
- 1数据结构——外部排序
- 2【bug修复】—— [vuex] Do not mutate vuex store state outside mutation handlers.
- 3基于深度学习神经网络的AI图片上色DDcolor系统源码
- 4Redis明明启动了,但IDEA就是一直显示Unable to connect to Redis,不妨这样启动Redis_unable to connect to redis server:
- 5解决系统缺少api-ms-win-core-sysinfo-l1-2-1.dll文件问题
- 6AWS - redshift 中的锁_redshift accesssharelock属于行锁还是表锁
- 7部署一个自己的GPT客户端[以ChatGPT-Next-Web为例]
- 8Prometheus实战教程:监控Kafka消息_prometheus监控kafka
- 9OkHttp证书校验_如何验证okhtpp配置是不是正常
- 10乌云章华鹏:如何构建高效的安全运维服务平台
【持续更新】NebulaGraph详细学习文档
赞
踩
文章目录
- NebulaGraph
- 一、简介
- 二、部署
- 2.1 单机部署
- 2.1.1下载安装包
- 2.1.2上传至虚拟机中
- 2.1.3rpm安裝
- 2.1.3*压缩包安装
- 2.1.4关闭防火墙
- 2.1.5使用 NTP 服务同步时间
- 2.1.6Meta 服务配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/2.meta-config/#meta)
- logging 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/2.meta-config/#logging)
- networking 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/2.meta-config/#networking)
- storage 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/2.meta-config/#storage)
- misc 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/2.meta-config/#misc)
- rocksdb options 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/2.meta-config/#rocksdb_options)
- 2.1.6Graph 服务配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#graph)
- basics 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#basics)
- logging 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#logging)
- query 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#query)
- networking 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#networking)
- charset and collate 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#charset_and_collate)
- authorization 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#authorization)
- memory 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#memory)
- metrics 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#metrics)
- session 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#session)
- experimental 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#experimental)
- memory tracker 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#memory_tracker)
- performance optimization 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/3.graph-config/#performance_optimization)
- 2.1.7Storage 服务配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#storage)
- basics 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#basics)
- logging 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#logging)
- networking 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#networking)
- raft 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#raft)
- disk 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#disk)
- misc 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#misc)
- rocksdb options 配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/4.storage-config/#rocksdb_options)
- 2.1.8Linux 内核配置[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/6.kernel-config/#linux)
- 资源控制[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/6.kernel-config/#_1)
- 内存[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/6.kernel-config/#_2)
- 网络[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/6.kernel-config/#_3)
- 其他参数[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/6.kernel-config/#_4)
- 修改参数[¶](https://docs.nebula-graph.com.cn/3.5.0/5.configurations-and-logs/1.configurations/6.kernel-config/#_5)
- 2.1.9运行日志
- 2.2 集群部署
- 三、NebulaGraph监控指标[¶](https://docs.nebula-graph.com.cn/3.5.0/6.monitor-and-metrics/1.query-performance-metrics/#nebulagraph)
- 四、NebulaGraph客户端
- 4.1 [NebulaGraph Console](https://docs.nebula-graph.com.cn/3.5.0/nebula-console/):原生客户端
- 4.2 [NebulaGraph CPP](https://docs.nebula-graph.com.cn/3.5.0/14.client/3.nebula-cpp-client/):C++ 客户端
- 4.3 [NebulaGraph Java](https://docs.nebula-graph.com.cn/3.5.0/14.client/4.nebula-java-client/):Java 客户端
- 4.4 [NebulaGraph Python](https://docs.nebula-graph.com.cn/3.5.0/14.client/5.nebula-python-client/):Python 客户端
- 4.5 [NebulaGraph Go](https://docs.nebula-graph.com.cn/3.5.0/14.client/6.nebula-go-client/):Go 客户端
- 五、启动所有服务
- 六、数据导入
- 6.1 NebulaGraph Importer[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-importer/use-importer/#nebulagraph_importer)
- 6.2 NebulaGraph Exchange
- 优点
- 6.2.1下载 JAR 文件[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/ex-ug-compile/#jar)
- 6.2.2配置application.conf
- Spark 相关配置[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#spark)
- Hive 配置(可选)[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#hive)
- NebulaGraph相关配置[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#nebulagraph)
- 点配置[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#_2)
- 通用参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#_3)
- Parquet/JSON/ORC 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#parquetjsonorc)
- CSV 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#csv)
- Hive 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#hive_1)
- MaxCompute 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#maxcompute)
- Neo4j 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#neo4j)
- MySQL/PostgreSQL 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#mysqlpostgresql)
- Oracle 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#oracle)
- ClickHouse 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#clickhouse)
- Hbase 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#hbase)
- Pulsar 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#pulsar)
- Kafka 源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#kafka)
- 生成 SST 时的特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#sst)
- 边配置[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#_4)
- 通用参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#_5)
- 生成 SST 时的特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#sst_1)
- NebulaGraph源特有参数[¶](https://docs.nebula-graph.com.cn/3.5.0/nebula-exchange/parameter-reference/ex-ug-parameter/#nebulagraph_1)
- 导入模板
- 6.2.3提交spark任务
- 6.3 NebulaGraph Spark Connector
- 6.4如何选择导入工具
- 6.5导入数据遇到的问题
- 七、Nebula数据备份
- 八、Supervisor进程守护Nebula Graph
NebulaGraph
一、简介
图数据库是一种专门用于存储和管理图数据结构的数据库管理系统。图数据库使用图的概念来表示和处理数据,其中图是由节点和边组成的数据结构,用于表示实体(节点)之间的关系(边)。与传统的关系型数据库不同,图数据库的核心思想是侧重于节点和边的关系,从而更好地处理复杂的数据关联和查询。
图数据库具有以下特点:
- 图结构:图数据库使用节点和边来表示数据。节点表示实体,边表示实体之间的关系。通过节点和边的连接,可以构建出复杂的数据网络。
- 关系导向:图数据库以关系为中心,强调实体之间的关联和连接。这使得图数据库在处理复杂的关系型查询时更加高效。
- 灵活性:图数据库具有很高的灵活性,可以适应数据结构的变化和扩展。新的实体和关系可以轻松地添加到数据库中,而不需要修改现有的表结构。
- 高性能:图数据库在处理复杂的关联查询时非常高效。由于图数据库中的关系已经预先建立,查询可以直接通过边的引用进行导航,而无需进行多重的连接操作。
- 查询能力:图数据库提供了强大的查询语言和操作,使得可以轻松地进行复杂的关联查询和路径分析。这使得图数据库在社交网络分析、推荐系统、网络安全等领域有着广泛的应用。
在图数据库的应用方面,它可以被用于许多不同的场景,如社交网络分析、知识图谱构建、推荐系统、路径规划、股权穿透等。例如,在社交网络分析中,图数据库可以存储社交用户之间的关注关系、好友关系等,并进行高效的关联查询;在推荐系统中,可以使用图数据库存储用户行为和物品关系,以提供个性化的推荐结果。
2.1系统架构
NebulaGraph由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署NebulaGraph集群。
下图展示了NebulaGraph集群的经典架构。
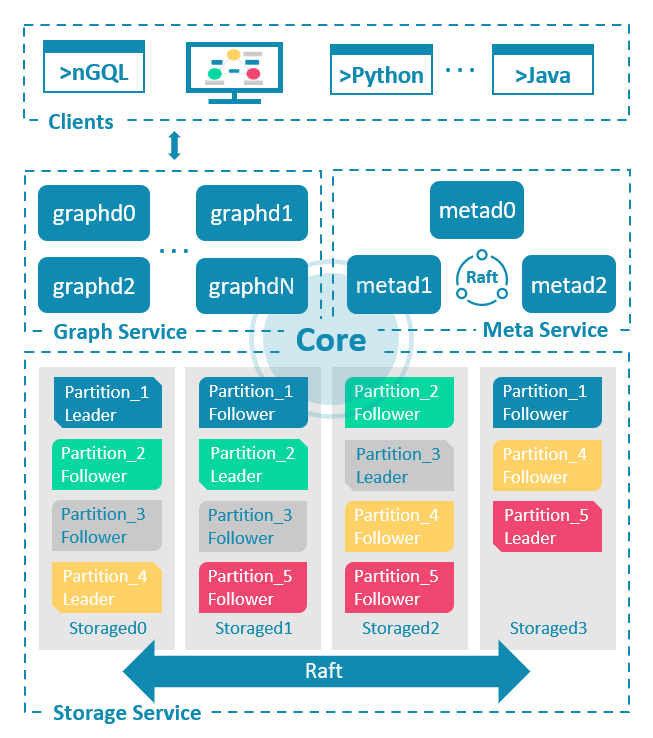
Meta 服务¶
在NebulaGraph架构中,Meta 服务是由 nebula-metad 进程提供的,负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。
Meta 服务的详细说明,请参见 Meta 服务。
Graph 服务和 Storage 服务¶
NebulaGraph采用计算存储分离架构。Graph 服务负责处理计算请求,Storage 服务负责存储数据。它们由不同的进程提供,Graph 服务是由 nebula-graphd 进程提供,Storage 服务是由 nebula-storaged 进程提供。计算存储分离架构的优势如下:
-
易扩展
分布式架构保证了 Graph 服务和 Storage 服务的灵活性,方便扩容和缩容。
-
高可用
如果提供 Graph 服务的服务器有一部分出现故障,其余服务器可以继续为客户端提供服务,而且 Storage 服务存储的数据不会丢失。服务恢复速度较快,甚至能做到用户无感知。
