
- 1CVPR 2022 | 南开程明明团队和天大提出LD:目标检测的定位蒸馏
- 2鸿蒙App开发,Button坑死你不偿命!_鸿蒙设置button不可点击
- 3Redis部署之哨兵
- 4大数据知识图谱之深度学习——基于BERT+LSTM+CRF深度学习识别模型医疗知识图谱问答可视化系统_bert+lstm+crf的识别模型
- 5可以不用KEPServer吗?上位机软件便捷、稳定、隐蔽地获取PLC数据的另外一种选择_类似kepserver的软件
- 6【MySQL】20. 使用C语言链接
- 7LLaMA Pro: Progressive LLaMA with Block Expansion
- 8网格搜索:GridSearchCV函数参数解释及示例_gridsearchcv官方文档
- 9PINN神经网络求解偏微分方程的11种方法【附论文和代码下载】
- 10开发5年!三面字节,成功拿到27k*17offer,原来也没那么难_字节二面比一面难很多吗
PyTorch搭建双向LSTM实现时间序列预测(负荷预测)_pytorch实现双向lstm
赞
踩
I. 前言
前面几篇文章中介绍的都是单向LSTM,这篇文章讲一下双向LSTM。
系列文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch中利用LSTMCell搭建多层LSTM实现时间序列预测
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
- PyTorch-LSTM时间序列预测中如何预测真正的未来值
- PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- PyTorch搭建ANN实现时间序列预测(风速预测)
- PyTorch搭建CNN实现时间序列预测(风速预测)
- PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
- PyTorch时间序列预测系列文章总结(代码使用方法)
- TensorFlow搭建LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量时间序列预测(负荷预测)
- TensorFlow搭建双向LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- TensorFlow搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- TensorFlow搭建ANN实现时间序列预测(风速预测)
- TensorFlow搭建CNN实现时间序列预测(风速预测)
- TensorFlow搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyG搭建图神经网络实现多变量输入多变量输出时间序列预测
- PyTorch搭建GNN-LSTM和LSTM-GNN模型实现多变量输入多变量输出时间序列预测
- PyG Temporal搭建STGCN实现多变量输入多变量输出时间序列预测
- 时序预测中Attention机制是否真的有效?盘点LSTM/RNN中24种Attention机制+效果对比
- 详解Transformer在时序预测中的Encoder和Decoder过程:以负荷预测为例
- (PyTorch)TCN和RNN/LSTM/GRU结合实现时间序列预测
- PyTorch搭建Informer实现长序列时间序列预测
- PyTorch搭建Autoformer实现长序列时间序列预测
II. 原理
关于LSTM的输入输出在深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中已经有过详细叙述。
关于nn.LSTM的参数,官方文档给出的解释为:
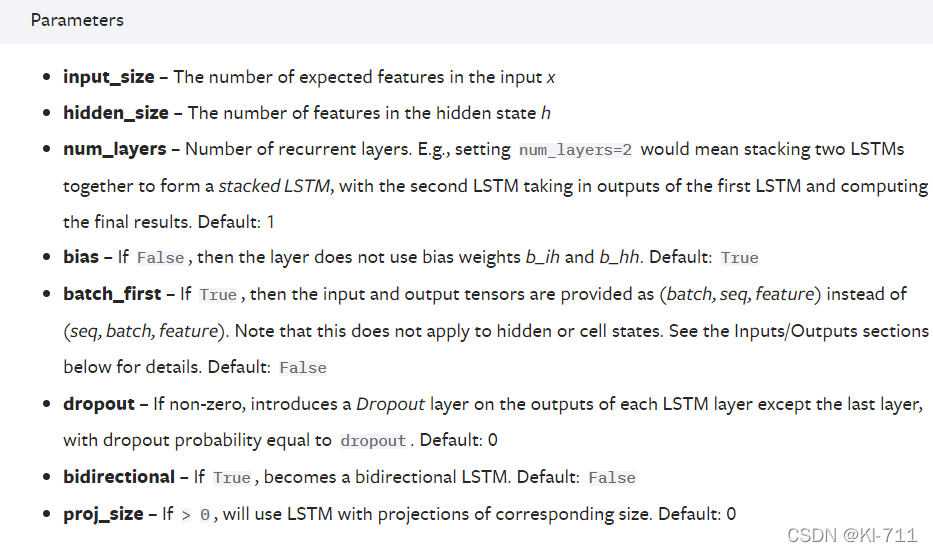
总共有七个参数,其中只有前三个是必须的。由于大家普遍使用PyTorch的DataLoader来形成批量数据,因此batch_first也比较重要。LSTM的两个常见的应用场景为文本处理和时序预测,因此下面对每个参数我都会从这两个方面来进行具体解释。
- input_size:在文本处理中,由于一个单词没法参与运算,因此我们得通过Word2Vec来对单词进行嵌入表示,将每一个单词表示成一个向量,此时input_size=embedding_size。比如每个句子中有五个单词,每个单词用一个100维向量来表示,那么这里input_size=100;在时间序列预测中,比如需要预测负荷,每一个负荷都是一个单独的值,都可以直接参与运算,因此并不需要将每一个负荷表示成一个向量,此时input_size=1。 但如果我们使用多变量进行预测,比如我们利用前24小时每一时刻的[负荷、风速、温度、压强、湿度、天气、节假日信息]来预测下一时刻的负荷,那么此时input_size=7。
- hidden_size:隐藏层节点个数。可以随意设置。
- num_layers:层数。nn.LSTMCell与nn.LSTM相比,num_layers默认为1。
- batch_first:默认为False,意义见后文。
Inputs
关于LSTM的输入,官方文档给出的定义为:

可以看到,输入由两部分组成:input、(初始的隐状态h_0,初始的单元状态c_0)
其中input:
input(seq_len, batch_size, input_size)
- 1
- seq_len:在文本处理中,如果一个句子有7个单词,则seq_len=7;在时间序列预测中,假设我们用前24个小时的负荷来预测下一时刻负荷,则seq_len=24。
- batch_size:一次性输入LSTM中的样本个数。在文本处理中,可以一次性输入很多个句子;在时间序列预测中,也可以一次性输入很多条数据。
- input_size:见前文。
(h_0, c_0):
h_0(num_directions * num_layers, batch_size, hidden_size)
c_0(num_directions * num_layers, batch_size, hidden_size)
- 1
- 2
h_0和c_0的shape一致。
- num_directions:如果是双向LSTM,则num_directions=2;否则num_directions=1。
- num_layers:见前文。
- batch_size:见前文。
- hidden_size:见前文。
Outputs
关于LSTM的输出,官方文档给出的定义为:

