
热门标签
热门文章
- 1Androidstudio ADB调试_andriod studio canary11 adb 调试
- 2通过mac电脑将macos系统的dmg镜像转换为iso文件,供VMware安装mac系统_dmg转iso
- 3自动驾驶合集5
- 4【免费】如何考取HarmonyOS应用开发者基础认证和高级认证(详细教程)_华为开发者认证考试在哪里打开
- 5CodeWhisperer--手把手教你使用一个十分强大的工具_coderormer
- 6Android性能优化系列之Bitmap图片优化_android 列表获取封面 bitmapfactory.decodebytearray 太卡
- 7使用 python nltk 库对预料库进行自动词性标注_怎么利用nltk进行词性标注要把语料放哪里
- 8BERT_论文解析_bert 论文
- 9VUE点击切换样式_vue ul li 文本内容样式
- 10pycharm中的terminal运行前面的PS如何修改成自己环境_terminal里面ps怎么换成base
当前位置: article > 正文
【深度学习 项目实战】Keras深度学习多变量时间序列预测的LSTM模型_关于keras用深度学习预测时间序列
作者:Cpp五条 | 2024-03-28 00:17:23
赞
踩
关于keras用深度学习预测时间序列
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。人工智能教程
本篇文章将介绍基于Keras深度学习的多变量时间序列预测的LSTM模型。
项目名称:空气污染预测
一、主要内容:
如何将原始数据集转换为可用于时间序列预测的内容。
如何准备数据并使LSTM适合多变量时间序列预测问题。
如何进行预测并将结果重新缩放为原始单位。
- 1
- 2
- 3
二、数据下载
在本教程中,我们将使用空气质量数据集。该数据集报告了美国驻中国大使馆五年来每小时的天气和污染水平。数据包括日期时间,称为PM2.5浓度的污染以及包括露点,温度,压力,风向,风速和雪雨累计小时数的天气信息。原始数据中的完整功能列表如下:
否:行号
年:此行中的数据年份
month:此行中数据的月份
日期:此行中的数据日期
hour:该行中的数据小时
pm2.5:PM2.5浓度
露点:露点
TEMP:温度
PRES:压力
cbwd:组合风向
Iws:累计风速
是:累计下雪时间
Ir:累计下雨时间
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
我们可以使用这些数据来构建预测问题,在此情况下,鉴于前几个小时的天气条件和污染,我们可以预测下一个小时的污染。
数据下载地址
下载数据集并将其命名为 raw.csv
三、数据处理
第一步,将零散的日期时间信息整合为一个单一的日期时间,以便我们可以将其用作 Pandas 的索引。
快速检查第一天的 pm2.5 的 NA 值。因此,我们需要删除第一行数据。在数据集中还有几个零散的「NA」值,我们现在可以用 0 值标记它们。
以下脚本用于加载原始数据集,并将日期时间信息解析为 Pandas DataFrame 索引。「No」列被删除,每列被指定更加清晰的名称。最后,将 NA 值替换为「0」值,并删除前一天的数据。
# -*- coding: utf-8 -*- from pandas import * # 定义字符串转换为日期数据 def parse(x): return datetime.strptime(x, '%Y %m %d %H') # 数据存放路径设置 data_path=r'D:\深度学习\数据集\raw.csv' # 读取数据 dataset = read_csv(data_path,sep=',', parse_dates = [['year', 'month', 'day', 'hour']], index_col=0, date_parser=parse) # 删除NO列 dataset.drop('No', axis=1, inplace=True) # 重命名 dataset.columns = ['pollution', 'dew', 'temp', 'press', 'wnd_dir', 'wnd_spd', 'snow', 'rain'] # 索引重命名 dataset.index.name = 'date' # 填充NA值为0 dataset['pollution'].fillna(0, inplace=True) # 删除前24行无效数据 dataset = dataset[24:] # 打印前五行数据 print(dataset.head(5)) # 保存数据 dataset.to_csv(r'D:\深度学习\数据集\pollution.csv')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
pollution dew temp press wnd_dir wnd_spd snow rain
date
2010-01-02 00:00:00 129.0 -16 -4.0 1020.0 SE 1.79 0 0
2010-01-02 01:00:00 148.0 -15 -4.0 1020.0 SE 2.68 0 0
2010-01-02 02:00:00 159.0 -11 -5.0 1021.0 SE 3.57 0 0
2010-01-02 03:00:00 181.0 -7 -5.0 1022.0 SE 5.36 1 0
2010-01-02 04:00:00 138.0 -7 -5.0 1022.0 SE 6.25 2 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
四、建立多变量 LSTM 预测模型
