
- 1程序人生:新媒体运营毅然转行测试涨薪3k,我的入行秘籍是什么..._java转测试还是新媒体运营
- 2媒体梦工厂AI智聊:轻松提升工作效率的智能助手
- 3Java面试题总结(1-111)_java: 方法不会覆盖或实现超类型的方法且函数名变灰色
- 4结构设计到项目管理:工程师是怎么练成的._冰箱结构工程师项目经验怎么写
- 5为大模型而生!顶流大佬发起成立学术会议 COLM,或成为未来 NLP 最强顶会?!_如何看待 colm 顶会
- 6Java【动态规划】图文详解 “路径问题模型“ , 教你手撕动态规划_java 动态规划
- 7让 macOS 终端走代理的四种方法_mac 终端不能访问代理
- 8RabbitMQ集群搭建详细介绍以及解决搭建过程中的各种问题 + 配置镜像队列——实操型
- 9Oracle中的plsql编程_oracle plsql编程
- 10基于Springboot+Vue的Java项目-大学生租房平台系统(附演示视频+源码+LW)
【nlp学习】知识图谱ch1.知识图谱原理与应用概述——学习笔记_知识图谱从哪些维度评估
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、知识图谱(knowledge graph)
知识图谱本质上是基于图的语义网络,表示实体和实体之间的关系。
传统互联网搜索技术:基于关键词字符串匹配
- 爬取网页建立倒排索引。
- 基于倒排索引,搜索引擎首先找到了包含关键词的网页。
- 根据打分规则(如pagerank,HITS等),对网页进行排序。
- 返回用户。
但是机器并不理解背后的语义。
比如我们搜索:“瓦特是哪个大学的?”计算机只能搜索到包含关键字的网页,而不是直接返回“格拉斯哥大学”给用户。
要求计算机懂得数据之间的关联。
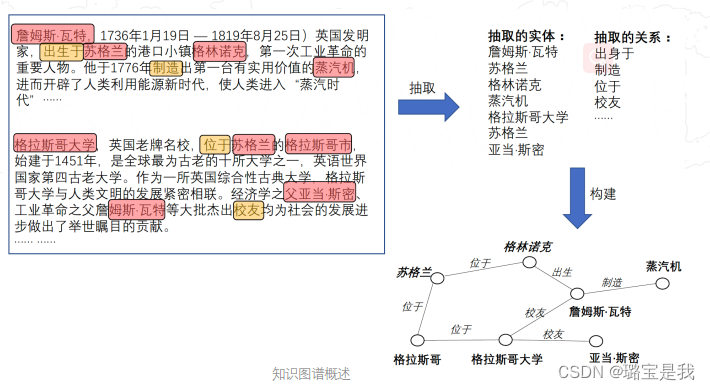
二、知识图谱研究的多个维度
- 自然语言处理:信息抽取,语义解析。
- 数据库:RDF数据库系统,数据集成,知识融合。
- 机器学习:知识图谱数据的知识表示(graph embedding)