-
节约成本
计算存储分离架构能够提高资源利用率,而且可根据业务需求灵活控制成本。
-
更多可能性
基于分离架构的特性,Graph 服务将可以在更多类型的存储引擎上单独运行,Storage 服务也可以为多种目的计算引擎提供服务。
Graph 服务和 Storage 服务的详细说明,请参见 Graph 服务和 Storage 服务。
二、部署
2.1 单机部署
系统:CentOS7
版本:v3.5.0
2.1.1下载安装包
进入官网选择对应的安装包进行下载
NebulaGraph 安装下载 (nebula-graph.com.cn)
2.1.2上传至虚拟机中
#创建nebula目录,将安装包传入目录中
mkdir /usr/local/nebula/
- 1
- 2
2.1.3rpm安裝
下载
xxx.rpm格式的安装包则进行该步骤
cd /usr/local/nebula/
sudo rpm -ivh xxx.rpm
- 1
- 2
2.1.3*压缩包安装
下载
xxx.tar.gz格式的安装包则进行该步骤
cd /usr/local/nebula/
tar -xzvf xxx.tar.gz
- 1
- 2
2.1.4关闭防火墙
systemctl stop firewalld
systemctl enable firewalld
- 1
- 2
2.1.5使用 NTP 服务同步时间
防止集群时间不统一
sudo yum install ntpdate
sudo ntpdate ntp1.aliyun.com
- 1
- 2
2.1.6Meta 服务配置¶
Meta 服务提供了两份初始配置文件
nebula-metad.conf.default和nebula-metad.conf.production,方便在不同场景中使用。文件的默认路径为/usr/local/nebula/etc/如需使用初始配置文件,从上述两个文件选择其一,删除后缀
.default或.production,Meta 服务才能将其识别为配置文件并从中获取配置信息。配置文件内没有设置某个参数表示参数使用的是默认值。文件内只预设了部分参数的值,而且两份初始配置文件内的参数值也略有不同,本文的预设值以
nebula-metad.conf.default为准
basics 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
daemonize | true | 是否启动守护进程。 | 不支持 |
pid_file | pids/nebula-metad.pid | 记录进程 ID 的文件。 | 不支持 |
timezone_name | - | 指定NebulaGraph的时区。初始配置文件中未设置该参数,如需使用请手动添加。系统默认值为UTC+00:00:00。格式请参见 Specifying the Time Zone with TZ。例如,东八区的设置方式为--timezone_name=UTC+08:00。 | 不支持 |
Note
- 在插入时间类型的属性值时,NebulaGraph会根据
timezone_name设置的时区将该时间值(TIMESTAMP 类型例外)转换成相应的 UTC 时间,因此在查询中返回的时间类型属性值为 UTC 时间。 timezone_name参数只用于转换NebulaGraph中存储的数据,NebulaGraph进程中其它时区相关数据,例如日志打印的时间等,仍然使用主机系统默认的时区。
logging 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
log_dir | logs | 存放 Meta 服务日志的目录,建议和数据保存在不同硬盘。 | 不支持 |
minloglevel | 0 | 最小日志级别,即记录此级别或更高级别的日志。可选值为0(INFO)、1(WARNING)、2(ERROR)、3(FATAL)。建议在调试时设置为0,生产环境中设置为1。如果设置为4,NebulaGraph不会记录任何日志。 | 支持 |
v | 0 | VLOG 日志详细级别,即记录小于或等于此级别的所有 VLOG 消息。可选值为0、1、2、3、4、5。glog 提供的 VLOG 宏允许用户定义自己的数字日志记录级别,并用参数v控制记录哪些详细消息。详情参见 Verbose Logging。 | 支持 |
logbufsecs | 0 | 缓冲日志的最大时间,超时后输出到日志文件。0表示实时输出。单位:秒。 | 不支持 |
redirect_stdout | true | 是否将标准输出和标准错误重定向到单独的输出文件。 | 不支持 |
stdout_log_file | metad-stdout.log | 标准输出日志文件名称。 | 不支持 |
stderr_log_file | metad-stderr.log | 标准错误日志文件名称。 | 不支持 |
stderrthreshold | 3 | 要复制到标准错误中的最小日志级别(minloglevel)。 | 不支持 |
timestamp_in_logfile_name | true | 日志文件名称中是否包含时间戳。true表示包含,false表示不包含。 | 不支持 |
networking 配置¶
必须在配置文件中使用真实的 IP 地址。否则某些情况下
127.0.0.1/0.0.0.0无法正确解析。
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
meta_server_addrs | 127.0.0.1:9559 | 全部 Meta 服务的 IP 地址和端口。多个 Meta 服务用英文逗号(,)分隔。 | 不支持 |
local_ip | 127.0.0.1 | Meta 服务的本地 IP 地址。本地 IP 地址用于识别 nebula-metad 进程,如果是分布式集群或需要远程访问,请修改为对应地址。 | 不支持 |
port | 9559 | Meta 服务的 RPC 守护进程监听端口。Meta 服务对外端口为9559,对内端口为对外端口+1,即9560,NebulaGraph使用内部端口进行多副本间的交互。 | 不支持 |
ws_ip | 0.0.0.0 | HTTP 服务的 IP 地址。 | 不支持 |
ws_http_port | 19559 | HTTP 服务的端口。 | 不支持 |
ws_storage_http_port | 19779 | HTTP 协议监听 Storage 服务的端口,需要和 Storage 服务配置文件中的ws_http_port保持一致。仅存算合并版NebulaGraph需要设置本参数。 | 不支持 |
heartbeat_interval_secs | 10 | 默认心跳间隔。请确保所有服务的heartbeat_interval_secs取值相同,否则会导致系统无法正常工作。单位:秒。 | 支持 |
storage 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
data_path | data/meta | meta 数据存储路径。 | 不支持 |
misc 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
default_parts_num | 100 | 创建图空间时的默认分片数量。 | 不支持 |
default_replica_factor | 1 | 创建图空间时的默认副本数量。 | 不支持 |
rocksdb options 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
rocksdb_wal_sync | true | 是否同步 RocksDB 的 WAL 日志。 | 不支持 |
2.1.6Graph 服务配置¶
basics 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
daemonize | true | 是否启动守护进程。 | 不支持 |
pid_file | pids/nebula-graphd.pid | 记录进程 ID 的文件。 | 不支持 |
enable_optimizer | true | 是否启用优化器。 | 不支持 |
timezone_name | - | 指定NebulaGraph的时区。初始配置文件中未设置该参数,使用需手动添加。系统默认值为UTC+00:00:00。格式请参见 Specifying the Time Zone with TZ。例如,东八区的设置方式为--timezone_name=UTC+08:00。 | 不支持 |
local_config | true | 是否从配置文件获取配置信息。 | 不支持 |
Note
- 在插入时间类型 的属性值时,NebulaGraph会根据
timezone_name设置的时区将该时间值(TIMESTAMP 类型例外)转换成相应的 UTC 时间,因此在查询中返回的时间类型属性值为 UTC 时间。 timezone_name参数只用于转换NebulaGraph中存储的数据,NebulaGraph进程中其它时区相关数据,例如日志打印的时间等,仍然使用主机系统默认的时区。
logging 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
log_dir | logs | 存放 Graph 服务日志的目录,建议和数据保存在不同硬盘。 | 不支持 |
minloglevel | 0 | 最小日志级别,即记录此级别或更高级别的日志。可选值为0(INFO)、1(WARNING)、2(ERROR)、3(FATAL)。建议在调试时设置为0,生产环境中设置为1。如果设置为4,NebulaGraph不会记录任何日志。 | 支持 |
v | 0 | VLOG 日志详细级别,即记录小于或等于此级别的所有 VLOG 消息。可选值为0、1、2、3、4、5。glog 提供的 VLOG 宏允许用户定义自己的数字日志记录级别,并用参数v控制记录哪些详细消息。详情参见 Verbose Logging。 | 支持 |
logbufsecs | 0 | 缓冲日志的最大时间,超时后输出到日志文件。0表示实时输出。单位:秒。 | 不支持 |
redirect_stdout | true | 是否将标准输出和标准错误重定向到单独的输出文件。 | 不支持 |
stdout_log_file | graphd-stdout.log | 标准输出日志文件名称。 | 不支持 |
stderr_log_file | graphd-stderr.log | 标准错误日志文件名称。 | 不支持 |
stderrthreshold | 3 | 要复制到标准错误中的最小日志级别(minloglevel)。 | 不支持 |
timestamp_in_logfile_name | true | 日志文件名称中是否包含时间戳。true表示包含,false表示不包含。 | 不支持 |
query 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
accept_partial_success | false | 是否将部分成功视为错误。此配置仅适用于只读请求,写请求总是将部分成功视为错误。 | 支持 |
session_reclaim_interval_secs | 60 | 将 Session 信息发送给 Meta 服务的间隔。单位:秒。 | 支持 |
max_allowed_query_size | 4194304 | 最大查询语句长度。单位:字节。默认为4194304,即 4MB。 | 支持 |
networking 配置¶
必须在配置文件中使用真实的 IP 地址。否则某些情况下
127.0.0.1/0.0.0.0无法正确解析。
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
meta_server_addrs | 127.0.0.1:9559 | 全部 Meta 服务的 IP 地址和端口。多个 Meta 服务用英文逗号(,)分隔。 | 不支持 |
local_ip | 127.0.0.1 | Graph 服务的本地 IP 地址。本地 IP 地址用于识别 nebula-graphd 进程,如果是分布式集群或需要远程访问,请修改为对应地址。 | 不支持 |
listen_netdev | any | 监听的网络设备。 | 不支持 |
port | 9669 | Graph 服务的 RPC 守护进程监听端口。 | 不支持 |
reuse_port | false | 是否启用 SO_REUSEPORT。 | 不支持 |
listen_backlog | 1024 | socket 监听的连接队列最大长度,调整本参数需要同时调整net.core.somaxconn。 | 不支持 |
client_idle_timeout_secs | 28800 | 空闲连接的超时时间。取值范围为 1~604800,单位:秒。默认 8 小时。 | 不支持 |
session_idle_timeout_secs | 28800 | 空闲会话的超时时间。取值范围为 1~604800。默认 8 小时。单位:秒。 | 不支持 |
num_accept_threads | 1 | 接受传入连接的线程数。 | 不支持 |
num_netio_threads | 0 | 网络 IO 线程数。0表示 CPU 核数。 | 不支持 |
num_max_connections | 0 | 所有网络线程的最大活动连接数,0表示没有限制。 每个网络线程的最大连接数=num_max_connections/num_netio_threads。 | 不支持 |
num_worker_threads | 0 | 执行用户查询的线程数。0表示 CPU 核数。 | 不支持 |
ws_ip | 0.0.0.0 | HTTP 服务的 IP 地址。 | 不支持 |
ws_http_port | 19669 | HTTP 服务的端口。 | 不支持 |
heartbeat_interval_secs | 10 | 默认心跳间隔。请确保所有服务的heartbeat_interval_secs取值相同,否则会导致系统无法正常工作。单位:秒。 | 支持 |
storage_client_timeout_ms | - | Graph 服务与 Storage 服务的 RPC 连接超时时间。初始配置文件中未设置该参数,使用需手动添加。默认值为60000毫秒。 | 不支持 |
enable_record_slow_query | true | 是否启用慢查询记录。注:企业版功能。 | 不支持 |
slow_query_limit | 100 | 慢查询记录的最大条数。注:企业版功能。 | 不支持 |
slow_query_threshold_us | 200000 | 定义超过多长时间的查询为慢查询。单位:微秒。 | 不支持 |
ws_meta_http_port | 19559 | HTTP 协议监听 Meta 服务的端口,需要和 Meta 服务配置文件中的ws_http_port保持一致。 | 不支持 |
charset and collate 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
default_charset | utf8 | 创建图空间时的默认字符集。 | 不支持 |
default_collate | utf8_bin | 创建图空间时的默认排序规则。 | 不支持 |
authorization 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
enable_authorize | false | 用户登录时是否进行身份验证。身份验证详情请参见身份验证。 | 不支持 |
auth_type | password | 用户登录的身份验证方式。取值为password、ldap、cloud。 | 不支持 |
memory 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
system_memory_high_watermark_ratio | 0.8 | 内存高水位报警机制的触发阈值。系统内存占用率高于该值会触发报警机制,NebulaGraph会停止接受查询。 | 支持 |
metrics 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
enable_space_level_metrics | false | 开启后可打开图空间级别的监控,对应的监控指标名称中包含图空间的名称,例如query_latency_us{space=basketballplayer}.avg.3600。支持的监控指标可用curl命令查看,详细说明参见查询监控指标。 | 不支持 |
