
- 1Docker学习(04)——容器命令_docker启动tomcat容器失败:exited (1) 2 minutes ago
- 2【LQR】离散代数黎卡提方程的求解,附Matlab/python代码(笔记)_matlab离散代数黎卡提方程
- 3git-lfs基本知识讲解
- 4ai关键词整理(分享)
- 5悬浮窗(穿透实现)_android悬浮窗代码
- 6python学习(8)——字典dict,创建、len()、in和not in、修改、复制、删除、遍历_python dict in
- 7去水印小程序API接口和搭建教程_去水印为什么带?的api无法使用,而直接使用key的可以使用
- 87-云原生监控体系-PromQL-函数功能和示例
- 9阿里云esc云盘在线扩容排查记录 - by 勤勤学长
- 10聊聊Git合并和变基_git合并策略
[论文笔记]ITRANSFORMER: INVERTEDTRANSFORMERSARE EFFECTIVEFORTIMESERIESFORECASTING_itransformer: inverted transformers are effective
赞
踩
文章地址:iTransformer_pdf
code地址:github
文章是阅读论文后的个人总结,可能存在理解上的偏差,欢迎大家一起交流学习,给我指出问题。
1、问题描述
之前的工作DLinear和NLinear验证了线性模型在时序预测中的强大作用,对Transformer在多维时序预测的有效性提出了质疑。如果还想继续用former系列模型进行时序预测应该进行怎样的改进?
