
热门标签
热门文章
- 1Android 通过包名来判断是否安装APP_android 根据包名判断当前是否安装某应用
- 2字节面经总结_字节社招面经
- 3【腾讯云 TDSQL-C Serverless 产品体验】聚焦业务价值之在Serverless上的探索和实践_腾讯云的serverless
- 4python系统基础信息模块详解
- 5kali执行php代码的exp,ThinkPHP 5.x (v5.0.23及v5.1.31以下版本) 远程命令执行漏洞利用(GetShell)...
- 6Unity实现第一人称移动(胎教级教学)
- 7ng-class的几种用法
- 8Mac下的FFmpeg安装和基本使用_brew ffmpeg
- 9对于fast-lio论文和代码的一些个人理解
- 10数据库连接失败_“encrypt”属性设置为“true”且 “trustservercertificate”属性设置
当前位置: article > 正文
论文笔记:UrbanGPT: Spatio-Temporal Large Language Models
作者:菜鸟追梦旅行 | 2024-04-23 21:59:59
赞
踩
论文笔记:UrbanGPT: Spatio-Temporal Large Language Models
1 intro
时空预测的目标是预测并洞察城市环境随时间和空间不断变化的动态。其目的是预见城市生活多个方面的未来模式、趋势和事件,包括交通、人口流动和犯罪率。虽然已有许多努力致力于开发神经网络技术,以准确预测时空数据,但重要的是要注意,许多这些方法严重依赖于拥有足够的标记数据来生成精确的时空表示。
不幸的是,数据稀缺问题在实际的城市感知场景中普遍存在。在某些情况下,从下游场景收集任何标记数据变得具有挑战性,这进一步加剧了问题。
因此,建立一个能在多种时空学习场景中表现出强大泛化能力的时空模型变得必要。
借鉴大型语言模型(LLM)的显著成就,我们的目标是创建一个能在广泛的城市下游任务中表现出卓越泛化能力的时空LLM。
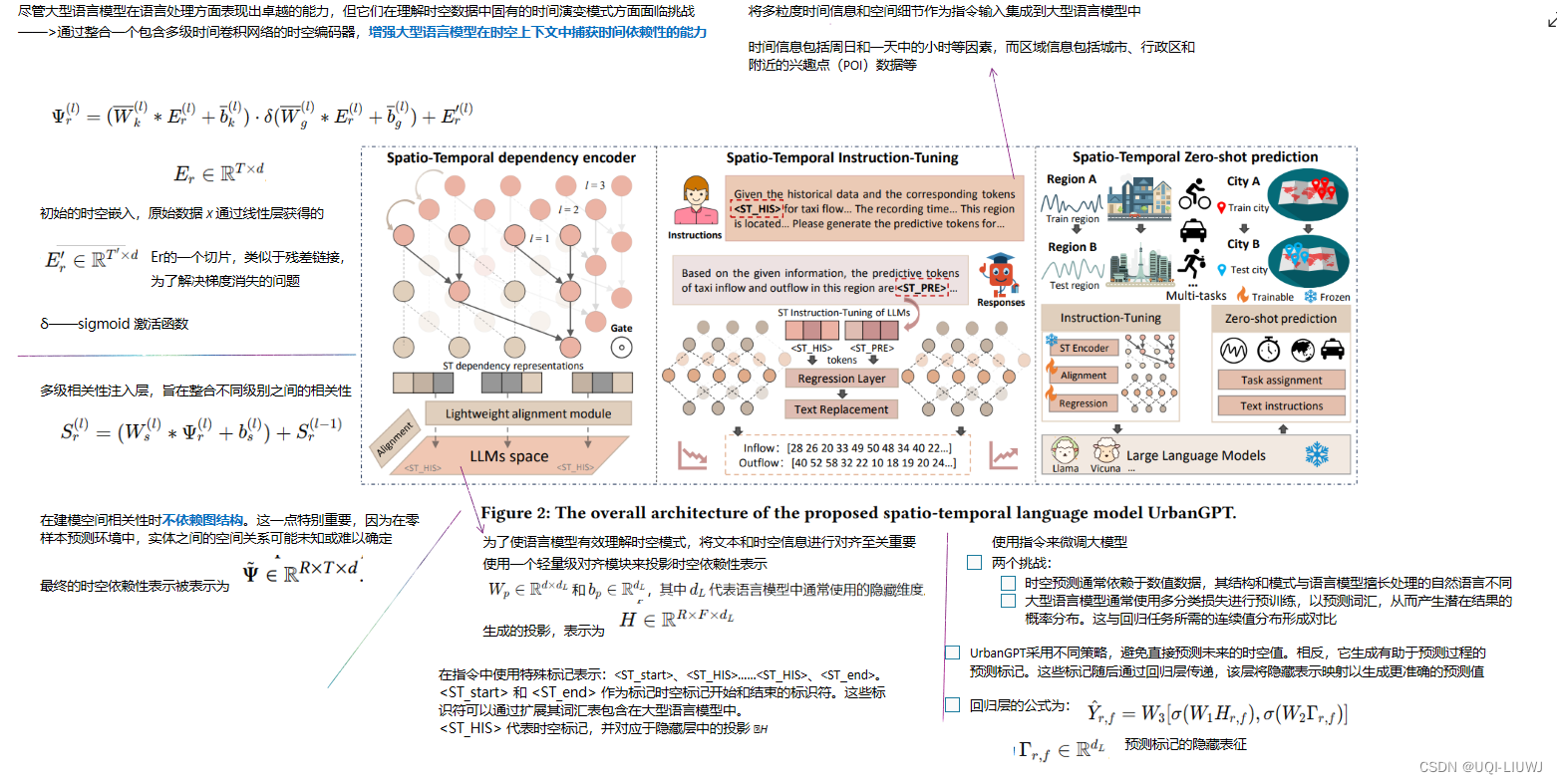
为实现这一目标,我们推出了UrbanGPT,它将时空依赖性编码器与指令调优范式无缝集成。这种集成使LLM能够理解时间和空间的复杂相互依赖性,有助于在数据稀缺的情况下进行更全面、更准确的预测。
为验证我们方法的有效性,我们在多个公共数据集上进行了广泛的实验,涵盖了不同的时空预测任务。结果一致表明,我们精心设计的架构的UrbanGPT始终优于最先进的基准。这些发现突显了为时空学习构建大型语言模型的潜力,特别是在标记数据稀缺的零样本场景中。
2 现有挑战
- 挑战1:稀缺标签数据和重新训练的巨大开销
- 虽然先进时空网络技术在预测方面非常有效,但它们受限于对大量标记数据的需求。
- 在城市环境中,数据往往难以获得,如全市范围内的交通和空气质量监控代价高昂。