可以看到,输出也由两部分组成:otput、(隐状态h_n,单元状态c_n)
其中output的shape为:
output(seq_len, batch_size, num_directions * hidden_size)
- 1
h_n和c_n的shape保持不变,参数解释见前文。
batch_first
如果在初始化LSTM时令batch_first=True,那么input和output的shape将由:
input(seq_len, batch_size, input_size)
output(seq_len, batch_size, num_directions * hidden_size)
- 1
- 2
变为:
input(batch_size, seq_len, input_size)
output(batch_size, seq_len, num_directions * hidden_size)
- 1
- 2
即batch_size提前。
输出提取
假设最后我们得到了output(batch_size, seq_len, 2 * hidden_size),我们需要将其输入到线性层,有以下两种方法可以参考:
(1)直接输入
和单向一样,我们可以将output直接输入到Linear。在单向LSTM中:
self.linear = nn.Linear(self.hidden_size, self.output_size)
- 1
而在双向LSTM中:
self.linear = nn.Linear(2 * self.hidden_size, self.output_size)
- 1
模型:
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 2
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=True)
self.linear = nn.Linear(self.num_directions * self.hidden_size, self.output_size)
def forward(self, input_seq):
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# print(input_seq.size())
seq_len = input_seq.shape[1]
# input(batch_size, seq_len, input_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
pred = self.linear(output) # pred()
pred = pred[:, -1, :]
return pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(2)处理后再输入
在LSTM中,经过线性层后的output的shape为(batch_size, seq_len, output_size)。假设我们用前24个小时(1 to 24)预测后2个小时的负荷(25 to 26),那么seq_len=24, output_size=2。根据LSTM的原理,最终的输出中包含了所有位置的预测值,也就是((2 3), (3 4), (4 5)…(25 26))。很显然我们只需要最后一个预测值,即output[:, -1, :]。
而在双向LSTM中,一开始output(batch_size, seq_len, 2 * hidden_size),这里面包含了所有位置的两个方向的输出。简单来说,output[0]为序列从左往右第一个隐藏层状态输出和序列从右往左最后一个隐藏层状态输出的拼接;output[-1]为序列从左往右最后一个隐藏层状态输出和序列从右往左第一个隐藏层状态输出的拼接。
如果我们想要同时利用前向和后向的输出,我们可以将它们从中间切割,然后求平均。比如output的shape为(30, 24, 2 * 64),我们将其变成(30, 24, 2, 64),然后在dim=2上求平均,得到一个shape为(30, 24, 64)的输出,此时就与单向LSTM的输出一致了。
具体处理方法:
output = output.contiguous().view(self.batch_size, seq_len, self.num_directions, self.hidden_size)
output = torch.mean(output, dim=2)
- 1
- 2
模型代码:
class BiLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 2
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True, bidirectional=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# print(input_seq.size())
seq_len = input_seq.shape[1]
# input(batch_size, seq_len, input_size)
input_seq = input_seq.view(self.batch_size, seq_len, self.input_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
output = output.contiguous().view(self.batch_size, seq_len, self.num_directions, self.hidden_size)
output = torch.mean(output, dim=2)
pred = self.linear(output)
# print('pred=', pred.shape)
pred = pred[:, -1, :]
return pred
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
III. 训练和预测
数据处理、训练以及预测同前面几篇文章。
这里对单步长多变量的预测进行对比,在其他条件保持一致的情况下,得到的实验结果如下所示:
| 方法 | LSTM | BiLSTM(1) | BiLSTM(2) |
|---|---|---|---|
| MAPE | 7.43 | 7.09 | 7.29 |
可以看到,对于前面提到的两种方法,貌似差异不大。
IV. 源码及数据
后面将陆续公开~

