
- 1八大排序时间复杂度与稳定性_八种基本排序及其时间复杂度
- 2微信小程序 | 云函数上的数据库操作_微信小程序 云函数 db.deletecollection
- 3stable diffusion 基础教程-提示词之艺术风格用法_stable diff 提示词 中国风
- 4Jmeter 中 CSV 如何参数化测试数据并实现自动断言
- 5adb connect:由于目标计算机积极拒绝,无法连接。 (10061)_adb connect 由于目标计算机积极拒绝,无法连接
- 6Jenkins构建时报错 ERROR: Error fetching remote repo 'origin' hudson.plugins.git.GitException
- 7GoF之代理模式
- 8Android Studio通过点击按键button返回上一个页面,且不改变上一个页面的任何值_android button 实现页面返回
- 9基于docker安装elastalert2进行慢日志邮件报警_elastalert2 邮件
- 10解决npm install 报错 “npm err code 1“_npm err! code 1
笔记1--Llama 3 超级课堂 | Llama3概述与演进历程
赞
踩
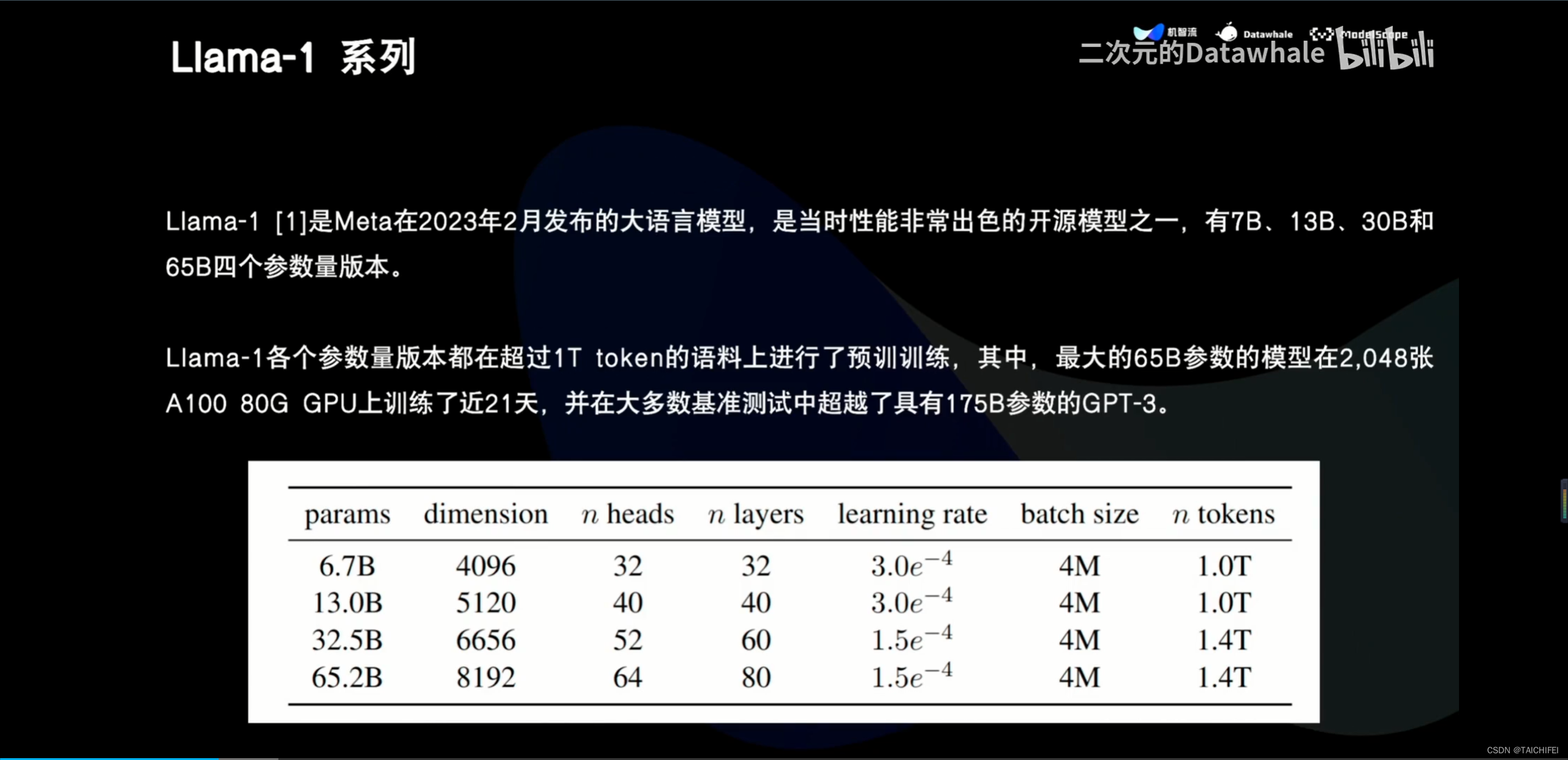
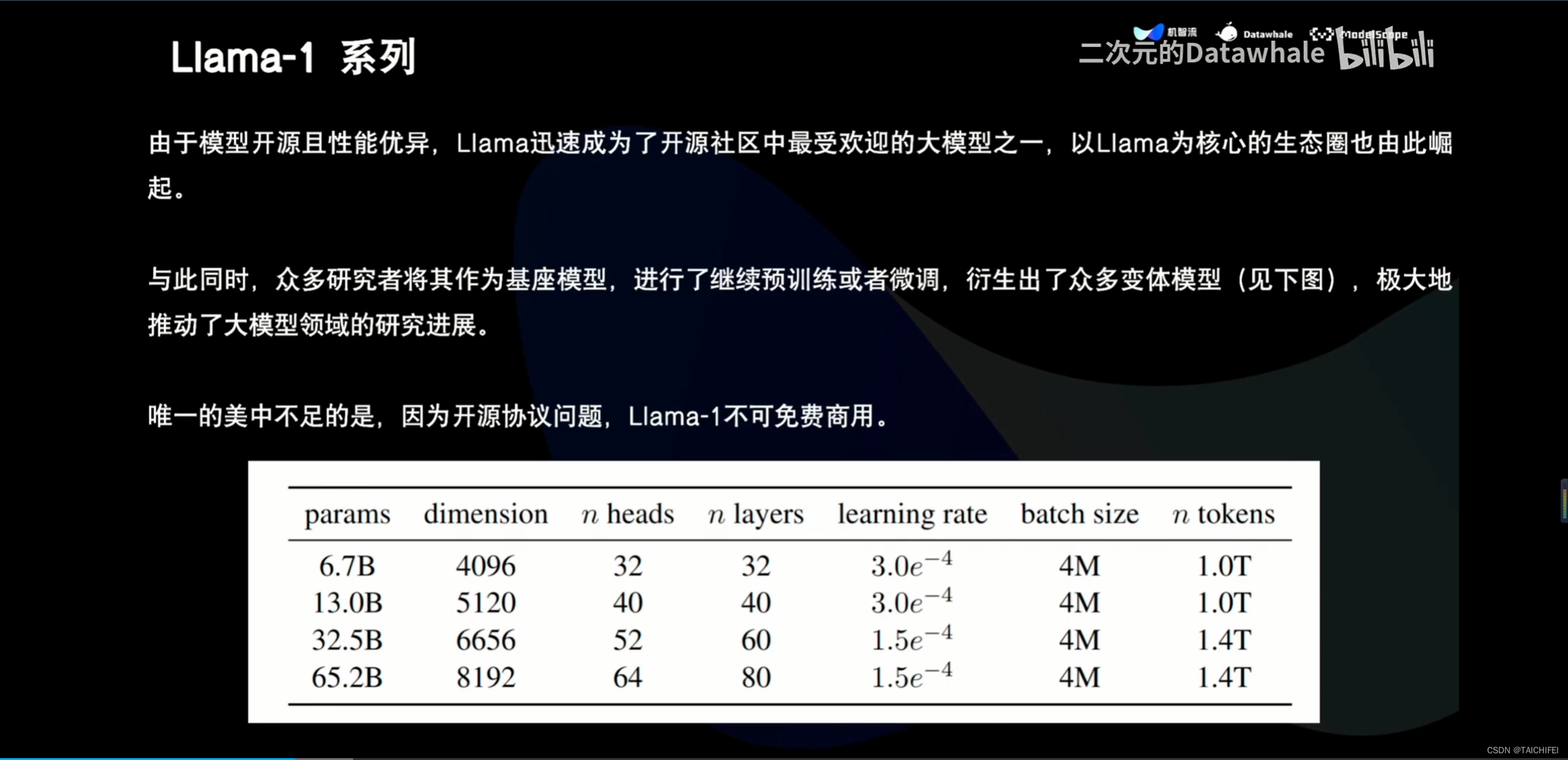
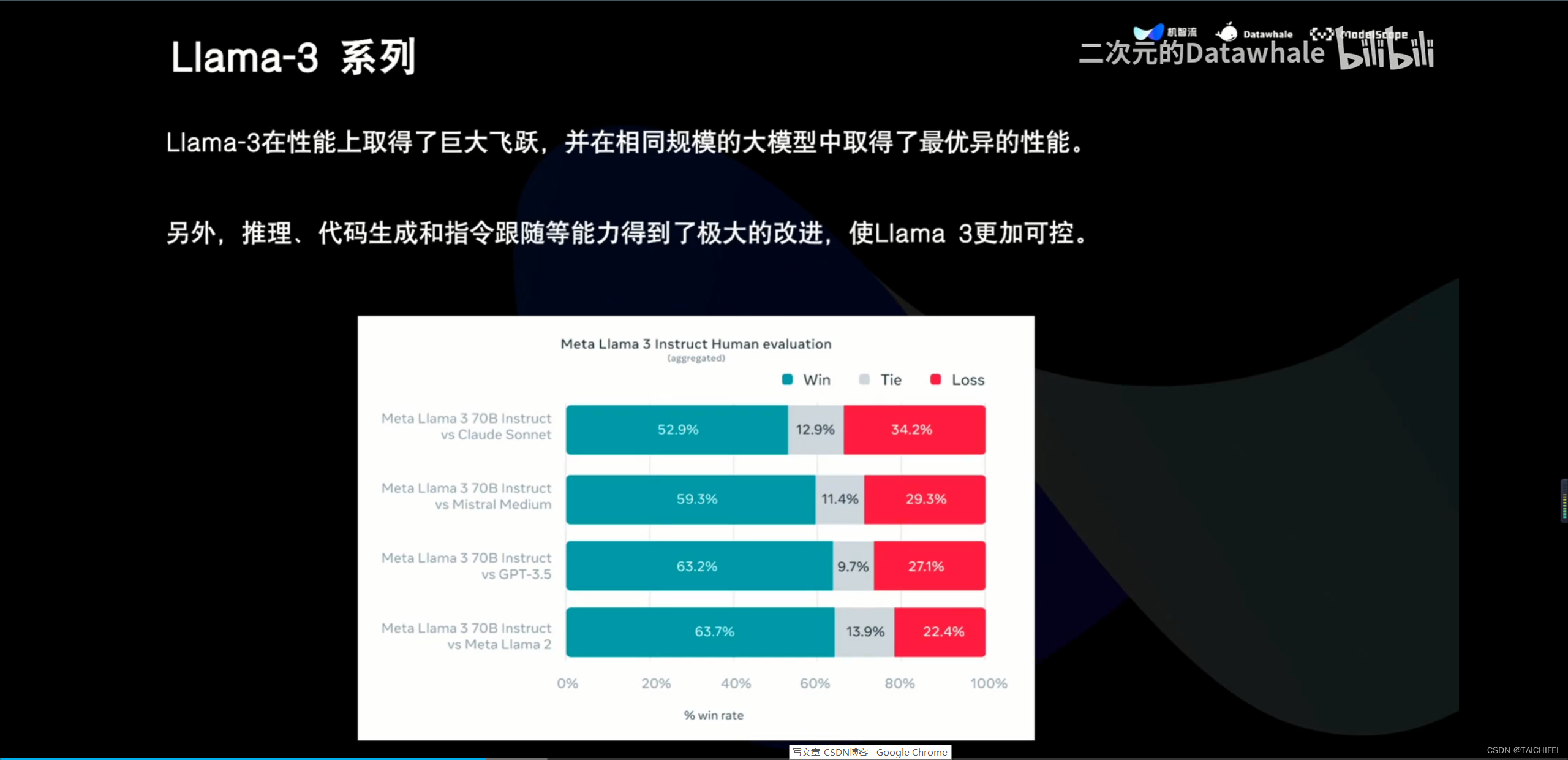
1、Llama 3概述
https://github.com/SmartFlowAI/Llama3-Tutorial.git
【Llama 3 五一超级课堂 | Llama3概述与演进历程】





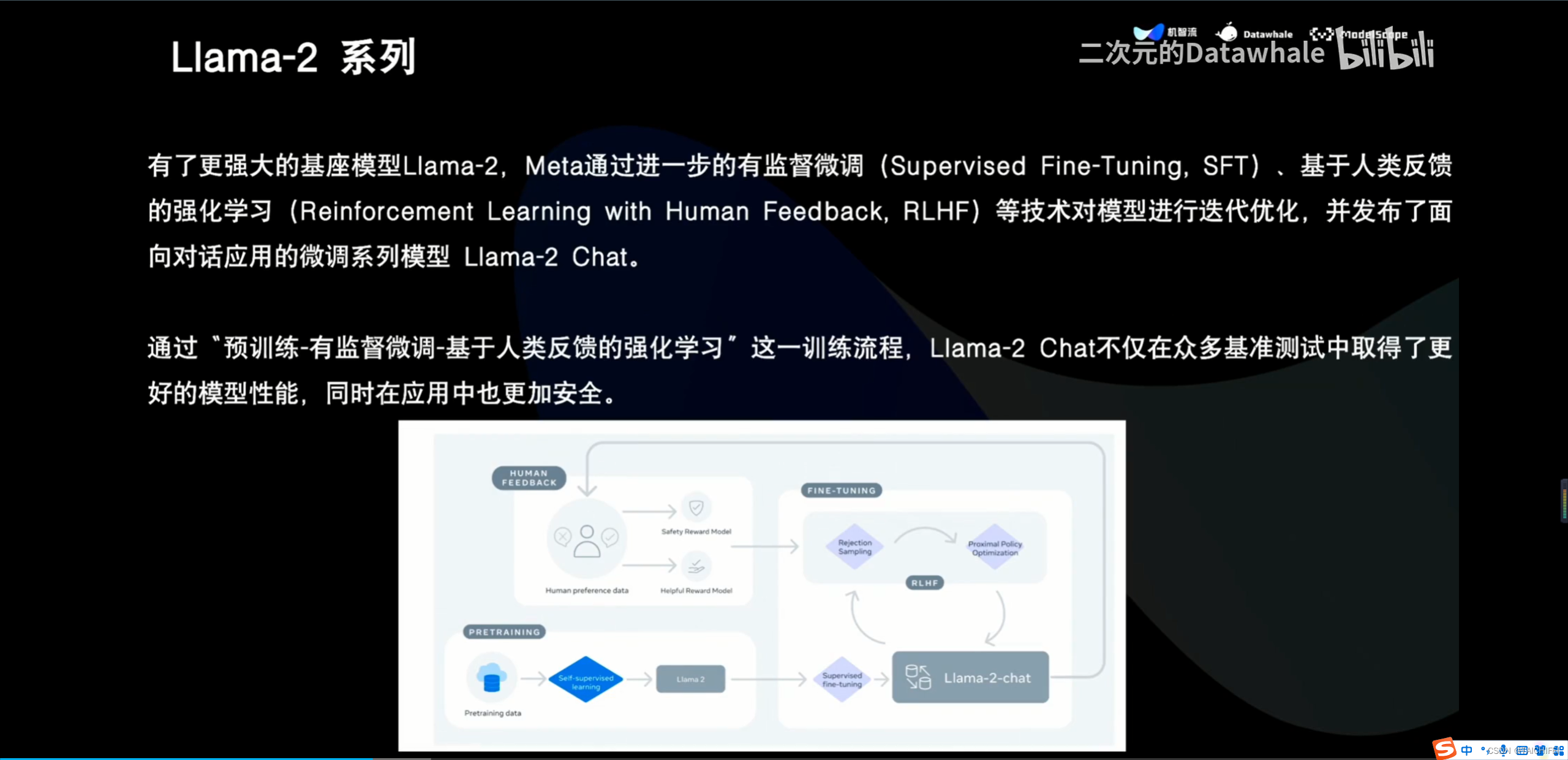
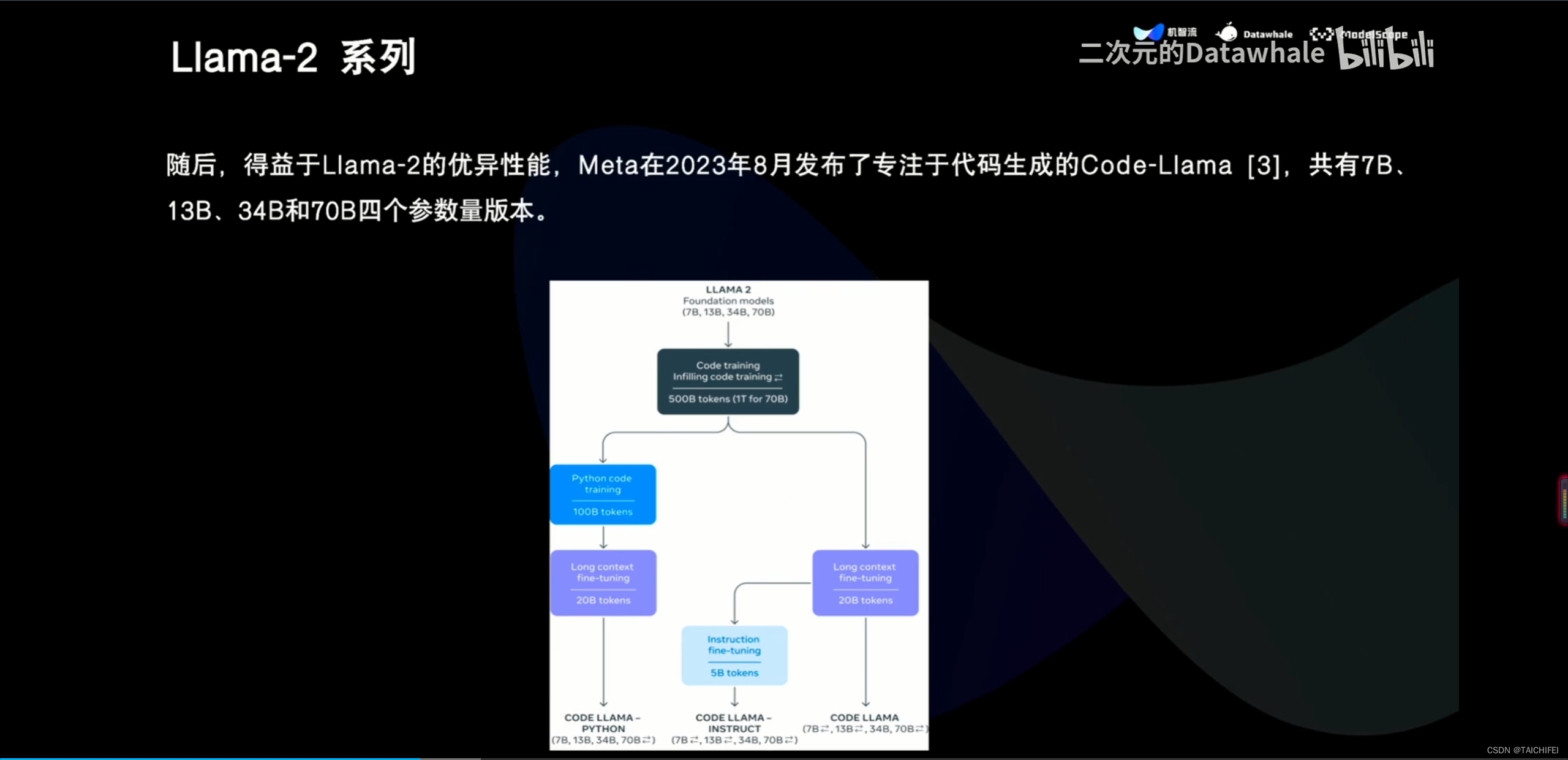

