
- 1一篇文章彻底理解SharedPreferences_shared_prefs
- 2图论最短路径以及floyd算法的MATLAB实现
- 3基于Prometheus监控Kubernetes集群_prometheus 监控集群
- 4如何快速构建自己的AI客服 将GPT接入淘宝,抖店,拼多多,美团等电商平台 实现当前最强的客服机器人_轻简客服
- 5深度解析MFCC特征提取
- 6中洺科技:有多少智能,背后就有多少数据标注员_中洛科技有限公司数据标注
- 7华为畅享20se是鸿蒙系统吗,1299元的华为畅享20SE,你觉得值得入手吗?
- 8金融×元宇宙:虚实交融共进下的金融体系_但存在脱实
- 9adb进入recovery 以及fastboot模式_adb reboot recovery
- 10PostGIS 测试 - 基本类型(WKT & WKB)
Elasticsearch 全文搜索
赞
踩
一、Elasticsearch 概念
Elasticsearch数据存储方式(基本概念)
.1、Elasticsearch存储方式
(1)面向文档
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
(2)JSON
ELasticsearch使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。它简洁、简单且容易阅读。
以下使用JSON文档来表示一个用户对象:
{
"email": "john@smith.com",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [ "dolphins", "whales" ]
},
"join_date": "2014/05/01"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
尽管原始的user对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在Elasticsearch中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。
2、Elasticsearch存储结构

Mysql数据与ES数据转化
(1)元数据
创建文档语句
PUT atguigu/doc
{
“name”:”zhangsan”,
“age”:10
}
- 1
- 2
- 3
- 4
- 5
_index:文档所在索引名称
_type:文档所在类型名称
_id:文档唯一id
_uid:组合id,由_type和_id组成(6.x后,_type不再起作用,同_id)
_source:文档的原始Json数据,包括每个字段的内容
_all:将所有字段内容整合起来,默认禁用(用于对所有字段内容检索)(2)名词解释 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
类型 type Es6之后,一个index中只能有一个type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
字段Field 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript
Object
Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
cluster 整个elasticsearch 默认就是集群状态,整个集群是一份完整、互备的数据。
node 集群中的一个节点,一般只一个进程就是一个node
shard 分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。
index 相当于rdbms的database, 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。
type 类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。
document 类似于rdbms的 row、面向对象里的object
field 相当于字段、属性
cluster 整个elasticsearch 默认就是集群状态,整个集群是一份完整、互备的数据。**(多个node组成一个cluster集群)**
node 集群中 的一个节点,一般只一个进程就是一个node **(一个运行中的elasticsearch进程)**
shard 分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。
index 相当于rdbms的database, 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。
type 类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。
document 类似于rdbms的 row、面向对象里的object
field 相当于字段、属性 d
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
二、ElasticSearch的增删改查
- 增加一个索引(库)
PUT one_index
- 1
| PUT | 新增 |
|---|---|
| one_index | 索引名(库名) |
- 增加一个文本(表和数据)
PUT /moive_index/moive/1
{
"name":"Mr.xu"
}
- 1
- 2
- 3
- 4
- 5
| PUT | 代表添加 |
|---|---|
| moive_index | 索引名(库名) |
| moive | 表示表名 |
| 1 | 表示主键 |
| {} | 大括号中的为json数据 |
| “name”:“Mr.xu” | 文本:K :V |
- 删除数据
DELETE /索引名/表名/主键
- 1
- 更新数据
更新既覆盖
- 1
- 获取数据
GET /索引名/表名/主键 //查询一条数据
GET /索引名/表名/_search //查询所有
- 1
- 2
- 3
三 、关键字拆分
GET _analyze
{
"text": "how are you"
}
- 1
- 2
- 3
- 4
{ "tokens": [ { "token": "how", "start_offset": 0, //拆分的起始位置 "end_offset": 3, //拆分的起始位置 "type": "<ALPHANUM>", "position": 0 //拆分后的位置 }, { "token": "are", "start_offset": 4, "end_offset": 7, "type": "<ALPHANUM>", "position": 1 }, { "token": "you", "start_offset": 8, "end_offset": 11, "type": "<ALPHANUM>", "position": 2 } ] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
四、分词器
1、分词机制
洗→拆→分
Character Filter 对原始文本进行处理 例:去除html标签、特殊字符等
Tokenizer 将原始文本进行分词 例:培训机构–>培训,机构
Token Filters 分词后的关键字进行加工 例:转小写、删除语气词、近义词和同义词等
在elasticsearch中默认的分词器拆分不了中文,所以需要安装ik分词器的插件
ik插件须安装在elasticsearch目录下的plugins下,不能再拆分子目录,再拆就报错了。
- 1
分词器名称 介绍 特点 地址
IK 实现中英文单词切分 自定义词库 https://github.com/medcl/elasticsearch-analysis-ik
- 1
- 2
Jieba python流行分词系统,支持分词和词性标注 支持繁体、自定义、并行分词 http://github.com/sing1ee/elasticsearch-jieba-plugin
- 1
Hanlp 由一系列模型于算法组成的java工具包 普及自然语言处理在生产环境中的应用 https://github.com/hankcs/HanLP
- 1
THULAC 清华大学中文词法分析工具包 具有中文分词和词性标注功能 https://github.com/microbun/elasticsearch-thulac-plugin
- 1
分词器相关关键字
GET _analyze
{
"text": "我是中国人"
, "analyzer": "ik_max_word" //最大分词器,一般用在标题或关键字,如商品标题上
}
----------------------------------------------------------------------------------
GET _analyze
{
"text": "我是中国人"
, "analyzer": "ik_smart" //简易分词器,一般用在文本较多,如博客,文章,或商品描述上
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
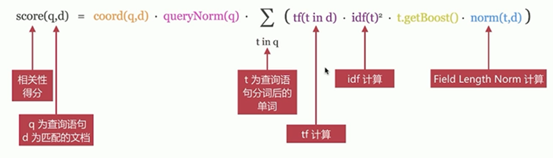
相关性算分

相关性算分:指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表
如何将最符合用户查询需求的文档放到前列呢?
本质问题是一个排序的问题,排序的依据是相关性算分,确定倒排索引哪个文档排在前面
影响相关度算分的参数:
1、TF(Term Frequency):词频,即单词在文档中出现的次数,词频越高,相关度越高
2、Document Frequency(DF):文档词频,即单词出现的文档数
3、IDF(Inverse Document Frequency):逆向文档词频,与文档词频相反,即1/DF。即单词出现的文档数越少,相关度越高(如果一个单词在文档集出现越少,算为越重要单词)
4、Field-length Norm:文档越短,相关度越高
- 1
- 2
- 3
- 4
- 5
- 6
TF/IDE模型
BM25模型(5.X之后的默认模型)对之前算分进行优化
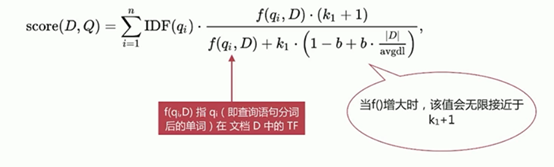

BM25相比TF/IDF的一大优化是降低了tf在过大时的权重,避免词频对查询影响过大


