
- 1蓝桥杯备赛:洛谷刷题日常积累_蓝桥杯洛谷要刷哪些题
- 2YOLOv5、YOLOv8改进ELAN系列:首发结合最新efficient Layer Aggregation Networks结构(内附源代码),高效的聚合网络设计,提升性能_elan可以怎样改进
- 3python bottle框架 重定向_Python的web框架bottle静态文件的路径
- 4信息安全数学基础——模重复平方计算法(两种方法实现C+JAVA)
- 5微信小程序自定义弹窗组件
- 6基于Qt5开发的停车场管理系统_qt停车场项目
- 7面试八股文_github nlp八股
- 8TensorRT&Triton学习笔记(一):triton和模型部署+client
- 9python词云需要导入什么包_[python] 词云:wordcloud包的安装、使用、原理(源码分析)、中文词云生成、代码重写...
- 10在ASP.Net Core 中禁用HTTP选项方法_asp.net core禁用http/2
BERT_论文解析_bert 论文
赞
踩
论文原址:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
读这篇论文前,我建议大家提前读一读Transformer这篇论文,求快的话可以看李沐老师的论文课。
前言
在计算机视觉领域内,我们可以利用一个大型的数据集例如ImageNet来训练一个CNN网络,利用训练好的模型可以来帮助之后很多的计算机视觉的任务,而对于BERT之前的NLP领域,我们针对每个NLP任务都是要单独训练一个网络来进行实际操作,做不到加载预训练的目的。那由于BERT的出现,我们终于可以在一个大型的数据集上训练一个深的神经网络,以至于可以应用在以后很多的NLP任务上面,达成这样一个预训练的操作,既简化了训练的过程,又提升了网络的性能。所以BERT以及BERT的后续操作,对后续nlp的任务实现,有了一个质的飞跃。
标题
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT:是论文作者起的一个名字,简洁,而且能让人很容易记住,起名字这种东西,例如卷积神经网络LeNet,AlexNet,ResNet,循环神经网络RNN,LSTM,GRU,以及视觉领域的RCNN,FCN,新网络Transformer,GNN,GAN,这些名字就很简洁而且一想就能想到了,以后各位同学构造出新网络了也可以参照类似于上述的操作,给自己的新网络定义一个一眼就知道什么意思而且能记得住的名字。
Pre-training:是预训练的意思,预训练指的是我在一个数据集上训练好一个模型,但是利用这个模型跑别的一个任务,这个别的任务是training的话,那我之前针对大的数据集上来训练的这个过程就是pre-training。还有一种最直白的“预训练”的理解就是,把别人在某个问题上(和自己的问题有相似的解法)已经训练好的模型拿来用,再在自己的数据上进行训练一下,更新一下参数就是自己的模型。