# -*- coding: utf-8 -*- from math import sqrt from numpy import concatenate from matplotlib import pyplot from pandas import read_csv from pandas import DataFrame from pandas import concat from sklearn.preprocessing import MinMaxScaler from sklearn.preprocessing import LabelEncoder from sklearn.metrics import mean_squared_error,r2_score from keras.models import Sequential from keras.layers import Dense from keras.layers import LSTM # 将序列转换为监督学习函数 def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols, names = list(), list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)] # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) if i == 0: names += [('var%d(t)' % (j + 1)) for j in range(n_vars)] else: names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)] # put it all together agg = concat(cols, axis=1) agg.columns = names # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg # 导入数据集 dataset = read_csv(r'D:\深度学习\数据集\pollution.csv', header=0, index_col=0) values = dataset.values # 离散变量独热编码 encoder = LabelEncoder() values[:, 4] = encoder.fit_transform(values[:, 4]) # 转换数据类型 values = values.astype('float32') # 特征归一化为0-1之间 scaler = MinMaxScaler(feature_range=(0, 1)) scaled = scaler.fit_transform(values) # 数据转换为监督学习数据集 reframed = series_to_supervised(scaled, 1, 1) # 删除不需要的列 reframed.drop(reframed.columns[[9, 10, 11, 12, 13, 14, 15]], axis=1, inplace=True) # 划分训练数据集和测试数据集 values = reframed.values n_train_hours = 365 * 24 train = values[:n_train_hours, :] test = values[n_train_hours:, :] train_X, train_y = train[:, :-1], train[:, -1] test_X, test_y = test[:, :-1], test[:, -1] # 将输入(X)重构为 LSTM 预期的 3D 格式,即 [样本,时间步,特征]。 # reshape input to be 3D [samples, timesteps, features] train_X = train_X.reshape((train_X.shape[0], 1, train_X.shape[1])) test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1])) print(train_X.shape, train_y.shape, test_X.shape, test_y.shape) # 设计lstm模型 model = Sequential() model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2]))) model.add(Dense(1)) model.compile(loss='mae', optimizer='adam') # 训练模型 history = model.fit(train_X, train_y, epochs=100, batch_size=50, validation_data=(test_X, test_y), verbose=2, shuffle=False) # 误差可视化 pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() # 模型预测 yhat = model.predict(test_X) # 转换预测值 test_X = test_X.reshape((test_X.shape[0], test_X.shape[2])) inv_yhat = concatenate((yhat, test_X[:, 1:]), axis=1) inv_yhat = scaler.inverse_transform(inv_yhat) inv_yhat = inv_yhat[:,0] # 转换实际值 test_y = test_y.reshape((len(test_y), 1)) inv_y = concatenate((test_y, test_X[:, 1:]), axis=1) inv_y = scaler.inverse_transform(inv_y) inv_y = inv_y[:,0] # 模型评估 # 均方误差 rmse = sqrt(mean_squared_error(inv_y, inv_yhat)) # R方 r2=r2_score(inv_y, inv_yhat) print('Test RMSE: %.3f' % rmse) print('Test R2:%.3f' % r2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
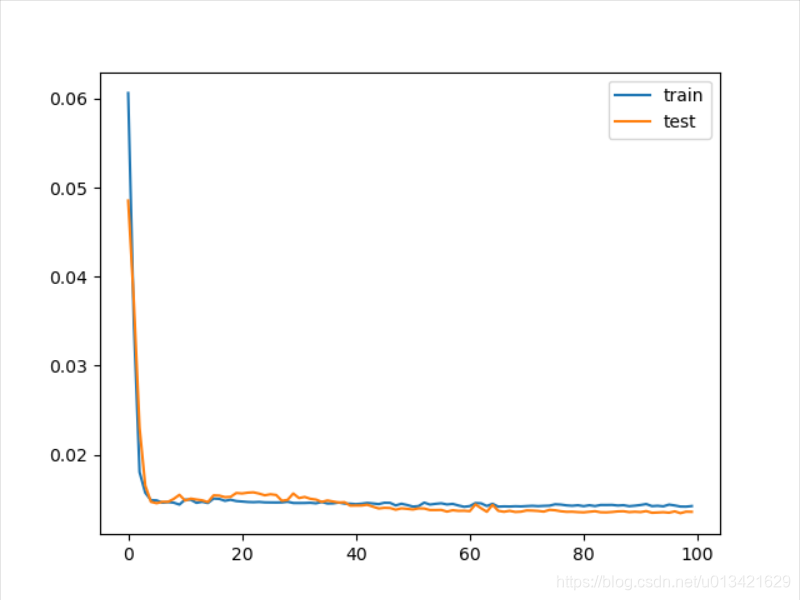