session 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
max_sessions_per_ip_per_user | 300 | 相同用户和 IP 地址可以创建的最大活跃会话数。 | 不支持 |
experimental 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
enable_experimental_feature | false | 实验性功能开关。可选值为true和false。 | 不支持 |
enable_data_balance | true | 是否开启均衡分片功能。仅当enable_experimental_feature为true时生效。 | 不支持 |
memory tracker 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
memory_tracker_limit_ratio | 0.8 | 可用内存的百分比,当可用内存低于该值时,NebulaGraph会停止接受查询。 计算公式:可用内存/(总内存 - 保留内存)。 注意:对于混合部署的集群,需要根据实际情况调小该参数。例如,当预期 Graphd 只占用 50% 的内存时,该参数的值可设置为小于0.5。 | 支持 |
memory_tracker_untracked_reserved_memory_mb | 50 | 保留内存的大小,单位:MB。 | 支持 |
memory_tracker_detail_log | false | 是否定期生成较详细的内存跟踪日志。当值为true时,会定期生成内存跟踪日志。 | 支持 |
memory_tracker_detail_log_interval_ms | 60000 | 内存跟踪日志的生成时间间隔,单位:毫秒。仅当memory_tracker_detail_log为true时,该参数生效。 | 支持 |
memory_purge_enabled | true | 是否定期开启内存清理功能。当值为true时,会定期清理内存。 | 支持 |
memory_purge_interval_seconds | 10 | 内存清理的时间间隔,单位:秒。memory_purge_enabled为true时,该参数生效。 | 支持 |
performance optimization 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
max_job_size | 1 | 最大作业并发数,即查询执行时在可以并发执行的阶段所采用的最大线程数。建议为物理 CPU 核数的一半。 | 支持 |
min_batch_size | 8192 | 处理数据集的最小批处理大小。仅在max_job_size大于 1 时生效。 | 支持 |
optimize_appendvertices | false | 启用后,执行MATCH语句时不过滤悬挂边。 | 支持 |
path_batch_size | 10000 | 每个线程构建的路径数。 | 支持 |
2.1.7Storage 服务配置¶
basics 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
daemonize | true | 是否启动守护进程。 | 不支持 |
pid_file | pids/nebula-storaged.pid | 记录进程 ID 的文件。 | 不支持 |
timezone_name | UTC+00:00:00 | 指定NebulaGraph的时区。初始配置文件中未设置该参数,如需使用请手动添加。格式请参见 Specifying the Time Zone with TZ。例如,东八区的设置方式为--timezone_name=UTC+08:00。 | 不支持 |
local_config | true | 是否从配置文件获取配置信息。 | 不支持 |
- 在插入时间类型的属性值时,NebulaGraph会根据
timezone_name设置的时区将该时间值(TIMESTAMP 类型例外)转换成相应的 UTC 时间,因此在查询中返回的时间类型属性值为 UTC 时间。 timezone_name参数只用于转换NebulaGraph中存储的数据,NebulaGraph进程中其它时区相关数据,例如日志打印的时间等,仍然使用主机系统默认的时区。
logging 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
log_dir | logs | 存放 Storage 服务日志的目录,建议和数据保存在不同硬盘。 | 不支持 |
minloglevel | 0 | 最小日志级别,即记录此级别或更高级别的日志。可选值:0(INFO)、1(WARNING)、2(ERROR)、3(FATAL)。建议在调试时设置为0,生产环境中设置为1。如果设置为4,NebulaGraph不会记录任何日志。 | 支持 |
v | 0 | VLOG 日志详细级别,即记录小于或等于此级别的所有 VLOG 消息。可选值为0、1、2、3、4、5。glog 提供的 VLOG 宏允许用户定义自己的数字日志记录级别,并用参数v控制记录哪些详细消息。详情参见 Verbose Logging。 | 支持 |
logbufsecs | 0 | 缓冲日志的最大时间,超时后输出到日志文件。0表示实时输出。单位:秒。 | 不支持 |
redirect_stdout | true | 是否将标准输出和标准错误重定向到单独的输出文件。 | 不支持 |
stdout_log_file | storaged-stdout.log | 标准输出日志文件名称。 | 不支持 |
stderr_log_file | storaged-stderr.log | 标准错误日志文件名称。 | 不支持 |
stderrthreshold | 3 | 要复制到标准错误中的最小日志级别(minloglevel)。 | 不支持 |
timestamp_in_logfile_name | true | 日志文件名称中是否包含时间戳。true表示包含,false表示不包含。 | 不支持 |
networking 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
meta_server_addrs | 127.0.0.1:9559 | 全部 Meta 服务的 IP 地址和端口。多个 Meta 服务用英文逗号(,)分隔。 | 不支持 |
local_ip | 127.0.0.1 | Storage 服务的本地 IP 地址。本地 IP 地址用于识别 nebula-storaged 进程,如果是分布式集群或需要远程访问,请修改为对应地址。 | 不支持 |
port | 9779 | Storage 服务的 RPC 守护进程监听端口。Storage 服务对外端口为9779,对内端口为9777、9778和9780,NebulaGraph使用内部端口进行多副本间的交互。 9777:drainer 服务占用端口,仅在企业版集群中暴露;9778:Admin 服务(Storage 接收 Meta 命令的服务)占用的端口;9780:Raft 通信端口。 | 不支持 |
ws_ip | 0.0.0.0 | HTTP 服务的 IP 地址。 | 不支持 |
ws_http_port | 19779 | HTTP 服务的端口。 | 不支持 |
heartbeat_interval_secs | 10 | 默认心跳间隔。请确保所有服务的heartbeat_interval_secs取值相同,否则会导致系统无法正常工作。单位:秒。 | 支持 |
Caution
必须在配置文件中使用真实的 IP 地址。否则某些情况下127.0.0.1/0.0.0.0无法正确解析。
raft 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
raft_heartbeat_interval_secs | 30 | Raft 选举超时时间。单位:秒。 | 支持 |
raft_rpc_timeout_ms | 500 | Raft 客户端的远程过程调用(RPC)超时时间。单位:毫秒。 | 支持 |
wal_ttl | 14400 | Raft WAL 的有效时间。单位:秒。 | 支持 |
disk 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
data_path | data/storage | 数据存储路径,多个路径用英文逗号(,)分隔。一个 RocksDB 实例对应一个路径。 | 不支持 |
minimum_reserved_bytes | 268435456 | 每个数据存储路径的剩余空间最小值,低于该值时,可能会导致集群数据写入失败。单位:字节。 | 不支持 |
rocksdb_batch_size | 4096 | 批量操作的缓存大小。单位:字节。 | 不支持 |
rocksdb_block_cache | 4 | BlockBasedTable 的默认块缓存大小。单位:兆字节。 | 不支持 |
disable_page_cache | false | 允许或禁止NebulaGraph使用操作系统的页缓存。默认值为false,表示允许使用 page cache。当值为true时,禁止NebulaGraph使用 page cache,此时须设置充足的块缓存(block cache)空间。 | 不支持 |
engine_type | rocksdb | 存储引擎类型。 | 不支持 |
rocksdb_compression | lz4 | 压缩算法,可选值:no、snappy、lz4、lz4hc、zlib、bzip2、zstd。 该参数会修改每一层的压缩算法,如需为不同层级设置不同的压缩算法,请使用rocksdb_compression_per_level参数。 | 不支持 |
rocksdb_compression_per_level | - | 为不同层级设置不同的压缩算法。优先级高于rocksdb_compression。例如no:no:lz4:lz4:snappy:zstd:snappy。 也可以不设置某个层级的压缩算法,例如no:no:lz4:lz4::zstd,此时 L4、L6 层使用rocksdb_compression参数的压缩算法。 | 不支持 |
enable_rocksdb_statistics | false | 是否启用 RocksDB 的数据统计。 | 不支持 |
rocksdb_stats_level | kExceptHistogramOrTimers | RocksDB 的数据统计级别。可选值:kExceptHistogramOrTimers(禁用计时器统计,跳过柱状图统计)、kExceptTimers(跳过计时器统计)、kExceptDetailedTimers(收集除互斥锁和压缩花费时间之外的所有统计数据)、kExceptTimeForMutex收集除互斥锁花费时间之外的所有统计数据)、kAll(收集所有统计数据)。 | 不支持 |
enable_rocksdb_prefix_filtering | true | 是否启用 prefix bloom filter,启用时可以提升图遍历速度,但是会增加内存消耗。 | 不支持 |
enable_rocksdb_whole_key_filtering | false | 是否启用 whole key bloom filter。 | 不支持 |
rocksdb_filtering_prefix_length | 12 | 每个 key 的 prefix 长度。可选值:12(分片 ID+点 ID)、16(分片 ID+点 ID+TagID/Edge typeID)。单位:字节。 | 不支持 |
enable_partitioned_index_filter | false | 设置为true可以降低 bloom 过滤器占用的内存大小,但是在某些随机寻道(random-seek)的情况下,可能会降低读取性能。初始配置文件中未设置该参数,如需使用请手动添加。 | 不支持 |
misc 配置¶
下表中的snapshot与NebulaGraph快照是不同的概念,这里的snapshot指 Raft 同步过程中 leader 上的存量数据。
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
query_concurrently | true | 是否开启多线程查询。开启后可以提高单个查询的时延性能,但大压力下会降低整体的吞吐量。 | 支持 |
auto_remove_invalid_space | true | 在执行DROP SPACE后,会删除指定图空间,该参数设置是否同时删除指定图空间内的所有数据。当值为true时,同时删除指定图空间内的所有数据。 | 支持 |
num_io_threads | 16 | 网络 I/O 线程的数量,用于发送 RPC 请求和接收响应。 | 支持 |
num_max_connections | 0 | 所有网络线程的最大活动连接数,0表示没有限制。 每个网络线程的最大连接数=num_max_connections/num_netio_threads。 | 不支持 |
num_worker_threads | 32 | Storage 的 RPC 服务的工作线程数量。 | 支持 |
max_concurrent_subtasks | 10 | TaskManager 并发执行子任务的最大个数。 | 支持 |
snapshot_part_rate_limit | 10485760 | Raft leader 向 Raft group 中其它成员同步存量数据时的限速。单位:字节/秒。 | 支持 |
snapshot_batch_size | 1048576 | Raft leader 向 Raft group 中其它成员同步存量数据时每批发送的数据量。单位:字节。 | 支持 |
rebuild_index_part_rate_limit | 4194304 | 重建索引过程中,Raft leader 向 Raft group 中其它成员同步索引数据时的限速。单位:字节/秒。 | 支持 |
rebuild_index_batch_size | 1048576 | 重建索引过程中,Raft leader 向 Raft group 中其它成员同步索引数据时每批发送的数据量。单位:字节。 | 支持 |
rocksdb options 配置¶
| 名称 | 预设值 | 说明 | 是否支持运行时动态修改 |
|---|---|---|---|
rocksdb_db_options | {} | RocksDB database 选项。 | 支持 |
rocksdb_column_family_options | {"write_buffer_size":"67108864", "max_write_buffer_number":"4", "max_bytes_for_level_base":"268435456"} | RocksDB column family 选项。 | 支持 |
rocksdb_block_based_table_options | {"block_size":"8192"} | RocksDB block based table 选项。 | 支持 |
2.1.8Linux 内核配置¶
本文介绍与NebulaGraph相关的 Linux 内核配置,并介绍如何修改配置。
资源控制¶
ulimit 注意事项¶
命令ulimit用于为当前 shell 会话设置资源阈值,注意事项如下:
-
ulimit所做的更改仅对当前会话或子进程生效。 -
资源的阈值(软阈值)不能超过硬阈值。
-
普通用户不能使用命令调整硬阈值,即使使用
sudo也不能调整。 -
修改系统级别或调整硬性阈值,请编辑文件
/etc/security/limits.conf。这种方式需要重新登录才生效。
ulimit -c¶
ulimit -c用于限制 core 文件的大小,建议设置为unlimited,命令如下:
ulimit -c unlimited
- 1
ulimit -n¶
ulimit -n用于限制打开文件的数量,建议设置为超过 10 万,例如:
ulimit -n 130000
- 1
内存¶
vm.swappiness¶
vm.swappiness是触发虚拟内存(swap)的空闲内存百分比。值越大,使用 swap 的可能性就越大,建议设置为 0,表示首先删除页缓存。需要注意的是,0 表示尽量不使用 swap。