- 此外,这些模型处理新区域或任务时的泛化能力不足,常需重新训练,以适应新的时空场景
- 挑战2:LLMs和现有时空模型缺乏零样本场景下的泛化能力
- 大语言模型LLaMA可基于输入文本对流量模式的推断。
- 然而,它在处理具有复杂时空依赖性的数字时间序列数据方面存在局限,可能会导致相反的预测结果。
- 另一方面,预训练的baseline能够很好地编码时空依赖关联,但它们可能因过度拟合原始数据导致在零样本场景下表现不佳
- 大语言模型LLaMA可基于输入文本对流量模式的推断。
- 挑战3:如何将LLMs的出色推理能力扩展到时空预测场景
- 时空数据的独特特征与LLMs中所编码的知识之间的存在差距,如何减少这一差距进而建立在广泛的城市任务中具有出色的泛化能力时空大语言模型是一项重大挑战
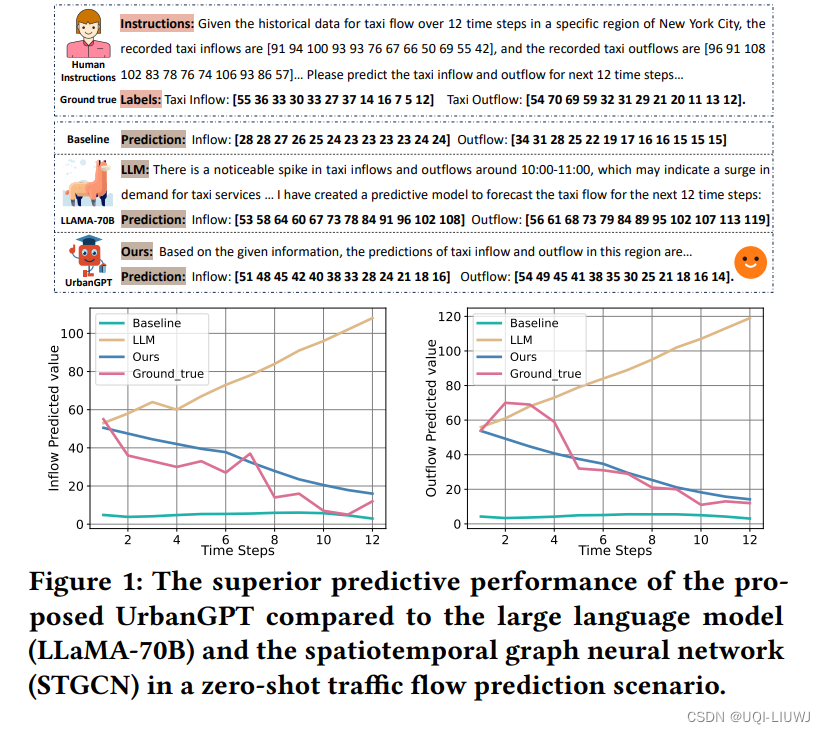
3 方法
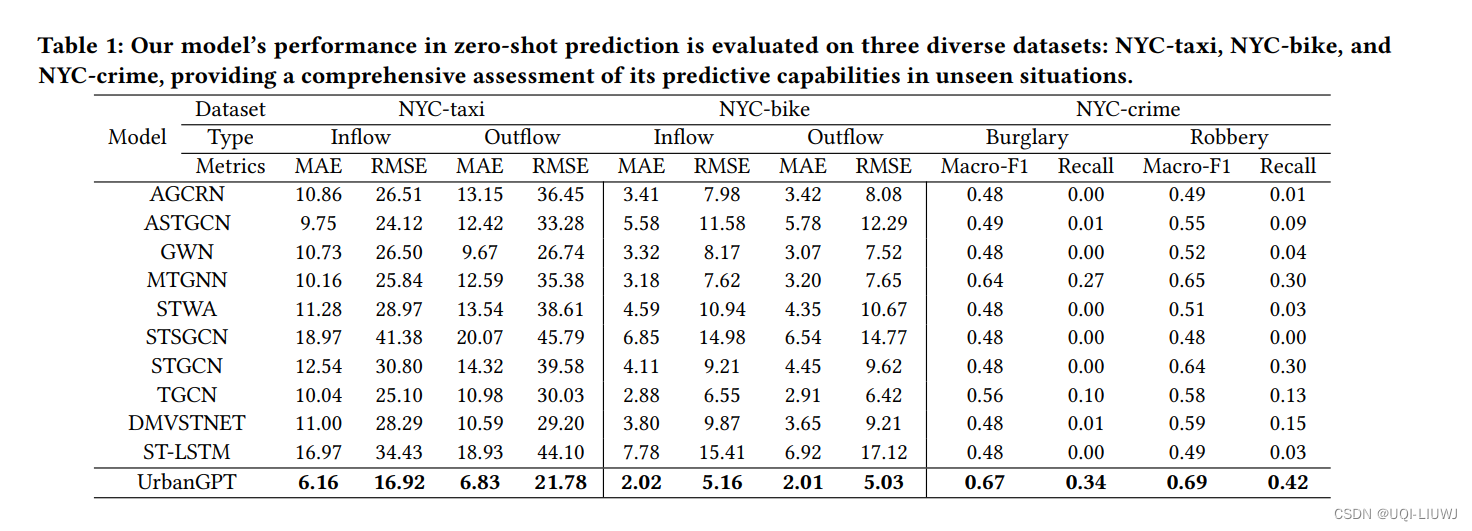
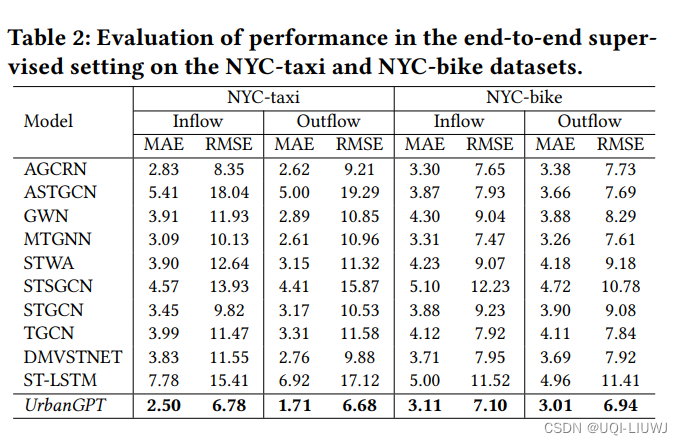
4 实验
- zero-shot 场景——通过预测训练阶段未见过的纽约市或芝加哥地区的未来时空数据来评估模型性能。
- 监督学习场景——使用与训练集相同区域的未来数据评估模型
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/476217
推荐阅读
相关标签