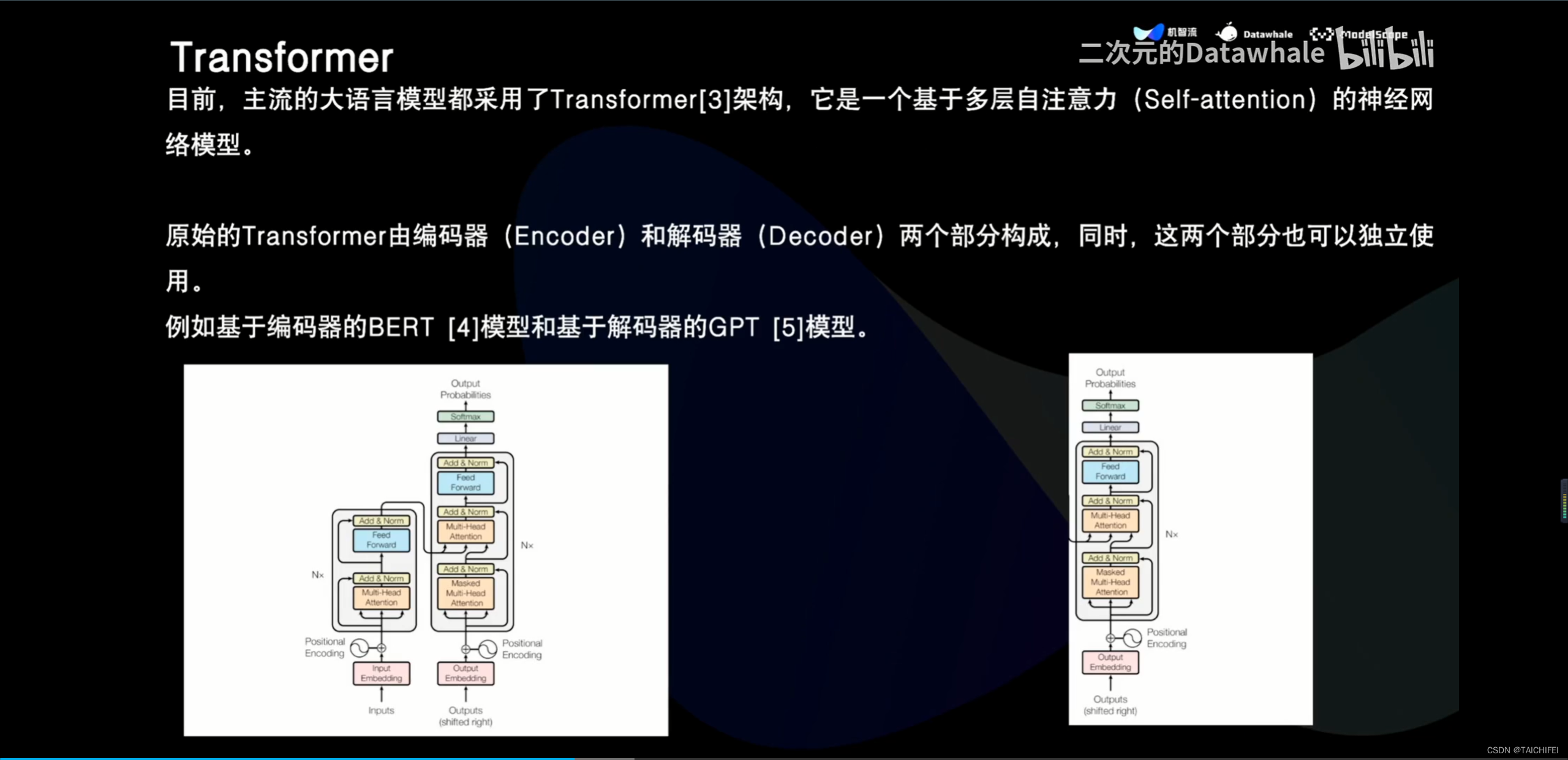


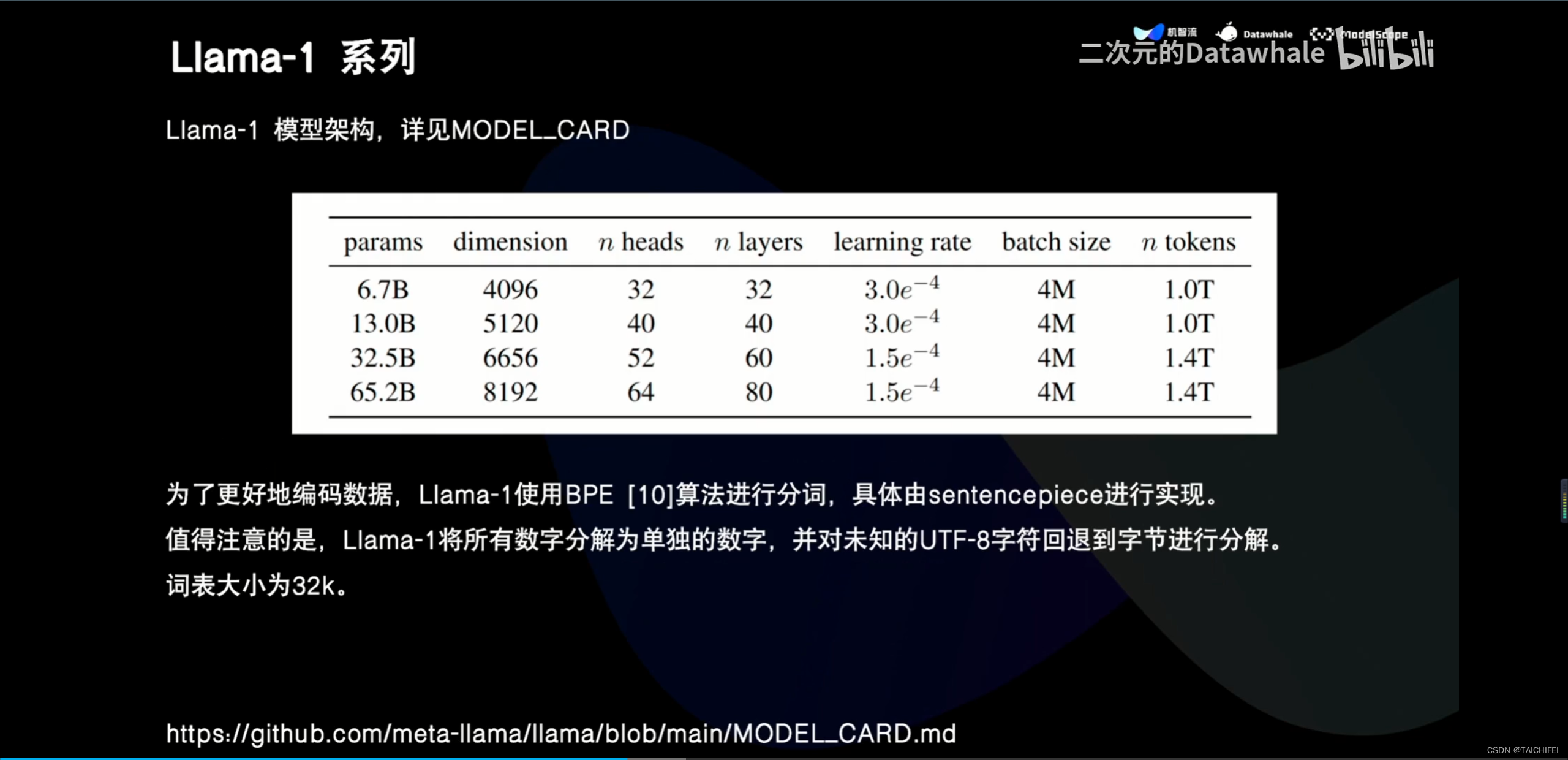
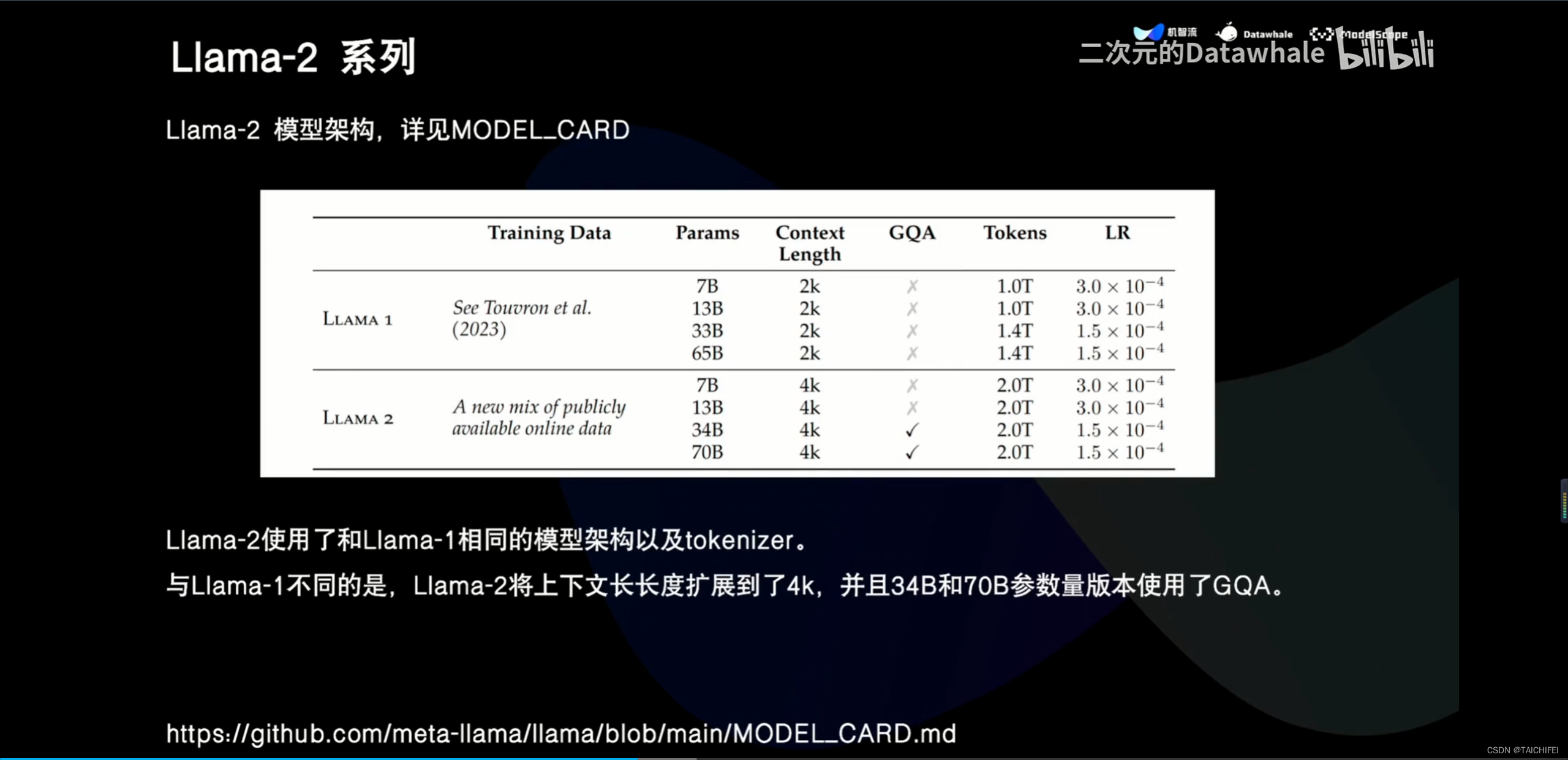
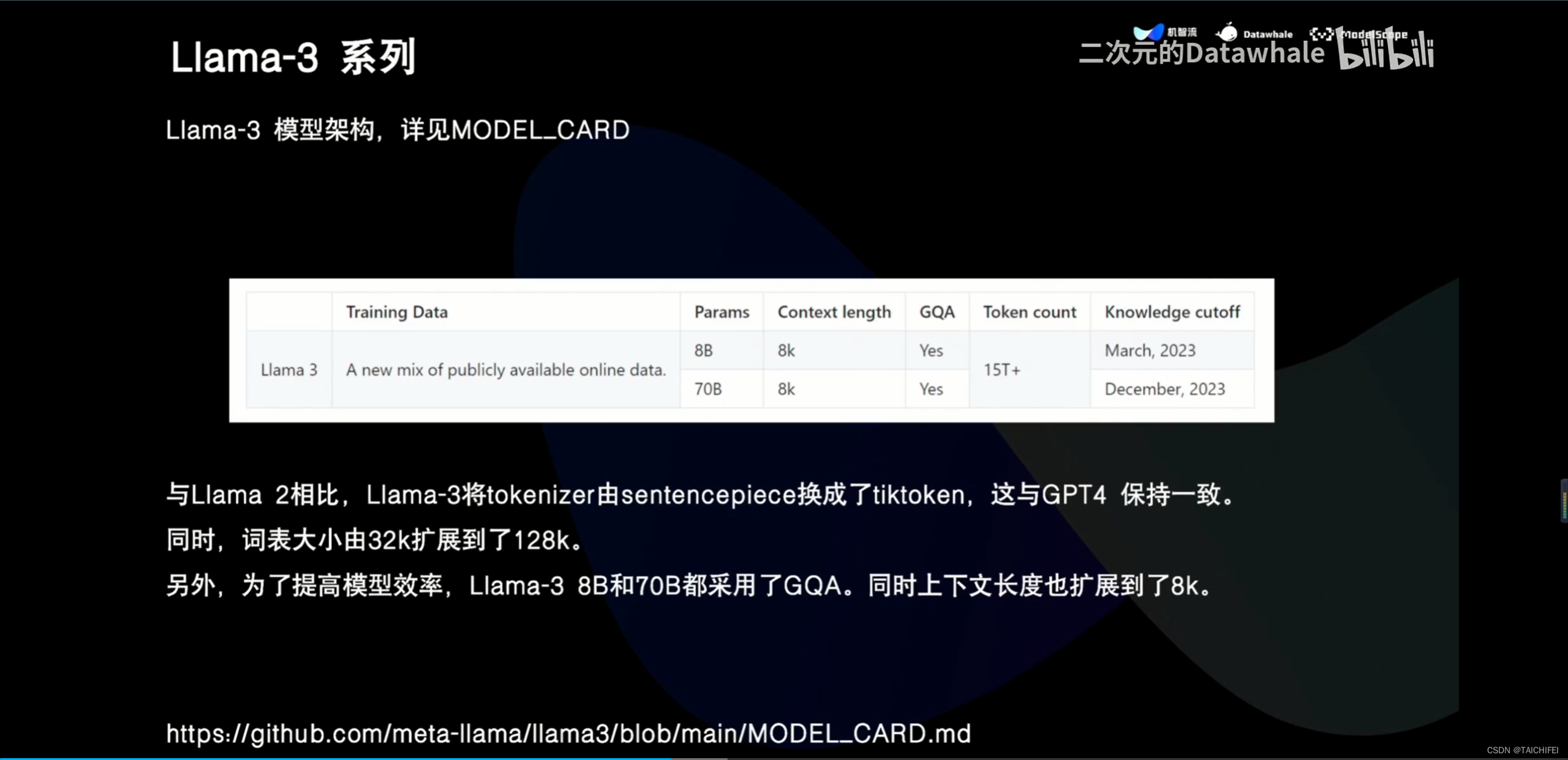
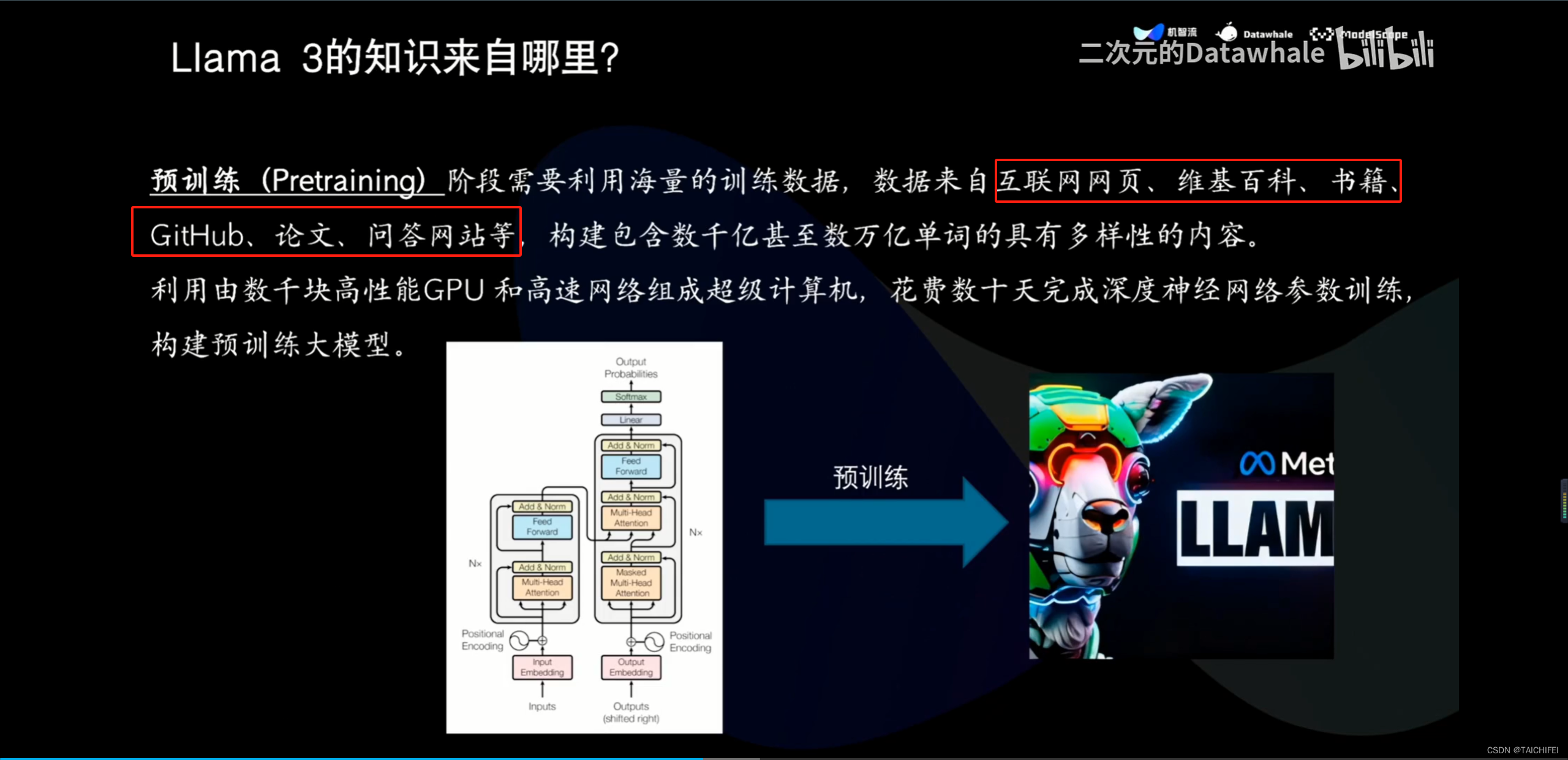

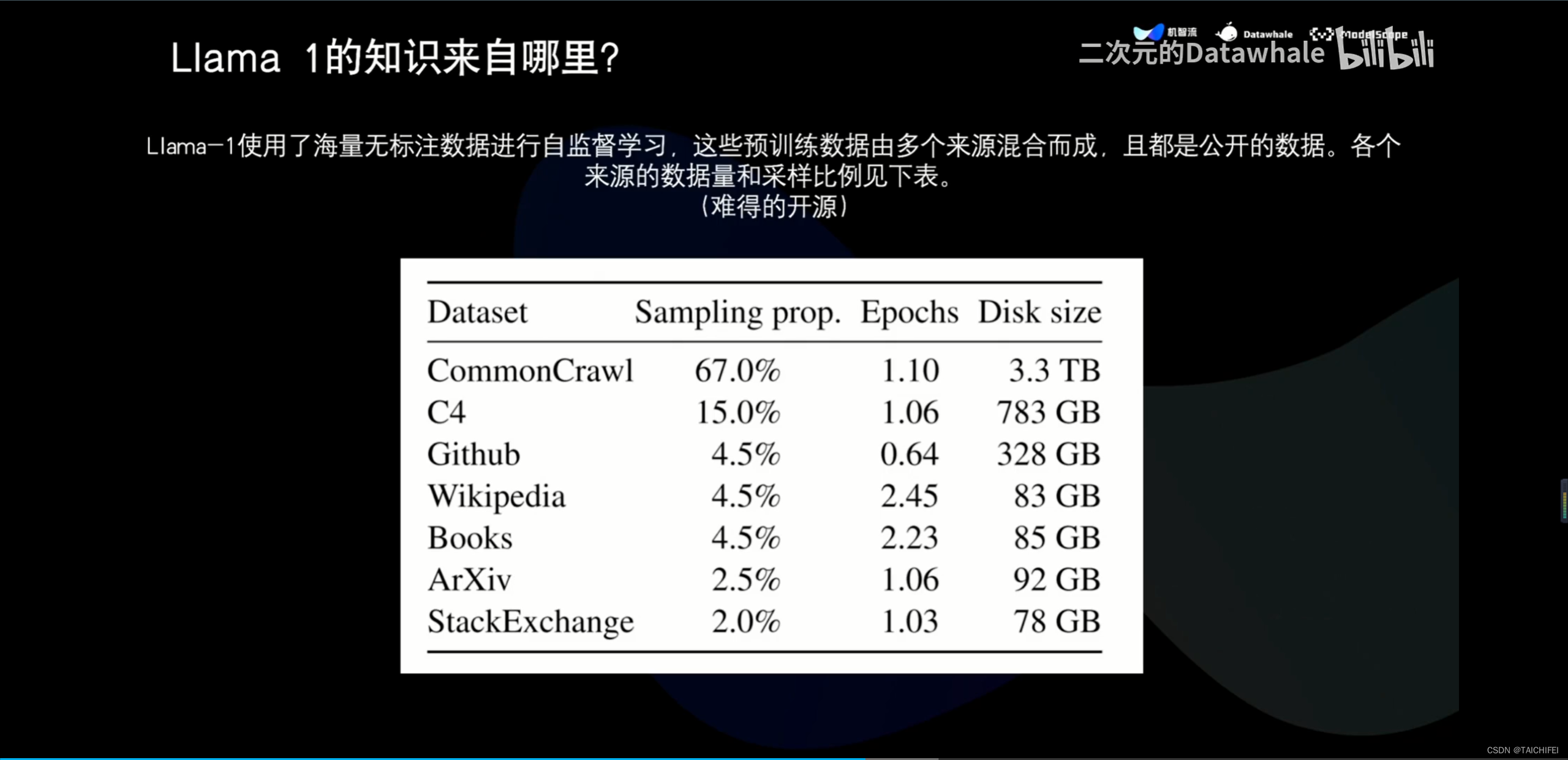
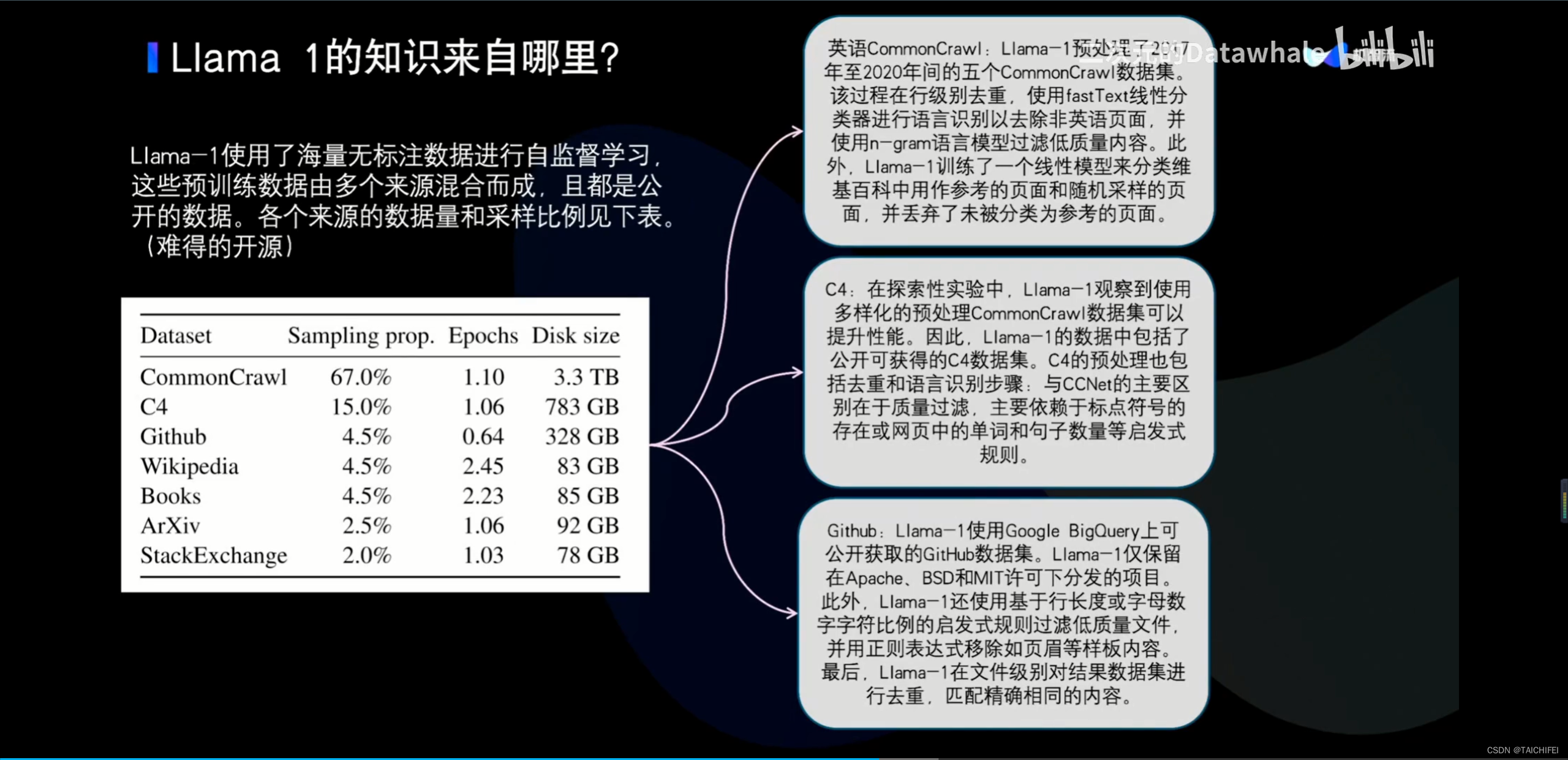