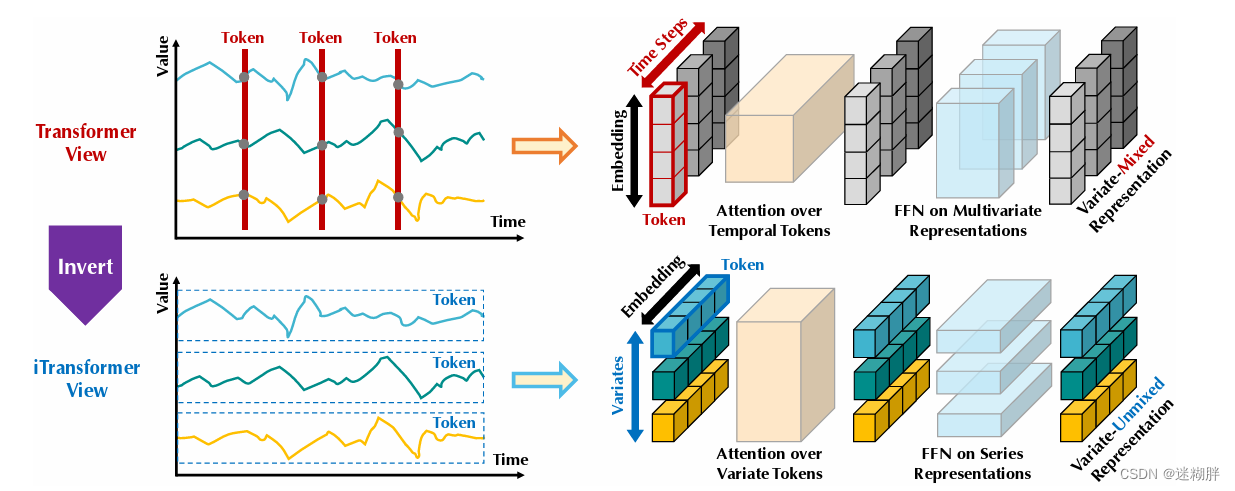
图1上部分是传统Transformer的运行机制,传统的Transformer是将同一时间戳下的各个变量赋予相同的Token值,会影响各个变量之间相关性的提取;同时当遇到时间不对齐事件时,这种方式也会引入噪声。传统的Transformer的self-attention和Embedding也会将时序信息打乱,这样也会对预测产生影响。
基于此,本文提出iTransformer“倒置Transformer”,简而言之就是对时间序列采取一种“倒置视角”,将每个变量的整个时间序列独立地Embedding为一个token,并用注意力机制进行多元关联,同时利用FNN进行序列表示。
2、创新点
- 将单个变量的整个时间序列视为一个Token
- Transformer中的self-attention和FNN机制的职责倒置(self-attention捕获变量之间的相关性;FNN来进行序列内的全局表示)
3、相关工作
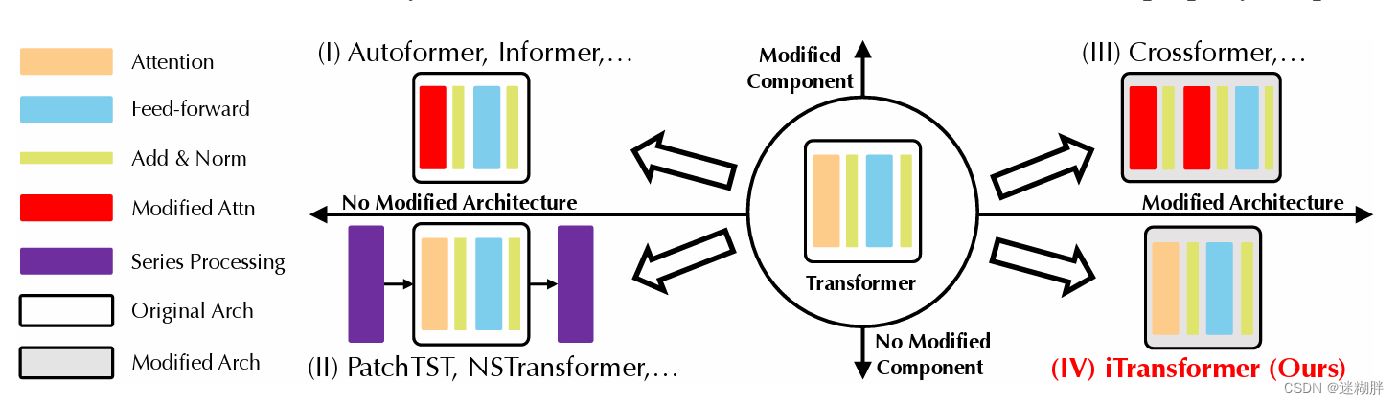
本文总结了在之前的former系进行时序预测文章中的主要方向,主要分为三个方向。
- 对组件的调整。代表工作是Autoformer、Informer,它们主要通过调整组件来实现更优的时间依赖建模和长序列复杂性注意力模块
- 对时间序列的调整。代表工作是PatchTST。这类工作是充分利用Transformer,通过对时间序列的固有处理(时间序列的平稳性、patc以及通道独立性)来提高预测的准确性。