vm.min_free_kbytes¶
vm.min_free_kbytes用于设置 Linux 内核保留的最小空闲千字节数。如果系统内存足够,建议设置较大值。例如物理内存为 128 GB,可以将vm.min_free_kbytes设置为 5 GB。如果值太小,会导致系统无法申请足够的连续物理内存。
vm.max_map_count¶
vm.max_map_count用于限制单个进程的 VMA(虚拟内存区域)数量。默认值为65530,对于绝大多数应用程序来说已经足够。如果应用程序因为内存消耗过大而报错,请增大本参数的值。
vm.dirty_¶
vm.dirty_*是一系列控制系统脏数据缓存的参数。对于写密集型场景,用户可以根据需要进行调整(吞吐量优先或延迟优先),建议使用系统默认值。
Transparent huge page¶
为了降低延迟,用户必须关闭 THP(transparent huge page)。命令如下:
root# echo never > /sys/kernel/mm/transparent_hugepage/enabled
root# echo never > /sys/kernel/mm/transparent_hugepage/defrag
root# swapoff -a && swapon -a
- 1
- 2
- 3
为了防止系统重启后该配置失效,可以在GRUB配置文件或/etc/rc.local中添加相关配置,使系统启动时自动关闭 THP。
网络¶
net.ipv4.tcp_slow_start_after_idle¶
net.ipv4.tcp_slow_start_after_idle默认值为 1,会导致闲置一段时间后拥塞窗口超时,建议设置为0,尤其适合大带宽高延迟场景。
net.core.somaxconn¶
net.core.somaxconn用于限制 socket 监听的连接队列数量。默认值为128。对于有大量突发连接的场景,建议设置为不低于1024。
net.ipv4.tcp_max_syn_backlog¶
net.ipv4.tcp_max_syn_backlog用于限制处于 SYN_RECV(半连接)状态的 TCP 连接数量。默认值为128。对于有大量突发连接的场景,建议设置为不低于1024。
net.core.netdev_max_backlog¶
net.core.netdev_max_backlog用于限制队列中数据包的数量。默认值为1000,建议设置为10000以上,尤其是万兆网卡。
net.ipv4.tcp_keepalive_*¶
net.ipv4.tcp_keepalive_*是一系列保持 TCP 连接存活的参数。对于使用四层透明负载均衡的应用程序,如果空闲连接异常断开,请增大tcp_keepalive_time和tcp_keepalive_intvl的值。
net.ipv4.tcp_wmem/rmem¶
TCP 套接字发送/接收缓冲池的最小、最大、默认空间。对于大连接,建议设置为带宽 (GB) *往返时延 (ms)。
scheduler¶
对于 SSD 设备,建议将scheduler设置为noop或者none,路径为/sys/block/DEV_NAME/queue/scheduler。
其他参数¶
kernel.core_pattern¶
建议设置为core,并且将kernel.core_uses_pid设置为1。
修改参数¶
sysctl 命令¶
-
sysctl <conf_name>查看当前参数值。
-
sysctl -w <conf_name>=<value>临时修改参数值,立即生效,重启后恢复原值。
-
sysctl -p [<file_path>]从指定配置文件里加载 Linux 系统参数,默认从
/etc/sysctl.conf加载。
prlimit¶
命令prlimit可以获取和设置进程资源的限制,结合sudo可以修改硬阈值,例如,prlimit --nofile=140000 --pid=$$调整当前进程允许的打开文件的最大数量为140000,立即生效,此命令仅支持 RedHat 7u 或更高版本。
2.1.9运行日志
NebulaGraph默认使用 glog 打印运行日志,使用 gflags 控制日志级别,并在运行时通过 HTTP 接口动态修改日志级别,方便跟踪问题
运行日志的默认目录为/usr/local/nebula/logs/。
如果在NebulaGraph运行过程中删除运行日志目录,日志不会继续打印,但是不会影响业务。重启服务可以恢复正常。
配置说明
minloglevel:最小日志级别,即不会记录低于这个级别的日志。可选值为0(INFO)、1(WARNING)、2(ERROR)、3(FATAL)。建议在调试时设置为0,生产环境中设置为1。如果设置为4,NebulaGraph不会记录任何日志。
v:日志详细级别,值越大,日志记录越详细。可选值为0、1、2、3。
Meta 服务、Graph 服务和 Storage 服务的日志级别可以在各自的配置文件中查看,默认路径为/usr/local/nebula/etc/。
查看运行日志级别
使用如下命令查看当前所有的 gflags 参数(包括日志参数):
curl <ws_ip>:<ws_port>/flags
- 1
| 参数 | 说明 |
|---|---|
| ws_ip | HTTP 服务的 IP 地址,可以在配置文件中查看。默认值为127.0.0.1。 |
| ws_port | HTTP 服务的端口,可以在配置文件中查看。默认值分别为19559(Meta)、19669(Graph)19779(Storage)。 |
示例如下:
查看 Meta 服务当前的最小日志级别:
curl 127.0.0.1:19559/flags | grep 'minloglevel'
- 1
查看 Storage 服务当前的日志详细级别:
curl 127.0.0.1:19779/flags | grep -w 'v'
- 1
修改运行日志级别
使用如下命令修改运行日志级别:
curl -X PUT -H "Content-Type: application/json" -d '{"<key>":<value>[,"<key>":<value>]}' "<ws_ip>:<ws_port>/flags"
- 1
| 参数 | 说明 |
|---|---|
| key | 待修改的运行日志类型,可选值请参见配置说明。 |
| value | 运行日志级别,可选值请参见配置说明。 |
| ws_ip | HTTP 服务的 IP 地址,可以在配置文件中查看。默认值为127.0.0.1。 |
| ws_port | HTTP 服务的端口,可以在配置文件中查看。默认值分别为19559(Meta)、19669(Graph)19779(Storage)。 |
示例如下:
curl -X PUT -H "Content-Type: application/json" -d '{"minloglevel":0,"v":3}' "127.0.0.1:19779/flags" #storaged
curl -X PUT -H "Content-Type: application/json" -d '{"minloglevel":0,"v":3}' "127.0.0.1:19669/flags" #graphd
curl -X PUT -H "Content-Type: application/json" -d '{"minloglevel":0,"v":3}' "127.0.0.1:19559/flags" # metad
- 1
- 2
- 3
如果在NebulaGraph运行时修改了运行日志级别,重启服务后会恢复为配置文件中设置的级别,如果需要永久修改,请修改配置文件。
2.2 集群部署
2.2.1集群角色
将单机版复制的基础虚拟机复制为三份,配置其IP如下
| 计算机名称 | IP地址 | graphd | storaged | metad |
|---|---|---|---|---|
| nebula1 | 10.8.16.150 | 1 | 1 | 1 |
| nebula2 | 10.8.16.151 | 1 | 1 | 1 |
| nebula3 | 10.8.16.152 | 1 | 1 | 1 |
2.2.2hosts
10.8.16.150 nebula1
10.8.16.151 nebula2
10.8.16.152 nebula3
- 1
- 2
- 3
2.2.3修改配置
复制nebula-storaged.conf.production为nebula-storaged.conf
cd /usr/local/nebula/etc/
cp nebula-graphd.conf.production nebula-graphd.conf
cp nebula-storaged.conf.production nebula-storaged.conf
cp nebula-metad.conf.production nebula-metad.conf
- 1
- 2
- 3
- 4
| 计算机名称 | 要修改的配置 |
|---|---|
| nebula1 | nebula-graphd.conf,nebula-storaged.conf,nebula-metad.conf |
| nebula2 | nebula-graphd.conf,nebula-storaged.conf,nebula-metad.conf |
| nebula3 | nebula-graphd.conf,nebula-storaged.conf,nebula-metad.conf |
修改三个文件中对应配置如以下配置
-
nebula-graphd.conf########## networking ########## # Comma separated Meta Server Addresses --meta_server_addrs=10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559 # Local IP used to identify the nebula-graphd process. # Change it to an address other than loopback if the service is distributed or # will be accessed remotely. --local_ip=10.8.16.150 # Network device to listen on --listen_netdev=any # Port to listen on --port=9669 ########## authentication ########## # 设置用户认证 --enable_authorize=true # User login authentication type, password for nebula authentication, ldap for ldap authentication, cloud for cloud authentication --auth_type=password --failed_login_attempts=15 # 可选项,需要手动添加该参数。单个 Graph 节点允许连续输入错误密码的次数。超过该次数时,账户会被锁定。如果有多个 Graph 节点,允许的次数为节点数 * 次数。 --password_lock_time_in_secs=60 #可选项,需要手动添加该参数。多次输入错误后,账户被锁定的时间。单位:秒。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
-
nebula-storaged.conf########## networking ########## # Comma separated Meta server addresses --meta_server_addrs=10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559 # Local IP used to identify the nebula-storaged process. # Change it to an address other than loopback if the service is distributed or # will be accessed remotely. --local_ip=10.8.16.150 # Storage daemon listening port --port=9779- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
nebula-metad.conf########## networking ########## # Comma separated Meta Server addresses --meta_server_addrs=10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559 # Local IP used to identify the nebula-metad process. # Change it to an address other than loopback if the service is distributed or # will be accessed remotely. --local_ip=10.8.16.150 # Meta daemon listening port --port=9559- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2.4启动集群
在每台计算机上启动相应的服务。说明如下。
| 计算机名称 | 要启动的进程 |
|---|---|
| nebula1 | graphd, storaged, metad |
| nebula2 | graphd, storaged, metad |
| nebula3 | graphd, storaged, metad |
#启动命令
sudo /usr/local/nebula/scripts/nebula.service start all
sudo /usr/local/nebula/scripts/nebula.service start metad
sudo /usr/local/nebula/scripts/nebula.service start graphd
sudo /usr/local/nebula/scripts/nebula.service start storaged
- 1
- 2
- 3
- 4
- 5
2.2.5连接集群
原生CLI客户端连接
- 下载原生CLI客户端安装包
- 解压重命名文件为
nebula-console,对于Windows,请将文件重命名为 。nebula-console.exe - 授予原生CLI客户端二进制文件的执行权限。对于 Windows,请跳过此步骤。
- 连接控制台
#对于 Linux 或 macOS:
./nebula-console -addr <ip> -port <port> -u <username> -p <password>
[-t 120] [-e "nGQL_statement" | -f filename.nGQL]
#对于Windows:
nebula-console.exe -addr <ip> -port <port> -u <username> -p <password>
[-t 120] [-e "nGQL_statement" | -f filename.nGQL]
- 1
- 2
- 3
- 4
- 5
- 6
NebulaGraph Studio
为了方便连接数据库,需要部署NebulaGraph Studio,它是一款可以通过 Web 访问的开源图数据库可视化工具。
- 下载安装包
最新活动-NebulaGraph 图数据库 (nebula-graph.com.cn)
- 解压
tar -xzvf nebula-graph-studio-3.5.0.x86_64.tar.gz
- 1
- 启动
cd /usr/local/nebula/nebula-graph-studio
nohup ./server start &
- 1
- 2
- 访问web
如果未开启认证,输入ip端口后,用户为root,密码root(随意输入即可登录),如果开了默认密码为nebula
http://10.8.16.150:7001/login
注:连接后控制台输入以下SQL,集群才能正常运转
ADD HOSTS 10.8.16.150:9779, 10.8.16.151:9779, 10.8.16.152:9779;