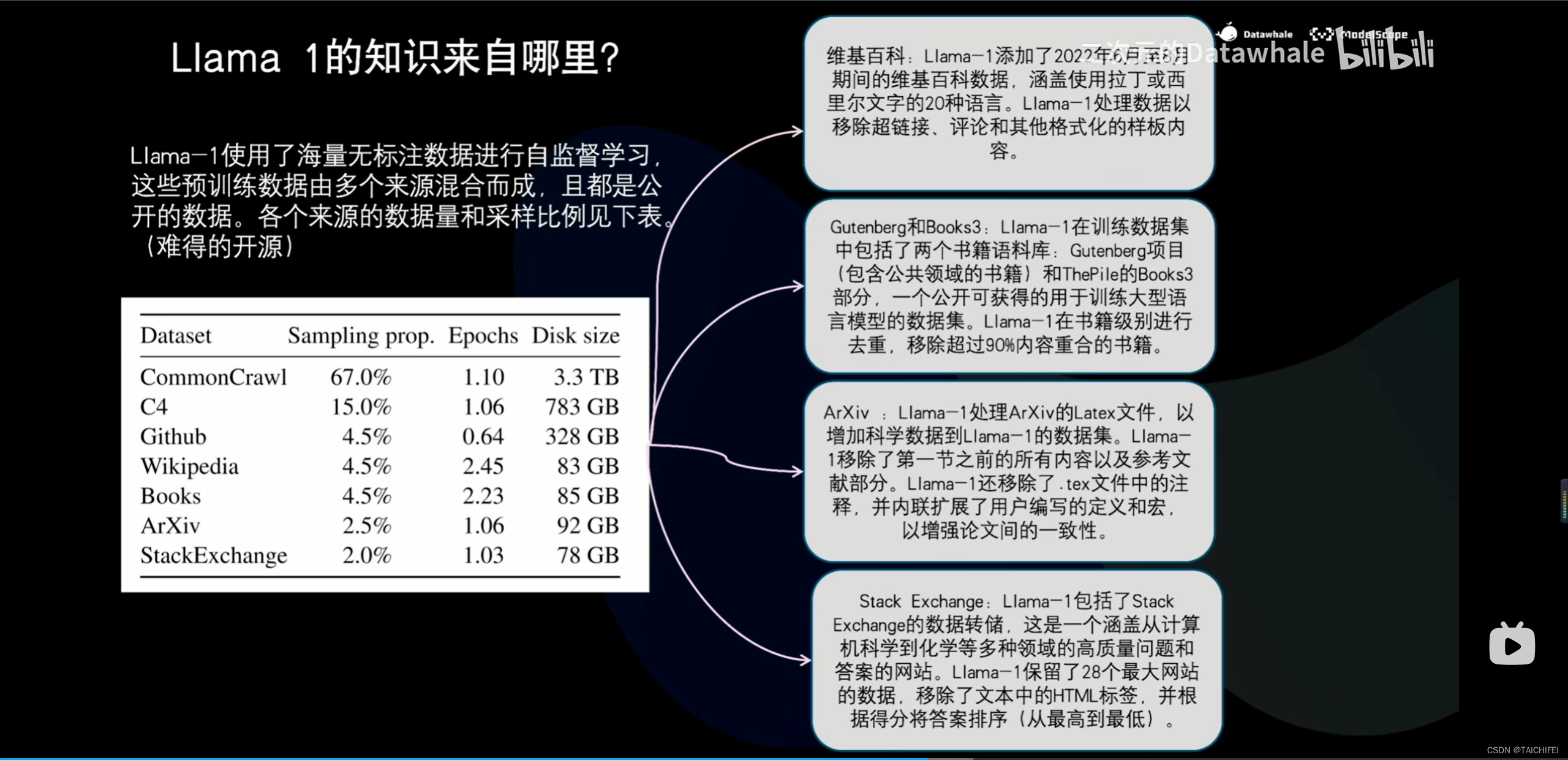
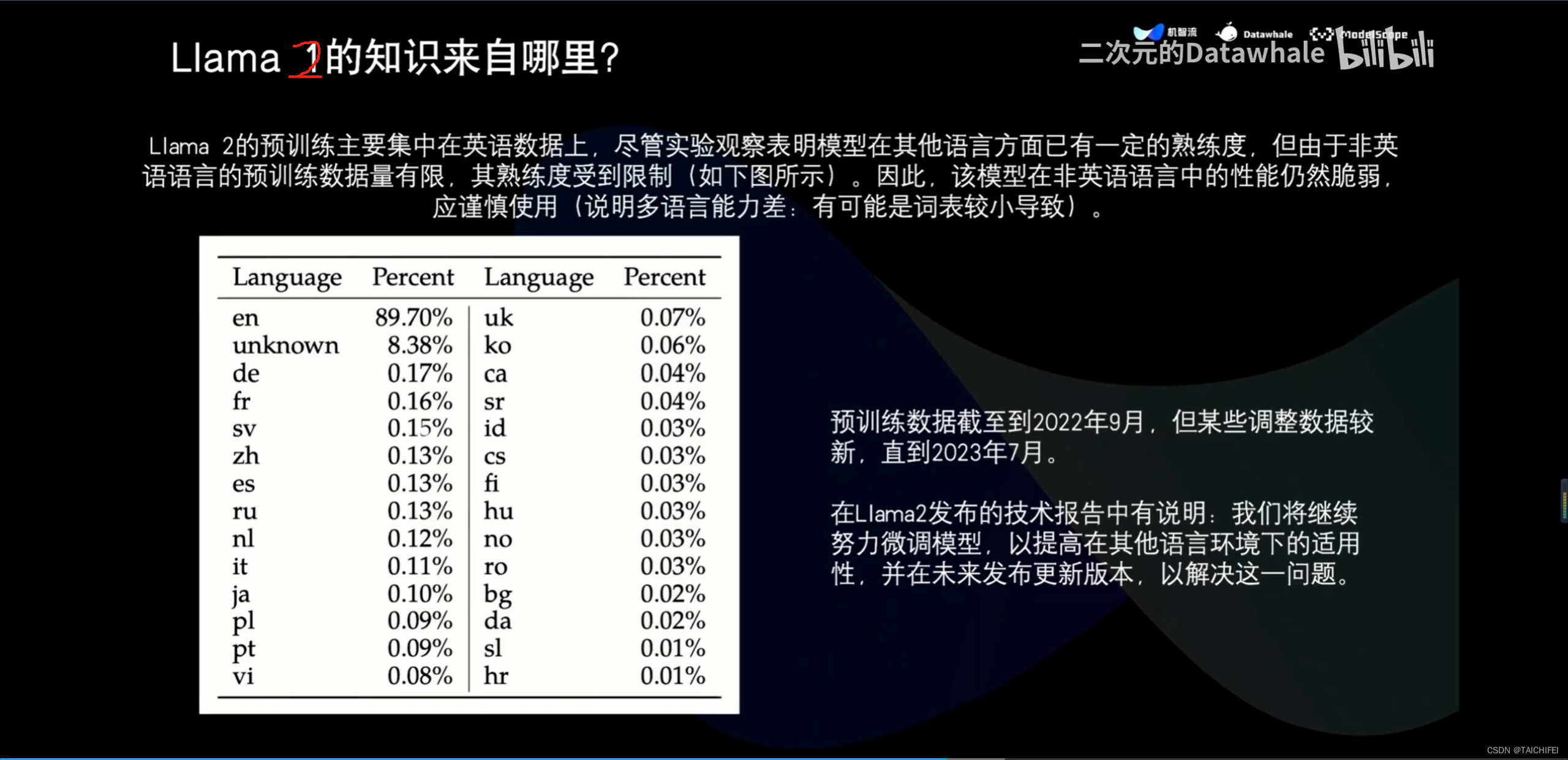



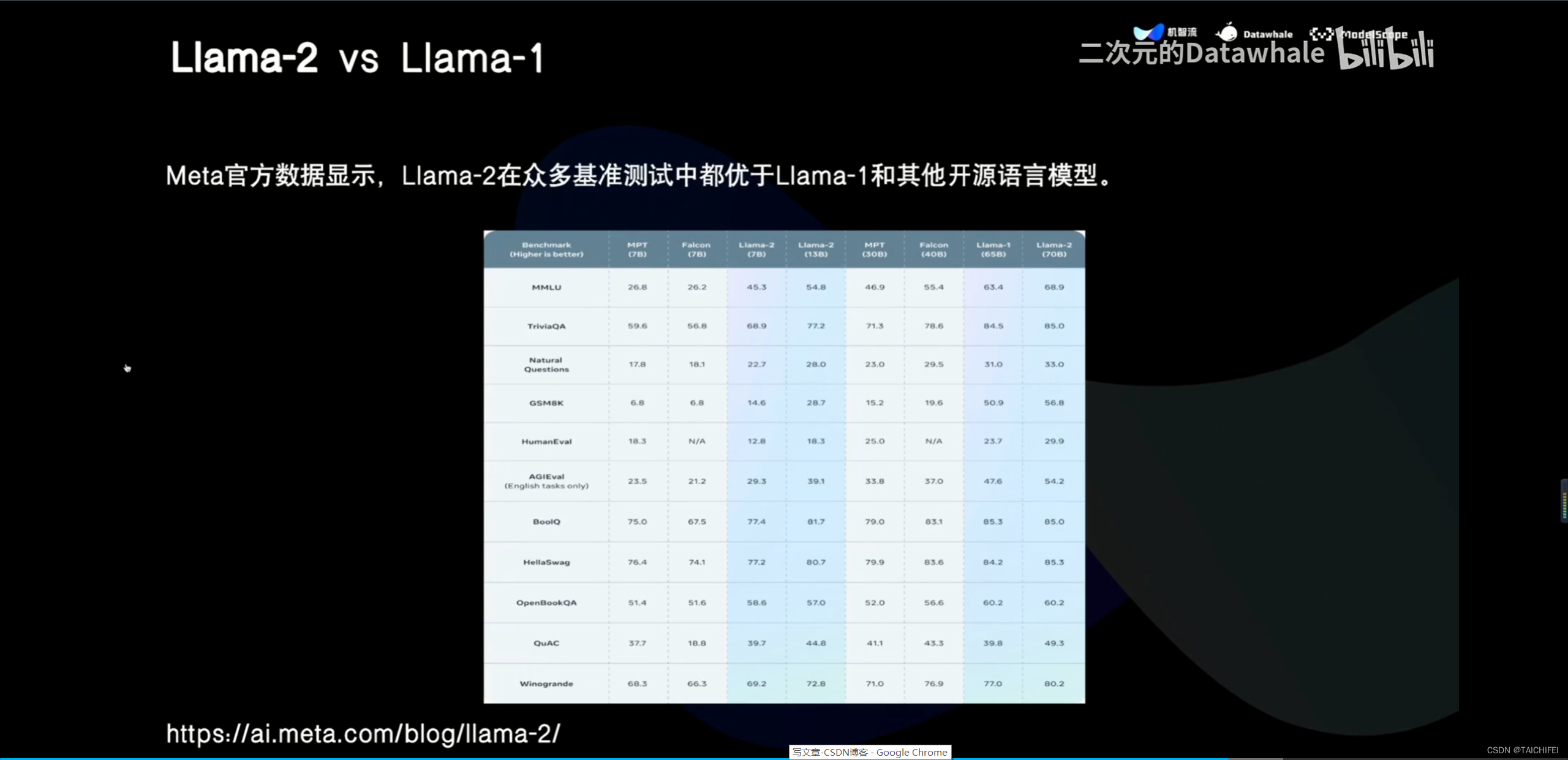
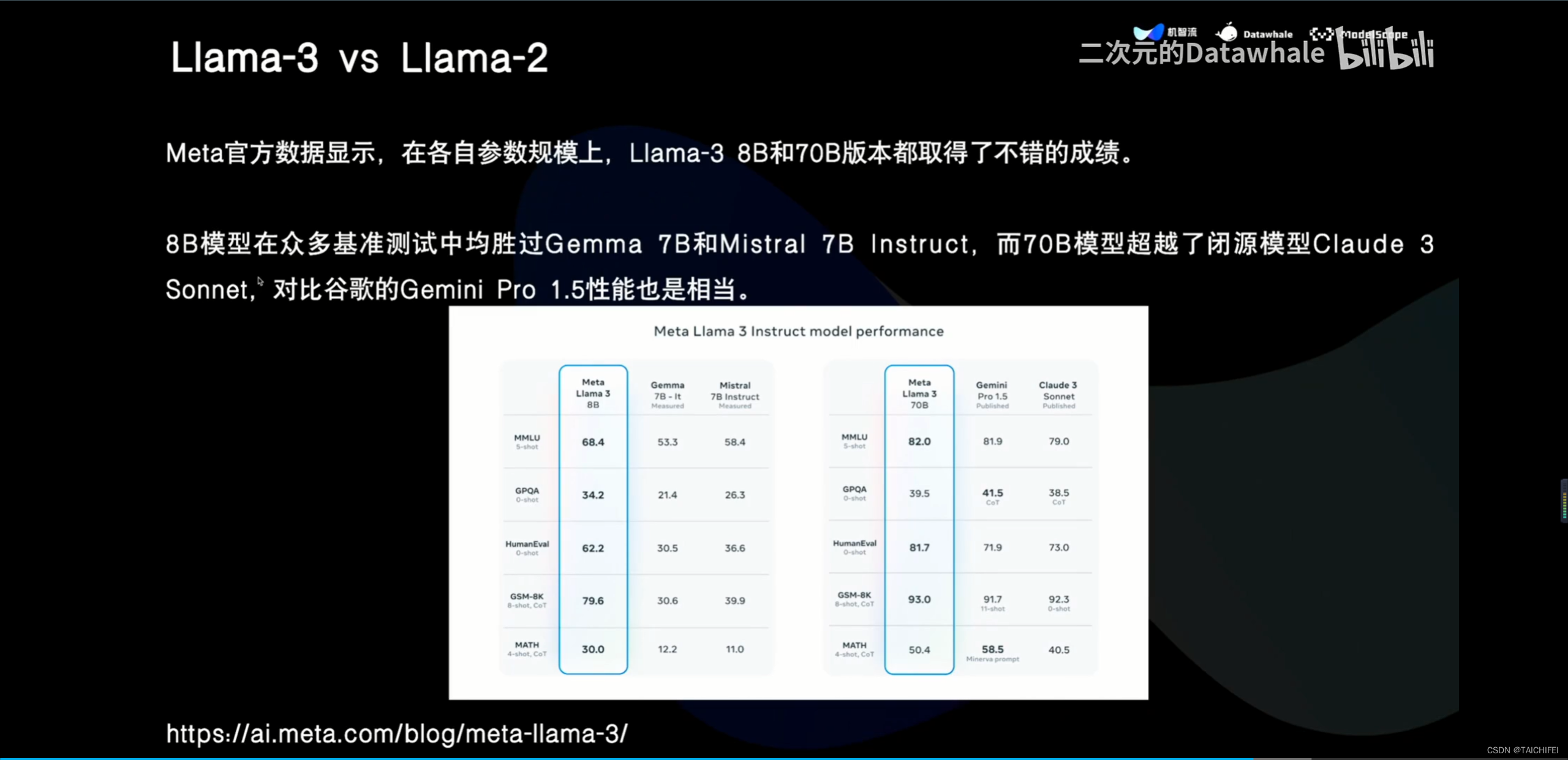

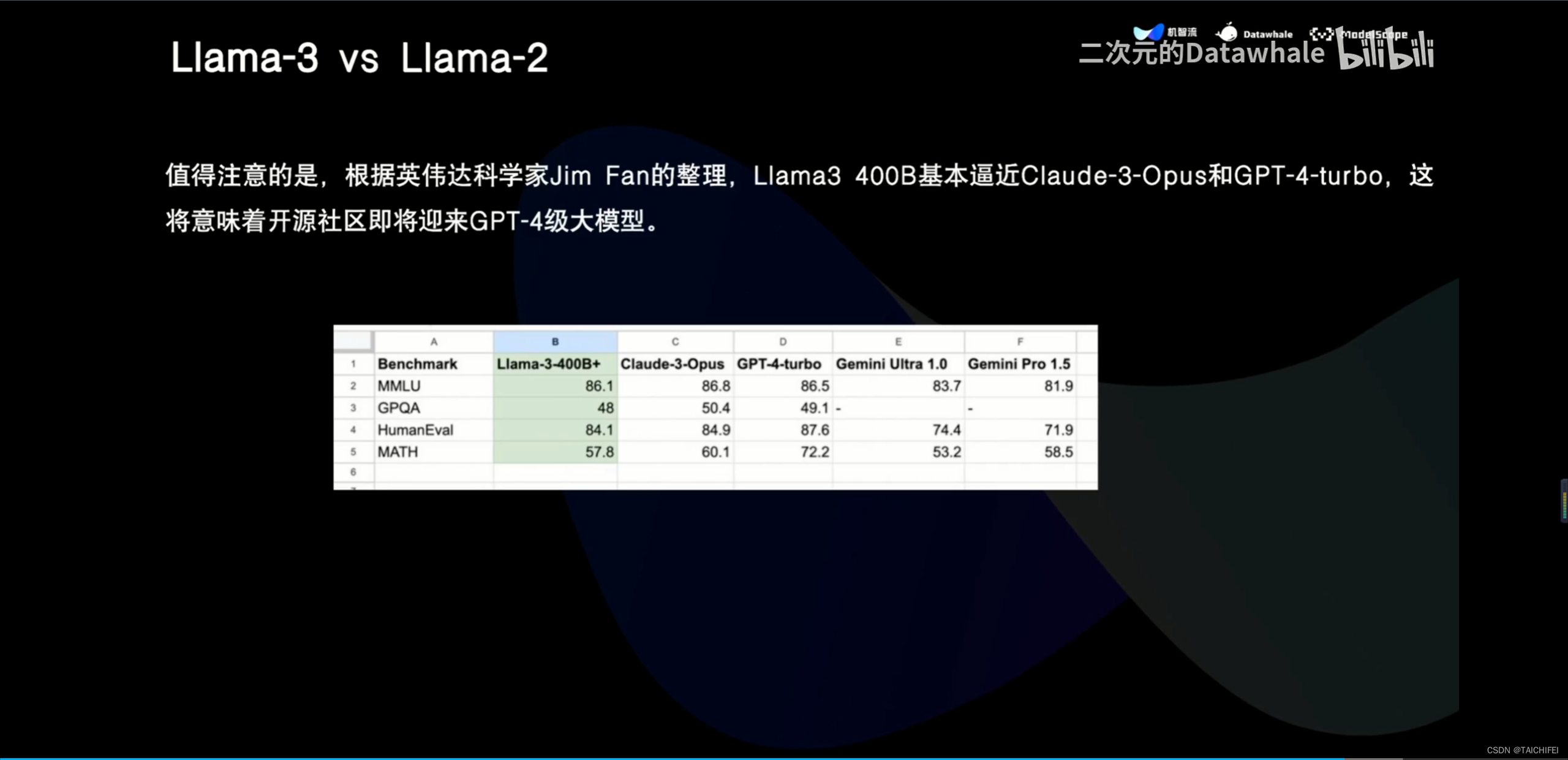
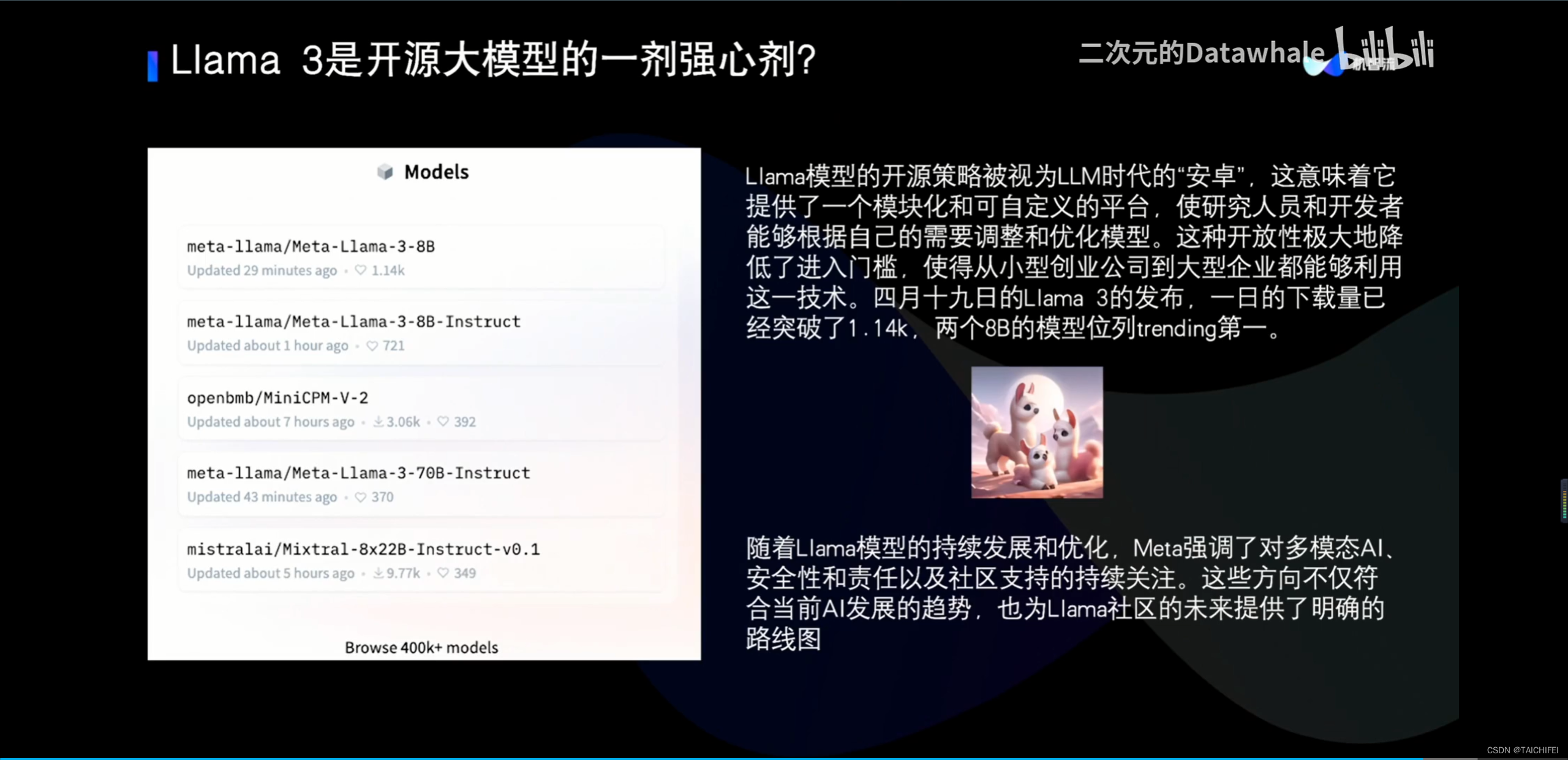
2、Llama 3 改进点
