
vLLM: Easy, Fast, and Memory-Efficient LLM Serving with PagedAttention_vllm-project/vllm: a high-throughput and memory-ef
赞
踩
论文:https://arxiv.org/abs/2309.06180
代码:GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs
核心要点
-
为什么切换简单?Easy
-
本质是优化了底层推理过程的内存调用逻辑,CUDA Op的改变,与模型架构关联小,可以无痛切换
-
-
为什么节省了内存?Memory-Efficient
-
序列存储的空间是按需分块存储,降低了物理空间的浪费,原生支持内存共享
-
-
为什么增加了推理的吞吐量?Fast
-
通过内存共享、分块存储的方式,降低了单request的内存占用,增加BatchSize,优化调度策略,提升GPU利用率
-
-
文章贡献:
-
受操作系统虚拟内存和分页机制的启发,提出了一种基于非连续分页内存KV cache的注意力算法PagedAttention
-
设计并实现了vLLM框架,一个基于PagedAttention建立的分布式LLM服务
-
在各种场景下评估了vLLM,并证明它明显优于之前的SOTA,如FasterTransformer
-
不同框架性能对比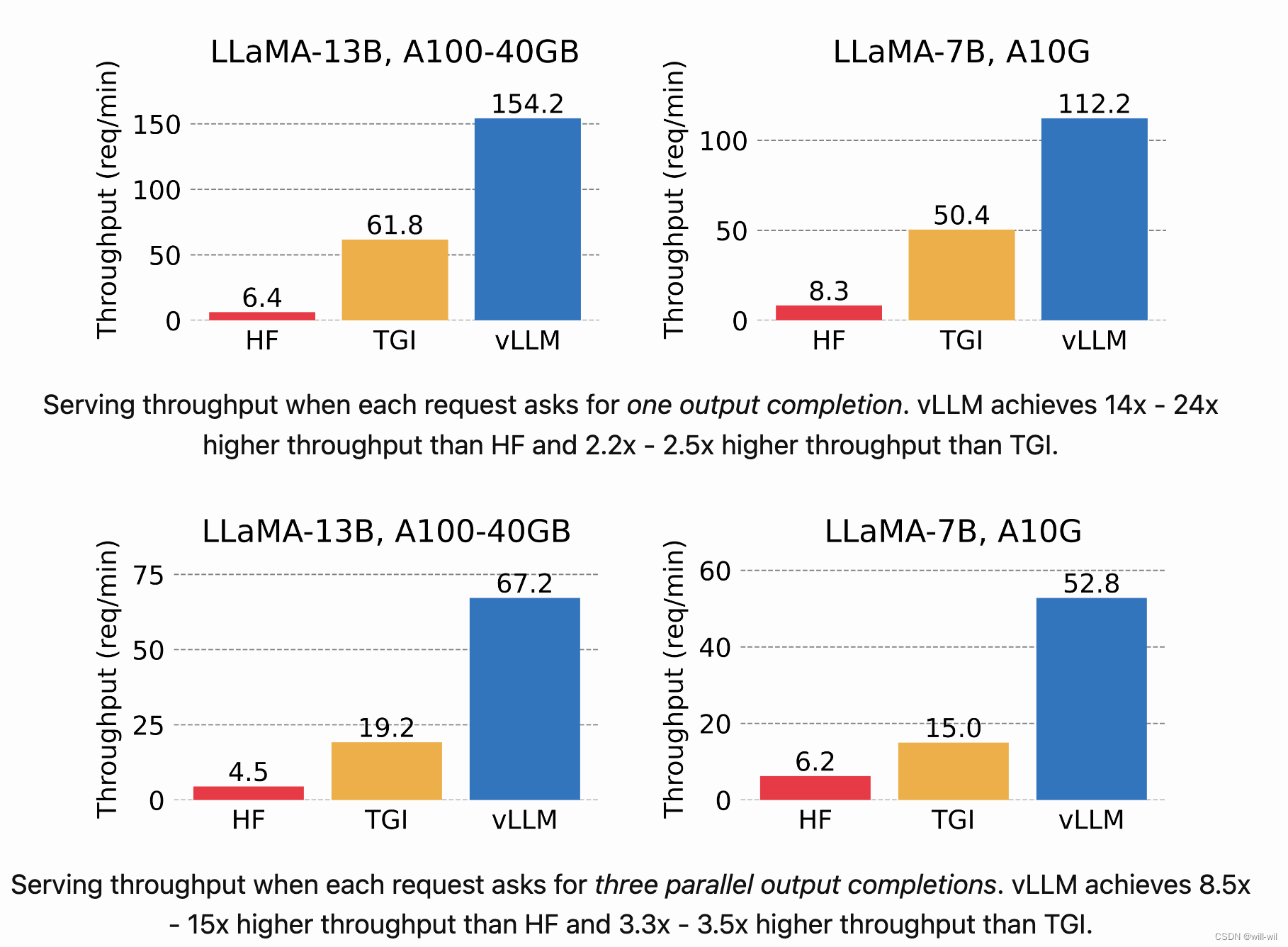
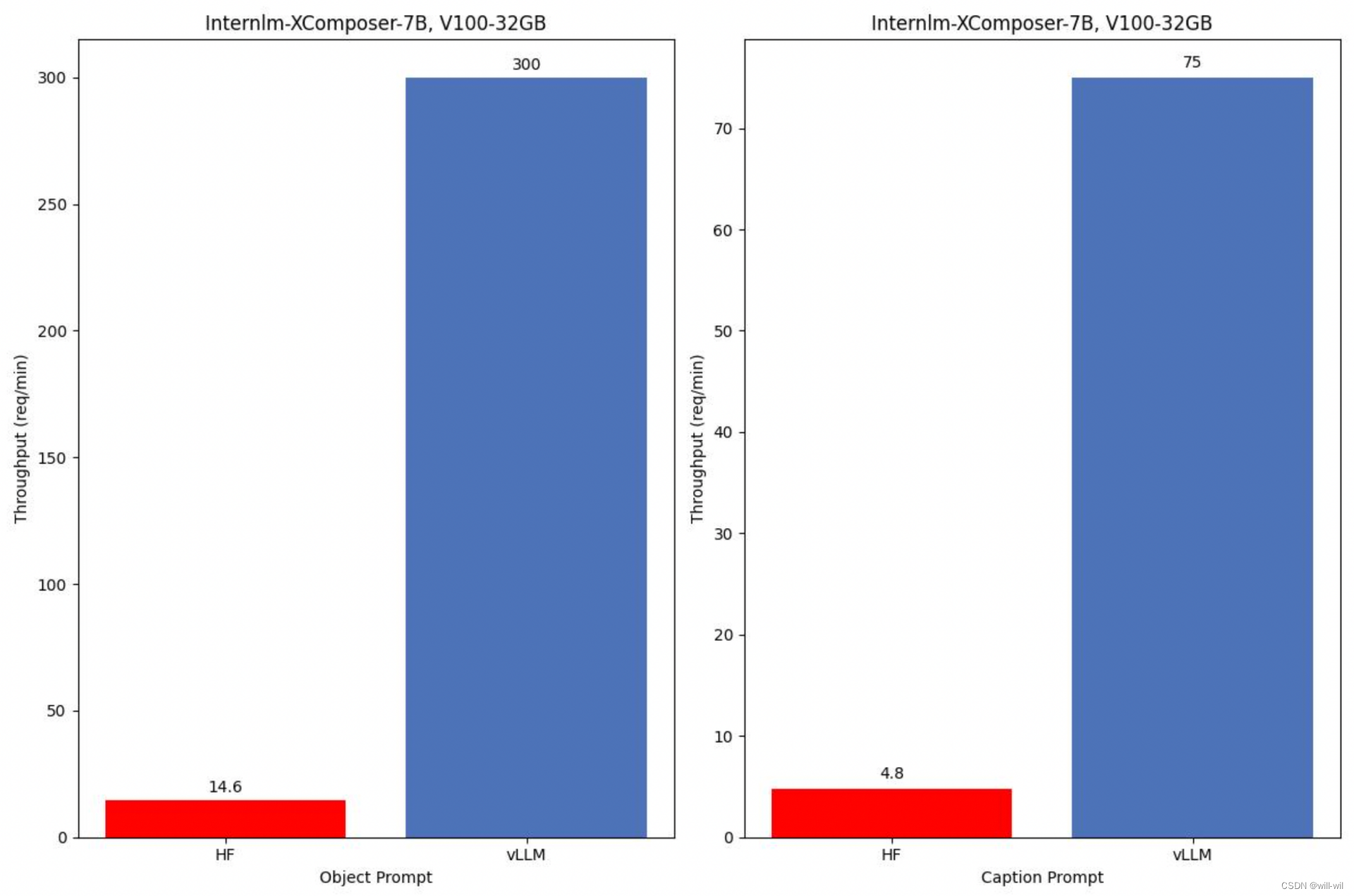
多模态大模型性能自测
框架介绍
vLLM框架整体结构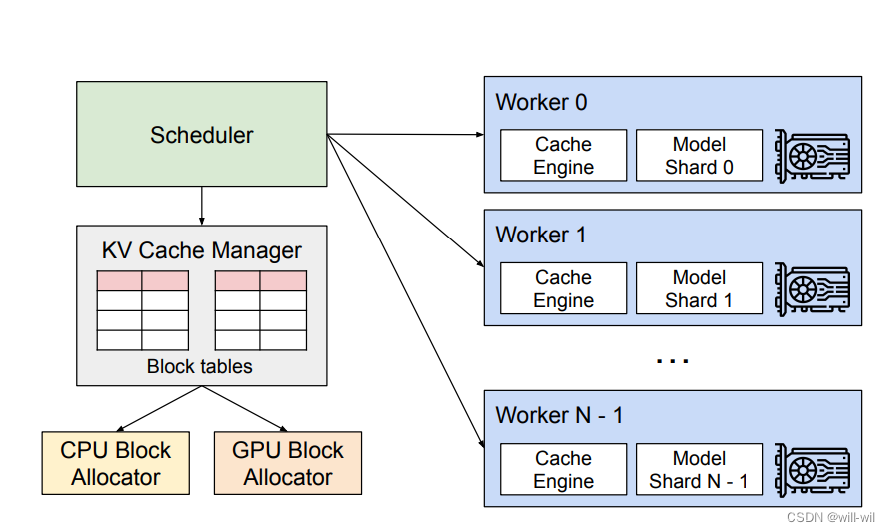
LLM模型推理流程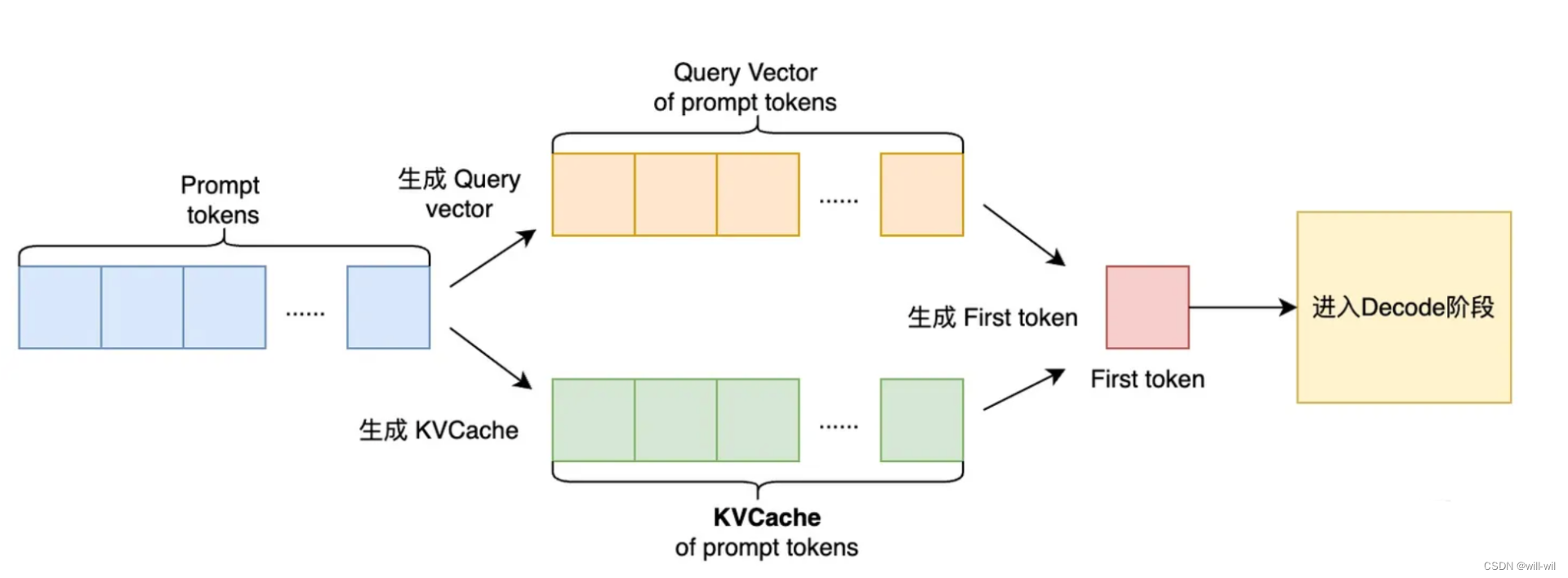
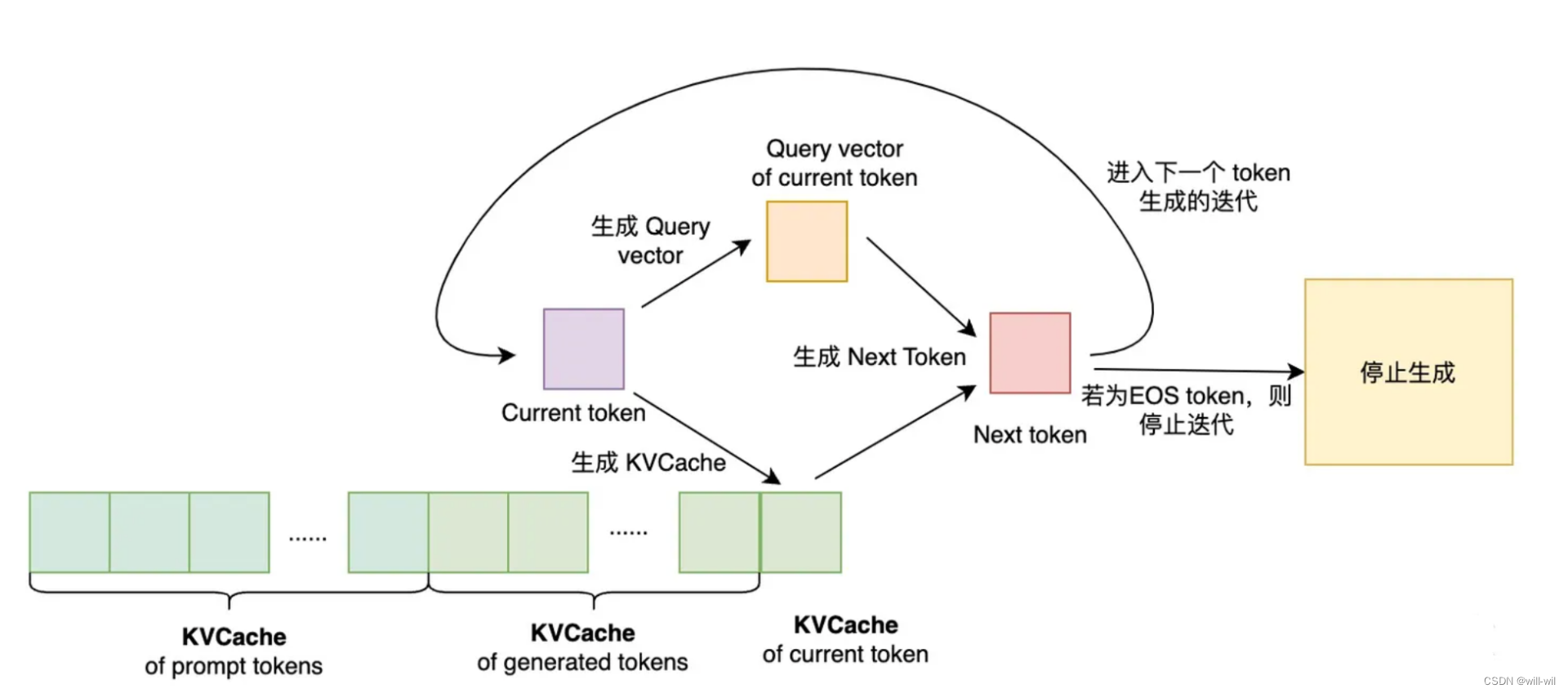
-
Prompt阶段:通过用户输入的prompt计算第一个生成token的条件概率,即生成第一个 token。生成过程中得到 prompt token 的 KVCache,用于后续 token 的生成。
-
Decode阶段:逐步迭代生成每个 token,在生成第t+1个token时,需要将prompt token、已生成的 token 及当前第t个token 的 KVCache拼接起来,与第t个token的query vector 完成SelfAttention等计算,由于数据依赖性,无法并行,是LLM推理性能的主要瓶颈位置
LLM模型batch推理
batch推理能提升模型服务的吞吐,常规模型服务的batch推理策略:
-
设置一个 batch推理延时以及最大 batch size;
-
收到新请求时将请求入队,判断请求队列中的请求数是否达到最大batch size或者最早请求与最迟请求的到达时间差是否达到batch推理延时
-
对合并后的模型输入进行batch推理,结果返回客户端
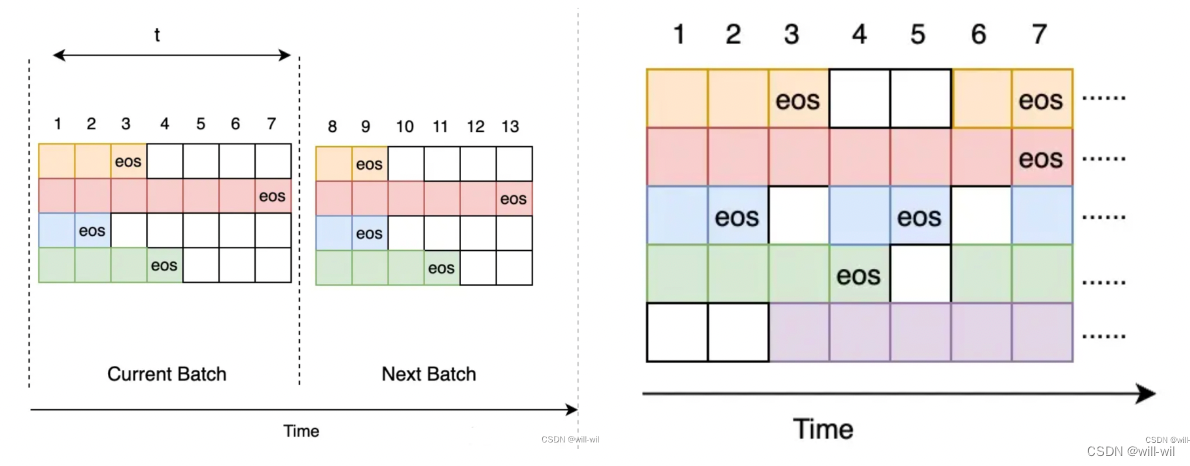
常规的模型服务的batch推理策略的问题:
-
请求端到端延时提升:batch推理延时和队列等待延时。生成单个 token 耗时在毫秒级别,那么生成千级别 token 数 Decode 耗时基本在秒级别,所以等待延时可达秒级别
-
GPU计算、存储资源有效利用率低:模型输入输出的长度不一致。
-
对于不同的输入长度,模型在构造输入的时候会进行padding,浪费GPU计算资源。
-
对于不同的输出长度,整个batch推理结束服务才会返回结果,已经完成推理的请求会一直空转,导致GPU资源的浪费
-
vLLM框架针对此问题提出的优化:
-
解决办法:
-
提出Iteration-Level请求调度方式,与Request-Level方式相比,请求调度的粒度减小了
-
当完成一轮Decode迭代时,如果Batch内有请求完成推理(即生成EOS token),则将该请求剔除出Batch;如果有新的请求进入,则将新请求加入到当前 Batch 进行推理。
