
- 1XP使用技巧
- 2C++基础与技巧【顺序容器】 (三大顺序容器~vector, list, deque)_顺序寻址 vector list
- 3spyder下报错ModuleNotFoundError: No module named_它没有 spyder kernels 模块或没有安装正确的版本 (>= 2.4.0 并 < 2.5.
- 4Python基础知识总结(期末复习精简版)_华中农业大学python考试
- 5微信开发者工具使用git提交项目至gitee远程仓库(保姆级)_微信开发者工具 gitee
- 6精选力扣500题 第31题 LeetCode 69. x 的平方根【c++ / java 详细题解】_69. x 的平方根 c++
- 7数据结构-栈
- 8cfg是什么
- 9自定义幂等注解_自定义注解实现幂等
- 10猿创征文|2022年前端之路——我的前端开发好帮手_csdn前端征文
Python文本数据分析实战_python 文本分析
赞
踩
1.文本预处理
文本预处理一般包括分词、词形归一化、删除停用词,具体流程如下:
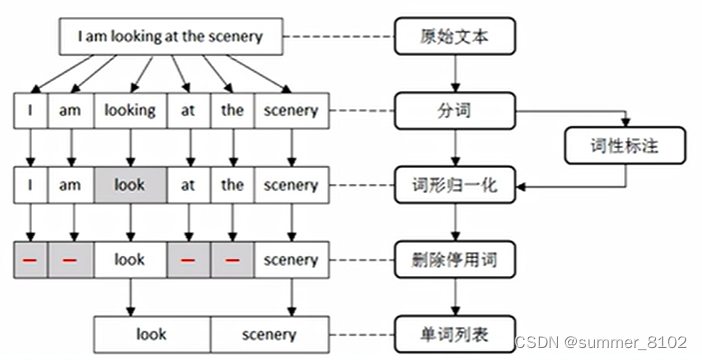
1.1 分词
分词是指将由连续字符组成语句,按照一定的规则划分成一个个独立词语的过程。不同的语言具有不同的语法结构。
- 英文:以空格为分隔符
- 中文:没有形式上的分隔符
根据中文的结构特点,可以把分词算法分为以下三类:
- 基于规则的分词方法:按照一定的策略将待分析的中文句子与一个“充分大的”机器词典中词条进行匹配。
- 基于统计的分词方法:它的基本思路是常用的词语是比较稳定的组合。
- 基于理解的分词方法:它的基本思路是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
1.1.1 英文分词
要使用 NLTK 对英文句子分词,则可以调用 word_tokenize() 函数基于空格或标点进行划分,并返回单词列表。
import nltk
import jieba
import nltk
nltk.download('punkt')
sentence = 'I like blue.'
# 将句子切分为单词
words = nltk.word_tokenize(sentence)
print(words)
# ['I', 'like', 'blue', '.']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.1.2 中文分词
要使用 jieba 对中文句子分词,则可以通过 jieba.cut() 函数进行划分,该函数接收如下三个参数:
- 需要分词的字符串。
- cut_all 参数用来空值是否采用全模式。
- HMM 参数用来空值是否使用 HMM 模型。
如果将 cut_all 参数设置为 True,则白哦是按照全模式进行分词,示例如下:
sentence = '数学与统计学院的数学专业研究生二年级学生在此学习。'
# 全模式划分中文句子
terms_list = jieba.cut(sentence,cut_all=True)
print('【全模式】:'+'/'.join(terms_list))
# 【全模式】:数学/与/统计/统计学/计学/学院/的/数学/专业/研究/研究生/二年/二年级/年级/学生/生在/此/学习/。
- 1
- 2
- 3
- 4
- 5
如果将 cut_all 参数设为 False,则表示的是按照精确模式进行分词,示例如下:
sentence = '数学与统计学院的数学专业研究生二年级学生在此学习。'
# 全模式划分中文句子
terms_list = jieba.cut(sentence,cut_all=False)
print('【精确模式】:'+'/'.join(terms_list))
#【精确模式】:数学/与/统计/学院/的/数学/专业/研究生/二年级/学生/在/此/学习/。
- 1
- 2
- 3
- 4
- 5
1.2 词性标注
1.2.1 词性标注
词性是对词语分类的一种方式。
- 英文词汇: 名词、形容词、动词、代词、数词、副词、介词、连词、冠词和感叹词。
- **中文词汇:**名词、动词、形容词、数词、量词、代词、介词、副词、连词、感叹词、助词和拟声词。
1.2.2 词性标注
词性标注,又称词类标注,是指为分词结果中的每个词标注一个正确的词性。