【最新【大模型微调】大模型llama3技术全面解析 大模型应用部署 据说llama3不满足scaling law?】 https://www.bilibili.com/video/BV1kM4m1f7iM/?share_source=copy_web&vd_source=dda2d2fa9c7a85f3fb74cf7ccca3de22
GQA
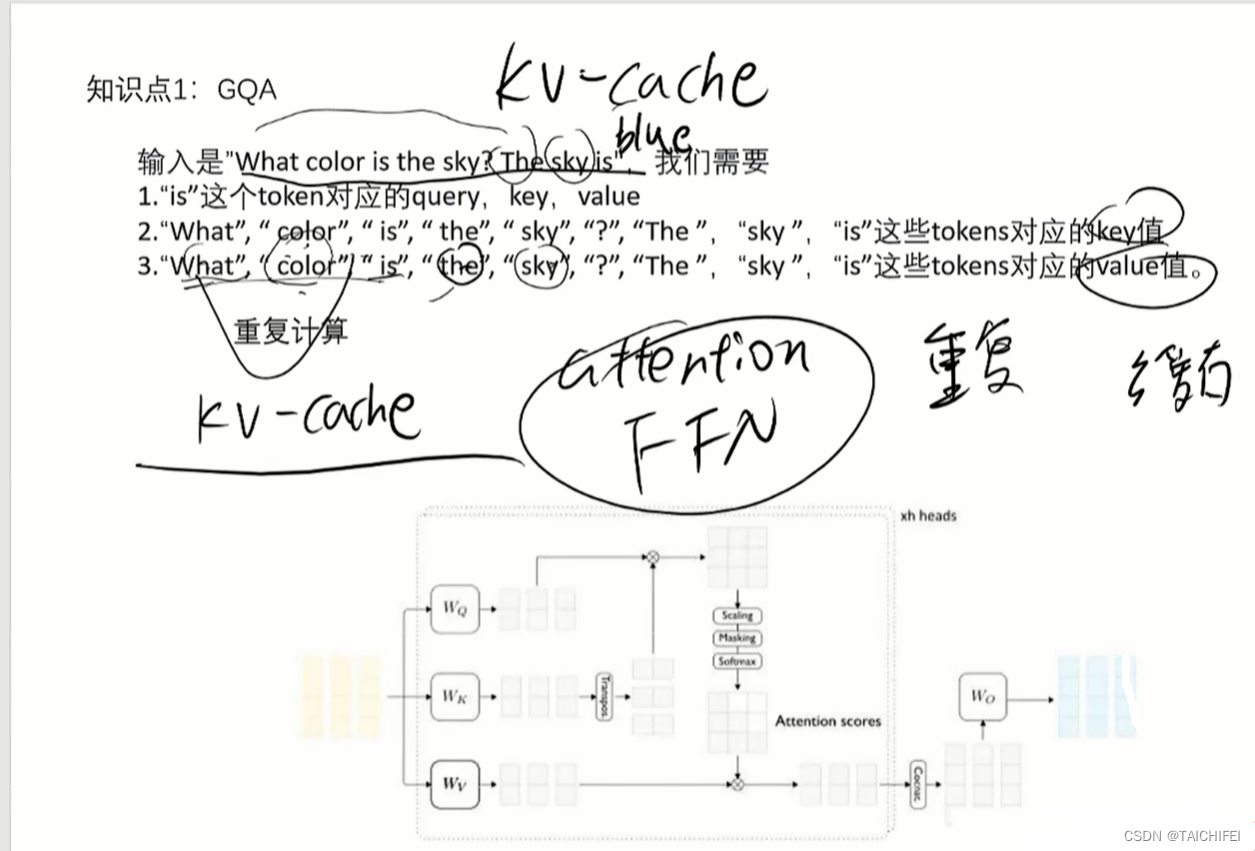
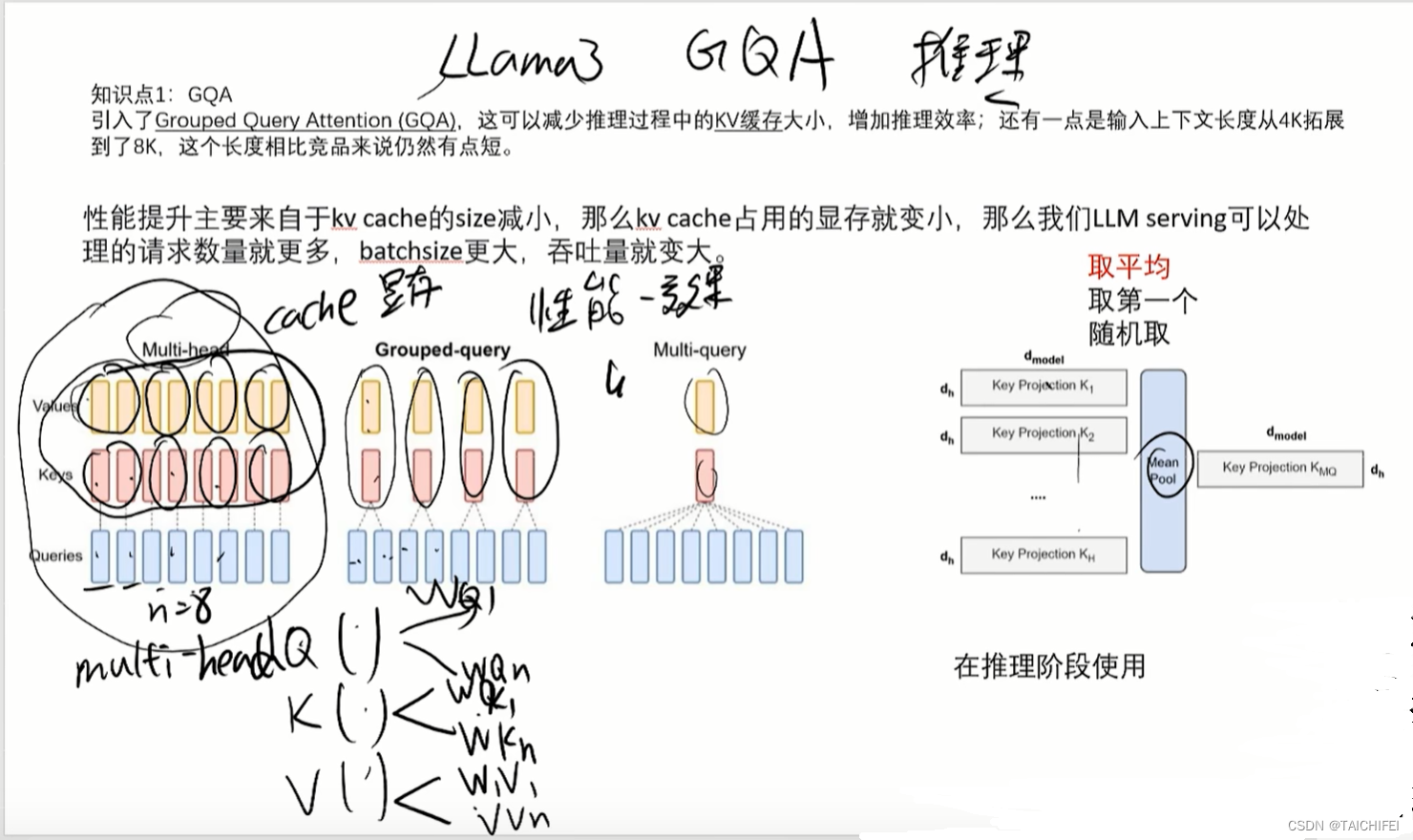
编码词表

数据合成

模型最优化
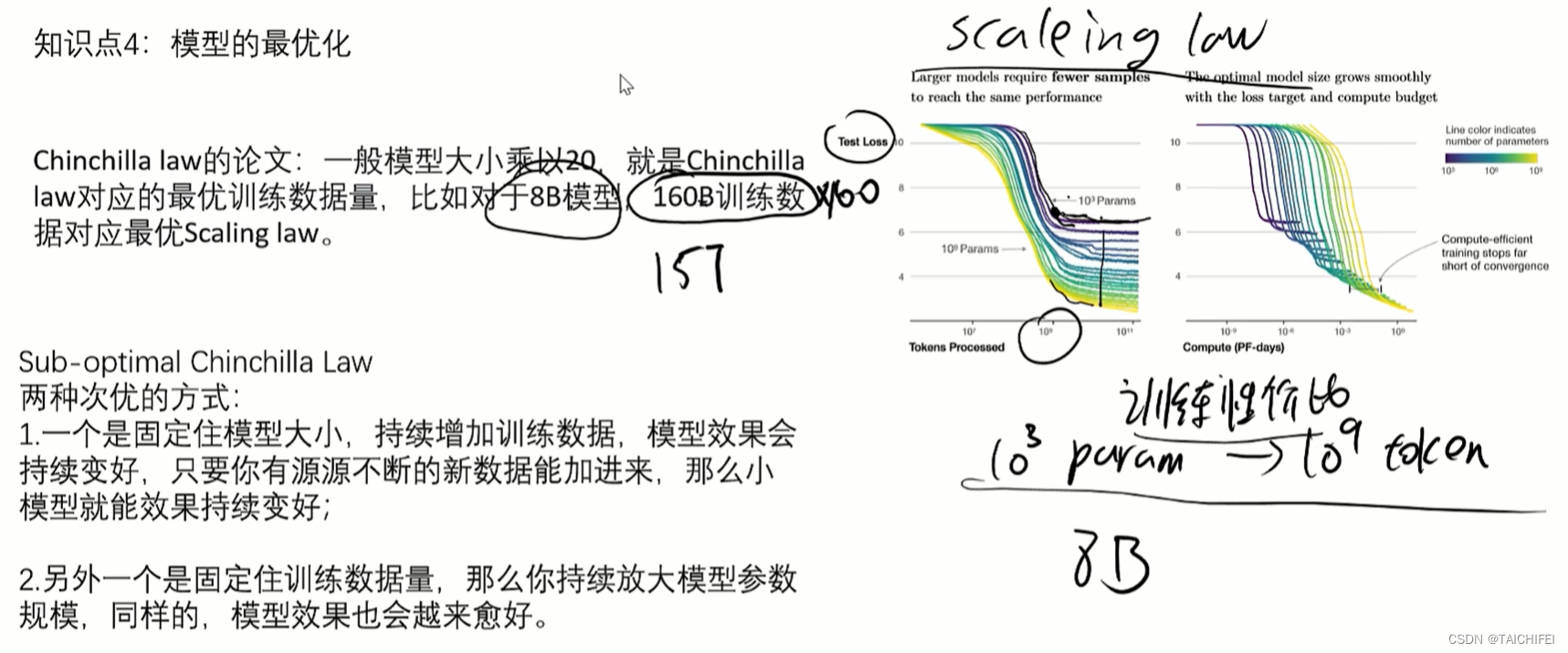
