
- 1MYSQL事务与MVCC_mysql中的事务和mvcc
- 2【自然语言处理(NLP)】基于PaddleNLP的短文本相似度计算_paddle短文本相似度计算
- 3python-django 招聘数据可视化系统_django招聘网站数据可视化
- 4【Python实战】随机图像数据集自动生成(原创)_python randimage
- 5Sora技术分解(dw00)
- 6二手车价格预测 | 构建AI模型并部署Web应用 ⛵_scikitlearn二手车价格预测模型
- 7改进YOLOv7 | 在 ELAN 模块中添加【Triplet】【SpatialGroupEnhance】【NAM】【S2】注意力机制 | 附详细结构图_triplet改进yolo
- 8年度书单盘点 | 史上最卷考研潮过后,这十本书让你不再迷茫
- 9【情商智慧:630】你混得好不好,这些能力很重要_高情商:630年 dddd
- 10美团NLP以及知识图谱文章提炼_iterative strategy for named entity recognition wi
ElasticSearch——全文搜索引擎_es搜索引擎
赞
踩
一、为什么需要全文搜索引擎?
首先先来了解一个概念,在我们生活中一般来说有两种数据:结构化数据、非结构化数据
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据: 非结构化数据又可称为全文数据,指不定长或无固定格式的数据,如邮件,word文档等。
对于结构化数据我们可以直接从数据库查询,而对于非结构化的数据此时就要用到全文检索的方式查询,比如对一个文档或者网页中的内容文本每个词建立一个索引,把这些非结构化的变成结构化的方式然后来查询。
全文搜索引擎百度百科定义:全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
简单理解:比如像淘宝、京东这种电商网站,商品的数据量很大很大,这些数据若存放在数据库中然后我们搜索是直接去数据库查询这样显然很不合理,因为一是查询慢,二是数据量大放数据库中存储需要空间。所以为了解决查询慢的问题,我们需要全文搜索引擎来去查询这些数据。
二、ElasticSearch概述
在介绍ElasticSearch之前,首先需要先了解lunece
Lucene:是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,lucene提供了查询引擎、索引引擎、部分文本分析引擎。
简单来说,lucene就是为我们开发人员提供了一些全文检索引擎工具包,我们调这些包里的方法就可以去实现全文搜索的功能了。(但其实直接去使用lucene来做也是很麻烦的,所以后面才有了类似solr、elasticsearch等这些搜索引擎)
lucene是迄今为止最先进、性能最好、功能最全的搜索引擎库,但是需要明白lucene只是一个库,lucene是java语言编写的,想要使用它就必须使用java作为开发语言来将其集成到我们的应用中,这就导致了有一定的局限性。再一个lucene非常复杂,如果直接来使用lucene那就需要深入了解它的底层工作原理,显然这个学习和使用成本太大了。
了解完lucene后再来看elasticsearch就很好理解了~
ElasticSearch:Elasticsearch是一个实时分布式搜索和分析引擎(注意,elasticsearch是一个真正的搜索引擎了),elasticsearch底层其实用到的就是lucene,它是对lucene的封装,从而对外留下一套简单的RestFul API,让我们更简单去实现我们所需要的全文搜索的功能。
Solr和Elasticsearch类似,都是基于Lucene的全文搜索引擎,solr的功能相较elasticsearch来说更多更广。
solr对已有的数据查询来说比elasticsearch要快,elasticsearch建立索引(也就是实时查询)比solr要快,因为solr建立索引时会产生io阻塞。
在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
三、ElasticSearch安装
ElasticSearch是java语言编写的,此次安装的es版本是7.6.1,安装前需要确定jdk的版本最少是1.8以上,且配置好了jdk的环境变量。
官网下载: https://www.elastic.co/products/elasticsearch
-
elasticsearch解压后就可用了,和tomcat类似,开箱即用
-
进入bin目录,双击elasticsearch.bat启动
-
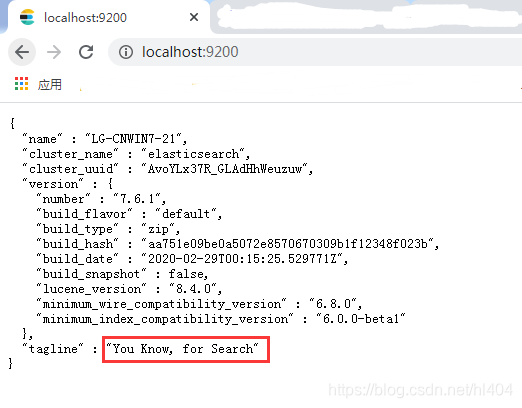
浏览器输入localhost:9200得到以下信息,就表示安装成功!
