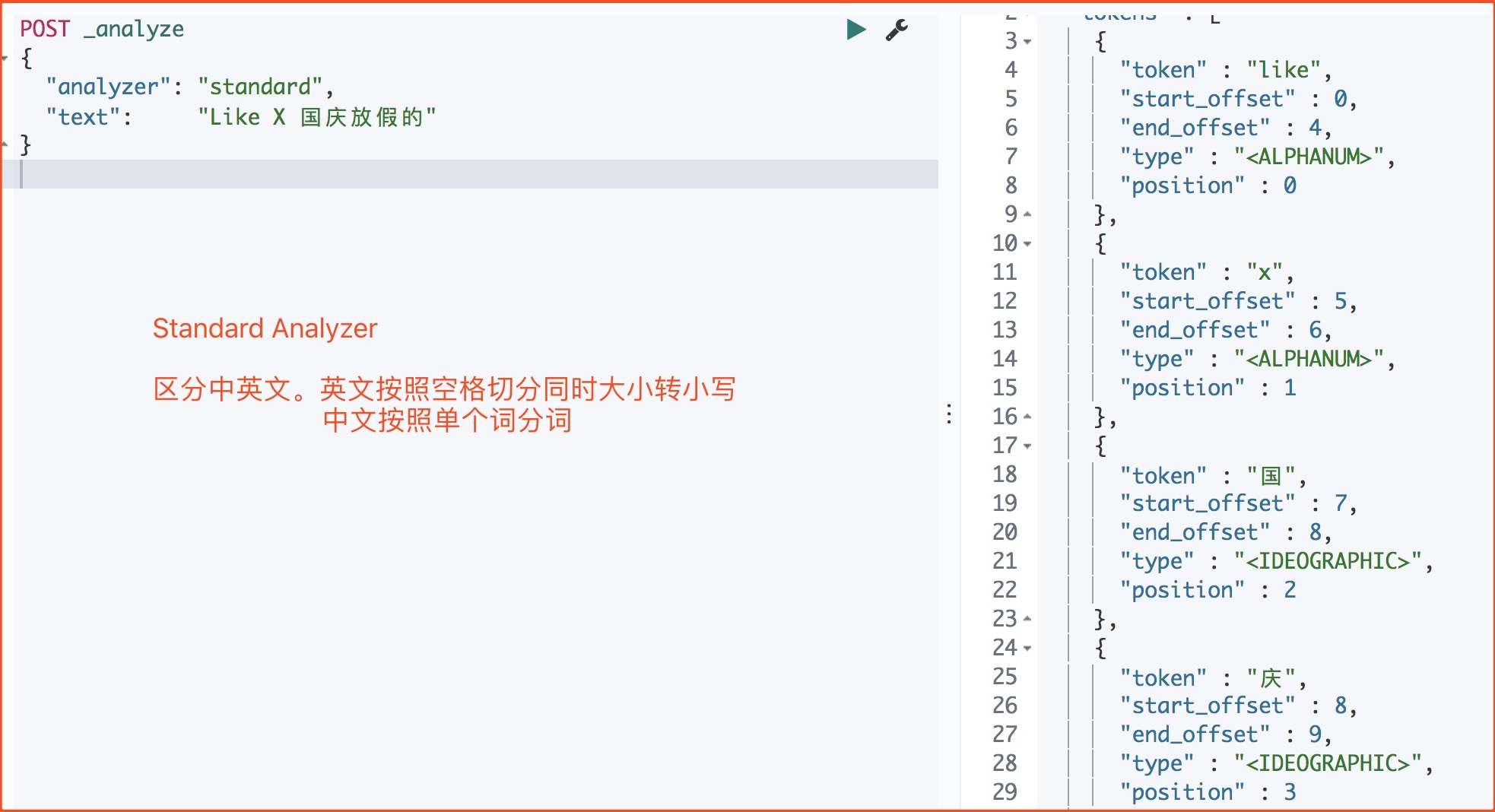
| Standard | ES默认分词器,英文按空格分且大写转小写,中文按单个词分 | |
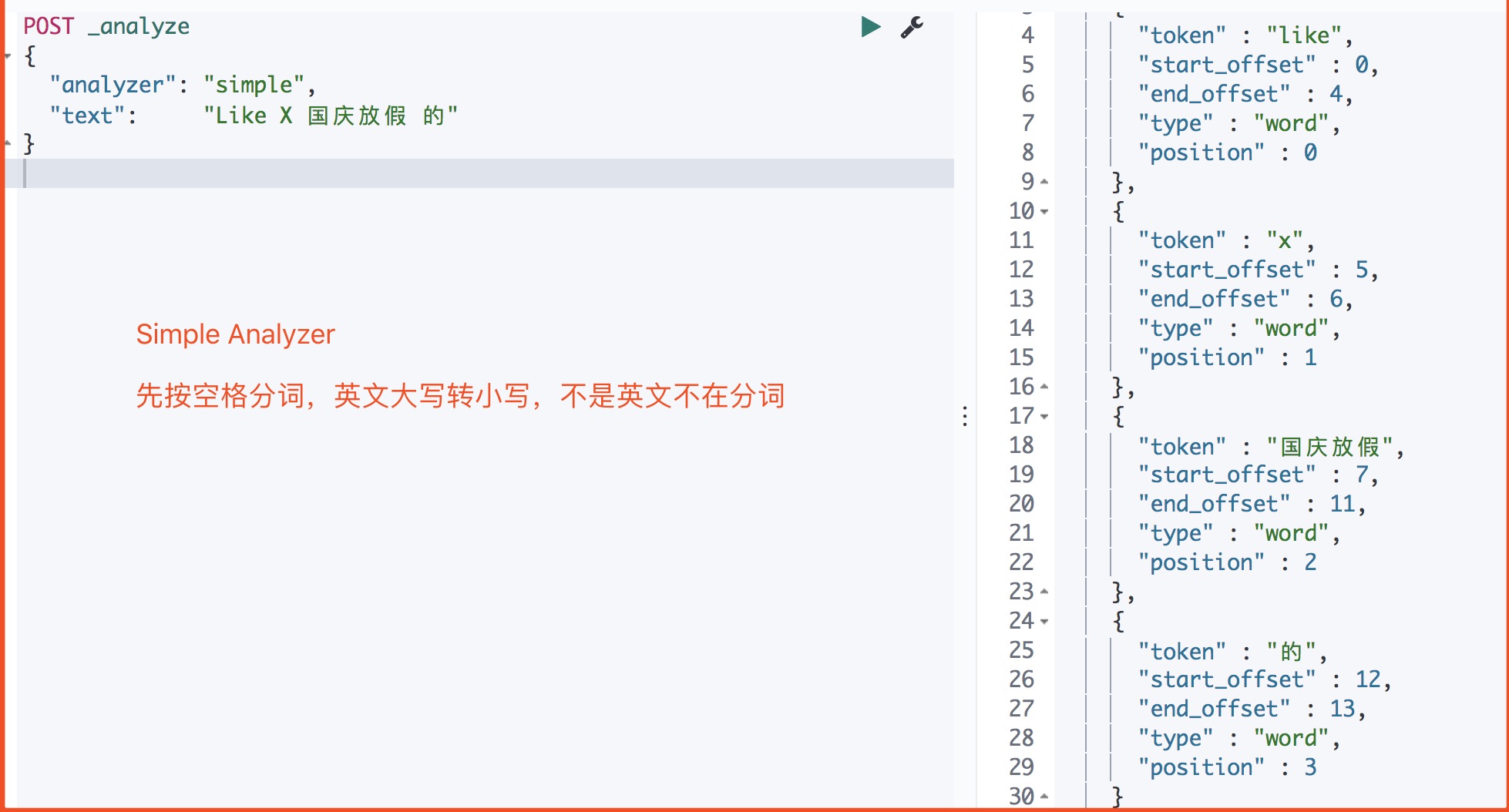
| Simple | 按照非字母切分,然后去除非字母并进行小写处理 | |
| Stop | 按照停用词过滤并进行小写处理,停用词包括the、a、is | |
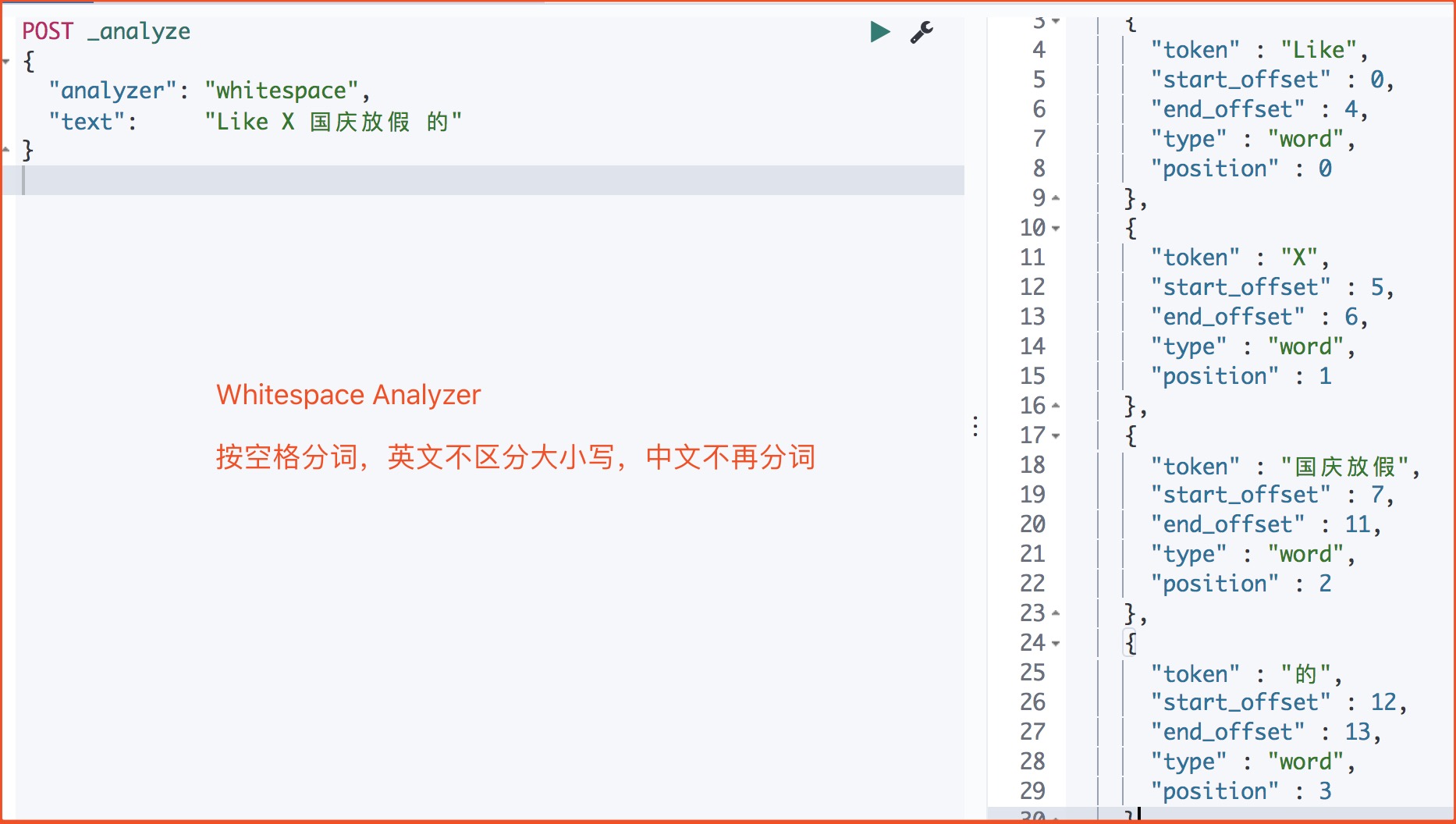
| Whitespace | 按照空格切分 | |
| Language | 据说提供了30多种常见语言的分词器 | |
| Patter | 按照正则表达式进行分词,默认是\W+ ,代表非字母 | |
| Keyword | 不进行分词,作为一个整体输出 |
下面讲解下常见的几个分词器:
Standard Analyzer(默认)
POST _analyze
{
"analyzer": "standard",
"text": "Like X 国庆放假的"
}
- 1
- 2
- 3
- 4
- 5
Simple Analyzer
POST _analyze
{
"analyzer": "simple",
"text": "Like X 国庆放假 的"
}
- 1
- 2
- 3
- 4
- 5
Whitespace Analyzer
POST _analyze
{
"analyzer": "whitespace",
"text": "Like X 国庆放假 的"
}
- 1
- 2
- 3
- 4
- 5
Keyword
GET _analyze
{
"analyzer": "keyword",
"text": "Like X 国庆放假的"
}
- 1
- 2
- 3
- 4
- 5

可以发现,这些内置分词器擅长处理单词和字母,所以如果咱们要处理的是英文数据的话,它们的功能可以说已经很全面了!那处理中文效果怎么样呢?下面咱们举例验证一下。
内置分词器对中文的局限性
首先咱们创建一个索引,并批量插入一些包含中文和英文的数据:
// 创建索引
PUT /ropledata
{
"settings": {
"number_of_shards": "2",
"number_of_replicas": "0"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

es head中刷新即可看到新创建的索引
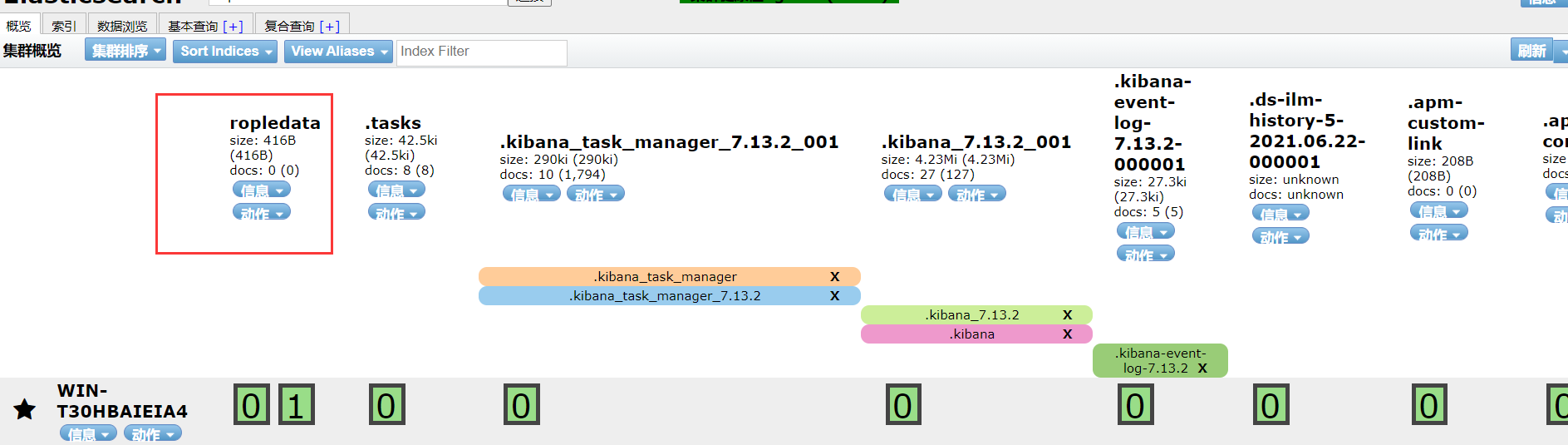
批量插入数据
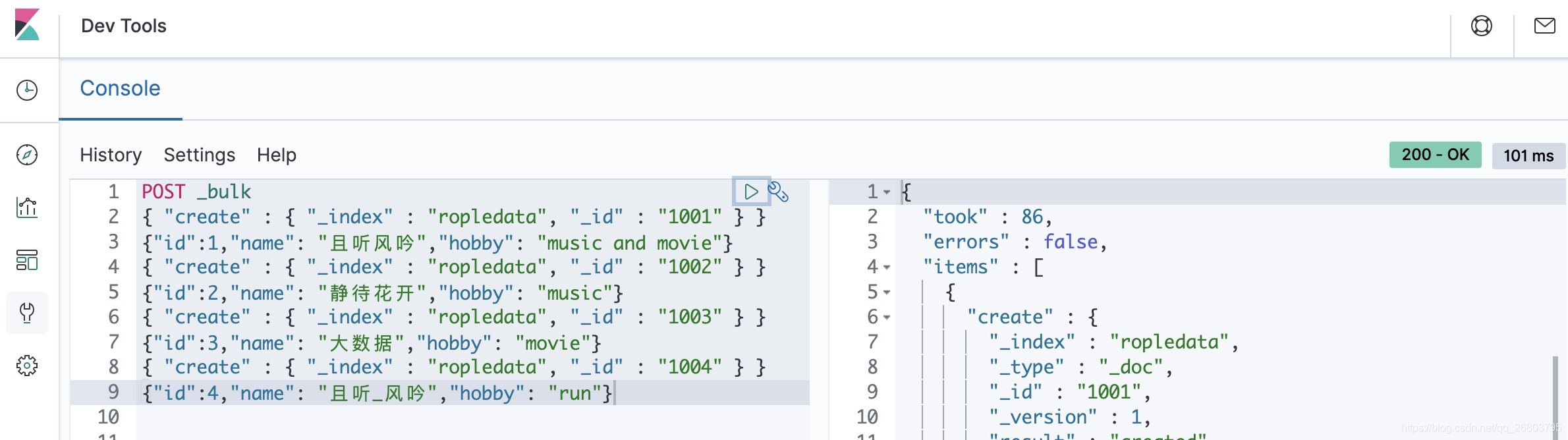
// 批量插入数据
POST _bulk
{ "create" : { "_index" : "ropledata", "_id" : "1001" } }
{"id":1,"name": "且听风吟","hobby": "music and movie"}
{ "create" : { "_index" : "ropledata", "_id" : "1002" } }
{"id":2,"name": "静待花开","hobby": "music"}
{ "create" : { "_index" : "ropledata", "_id" : "1003" } }
{"id":3,"name": "大数据","hobby": "movie"}
{ "create" : { "_index" : "ropledata", "_id" : "1004" } }
{"id":4,"name": "且听_风吟","hobby": "run"}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在kibana的Dev Tools里执行情况:
查看Elasticsearch head里ropledata索引下的数据:
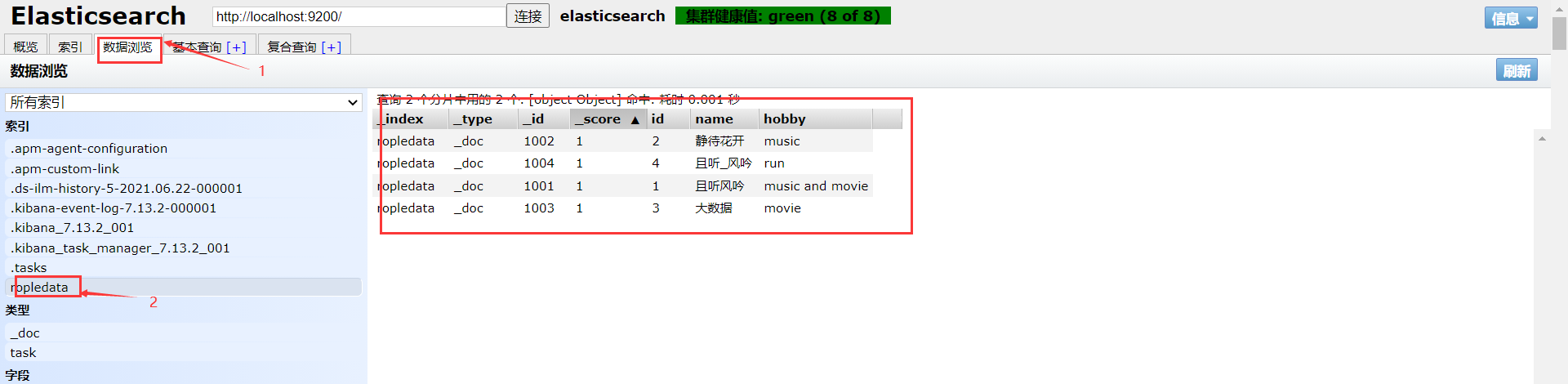