Using TensorFlow backend. 2019-12-19 10:32:46.083137: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_100.dll (8760, 1, 8) (8760,) (35039, 1, 8) (35039,) 2019-12-19 10:32:47.305909: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library nvcuda.dll 2019-12-19 10:32:47.333454: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties: name: GeForce GTX 1650 major: 7 minor: 5 memoryClockRate(GHz): 1.56 pciBusID: 0000:01:00.0 2019-12-19 10:32:47.333855: I tensorflow/stream_executor/platform/default/dlopen_checker_stub.cc:25] GPU libraries are statically linked, skip dlopen check. 2019-12-19 10:32:47.334613: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0 2019-12-19 10:32:47.335203: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2019-12-19 10:32:47.337976: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1618] Found device 0 with properties: name: GeForce GTX 1650 major: 7 minor: 5 memoryClockRate(GHz): 1.56 pciBusID: 0000:01:00.0 2019-12-19 10:32:47.338315: I tensorflow/stream_executor/platform/default/dlopen_checker_stub.cc:25] GPU libraries are statically linked, skip dlopen check. 2019-12-19 10:32:47.339027: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1746] Adding visible gpu devices: 0 2019-12-19 10:32:47.854835: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1159] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-12-19 10:32:47.855022: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1165] 0 2019-12-19 10:32:47.855120: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1178] 0: N 2019-12-19 10:32:47.855868: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1304] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 2919 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1650, pci bus id: 0000:01:00.0, compute capability: 7.5) Train on 8760 samples, validate on 35039 samples Epoch 1/100 2019-12-19 10:32:48.783437: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_100.dll - 2s - loss: 0.0606 - val_loss: 0.0485 Epoch 2/100 - 1s - loss: 0.0347 - val_loss: 0.0372 Epoch 3/100 - 1s - loss: 0.0180 - val_loss: 0.0230 Epoch 4/100 - 1s - loss: 0.0157 - val_loss: 0.0165 Epoch 5/100 - 1s - loss: 0.0149 - val_loss: 0.0147 Epoch 6/100 - 2s - loss: 0.0149 - val_loss: 0.0145 Epoch 7/100 - 2s - loss: 0.0146 - val_loss: 0.0147 Epoch 8/100 - 2s - loss: 0.0147 - val_loss: 0.0147 Epoch 9/100 - 2s - loss: 0.0146 - val_loss: 0.0150 Epoch 10/100 - 2s - loss: 0.0144 - val_loss: 0.0155 Epoch 11/100 - 2s - loss: 0.0149 - val_loss: 0.0148 Epoch 12/100 - 2s - loss: 0.0149 - val_loss: 0.0151 Epoch 13/100 - 2s - loss: 0.0146 - val_loss: 0.0150 Epoch 14/100 - 2s - loss: 0.0147 - val_loss: 0.0149 Epoch 15/100 - 2s - loss: 0.0146 - val_loss: 0.0147 Epoch 16/100 - 2s - loss: 0.0151 - val_loss: 0.0154 Epoch 17/100 - 2s - loss: 0.0150 - val_loss: 0.0154 Epoch 18/100 - 2s - loss: 0.0148 - val_loss: 0.0152 Epoch 19/100 - 2s - loss: 0.0149 - val_loss: 0.0153 Epoch 20/100 - 2s - loss: 0.0148 - val_loss: 0.0157 Epoch 21/100 - 2s - loss: 0.0147 - val_loss: 0.0156 Epoch 22/100 - 2s - loss: 0.0147 - val_loss: 0.0157 Epoch 23/100 - 2s - loss: 0.0147 - val_loss: 0.0158 Epoch 24/100 - 2s - loss: 0.0147 - val_loss: 0.0156 Epoch 25/100 - 2s - loss: 0.0146 - val_loss: 0.0154 Epoch 26/100 - 2s - loss: 0.0146 - val_loss: 0.0155 Epoch 27/100 - 2s - loss: 0.0146 - val_loss: 0.0155 Epoch 28/100 - 2s - loss: 0.0146 - val_loss: 0.0148 Epoch 29/100 - 2s - loss: 0.0147 - val_loss: 0.0149 Epoch 30/100 - 2s - loss: 0.0146 - val_loss: 0.0156 Epoch 31/100 - 2s - loss: 0.0146 - val_loss: 0.0151 Epoch 32/100 - 2s - loss: 0.0146 - val_loss: 0.0152 Epoch 33/100 - 2s - loss: 0.0146 - val_loss: 0.0150 Epoch 34/100 - 2s - loss: 0.0145 - val_loss: 0.0149 Epoch 35/100 - 2s - loss: 0.0147 - val_loss: 0.0147 Epoch 36/100 - 2s - loss: 0.0145 - val_loss: 0.0148 Epoch 37/100 - 2s - loss: 0.0145 - val_loss: 0.0147 Epoch 38/100 - 2s - loss: 0.0146 - val_loss: 0.0146 Epoch 39/100 - 2s - loss: 0.0145 - val_loss: 0.0146 Epoch 40/100 - 2s - loss: 0.0145 - val_loss: 0.0143 Epoch 41/100 - 2s - loss: 0.0144 - val_loss: 0.0143 Epoch 42/100 - 2s - loss: 0.0145 - val_loss: 0.0143 Epoch 43/100 - 2s - loss: 0.0146 - val_loss: 0.0144 Epoch 44/100 - 2s - loss: 0.0145 - val_loss: 0.0141 Epoch 45/100 - 2s - loss: 0.0144 - val_loss: 0.0139 Epoch 46/100 - 2s - loss: 0.0146 - val_loss: 0.0140 Epoch 47/100 - 2s - loss: 0.0146 - val_loss: 0.0140 Epoch 48/100 - 2s - loss: 0.0143 - val_loss: 0.0138 Epoch 49/100 - 2s - loss: 0.0145 - val_loss: 0.0140 Epoch 50/100 - 2s - loss: 0.0143 - val_loss: 0.0139 Epoch 51/100 - 2s - loss: 0.0142 - val_loss: 0.0138 Epoch 52/100 - 2s - loss: 0.0142 - val_loss: 0.0140 Epoch 53/100 - 2s - loss: 0.0146 - val_loss: 0.0139 Epoch 54/100 - 2s - loss: 0.0144 - val_loss: 0.0138 Epoch 55/100 - 2s - loss: 0.0145 - val_loss: 0.0138 Epoch 56/100 - 2s - loss: 0.0145 - val_loss: 0.0138 Epoch 57/100 - 2s - loss: 0.0144 - val_loss: 0.0136 