- 1
三、NebulaGraph监控指标¶
3.1监控指标结构说明
NebulaGraph的每个监控指标都由三个部分组成,中间用英文句号(.)隔开,例如num_queries.sum.600。不同的NebulaGraph服务支持查询的监控指标也不同。指标结构的说明如下。
| 类型 | 示例 | 说明 |
|---|---|---|
| 指标名称 | num_queries | 简单描述指标的含义。 |
| 统计类型 | sum | 指标统计的方法。当前支持 SUM、AVG、RATE 和 P 分位数(P75、P95、P99、P999)。 |
| 统计时间 | 600 | 指标统计的时间范围,当前支持 5 秒、60 秒、600 秒和 3600 秒,分别表示最近 5 秒、最近 1 分钟、最近 10 分钟和最近 1 小时。 |
3.2通过 HTTP 端口查询监控指标
语法
curl -G "http://<ip>:<port>/stats?stats=<metric_name_list> [&format=json]"
- 1
| 选项 | 说明 |
|---|---|
ip | 服务器的 IP 地址,可以在安装目录内查看配置文件获取。 |
port | 服务器的 HTTP 端口,可以在安装目录内查看配置文件获取。默认情况下,Meta 服务端口为 19559,Graph 服务端口为 19669,Storage 服务端口为 19779。 |
metric_name_list | 监控指标名称,多个监控指标用英文逗号(,)隔开。 |
&format=json | 将结果以 JSON 格式返回。 |
- 如果NebulaGraph服务部署在容器中,需要执行docker-compose ps命令查看映射到容器外部的端口,然后通过该端口查询。
3.3查询图空间监控指标
Graph 服务支持一系列基于图空间的监控指标,对不同图空间的数据分别记录。
图空间指标只能通过查询所有监控指标的形式查询到,例如curl -G "http://10.8.16.150:19559/stats",返回结果中以{space=space_name}的形式包含图空间名称,例如num_active_queries{space=basketballplayer}.sum.5=0。
- 如需开启图空间监控指标,先在 Graph 服务的配置文件中将enable_space_level_metrics参数的值修改为true,再启动NebulaGraph。修改配置的详细方式参见配置管理。
3.4监控指标说明
3.4.1Graph
| 参数 | 说明 |
|---|---|
| num_active_queries | 活跃的查询语句数的变化数。计算公式:时间范围内开始执行的语句数减去执行完毕的语句数。 |
| num_active_sessions | 活跃的会话数的变化数。计算公式:时间范围内登录的会话数减去登出的会话数。例如查询num_active_sessions.sum.5,过去 5 秒中登录了 10 个会话数,登出了 30 个会话数,那么该指标值就是-20(10-30)。 |
| num_aggregate_executors | 聚合(Aggregate)算子执行时间。 |
| num_auth_failed_sessions_bad_username_password | 因用户名密码错误导验证失败的会话数量。 |
| num_auth_failed_sessions_out_of_max_allowed | 因为超过FLAG_OUT_OF_MAX_ALLOWED_CONNECTIONS****参数导致的验证登录的失败的会话数量。 |
| num_auth_failed_sessions | 登录验证失败的会话数量。 |
| num_indexscan_executors | 索引扫描(IndexScan)算子执行时间。 |
| num_killed_queries | 被终止的查询数量。 |
| num_opened_sessions | 服务端建立过的会话数量。 |
| num_queries | 查询次数。 |
| num_query_errors_leader_changes | 因查询错误而导致的 Leader 变更的次数。 |
| num_query_errors | 查询错误次数。 |
| num_reclaimed_expired_sessions | 服务端主动回收的过期的会话数量。 |
| num_rpc_sent_to_metad_failed | Graphd 服务发给 Metad 的 RPC 请求失败的数量。 |
| num_rpc_sent_to_metad | Graphd 服务发给 Metad 服务的 RPC 请求数量。 |
| num_rpc_sent_to_storaged_failed | Graphd 服务发给 Storaged 服务的 RPC 请求失败的数量。 |
| num_rpc_sent_to_storaged | Graphd 服务发给 Storaged 服务的 RPC 请求数量。 |
| num_sentences | Graphd 服务接收的语句数。 |
| num_slow_queries | 慢查询次数。 |
| num_sort_executors | 排序(Sort)算子执行时间。 |
| optimizer_latency_us | 优化器阶段延迟时间。 |
| query_latency_us | 查询延迟时间。 |
| slow_query_latency_us | 慢查询延迟时间。 |
| num_queries_hit_memory_watermark | 达到内存水位线的语句的数量。 |
3.4.2Meta
| 参数 | 说明 |
|---|---|
| commit_log_latency_us | Raft 协议中 Commit 日志的延迟时间。 |
| commit_snapshot_latency_us | Raft 协议中 Commit 快照的延迟时间。 |
| heartbeat_latency_us | 心跳延迟时间。 |
| num_heartbeats | 心跳次数。 |
| num_raft_votes | Raft 协议中投票的次数。 |
| transfer_leader_latency_us | Raft 协议中转移 Leader 的延迟时间。 |
| num_agent_heartbeats | AgentHBProcessor 心跳次数。 |
| agent_heartbeat_latency_us | AgentHBProcessor 延迟时间。 |
| replicate_log_latency_us | Raft 复制日志至大多数节点的延迟。 |
| num_send_snapshot | Raft 发送快照至其他节点的次数。 |
| append_log_latency_us | Raft 复制日志到单个节点的延迟。 |
| append_wal_latency_us | Raft 写入单条 WAL 的延迟。 |
| num_grant_votes | Raft 投票给其他节点的次数。 |
| num_start_elect | Raft 发起投票的次数。 |
3.4.3Storage
| 参数 | 说明 |
|---|---|
| add_edges_latency_us | 添加边的延迟时间。 |
| add_vertices_latency_us | 添加点的延迟时间。 |
| commit_log_latency_us | Raft 协议中 Commit 日志的延迟时间。 |
| commit_snapshot_latency_us | Raft 协议中 Commit 快照的延迟时间。 |
| delete_edges_latency_us | 删除边的延迟时间。 |
| delete_vertices_latency_us | 删除点的延迟时间。 |
| get_neighbors_latency_us | 查询邻居延迟时间。 |
| get_dst_by_src_latency_us | 通过起始点获取终点的延迟时间。 |
| num_get_prop | GetPropProcessor 执行的次数。 |
| num_get_neighbors_errors | GetNeighborsProcessor 执行出错的次数。 |
| num_get_dst_by_src_errors | GetDstBySrcProcessor 执行出错的次数。 |
| get_prop_latency_us | GetPropProcessor 执行的延迟时间。 |
| num_edges_deleted | 删除的边数量。 |
| num_edges_inserted | 插入的边数量。 |
| num_raft_votes | Raft 协议中投票的次数。 |
| num_rpc_sent_to_metad_failed | Storaged 服务发给 Metad 服务的 RPC 请求失败的数量。 |
| num_rpc_sent_to_metad | Storaged 服务发给 Metad 服务的 RPC 请求数量。 |
| num_tags_deleted | 删除的 Tag 数量。 |
| num_vertices_deleted | 删除的点数量。 |
| num_vertices_inserted | 插入的点数量。 |
| transfer_leader_latency_us | Raft 协议中转移 Leader 的延迟时间。 |
| lookup_latency_us | LookupProcessor 执行的延迟时间。 |
| num_lookup_errors | LookupProcessor 执行时出错的次数。 |
| num_scan_vertex | ScanVertexProcessor 执行的次数。 |
| num_scan_vertex_errors | ScanVertexProcessor 执行时出错的次数。 |
| update_edge_latency_us | UpdateEdgeProcessor 执行的延迟时间。 |
| num_update_vertex | UpdateVertexProcessor 执行的次数。 |
| num_update_vertex_errors | UpdateVertexProcessor 执行时出错的次数。 |
| kv_get_latency_us | Getprocessor 的延迟时间。 |
| kv_put_latency_us | PutProcessor 的延迟时间。 |
| kv_remove_latency_us | RemoveProcessor 的延迟时间。 |
| num_kv_get_errors | GetProcessor 执行出错次数。 |
| num_kv_get | GetProcessor 执行次数。 |
| num_kv_put_errors | PutProcessor 执行出错次数。 |
| num_kv_put | PutProcessor 执行次数。 |
| num_kv_remove_errors | RemoveProcessor 执行出错次数。 |
| num_kv_remove | RemoveProcessor 执行次数。 |
| forward_tranx_latency_us | 传输延迟时间。 |
| scan_edge_latency_us | ScanEdgeProcessor 执行的延迟时间。 |
| num_scan_edge_errors | ScanEdgeProcessor 执行时出错的次数。 |
| num_scan_edge | ScanEdgeProcessor 执行的次数。 |
| scan_vertex_latency_us | ScanVertexProcessor 执行的延迟时间。 |
| num_add_edges | 添加边的次数。 |
| num_add_edges_errors | 添加边时出错的次数。 |
| num_add_vertices | 添加点的次数。 |
| num_start_elect | Raft 发起投票的次数 |
| num_add_vertices_errors | 添加点时出错的次数。 |
| num_delete_vertices_errors | 删除点时出错的次数。 |
| append_log_latency_us | Raft 复制日志到单个节点的延迟。 |
| num_grant_votes | Raft 投票给其他节点的次数。 |
| replicate_log_latency_us | Raft 复制日志到大多数节点的延迟。 |
| num_delete_tags | 删除 Tag 的次数。 |
| num_delete_tags_errors | 删除 Tag 时出错的次数。 |
| num_delete_edges | 删除边的次数。 |
| num_delete_edges_errors | 删除边时出错的次数。 |
| num_send_snapshot | 发送快照的次数。 |
| update_vertex_latency_us | UpdateVertexProcessor 执行的延迟时间。 |
| append_wal_latency_us | Raft 写入单条 WAL 的延迟。 |
| num_update_edge | UpdateEdgeProcessor 执行的次数。 |
| delete_tags_latency_us | 删除 Tag 的延迟时间。 |
| num_update_edge_errors | UpdateEdgeProcessor 执行时出错的次数。 |
| num_get_neighbors | GetNeighborsProcessor 执行的次数。 |
| num_get_dst_by_src | GetDstBySrcProcessor 执行的次数。 |
| num_get_prop_errors | GetPropProcessor 执行时出错的次数。 |
| num_delete_vertices | 删除点的次数。 |
| num_lookup | LookupProcessor 执行的次数。 |
| num_sync_data | Storage 同步 Drainer 数据的次数。 |
| num_sync_data_errors | Storage 同步 Drainer 数据出错的次数。 |
| sync_data_latency_us | Storage 同步 Drainer 数据的延迟时间。 |
3.4.4图空间级别监控指标
- 图空间级别监控指标是动态创建的, 只有当图空间内触发该行为时,对应的指标才会创建,用户才能查询到。
| 参数 | 说明 |
|---|---|
| num_active_queries | 当前正在执行的查询数。 |
| num_queries | 查询次数。 |
| num_sentences | Graphd 服务接收的语句数。 |
| optimizer_latency_us | 优化器阶段延迟时间。 |
| query_latency_us | 查询延迟时间。 |
| num_slow_queries | 慢查询次数。 |
| num_query_errors | 查询报错语句数量。 |
| num_query_errors_leader_changes | 因查询错误而导致的 Leader 变更的次数。 |
| num_killed_queries | 被终止的查询数量。 |
| num_aggregate_executors | 聚合(Aggregate)算子执行时间。 |
| num_sort_executors | 排序(Sort)算子执行时间。 |
| num_indexscan_executors | 索引扫描(IndexScan)算子执行时间。 |
| num_auth_failed_sessions_bad_username_password | 因用户名密码错误导验证失败的会话数量。 |
| num_auth_failed_sessions | 登录验证失败的会话数量。 |
| num_opened_sessions | 服务端建立过的会话数量。 |
| num_queries_hit_memory_watermark | 达到内存水位线的语句的数量。 |
| num_reclaimed_expired_sessions | 服务端主动回收的过期的会话数量。 |
| num_rpc_sent_to_metad_failed | Graphd 服务发给 Metad 的 RPC 请求失败的数量。 |
| num_rpc_sent_to_metad | Graphd 服务发给 Metad 服务的 RPC 请求数量。 |