这里我碰到一个问题,那就是使用 Elasticsearch Head 查看“数据浏览”时,右侧不出数据。如果可以正常看到数据(忽略这一段)
解决方法
进入 es-head 安装目录,找到 vendor.js文件,编辑它。 共有两处需要修改
将 6886行
contentType: "application/x-www-form-urlencoded"修改为contentType: "application/json;charset=UTF-8"
然后再将 7574行
var inspectData = s.contentType === "application/x-www-form-urlencoded"&& 修改为var inspectData = s.contentType === "application/json;charset=UTF-8" &&
保存退出vendor.js,强制刷新浏览器验证。就出来了。
- 首先咱们查询爱好包含 ”music“ 的用户数据,根据咱们之前录入的数据,应该返回第一条和第三条才对,代码如下:
POST /ropledata/_search
{
"query" : {
"term" : {
"hobby" : "music"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果:
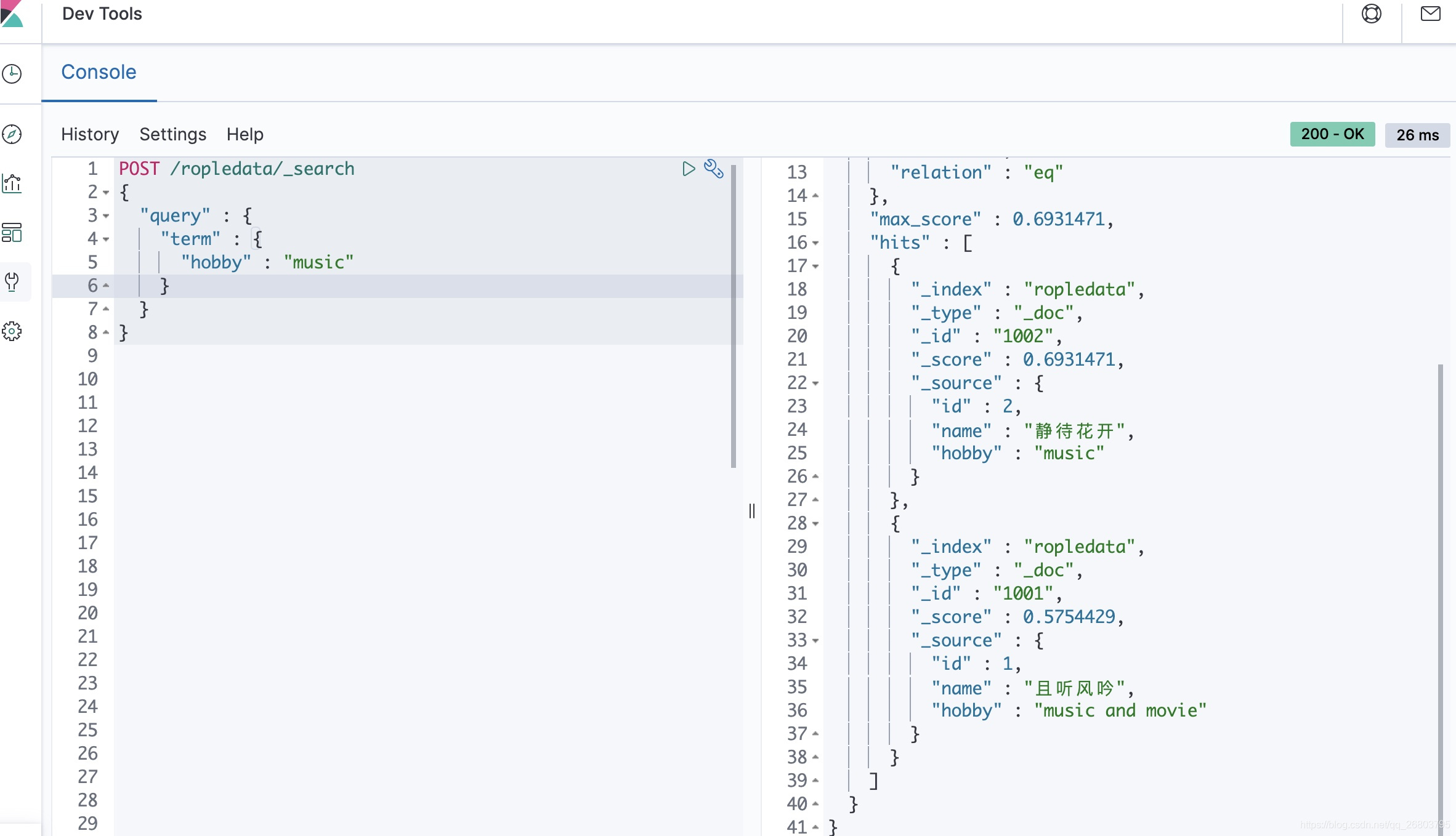
可以看到,很顺利的就查出来咱们期望的数据,所以在英文词汇下,即使是默认的分词器Standard也够用了。
- 然后咱们试一下查找名字包含 “风吟” 的用户,理想情况下,应该能返回第二条和第三条数据才对,咱们执行如下代码:
POST /ropledata/_search
{
"query" : {
"term" : {
"name" : "风吟"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果:
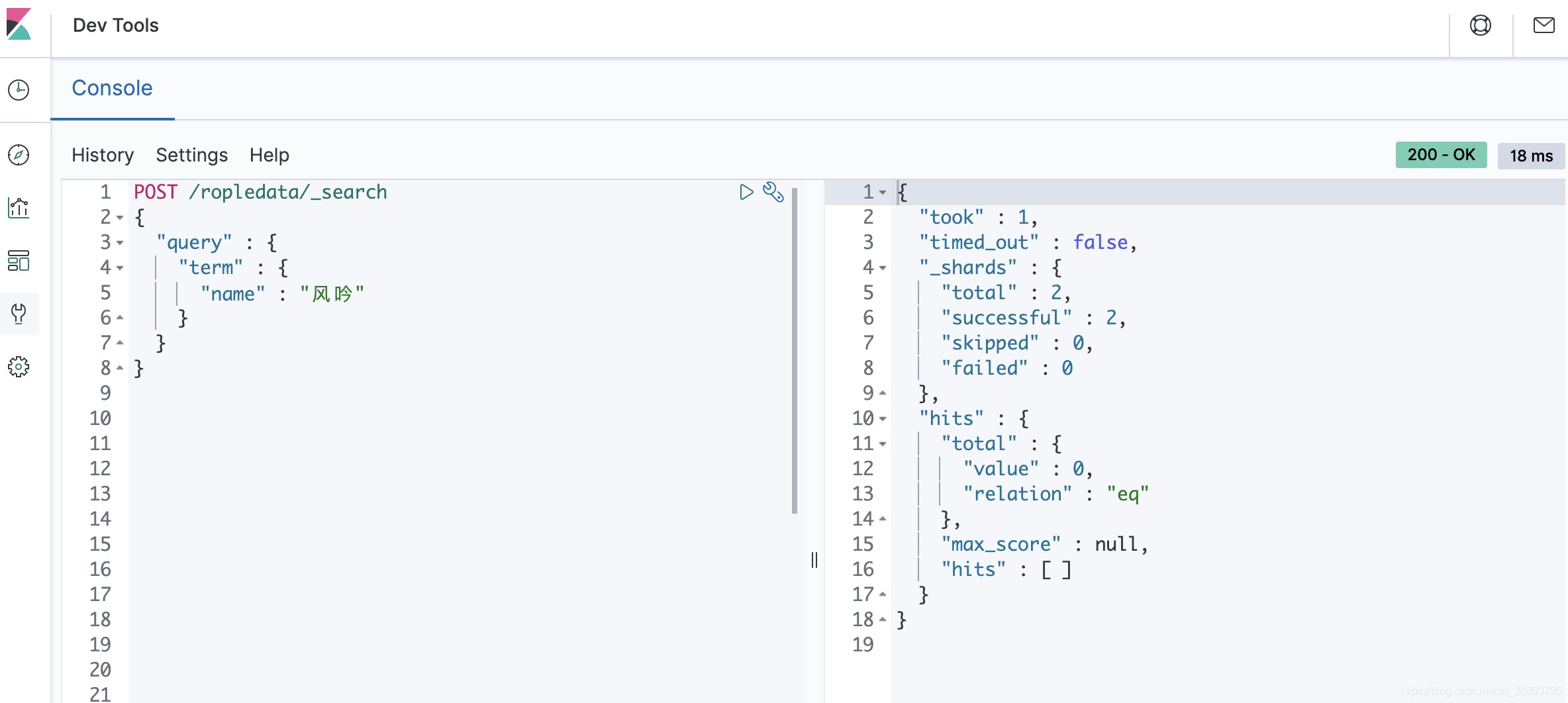
我们可以发现,查中文词汇居然什么都没有匹配到,好奇怪呀!
疑问一:为什么在默认分词器下,不能查找到词汇呢?
因为咱们中文是非常博大精深的,词汇是由多个汉字组成的,不像英文,一个词汇就是一个单词,比如“music”对应音乐,汉字需要两个字才可以表示。而内置分词器是没有考虑到这类情况的,所以它们切分汉字时就会全部切分成单个汉字了,因此咱们找不到“风吟”这条数据,但是应该可以找到“风”这条数据,咱们接下来试一下。
POST /ropledata/_search
{
"query" : {
"term" : {
"name" : "风"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
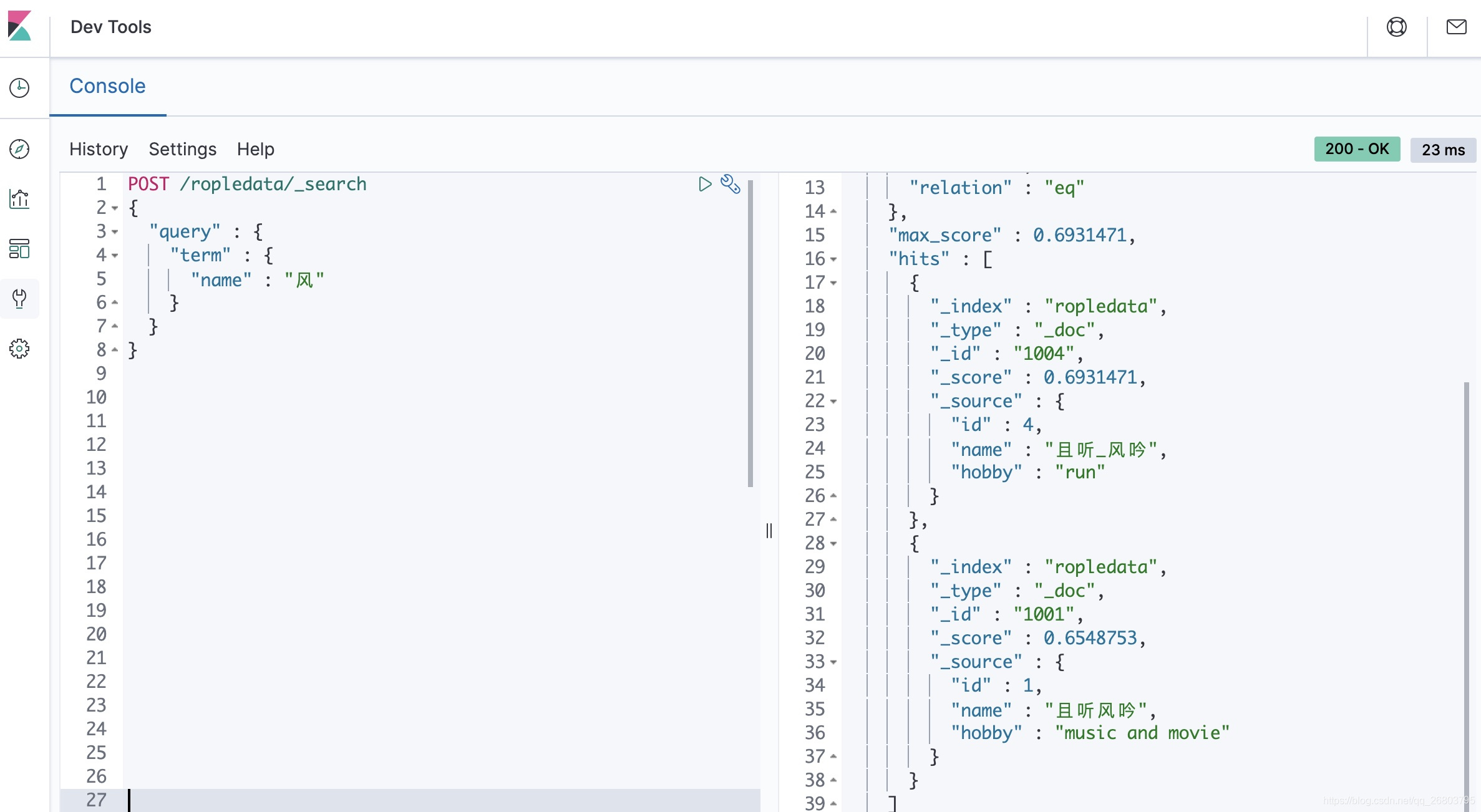
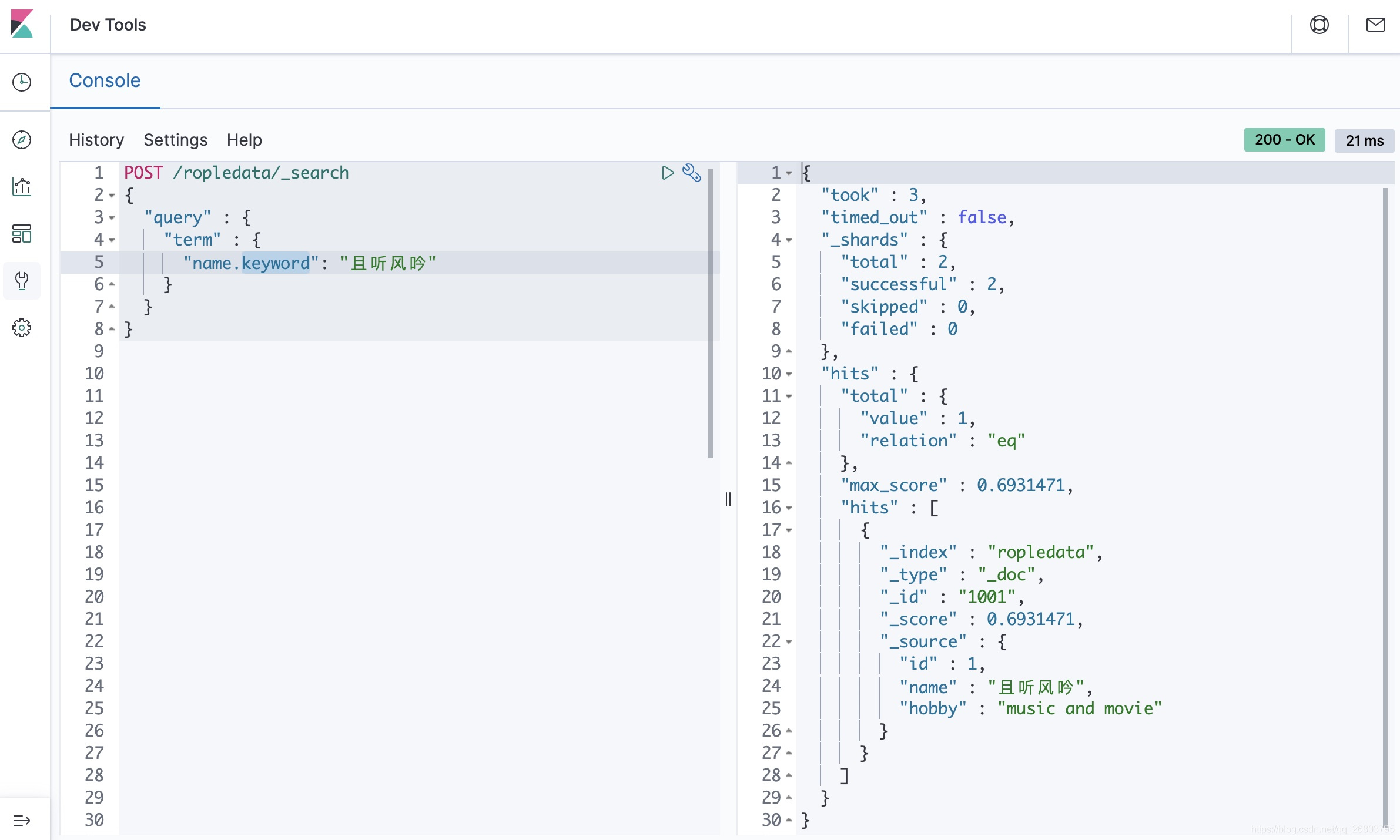
所以,咱们刚才对这个疑问的解释是正确的。如果想匹配到某条数据而不想让它分词,需要使用keyword,这样对应的text就会作为一个整体来查询:
为了解决中文分词的问题,咱们需要掌握至少一种中文分词器,常用的中文分词器有IK、jieba、THULAC等,推荐使用IK分词器,这也是目前使用最多的分词器。
安装使用IK分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases。
下载完后,创建一个ik文件夹将它解压到这个文件夹下,然后把这个文件放在elasticsearch-7.13.2\plugins文件夹下

注意:plugins文件夹和它的子文件夹中不能有es不能处理的文件,如压缩文件,和其他不想关的文件。不然重启elasticserach会闪退。
重启es,验证分词器
IK提供了两个分词算法: ik_ smart和ik_ max_ word ,其中ik_ smart为最少切分, ik_ max_ _word为最细粒度划分!一会我们测试!