es安装好了,我们还需要一个可以查看es信息的图形化界面,不然怎么很直观去看es里面的索引啊文档啊这些信息呢?所以下一步要安装ES的图形化界面插件客户端
这个客户端就是一个基于node.js的一个前端项目(所以前提是一定要安装node.js的环境),从github上下载项目代码即可,
下载地址: https://github.com/mobz/elasticsearch-head/
- 下载后解压文件:
- 解压之后安装依赖,在当前解压目录下打开cmd,输入cnpm install(安装一次即可,之后直接启动就行了)
- 启动项目,在当前目录的cmd下输入:npm run start
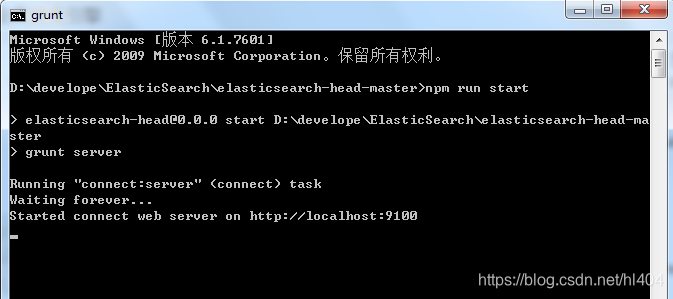
- 浏览器输入http://localhost:9100 ,连接中输入elasticsearch的9200连接,连接成功,启动成功!
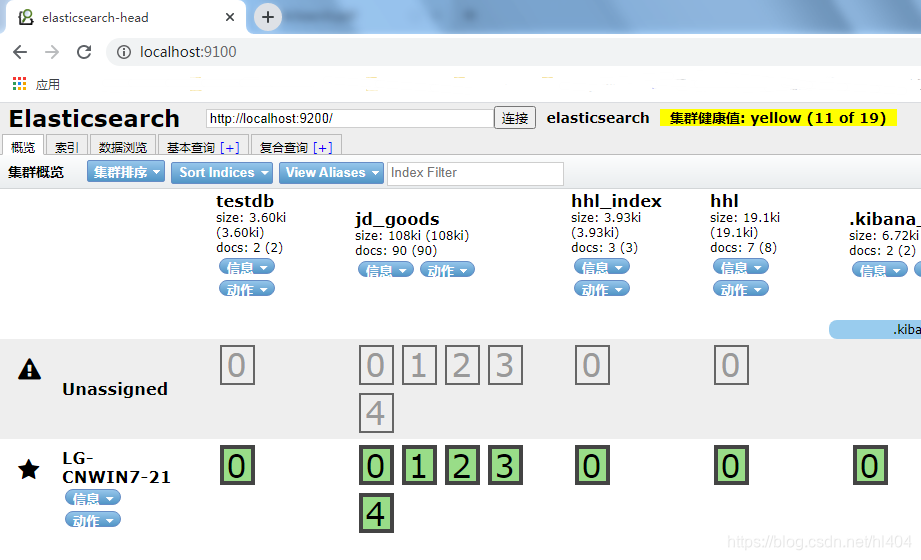
注意:由于es和head客户端两个进程的端口号不同,所以存在跨域的问题,首次通过head客户端连接9200的es肯定连接不上,所以要在es的配置文件中增加如下配置:

#跨域配置
http.cors.enabled: true
http.cors.allow-origin: “*”
ELK 就是Elasticsearch、Logstash、Kibana,也被称为ElasticStack。Elasticsearch上面已经介绍过了,Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。和上面的那个head项目相比,kibana是一个更专业的查看分析数据的平台。
ELK在大数据中用到的比较多,有专业的ELK工程师这个岗位。
由于head项目作为es的图形化管理工具查看起来没有kibana专业,所以我们这里就再安装个kibana来认识一下kibana
安装kibana:
- 官网下载地址:https://www.elastic.co/cn/kibana,注意kibana版本要和es版本对应
- 下载完毕后解压即可,拆箱即用
- kibana默认是英文版本的,可以改成中文的,在kibana.yml配置文件中加入一行配置:i18n.locale: “zh-CN” ,然后启动kibana就变成中文了
- 启动kibana
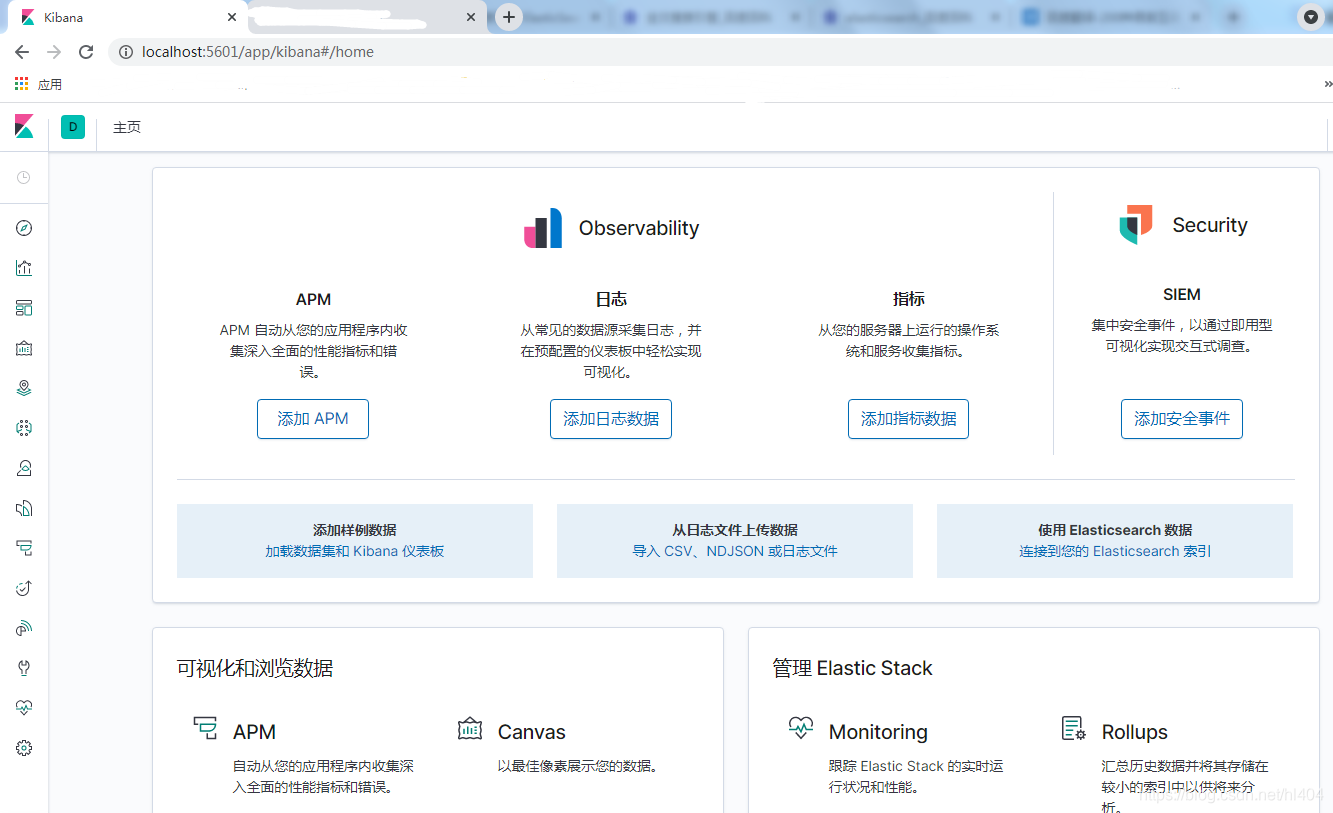