| num_rpc_sent_to_storaged_failed | Graphd 服务发给 Storaged 服务的 RPC 请求失败的数量。 |
| num_rpc_sent_to_storaged | Graphd 服务发给 Storaged 服务的 RPC 请求数量。 |
| slow_query_latency_us | 慢查询延迟时间。 |
3.2 RocksDB 统计数据¶
3.3 NebulaGraph Dashboard
NebulaGraph Dashboard(简称 Dashboard)是一款用于监控NebulaGraph集群中机器和服务状态的可视化工具。
3.3.1前置条件
-
NebulaGraph服务已经部署并启动。详细信息参考 NebulaGraph安装部署。
-
确保以下端口未被使用:
9200、9100、9090、8090、7003 -
待监控的所有机器上已经安装 node-exporter。
yum install wget
cd /usr/local/nebula
#下载不了官网手动下载 https://prometheus.io/download/#node_exporter
wget https://github.com/prometheus/node_exporter/releases/tag/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar xvfz node_exporter-1.6.1.linux-amd64.tar.gz
mv node_exporter-1.6.1.linux-amd64 /node_exporter
cd node_exporter
- 1
- 2
- 3
- 4
- 5
- 6
- 7
vi /etc/systemd/system/node_exporter.service
#添加以下内容
[Unit]
Description=node_exporter server
After=network.target
[Service]
ExecStart=/usr/local/nebula/node_exporter/node_exporter
Restart=always
[Install]
WantedBy=multi-user.target
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
systemctl start node_exporter.service
systemctl enable node_exporter.service
- 1
- 2
3.3.2安装Dashboard
安裝包部署
-
下载 TAR 包 nebula-dashboard-3.4.0.x86_64.tar.gz。
-
执行命令
tar -xvf nebula-dashboard-3.4.0.x86_64.tar.gz解压缩。 -
进入解压缩的
nebula-dashboard文件夹,并修改配置文件config.yaml。
配置文件内主要包含 4 种依赖服务的配置和集群的配置。依赖服务的说明如下。
| 服务名称 | 默认端口号 | 说明 |
|---|---|---|
| nebula-http-gateway | 8090 | 为集群服务提供 HTTP 接口,执行 nGQL 语句与NebulaGraph进行交互。 |
| nebula-stats-exporter | 9200 | 收集集群的性能指标,包括服务 IP 地址、版本和监控指标(例如查询数量、查询延迟、心跳延迟 等)。 |
| node-exporter | 9100 | 收集集群中机器的资源信息,包括 CPU、内存、负载、磁盘和流量。 |
| prometheus | 9090 | 存储监控数据的时间序列数据库。 |
配置文件说明如下。
port: 7003 # Web 服务端口。
gateway:
ip: 10.8.16.150 # 部署 Dashboard 的机器 IP。
port: 8090
https: false # 是否为 HTTPS 端口。
runmode: dev # 程序运行模式,包括 dev、test、prod。一般用于区分不同运行环境。
stats-exporter:
ip: 10.8.16.150 # 部署 Dashboard 的机器 IP。
nebulaPort: 9200
https: false # 是否为 HTTPS 端口。
node-exporter:
- ip: 10.8.16.150 # 部署node-exporter的机器 IP。
port: 9100
https: false # 是否为 HTTPS 端口。
- ip: 10.8.16.151
port: 9100
https: false
- ip: 10.8.16.153
port: 9100
https: false
prometheus:
ip: 10.8.16.150 # 部署 Dashboard 的机器 IP。
prometheusPort: 9090
https: false # 是否为 HTTPS 端口。
scrape_interval: 5s # 收集监控数据的间隔时间。默认为 1 分钟。
evaluation_interval: 5s # 告警规则扫描时间间隔。默认为 1 分钟。
# 集群节点信息
nebula-cluster:
name: 'default' # 集群名称
metad:
- name: metad0
endpointIP: 10.8.16.150 # 部署 Meta 服务的机器 IP。
port: 9559
endpointPort: 19559
- name: metad1
endpointIP: 10.8.16.151 # 部署 Meta 服务的机器 IP。
port: 9559
endpointPort: 19559
- name: metad2
endpointIP: 10.8.16.152 # 部署 Meta 服务的机器 IP。
port: 9559
endpointPort: 19559
graphd:
- name: graphd0
endpointIP: 10.8.16.150 # 部署 Graph 服务的机器 IP。
port: 9669
endpointPort: 19669
- name: graphd1
endpointIP: 10.8.16.151 # 部署 Graph 服务的机器 IP。
port: 9669
endpointPort: 19669
- name: graphd2
endpointIP: 10.8.16.152 # 部署 Graph 服务的机器 IP。
port: 9669
endpointPort: 19669
storaged:
- name: storaged0
endpointIP: 10.8.16.150 # 部署 Storage 服务的机器 IP。
port: 9779
endpointPort: 19779
- name: storaged1
endpointIP: 10.8.16.151 # 部署 Storage 服务的机器 IP。
port: 9779
endpointPort: 19779
- name: storaged2
endpointIP: 10.8.16.152 # 部署 Storage 服务的机器 IP。
port: 9779
endpointPort: 19779
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 执行
./dashboard.service start all一键启动服务。
容器部署¶
如果使用容器部署 Dashboard,同样是修改配置文件config.yaml,修改完成后,执行docker-compose up -d即可启动容器。
如果修改了
config.yaml内的端口号,docker-compose.yaml里的端口号也需要保持一致。执行
docker-compose stop命令停止容器部署的 Dashboard。
3.2.3管理 Dashboard 服务¶
Dashboard 使用脚本dashboard.service管理服务,包括启动、重启、停止和查看状态。
sudo <dashboard_path>/dashboard.service
[-v] [-h]
<start|restart|stop|status> <prometheus|webserver|exporter|gateway|all>
- 1
- 2
- 3
| 参数 | 说明 |
|---|---|
dashboard_path | Dashboard 安装路径。 |
-v | 显示详细调试信息。 |
-h | 显示帮助信息。 |
start | 启动服务。 |
restart | 重启服务。 |
stop | 停止服务。 |
status | 查看服务状态。 |
prometheus | 管理 prometheus 服务。 |
webserver | 管理 webserver 服务。 |
exporter | 管理 exporter 服务。 |
gateway | 管理 gateway 服务。 |
all | 管理所有服务。 |
查看 Dashboard 版本可以使用命令./dashboard.service -version
四、NebulaGraph客户端
NebulaGraph提供多种类型客户端,便于用户连接、管理NebulaGraph图数据库。
4.1 NebulaGraph Console:原生客户端
4.2 NebulaGraph CPP:C++ 客户端
4.3 NebulaGraph Java:Java 客户端
4.4 NebulaGraph Python:Python 客户端
下面是一个简单的案例
'''
pip install nebula3-python
'''
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
config = Config()
config.max_connection_pool_size = 2
# init connection pool
connection_pool = ConnectionPool()
assert connection_pool.init([('10.8.16.150', 9669)], config)
client = connection_pool.get_session('root', 'nebula')
#查询
res=client.execute_json('use `股权穿透-test`;match (v2)-[e1:投资*0..6]->(v:企业)-[e2:投资*0..6]->(v3) where id(v)=="2d5e50c1-945e-4b69-befe-fdd06a3336fd" and (e1 or e2) and (v2!=v or v3!=v) return v2 as `shareHolders`,v3 as `investmentCompany`,e1 as `shareholdingRatio`,e2 as `investmentRatio`;')
assert res.is_succeeded(),(res.error_code,res.error_msg)
from nebula3.data.ResultSet import ResultSet
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.5 NebulaGraph Go:Go 客户端
五、启动所有服务
cd /usr/local/nebula
scripts/nebula.service start all
cd /usr/local/nebula/nebula-graph-studio/
nohup ./server start &
systemctl start node_exporter.service
cd /usr/local/nebula/nebula-dashboard/
./dashboard.service start all
- 1
- 2
- 3
- 4
- 5
- 6
- 7
六、数据导入
6.1 NebulaGraph Importer¶
NebulaGraph Importer(简称 Importer)是一款NebulaGraph的 CSV 文件单机导入工具,可以读取并导入多种数据源的 CSV 文件数据。
功能¶
- 支持多种数据源,包括本地、S3、OSS、HDFS、FTP、SFTP。
- 支持导入 CSV 格式文件的数据。单个文件内可以包含多种 Tag、多种 Edge type 或者二者混合的数据。
- 支持同时连接多个 Graph 服务进行导入并且动态负载均衡。
- 支持失败后重连、重试。
- 支持多维度显示统计信息,包括导入时间、导入百分比等。统计信息支持打印在 Console 或日志中。
优势¶
-
轻量快捷:不需要复杂环境即可使用,快速导入数据。
-
灵活筛选:通过配置文件可以实现对 CSV 文件数据的灵活筛选。
6.1.1下载并解压
Release NebulaGraph Importer 4.0.0 · vesoft-inc/nebula-importer (github.com)
6.1.2job.yaml配置
- Client 配置¶
Client 配置存储客户端连接NebulaGraph相关的配置。
示例配置如下:
client:
version: v3
address: "192.168.1.100:9669,192.168.1.101:9669"
user: root
password: nebula
concurrencyPerAddress: 10
reconnectInitialInterval: 1s
retry: 3
retryInitialInterval: 1s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
| 参数 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|
client.version | v3 | 是 | 指定连接的NebulaGraph的大版本。当前仅支持v3。 |
client.address | "127.0.0.1:9669" | 是 | 指定连接的NebulaGraph地址。多个地址用英文逗号(,)分隔。 |
client.user | root | 否 | NebulaGraph的用户名。 |
client.password | nebula | 否 | NebulaGraph用户名对应的密码。 |
client.concurrencyPerAddress | 10 | 否 | 单个 Graph 服务的客户端并发连接数。 |
client.retryInitialInterval | 1s | 否 | 重连间隔时间。 |
client.retry | 3 | 否 | nGQL 语句执行失败的重试次数。 |
client.retryInitialInterval | 1s | 否 | 重试间隔时间。 |
- Manager 配置¶
Manager 配置是连接数据库后的人为控制配置。
示例配置如下:
manager:
spaceName: basic_string_examples
batch: 128
readerConcurrency: 50
importerConcurrency: 512
statsInterval: 10s
hooks:
before:
- statements:
- |
DROP SPACE IF EXISTS basic_string_examples;
CREATE SPACE IF NOT EXISTS basic_string_examples(partition_num=5, replica_factor=1, vid_type=int);
USE basic_string_examples;
wait: 10s
after:
- statements:
- |
SHOW SPACES;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
| 参数 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|
manager.spaceName | - | 是 | 指定数据要导入的图空间。不支持同时导入多个图空间。 |
manager.batch | 128 | 否 | 执行语句的批处理量(全局配置)。 对某个数据源单独设置批处理量可以使用下文的sources.batch。 |
manager.readerConcurrency | 50 | 否 | 读取器读取数据源的并发数。 |