ik_ smart为最少切分
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
- 1
- 2
- 3
- 4
- 5
运行结果
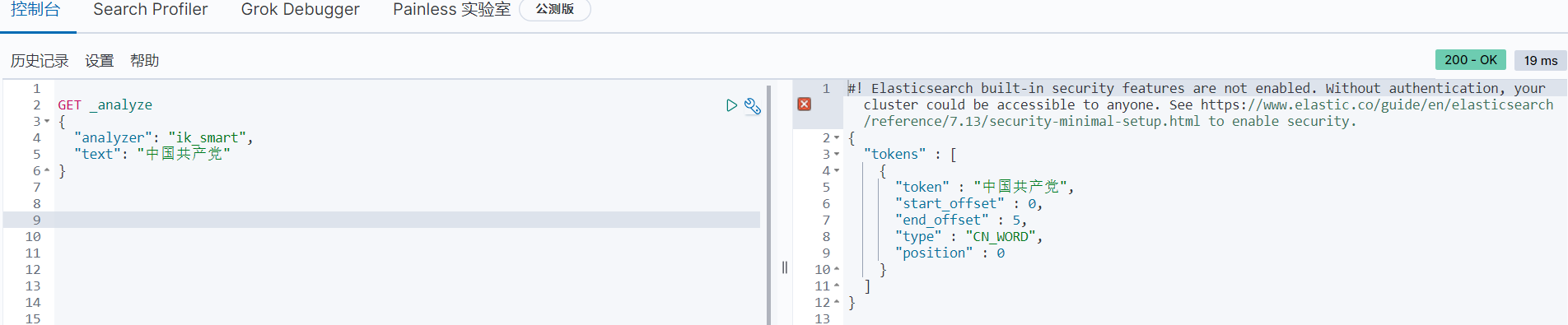
ik_ max_ _word为最细粒度划分!
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
- 1
- 2
- 3
- 4
- 5
运行结果
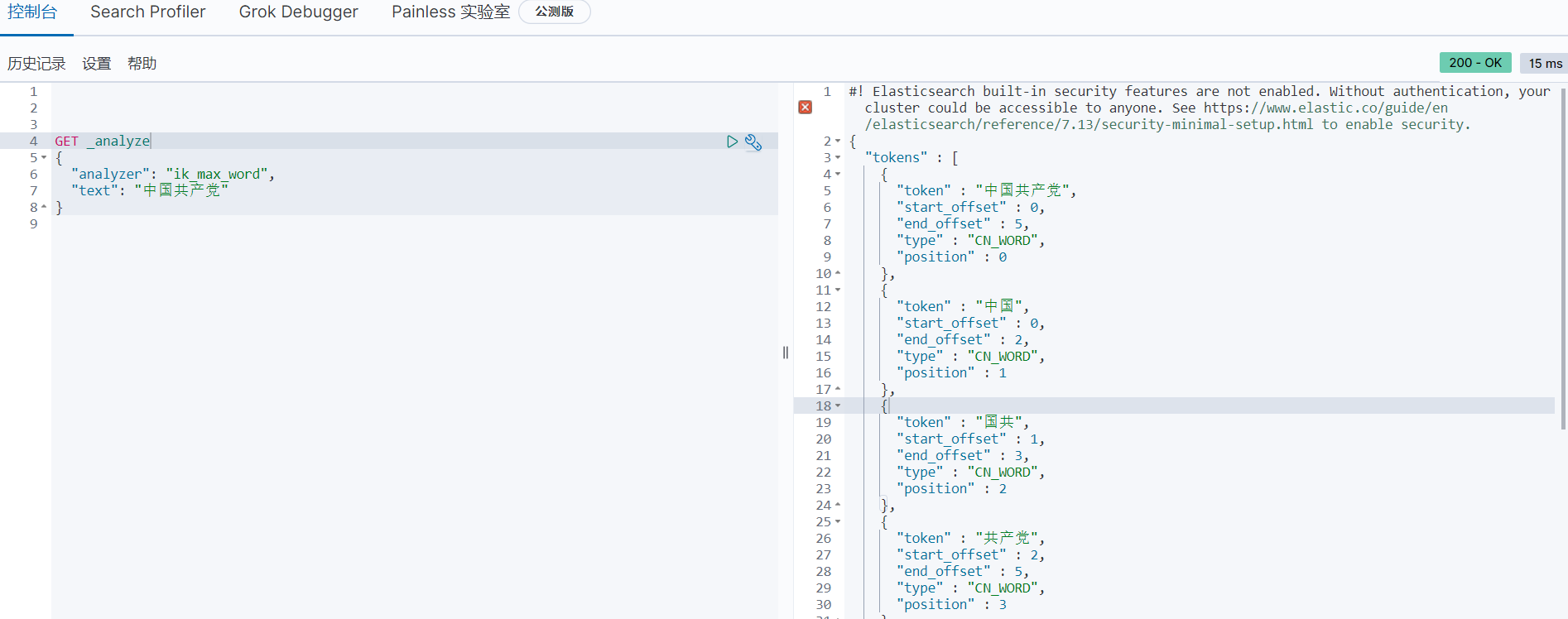
可以看到所有可能组成词语的都被ik分词器分开了。不再是一个中文字就分词。
前面我们查“风吟”什么都没有匹配到,现在再查一次。
POST /ropledata/_search
{
"query": {
"match": {
"name": "风吟"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
运行结果:
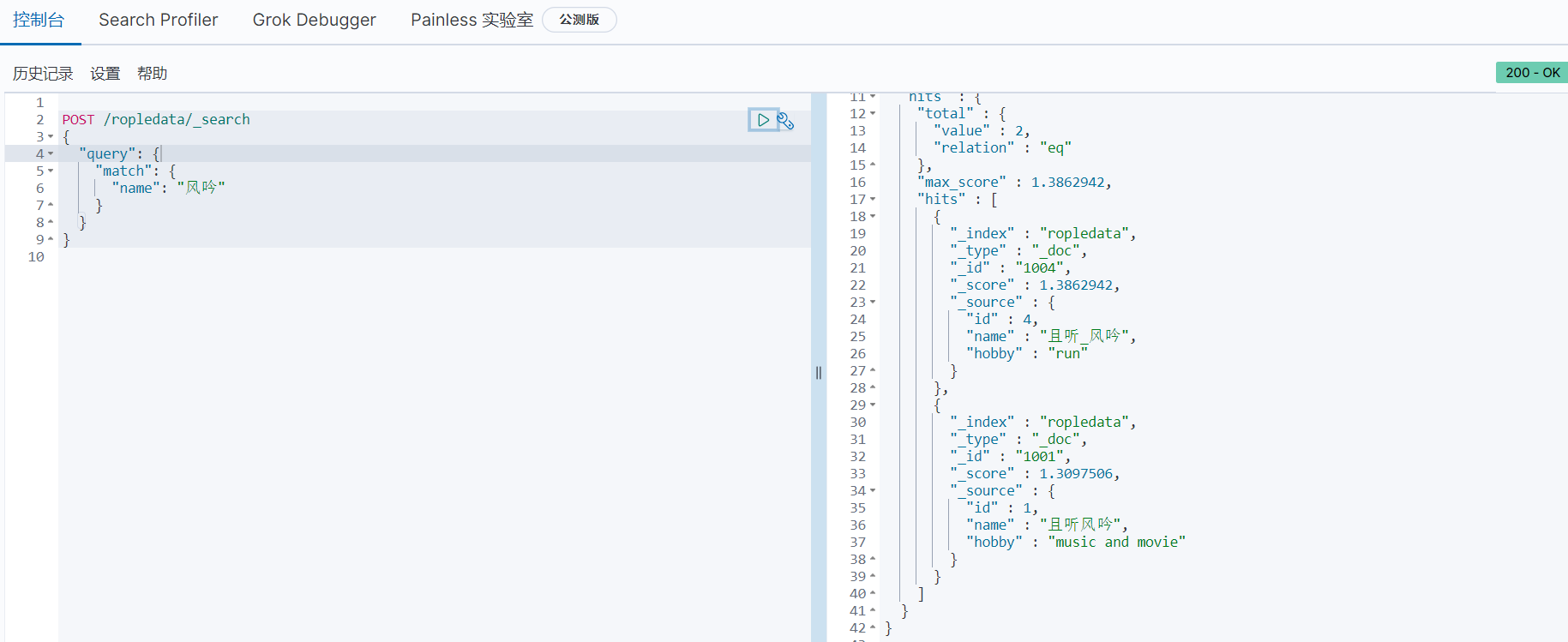
可以发现它查到了数据。
**ik分词器是根据什么来分词的呢?**如果有些特殊的词汇比如人名,店名,网名,想根据自己的要求特殊处理来分词,能不能解决呢?
ik分词器本身维护了一个超大的词汇文本,里面有非常多的中文词汇。这个文件在
ik/config/下,名为main.dic,咱们可以打开看看:
如果要根据自己的特殊词汇来切分,咱们可以把想要切分成的词汇加入到这个文件里面就可以了。
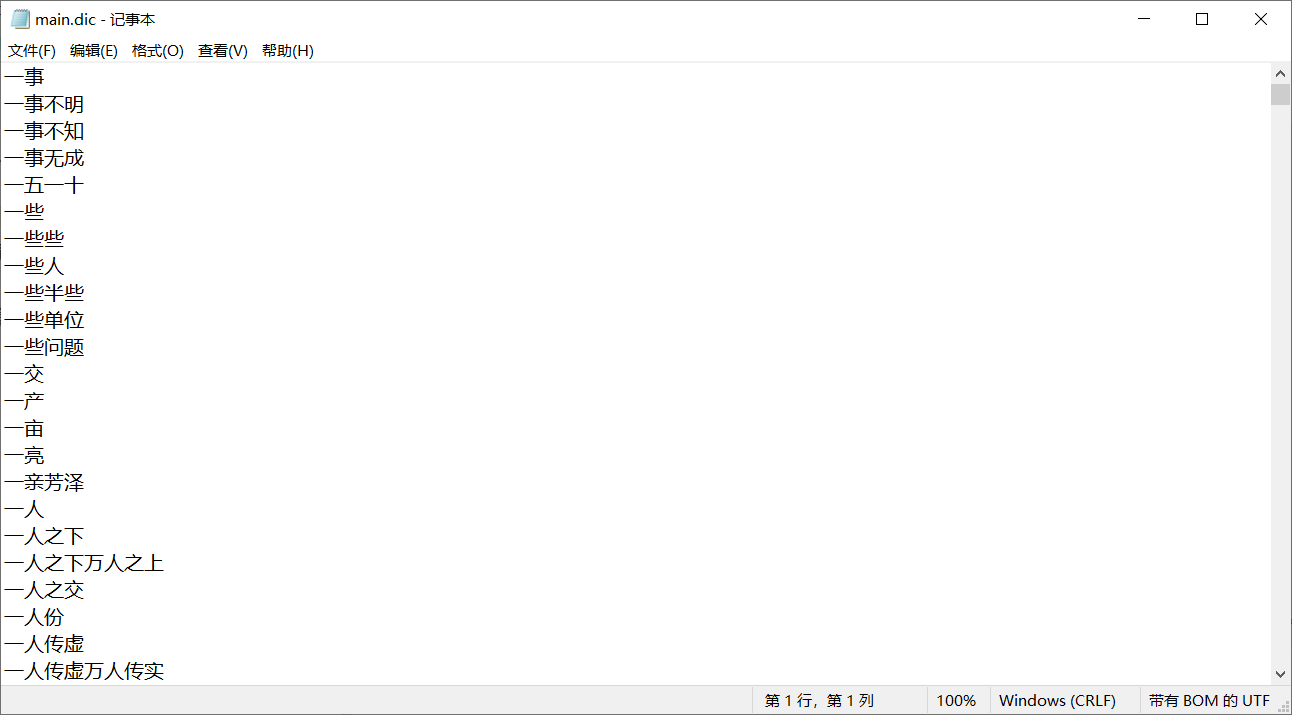
ElasticSearch基本概念
第一次学习ES,看到基本概念后瞬间懵逼了,其实可以把它当成数据库来对比学习(但它不是数据库)
| ES | MySql |
|---|---|
| 索引 | 数据库 |
| 类型 | (已废弃) 表 |
| 文档 | 一行数据 |
| 字段 | 列 |
下面我们对这些概念分别进行详细的解释:
文档(Document)
- 我们知道Java是面向对象的,而Elasticsearch是面向文档的,也就是说文档是所有可搜索数据的最小单元。ES的文档就像MySql中的一条记录,只是ES的文档会被序列化成json格式,保存在Elasticsearch中;
- 这个json对象是由字段组成,字段就相当于Mysql的列,每个字段都有自己的类型(字符串、数值、布尔、二进制、日期范围类型);当我们创建文档时,如果不指定字段的类型,Elasticsearch会帮我们自动匹配类型;
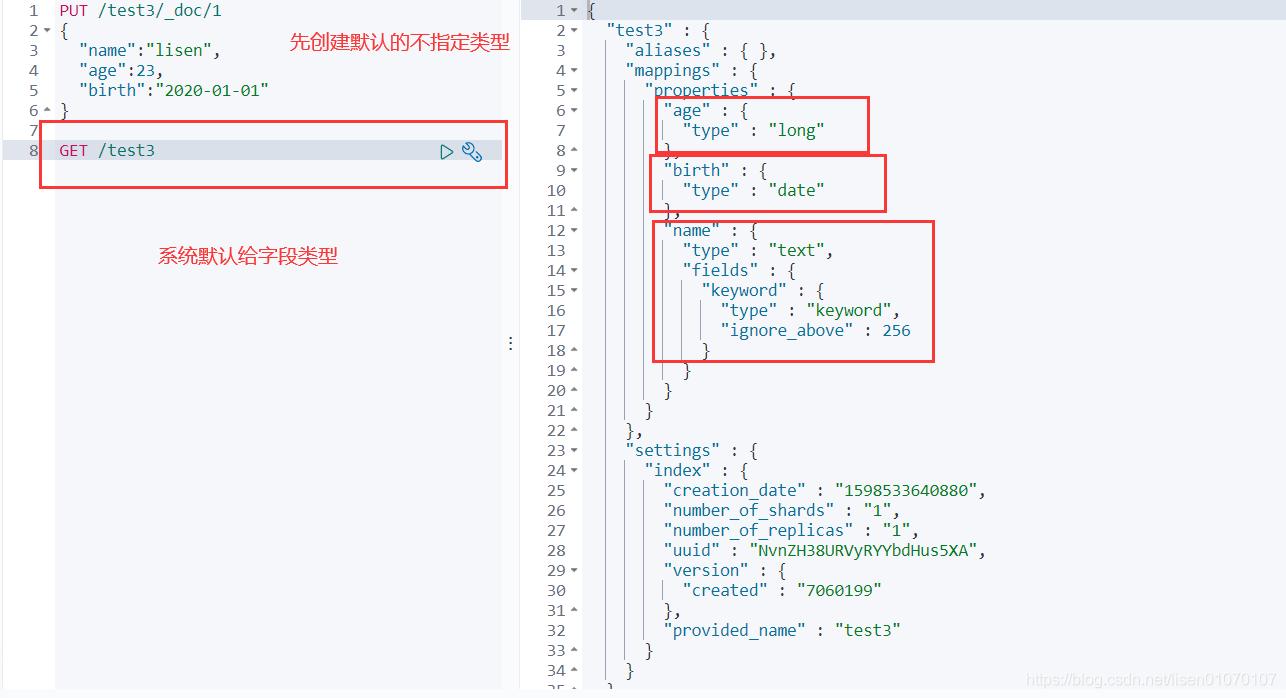
- 每个文档都有一个ID,类似MySql的主键,咱们可以自己指定,也可以让Elasticsearch自动生成;
类型(Type)
类型就相当于MySql里的表,我们知道MySql里一个库下可以有很多表,最原始的时候ES也是这样,一个索引下可以有很多类型,但是从7.0版本开始,type已经废弃,一个索引就只能创建一个类型了(_doc)。
索引(Index)
索引就相当于MySql里的数据库,它是具有某种相似特性的文档集合。索引的名称必须全部是小写;
索引具有mapping和setting的概念,mapping用来定义文档字段的类型,setting用来定义不同数据的分布。除了这些常用的概念,我们还需要知道节点概念的作用,因此咱们接着往下看!
