
- 1Git版本控制系统之分支与标签(版本)_分支 标签
- 2高版本Keras多GPU和分布式训练(Multi-GPU and distributed training)_multi-gpu and multi-node distributed training with
- 3解决Error error0308010Cdigital envelope routinesunsupported_emitting compressionplugin error error: error:0308
- 4手打RPC-动态注入服务_rpc 动态接入
- 5【调剂】2022年南昌航空大学计算机视觉与人工智能团队接收调剂研究生
- 6css 外边距塌陷解决方法_css 兄弟盒子外边距塌陷怎么解决啊
- 7【玩转 TableAgent 数据智能分析】股票交易数据分析+预测_如何用agent分析股票
- 8用通俗易懂的方式讲解:万字长文带你入门大模型_大模型入门文章
- 9java中的集合类_java键值对有哪些集合
- 10python机器人编程——差速机器人小车的控制,控制模型、轨迹跟踪,轨迹规划、自动泊车(中)未完待续..._差速轮小车mpc控制
深度学习之基于Pytorch和OCR的识别文本检测系统_pytorch ocr
赞
踩
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
深度学习在图像处理领域取得了显著的成就,其中基于PyTorch的OCR(Optical Character Recognition)系统在文本检测方面表现突出。本文将介绍这一系统的基本原理和主要特点。
深度学习与OCR
深度学习通过模拟人脑神经网络的方式,实现了在复杂任务上的卓越表现。在OCR领域,深度学习模型通过学习字体、排版和语言结构,能够有效地识别和理解图像中的文字。
PyTorch在OCR中的应用
PyTorch是一个开源的深度学习框架,广泛应用于图像处理和自然语言处理任务。其灵活性和易用性使得它成为OCR系统开发的理想选择。PyTorch提供的动态图机制允许开发者更灵活地构建、调试和修改模型。
文本检测系统的关键组成部分
基于PyTorch的OCR系统主要包括以下几个关键组成部分:
1. 图像预处理
在将图像输入模型之前,需要对其进行预处理。这可能包括调整图像大小、灰度化、去噪等步骤,以确保模型能够更好地理解文本。
2. 深度学习模型
系统的核心是深度学习模型,它通过训练从大量标注文本的图像中学¥¥征和模式。常用的模型包括卷积神经网络(CNN)和循环神经网络(RNN)的组合,以及Transformer架构。
3. 文本检测算法
文本检测算法负责在图像中定位和标记文本区域。一些流行的算法包括基于锚点框的方法、滑动窗口方法等。
4. 后处理
识别到文本后,系统可能需要进行后处理步骤,以提高准确性和去除误差。这可能包括非极大值抑制(NMS)等技术。
二、功能
环境:Python3.8.5、OpenCV、Pytorch、PyCharm2020
简介:CRNN+CTC文本识别网络构建
首先CNN提取图像卷积特征
然后LSTM进一步提取图像卷积特征中的序列特征
三、系统
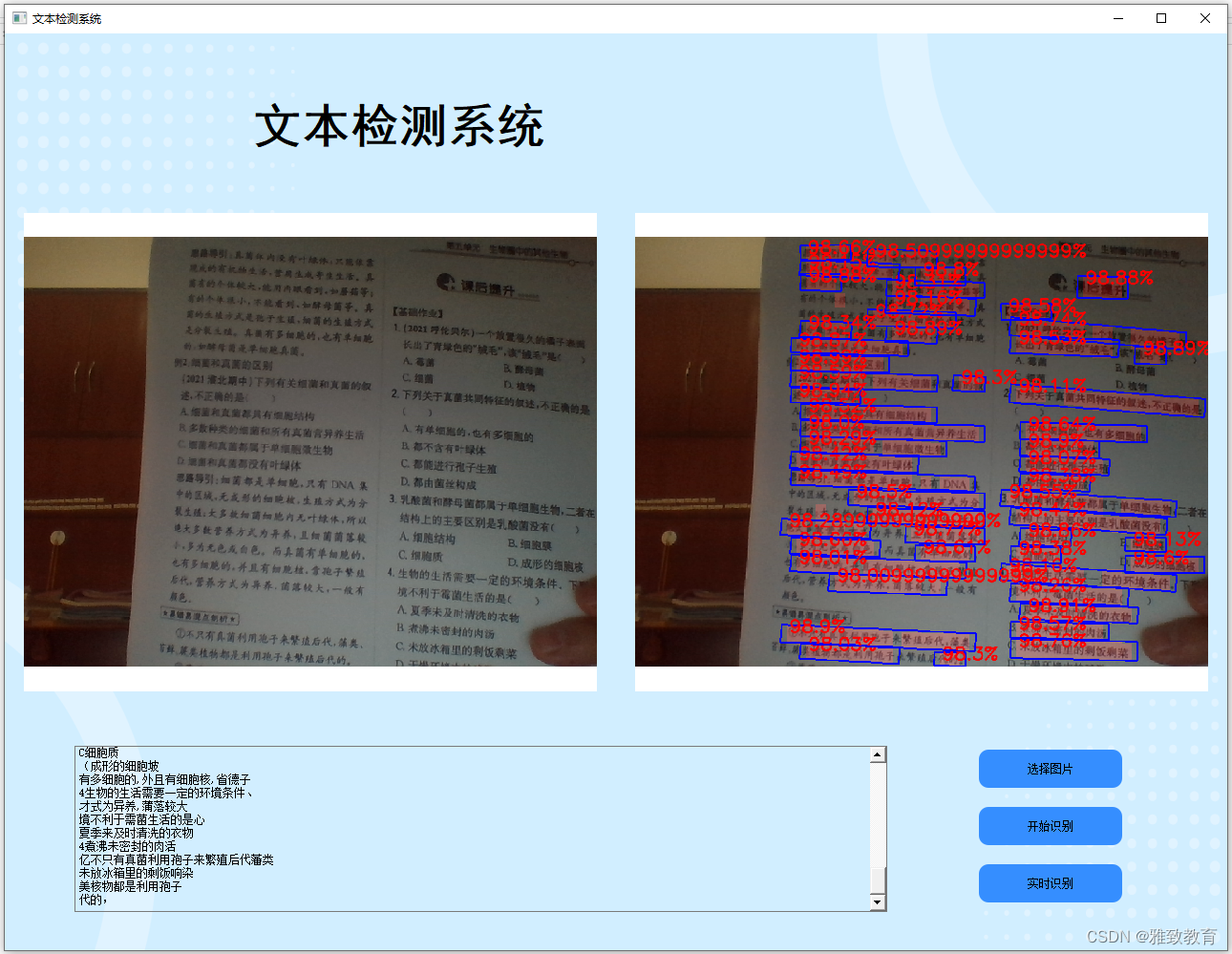


四. 总结
基于PyTorch的OCR系统在文本检测方面具有卓越的性能,其灵活性和强大的深度学习工具使其成为研究和应用领域的首选。通过不断改进模型和算法,这一系统在实际应用中将发挥越来越重要的作用。