- 知识工程:知识库构建,基于规则的推理。
1.知识工程
知识工程的核心:知识库和推理引擎
- 领域本体的构建
- 知识抽取,知识融合
2.知识图谱数据模型
RDF (Resource Description Framework)
RDF定义了一个简单的模型,用于描述资源,属性和值之间的关系。资源是可以用URI标识的所
有事物,属性是资源的一个特定的方面或特征,值可以是另一个资源,也可以是字符串。总的
来说,一个RDF描述就是一个三元组:<主语、谓词、宾语>。
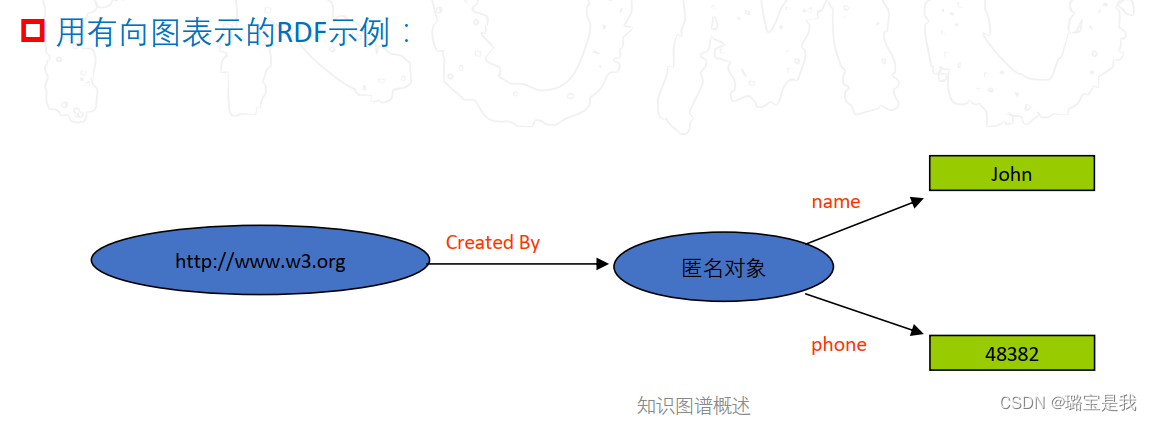

3.知识抽取
知识抽取的目标是从海量的文本数据中通过信息抽取的方式获取知识,其方法根据所处理的数据源的不同而不同。
- 结构化数据
- 半结构化数据
- 非结构化文本数据
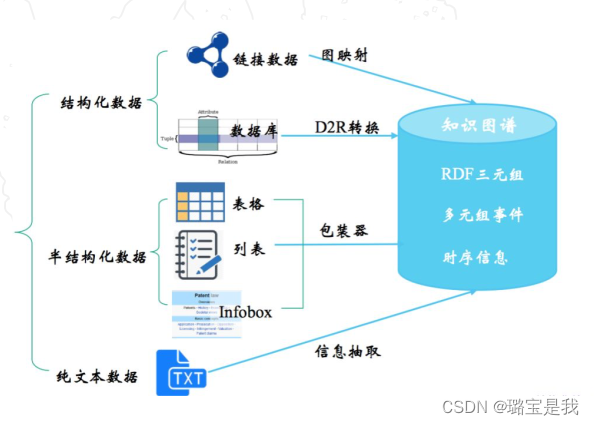
文本信息抽取:从非结构化文本数据中进行知识抽取。 - 实体识别
- 实体消歧
- 关系抽取
- 事件抽取
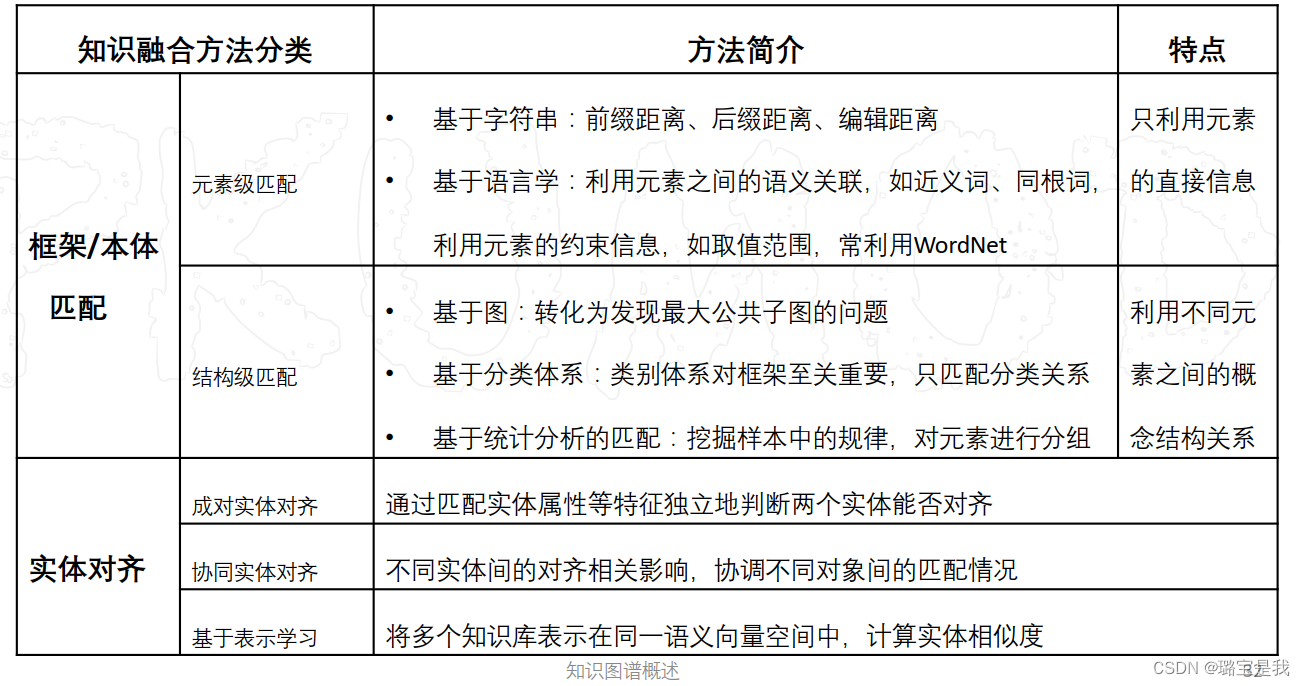
4.知识融合
实体对齐:比如都是北京大学,可能在不同的网站上有不同的名。如Peking University或Beijing University,但他们实际上是一个实体,如何判定这两个实体是相似的?
实体对齐必然涉及到实体相似度的计算,假设两个实体的记录x和y,x和y在第i个属性上的值
是xi,yi,那么需要通过两步计算:

5.知识图谱与自然语言处理
自然语言处理和知识图谱是双向互动的关系。
- 自然语言处理——(抽取知识)——知识图谱
- 知识图谱——(提升NLP任务的准确度)——自然语言处理
6语义解析之语义搜索
语义搜索:是指搜索引擎的工作不再拘泥于用户所输入请求语句的字面本身,二十透过现象看本质,准确的捕捉到用户所输入语句后面的真正意图,并以此来进行搜索,从而更加准确的向用户返回最符合要求的搜索结果。
待补充。。。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