节点(node)
一个节点就是一个ES实例,其实本质上就是一个java进程;ES的节点类型主要分为如下几种:
- Master Eligible节点:每个节点启动后,默认就是Master Eligible节点,可以通过设置node.master: false 来禁止。Master Eligible可以参加选主流程,并成为Master节点(当第一个节点启动后,它会将自己选为Master节点);注意:每个节点都保存了集群的状态,只有Master节点才能修改集群的状态信息。
- Data节点:可以保存数据的节点。主要负责保存分片数据,利于数据扩展。
- Coordinating 节点:负责接收客户端请求,将请求发送到合适的节点,最终把结果汇集到一起
分片(shard)
ES里面的索引可能存储大量数据,这些数据可能会超出单个节点的硬件限制。为了解决这个问题,ES提供了将索引细分为多个碎片的功能,这就是分片。
分片的好处
- 通过分片技术,咱们可以水平拆分数据量,同时它还支持跨碎片(可能在多个节点上)分布和并行操作,从而提高性能/吞吐量;
- ES可以完全自动管理分片的分配和文档的聚合来完成搜索请求,并且对用户完全透明;
注意:主分片数在索引创建时指定,后续只能通过Reindex修改,但是较麻烦,一般不进行修改。
副本分片(replica shard)
为了实现高可用、遇到问题时实现分片的故障转移机制,ElasticSearch允许将索引分片的一个或多个复制成所谓的副本分片。
副本分片的好处
-
当分片或者节点发生故障时提供高可用性。因此,副本分片永远不会分配到复制它的原始或主分片所在的节点上;
-
可以提高扩展搜索量和吞吐量,因为ES允许在所有副本上并行执行搜索;
默认情况下,ES中的每个索引都分配5个主分片,并为每个主分片分配1个副本分片。主分片在创建索引时指定,不能修改,副本分片可以修改。
分数 score
关于查询时,分数越高排位更高。那么分数是如何计算的:
- 搜索的关键字在文档中出现的频次越高,分数就越高
- 指定的文档内容越短,分数就越高
- 我们在搜索时,指定的关键字也会被分词,这个被分词的内容,被分词库匹配的个数越多,分数越高
操作ES的RESTful语法
- GET请求:
- http://ip:port/index:查询索引信息
- http://ip:port/index/type/doc_id:查询指定的文档信息
- POST请求:
- http://ip:port/index/type/_search:查询文档,可以在请求体中添加json字符串来代表查询条件
- http://ip:port/index/type/doc_id/_update:修改文档,在请求体中指定json字符串代表修改的具体信息
- PUT请求:
- http://ip:port/index:创建一个索引,需要在请求体中指定索引的信息,类型,结构
- http://ip:port/index/type/_mappings:代表创建索引时,指定索引文档存储的属性的信息
- DELETE请求:
- http://ip:port/index:删除索引
- http://ip:port/index/type/doc_id:删除指定的文档
索引的操作
创建一个索引
比如咱们创建一个3副本2分片的名为ropledata的索引:
# 创建一个索引
PUT /ropledata
{
"settings": {
"number_of_shards": "2",
"number_of_replicas": "3"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
查看索引信息
# 查看索引信息
GET /ropledata
- 1
- 2
修改索引副本数
这里要注意,索引的分片是不允许修改的,咱们只能修改索引的副本数量,比如想把副本数量修改为2个,只需要执行:
PUT ropledata/_settings
{
"number_of_replicas" : "2"
}
- 1
- 2
- 3
- 4
删除索引
# 删除索引
DELETE /ropledata
- 1
- 2
Field可以指定的类型
字符串类型:
- text:一般被用于全文检索。 将当前Field进行分词。
- keyword:当前Field不会被分词。
数值类型:
- long:取值范围为-9223372036854774808~922337203685477480(-2的63次方到2的63次方-1),占用8个字节
- integer:取值范围为-2147483648~2147483647(-2的31次方到2的31次方-1),占用4个字节
- short:取值范围为-32768~32767(-2的15次方到2的15次方-1),占用2个字节
- byte:取值范围为-128~127(-2的7次方到2的7次方-1),占用1个字节
- double:1.797693e+308~ 4.9000000e-324 (e+308表示是乘以10的308次方,e-324表示乘以10的负324次方)占用8个字节
- float:3.402823e+38 ~ 1.401298e-45(e+38表示是乘以10的38次方,e-45表示乘以10的负45次方),占用4个字节
- half_float:精度比float小一半。
- scaled_float:根据一个long和scaled来表达一个浮点型,long-345,scaled-100 -> 3.45
时间类型:
- date类型,针对时间类型指定具体的格式
布尔类型:
- boolean类型,表达true和false
二进制类型:
- binary类型暂时支持Base64 encode string
范围类型:
- long_range:赋值时,无需指定具体的内容,只需要存储一个范围即可,指定gt,lt,gte,lte
- integer_range:同上
- double_range:同上
- float_range:同上
- date_range:同上
- ip_range:同上
经纬度类型:
- geo_point:用来存储经纬度的
ip类型:
- ip:可以存储IPV4或者IPV6
其他的数据类型参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/mapping-types.html
创建索引并指定数据结构
语法如下
# 创建索引,指定数据结构 PUT /book { "settings": { # 分片数 "number_of_shards": 5, # 备份数 "number_of_replicas": 1 }, # 指定数据结构 "mappings": { # 文档存储的Field "properties": { # Field属性名 "name": { # 类型 "type": "text", # 指定分词器 "analyzer": "ik_max_word", # 指定当前Field可以被作为查询的条件 "index": true , # 是否需要额外存储 "store": false }, "author": { "type": "keyword" }, "count": { "type": "long" }, "on-sale": { "type": "date", # 时间类型的格式化方式 "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" }, "descr": { "type": "text", "analyzer": "ik_max_word" } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
文档的操作
文档在ES服务中的唯一标识,
_index,_type,_id三个内容为组合,锁定一个文档,
新建文档(插入数据)
新建文档可以分为两种情况。一种是指定文档的id,一种是不指定。不指定的时候,ES会帮我们自动生成,不过不容易记忆,因此推荐指定id的方式。
注意:这里的ID是创建文档时候指定或者ES自动生成的那个id,那个是唯一id,而不是文档里面大括号的那个叫id 字段!
自动生成_id
POST /book/_doc
{
"name": "盘龙",
"author": "我吃西红柿",
"count": 100000,
"on-sale": "2000-01-01",
"descr": "山重水复疑无路,柳暗花明又一村"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
