
- 1Explain 关键字_explain关键字
- 2顺序表中的基本操作(详细代码图解+注释+算法步骤)_顺序表的基本操作代码
- 3meterpreter使用详解_meterpreter gettid
- 4单片机和嵌入式的异同_与单片机相比嵌入式的相同点
- 5万字长文解读最新最全的大数据技术体系图谱!
- 6访问网站显示不安全是什么原因?怎么解决?_为什么访问一个网站会显示不是安全链接
- 7Springboot计算机毕业设计基于标签电影推荐微信小程序【附源码】开题+论文+mysql+程序+部署_基于springboot影视分享
- 8NLP自然语言处理中oov的词的解释_nlp oov
- 9芯片设计围炉札记
- 10李善友《第一性原理》读后感-总结_第一性原理心得体会
PG数据库入门知识
赞
踩
前言
Linux和windows的路劲分隔符是不同的,Linux下是斜杠/,而windows是反斜杠(\)。但在PG里window下也要使用linux的/作为路劲分隔符。
基础知识
为什么选择PG
PostgreSQL是一款企业级关系型数据库管理系统。PostgreSQL之所以如此特别,是因为它不仅仅是一个数据库,还是一个功能强大的应用开发平台。
PostgreSQL在数据类型的支持方面有两个优势,不但支持比绝大多数数据库更丰富的原生数据类型,而且还允许用户按需求自定义数据类型。
PostGRESQL同样还允许用户重定义基础运算符。
PostgreSQL会为每一张用户表自动创建一个数据类型的定义。你比如说我创建一个名为dogs的表,那么PosrgreSQL就会自动在后台创建一个同名的dogs数据类型,这一特性将关系型数据库领域的表的概念与面向对象领域的对象概念紧密的联系到了一起,用户可以像处理对象实例一样去处理记录。比如你可以创建一个函数来每次处理一个或者一批对象实例。
不适用PG的场景
- 在不安装任何扩展包的情况下,PG需要占用100MB以上的磁盘空间,可以看出它的个头是比较大的,因此在一些存储空间极为有限的小型设备上使用PG是不合适的。因此在一些存储空间极为有限的小型设备上使用PG是不合适的,把PG当成简单的缓存区来用也是不合适的,此时应选用一些更轻量级的数据库。
- 因为作为一款企业级数据库产品,PG对其安全也是极其重视的,因此,如果你在开发一个把安全管理放到应用层去做的轻量级应用,那么PG完善的安全机制反倒会成为负担,因为它的角色和权限管理非常复杂,会带来不必要的管理复杂度和性能损耗。
鉴于上面的种种,PG数据库一般是会和别的数据库搭配使用,使他们各展所长。一种常见的组合是把Redis当成PG的查询缓存来用,另一种的组合是用PG做主数据库。
PG数据库对象
database
每个PG服务可以包含多个独立的database
schema
如果把databases比作一个国家,那么schema就是一些独立的省。大多数对象是隶属于某个schema的,然后schema又隶属于某个databases。在创建一个新的database时,PG会自动为其创建一个名为public的schema。如果未设置searc_path变量,那么PG会将你创建的所有对象默认放入public schema中。如果表的数量较少,这是没问题的,但是如果你有几千张表,那么我们还是建议你将他们分门别类放入不同的schema中。
表
任何一个数据库中,表都是最核心的对象类型。在PG中,表首先属于某个schema,而schema有属于某个database,这样就构成一种三级存储结构。PG的表支持两种很强大的功能。第一种是继承,即一张表可以有父表和子表,这种层次化的结构可以极大的简化数据库设计,还可以为你省掉大量的重复查询代码。第二种是创建一张表的同时,系统会自动为此表创建一种对应的自定义数据类型。
PG数据库管理
配置文件
配置文件在data目录下
postgresql.conf
在9.4的版本里引入了一个新的名为postgresql.auto.conf的配置文件,其中配置项会覆盖postgresql.conf的同名配置项。所以建议不要修改postgresql.conf,而是优先修改postgresql.auto.conf
该文件中包含一些通用的设置,比如内存分配 ,新建database的默认存储位置,postgresql服务器的ip地址,日志以及许多其他设置。
- 查看postgresql.conf视图即可查看所有配置项内容,无需打开配置文件。
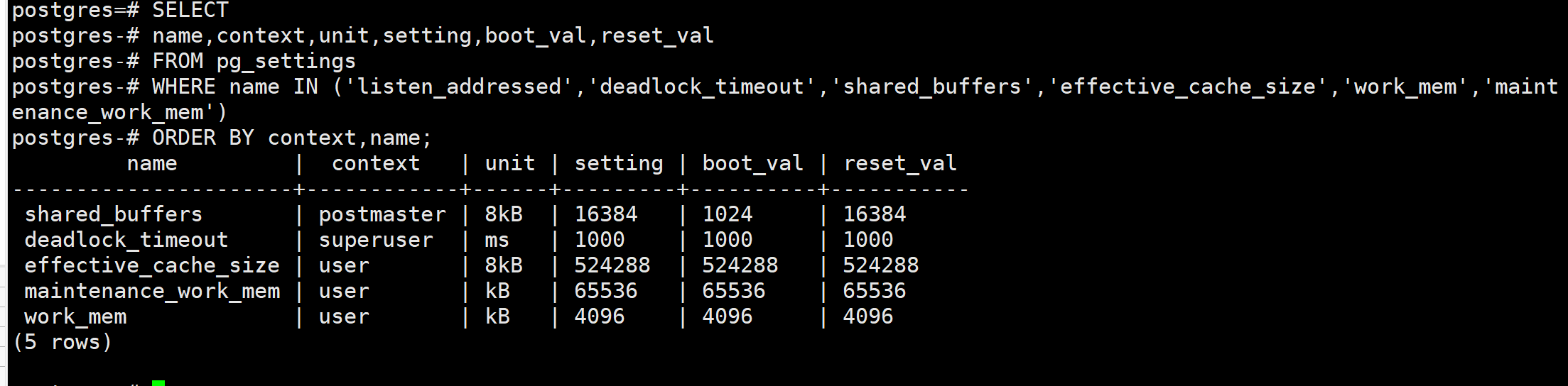
SELECT
name,context,unit,setting,boot_val,reset_val
FROM pg_settings
WHERE name IN ('listen_addressed','deadlock_timeout','shared_buffers','effective_cache_size','work_mem','maintenance_work_mem')
ORDER BY context,name;
- 1
- 2
- 3
- 4
- 5
-
context字段代表配置项的作用范围。
user表示用户级配置项,他可以被每个用户单独修改,也就是说该配置项针对每个用户都可以有不同的值,用户修改后会在自己的所有会话中生效。如果是超级用户修改了一个user级的配置项,那么此后链接上的用户都会将这个修改过的值作为默认值。