- 对组件和序列同时进行优化。代表工作Crossformer通过更新过的注意力机制和架构明确捕捉了跨时间和跨变量的依赖关系
- 本文的工作不改transformer原来的模块,就是对transformer的模块进行微调,就可以实现更好的效果,这也是本文的一大创新立足点。
4、iTransformer详解
encoder-only
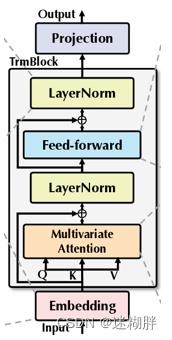
首先注意本文只用到了encoder模块,在前文中也提到之前的工作验证了线性模型在时序预测工作中的有效性,挑战了encoder和decoder模块的必要性,所以本文只用encoder也可以实现预测工作
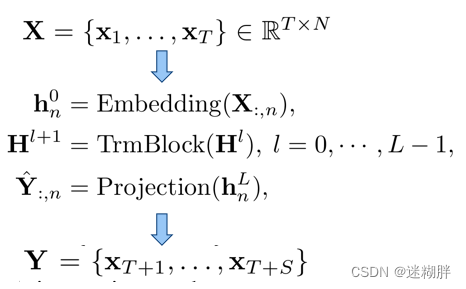
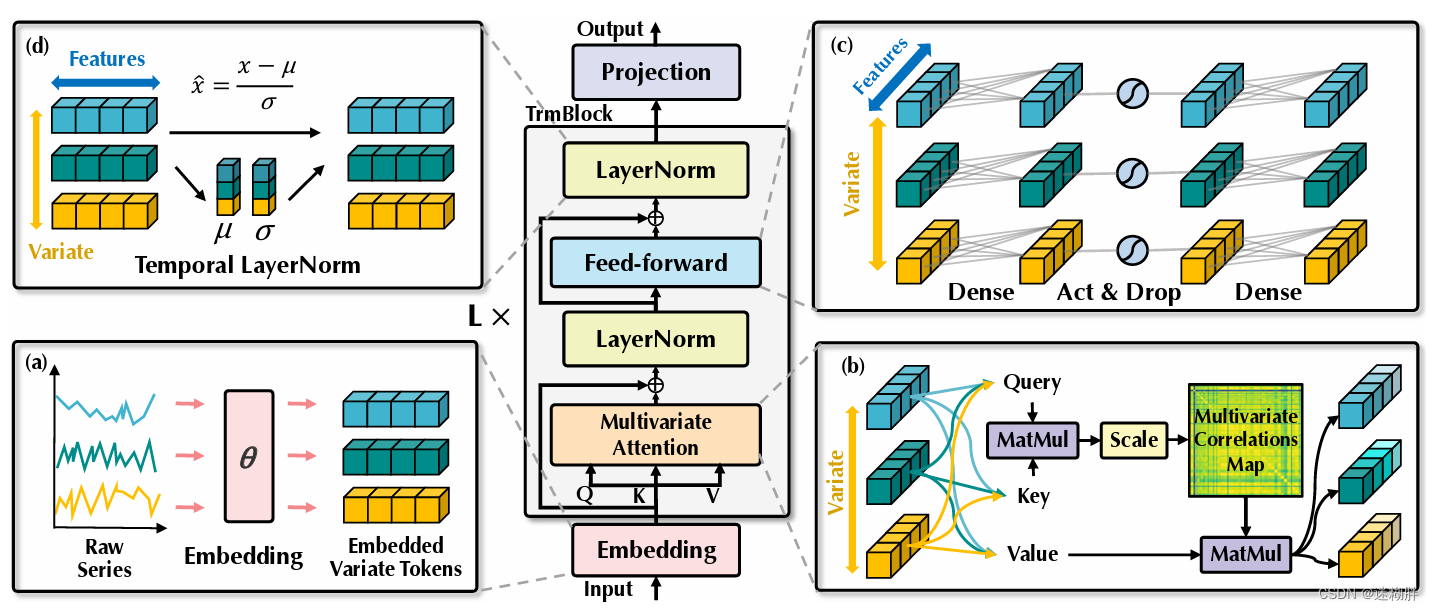
这里描述了问题,历史序列大小为(T x N),其中T为时间序列的长度,N为特征维度,S为预测的序列长度。中间通过Embedding、TrmBlock的多层堆叠以及最后的Projection来实现对未来长度为S时间序列的预测。
Embedding
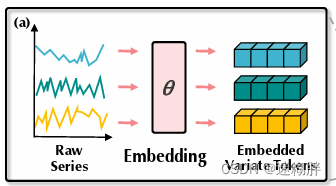
这个模块将一个变量的整个时间序列Embedding为一个token,看代码就是将(B,T,N)转为(B,N,T)然后再通过一个linear层进行Embedding。
self-attention