手动指定_id
# 添加文档,手动指定id
PUT /book/_doc/1
{
"name": "红楼梦",
"author": "曹雪芹",
"count": 10000000,
"on-sale": "1985-01-01",
"descr": "一个是阆苑仙葩,一个是美玉无瑕"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
修改文档
ES里的文档是不可以修改的,但是可以覆盖,所以ES修改数据本质上是对文档的覆盖。
ES对数据的修改分为全局更新和局部更新,下面咱们进行对比说明:
- 全局更新本质上是替换操作,即使内容一样也会去替换;
- 局部更新本质上是更新操作,只有遇到新的东西才更新,没有新的修改就不更新;
- 局部更新比全局更新的性能好,因此推荐使用局部更新。
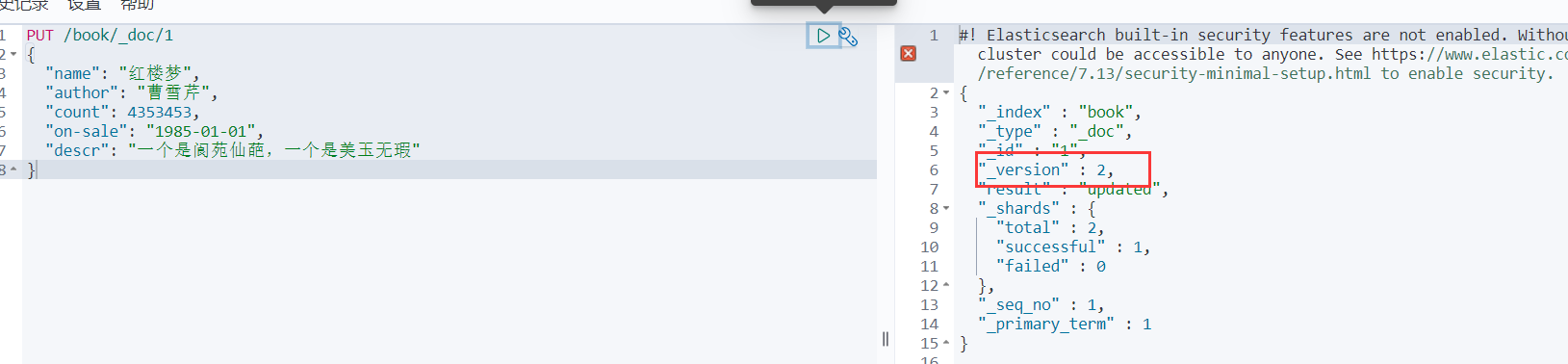
全局更新
PUT /book/_doc/1
{
"name": "红楼梦",
"author": "曹雪芹",
"count": 4353453,
"on-sale": "1985-01-01",
"descr": "一个是阆苑仙葩,一个是美玉无瑕"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
然后大家可以多全局更新几次,会发现每次全局更新之后这个文档的_version都会发生改变!
如果我们只给部分属性赋值,其他属性会怎么样呢?
PUT /book/_doc/1
{
"count": 4353453
}
- 1
- 2
- 3
- 4

可以看到其他属性默认都为空了,所以它是覆盖操作
局部更新
POST /book/_doc/1/_update
{
"doc":
{
"count": 1234565
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这时候我们可以多次去执行上面的局部更新代码,会发现除了第一次执行,后续不管又执行了多少次,_version都不再变化!
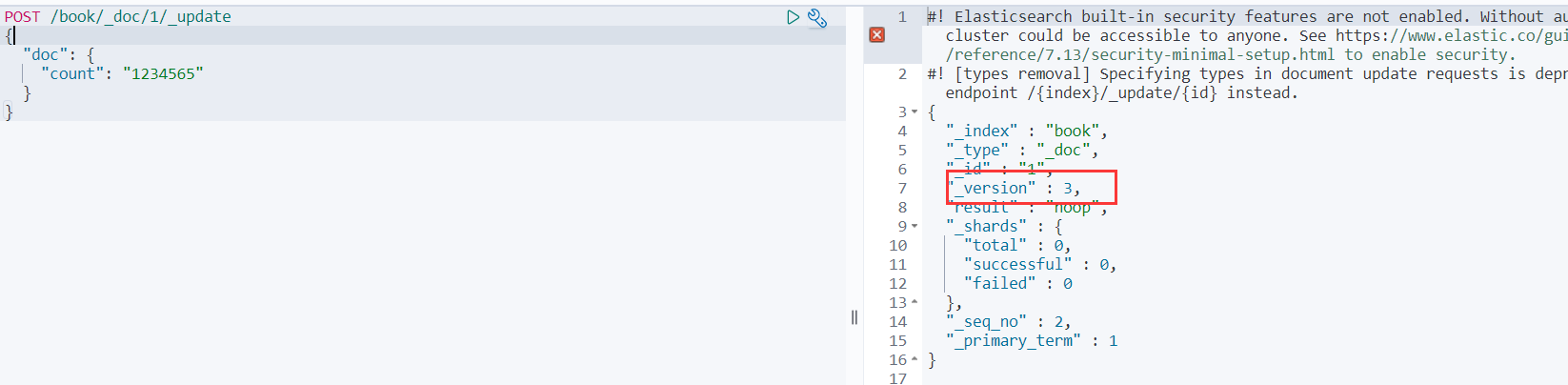
而且其他属性也都还在,只修改了count

删除文档
# 根据id删除文档
DELETE /book/_doc/_id
- 1
- 2

查询
索引ropledata中有如下数据
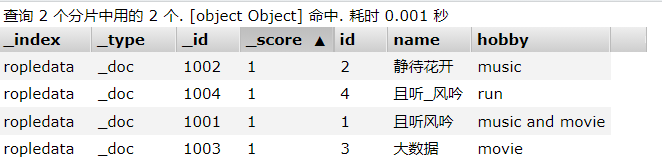
GET查询
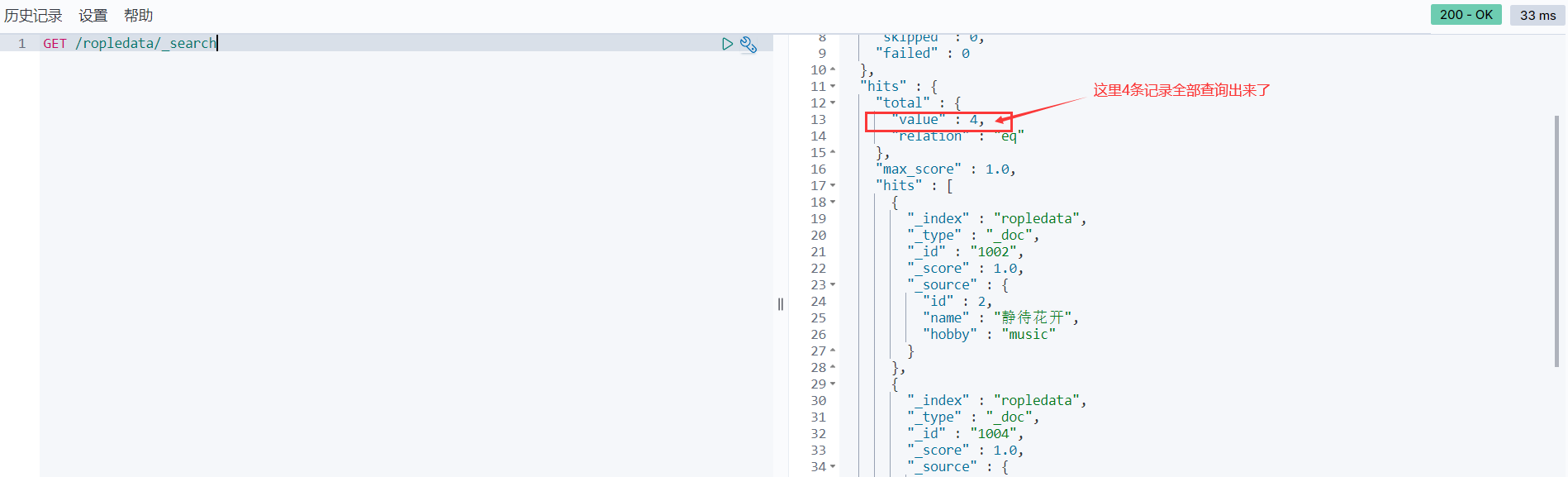
GET全局搜索数据:
GET /ropledata/_search
- 1
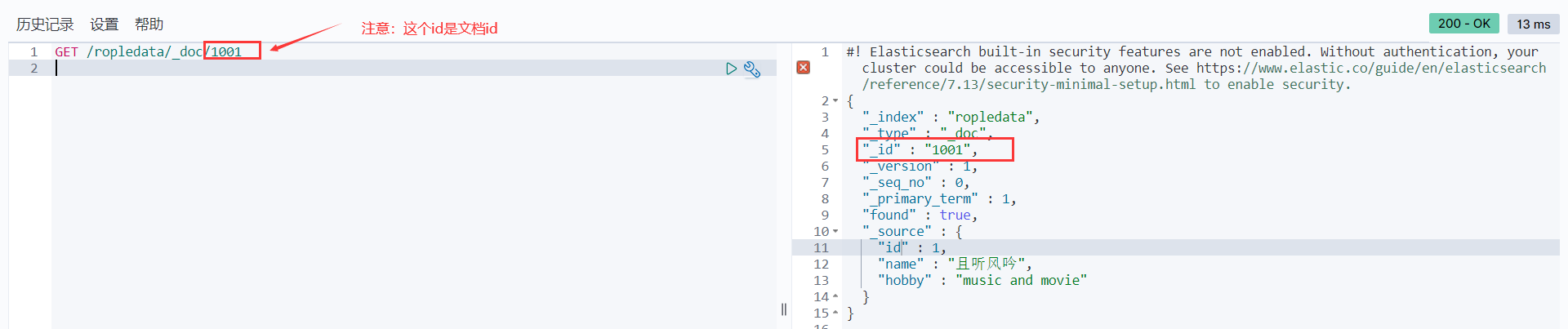
指定文档id搜索数据:
GET /ropledata/_doc/1001
- 1
根据关键字搜索数据
GET /ropledata/_search?q=name:"且听风吟"
- 1
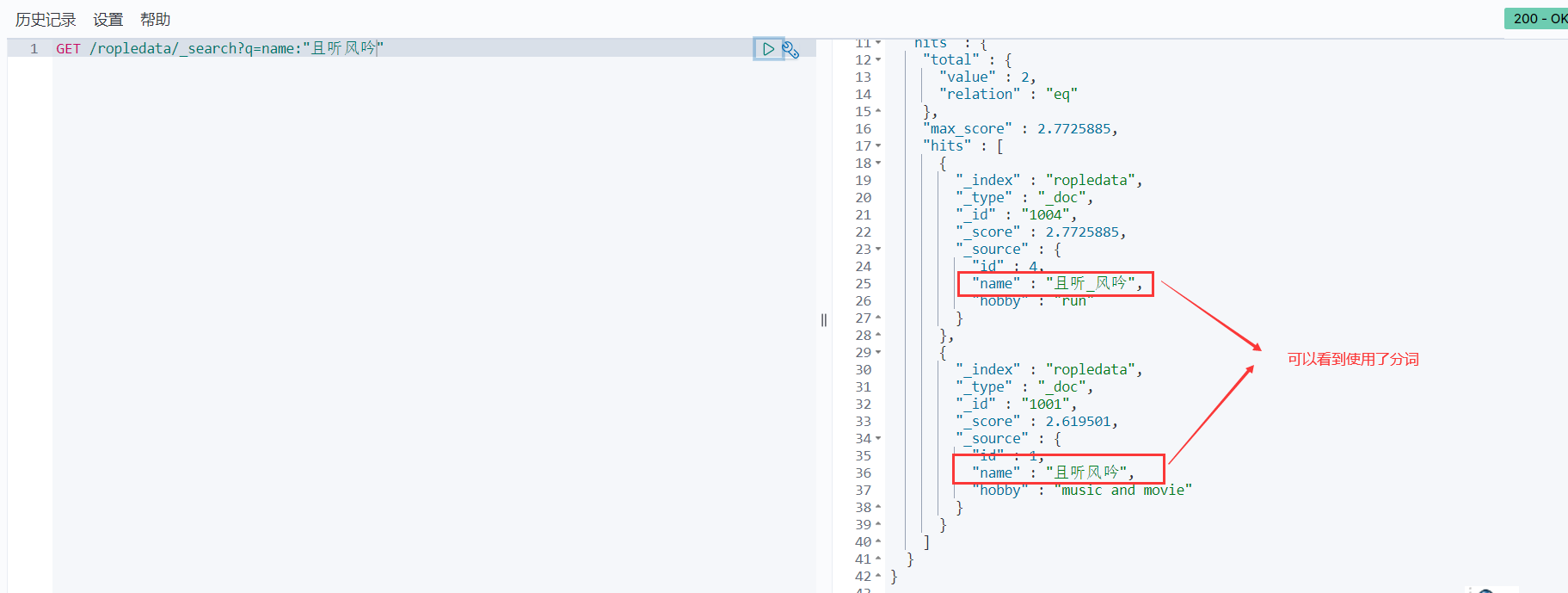
term查询
term的查询是代表完全匹配,搜索之前不会对你搜索的关键字进行分词,对你的关键字去文档分词库中去匹配内容。
比如咱们查询id字段为2的数据
POST /ropledata/_search
{
"query": {
"term": {
"id": 2
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
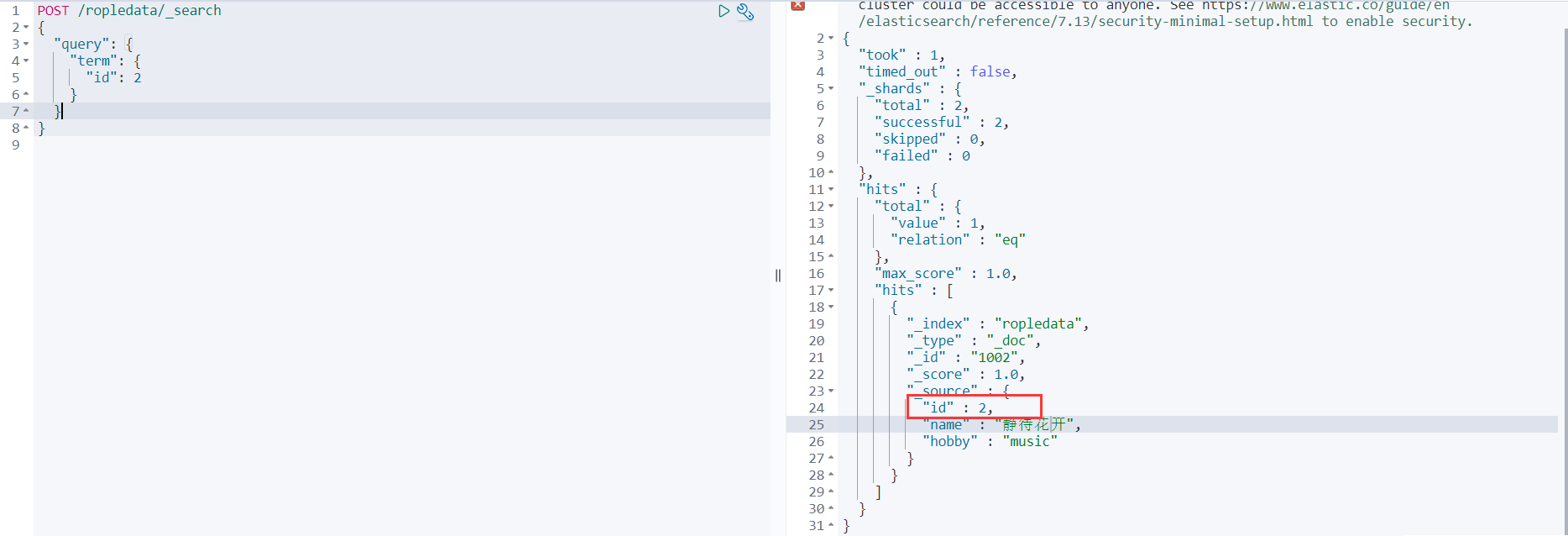
terms查询
terms和term的查询机制是一样,都不会将指定的查询关键字进行分词,直接去分词库中匹配,找到相应文档内容。
terms是在针对一个字段包含多个值的时候使用。
比如查询id字段为1和3的数据:
POST /ropledata/_search
{
"query": {
"terms": {
"id": [1,3]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
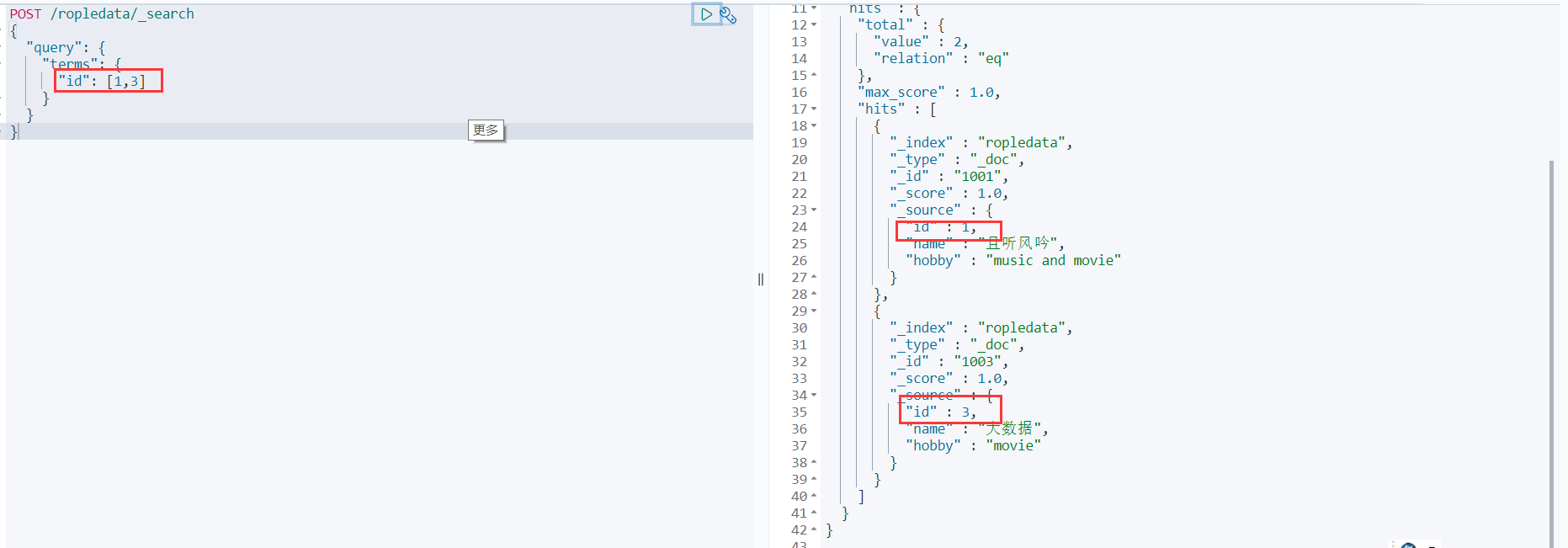
match查询
match_all全局搜索数据
查询全部内容,不指定任何查询条件。
POST /ropledata/_search
{
"query": {
"match_all": {
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
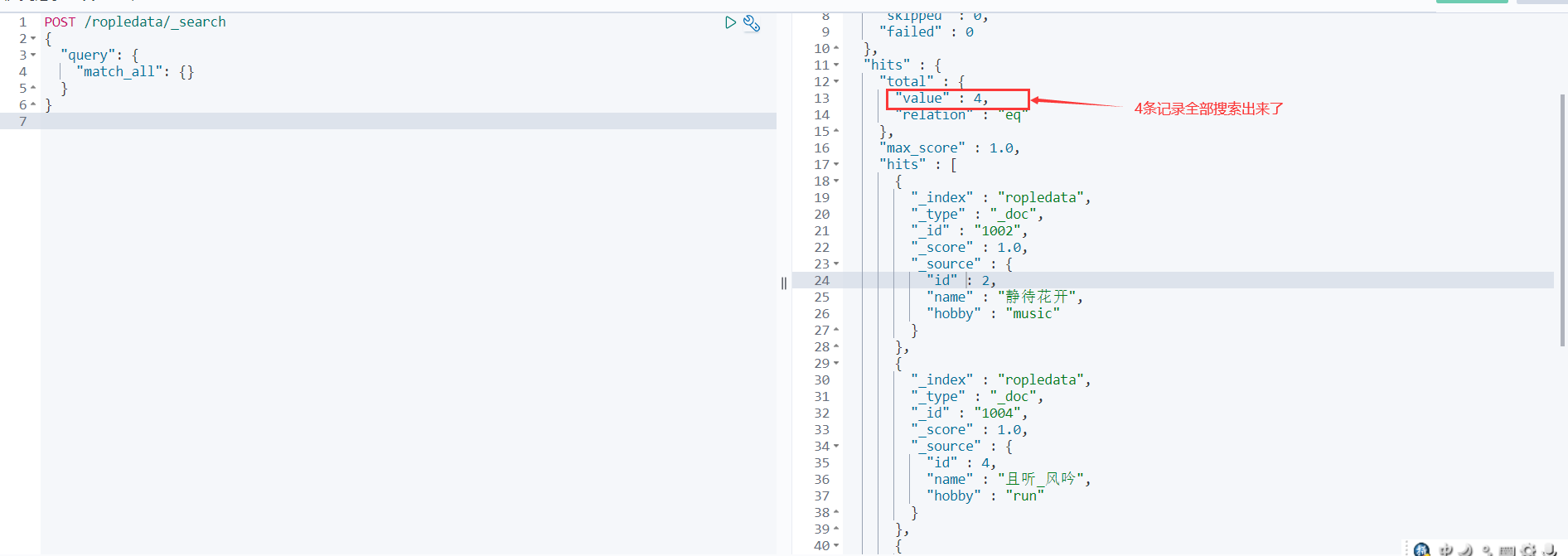
match查询
指定一个Field作为筛选的条件 match会使用分词器解析!(先分析文档,然后通过分析的文档进行查询)
POST /ropledata/_search
{
"query": {
"match": {
"name": "风吟"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
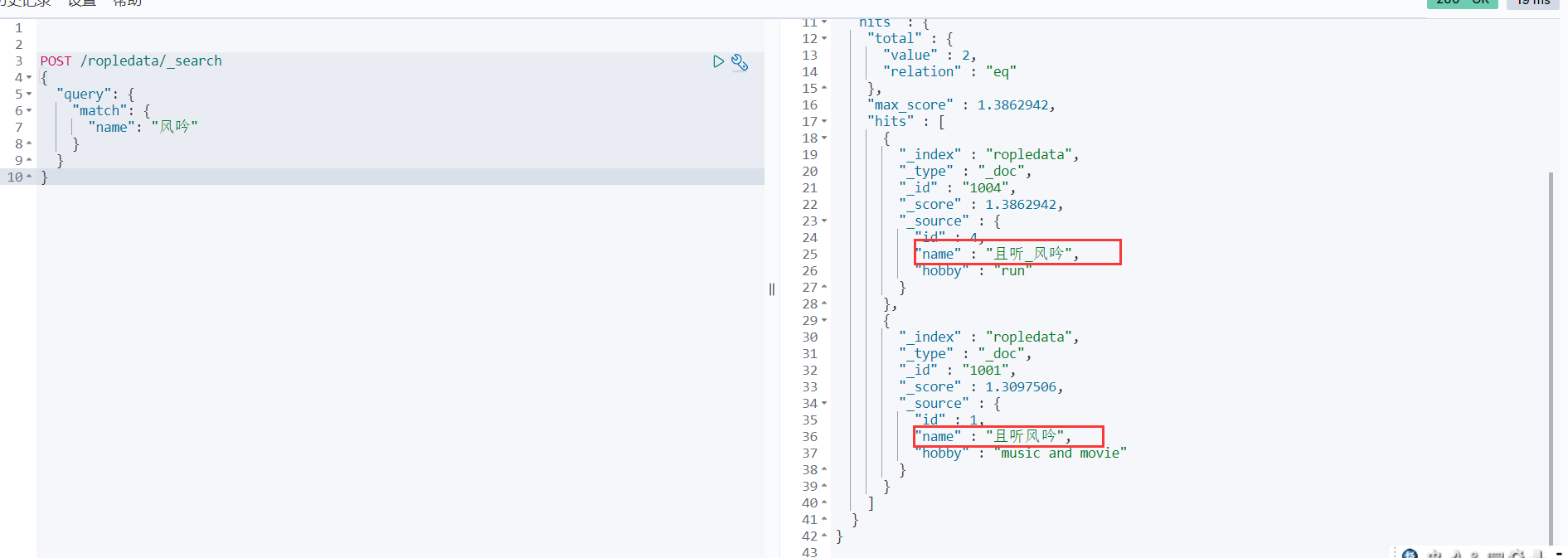
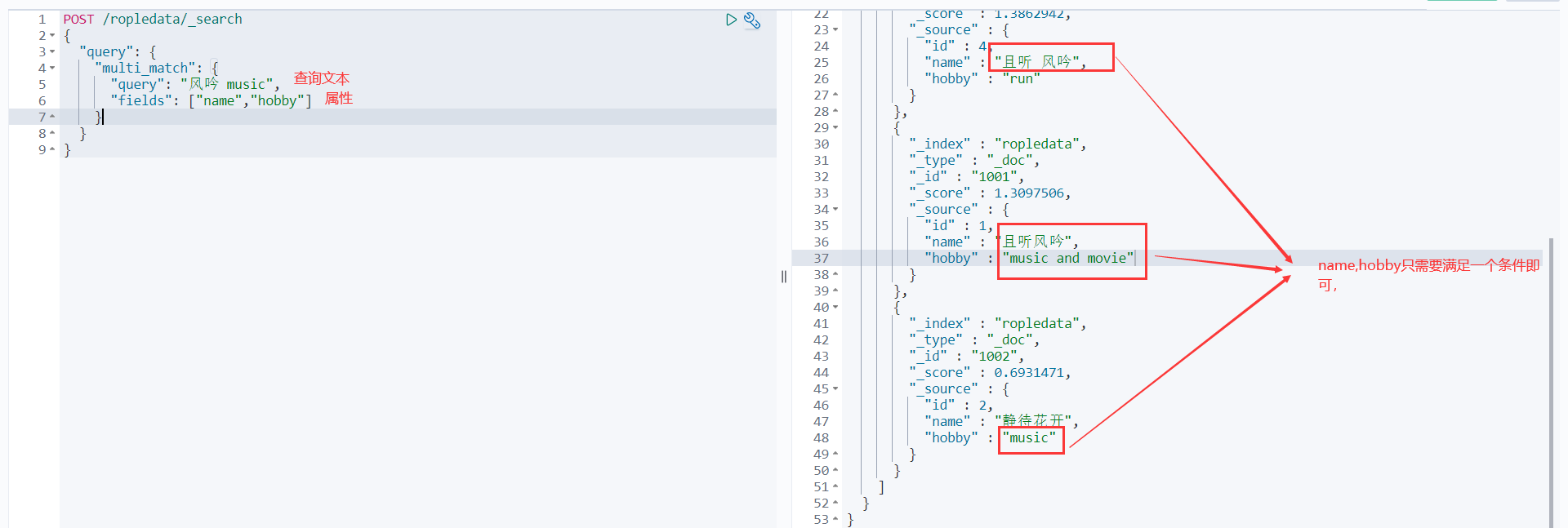
multi_match查询
match针对一个field做检索,multi_match针对多个field进行检索,多个field对应一个text。
POST /ropledata/_search
{
"query": {
"multi_match": {
"query": "风吟 music", #多个条件用空格隔开。这相当于两个条件 风吟和music
"fields": ["name","hobby"]
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
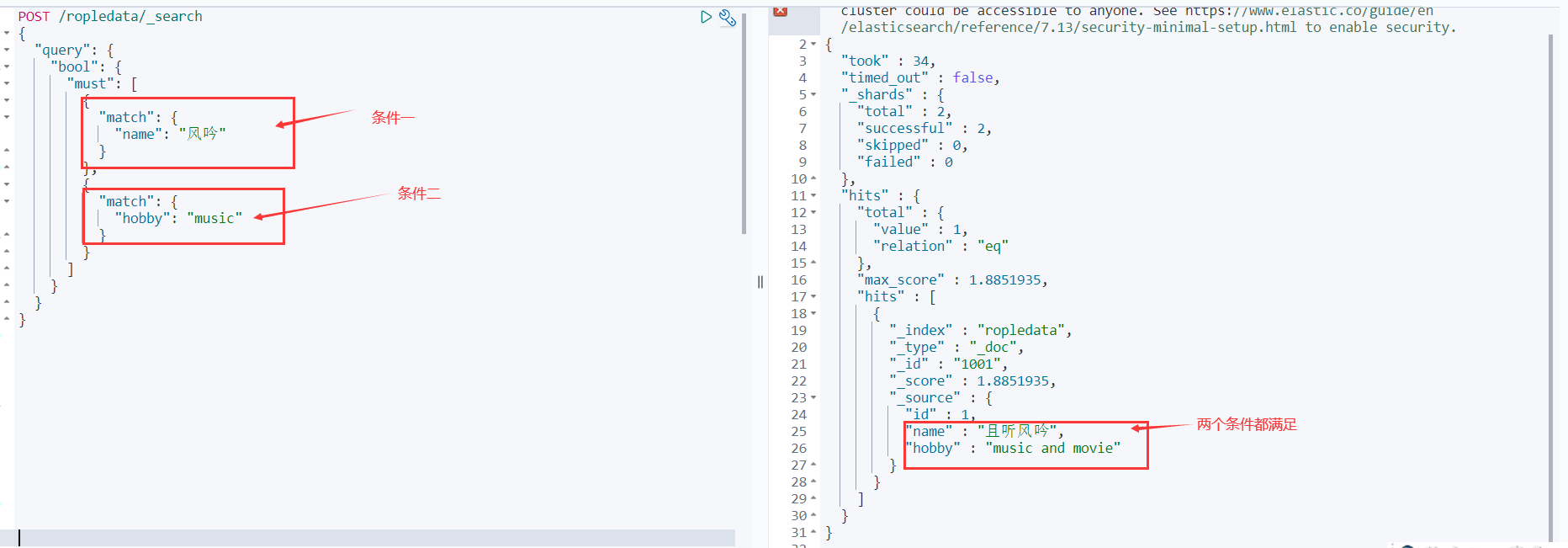
bool查询
复合过滤器,将你的多个查询条件,以一定的逻辑组合在一起。
- must: 所有的条件,用must组合在一起,表示And的意思
- must_not:将must_not中的条件,全部都不能匹配,标识Not的意思
- should:所有的条件,用should组合在一起,表示Or的意思
must(and),所有的条件都要符合
POST /ropledata/_search { "query": { "bool": { "must": [ { "match": { "name": "风吟" } }, { "match": { "hobby": "music" } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
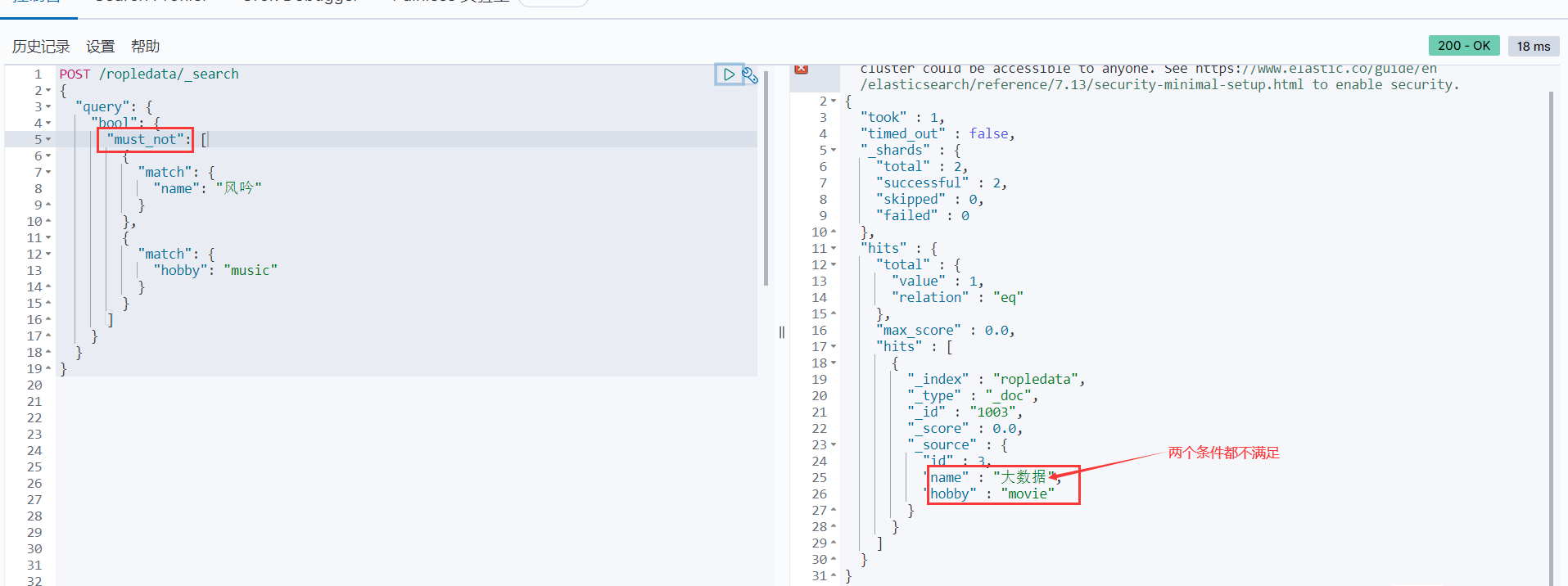
must_not(not)全部都不能匹配
POST /ropledata/_search { "query": { "bool": { "must_not": [ { "match": { "name": "风吟" } }, { "match": { "hobby": "music" } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
should(or)或者的 跟数据库一样
POST /ropledata/_search { "query": { "bool": { "should": [ { "match": { "name": "风吟" } }, { "match": { "hobby": "music" } } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hxt5fICG-1631029662386)(C:\Users\Administrator\Desktop\笔记\ElasticSearch\Pictures\QQ截图20210623203059.png)]
范围查询
- gt大于
- gte大于等于
- lte小于
- lte小于等于
range查询
range查询,只针对数值类型,对某一个Field进行大于或者小于的范围指定
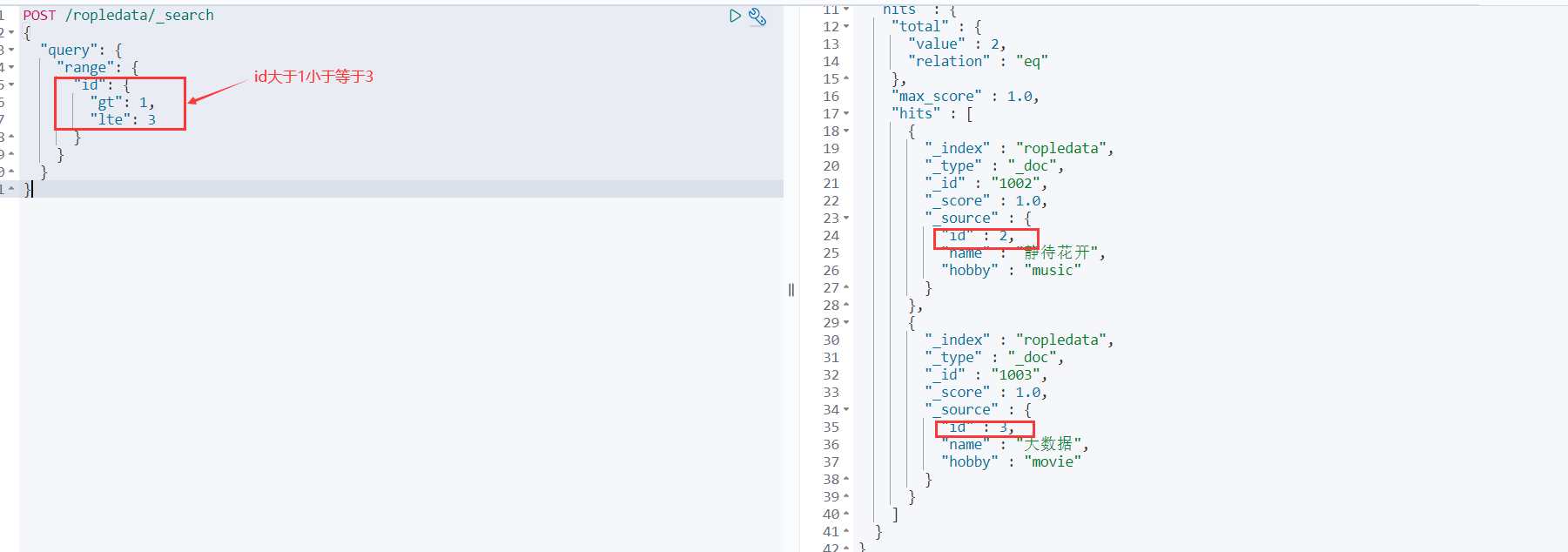
POST /ropledata/_search
{
"query": {
"range": {
"id": {
"gt": 1,
"lte": 3
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