Deep Bidirectional Transformers:这里涉及到了Transformers的讲解,推荐大家看一下bilibili李沐的transformers的论文讲解李沐《Transformer》。Deep就是这个网络是一个比较深的网络,Bidirectional是双向的意思。
Language Understanding:在Transformer论文里,作者的实验部分主要是放在了机器翻译上面,这里就用了一个更加广义的词汇,就是对语言的一个理解。
总结:BERT是一个深的双向的Transformer网络,是用来做预训练的,针对的一般的语言理解任务。
后续建议大家照着论文来观看此文,一段一段复制粘贴太麻烦了。
摘要
BERT的全称是Bidirectional Encoder Representations from Transformers,意思是Transformer的双向编码器表示。这篇论文名称的想法来自于一个叫BERT,一个来自于芝麻街的动画人物(这是属于一个叫“芝麻街”系列的NLP论文,其中还包括ELMo模型等,ELMo也是芝麻街一个动画人物的名字)。
伯特(BERT)长期痛苦地忍受着厄尼的取笑,他对人特认真,任何事都可以令他沉迷,他最喜欢收集瓶盖和回形针,还喜欢管弦乐和他的宠物鸽子。总是能原谅厄尼,永远做他的好朋友。
BERT是用来训练一个深的双向表示,使用没有标签的数据,联合左右的上下文信息。因为原作者的设计,我们只需加一个额外的输出层,就可以得到一个不错的结果,对很多NLP的任务都达到了一个不错的效果,并且不需要对任务的架构做一些大的改动(这里主要是讲BERT和ELMo和GPT的区别)。
BERT在概念上是比较简单的,而且在11个NLP任务的实际运用上取得好新的比较好的效果(任务包括有GLUE等)。
这里李沐老师的论文精度课程提到了我们写论文摘要部分时,第一是要用简短的话来区分你和之前同领域相关任务的工作;第二是要写清楚我们任务在相关数据集上的绝对精度和相对精度,给审稿人或读者一个明确的评价指标。
导言
在语言任务中,预训练可以提升很多任务的性能。自然语言任务包括2类:第一个是句子层面的任务,主要用来建模这些句子之间的一个关联;第二个是词元层面的一个任务,包括一些实体命名的识别,最该类任务需要输出一些细粒度的词元层面的输出。
在使用预训练模型做特征表示时,一般有两类策略:第一个是基于特征的(feature-based),第二个是基于微调的(fine-tuning)。基于特征的代表作是ELMo,利用RNN这个结构,对每一个下游任务,构造一个与这个任务相关的神经网络,在预训练好的这些representations中,它作为一个额外的特征,和输入是一起输入进这个模型里面,由于这些特征已经有了好的representations,所以导致你的模型训练起来就比较容易。基于微调的代表作是GPT,这个模型会在你下游的数据上进行一个微调,所有的权重根据你的新的数据器进行一个微调。(BERT是属于一个基于微调的模型),这但这种方法在预训练时,使用一个相同的目标函数,即使用一个单向的语言模型。
这种方法都是有一个局限性:标准的语言模型是一个单向的,比如说GPT的语言模型是从左看到右。但作者认为这个不是很好,比如说我要判断一个句子的情感状态的话,我从左看到右,和我从右看到左都是可行的。所以作者要把两个方向的信息都放进来,用来提升任务的性能。