Epoch 58/100 - 2s - loss: 0.0145 - val_loss: 0.0137 Epoch 59/100 - 2s - loss: 0.0143 - val_loss: 0.0137 Epoch 60/100 - 2s - loss: 0.0141 - val_loss: 0.0137 Epoch 61/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 62/100 - 2s - loss: 0.0146 - val_loss: 0.0144 Epoch 63/100 - 2s - loss: 0.0145 - val_loss: 0.0140 Epoch 64/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 65/100 - 2s - loss: 0.0145 - val_loss: 0.0144 Epoch 66/100 - 2s - loss: 0.0142 - val_loss: 0.0137 Epoch 67/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 68/100 - 2s - loss: 0.0142 - val_loss: 0.0137 Epoch 69/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 70/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 71/100 - 2s - loss: 0.0142 - val_loss: 0.0137 Epoch 72/100 - 2s - loss: 0.0142 - val_loss: 0.0137 Epoch 73/100 - 2s - loss: 0.0142 - val_loss: 0.0137 Epoch 74/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 75/100 - 2s - loss: 0.0143 - val_loss: 0.0138 Epoch 76/100 - 2s - loss: 0.0144 - val_loss: 0.0137 Epoch 77/100 - 2s - loss: 0.0144 - val_loss: 0.0136 Epoch 78/100 - 2s - loss: 0.0143 - val_loss: 0.0136 Epoch 79/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 80/100 - 2s - loss: 0.0143 - val_loss: 0.0135 Epoch 81/100 - 2s - loss: 0.0142 - val_loss: 0.0135 Epoch 82/100 - 2s - loss: 0.0143 - val_loss: 0.0136 Epoch 83/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Epoch 84/100 - 2s - loss: 0.0143 - val_loss: 0.0135 Epoch 85/100 - 2s - loss: 0.0143 - val_loss: 0.0135 Epoch 86/100 - 2s - loss: 0.0143 - val_loss: 0.0135 Epoch 87/100 - 2s - loss: 0.0143 - val_loss: 0.0136 Epoch 88/100 - 2s - loss: 0.0143 - val_loss: 0.0136 Epoch 89/100 - 2s - loss: 0.0142 - val_loss: 0.0135 Epoch 90/100 - 2s - loss: 0.0143 - val_loss: 0.0136 Epoch 91/100 - 2s - loss: 0.0143 - val_loss: 0.0135 Epoch 92/100 - 2s - loss: 0.0144 - val_loss: 0.0136 Epoch 93/100 - 2s - loss: 0.0142 - val_loss: 0.0135 Epoch 94/100 - 2s - loss: 0.0142 - val_loss: 0.0135 Epoch 95/100 - 2s - loss: 0.0142 - val_loss: 0.0135 Epoch 96/100 - 2s - loss: 0.0144 - val_loss: 0.0135 Epoch 97/100 - 2s - loss: 0.0143 - val_loss: 0.0136 Epoch 98/100 - 2s - loss: 0.0142 - val_loss: 0.0134 Epoch 99/100 - 2s - loss: 0.0141 - val_loss: 0.0136 Epoch 100/100 - 2s - loss: 0.0142 - val_loss: 0.0136 Test RMSE: 26.489 Test R2:0.917 Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
评估模型
模型拟合后,我们可以预测整个测试数据集。通过初始预测值和实际值,我们可以计算模型的误差分数。在这种情况下,我们可以计算出与变量相同的单元误差的均方根误差(RMSE)。
以及R方确定系数
Test RMSE: 26.489
Test R2:0.917
模型效果不错哦
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/327706
推荐阅读
相关标签