-
-
Iteration-Level请求调度方式的优点:
-
延时方面:大幅度降低请求端到端延时,队列等待时间从原来的秒级别下降到毫秒级别。
-
资源利用率方面:避免数据空转和输入数据padding,提升GPU资源有效利用率
-
LLM服务的内存挑战
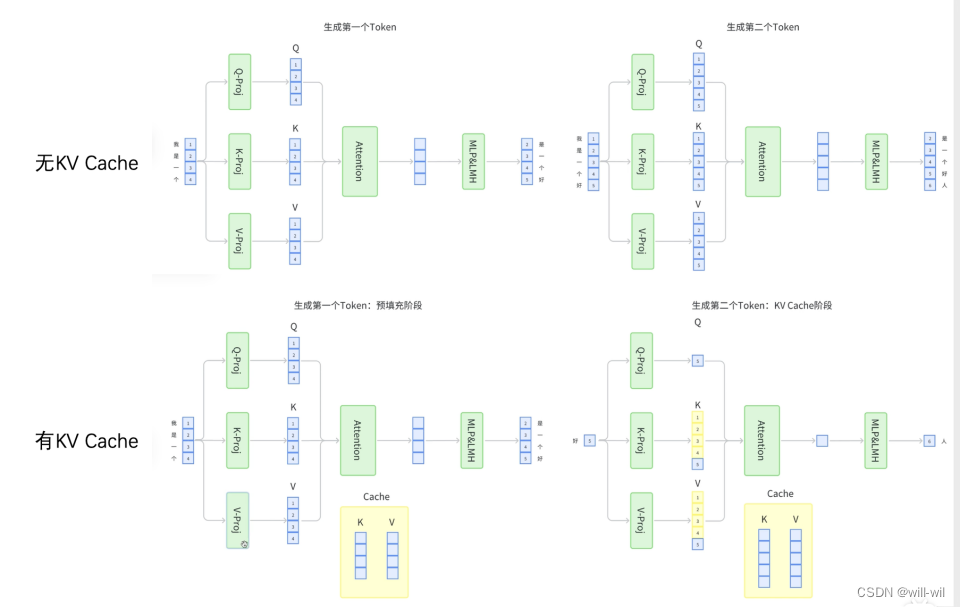
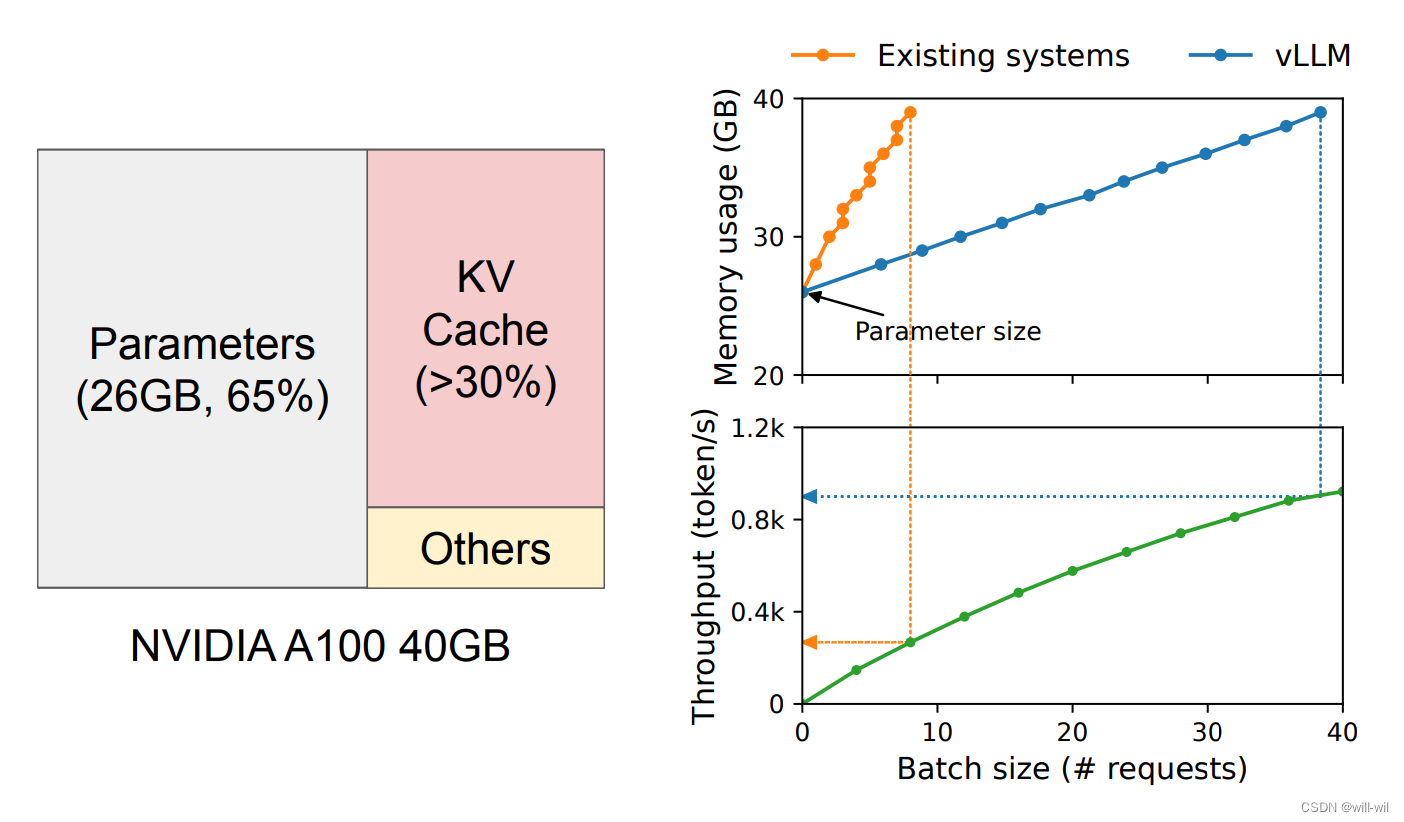
-
单次推理合并越多请求,吞吐越高,但是能同时推理的请求数是会受限于显存的,LLM服务显存占用主要由三部分组成:模型权重、KVCache 以及其他激活值
-
Large KV cache的限制:
-
KV cache Memory大小 = 2 x batch_size x num_layers x max_seq_len x hidden_size x sizeof(dtype)
-
假设13B的OPT模型,单个token的KV cache需要800KB(2x5120x40x2),如果生成2048个token,则需要1.6GB的显存存储

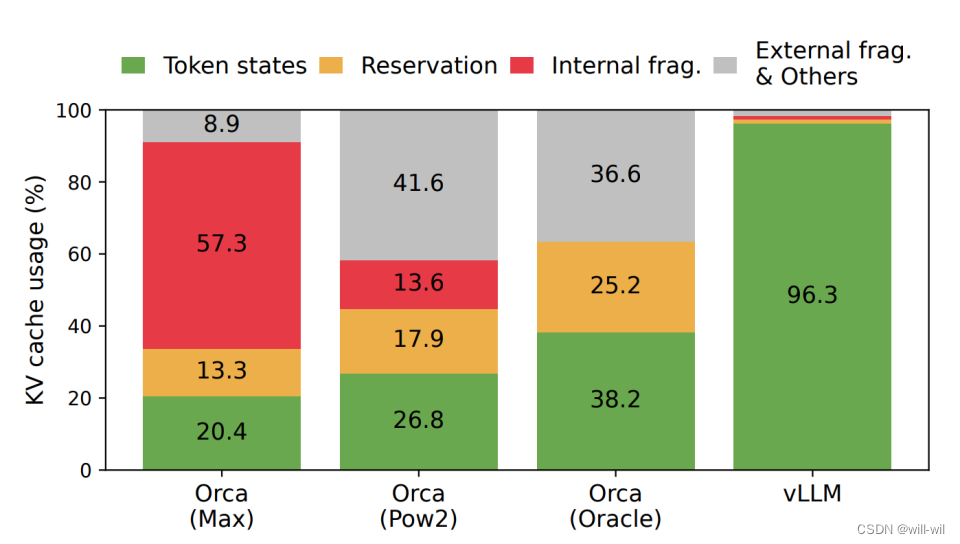
-
-
Memory Management in Existing Systems:现有系统存在以下三种资源浪费