context值为superuser表示是超级用户级配置项,只能由超级用户修改,修改并且重新加载后会在所有用户会话中生效。非超级用户不能在自己的会话中修改覆盖这个值。
context值为postmaster表示是整个服务实例级配置项,更改后需要重启postgresSQL服务才能生效。
context为usr和superuser的配置项可以在database级,用户级,会话级和函数级分别设置。比如说如果会写很长sql的用户来说,work_mem参数应该设置大一些;再比如有密集的排序操作,也就可以调大work_mem的值。database级,用户级,会话级和函数级的参数设置不需要执行重新加载操作。数据库级的参数设置会在用户下次连接到该数据库时生效。会话级和函数级的参数设置立即生效。
-
我们要注意内存相关参数所用的单位。在上图我们可以看到,内存相关参数,有些是8KB有些是KB
-
setting是指当前设置;boot_val是指默认设置;reset_val是指重新启动服务器或重新加载设置之后的新设置。修改 了设置后,一定要去查看setting和reset_val并确保二者是一致的,否则就说明设置并未生效,需要重启服务器或者重新加载设置。
- pg的9.5版本引入了一个新的pg_file_settings视图,通过该视图也可以进行配置信息查询。查询该视图会列出每个配置项所属的配置文件。其中applied字段表示该配置项是否已经生效,如果值为f,表示需要重启服务器或者重新加载配置文件。如果postgresql.conf和postgresql.auto.conf中存在同名配置,那么后者会覆盖前者,并且前者在pg_file_settings中对应的条目会显示applied字段为f。
SELECT name,sourcefile,sourceline,setting,applied
FROM pg_file_settings
WHERE name IN ('listen_addresses','deadlock_timeout','shared_buffers','effective_cache_size','work_mem','maintenance_work_mem')
ORDER BY name;
- 1
- 2
- 3
- 4
以下几个配置项需要注意,不然可能导致客户端无法连接:
- listen_addresses
表示postgresql服务使用的ip地址,我这里设置的*,表示使用任意的ip均可连接到POSTgresql数据库。
- port
pg库的侦听端口,默认值为5432.
- max_connections
系统允许的最大并发连接数
- log_destination
定义日志文件的输出格式,默认值是stderr。如果是要记日志的话切记要讲logging_collection配置项设为on。
下面介绍的这些配置项会影响系统的整体性能,其默认值一般不是最优的。建议根据实际情况进行调整。
- shared_buffers
此设置定义了用于缓存最近访问过的数据页的内存区大小,所有用户会话均可共享此缓存区。此设置对查询速度有着重大影响,一般来说设置的越大越好,至少应该达到系统的总内存的25% ,但不适宜超过8GB,因为超过会出现边际收益递减效应,即消耗的内存很多,但得到的速度提升却很少,这是得不偿失的,意义不大的。
- effective_cache_size
该配置是一个估算值,表示操作系统分配多少内存给PG专用。系统并不会根据这个值来真实地分配这么多内存,但是规划器会根据这个值来判断系统是否能提供查询执行过程所需的内存。如果将此值设置的过小,远远小于系统的真实可用内存量,那么可能会给规划器造成误导,让规划器认为系统可用内存有限,从而选择不使用索引而是执行全表扫描(因为使用索引虽然速度快,但需要占用更多的中间内存)。在一台专用于 运行pgsql数据库服务的机器上,建议是将effective_cache_size的值设为系统总内存的一般或者更多。
- work_mem
此设置指定了用于执行排序,散列关联,表扫描等操作的最大内存大小。要得到此设置的最优值需要考虑以下因素:数据库的使用方式,需要预留多少内存给除数据库系统外的程序,以及服务器是否专用于pgsql服务等问题。如果使用场景仅仅是有很多用户并发执行简单查询,那么这个值可以设得小一点,这样每个用户都得以较为公平的使用内存,否则第一个用户就可能会把内存占光。这个值该设多大同样取决于你的机器总共有多少内存可用
- maintenance_work_mem
此设置指定了可用于vaccum(即清空已标记为“被删除”状态的记录)这类系统内部维护操作的内存总量。其值不应大于1GB,此设置的更改可动态生效,执行重新加载既可。
- max_parallel_workers_per_gather
这是9.6版本新引入的一个配置项,用于控制语句执行的并行度。该配置项决定了执行计划的每个gather节点中最多允许启动多少个worker进程并行工作。默认值为0,表示不启用并行功能。
- 修改postgresql.conf中配置项的值
ALTER SYSTEM
- 1
这是9.4版本之后引入的一个命令,这个命令可以更改设置。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

