
- 1我用numpy实现了VIT,手写vision transformer, 可在树莓派上运行,在hugging face上训练模型保存参数成numpy格式,纯numpy实现...
- 2实验报告-安装Modelsim10.5版本并跑通一个工程!
- 3el-tree 父子不关联,勾选父节点全选子节点,子节点仅勾选自己_el-tree 不传父级过去可以全选
- 4图文轻松弄懂一二维的前缀和与差分_二维前缀和差分
- 5头歌Educoder——大数据Hadoop开发环境搭建_本关任务:配置javajdk。
- 6Apache PDFBox 是一个开源 Java 库,支持 PDF 文档的开发和转换
- 7探讨CSDN等级制度:博客等级、原力等级、创作者等级_csdn博客等级
- 8CSS外边距和并(塌陷)及多种解决方法_外边距合并
- 9stm32f103rct6引脚功能表格
- 10ab测试算法的基本概念_ab测算法
深入理解Polygon zkEVM (一)
赞
踩
Polygon zkEVM系列文章的第一篇,简要的阐述了polygon zkEVM的的整体架构和交易执行流程,并且分析了polygon zkEVM是如何实现计算扩容的同时继承以太坊的安全性的。
同时还会在接下来两篇文章会详细介绍Polygon zkEVM的zkEVM Bridge和zkEVM的设计细节,以及polygon zkEVM接下来的去中心化sequencer的路线图。
目录
-
Rollup 是为了给以太坊实现计算扩容
-
不同 Rollup 路线之间的区别
-
-
Polygon zkEVM 的具体执行流程 & 整体架构
-
从模块化区块链的角度解析 Polygon zkEVM
-
Polygon zkEVM 如何继承L1的安全性
-
Polygon zkEVM 激励机制
1.Rollup为了给以太坊实现计算扩容
首先,我们需要明确rollup的大概工作原理:
rollup的出现的是为了给Ethereum实现计算扩容,具体的实现方法是将交易的执行外包给 Rollup,然后将交易和交易执行后的状态(state)存储在 Ethereum 的合约内。
由于技术路线的不同演变出了两种类型的 Rollup:
-
Optimistic Rollup:
-
乐观的认为发送到 Ethereum 的 Rollup 交易(Rollup transaction)和对应的 Rollup 状态(Rollup State )都是正确的,任何人都可以通过提供欺诈证明(fraud proof)对还处于挑战期的Rollup State进行挑战(challenge)
-