- 浏览器访问localhost:5601,kibana会自动去访问es的9200端口,出现以下界面,表示启动成功!
四、ES核心概念
es是一个全文搜索引擎,那es是如何存储数据的呢?es的数据结构是什么,和传统的mysql、oracle一样吗?es如何实现搜索的功能呢?
首先要理解清楚一个概念,es是面向文档的,它里面不像数据库mysql一样有库、表、字段等概念,es中说的是索引、类型、文档、字段这几个概念,我们可以将传统的db和es做一个概念的对比如下:
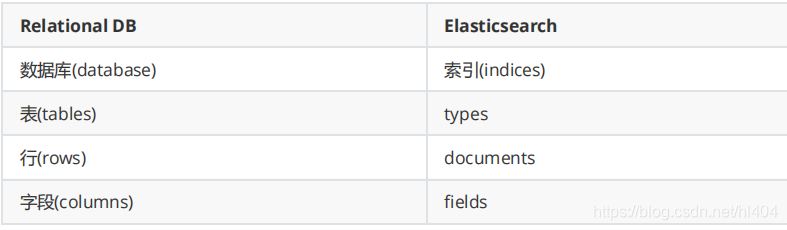
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多 个文档(行),每个文档中又包含多个字段(列)。
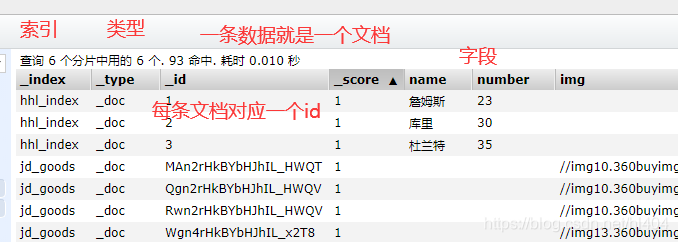
上图就是es图形化界面管理工具head项目下的索引查看页面,可以看到一个索引下可以有多个type类型(这个type默认是_doc)。
一个索引默认有5个分片(又称主分片)构成,每个分片会有一个副本(又称复制分片),在es集群中,主分片和复制分片会在不同的节点下,这样有利于一个节点挂掉后数据也不会丢失。一个分片就是一个lucene索引,一个包含倒排索引的目录。
总结:也就是说一个es索引是由多个lucene索引组成的,如无特指,说起索引指的就是es索引
倒排索引的结构使得es在不扫描全部文档的情况下,就能知道哪些文档包含哪些关键字。
倒排索引的概念:简单理解就是把所有文档中的每个词提取出来,然后创建一个不含重复词条的列表来记录这些词都出现在哪个文档了,在查询的时候我们只需要去看这个不重复的词条列表就可以快速的定位到与当前所查找的关键字相匹配的文档了。

如上图,若我们不用倒排索引,那需要检索所有的文档提取出与所查关键词相匹配的文档;而使用倒排索引我们直接就可以定位到所匹配的文档的id,这样更快!
五、IK分词器
分词:es是一个搜索引擎,那肯定是用来搜索的,es中默认的分词是把中文的每一个字看成一个词,这显然是不合理的,比如搜索一个“今天天气如何” , 那这句话里面的今天应该是一个词,天气又是一个词,不能把这句话每个字都分出来去查询吧,那样查询出来的结果不是我们想要的。所以我们需要安装中文分词器IK来解决这个分词的问题。
- 下载IK分词器: ik分词器下载地址,注意要下载和你es版本对应的ik分词器的版本,不对应的话es会启动不成功!