manager.importerConcurrency | 512 | 否 | 生成待执行的 nGQL 语句的并发数,然后会调用客户端执行这些语句。 |
manager.statsInterval | 10s | 否 | 打印统计信息的时间间隔。 |
manager.hooks.before.[].statements | - | 否 | 导入前在图空间内执行的命令。 |
manager.hooks.before.[].wait | - | 否 | 执行statements语句后的等待时间。 |
manager.hooks.after.[].statements | - | 否 | 导入后在图空间内执行的命令。 |
manager.hooks.after.[].wait | - | 否 | 执行statements语句后的等待时间。 |
- Log 配置¶
Log 配置是设置日志相关配置。
示例配置如下:
log:
level: INFO
console: true
files:
- logs/nebula-importer.log
- 1
- 2
- 3
- 4
- 5
| 参数 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|
log.level | INFO | 否 | 日志级别。可选值为DEBUG、INFO、WARN、ERROR、PANIC、FATAL。 |
log.console | true | 否 | 存储日志时是否将日志同步打印到 Console。 |
log.files | - | 否 | 日志文件路径。需手动创建日志文件目录。 |
- Source 配置¶
Source 配置中需要配置数据源信息、数据处理方式和 Schema 映射。
示例配置如下:
sources:
- path: ./person.csv # 指定存储数据文件的路径。如果使用相对路径,则路径和当前配置文件目录拼接。也支持通配符文件名,例如:./follower-*.csv,请确保所有匹配的文件具有相同的架构。
# - s3: # AWS S3
# endpoint: endpoint # 可选。S3 服务端点,如果使用 AWS S3 可以省略。
# region: us-east-1 # 必填。S3 服务的区域。
# bucket: gdelt-open-data # 必填。S3 服务中的 bucket。
# key: events/20190918.export.csv # 必填。S3 服务中文件的 key。
# accessKeyID: "" # 可选。S3 服务的访问密钥。如果是公共数据,则无需配置。
# accessKeySecret: "" # 可选。S3 服务的密钥。如果是公共数据,则无需配置。
# - oss:
# endpoint: https://oss-cn-hangzhou.aliyuncs.com # 必填。OSS 服务端点。
# bucket: bucketName # 必填。OSS 服务中的 bucket。
# key: objectKey # 必填。OSS 服务中文件的 object key。
# accessKeyID: accessKey # 必填。OSS 服务的访问密钥。
# accessKeySecret: secretKey # 必填。OSS 服务的秘钥。
# - ftp:
# host: 192.168.0.10 # 必填。FTP 服务的主机。
# port: 21 # 必填。FTP 服务的端口。
# user: user # 必填。FTP 服务的用户名。
# password: password # 必填。FTP 服务的密码。
# path: "/events/20190918.export.csv" # FTP 服务中文件的路径。
# - sftp:
# host: 192.168.0.10 # 必填。SFTP 服务的主机。
# port: 22 # 必填。SFTP 服务的端口。
# user: user # 必填。SFTP 服务的用户名。
# password: password # 可选。SFTP 服务的密码。
# keyFile: keyFile # 可选。SFTP 服务的 SSH 密钥文件路径。
# keyData: keyData $ 可选。SFTP 服务的 SSH 密钥文件内容。
# passphrase: passphrase # 可选。SFTP 服务的 SSH 密钥密码。
# path: "/events/20190918.export.csv" # 必填。SFTP 服务中文件的路径。
# - hdfs:
# address: "127.0.0.1:8020" # 必填。HDFS 服务的地址。
# user: "hdfs" # 可选。HDFS 服务的用户名。
# path: "/events/20190918.export.csv" # 必填。HDFS 服务中文件的路径。
batch: 256
csv:
delimiter: "|"
withHeader: false
lazyQuotes: false
tags:
- name: Person
id:
type: "STRING"
function: "hash"
# index: 0
concatItems:
- person_
- 0
- _id
props:
- name: "firstName"
type: "STRING"
index: 1
- name: "lastName"
type: "STRING"
index: 2
- name: "gender"
type: "STRING"
index: 3
nullable: true
defaultValue: female
- name: "birthday"
type: "DATE"
index: 4
nullable: true
nullValue: _NULL_
- name: "creationDate"
type: "DATETIME"
index: 5
- name: "locationIP"
type: "STRING"
index: 6
- name: "browserUsed"
type: "STRING"
index: 7
- path: ./knows.csv
batch: 256
edges:
- name: KNOWS # person_knows_person
src:
id:
type: "STRING"
concatItems:
- person_
- 0
- _id
dst:
id:
type: "STRING"
concatItems:
- person_
- 1
- _id
props:
- name: "creationDate"
type: "DATETIME"
index: 2
nullable: true
nullValue: _NULL_
defaultValue: 0000-00-00T00:00:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
配置主要包括以下几个部分:
- 指定数据源信息。
- 指定执行语句的批处理量。
- 指定 CSV 文件格式信息。
- 指定 Tag 的模式映射。
- 指定 Edge type 的模式映射。
| 参数 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|
sources.path sources.s3 sources.oss sources.ftp sources.sftp sources.hdfs | - | 否 | 指定数据源信息,例如本地文件、HDFS、S3 等。一个source只能配置一种数据源,配置多个数据源请在多个source内配置。 不同数据源的配置项说明请参见示例内的注释。 |
sources.batch | 256 | 否 | 导入该数据源时执行语句的批处理量。优先级高于manager.batch。 |
sources.csv.delimiter | , | 否 | CSV 文件的分隔符。仅支持 1 个字符的字符串分隔符。使用特殊字符做分隔符时需要进行转义。例如当分隔符为十六进制0x03即Ctrl+C时,转义的写法为:"\x03"或"\u0003"。关于 yaml 格式特殊字符转义的细节请参见Escaped Characters。 |
sources.csv.withHeader | false | 否 | 是否忽略 CSV 文件中的第一条记录。 |
sources.csv.lazyQuotes | false | 否 | 是否允许惰性解析引号。如果值为true,引号可以出现在非引号字段中,非双引号可以出现在引号字段中,而不会引发解析错误。 |
sources.tags.name | - | 是 | Tag 名称。 |
sources.tags.id.type | STRING | 否 | VID 的类型。 |
sources.tags.id.function | - | 否 | 生成 VID 的函数。目前仅支持hash。 |
sources.tags.id.index | - | 否 | VID 对应的数据文件中的列号。如果未配置sources.tags.id.concatItems,该参数必须配置。 |
sources.tags.id.concatItems | - | 否 | 用于连接两个或多个数组,连接项可以是string、int或者混合。string代表常量,int表示索引列。如果设置了该参数,sources.tags.id.index参数将不生效。 |
sources.tags.ignoreExistedIndex | true | 否 | 是否启用IGNORE_EXISTED_INDEX,即插入点后不更新索引。 |
sources.tags.props.name | - | 是 | VID 上的属性名称,必须与数据库中的属性相同。 |
sources.tags.props.type | STRING | 否 | VID 上属性的数据类型。目前支持BOOL、INT、FLOAT、DOUBLE、STRING、TIME、TIMESTAMP、DATE、DATETIME、GEOGRAPHY、GEOGRAPHY(POINT)、GEOGRAPHY(LINESTRING)、GEOGRAPHY(POLYGON)。 |
sources.tags.props.index | - | 是 | 属性值对应的数据文件中的列号。 |
sources.tags.props.nullable | false | 否 | 属性是否可以为NULL,可选true或者false。 |
sources.tags.props.nullValue | - | 否 | nullable设置为true时,属性的值与nullValue相等则将该属性值设置为NULL。 |
sources.tags.props.alternativeIndices | - | 否 | 当nullable为false时忽略。该属性根据索引顺序从文件中获取,直到不等于nullValue。 |
sources.tags.props.defaultValue | - | 否 | 当nullable为false时忽略。根据index和alternativeIndices获取的所有值为nullValue时设置默认值。 |
sources.edges.name | - | 是 | Edge type 名称。 |
sources.edges.src.id.type | STRING | 否 | 边上起点 VID 的数据类型。 |
sources.edges.src.id.index | - | 是 | 边上起点 VID 对应的数据文件中的列号。 |
sources.edges.dst.id.type | STRING | 否 | 边上终点 VID 的数据类型。 |
sources.edges.dst.id.index | - | 是 | 边上终点 VID 对应的数据文件中的列号。 |
sources.edges.rank.index | - | 否 | 边上 RANK 对应的数据文件中的列号。 |
sources.edges.ignoreExistedIndex | true | 否 | 是否启用IGNORE_EXISTED_INDEX,即插入点后不更新索引。 |
sources.edges.props.name | - | 是 | 边上属性的名称,必须与数据库中的属性相同。 |
sources.edges.props.type | STRING | 否 | 边上属性的数据类型。目前支持BOOL、INT、FLOAT、DOUBLE、STRING、TIME、TIMESTAMP、DATE、DATETIME、GEOGRAPHY、GEOGRAPHY(POINT)、GEOGRAPHY(LINESTRING)、GEOGRAPHY(POLYGON)。 |
sources.edges.props.index | - | 是 | 属性值对应的数据文件中的列号。 |
sources.edges.props.nullable | - | 否 | 属性是否可以为NULL,可选true或者false。 |
sources.edges.props.nullValue | - | 否 | nullable设置为true时,属性的值与nullValue相等则将该属性值设置为NULL。 |
sources.edges.props.defaultValue | - | 否 | 当nullable为false时忽略。根据index和alternativeIndices获取的所有值为nullValue时设置默认值。 |
6.1.3编写job.yaml案例
本文以导出hdfs上的csv文件到nebula为例
更多导入模板
client:
version: v3
address: "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669"
user: root
password: nebula
concurrencyPerAddress: 10
reconnectInitialInterval: 1s
retry: 3
retryInitialInterval: 1s
manager:
#导入的图空间
spaceName: "股权穿透"
batch: 128
readerConcurrency: 50
importerConcurrency: 512
statsInterval: 10s
hooks:
before:
- statements:
- |
CREATE SPACE IF NOT EXISTS `股权穿透` (partition_num = 10, replica_factor = 1, charset = utf8, collate = utf8_bin, vid_type = FIXED_STRING(36)) comment = '股权穿透';
USE 股权穿透;
CREATE TAG IF NOT EXISTS `企业` ( `firm_name` string NULL COMMENT "企业名", `e_type` string NULL COMMENT "企业类型");
CREATE EDGE IF NOT EXISTS `投资` ( `sha_id_type` string NULL, `stock_percent` string NULL, `total_should_capi` string NULL, `total_real_capi` string NULL, `sha_type` string NULL);
CREATE TAG INDEX IF NOT EXISTS `firm_eid` ON `企业` ();
CREATE EDGE INDEX IF NOT EXISTS `sha_id` ON `投资` ();
wait: 3s
after:
- statements:
- |
SHOW SPACES;
log:
level: INFO
console: true
files:
- ../logs/nebula-importer.log
sources:
- hdfs:
address: "10.8.16.99:8020" # 必填。HDFS 服务的地址。
user: "cdh" # 可选。HDFS 服务的用户名。
path: "/user/cdh/点.csv" # 必填。HDFS 服务中文件的路径。
batch: 256
csv:
#分隔符
delimiter: ","
#是否有表头
withHeader: true
lazyQuotes: false
tags:
- name: "企业"
id:
type: "STRING"
index: 0
props:
- name: "firm_name"
type: "STRING"
index: 1
- name: "e_type"
type: "STRING"