Zero-knowledge Rollup:
-
会为发送到 Ethereum 的 Rollup交易(Rollup Transaction)和对应的 Rollup 状态(Rollup state)提供一个有效性证明(validity proof)(由以太坊上的合约验证,来证明 Rollup 的执行对应交易后的状态时正确的)
-
(参考以太坊官方定义) Scaling | ethereum.org
Zero-knowledge Rollup 和 Optimistic Rollup 最大的区别就是由于验证状态有效性的不同方式导致达成 finality 的时间不同;
Optimistic Rollup 乐观的认为提交到 Ethereum 上的交易和状态都是正确的,所以存在7天的挑战期(达成finality的时间是7天),期间任何人发现在 Ethereum 上的交易对应状态不正确都可以通过提交正确的状态进行挑战。
Zero-knowledge Rollup( zk-Rollup ) 达成 finality 的时间,则取决于: 交易对应的有效性证明( validity proof )提交到以太坊并且验证通过所花费的时间。目前可能在1个小时左右的finality居多。(因为需要考虑到Gas成本问题)
2.Polygon zkEVM 执行流程
接下里我们以一个简单的交易被确认流程来看看 Polygon zkEVM是怎么工作的,从而对整体协议有一个具体的理解;
整个过程可以主要分为三个步骤:
-
Optimistic Rollup:
-
乐观的认为发送到 Ethereum 的 Rollup 交易(Rollup transaction)和对应的 Rollup 状态(Rollup State )都是正确的,任何人都可以通过提供欺诈证明(fraud proof)对还处于挑战期的Rollup State进行挑战(challenge)
-
Zero-knowledge Rollup:
-
会为发送到 Ethereum 的 Rollup交易(Rollup Transaction)和对应的 Rollup 状态(Rollup state)提供一个有效性证明(validity proof)(由以太坊上的合约验证,来证明 Rollup 的执行对应交易后的状态时正确的)
-
(参考以太坊官方定义) Scaling | ethereum.org
Zero-knowledge Rollup 和 Optimistic Rollup 最大的区别就是由于验证状态有效性的不同方式导致达成 finality 的时间不同;