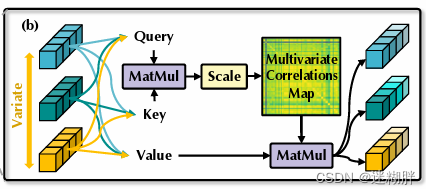 倒置模型将时间序列视为独立过程,通过自注意力模块全面提取时间序列表示,采用线性投影获取Q、K、V的值,计算前Softmax分数,揭示变量之间的相关性,为多元序列预测提供更自然和可解释的机制。原本的Transformer的注意力机制中的Q和K计算的是时间序列的相关性。
倒置模型将时间序列视为独立过程,通过自注意力模块全面提取时间序列表示,采用线性投影获取Q、K、V的值,计算前Softmax分数,揭示变量之间的相关性,为多元序列预测提供更自然和可解释的机制。原本的Transformer的注意力机制中的Q和K计算的是时间序列的相关性。
FNN
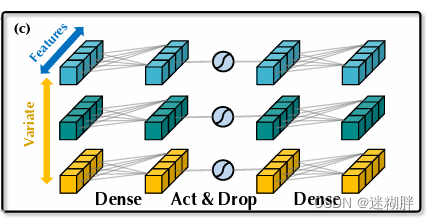
FNN包含激活函数层和两层Conv1d(第一层是对历史时间数据编码,第二层是解码进行预测),这里的FNN是计算的序列内的全局表示。在传统的Transformer中,由于对同一时间戳下的变量编码,由于构成token的多个变量之间的位置可能存在问题,过于局部化,不能提供详细的信息进行预测。但是本文的FNN是对变量的整个序列进行token表示,可以用于复杂的时间序列。
layer normalization
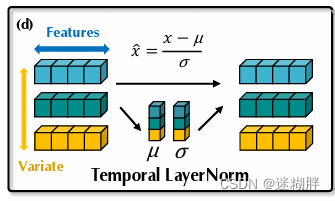
传统transformer中对同一时间戳的多变量表示进行归一化处理,逐渐将变量彼此融合。但是这个出现的问题就是,一旦收集的时间点不代表相同的事件,该操作也将在非因果或延迟过程中引入交互噪声。在倒置模型中,归一化用于单变量的时间序列表示。由于所有序列作为token被归一化为高斯分布,由不一致测量引起的差异就可以被减少。