-
外部碎片:深度学习框架一般都会将tensor存储在连续的内存中(pytorch .contiguous()),KV cache存储亦如此
-
内部碎片、预存显存:LLM输出是不可预测的,现有系统会默认给每个请求分配最大可能长度的内存块,其他请求不可用
-
-
vLLM框架提出的内存管理优化方法:核心为PageAttention模块-自定义了CUDA内核进行处理
-
PageAttention允许将一个序列的KV Cache存储在非连续的物理块上,每个块上存放固定数量token的KV数据
-
os虚拟内存的内存管理方法
-
os会将平台内存划分为多个固定大小的物理内存page,映射用户程序的逻辑page到物理page,连续的逻辑page可以对应到非连续的物理内存page,不提前分配物理内存,统一由os动态按需分配。
-
-
解决的方法:
-
连续的逻辑page对应到LLM的解码token序列,只预留最后一个block作为当前请求未来generate token的预留填充。
-
构建block表,记录每个逻辑block对应的物理block位置以及每个物理block已经填充的token数量,通过将逻辑、物理KV block进行分离,实现动态增加KV cache的能力。
-
举例:客户端传来一个请求,输入首先使用self-attn对prompt进行处理,将KV存到物理块中,并解码得到第一个token,第二次解码则是获取物理块中的KV数据使用pageAttention进行计算,当物理块存在空位则直接填充,若不存在空位则重新分配一个新的物理块,只有当前面的block已经被全部填充才会分配新的block,将内存浪费缩小到一个block,从而可以容纳更多的请求提升吞吐量


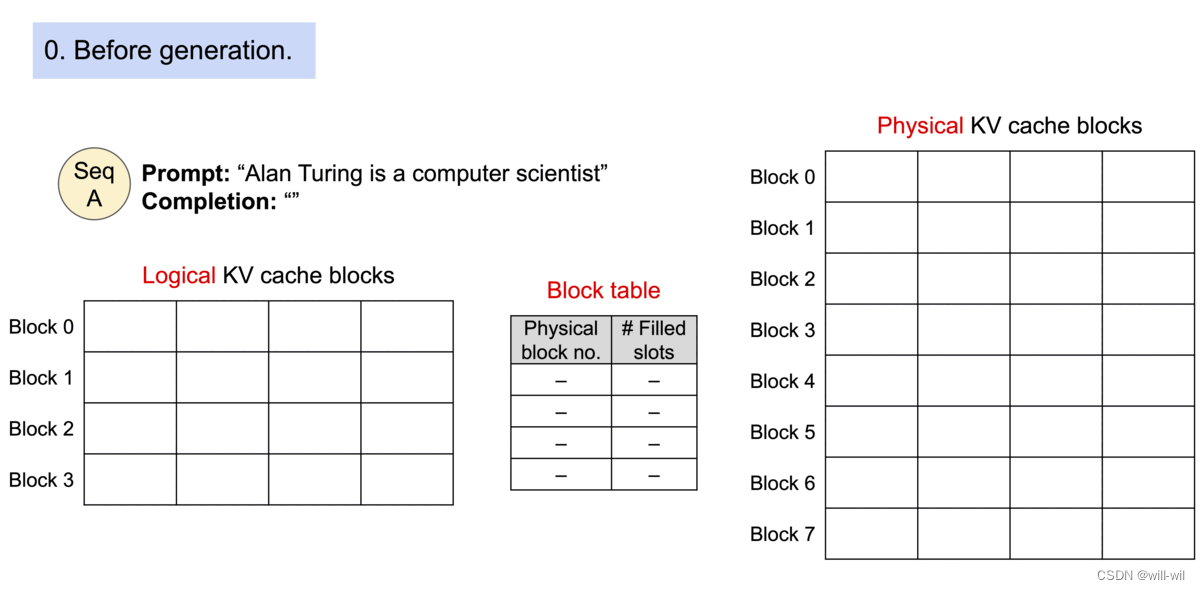
-
-
-
对于不同的采样策略,进行不同的内存优化
并行解码:单个prompt输入,输出多个采样输出,用户从中挑选一个最优结果。
-
-
内存优化方法:
-
共享输入prompt token的内存。父节点迭代一次后,子节点会共享父节点之前的物理block,导致父节点的ref+=1
-
学习os虚拟内存的写时复制机制,本文实现了一个块粒度的写时机制,一个物理块能被多个逻辑块映射,通过ref count参数表示引用次数,当一个物理block需要被多个seq修改的时候才会调用
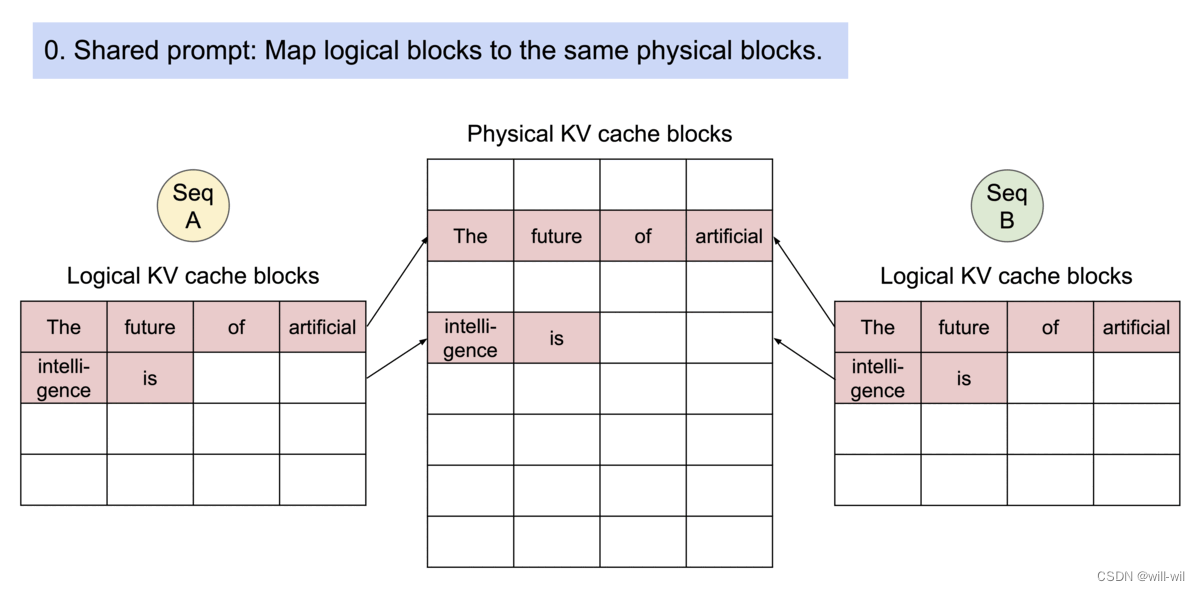
-
-
Beam search解码:集束搜索,单个prompt,推理期间多条路径解码,输出一个结果(不复制n份推理,topn会产生n个不同结果继续推理;如果复制n份推理,咋会得到相同的token的?)