- 下载后解压,并将文件拷贝至ElasticSearch根目录下的 plugins 目录中。
- 重新启动es
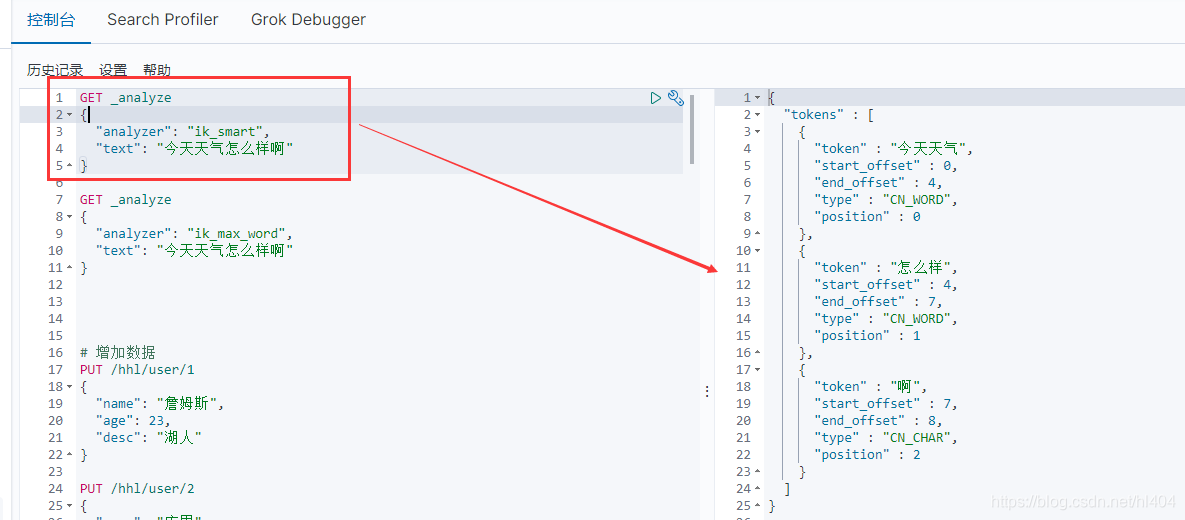
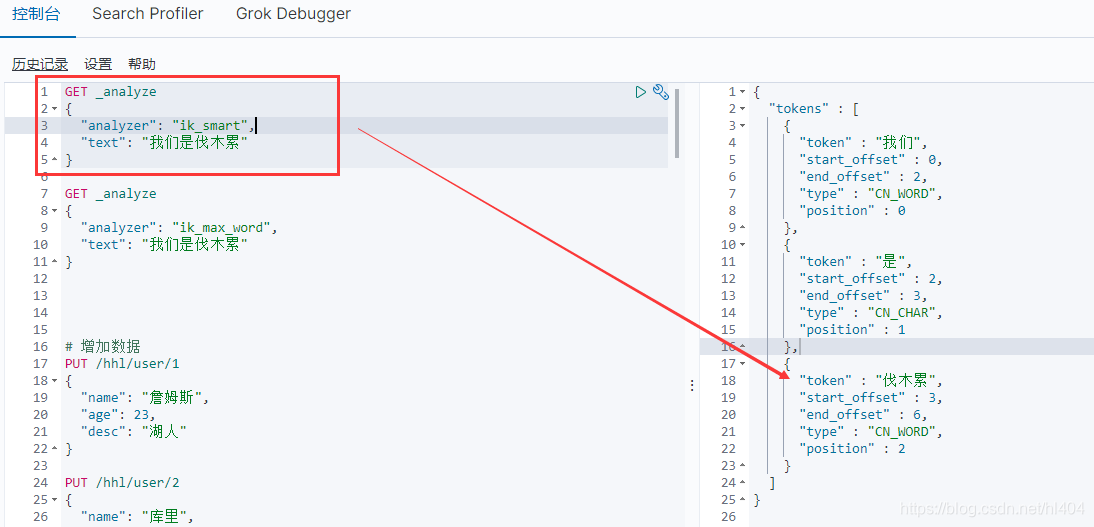
IK有两种分词的算法ik_smart 和 ik_max_word
ik_smart:粗粒度分词,优先匹配最长的词,就是把一句话中最长的词列出来即可,像下面的这句话“今天天气怎么样啊” ,因为“今天天气”是一个词,那它就不会在对这个词进行细分了,怎么样也不会再细分了
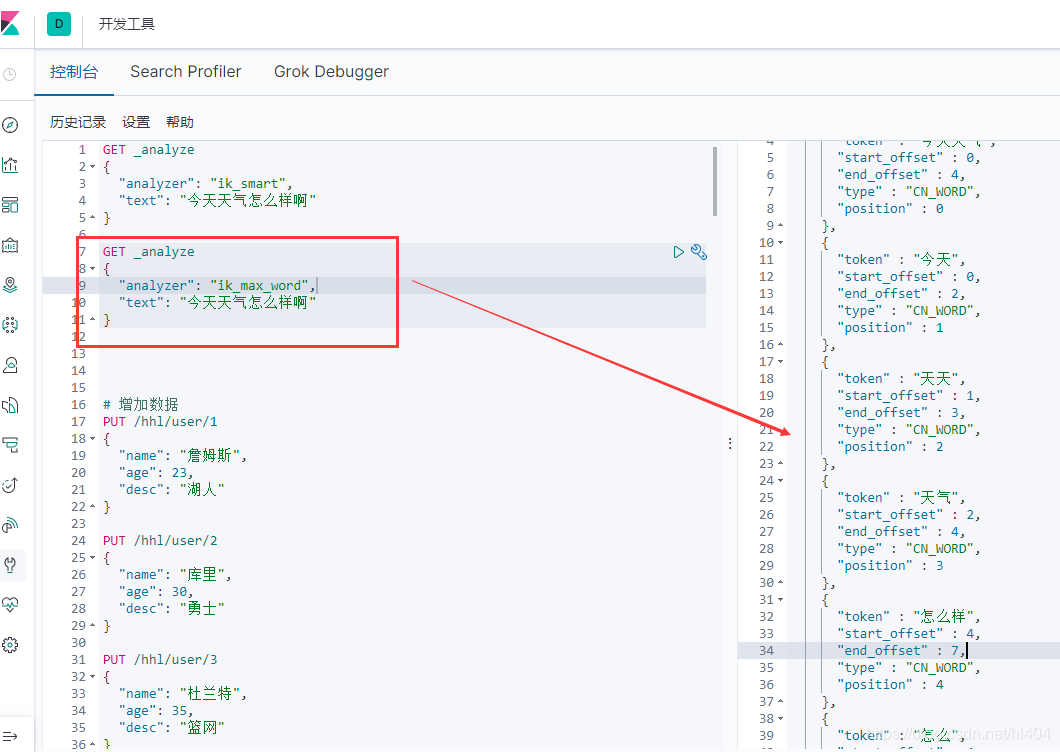
ik_max_word:细粒度分词,这个分词算法会穷尽一句话中所有分词的可能
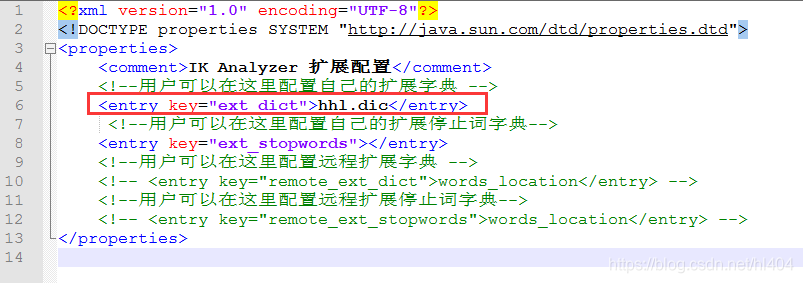
自定义词库:有些中文词不在ik分词算法中,比如"伐木累",但是我们想让它在进行搜索分词时当成一个词,此时我们需要编写一个自定义词库。
- 进入ik的config目录下,新建一个文件hhl.dic,并在该文件中写入伐木累这个词

- 修改当前目录下的IKAnalyzer.cfg.xml
- 修改完毕重启es
然后在kibana中测试,可以发现伐木累已经被分成一个词了
六、ES基本操作
ES的操作时基于Resutful风格的请求,Restful是一种软件架构风格,不是标准,只是提供了一组设计规则和约束条件,使用restful可以让我们的请求更加规范更简洁更有层次,更易于实现缓存等机制。(restful是一种风格,我们的软件应该尽可能的都去使用restful这种风格)
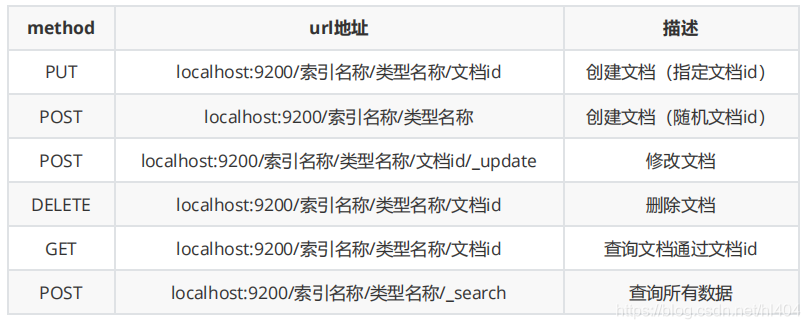
ES中基本Rest命令说明:
上面已经把es的基本概念和数据结构了解的差不多了,下面进入es的一些基本增删改查的操作,这些操作我们先在kibana中dev_tools下的Console控制台中完成。
# 增加一条数据,索引为hhl,类型为user,id为1 ,文档内容就是下面的内容 PUT /hhl/user/1 { "name": "詹姆斯", "age": 23, "desc": "湖人" } # 查询数据 GET hhl/user/1 返回结果如下: { "_index" : "hhl", "_type" : "user", "_id" : "1", "_version" : 8, "_seq_no" : 15, "_primary_term" : 1, "found" : true, "_source" : { "name" : "詹姆斯", "age" : 23, "desc" : "湖人" } } # 删除数据 DELETE hhl/user/1 # 更新数据,要修改的内容需放到doc文档中 POST hhl/user/1/_update { "doc":{ "name":"韦德", "age":3 } } GET hhl/user/_search?q=name:杜兰 # 构建查询,这种才是开发中常用的写法,上面的一般不用(可以理解为上面的详细写法) GET hhl/user/_search { "query": { "match": { "name": "杜兰" } } } # 不加条件,查询所有 GET hhl/user/_search # 等效于上面的查询所有 GET hhl/user/_search { "query": { "match_all": {} } } # _source 指定查询哪些字段,类似数据库中的select a.name,a.age from a GET hhl/user/_search { "query": { "match": { "name": "杜兰" } }, "_source": ["name","age"] } # sort 排序,根据age降序排列。注意:排序字段只能是数字、日期、id 这三种 GET hhl/user/_search { "query": { "match_all": {} }, "sort": [ { "age": { "order": "desc" } } ] } # 分页查询 from:从第几条开始 size:查询几条数据 GET hhl/user/_search { "query": { "match_all": {} }, "from": 0, "size": 3 } # 多条件查询,不是直接写两个match,而是要像下面这么写,bool 布尔查询 must就是and的意思 GET hhl/user/_search { "query": { "bool": { "must": [ { "match": { "name": "杜兰" } }, { "match": { "age": 35 } } ] } } } # should 就是 or GET hhl/user/_search { "query": { "bool": { "should": [ { "match": { "name": "杜兰" } }, { "match": { "age": 35 } } ] } } } # must_not ! 