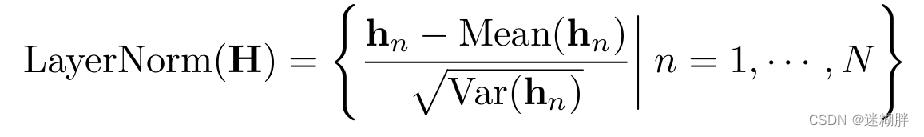
5.实验
主要结果
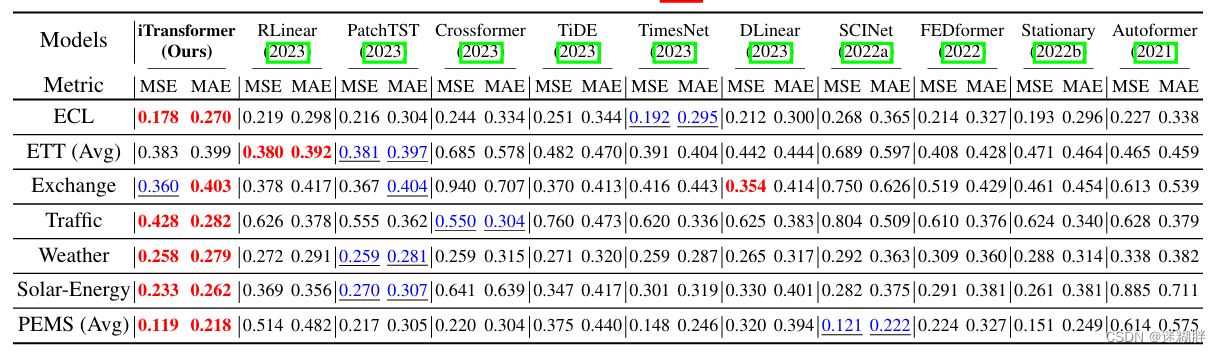
PEMS的预测长度S∈{12,24,36,48},其他的预测长度S∈{96,192,336,720},固定的回溯长度T=96进行多变量预测结果更新。结果是从所有预测长度中平均得出的。
性能提升
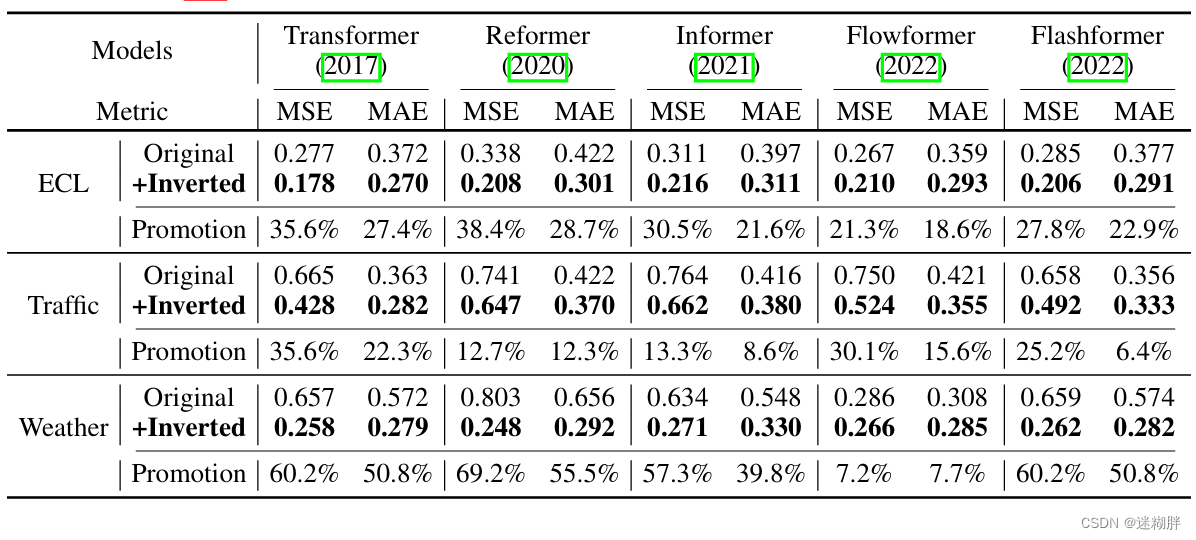
总体而言,在Transformer上实现了平均38.9%的提升,在Reformer上为36.1%,在Informer上为28.5%,在Flowformer上为16.8%,在Flashformer上为32.2%,揭示了之前在时间序列预测中对Transformer架构的不当使用。此外,由于本文在倒置结构中在变量维度采用了注意机制,引入具有线性复杂度的高效注意力实质上解决了由于众多变量而导致的计算问题。
变量泛华

通道独立验证:即训练一个共享的骨干网络来预测所有变量。我们将每个数据集的变量分成五个文件夹,仅用一个文件夹中20%的变量训练模型,并直接预测所有变量而无需微调。
增加历史回顾长度
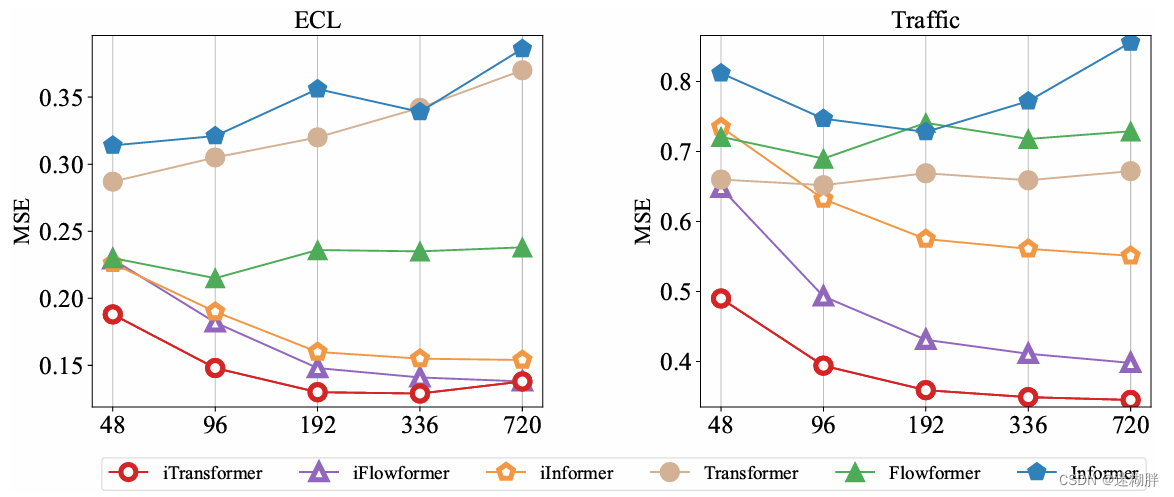
先前的研究发现,随着Transformers中回顾长度的增加,预测性能并不一定