Optimistic Rollup 乐观的认为提交到 Ethereum 上的交易和状态都是正确的,所以存在7天的挑战期(达成finality的时间是7天),期间任何人发现在 Ethereum 上的交易对应状态不正确都可以通过提交正确的状态进行挑战。
Zero-knowledge Rollup( zk-Rollup ) 达成 finality 的时间,则取决于: 交易对应的有效性证明( validity proof )提交到以太坊并且验证通过所花费的时间。目前可能在1个小时左右的finality居多。(因为需要考虑到Gas成本问题)
2.Polygon zkEVM 执行流程
接下里我们以一个简单的交易被确认流程来看看 Polygon zkEVM是怎么工作的,从而对整体协议有一个具体的理解;
整个过程可以主要分为三个步骤:
-
Optimistic Rollup:
-
乐观的认为发送到 Ethereum 的 Rollup 交易(Rollup transaction)和对应的 Rollup 状态(Rollup State )都是正确的,任何人都可以通过提供欺诈证明(fraud proof)对还处于挑战期的Rollup State进行挑战(challenge)
-
Zero-knowledge Rollup:
-
会为发送到 Ethereum 的 Rollup交易(Rollup Transaction)和对应的 Rollup 状态(Rollup state)提供一个有效性证明(validity proof)(由以太坊上的合约验证,来证明 Rollup 的执行对应交易后的状态时正确的)
-
(参考以太坊官方定义) Scaling | ethereum.org
Zero-knowledge Rollup 和 Optimistic Rollup 最大的区别就是由于验证状态有效性的不同方式导致达成 finality 的时间不同;
Optimistic Rollup 乐观的认为提交到 Ethereum 上的交易和状态都是正确的,所以存在7天的挑战期(达成finality的时间是7天),期间任何人发现在 Ethereum 上的交易对应状态不正确都可以通过提交正确的状态进行挑战。
Zero-knowledge Rollup( zk-Rollup ) 达成 finality 的时间,则取决于: 交易对应的有效性证明( validity proof )提交到以太坊并且验证通过所花费的时间。目前可能在1个小时左右的finality居多。(因为需要考虑到Gas成本问题)
2.Polygon zkEVM 执行流程
接下里我们以一个简单的交易被确认流程来看看 Polygon zkEVM是怎么工作的,从而对整体协议有一个具体的理解;