查询不匹配的条件 GET hhl/user/_search { "query": { "bool": { "must_not": [ { "match": { "name": "杜兰" } } ] } } } # filter 过滤条件 gte 大于等于 lte小于等于 gt 大于 lt小于 GET hhl/user/_search { "query": { "bool": { "filter": { "range": { "age": { "gte": 30, "lte": 40 } } } } } } # terms 精确查询 GET hhl/user/_search { "query": { "bool": { "should": [ { "terms": { "age": [ "35", "36" ] } }, { "terms": { "age": [ "37" ] } } ] } } } # 高亮显示 name字段 GET hhl/user/_search { "query": { "match": { "name": "杜兰特" } }, "highlight": { "fields": { "name":{} } } } # 默认高亮显示的样式是em标签,我们可以修改高亮样式 GET jd_goods/_doc/_search { "query": { "match": { "title": "华为" } }, "highlight": { "pre_tags": "<span class='red' style='color:red'>", "post_tags": "</span>", "fields": { "title":{} } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
这里高亮返回的结果需要注意一下:
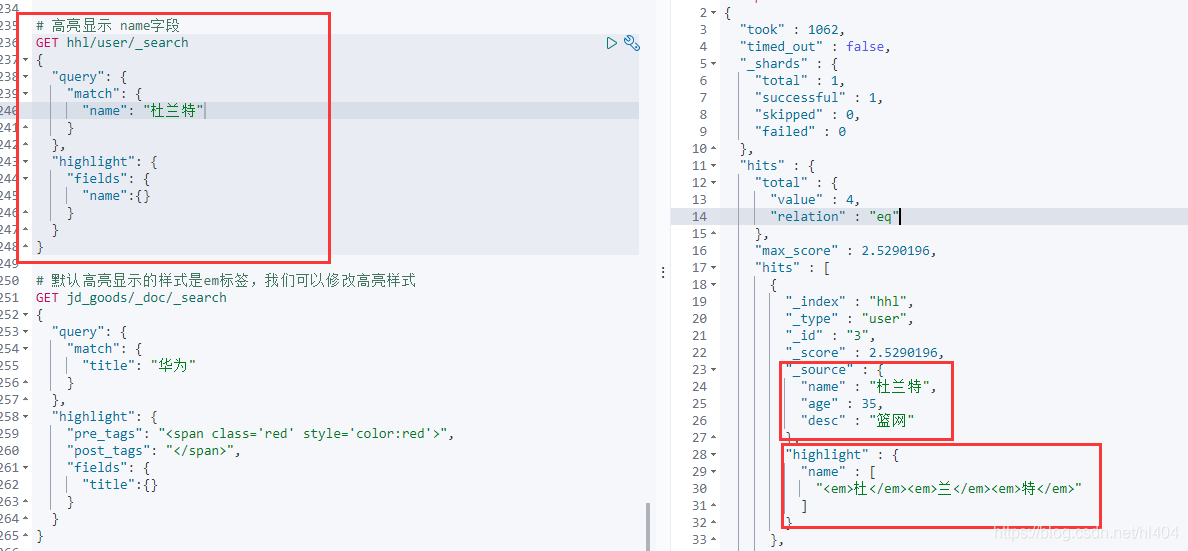
可以看到source里面是我们的文档内容,高亮字段并没有直接放到source内容里,而是单独分出来了高亮的内容在highlight标签中,所以后面我们在项目中实现高亮效果时,需要将highlight中高亮的字段内容去替换掉原本source中的内容
七:API操作ES索引及文档
上面是在kibana的控制台中去对es的基本增删盖查进行操作,而实际开发中我们肯定是在项目中去操作es,那就要先去熟悉es提供的客户端API。
ES提供两种客户端,一种高级的Java High Level REST Client,一种低级的Java Low Level REST Client,我们肯定要使用高级的啊。
- 首先创建一个springboot项目,导入es依赖,且es依赖版本要和我们安装的一致,所以需要指定es的版本

- 编写配置类,构建RestHighLevelClient对象
@Configuration
public class ElasticSearchClientConfig {
@Bean("restHighLevelClient")
public RestHighLevelClient getRestHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 进行api的测试
@SpringBootTest class ElasticSearchDemo01ApplicationTests { //@Autowired //@Qualifier("restHighLevelClient") @Resource(name = "restHighLevelClient") private RestHighLevelClient client; @Test void contextLoads() { } // =================对索引的操作=================== @Test // 创建索引 public void testCreateIndex() throws Exception{ CreateIndexRequest request = new CreateIndexRequest("hhl_index"); CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT); System.out.println(createIndexResponse); } @Test // 获取索引 public void testGetIndex() throws Exception{ GetIndexRequest request = new GetIndexRequest("hhl_index"); boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); System.out.println(exists); } @Test // 删除索引 public void testDeleteIndex() throws Exception{ DeleteIndexRequest request = new DeleteIndexRequest("hhl_index"); AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT); System.out.println(response.isAcknowledged()); } //=================对文档的操作================= @Test // 添加文档 public void testAddDocument() throws Exception{ User user = new User("詹姆斯",23); // 创建对应的request请求 IndexRequest indexRequest = new IndexRequest("hhl_index"); indexRequest.timeout("1s"); indexRequest.id("1"); indexRequest.source(JSON.toJSONString(user), XContentType.JSON); // 发送请求 IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT); System.out.println(indexResponse.toString()); System.out.println(indexResponse.status()); } @Test // 获取指定id文档 