-
内存优化方法:
-
先前的服务需要频繁复制beam分支之间所有的内存
-
vLLM的block共享机制可以大大减少复制开销,写时复制机制一般只需要复制一个block
-
按照output序列的困惑度进行排序,保留topN个序列。当物理block的ref count为0时,会执行内存释放操作
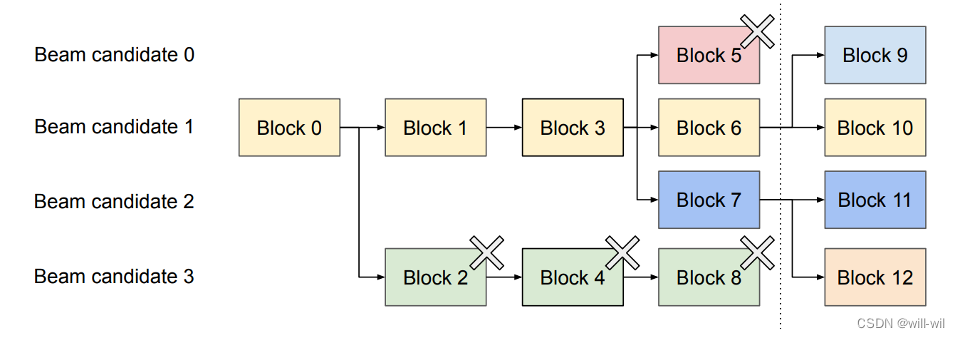
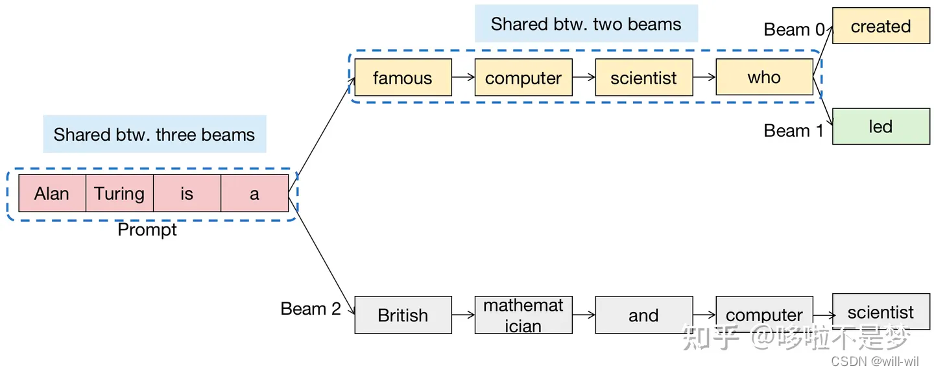
-
Shared prefix解码:
-
内存优化方法:
-
对于包含任务描述+示例类型+问题的用户prompt,服务可按照规律保存前置任务描述+示例类型的prompt KV物理块,只处理用户的问题、写时复制机制提高模型推理速度
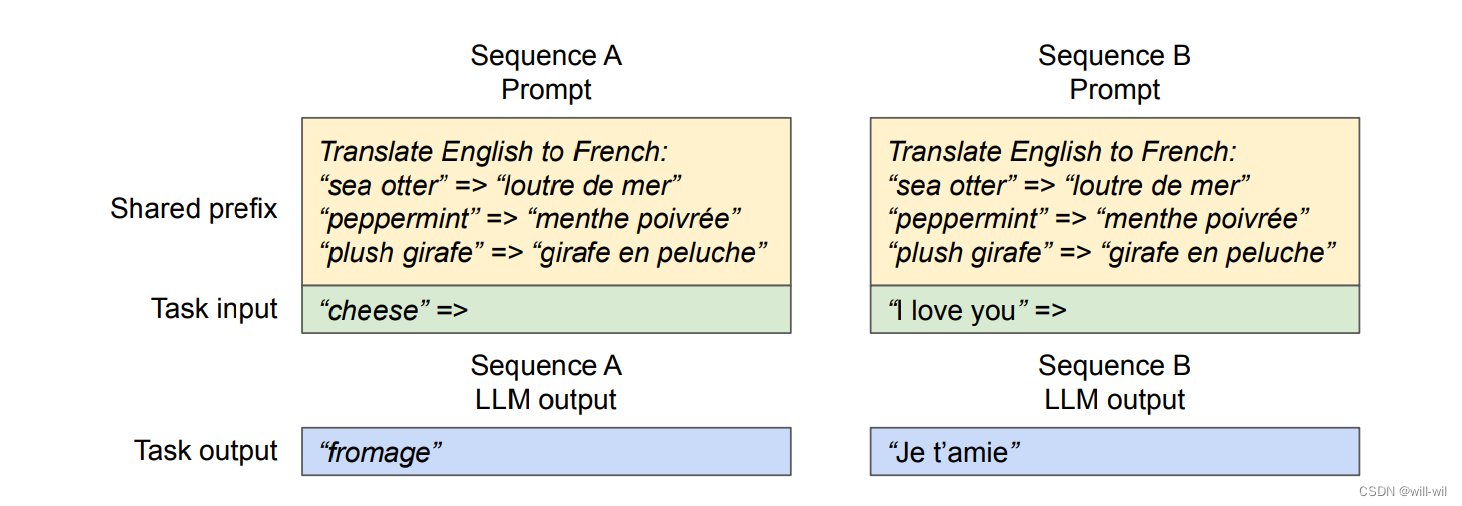
-
-
- Mixed decoding methods解码:由于逻辑block和物理block的优化,PageAttention模块的执行单元缩小到了单个物理block,使得vLLM框架能够实现不同解码请求的batch推理。
LLM服务的调度与抢占:
面临的问题:LLM输入的prompt长度不一,输出的长度是预先不知道的,随着请求和输出token的增多,可能会耗尽GPU所有的资源,需要面对两个问题1.应该驱逐哪些block?2.如果需要,如何恢复被驱逐的block?