整个过程可以主要分为三个步骤:
-
Sequencer 将多个用户交易打包成 Batch 提交到L1的合约上。
-
Prover 为每笔交易生成有效性证明(validity proof),并将多个交易的有效性证明聚合成一个有效性证明。
-
Aggregator 提交聚合了多个交易的有效性证明(validity proof) 到 L1 的合约中。
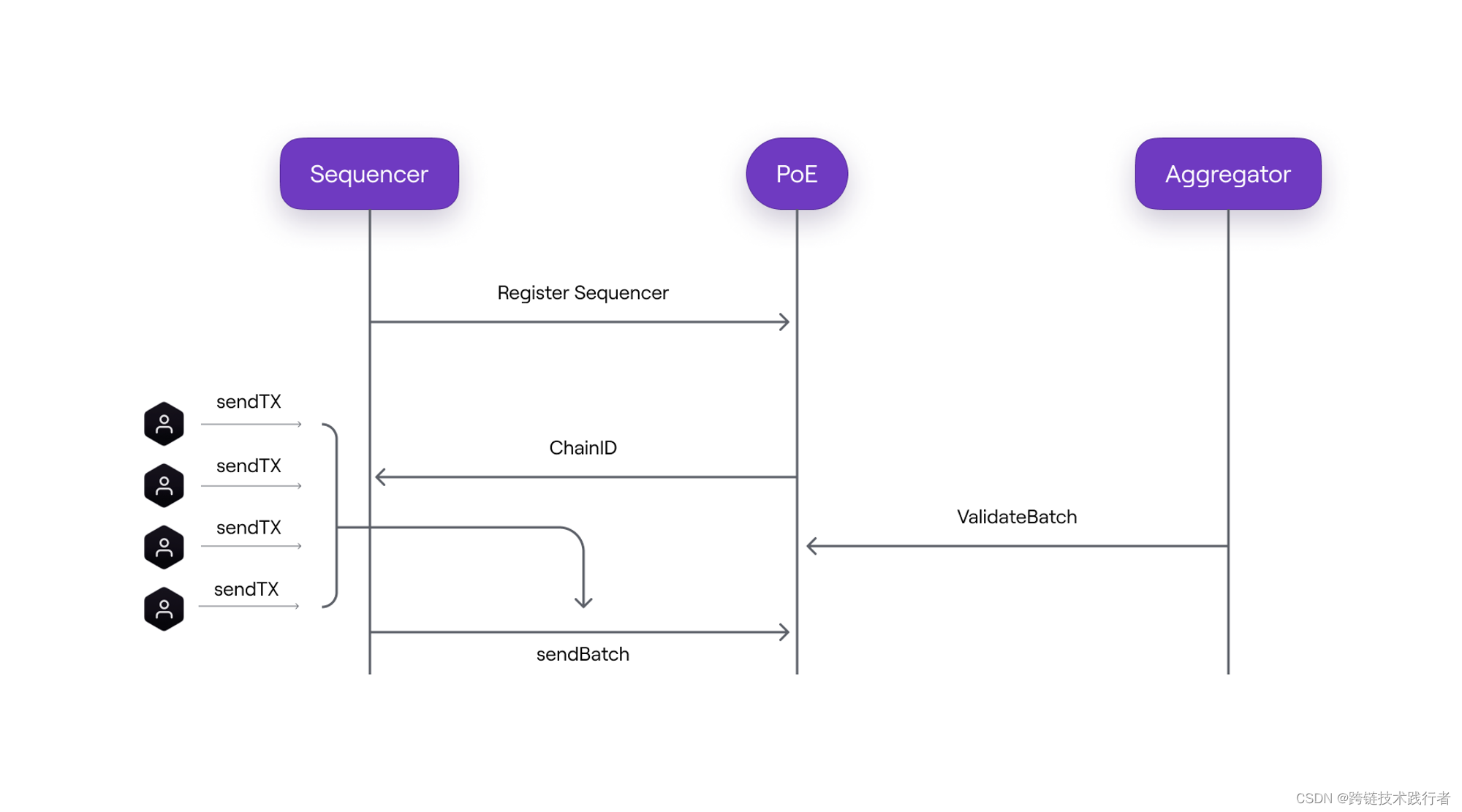
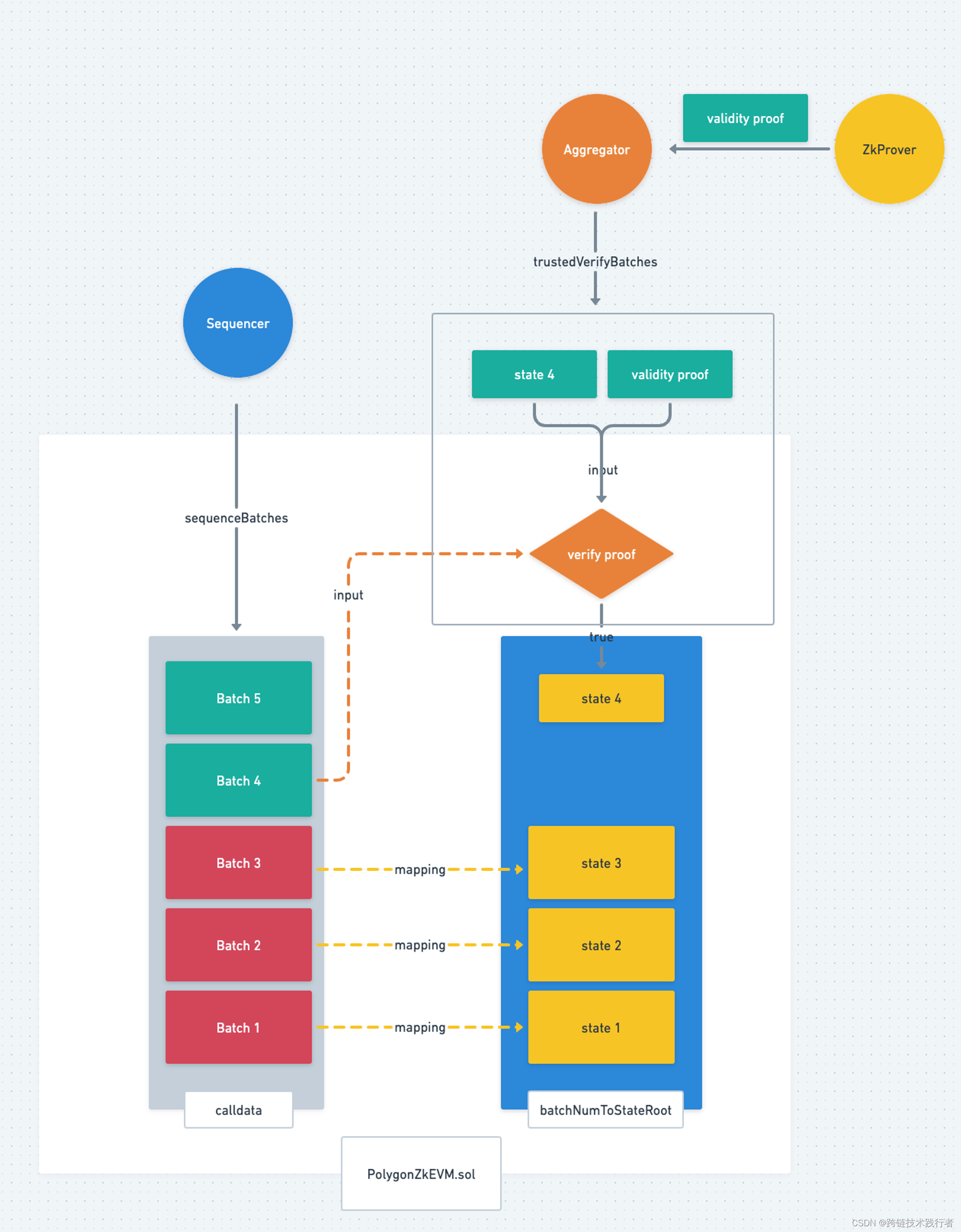
1) Sequencer 将用户交易打包成 Batch 提交到 L1 合约上
-
用户将交易发送给Sequencer, Sequencer会在本地按照收到交易的快慢顺序进行处理(FRFS),当Sequencer在本地将交易执行成功后,如果用户相信Sequencer是诚实的,那么他可以认为这个时候的交易已经达成了finality。
-
这里需要注意,目前大多数Sequencer内部的Mempool(交易池)都是私有的,所以暂时可以获取的MEV是比较少的
-
-
Sequencer 会将多笔交易打包进一个Batch里(目前是一个Batch里只包含一个交易) , 然后在收集到多个Batches之后, 通过L1上的
PolygonZKEvm.sol的sequenceBatch()函数将多个Batch一起送到L1的交易calldata上。function sequenceBatches(
BatchData[] memory batches
) public ifNotEmergencyState onlyTrustedSequencer
需要注意这里一次性提交多个Batch是为了尽可能减少L1的gas消耗
-
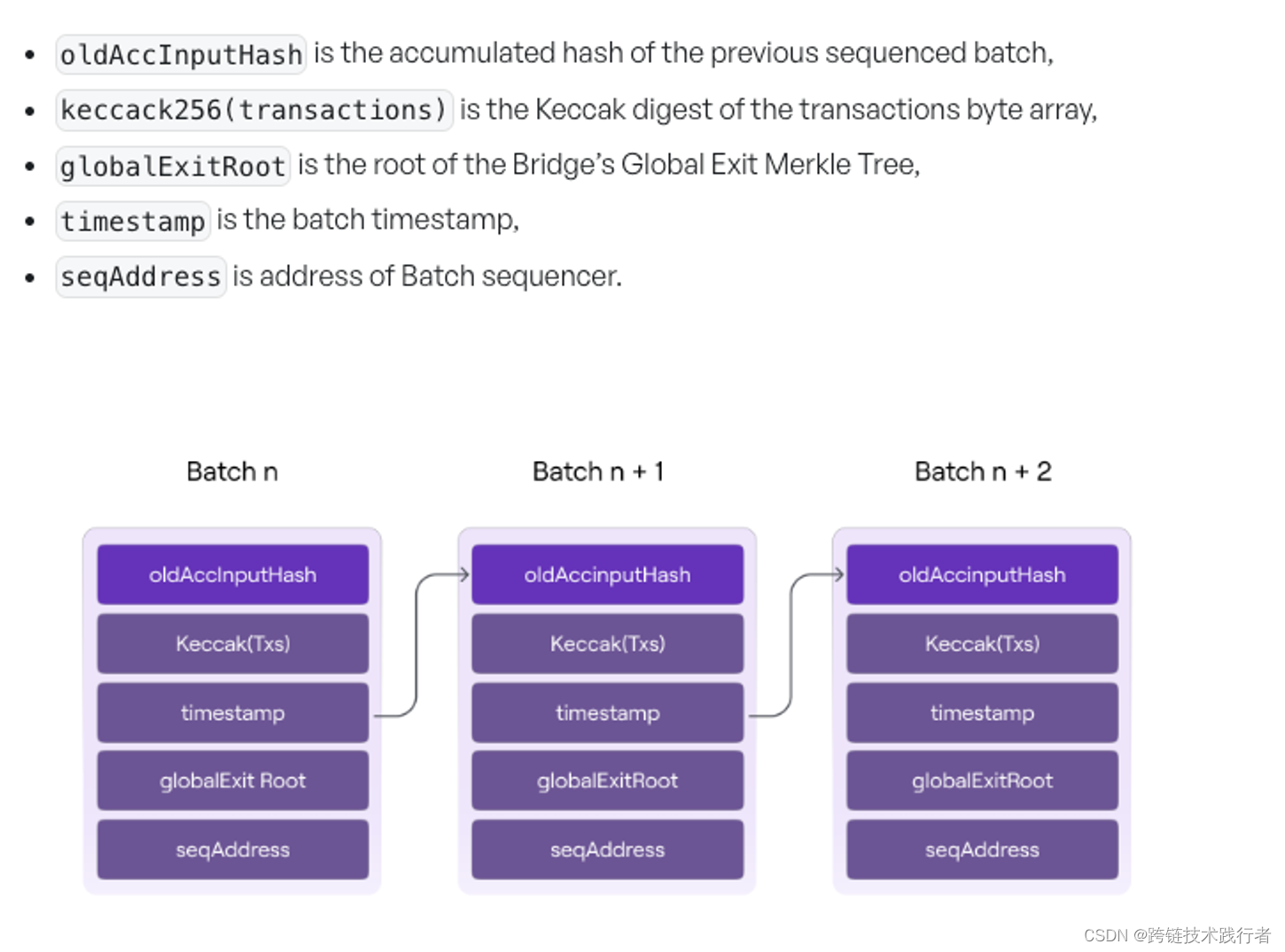
当
PolygonZkEvm.sol收到 Sequencer 提供的 Batches 后,它会依次在合约内计算每个Batch的哈希,然后在后一个Batch里记录前一个Batch的哈希,于是我们就得到了下图的Batch结构
-
每个Batch里的交易顺序也是确定的,所以当Batch的顺序确定之后,我们认为所有被包含在Batch提交到L1的 polygonZkEVM合约的交易的顺序都被确定了。
以上实际上过程也是L1充当Rollup DA层需要完成的工作(这个时候并没有完成任何状态检验或推进的工作)。
2) Aggregator 为多个Batch的交易生成 validity Proof
-
当Aggregator监听到L1的