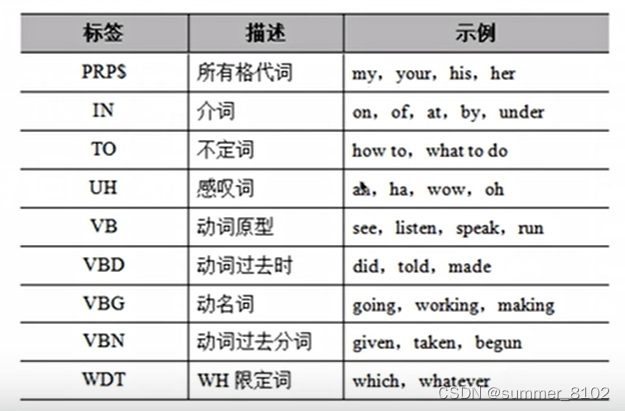
NLTK库中使用不同的约定来标记单词,下面通过一张表来列举通用的词性标注集。
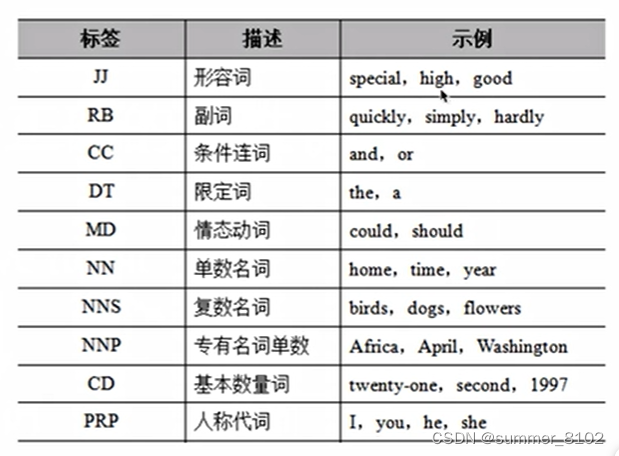
通用的词性标注集续表
如果希望给单词标注词性,则需要先确保已经下载了 averaged_perceptron_tagger 模块,然后再调用 pos_tag() 函数及逆行标注。
nltk.download('averaged_perceptron_tagger')
nltk.pos_tag(words)
# [('I', 'PRP'), ('like', 'VBP'), ('blue', 'JJ'), ('.', '.')]
- 1
- 2
- 3
1.3 词形归一化
在英文中,一个单词常常是另一个单词的变种。

一般在信息检索和文本挖掘时,需要对一个词的不同形态进行规范化,以提高文本处理的效率。
词形规范化过程主要包括两种:词干提取和词形还原。
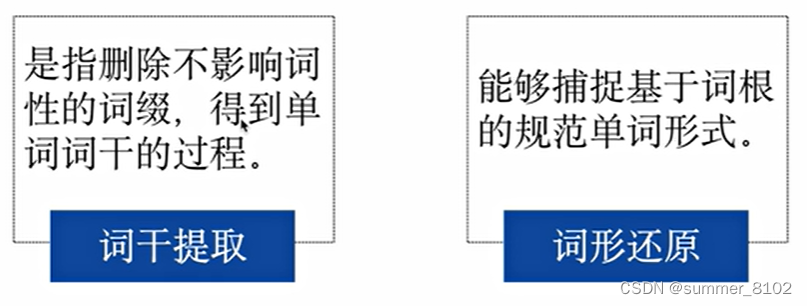
词干提取和词形还原的示例如下:
watching ==> watch
watched ==> watch
better ==> good
went ==> go
目前最受欢迎的就是波特词干提取器,它是基于波特词干算法来提取词干的,这些算法都集中在 PorterStemmer 类中。
from nltk.stem.porter import PorterStemmer
porter_stem = PorterStemmer()
porter_stem.stem('watched')
#'watch'
- 1
- 2
- 3
- 4
还可以使用兰卡斯特词干提取器,它是基于兰卡斯特词干算法来提取词干的,这些算法都集中在 LancasterStemmer 类中。
from nltk.stem.lancaster import LancasterStemmer
lancaster_stem = LancasterStemmer()
# 按照兰卡斯特算法提取词干
lancaster_stem.stem('jumped')
# 'jump'
- 1
- 2
- 3
- 4
- 5
还有一些其它的词干器,比如 SnowballStemmer,它除了支持英文意外,还支持其它13种不同的语言。
from nltk.stem import SnowballStemmer
snowball_stem = SnowballStemmer('english')
snowball_stem.stem('listened')
#'listen'
- 1
- 2
- 3
- 4
NLTK库中提供了一个强大的还原模块,它使用 WordNetLemmatizer 类来获得根词,使用前需要确保已经下载了 wordnet 预料库。
- 词形还原是去除词缀以获得单词的基本形式。
- 整个基本形式称为根刺,而不是词干。根词始终存在于字典中,词干不一定是标准的单词,它可能不存在于词典中。
WordNetLemmatizer 类里面提供了一个 lemmatize() 方法,用于获得单词的基本形式。
- lemmatize() 方法会比对 wordnet 语料库,并采用递归技术删除词缀,直至在词汇网络中找到匹配项,最终返回输入词的基本形式。
- 如果没有找到匹配项,则直接返回输入词,不做任何变化。
下面是一个基于WordNetLemmatizer 的词形还原示例。
# Lemmatization
nltk.download('omw-1.4')
from nltk.stem import WordNetLemmatizer
wordnet_lem = WordNetLemmatizer()
print(wordnet_lem.lemmatize('books')) # As a noun
print(wordnet_lem.lemmatize('went', pos='v')) # As a verb
#book
#go
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.4 删除停用词
停用词是指在信息检索中,为节省存储空间和提高效率,在处理自然语言文本之前或之后会自动过滤掉某些没有具体意义的字或词。
比如:英文单词 “I”、“the” 或中文中的 “啊”等。
如果直接用包含大量停用词的文本作为分析对象,则可能会导致分析结果存在较大偏差,通常在处理过程中会将它们从文本中删除。