filter查询
filter,根据你的查询条件去查询文档,不去计算分数,而且filter会对经常被过滤的数据进行缓存。通常和bool连用,
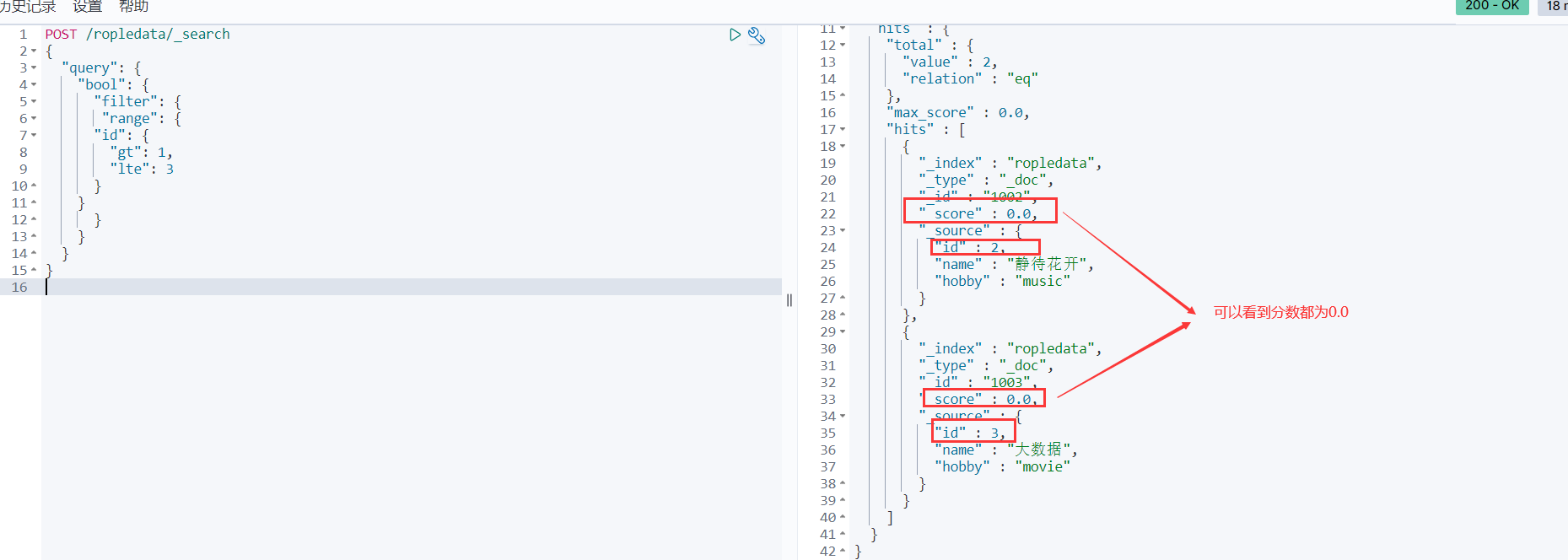
POST /ropledata/_search
{
"query": {
"bool": {
"filter": {
"term": {
"hobby": "music"
}
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
聚合查询
首先咱们需要了解几个非常常用的数学统计函数:
- avg:平均值
- max:最大值
- min:最小值
- sum:求和
- cardinality:去重
- value_count:计数统计
- terms:词聚合可以基于给定的字段,并按照这个字段对应的每一个数据为一个桶,然后计算每个桶里的文档个数。默认会按照文档的个数排序。
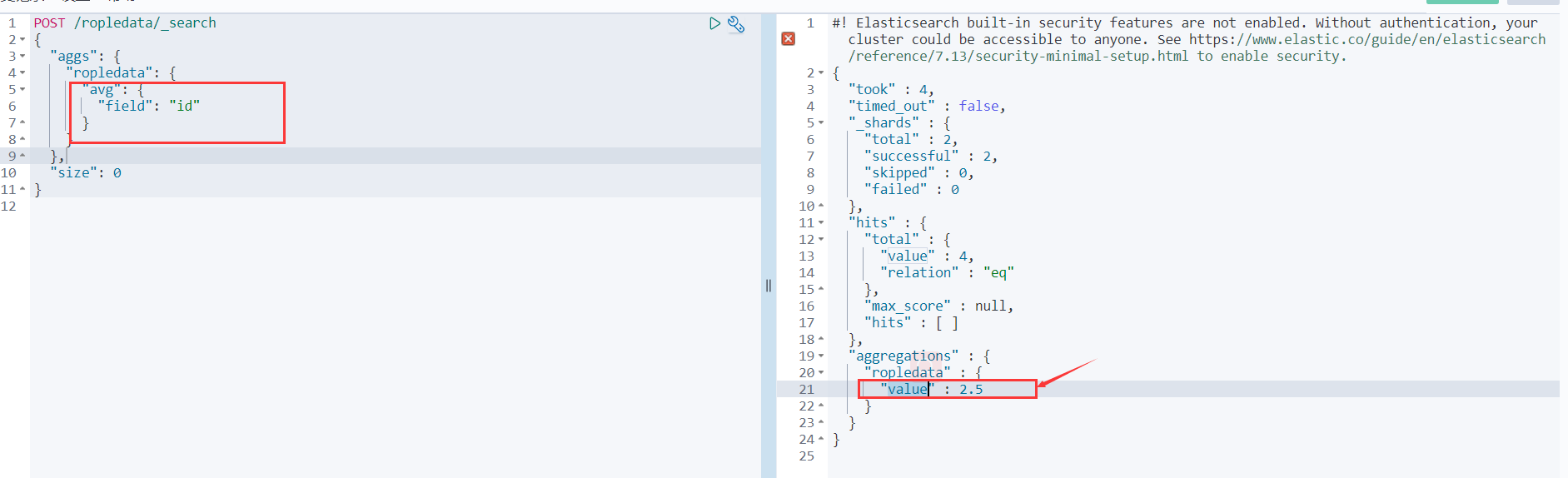
比如咱们求id的平均值
POST /ropledata/_search
{
"aggs": {
"ropledata": {
"avg": {
"field": "id"
}
}
},
"size": 0
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
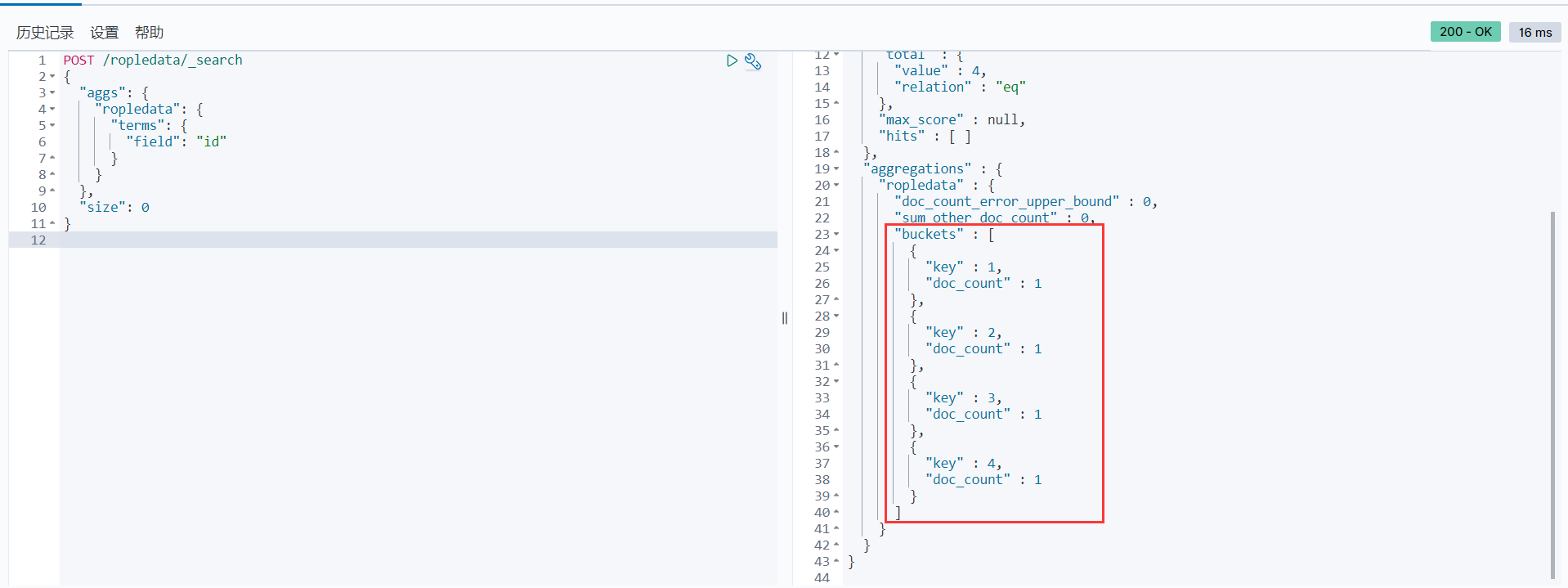
terms词聚合可以基于给定的字段,并按照这个字段对应的每一个数据为一个桶,然后计算每个桶里的文档个数。默认会按照文档的个数排序。
POST /ropledata/_search
{
"aggs": {
"ropledata": {
"terms": {
"field": "id"
}
}
},
"size": 0
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其他的函数用法相似,这里就不介绍了。大家可以自己试试
注意:size用来控制返回多少数据,由于咱们是想要在所有文档里求平均值和求和,所以要用size来控制返回一个数据即可,不然ES还会默认返回10条数据。
批量操作
作为一个存储系统,对数据的批量增删改查自然也是必不可少的!ES也提供了批量的操作,具体的用法如下。
批量插入
POST _bulk
{ "create" : { "_index" : "ropledata", "_id" : "1009" } }
{"id":9,"name": "且听风吟,静待花开","hobby": "music and movie"}
{ "create" : { "_index" : "ropledata", "_id" : "1010" } }
{"id":10,"name": "且听_风吟","hobby": "music"}
{ "create" : { "_index" : "ropledata", "_id" : "1011" } }
{"id":11,"name": "大数据领域","hobby": "movie"}
{ "create" : { "_index" : "ropledata", "_id" : "1012" } }
{"id":12,"name": "一起学习","hobby": "run"}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
批量查询
比如咱们想批量查询ropledata这个索引下文档id为1010,1011,1012的文档数据,可以这样写:
POST /ropledata/_mget
{
"ids": [
"1010",
"1011",
"1012"
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
批量更新
如果咱们想批量修改1011和1012的文档里的name字段的值,可以这样写:
POST _bulk
{ "update" : {"_id" : "1009", "_index" : "ropledata"} }
{ "doc" : {"name" : "批量修改"} }
{ "update" : {"_id" : "1010", "_index" : "ropledata"} }
{ "doc" : {"name" : "大家好"}}
- 1
- 2
- 3
- 4
- 5
批量删除
如果咱们想批量删除文档id为1011和1012的文档,可以这样写:
POST _bulk
{ "delete" : { "_index" : "ropledata", "_id" : "1011" } }
{ "delete" : { "_index" : "ropledata", "_id" : "1012" } }
- 1
- 2
- 3
注意:bulk api对json的语法,有严格的要求,每个json串不能换行,只能放一行,同时一个json串和一个json串之间,必须有一个换行
如下是错误示范:
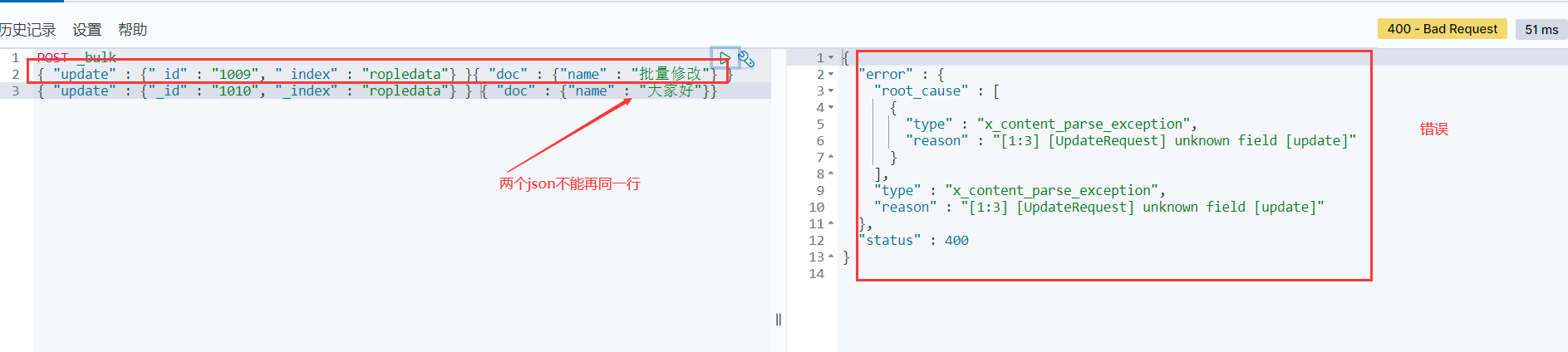
正确示范:
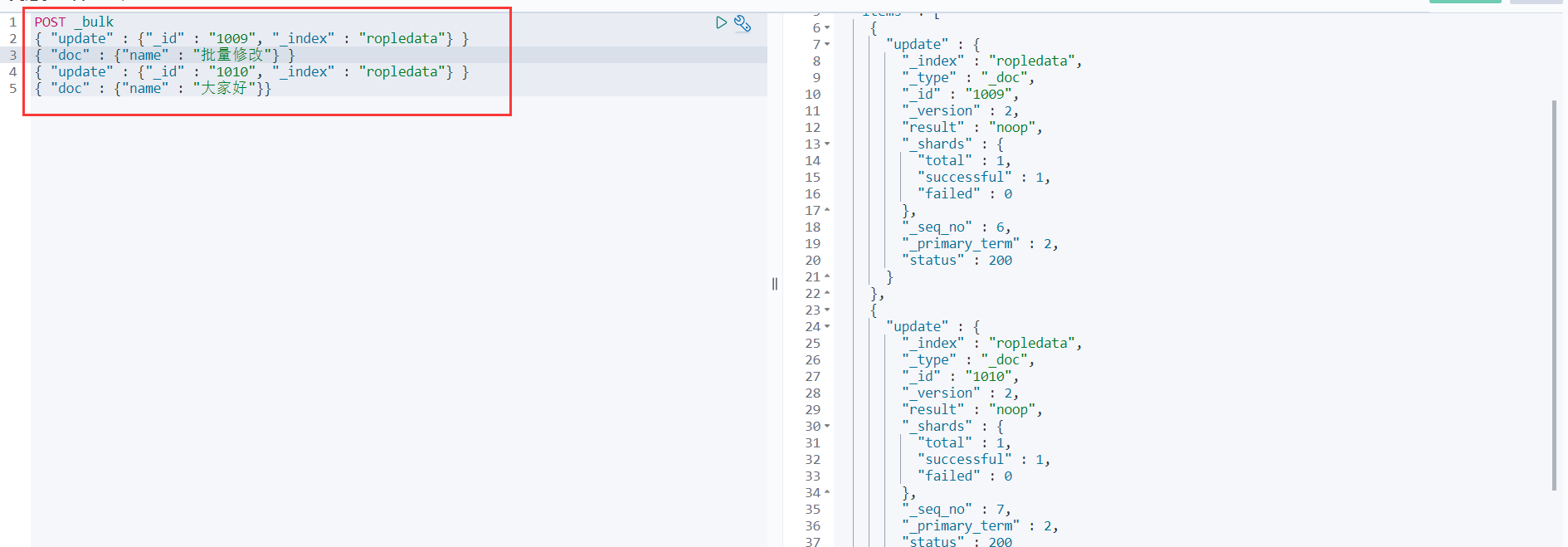
实用骚操作
高亮查询
高亮查询就是你用户输入的关键字,以一定的特殊样式展示给用户,让用户知道为什么这个结果被检索出来。
高亮展示的数据,本身就是文档中的一个Field,单独将Field以highlight的形式返回给你。
ES提供了一个highlight属性,和query同级别的。
- fragment_size:指定高亮数据展示多少个字符回来。
- pre_tags:指定前缀标签,举个栗子< font color=“red” >
- post_tags:指定后缀标签,举个栗子< /font >
- fields:指定哪几个Field以高亮形式返回
POST /ropledata/_search { "query": { "match": { "name": "大数据" } }, "highlight": { "fields": { "name": {} }, "pre_tags": "<font color='red'>", "post_tags": "</font>", "fragment_size": 10 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
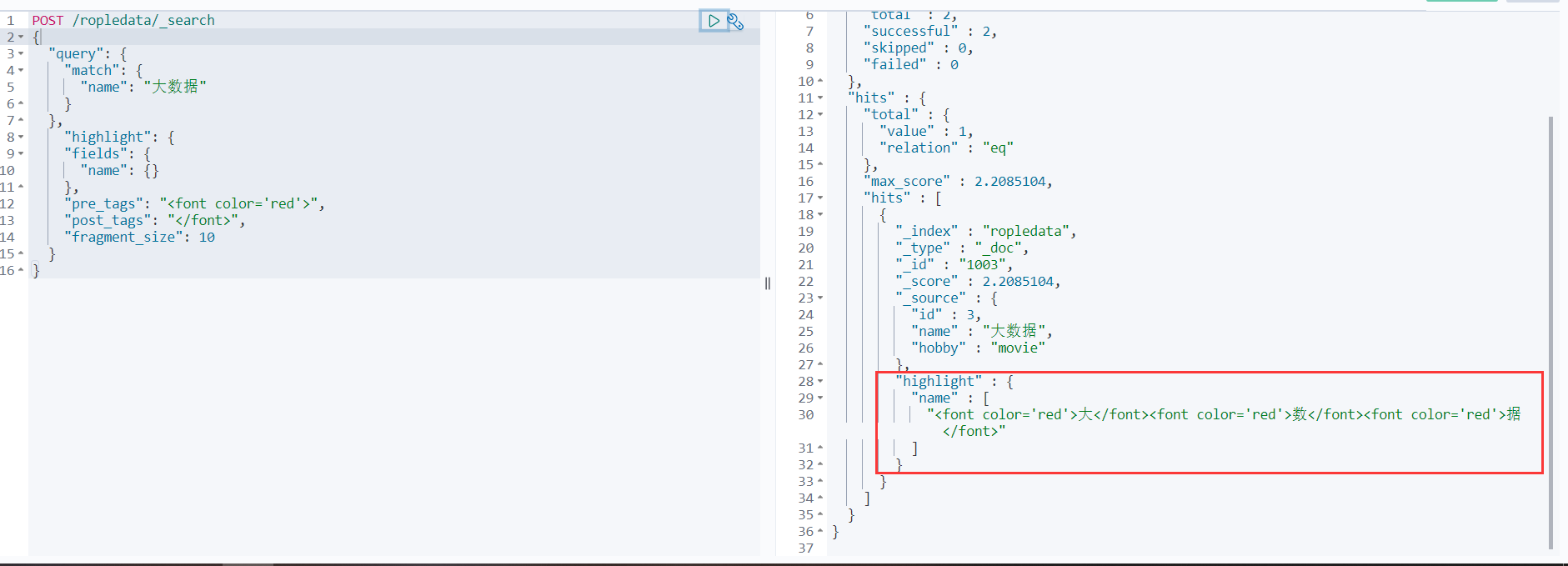
指定返回的字段
咱们有时候不需要返回整个文档所有的字段,只想要查看其中的一个或者多个字段,这时候ES也提供的有方法,只需要在最后使用**_source**参数,并传递想要返回的字段就可以了。默认是包含,想要不包含使用excludes
包含
POST /ropledata/_search
{
"query": {
"match": {
"name": "大数据"
}
},
"_source":["id","name"]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
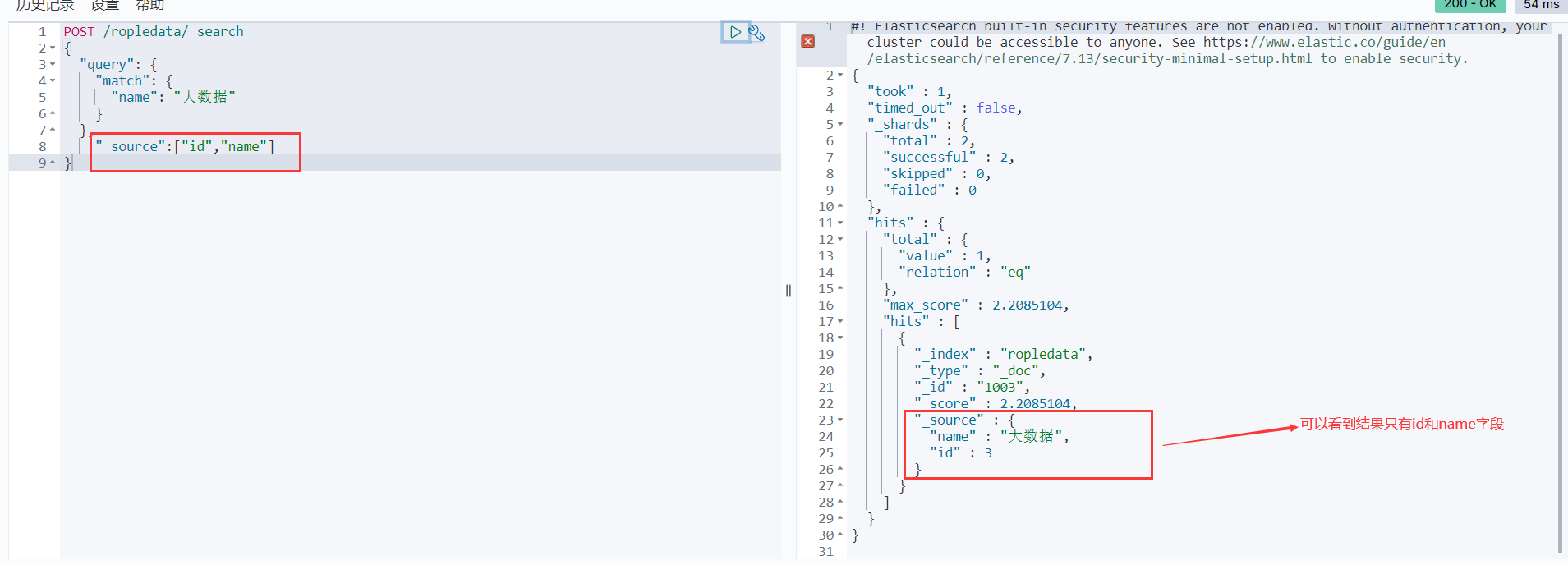
不包含
POST /ropledata/_search
{
"query": {
"match": {
"name": "大数据"
}
},
"_source":{"excludes":["id","name"]}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
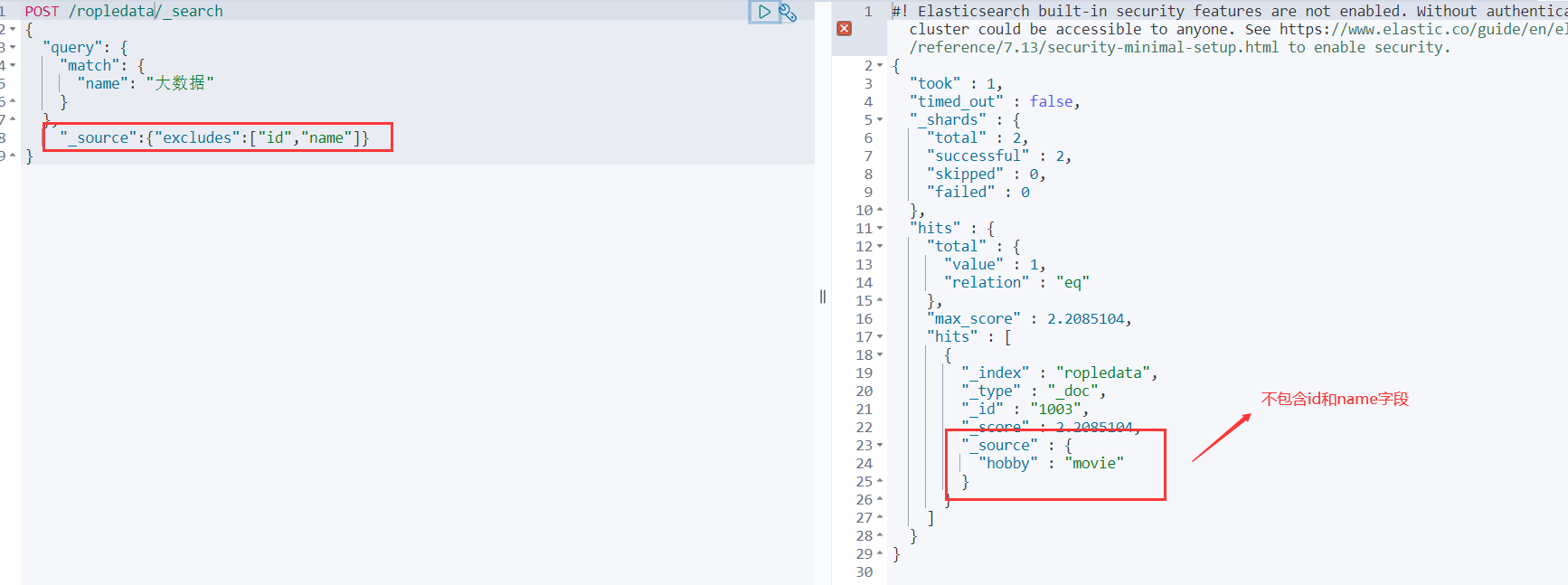
不显示元数据
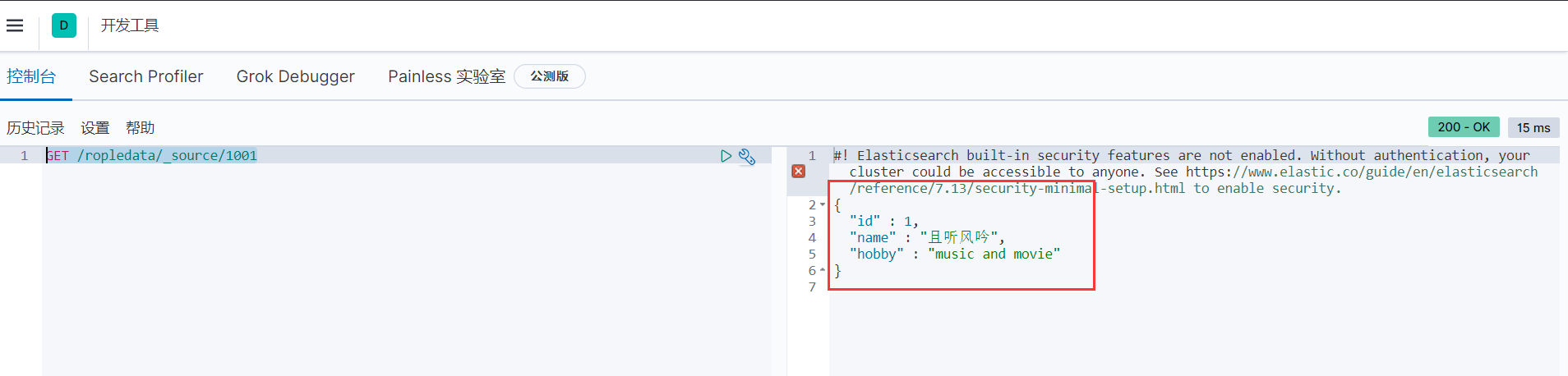
咱们查询的时候,会返回一大堆数据,上面那些称为元数据,那不需要的时候,怎么去掉呢?别急,只需要把_doc换成_source就可以了。
GET /ropledata/_source/1001
- 1
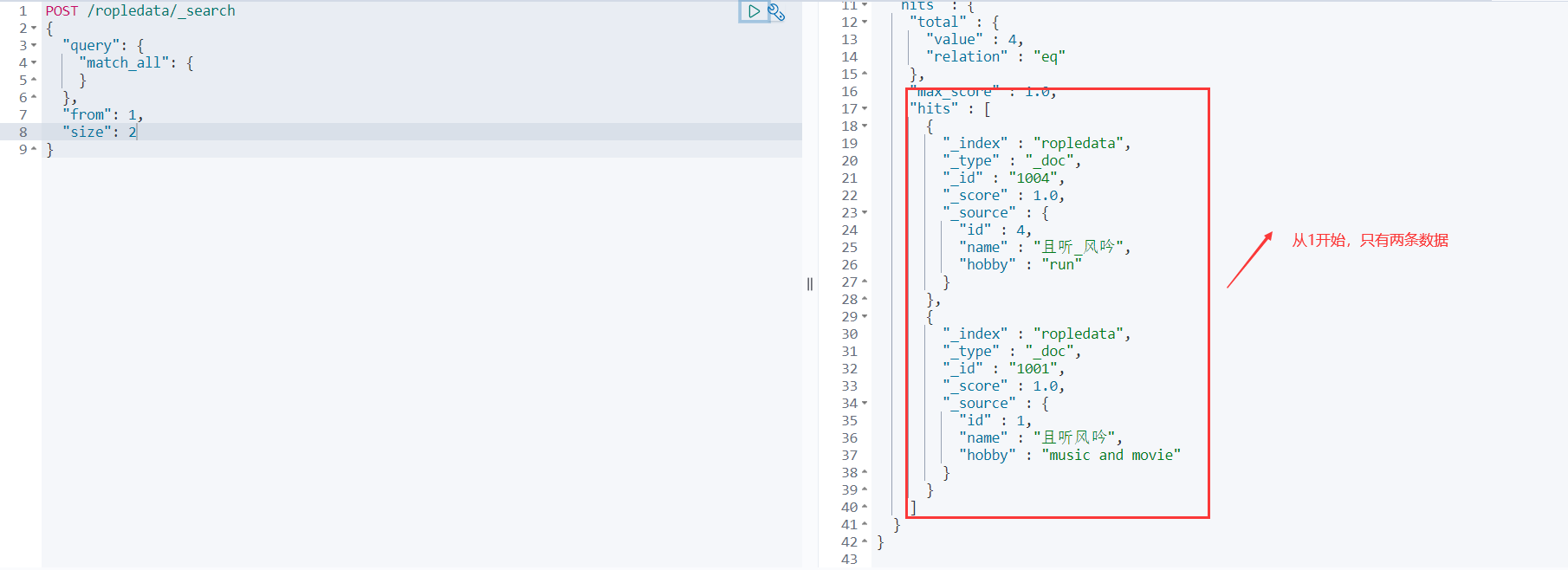
分页查询
对于海量存储的数据,有时候咱们需要分页查看。ES提供了size和from两个参数,size代表每页的个数,默认是10个,from代表从第几个获取。
POST /ropledata/_search
{
"query": {
"match_all": {
}
},