BERT呢是用来减轻上述单向的一个限制,用到一个叫做“masked language model(MLM)”带掩码的一个语言模型,这个模型是说每一次随机的选取一些词元,然后把它盖住,将目标函数设置为预测那些被盖住的字,等效为完形填空。带掩码的语言模型是允许你看左右的语言信息的,这样我们就可以训练一个深的双向的Transformer模型(ELMo是一个双向的RNN模型,要区分一下)。除了这个语言模型外,它还训练一个叫做“next sentence prediction”,就是说给两个句子,要判断出这两个句子是相邻的还是随机采样的,这样就可以学习句子层面的信息。
相关工作
这块具体还是得看原文,提到了很多的前人所做的工作以及参考文献。
非监督基于特征的工作
该部分介绍了前文提过的ELMo,还有ELMo之前的一些词嵌入等等前人所做的工作。
非监督基于微调的工作
介绍了代表作GPT,还有前人所做的一些工作。
在有标签的数据上做迁移学习
在NLP中有标签的,而且数据量很大的数据集(包括自然语言的推理以及机器翻译)上面进行训练,再将训练好的模型在别的任务上使用。
为什么在NLP这种预训练方法近几年才开始流行?第一是因为这两种任务目的是不同的,差别较大,第二是因为数据量还是不够
事实证明,BERT以及它后续的一些作品,在没有标签,数据量大的数据集上训练的模型,要比在有标签,数据量小的数据集上的模型效果要好。
上一段同样的想法也在计算机视觉相关领域中逐渐使用,即在大量的没有标签的图片上训练出了模型,可能比在ImageNet上训练出的模型效果会更好。
是否这一举措与数据样本量有关?这块值得关注一下,后续大家跑实验可以对比参照。
BERT模型
BERT中有两个步骤,第一个是叫做预训练,第二个叫做微调。预训练是指模型在一个没有标签的数据集上进行训练。在微调时,BERT模型的权重被初始化为预训练中间得到的权重,并且所有的权重,在微调的时候都会参与训练(这个时候用的是有标签的数据),每一个下游任务都会创建一个新的BERT模型,虽然它们都是用最早的那个已经预训练好的BERT模型作为初始化,初始化后,都会根据自己的数据来训练自己的模型。
显然,预训练和微调在计算机领域里运用很多了,但作者还是在这里进行了介绍,这是一个写论文非常好的习惯。当你在写论文时,你觉得应该所有人都知道的知识点,你如果一笔带过,这个不是很好的。
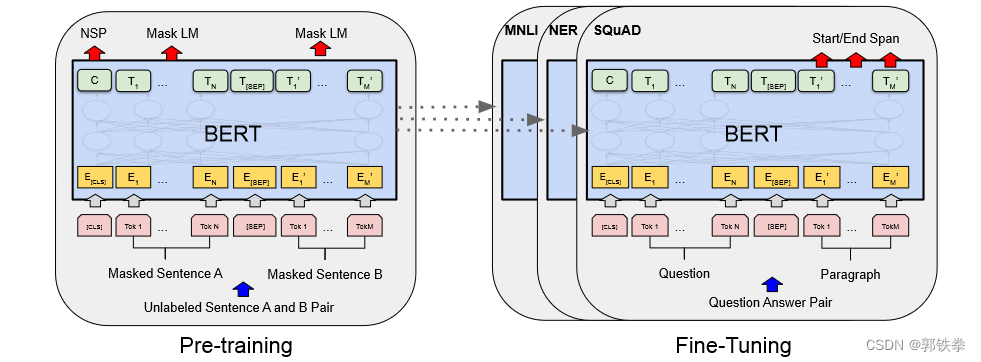
左边是预训练部分,右边是微调部分。预训练的输入是没有标签的句子,并开始训练,训练好每个权重,形成一个BERT模型。对每个下游任务,创建一个同样的BERT模型,初始化值是预训练得到的权重,然后利用自身已有的数据集来对模型进行继续训练,微调。
模型架构
作者概况了一下整体架构,BERT模型就是一个多层的双向的Transformer的编码器,而且它是直接基于原始的论文和它原始的代码,而且没有做什么改动(这里作者就没写,作者假设我们是熟读了Transformer这篇文章了)。