停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表,但是并没有一个明确的停用词表能够适用于所有的工具。
- 对于中文的停用词,可以参考中文停用词库、哈工大停用词表、百度停用词列表。
- 对于其它语言来说,可以参照
https://www.ranks.nl/stopwords进行了解。
NLTK库里面有一个标准的停用词列表,在使用之前要确保已经下载了 stopwords 语料库,并且用 import 语句导入stopwords 模块。
nltk.download('stopwords')
from nltk.corpus import stopwords
text = 'I am a beautiful girl and I study everyday.'
words = nltk.word_tokenize(text)
stop_words = stopwords.words('english')
remain_list = []
for word in words:
if word not in stop_words:
remain_list.append(word)
print(remain_list)
print(words)
#['I', 'beautiful', 'girl', 'I', 'study', 'everyday', '.']
#['I', 'am', 'a', 'beautiful', 'girl', 'and', 'I', 'study', 'everyday', '.']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2.文本情感分析
文本情感分析,又称为倾向性分析和意见挖掘,是指对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。

情感分析还可以细分为情感极性(倾向)分析、情感程度分析及主客观分析等。
其中,情感极性分析的目的在于,对文本进行褒义、贬义、中性的判断,比如对于“喜爱”和“厌恶” 这两个词,就属于不同的情感倾向。
目前,常见的情感极性分析方法主要分为两种:基于情感词典和基于机器学习。
2.1 情感词典情感分析

最简单的情感极性分析的方式就是情感词典,其实现的大致思路如下:

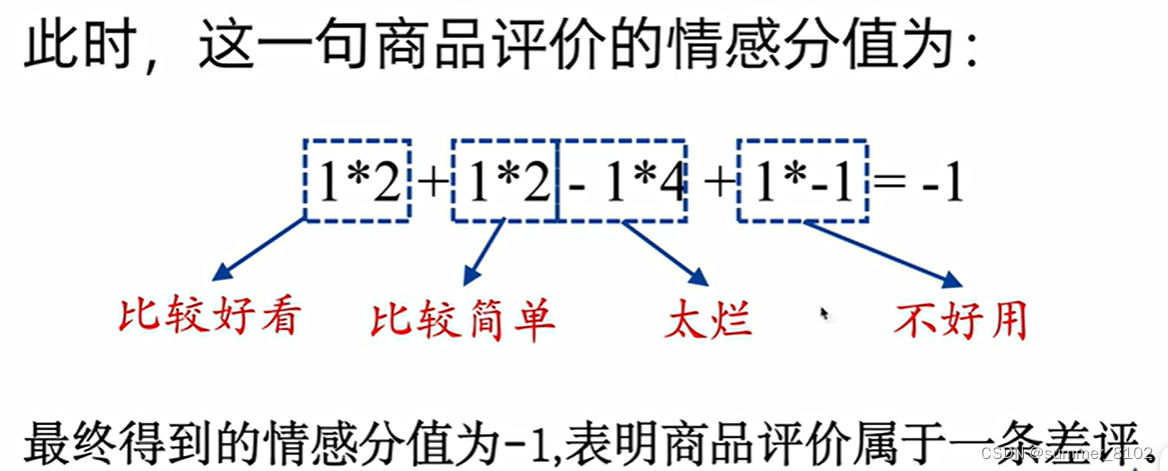
例如,有这么一句商品评价:

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