解决的方法:
-
前提,一般情况会采用启发式方法驱逐最久访问的block,但是LLM解码有个特点,一个序列的所有block是一起访问的,是一个整体。同时,在beam search搜索的情况下,一个序列组内的多个序列存在内存共享的情况
-
方法:采用两种技术,两者性能优劣取决于带宽和GPU计算能力
-
交换:
-
类似os虚拟内存中使用的经典方法,将要被驱逐的page复制到磁盘上的交换空间。
-
在vLLM检测新生成的token没有空间存放时,会选择一组序列驱逐,复制KV cache到CPU中,同时停止接受新的请求。
-
当现有序列完成时会释放空间,再接回被驱逐的序列,直到被抢占的序列都完成才重新接受请求。
-
-
重计算:直接丢弃KV cache,保留解码生成的token,需要重新调度的时候,拼接输入的prompt和解码生成的token,可以显著低于原始的延迟,因为能并行获取KV特征
-
模型实验
不同采样策略和不同LLM服务时延的对比
不同block大小对于时延的影响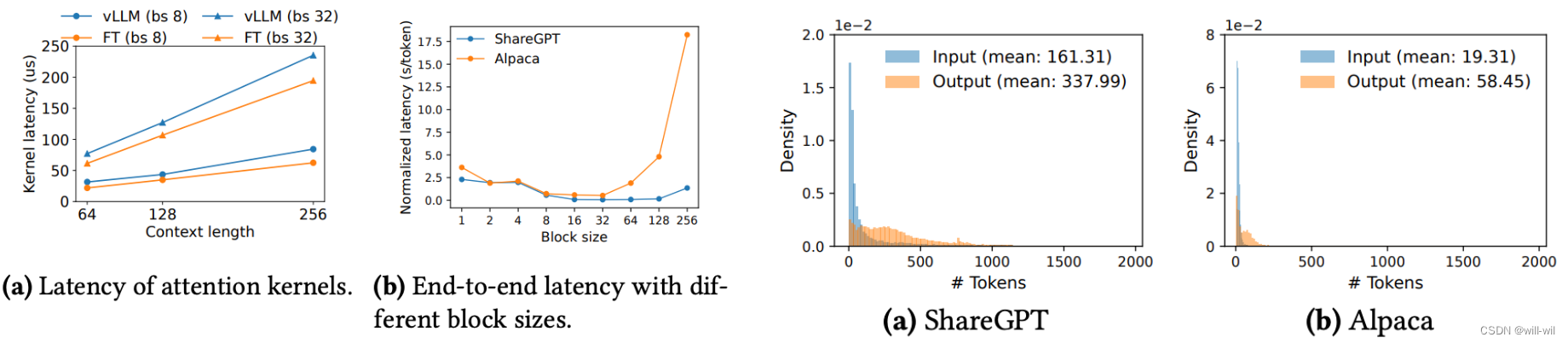
左图:attention内核模块的修改的时延对比
右图:block过小会降低GPU并行性利用率,block过大会导致内存共享率降低、内存浪费比例增大
不同抢占处理策略对于时延的影响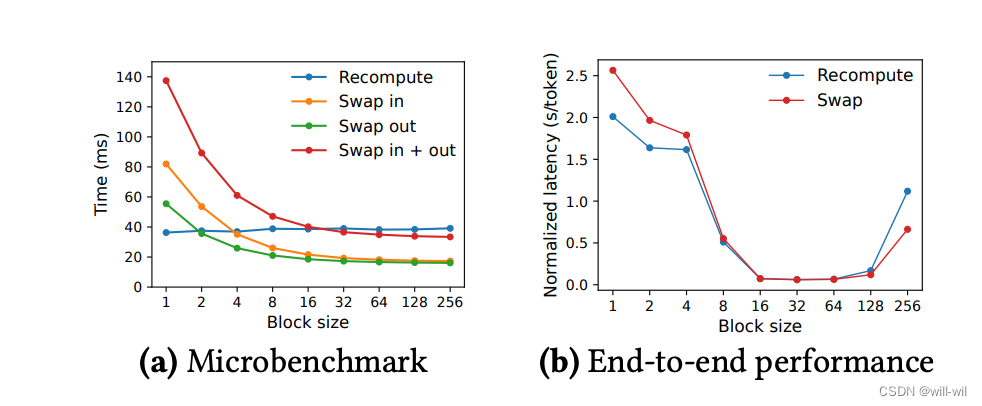
当block较小时,交换策略受限于带宽,重计算优于交换策略;当block较大时,交换策略优于重计算。