public void testGetDocument() throws Exception{ // 创建请求 GetRequest getRequest = new GetRequest("hhl_index", "1"); // 发送请求 GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT); // 打印文档内容 System.out.println(getResponse.getSourceAsString()); System.out.println(getResponse); } @Test // 更新文档 public void updateDocument() throws Exception{ // 创建更新请求 UpdateRequest updateRequest = new UpdateRequest("hhl_index", "1"); updateRequest.timeout(TimeValue.timeValueSeconds(1)); updateRequest.timeout("1s"); User user = new User("库里",30); updateRequest.doc(JSON.toJSONString(user),XContentType.JSON); // 发送更新请求 UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT); System.out.println(updateResponse); } @Test // 删除文档 public void deleteDocument() throws Exception{ //创建删除请求 DeleteRequest deleteRequest = new DeleteRequest("hhl_index", "1"); // 发送删除请求 client.delete(deleteRequest,RequestOptions.DEFAULT); } @Test // 批量添加文档 public void addDocumentList() throws Exception{ // 批量的操作其实就是将多个请求放入BulkRequest中,底层其实还是循环发生请求的 BulkRequest bulkRequest = new BulkRequest();// bulk 大量的 bulkRequest.timeout(TimeValue.timeValueMinutes(2)); bulkRequest.timeout("2m"); ArrayList<User> userList = new ArrayList<>(); userList.add(new User("詹姆斯",23)); userList.add(new User("库里",30)); userList.add(new User("杜兰特",35)); for (int i = 0; i < userList.size(); i++) { // 批量更新、删除就是在这里add不同的updateRequest 和 deleteRequest bulkRequest.add(new IndexRequest("hhl_index").id(""+(i+1)).source(JSON.toJSONString(userList.get(i)),XContentType.JSON)); } BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT); System.out.println(bulkResponse); System.out.println("批量操作是否成功:"+!bulkResponse.hasFailures());//hasFailures() 判断是否失败 } @Test // 文档查询 public void testSearchDocument() throws Exception{ // 1.创建查询请求 SearchRequest searchRequest = new SearchRequest("hhl_index"); // 2.创建SearchSourceBuilder SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); // 3.创建查询条件,matchAllQuery 查询所有 MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery(); //TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "杜兰特"); // 4.将查询条件放入searchSourceBuilder searchSourceBuilder.query(matchAllQueryBuilder); searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // 5.将searchSourceBuilder放入查询请求中 searchRequest.source(searchSourceBuilder); // 6.发送查询请求 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); // 7.遍历查询结果 hits() System.out.println(JSON.toJSONString(searchResponse.getHits())); System.out.println("==============SearchHit==============="); for (SearchHit documentFields : searchResponse.getHits().getHits()) { System.out.println(documentFields.getSourceAsMap()); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