"from": 1,
"size": 2
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
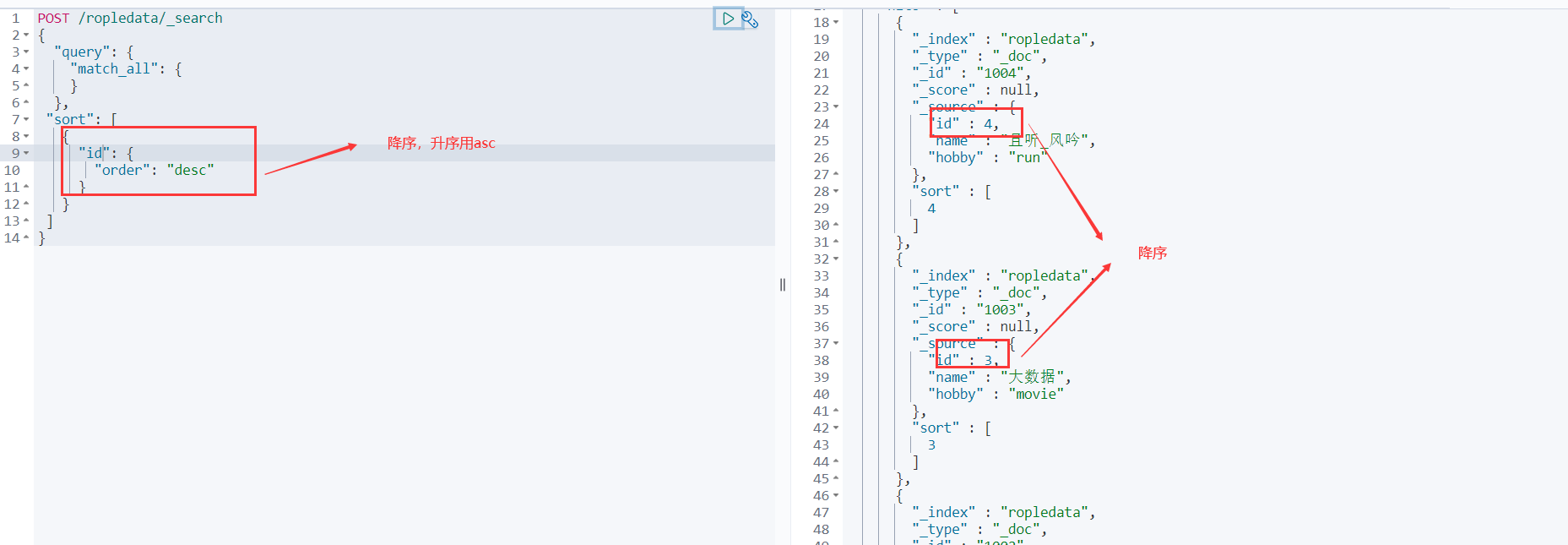
排序
POST /ropledata/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"id": {
"order": "desc"
}
}
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
springboot集成
创建一个springboot的项目 同时勾选上springboot-web的包以及Nosql的elasticsearch的包
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.76</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
注意下spring-boot的parent包内的依赖的es的版本是不是你对应的版本
不是的话就在pom文件下写个properties的版本
<!--这边配置下自己对应的版本-->
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.13.2</elasticsearch.version>
</properties>
- 1
- 2
- 3
- 4
- 5
注入RestHighLevelClient 客户端
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
测试索引,文档增删改,即批量操作
package com.example.springbootes; import com.alibaba.fastjson.JSON; import org.elasticsearch.action.admin.indices.create.CreateIndexRequest; import org.elasticsearch.action.admin.indices.create.CreateIndexResponse; import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest; import org.elasticsearch.action.bulk.BulkRequest; import org.elasticsearch.action.bulk.BulkResponse; import org.elasticsearch.action.delete.DeleteRequest; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.get.GetRequest; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.search.SearchRequest; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.action.support.master.AcknowledgedResponse; import org.elasticsearch.action.update.UpdateRequest; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.indices.GetIndexRequest; import org.elasticsearch.common.unit.TimeValue; import org.elasticsearch.common.xcontent.XContentType; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.index.query.TermQueryBuilder; import org.elasticsearch.search.SearchHit; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.junit.jupiter.api.Test; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.annotation.Qualifier; import org.springframework.boot.test.context.SpringBootTest; import java.io.IOException; import java.util.ArrayList; import java.util.concurrent.TimeUnit; @SpringBootTest class SpringbootEsApplicationTests { @Autowired @Qualifier("restHighLevelClient") private RestHighLevelClient client; //测试索引的创建 @Test void testCreateIndex() throws IOException { //1.创建索引的请求 CreateIndexRequest request = new CreateIndexRequest("lisen_index"); //2客户端执行请求,请求后获得响应 CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT); System.out.println(response); } //测试索引是否存在 @Test void testExistIndex() throws IOException { //1.创建索引的请求 GetIndexRequest request = new GetIndexRequest("lisen_index"); //2客户端执行请求,请求后获得响应 boolean exist = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println("测试索引是否存在-----"+exist); } //删除索引 @Test void testDeleteIndex() throws IOException { DeleteIndexRequest request = new DeleteIndexRequest("lisen_index"); AcknowledgedResponse delete = client.indices().delete(request,RequestOptions.DEFAULT); System.out.println("删除索引--------"+delete.isAcknowledged()); } //测试添加文档 @Test void testAddDocument() throws IOException { User user = new User("lisen",27); IndexRequest request = new IndexRequest("lisen_index"); request.id("1"); //设置超时时间 request.timeout("1s"); //将数据放到json字符串 request.source(JSON.toJSONString(user), XContentType.JSON); //发送请求 IndexResponse response = client.index(request,RequestOptions.DEFAULT); System.out.println("添加文档-------"+response.toString()); System.out.println("添加文档-------"+response.status()); // 结果 // 添加文档-------IndexResponse[index=lisen_index,type=_doc,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}] // 添加文档-------CREATED } //测试文档是否存在 @Test void testExistDocument() throws IOException { //测试文档的 没有index