PolyonZKEVM.sol合约中已经有新的 Batch 被成功的提交之后,它会把这些 Batch 同步到自己的节点里,然后给 zkProver 发送这些交易. -
zkProver 接收到这些交易之后会并行为每笔交易生成 validity proof,再将多个Batch包含的交易的 validity proof再聚合成一个有效性证明(validity proof).
-
zkProver 将聚合多个交易的validity proof发送给 Aggregator
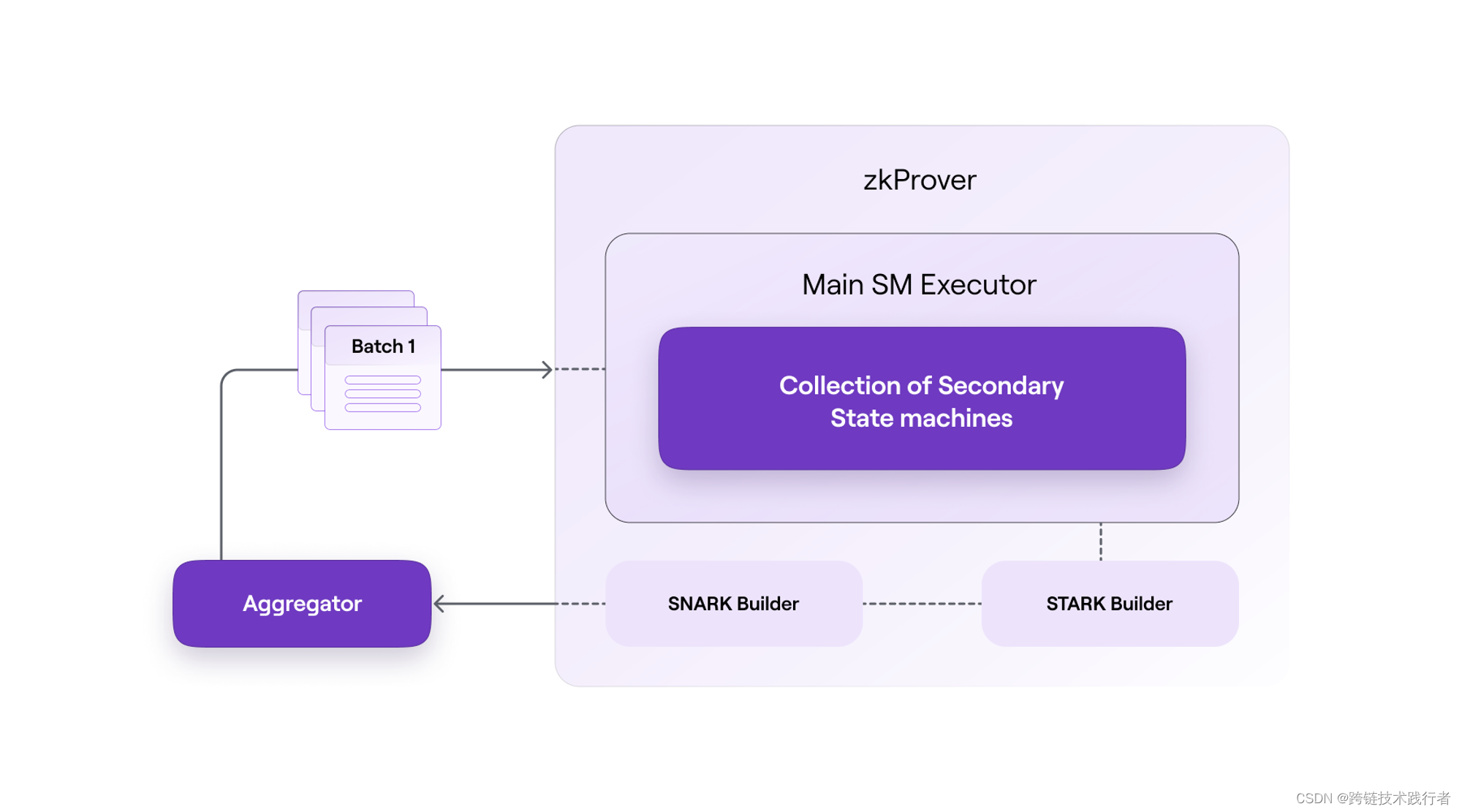
3) Aggregator 提交聚合证明到 L1 的合约
-
Aggregator 会将这个有效性证明(validity proof)以及对应的这些 Batch 执行后的状态一起提交到 L1 的
polygonZkEvm.sol合约内(通过调用以下方法)
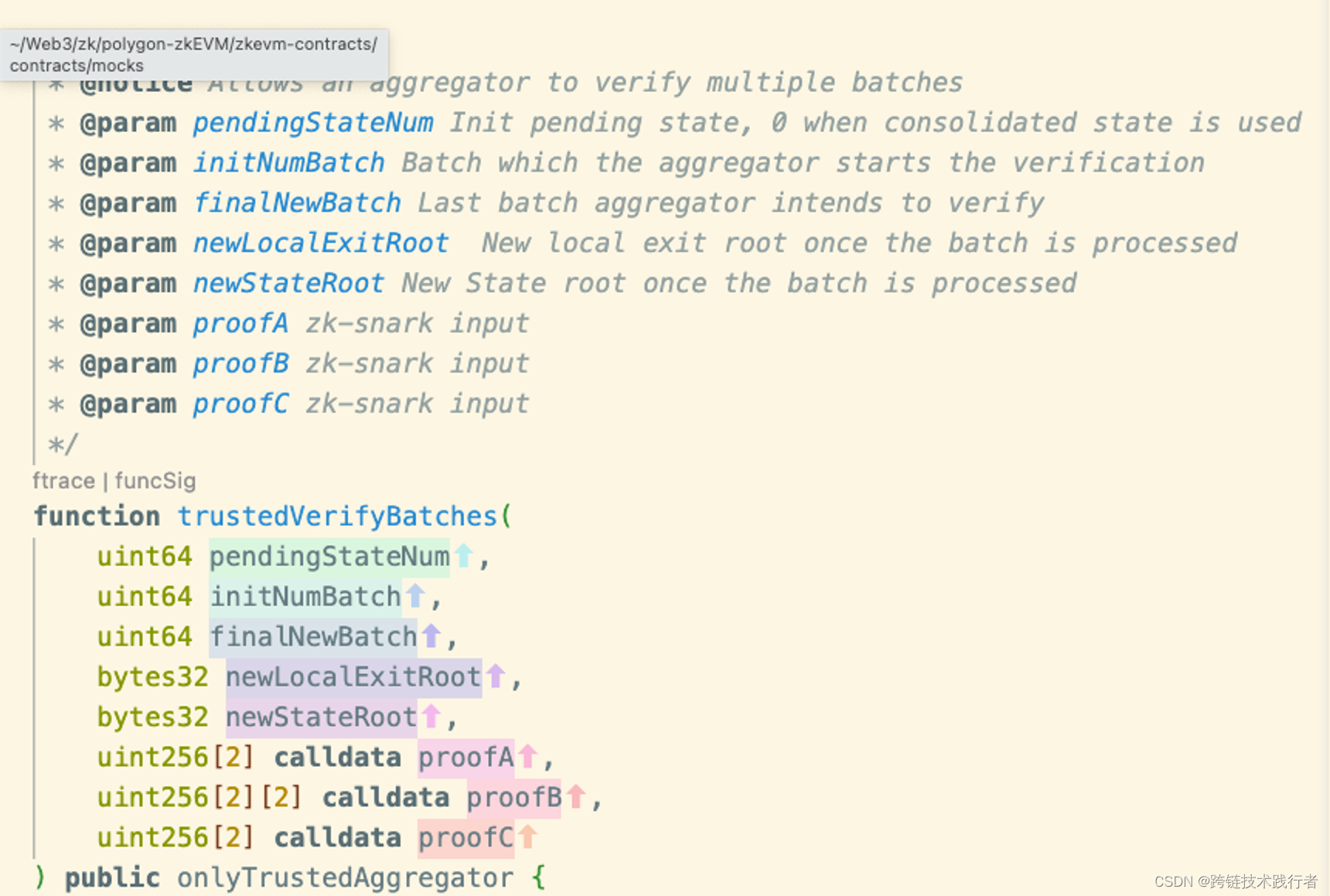
合约内接下来会执行以下操作来验证状态转换是否正确:
-
从合约内拿到最后一个被验证过的Batch的BatchIndex :
currentLastVerifiedBatch(理想情况下initNumBatch==currentLastVerifiedBatch) -
根据 BatchIndex 拿到合约内最新的状态 oldStateRoot
-
oldStateRoot = batchNumToStateRoot[initNumBatch];
-
合约内有这样一这个mapping: batchNumToStateRoot 维护一个batchIndex映射到该batch执行结束后对应的状态
-
-
然后传入validity proof对应(
[proofA,proofB,proofC]) ,这个validity proof要验证的batches的范围和这部分batch执行前的状态和执行后的状态;-
其中执行前的状态必须选定为合约内已有的经过验证的状态
-
-
将合约内的 MATIC 转帐给提交正确 validity proof 的 Aggregator
-
更新 batchNumToStateRoot 这个mapping, 和 lastVerifiedBatch
-
batchNumToStateRoot[finalNewBatch] = newStateRoot;
-
lastVerifiedBatch = finalNewBatch;
-
-
globalExitRootManager.updateExitRoot(newLocalExitRoot);
