
- 1回归模型使用实战xgb.XGBRegressor
- 2大模型接触(一)——模型蒸馏
- 3union查询 如何合成一个新表
- 4DPDK的PMD(uio/igb_uio/vfio-pci/uio_pci_generic)_dpdk pmd
- 5【转】微软研发职位介绍_微软首席研究员什么级别
- 6论文辅助笔记:TEMPO 之 utils.py
- 7人工电销机器人在销售行业中的重要性和作用,以及未来市场的发展前景
- 8【NLP】特征提取: 广泛指南和 3 个操作教程 [Python、CNN、BERT]
- 9vscode获取远程别人的分支_vscode上获取所有分支
- 10RabbitMQ部署指南_linux在线安装rabbitmq3.8
GraphGPT——图结构数据的新语言模型
赞
踩
在人工智能的浪潮中,图神经网络(GNNs)已经成为理解和分析图结构数据的强大工具。然而,GNNs在面对未标记数据时,其泛化能力往往受限。为了突破这一局限,研究者们提出了GraphGPT,这是一种为大语言模型(LLMs)量身定制的图结构知识融合框架。本文将探讨GraphGPT如何革新我们处理图数据的方式。

什么是GraphGPT?
GraphGPT是一种新型框架,它通过图指令调整(Graph Instruction Tuning)来提升大语言模型对图结构数据的理解力和泛化能力。这一框架特别适合于零样本学习场景,即在没有下游任务标签的情况下进行预训练和微调。
GraphGPT的核心优势在于其创新的框架设计,该设计专门针对图结构数据的理解与处理进行了优化。以下是GraphGPT几个关键优势的详细介绍:
1. 图结构编码与文本-图基础范式(Text-Graph Grounding)
GraphGPT通过一种称为文本-图基础范式的方法,实现了图结构信息与自然语言空间的有效对齐。这一范式允许模型生成保留图结构上下文的提示(prompts),从而使得大语言模型(LLMs)能够利用其固有的语言理解能力来解释图的语义信息。这种方法作为桥梁,连接了图的语义理解和图内的结构关系。
2. 双阶段图指令调整(Dual-Stage Graph Instruction Tuning)
GraphGPT采用了一个双阶段的指令调整过程,该过程包含自监督指令调整和任务特定指令调整两个部分:
- 自监督指令调整:在第一阶段,GraphGPT使用来自未标记图结构的自监督信号作为指令,以增强模型对图结构域特定知识的理解。通过设计结构感知的图匹配任务,模型能够区分不同的图标记,并将这些标记与其相应的文本描述准确关联。
- 任务特定指令调整:在第二阶段,模型通过使用特定于任务的图指令进行微调,以定制化模型的推理行为,满足不同图学习任务的特定约束和要求。
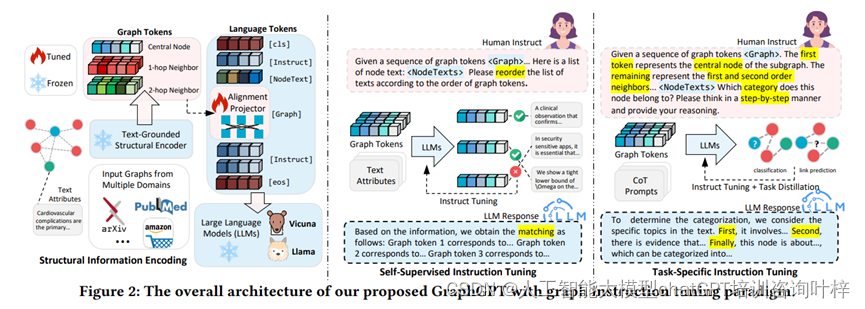
3. 链式思考(Chain-of-Thought, CoT)蒸馏
为了应对多样化的图数据和分布偏移问题,GraphGPT引入了链式思考技术,以增强模型的逐步推理能力。CoT技术通过明确模拟思考过程和推理步骤,提高了模型生成文本的连贯性和一致性。此外,通过从封闭源的强大语言模型(如ChatGPT)中提取有价值的知识,GraphGPT能够在不增加参数规模的情况下,提高模型的CoT推理能力。

实验与评估
实验使用了三个主要数据集:OGB-arxiv、PubMed 和 Cora,这些数据集覆盖了计算机科学论文引用网络、糖尿病相关科学出版物以及更广泛的研究论文。为了确保实验的兼容性和可比性,研究者们采用预训练的 BERT 模型对节点特征进行编码,并将数据集按照一定的比例划分为训练集、验证集和测试集。
在监督学习设置中,GraphGPT 在特定数据集上训练,并在相同数据集的测试集上评估性能。而在零样本学习设置中,GraphGPT 接受一个数据集的训练后,直接在完全不同的数据集上进行测试,无需额外训练。这种设置模拟了现实世界中标签数据稀缺的情况。
评估指标包括节点分类任务的准确率和宏平均 F1 分数,以及链接预测任务的 AUC(Area Under the Curve)。与多个现有的先进方法相比,包括传统的机器学习方法、图神经网络架构、自监督学习方法、知识蒸馏方法和最新的图变换网络,GraphGPT 在多个任务上均展现出了优越的性能。
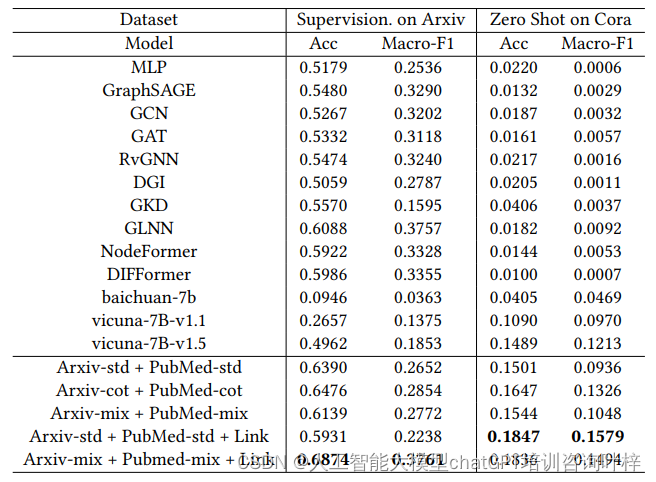
此外,研究者们还进行了模块消融研究,以评估 GraphGPT 中不同组件的贡献。结果表明,图指令调整和链式思考蒸馏对于提升模型性能至关重要。模型效率研究也表明,GraphGPT 在训练和推理阶段都具有较高的效率,这得益于其创新的图-文本对齐投影器和双阶段指令调整策略。
最终,通过模型案例研究,研究者们展示了 GraphGPT 如何在实际的图学习任务中,如节点分类和链接预测,提供准确的预测和合理的解释。这些实验结果不仅证明了 GraphGPT 在图学习任务中的有效性,也展示了其在零样本学习场景中的泛化能力。通过这些实验,研究者们成功地展示了 GraphGPT 作为一个强大的图学习框架的潜力。
实验结果证明了 GraphGPT 框架在图学习任务中的优越性能,特别是在缺乏标记数据的零样本学习场景下。此外,通过 CoT 蒸馏,GraphGPT 展现出了强大的逐步推理能力,能够更好地理解和推理图结构数据。