从以上API的测试中可以总结出来,基本分为以下几步:
- 创建rest请求
- 逻辑编写(查询条件之类的)
- 使用RestHighLevelClient 发送请求,获得相应结果
- 处理相应结果
ES提供了很多API,要去完全记住这些API还是要花点时间的…
八、项目实战测试
该项目测试是先将京东的商品数据读取到es中,然后对数据进行查询。(和上面的api调用差不多,就是多了个pa chong的操作)
Jsoup: 是一款java的html解析器,可直接解析某个url下的html文本内容,它提供了一套非常省力的API,可通过DOM,CSS以及类似于JQuery的操作方法来取出和操作数据。
具体的操作逻辑代码如下:
public class HtmlParseUtil { public static List<Content> parseJD(String keyword) throws Exception { String url="https://search.jd.com/Search?keyword="+keyword; // 1.使用Jsoup解析网页,获得网页的文档,这个document就相当于网页的html代码了 Document document = Jsoup.parse( new URL(url),30000); // 2.根据id获取元素,和原生js方法一样 Element element = document.getElementById("J_goodsList"); // 3.在当前id元素下获取所有的li标签 Elements elements = element.getElementsByTag("li"); List<Content> contentList = new ArrayList<>(); // 4.遍历所有的li标签,获取我们需要的数据 for (Element el : elements) { // 因为京东对商品图片采用了懒加载,所以直接读src属性是读不到路径的,要读data-lazy-img这个属性 String imgUrl= el.getElementsByTag("img").eq(0).attr("data-lazy-img"); String price = el.getElementsByClass("p-price").eq(0).text(); String title = el.getElementsByClass("p-name").eq(0).text(); // 封装数据 Content content = new Content(); content.setImg(imgUrl); content.setPrice(price); content.setTitle(title); contentList.add(content); } return contentList; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
根据关键词查询,把读取的数据放入es中
public Boolean parseContent(String keywords) throws Exception{ // 通过工具类获取到数据 List<Content> contentList = HtmlParseUtil.parseJD(keywords); BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout(TimeValue.timeValueMinutes(2)); bulkRequest.timeout("2m"); for (int i = 0; i < contentList.size(); i++) { if(isNotNull(contentList.get(i).getImg()) && isNotNull(contentList.get(i).getTitle()) && isNotNull(contentList.get(i).getPrice())){ bulkRequest.add(new IndexRequest("jd_goods").source(JSON.toJSONString(contentList.get(0)), XContentType.JSON)); } } // 将数据放入ES中 BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); return !bulkResponse.hasFailures(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
数据存进去了,下面就是查询数据了
public List<Map<String, Object>> searchContentPage(String keyword, int pageNo, int pageSize) throws Exception{ // 1.创建查询请求 SearchRequest searchRequest = new SearchRequest("jd_goods"); // 2.创建searchSourceBuilder SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); // 分页设置 searchSourceBuilder.from(pageNo); searchSourceBuilder.size(pageSize); // 3.