GetRequest request= new GetRequest("lisen_index","1"); //没有indices()了 boolean exist = client.exists(request, RequestOptions.DEFAULT); System.out.println("测试文档是否存在-----"+exist); } //测试获取文档 @Test void testGetDocument() throws IOException { GetRequest request= new GetRequest("lisen_index","1"); GetResponse response = client.get(request, RequestOptions.DEFAULT); System.out.println("测试获取文档-----"+response.getSourceAsString()); System.out.println("测试获取文档-----"+response); // 结果 // 测试获取文档-----{"age":27,"name":"lisen"} // 测试获取文档-----{"_index":"lisen_index","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"age":27,"name":"lisen"}} } //测试修改文档 @Test void testUpdateDocument() throws IOException { User user = new User("李逍遥", 55); //修改是id为1的 UpdateRequest request= new UpdateRequest("lisen_index","1"); request.timeout("1s"); request.doc(JSON.toJSONString(user),XContentType.JSON); UpdateResponse response = client.update(request, RequestOptions.DEFAULT); System.out.println("测试修改文档-----"+response); System.out.println("测试修改文档-----"+response.status()); // 结果 // 测试修改文档-----UpdateResponse[index=lisen_index,type=_doc,id=1,version=2,seqNo=1,primaryTerm=1,result=updated,shards=ShardInfo{total=2, successful=1, failures=[]}] // 测试修改文档-----OK // 被删除的 // 测试获取文档-----null // 测试获取文档-----{"_index":"lisen_index","_type":"_doc","_id":"1","found":false} } //测试删除文档 @Test void testDeleteDocument() throws IOException { DeleteRequest request= new DeleteRequest("lisen_index","1"); request.timeout("1s"); DeleteResponse response = client.delete(request, RequestOptions.DEFAULT); System.out.println("测试删除文档------"+response.status()); } //测试批量添加文档 @Test void testBulkAddDocument() throws IOException { ArrayList<User> userlist=new ArrayList<User>(); userlist.add(new User("cyx1",5)); userlist.add(new User("cyx2",6)); userlist.add(new User("cyx3",40)); userlist.add(new User("cyx4",25)); userlist.add(new User("cyx5",15)); userlist.add(new User("cyx6",35)); //批量操作的Request BulkRequest request = new BulkRequest(); request.timeout("1s"); //批量处理请求 for (int i = 0; i < userlist.size(); i++) { request.add( new IndexRequest("lisen_index") .id(""+(i+1)) .source(JSON.toJSONString(userlist.get(i)),XContentType.JSON) ); } BulkResponse response = client.bulk(request, RequestOptions.DEFAULT); //response.hasFailures()是否是失败的 System.out.println("测试批量添加文档-----"+response.hasFailures()); // 结果:false为成功 true为失败 // 测试批量添加文档-----false } //测试查询文档 @Test void testSearchDocument() throws IOException { SearchRequest request = new SearchRequest("lisen_index"); //构建搜索条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //设置了高亮 sourceBuilder.highlighter(); //term name为cyx1的 TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "cyx1"); sourceBuilder.query(termQueryBuilder); sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); request.source(sourceBuilder); SearchResponse response = client.search(request, RequestOptions.DEFAULT); System.out.println("测试查询文档-----"+JSON.toJSONString(response.getHits())); System.out.println("====================="); for (SearchHit documentFields : response.getHits().getHits()) { System.out.println("测试查询文档--遍历参数--"+documentFields.getSourceAsMap()); } // 测试查询文档-----{"fragment":true,"hits":[{"fields":{},"fragment":false,"highlightFields":{},"id":"1","matchedQueries":[],"primaryTerm":0,"rawSortValues":[],"score":1.8413742,"seqNo":-2,"sortValues":[],"sourceAsMap":{"name":"cyx1","age":5},"sourceAsString":"{\"age\":5,\"name\":\"cyx1\"}","sourceRef":{"fragment":true},"type":"_doc","version":-1}],"maxScore":1.8413742,"totalHits":{"relation":"EQUAL_TO","value":1}} // ===================== // 测试查询文档--遍历参数--{name=cyx1, age=5} } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206

