
热门标签
热门文章
- 1国产、自研、开源数据库的选型与应用 DAMS 2020
- 2uiautomation:基于windows的ui自动化框架_uiautomation安装
- 3软件测试之测试用例和缺陷报告模板分享_软件测试测试问题记录模版
- 4紫光同创国产FPGA学习之Design Editor_紫光同创ide如何查看fpga的布局
- 5在neo4j桌面版中利用.dump文件将已构建的图数据库中的数据导入到新数据库中_neo4j使用db.dump
- 6Stable Diffusion API 调用实战:详细教程_serverless-stable-diffusion-api
- 7MATLAB初学者入门(19)—— 均值算法
- 8(面试版)大数据组件的区别总结(hive,hbase,spark,flink)_hive spark flink
- 9必备年终绩效工作总结模板
- 10论文笔记:UrbanGPT: Spatio-Temporal Large Language Models
当前位置: article > 正文
Python爬虫之selenium爬取英雄联盟官网英雄皮肤图片下载到本地和保存到数据库
作者:Cpp五条 | 2024-04-26 04:46:27
赞
踩
Python爬虫之selenium爬取英雄联盟官网英雄皮肤图片下载到本地和保存到数据库
从英雄联盟皮肤网站的网页源代码中获取不到英雄的皮肤地址 通过selenium可以轻松获取想要的内容
源码展示
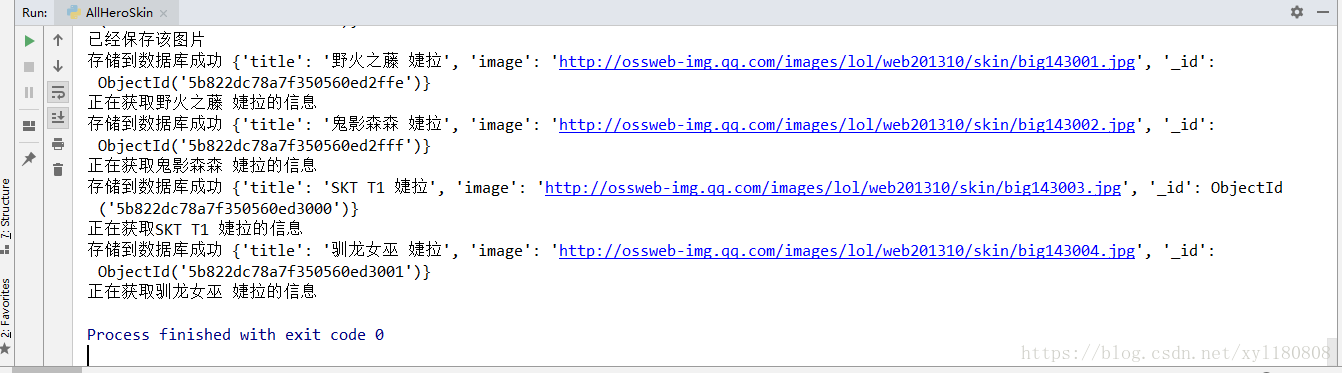
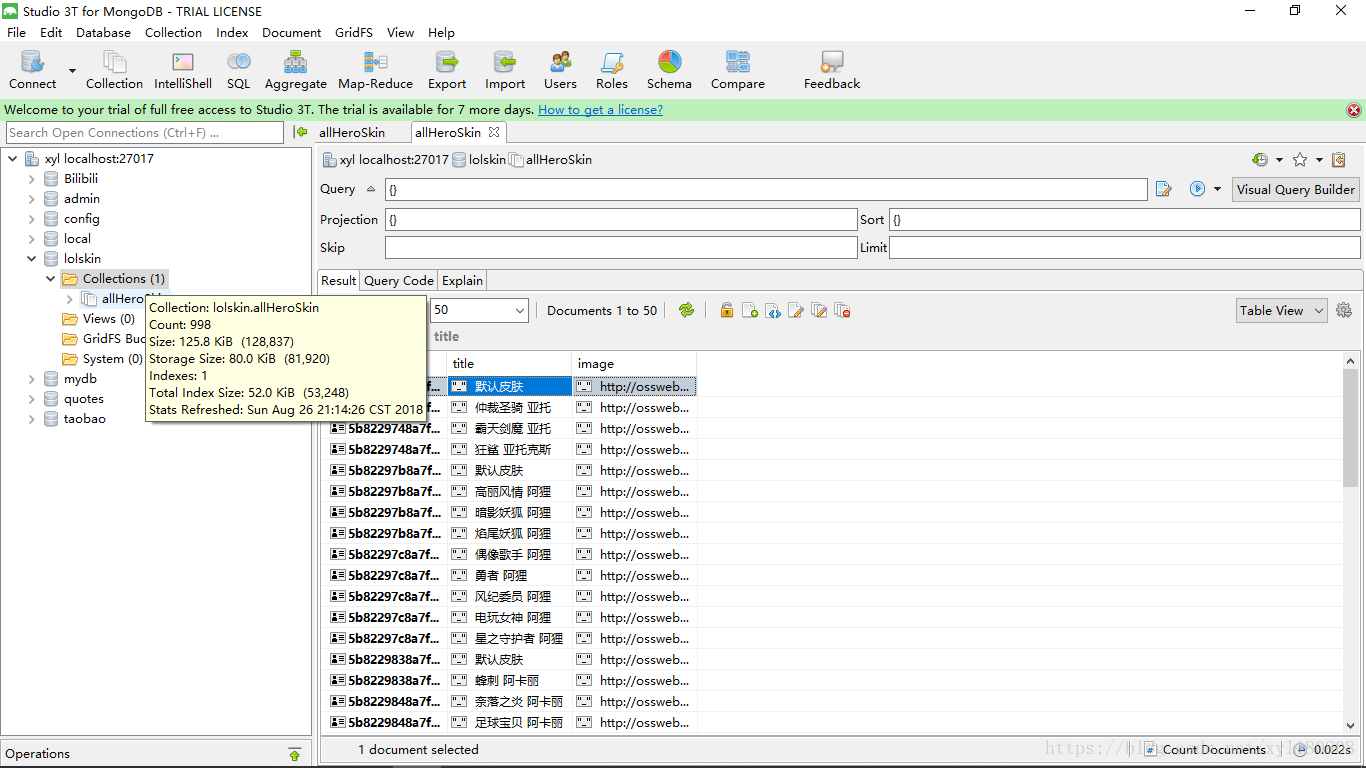
from selenium import webdriver from time import sleep from pyquery import PyQuery as pq import os,requests from config import * import pymongo from selenium.common.exceptions import NoSuchElementException browser = webdriver.Chrome() client = pymongo.MongoClient(MONGO_URL) db = client[MONGO_DB] def get_hero_url(): browser.get("http://lol.qq.com/web201310/info-heros.shtml") html = browser.page_source doc = pq(html) #通过PyQuery解析出来的网页 用css选择器获取li标签内容 并返回一个生成器 items = doc('#jSearchHeroDiv.imgtextlist li').items() #通过循环获取生成器下的内容 for item in items: data ={ 'hero_url':'http://lol.qq.com/web201310/'+item.find('a').attr('href'), 'hero_name':item.find('p').text() } #print(len(data['hero_url'])) # 在网页加载的时候可能会因为网络的问题 图片会加载不出来 然后css选择器就获取不到相应的内容 #从未抛出异常 抛出异常后让网页重新加载一次 try: get_hero_skin(data['hero_url']) except NoSuchElementException: print('出现异常再次请求网页') get_hero_skin(data['hero_url']) def get_hero_skin(url): browser.get(url) sleep(1) #只有点击第二个皮肤的时候所有的皮肤才会在网页的代码中显示出来 #所以这里设置了个自动点击的功能才能获取到英雄的所有皮肤 #否则只能获取到一个默认皮肤 skin = browser.find_element_by_css_selector('#skinNAV > li:nth-child(2)') skin.click() html = browser.page_source doc = pq(html) items = doc('.defail-skin #skinBG li').items() for item in items: data ={ 'title':item.find('img').attr('alt'), 'image':item.find('img').attr('src') } #print(data) save_to_mongo(data) download_image(data['image'],data['title']) def download_image(image_url,title): if not os.path.exists('images'): os.mkdir('images') response = requests.get(image_url) if response.status_code == 200: #每个英雄的第一个都是默认皮肤所以在保存到本地时候会将 #之前的默认皮肤覆盖 所以文件中一个最后一个默认皮肤的图片 # 这里可以自己简单修改下 file_path = 'images/{}.jpg'.format(title) if not os.path.exists(file_path): print("正在获取%s的信息" % (title)) # 图片以二进制格式保存 with open(file_path, 'wb')as f: # content获取图片内存 f.write(response.content) else: print("已经保存该图片") def save_to_mongo(data): try: #保存到mongodb数据库下的每一个数据都会有自己的id #所以数据库中的每个英雄的默认皮肤不会受到影响 if db[MONGO_TABLE].insert(data): print("存储到数据库成功",data) except Exception: print('存储到数据库错误',data) get_hero_url() browser.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
存储到MongoDB数据库需要一个配置文件
MONGO_URL = 'localhost'
MONGO_DB = 'lolskin'
MONGO_TABLE = 'allHeroSkin'
- 1
- 2
- 3
- 4

小结
selenium确实很容易将所有的皮肤爬取下来 但是效率太低 用进程池或者多线程是不是效率可以提高了 希望大佬可以提提建议
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/489077
推荐阅读
相关标签