160B和15T

DPO
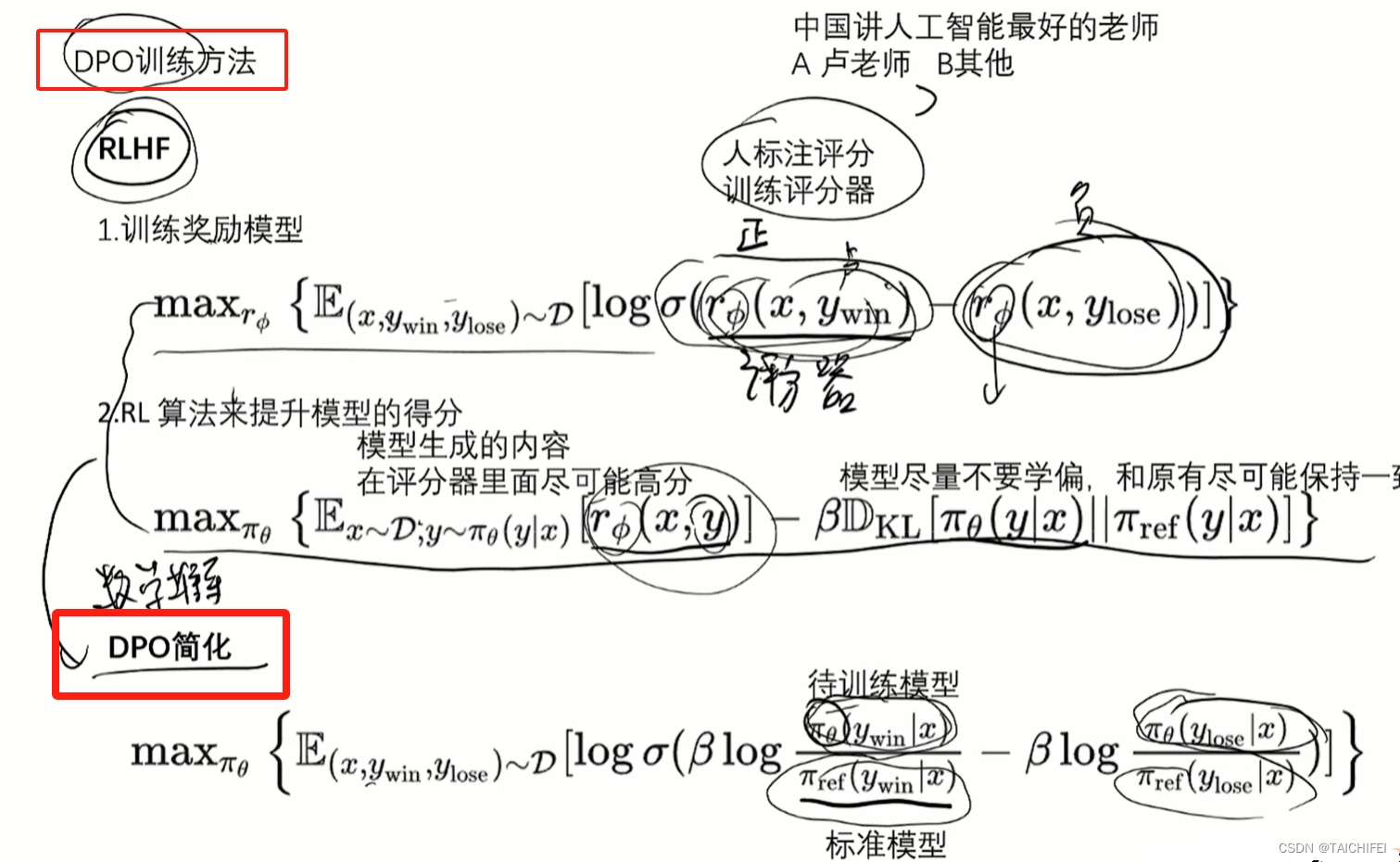

与 RLHF 首先训练奖励模型进行策略优化不同,DPO 直接将偏好信息添加到优化过程中,而无需训练奖励模型的中间步骤。
DPO 使用 LLM 作为奖励模型,并采用二元交叉熵目标来优化策略,利用人类偏好数据来识别哪些响应是首选的,哪些不是。该政策根据首选反应进行调整,以提高其绩效。
DPO 与 RLHF 相比具有以下诸多优点:
-
简单且易于实施
与RLHF 涉及收集详细反馈、优化复杂策略和奖励模型训练的多层过程不同,DPO 直接将人类偏好集成到训练循环中。这种方法不仅消除了与过程相关的复杂性,而且更好地与预训练和微调的标准系统保持一致。此外,DPO 不涉及构建和调整奖励函数的复杂性。
-
无需奖励模型训练
DPO 无需训练额外的奖励模型,从而节省了计算资源并消除了与奖励模型准确性和维护相关的挑战。开发一个有效的奖励模型,将人类反馈解释为人工智能可操作的信号是一项复杂的任务。它需要大量的努力并且需要定期更新才能准确地反映不断变化的人类偏好。 DPO 通过直接利用偏好数据来改进模型,从而完全绕过此步骤。
参考资料:
https://www.cnblogs.com/lemonzhang/p/17910358.html
总结