当这一步在L1合约内执行成功时,这部分batch包含的所有交易也就真正达成了finality(对应op的7天挑战期结束)

-
Ethereum 在 polygon-zkEVM 中充当的角色
上文我们已经了解了polygon zkEVM的整体流程, 可以回顾下Ethereum 为 Rollup 做了哪些工作:
-
Sequencer 将 Rollup 的交易收集起来打成 Batch 之后,提交到L1的合约中。
-
Aggregator 将validity proof 提及到L1合约上来达成新的状态
在第一步,实际上L1不仅仅提供了DA层的功能,实际上还完成了一部分交易排序的功能;实际上当你把交易提交到Sequencer时,交易是没有真正被定序的,因为Sequencer有权力可以随便改变交易的顺序,但是当交易被包含在Batch里提交到L1合约上之后,任何人都没有权利再修改其中的交易顺序。
在第二步,Aggregator则是类似Proposer的角色,合约则类似validator的角色;Aggregator 提供了一个validity proof来声明一个新的状态是正确的,并告诉validator我提供的validity proof涉及哪些交易Batch,他们都存在了L1的哪个位置。
接着validator从合约中提取对应的Batch,与validity proof结合在一起就可以验证状态转换的合法性了,如果验证成功实际上合约内也会更新到对应validity proof的新状态。
-
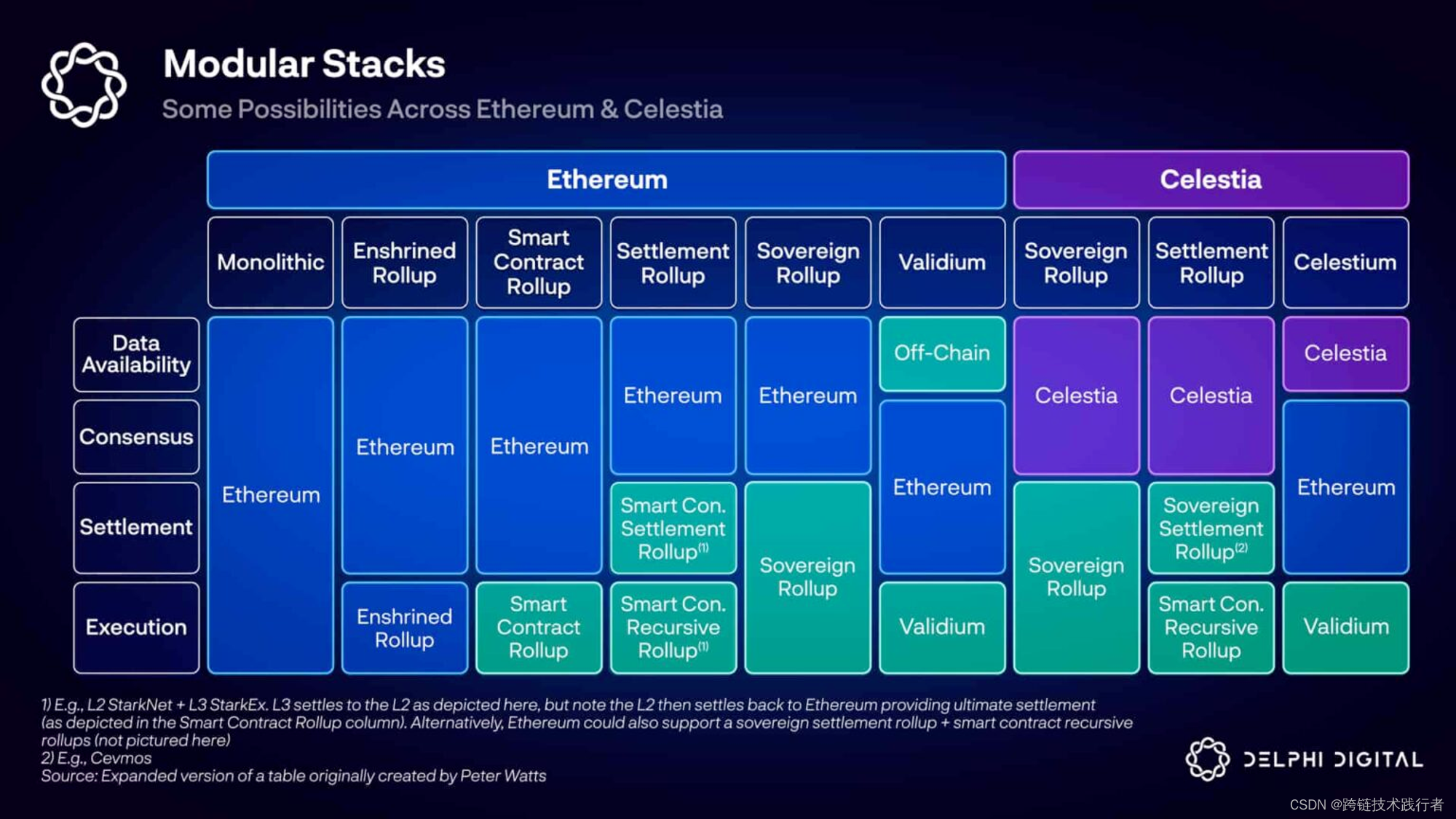
从模块化的角度结构 Smart Contract Rollup
如果从模块化的角度来看,Polygon zkEVM 属于Smart Contract Rollup 类型,我们可以尝试解构下它的各个模块:
从 Delphi 给的图中, 我们也可以看出实际上 Polygon ZkEVM 作为 Smart Contrat Rollup的Consensus Layer ,DA Layer 和 Settlement Layer其实都是耦合在polygonZkEVM.sol合约中,并不能很好的区分。
但是我们尝试着去解构各个模块:
-
数据可用层(Data Availability Layer): Rollup交易存放的地方
-
对于Polygon-zkEVM来说 ,当Sequencer调用
SequenceBatch()方法的时候,实际上就包含了往DA层提交交易数据 -
结算层(Settlement Layer): 具体指的是Rollup和L1之间的资金流动机制
-