作者在这里调了3个参数,第一个是L,是Transformer层的个数,第二个是隐藏层的大小H,第三个是多头自注意力(Multi-Head Attention)里头的个数A。这里提供了2个模型,一个是BERTbase(L=12,H=768,A=12,总参数=110M),另一个是BERTlarge(L=24,H=1024,A=16,总参数=340M)。BERTbase的参数量是与GPT的参数量大致相同,可以做一个相似的比较,BERTlarge肯定是要去刷榜的。
1024是怎么来的?因为BERT的模型的复杂度,与层数是一个线性关系,与宽度是一个平方的关系,深度的值变为原来的2倍,那宽度的选值,使得增加的平方大概是之前的两倍。增加的个数为12*12*2=288,但要选择2的幂次数,就将增加的数设置为256,即268+256=1024。
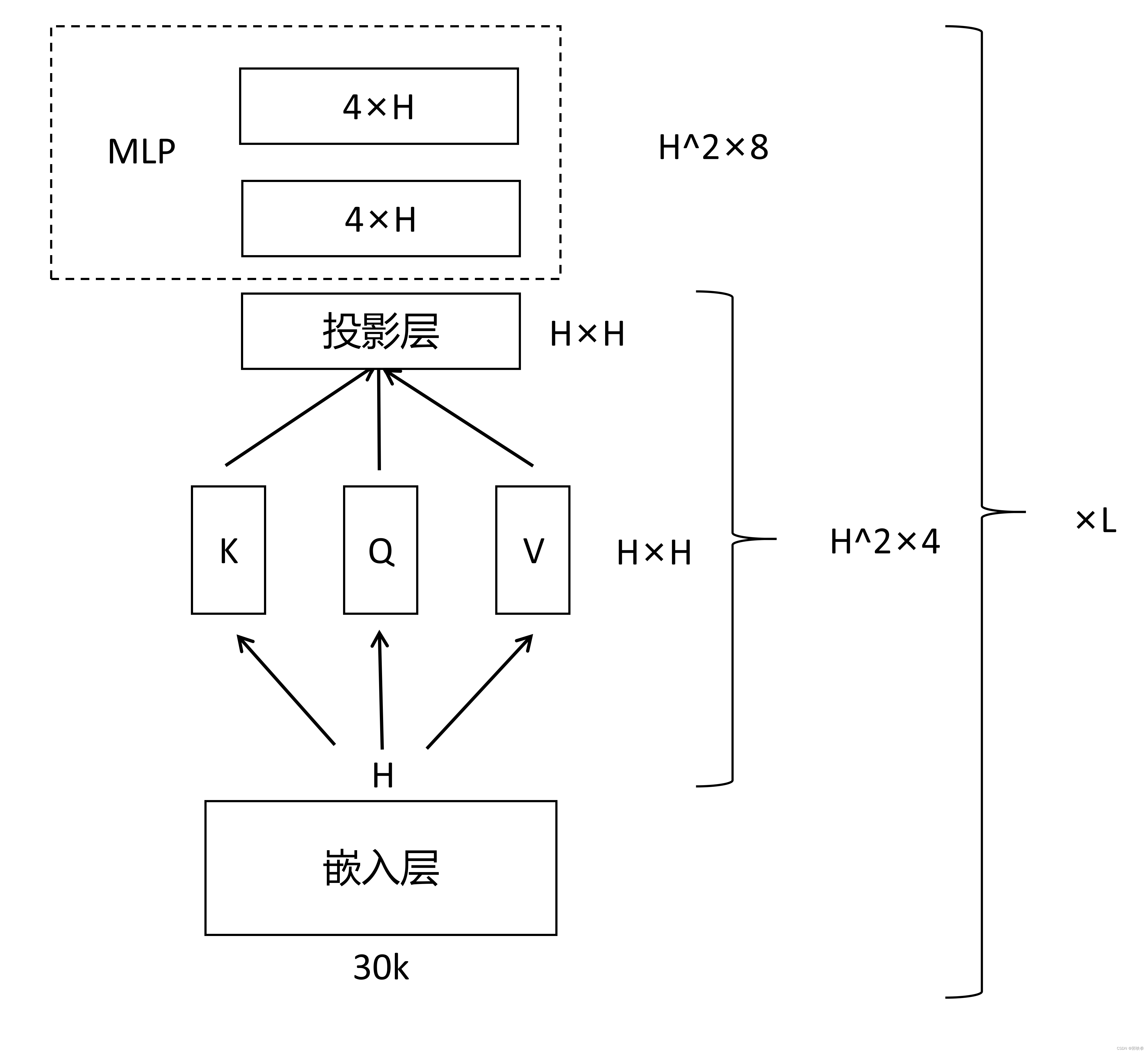
如何把超参数换成和学习参数的大小?(Transformer架构的小回顾)
该模型的科学系参数主要是分为两块,第一块是嵌入层,第二块就是Transformer块。首先看一下嵌入层,嵌入层是一个矩阵,输入是字典的大小(这里是30k),输出就是隐藏单元个数H,然后这个输出作为Transformer块的输入。Transformer块里有2个东西,一个是self-attention机制,另一个是后面的MLP(多层感知机)。Self-attention本身是没有可学习参数的,但是对于多头注意力的话,它会把你所有输入进去的K(key),V(value),Q(query)分别做一次投影,每一次投影它的维度都是等于64的(头的个数A乘以64是等于H的),每次投影都有一个投影矩阵,在每个头之间把他们合并起来就是一个
的矩阵。然后将这一部分的输出再做一次投影,这个投影矩阵仍然是一个
。再往后就是MLP,MLP需要2个全连接层,第一个层的输入是H,但输出是一个
的东西,第二个层输入是
,总的加起来的话就是
。因为最后还有L层,最后总的还要乘以L。所以总参数的个数就是
。
具体参数的计算
输入和输出
上面讲过,下游任务要处理的是一个句子,或者是两个句子,为了BERT模型能够处理所有任务的话,它的输入既可以是一个句子,一个也是一个句子对。具体来说,一个句子的意思是一段连续的文字,不一定是真正语义上的一段句子。它说我的输入叫做一个序列,所谓序列就是可以是一个句子,也可以是两个句子,这里与我们之前讲的Transformer有点不一样,Transformer训练的时候,它的输入是一个序列对,因为它的编码器和解码器会分别输入一个序列,但是BERT模型里只有一个编码器,所以为了能够处理两个句子,就要将两个句子变成一个序列。
序列的构成
在这块内容中,用的切词方法是WordPiece,其核心思想是说,假设按照空格切词的话,一个词作为一个token,因为我的数据量相对来说是比较大的,会导致词典大小特别大,根据之前算模型参数的方法,如果是百万级别的字典大小的话,会导致可学习参数都在嵌入层中。WordPiece的想法是说,如果一个词,在我句子中出现的概率不大的话,那我就应该把它切开,看它的一个子序列,如果这个子序列,可能是一个词根,出现了概率比较大的话,那就只需要保存这个子序列就可以了,我们就可以把一个相对来说比较长的词,切成一段一段经常出现的片段,这样的话,就可以用一个比较小的,30k的一个词典,表示一个比较大的文本。