创建查询条件 TermQueryBuilder termQuery = QueryBuilders.termQuery("title", keyword); searchSourceBuilder.query(termQuery); //4.将searchSourceBuilder放入查询请求中 searchRequest.source(searchSourceBuilder); //5.发送查询请求,返回响应结果 SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); // 6.解析结果 List<Map<String, Object>> list = new ArrayList<>(); for (SearchHit documentFields : searchResponse.getHits().getHits()) { list.add(documentFields.getSourceAsMap()); } return list; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
那为了使我们所查询的关键性高亮,所以要在上面的普通查询的代码中增加高亮的逻辑
public List<Map<String, Object>> searchContentHighlighter(String keyword, int pageNo, int pageSize) throws Exception{ // 1.创建查询请求 SearchRequest searchRequest = new SearchRequest("jd_goods"); // 2.创建searchSourceBuilder SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // 分页设置 searchSourceBuilder.from(pageNo); searchSourceBuilder.size(pageSize); // 3. 查询条件构建 TermQueryBuilder termQuery = QueryBuilders.termQuery("title", keyword); searchSourceBuilder.query(termQuery);// 放入查询条件 // 高亮构建 HighlightBuilder highlightBuilder = new HighlightBuilder(); highlightBuilder.field("title"); highlightBuilder.requireFieldMatch(false); highlightBuilder.preTags("<span style='color:red'>"); highlightBuilder.postTags("</span>"); searchSourceBuilder.highlighter(highlightBuilder); // 放入高亮条件 //4.将searchSourceBuilder放入查询请求中 searchRequest.source(searchSourceBuilder); //5.发送查询请求,返回响应结果 SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); // 6.解析结果 List<Map<String, Object>> list = new ArrayList<>(); for (SearchHit hit : searchResponse.getHits().getHits()) { // *****************高亮字段替换 start ******************* // 从kibana的控制台高亮查询可以发现,高亮字段是放到highlight这个标签里面的,而source字段里面放的就是纯数据 // 所以我们为了使输出的source带上高亮的效果,就需要把highlight标签里的高亮字段内容,替换掉source里面的字段内容 Map<String, Object> source = hit.getSourceAsMap();// 首先先获取source的数据内容,因为下面要对它进行替换 Map<String, HighlightField> highlightFields = hit.getHighlightFields();// 获取高亮highlight标签下的所有内容 HighlightField titleField = highlightFields.get("title");// 获取highlight标签中高亮的title字段 if(titleField!=null){ String title=""; Text[] fragments = titleField.fragments();// 解析字段title并循环获取到它的值 for (Text fragment : fragments) { title+=fragment; } // 这里就是用高亮字段,去替换掉source中本来的title字段 source.put("title",title); } // *****************高亮字段替换 end ******************* // 替换完成,放入list中 list.add(source); } return list; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
高亮效果其实就是在普通查询之前我们要构建高亮的条件,由于返回的结果_soucre标签的内容和高亮的内容是分开的,所以我们需要将高亮内容去替换掉原来的_source里面对应的需高亮的字段。(这个上面也说过)
以上就是ES的基本总结,上面的内容只是ES的基本概念和操作,ES的内容远不止这些,还有ES集群等更烧脑的东西…