会提高,这可以归因于对不断增长的输入分散了注意力。然而,线性预测通常能够实现期望的性能改善。本文结果也验证了利用MLP在时间维度上的合理性,使得Transformers可以从扩展的回顾窗口中受益,实现更精准的预测。
消融实验
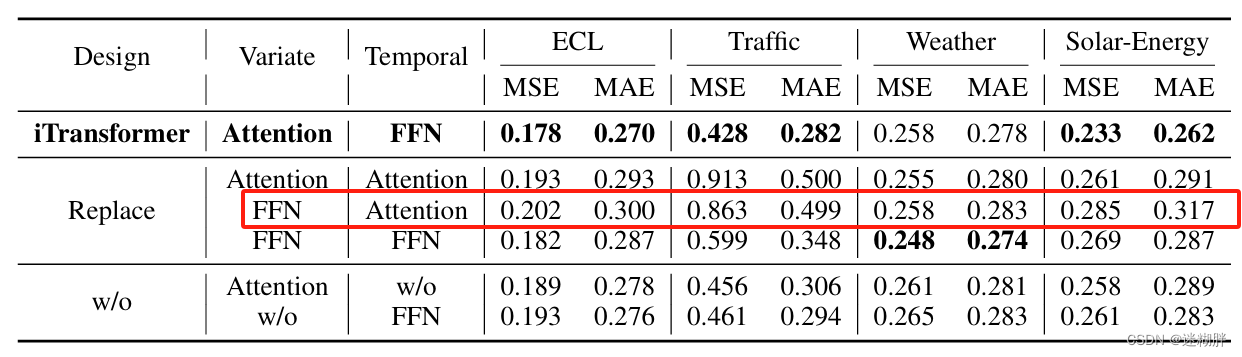
为验证Transformer组件的合理性,本文提供了详细的消融研究,涵盖了替换组件(替换)和删除组件(w/o)的实验。将注意力放在变量维度上并在时间维度上进行前馈的iTransformer通常表现最佳。传统Transformer的性能(第三行)在这些设计中表现最差,揭示了传统架构的潜在风险。
多变量关联分析
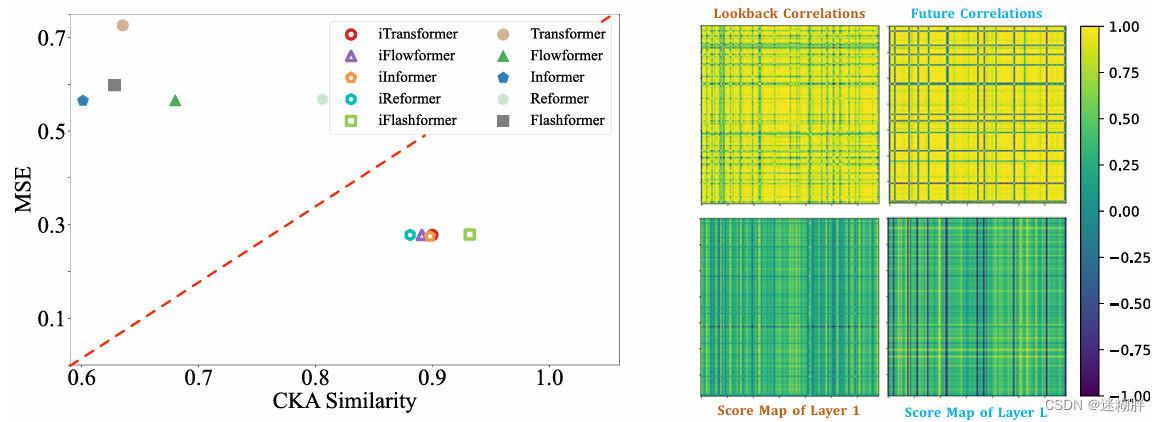
将多变量关联的任务分配给注意机制,学习的映射具有增强的可解释性。本文在Solar-Energy时间序列上展示了案例可视化,该序列在回顾和未来窗口中具有明显的关联。可以观察到,在浅层注意层中,学习的映射与原始输入序列的关联具有很多相似之处。随着向深层级别的深入,学习的映射逐渐类似于未来序列的关联,这验证了倒置操作增强了可解释的关注力以进行关联,并且在前馈过程中实质上进行了编码过去和解码未来的过程。
总结
本文提出了iTransformer,它颠倒了Transformer的结构,而不修改任何原生Transformer模块。iTransformer将独立的时间序列视为变量令牌,通过注意力机制捕获多变量之间的关联,并利用层归一化和前馈网络来学习序列表示。