切好词后,再看如何把句子放到一起,这里分为2点,第一是作者将序列的第一个词设置成一个特殊的记号[CLS](代表的是classification),这个词的作用是说,BERT想把它最后的输出,代表是整个序列的一个信息,比如说是对整个句子层面的一个信息(由于使用的是Transformer编码器,每一个词都会去看与所有输入里面的词的关系),就算这个词放在第一个的位置,也是可以看到所有的字的。
第二个是BERT将两个句子合在一起,但是因为我要做句子层面的分类,所以我们要区分开来这两个句子,这里有两个办法来区分:第一个方法在每个句子后面放一个特殊的词[SEP](代表separate);第二个方法是让模型去学一个嵌入层,让它去表示时第一个句子还是第二个句子。这里在下面的图有所表示:每一句句首有一个[CLS],每一句句末有一个[SEP],每一个token进入BERT都会得到这个token的embedding表示。
最后一段说每个词元进入BERT的向量表示,它是这个词元本身的embedding再加上它在哪一个句子里的embedding,再加上它在句子中位置的embedding。在下面的图里有所展示:
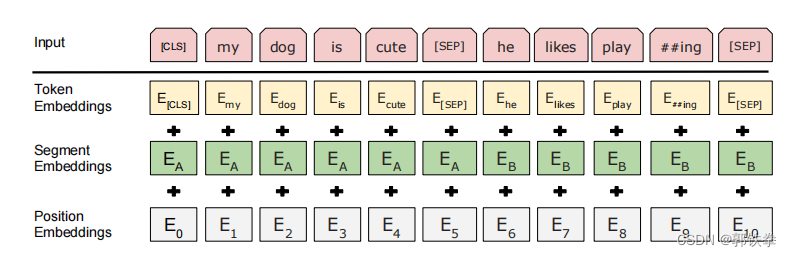
上图演示的是BERT嵌入层的做法,给一个词元的序列,输出一个向量的序列。第一个是一个正常的embedding层Token Embedding,对每一个词元,会输出一个对应的向量;第二个是Segement Embedding层,它表示时第一句话还是第二句话,是a还是b,它的输入长度是2;第三个是Position Embedding层,它表示词元的位置,它的输入长度是序列最长的长度,输入是每个词元的位置信息。最后就是词元本身的嵌入加上其他2个嵌入层上的信息(这里要相比较于Transformer,Transformer中的位置embedding是用函数构造的一个矩阵,而BERT中的第二个和第三个嵌入层都是学习得来的)。
BERT预训练
Task1:掩码的语言模型
对输入的词元序列,如果一个词元是由WordPiece生成的话,它就有15%的概率被替换成一个掩码,但是对于特殊的词元,比如上文讲到的[CLS]和[SEP],就不做替换了。这其实也有一个问题,当我们在做掩码的时候,就会把一个词元替换成一个特殊的token,叫做[MASK],但在微调的时候,是没有[MASK]这个东西的,因为不用这个目标函数,这就会导致在预训练和微调的时候,看到的数据会有一点点不一样。这一问题的解决方法是:在这些15%被选中做掩码的词,其中有80%的概率是真的把它替换成了[MASK],还有10%的概率我把它替换成一个随机的词元,还有10%的概率,放着不动啥也不干,就保存下来做预测。具体概率的选取,是跑了一个叫做ablation study实验,它在附录里讲了几个例子。
Task2:预测下一个句子
在Q&A和自然语言推理里面,他们输入都是一个句子对,若果能让它学一些句子层面的信息也是不错的。具体来说,一个输入序列有两个句子,有一个A有一个B,有50%的概率,B在原文中的位置真的是在A之后,还有50%的概率不是,B就是随机选取的一个句子,也就是说50%的样本是正例,50%的是负例。这同样在附录里有所体现。