具体指的是Polygon-zkEVM的官方桥(在下一篇文章会有详细介绍)
-
共识层(Consensus Layer): 包含交易排序和如何确定下一个合法状态(分叉选择)
-
Sequencer 调用L1合约中的
SequenceBatch()的时候完成了交易排序的工作,当Aggregator 调用L1合约中的trustedVerifyBatches()的时候完成了确认下一个合法状态的工作。 -
执行层(Execution Layer): 执行交易并且得到新的世界状态
-
当用户向Sequencer提交交易,并且Sequencer执行完之后得到新状态的过程(所以我们往往说rollup是计算扩容,因为L1把执行交易得出新状态的这个过程外包给了Rollup)
-
Sequencer会通过aggregator委托zkProver帮忙生成validity proof
-
为什么说 polygon-zkEVM 继承了L1的安全性
-
从上面介绍的整体流程上看,实际上Sequencer做了类似以太坊 Proposer的工作,提议了一批交易是有效交易,并且给出了这批交易执行后的新状态;而L1合约的验证逻辑,相当于所有L1的validator实际上都会在自己的以太坊客户端里执行一遍,实际上是所有的以太坊验证者充当了Rollup的验证者,因此我们认为 polygon zkEVM 继承了以太坊的安全性。
-
从另外一个角度上看,因为rollup的所有交易以及状态都存储在以太坊上,所以即便polygon zkEVM 这个团队跑路了,任何人都还是有能力依托以太坊上存储的数据,恢复整个Rollup网络。
-
-
Polygon zkEVM 激励机制
Rollup激励机制主要指的是如何让Sequencer和Aggregator有利可图,从而保持持续性的工作。

首先用户需要支付自己在Rollup上的交易的手续费,这部分的手续费是采用ETH计价的,用Bridged ETH支付。
Sequencer 则需要支付这些包含Rollup交易的Batch上传到L1交易的calldata上的成本(调用
SequenceBatch(batches)的成本),同时需要在上传Batch的同时支付一定的Matic到L1合约中,用于之后支付Aggregator为这些Batches提供validity proof的成本。Aggregator 在调用
trustedVerifyBatches()为L1合约内还没有被finality的Batches提供validity proof的同时,也可以取出Sequencer提前支付在合约内的Matic代币,作为提供validity proof的报酬。Sequencer的收入如下:
Aggregator的收入如下
-
收入 = Rollup所有交易的Gas费用 - 将Batches上传到L1花费的L1网络Gas费用 - 支付给Aggregator的证明费用(Matic计价)
-
收入 = Sequencer支付的Matic报酬 - 提交到validity proof到L1的Gas费用 - validity proof生成花费的硬件费用
-
调整支付给Aggregator的证明费用
同时为了避免Sequencer因为无利可图罢工,提供了以下的机制来调整Sequencer支付给Aggregator 的证明费用。
合约中存在这样一个方法用来调整为batch提供证明的费用:
function _updateBatchFee(uint64 newLastVerifiedBatch) internal
它会更改合约中一个名为batchFee的变量,而这个变量决定了Sequencer为每个Batch支付的Matic代币数量。
更改机制如下:
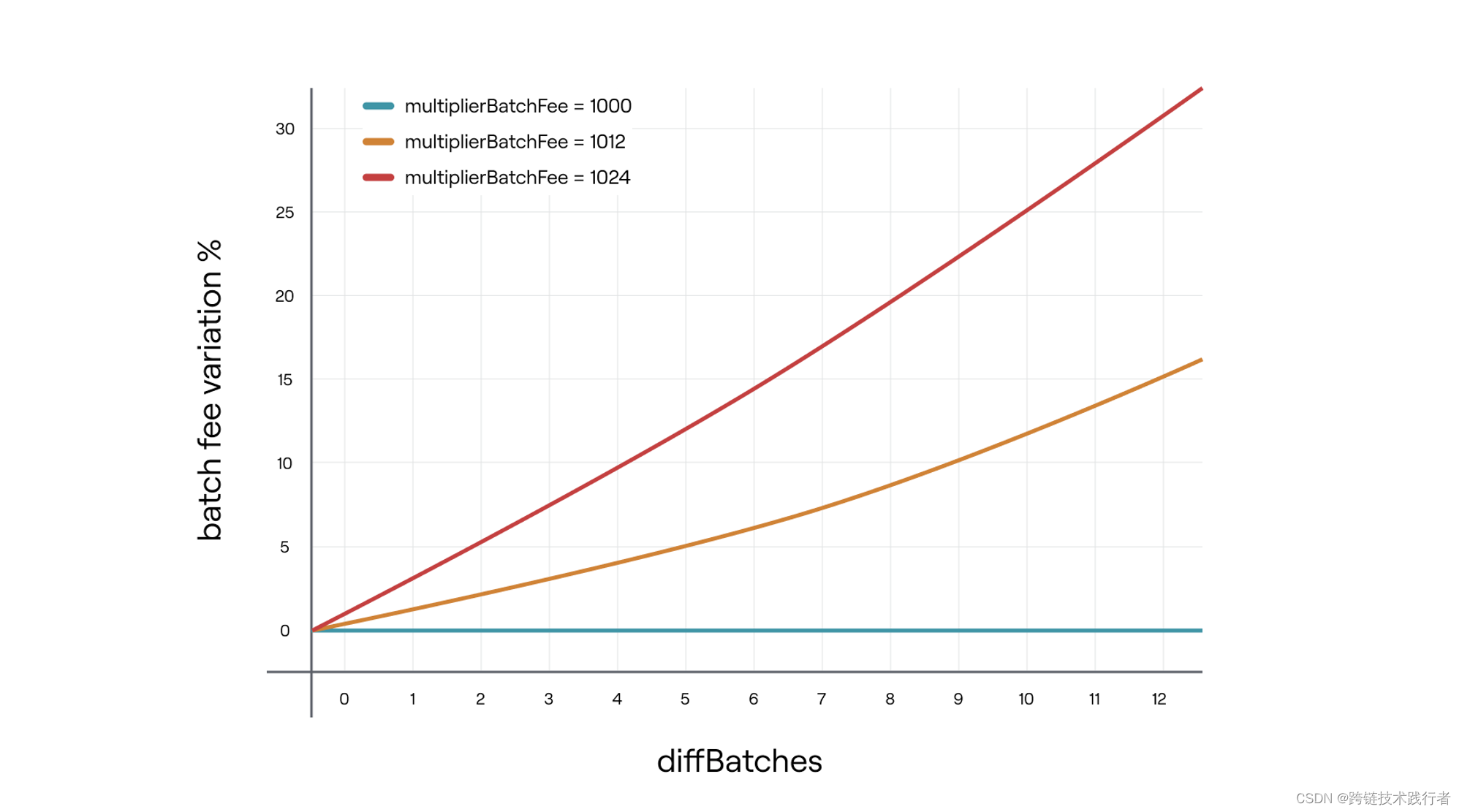
合约中维护了这样一个变量veryBatchTimeTarget ,代表每个Batch被Sequencer提交到L1之后期望在这个时间内被验证状态。
合约内会记录所有超过了veryBatchTimeTarget 之后还没有被验证状态的Batches, 并且将这些batches的总数量记为 diffBatches 。
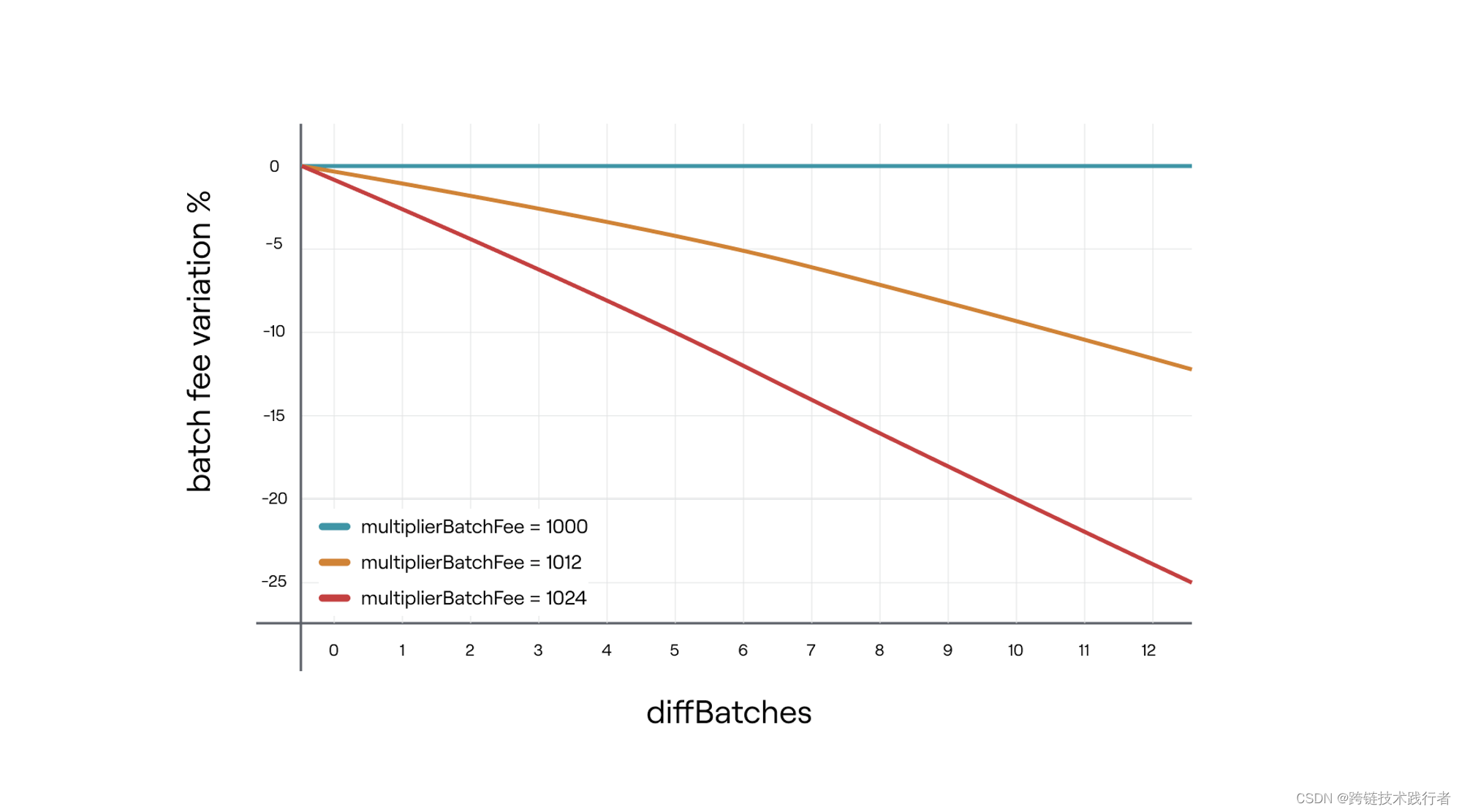
于是当有batches迟到的时候,会用以下公式来调整batchFee:
-
multiplierBatchFee是一个被限制在1000~1024范围的数,可以通过函数setMultiplierBatchFee()由合约管理员更改
function setMultiplierBatchFee(uint16 newMultiplierBatchFee) public onlyAdmin
-
需要注意这里的 采用
multiplierBatchFee和10^3是为了实现3个小数点后的调整精度
同理假如Batches提前了也会触发相应的batchFee调整机制:
-
diffBatches表示提前验证状态的Batches的数量
总结
在这篇文章里我们梳理了Polygon zkEVM的核心机制,并分析了它实现以太坊计算扩容的可行性。有了一个整体的大纲后,在接下来的文章里我们会深入到协议内部,依次解析zkEVM Bridge的设计细节,Sequencer的去中心化路线,zkProver的实现以及zkEVM的设计原理。