训练的数据
第一个数据集是:由8亿个词的一本书构成的数据集;第二个数据集是由25亿个词的Wikipedia英文的数据集。我们应该用文本层面的数据集,就是说是一篇一篇的文章,而不是随机打乱的句子,因为Transformer能看见序列全部信息,所以给一个文本层面的句子会好一些。
BERT微调
它首先讲了一下BERT和基于编码器解码器的架构有什么不同,Transformer是编码器解码器。因为我们把句子对,都放进去了,所以self-attention能够在两端之间互相看,但是在编码器解码器结构里,编码器一般是看不到解码器的内容的,所以BERT更好一点,但也为此付出了代价,不能像Transformer一样做机器翻译了。
在做下游任务的时候,通常会根据我们的任务设计与任务相关的输入和输出,所以好处是说,我的模型其实可以不怎么变,主要是如何将输入改成我想要的那一个句子对,如果是有两个句子的话,那输入就是句子A和句子B了,但如果只有一个句子的话,比如说我要做一个句子的分类的话,那就只有句子A没有句子B了,那就根据下游任务的要求,要么是拿到第一个词元[CLS]对应的输出做分类,或者是拿到对应那些词元的那些输出,做你要的那些输出。无论如何,都是在最后加一个输出层,然后用一个softmax得到我要的那些标号。
实验
GLUE
GLUE是一个句子层面的任务,所以BERT就是把第一个词元[CLS]词元,它最后的那个向量拿出来,然后学习一个输出层W,然后再用一个softmax得到你的标号,之后就是一个正常的多分类问题。
SQuAD
这是斯坦福的一个Q&A数据集,在这种类型的任务里,就是说我给你一段话,然后问你一个问题,需要你把答案找出来,答案就在我给你的那一段话里,你只需要把答案对应的一个小的片段找出来就行了。这样的话,就是判断某个词元是不是答案的开头,是不是答案的结尾。
具体就是学两个向量和
,分别表示这个答案开始和最后的概率。具体来说它对每一个词元,也就是第二句话(A:答案)的每个词元与
和
相乘,就会得到这个段里每一个词元它是答案开始还是结束的概率,具体计算公式为:
,其中
表示每个词元。
SWAG
这是一个用来判断两个句子之间关系的数据集,与上述任务没有太多区别。
Ablation Studies
这一块主要讲的是,既然BERT设计出了这么多东西,这块内容就是具体看一下每一块的贡献度。
首先假设去掉那一个下一个句子的预测,或者说,我是用了一个从左到右的语言模型,而不是使用“完形填空”的带掩码的语言模型。从结果上来看,去掉任何一个块,结果都会大打折扣。
模型大小
这里就阐述了模型的参数数量,这也是第一个在NLP领域里来讲,阐述了模型很大时,对语言模型有很大的提升。
不用微调,把BERT提取的特征作为一个静态特征输入进去会怎么样
结论是效果没有微调那么好,用BERT的话,你应该用微调。
结论
论文主要的工序就是把前人的结果拓展到深的双向的架构中,使得同样的一个预训练模型能够处理大量的不一样的自然语言的任务。作者是把ELMo双向的想法和GPT使用Transformer的东西合起来,就构成了BERT。即将预测未来,变成了完形填空。