index: 2
- hdfs:
address: "10.8.16.99:8020" # 必填。HDFS 服务的地址。
user: "cdh" # 可选。HDFS 服务的用户名。
path: "/user/cdh/边.csv" # 必填。HDFS 服务中文件的路径。
batch: 256
csv:
#分隔符
delimiter: ","
#是否有表头
withHeader: true
lazyQuotes: false
edges:
- name: "投资"
src:
id:
type: "STRING"
index: 1
dst:
id:
type: "STRING"
index: 0
props:
- name: "sha_type"
type: "STRING"
index: 2
- name: "sha_id_type"
type: "STRING"
index: 3
- name: "stock_percent"
type: "STRING"
index: 4
- name: "total_should_capi"
type: "STRING"
index: 5
- name: "total_real_capi"
type: "STRING"
index: 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
6.1.4提交job
./nebula-importer --config job.yaml
- 1
6.2 NebulaGraph Exchange
NebulaGraph Exchange(简称 Exchange)是一款 Apache Spark™ 应用,用于在分布式环境中将集群中的数据批量迁移到NebulaGraph中,能支持多种不同格式的批式数据和流式数据的迁移。
Exchange 由 Reader、Processor 和 Writer 三部分组成。Reader 读取不同来源的数据返回 DataFrame 后,Processor 遍历 DataFrame 的每一行,根据配置文件中fields的映射关系,按列名获取对应的值。在遍历指定批处理的行数后,Writer 会将获取的数据一次性写入到NebulaGraph中。下图描述了 Exchange 完成数据转换和迁移的过程。

优点
-
适应性强:支持将多种不同格式或不同来源的数据导入NebulaGraph,便于迁移数据。
-
支持导入 SST:支持将不同来源的数据转换为 SST 文件,用于数据导入。
-
支持 SSL 加密:支持在 Exchange 与NebulaGraph之间建立 SSL 加密传输通道,保障数据安全。
-
支持断点续传:导入数据时支持断点续传,有助于节省时间,提高数据导入效率。
-
异步操作:会在源数据中生成一条插入语句,发送给 Graph 服务,最后再执行插入操作。
-
灵活性强:支持同时导入多个 Tag 和 Edge type,不同 Tag 和 Edge type 可以是不同的数据来源或格式。
-
统计功能:使用 Apache Spark™ 中的累加器统计插入操作的成功和失败次数。
-
易于使用:采用 HOCON(Human-Optimized Config Object Notation)配置文件格式,具有面向对象风格,便于理解和操作。
6.2.1下载 JAR 文件¶
社区版 Exchange 的 JAR 文件可以直接下载。
要下载企业版 Exchange,需先获取NebulaGraph企业版套餐。
6.2.2配置application.conf
本文介绍使用 NebulaGraph Exchange 时如何修改配置文件 application.conf。
修改配置文件之前,建议根据数据源复制并修改文件名称,便于区分。例如数据源为 CSV 文件,可以复制为csv_application.conf。
配置文件的内容主要分为如下几类:
-
Spark 相关配置
-
Hive 配置(可选)
-
NebulaGraph相关配置
-
点配置
-
边配置
Spark 相关配置¶
本文只列出部分 Spark 参数,更多参数请参见官方文档。
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
spark.app.name | string | - | 否 | Spark 驱动程序名称。 |
spark.driver.cores | int | 1 | 否 | 驱动程序使用的 CPU 核数,仅适用于集群模式。 |
spark.driver.maxResultSize | string | 1G | 否 | 单个 Spark 操作(例如 collect)时,所有分区的序列化结果的总大小限制(字节为单位)。最小值为 1M,0 表示无限制。 |
spark.executor.memory | string | 1G | 否 | Spark 驱动程序使用的内存量,可以指定单位,例如 512M、1G。 |
spark.cores.max | int | 16 | 否 | 当驱动程序以“粗粒度”共享模式在独立部署集群或 Mesos 集群上运行时,跨集群(而非从每台计算机)请求应用程序的最大 CPU 核数。如果未设置,则值为 Spark 的独立集群管理器上的spark.deploy.defaultCores或 Mesos 上的 infinite(所有可用的内核)。 |
Hive 配置(可选)¶
如果 Spark 和 Hive 部署在不同集群,才需要配置连接 Hive 的参数,否则请忽略这些配置。
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
hive.warehouse | string | - | 是 | HDFS 中的 warehouse 路径。用双引号括起路径,以hdfs://开头。 |
hive.connectionURL | string | - | 是 | JDBC 连接的 URL。例如"jdbc:mysql://127.0.0.1:3306/hive_spark?characterEncoding=UTF-8"。 |
hive.connectionDriverName | string | "com.mysql.jdbc.Driver" | 是 | 驱动名称。 |
hive.connectionUserName | list[string] | - | 是 | 连接的用户名。 |
hive.connectionPassword | list[string] | - | 是 | 用户名对应的密码。 |
NebulaGraph相关配置¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
nebula.address.graph | list[string] | ["127.0.0.1:9669"] | 是 | 所有 Graph 服务的地址,包括 IP 和端口,多个地址用英文逗号(,)分隔。格式为["ip1:port1","ip2:port2","ip3:port3"]。 |
nebula.address.meta | list[string] | ["127.0.0.1:9559"] | 是 | 所有 Meta 服务的地址,包括 IP 和端口,多个地址用英文逗号(,)分隔。格式为["ip1:port1","ip2:port2","ip3:port3"]。 |
nebula.user | string | - | 是 | 拥有NebulaGraph写权限的用户名。 |
nebula.pswd | string | - | 是 | 用户名对应的密码。 |
nebula.space | string | - | 是 | 需要导入数据的的图空间名称。 |
nebula.ssl.enable.graph | bool | false | 是 | 开启 Exchange 与 Graph 服务之间的 SSL 加密传输。当值为true时开启,下方的 SSL 相关参数生效。如果 Exchange 运行在多机集群上,在设置以下 SSL 相关路径时,需要在每台机器的相同路径都存储相应的文件。 |
nebula.ssl.enable.meta | bool | false | 是 | 开启 Exchange 与 Meta 服务之间的 SSL 加密传输。当值为true时开启,下方的 SSL 相关参数生效。如果 Exchange 运行在多机集群上,在设置以下 SSL 相关路径时,需要在每台机器的相同路径都存储相应的文件。 |
nebula.ssl.sign | string | ca | 是 | 签名方式,可选值:ca(CA 签名)或self(自签名)。 |
nebula.ssl.ca.param.caCrtFilePath | string | "/path/caCrtFilePath" | 是 | nebula.ssl.sign的值为ca时生效,用于指定 CA 证书的存储路径。 |
nebula.ssl.ca.param.crtFilePath | string | "/path/crtFilePath" | 是 | nebula.ssl.sign的值为ca时生效,用于指定 CRT 证书的存储路径。 |
nebula.ssl.ca.param.keyFilePath | string | "/path/keyFilePath" | 是 | nebula.ssl.sign的值为ca时生效,用于指定私钥文件的存储路径。 |
nebula.ssl.self.param.crtFilePath | string | "/path/crtFilePath" | 是 | nebula.ssl.sign的值为self时生效,用于指定 CRT 证书的存储路径。 |
nebula.ssl.self.param.keyFilePath | string | "/path/keyFilePath" | 是 | nebula.ssl.sign的值为self时生效,用于指定私钥文件的存储路径。 |
nebula.ssl.self.param.password | string | "nebula" | 是 | nebula.ssl.sign的值为self时生效,用于指定密码文件的存储路径。 |
nebula.path.local | string | "/tmp" | 否 | 导入 SST 文件时需要设置本地 SST 文件路径。 |
nebula.path.remote | string | "/sst" | 否 | 导入 SST 文件时需要设置远端 SST 文件路径。 |
nebula.path.hdfs.namenode | string | "hdfs://name_node:9000" | 否 | 导入 SST 文件时需要设置 HDFS 的 namenode。 |
nebula.connection.timeout | int | 3000 | 否 | Thrift 连接的超时时间,单位为 ms。 |
nebula.connection.retry | int | 3 | 否 | Thrift 连接重试次数。 |
nebula.execution.retry | int | 3 | 否 | nGQL 语句执行重试次数。 |
nebula.error.max | int | 32 | 否 | 导入过程中的最大失败次数。当失败次数达到最大值时,提交的 Spark 作业将自动停止。 |
nebula.error.output | string | /tmp/errors | 否 | 输出错误日志的路径。错误日志保存执行失败的 nGQL 语句。 |
nebula.rate.limit | int | 1024 | 否 | 导入数据时令牌桶的令牌数量限制。 |
nebula.rate.timeout | int | 1000 | 否 | 令牌桶中拿取令牌的超时时间,单位:毫秒。 |
NebulaGraph默认不支持无 Tag 的点。如果需要导入无 Tag 的点,需要先在集群内开启支持无 Tag 点,然后在 Exchange 的配置文件内新增nebula.enableTagless参数,值为true。示例如下:
nebula: {
address:{
graph:["127.0.0.1:9669"]
meta:["127.0.0.1:9559"]
}
user: root
pswd: nebula
space: test
enableTagless: true
......
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
点配置¶
对于不同的数据源,点的配置也有所不同,有很多通用参数,也有部分特有参数,配置时需要配置通用参数和不同数据源的特有参数。
通用参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.name | string | - | 是 | NebulaGraph中定义的 Tag 名称。 |
tags.type.source | string | - | 是 | 指定数据源。例如csv。 |
tags.type.sink | string | client | 是 | 指定导入方式,可选值为client和SST。 |
tags.fields | list[string] | - | 是 | 属性对应的列的表头或列名。如果有表头或列名,请直接使用该名称。如果 CSV 文件没有表头,用[_c0, _c1, _c2]的形式表示第一列、第二列、第三列,以此类推。 |
tags.nebula.fields | list[string] | - | 是 | NebulaGraph中定义的属性名称,顺序必须和tags.fields一一对应。例如[_c1, _c2]对应[name, age],表示第二列为属性 name 的值,第三列为属性 age 的值。 |
tags.vertex.field | string | - | 是 | 点 ID 的列。例如 CSV 文件没有表头时,可以用_c0表示第一列的值作为点 ID。 |
tags.vertex.udf.separator | string | - | 否 | 通过自定义规则合并多列,该参数指定连接符。 |
tags.vertex.udf.oldColNames | list | - | 否 | 通过自定义规则合并多列,该参数指定待合并的列名。多个列用英文逗号(,)分隔。 |
tags.vertex.udf.newColName | string | - | 否 | 通过自定义规则合并多列,该参数指定新列的列名。 |
tags.batch | int | 256 | 是 | 单批次写入NebulaGraph的最大点数量。 |
tags.partition | int | 32 | 是 | Spark 分片数量。 |
Parquet/JSON/ORC 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.path | string | - | 是 | HDFS 中点数据文件的路径。用双引号括起路径,以hdfs://开头。 |
CSV 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.path | string | - | 是 | HDFS 中点数据文件的路径。用双引号括起路径,以hdfs://开头。 |
tags.separator | string | , | 是 | 分隔符。默认值为英文逗号(,)。对于特殊字符,如控制符^A,可以用 ASCII 八进制\001或 UNICODE 编码十六进制\u0001表示,控制符^B,用 ASCII 八进制\002或 UNICODE 编码十六进制\u0002表示,控制符^C,用 ASCII 八进制\003或 UNICODE 编码十六进制\u0003表示。 |
tags.header | bool | true | 是 | 文件是否有表头。 |
Hive 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.exec | string | - | 是 | 查询数据源的语句。例如select name,age from mooc.users。 |
MaxCompute 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.table | string | - | 是 | MaxCompute 的表名。 |
tags.project | string | - | 是 | MaxCompute 的项目名。 |
tags.odpsUrl | string | - | 是 | MaxCompute 服务的 odpsUrl。地址可根据阿里云文档查看。 |
tags.tunnelUrl | string | - | 是 | MaxCompute 服务的 tunnelUrl。地址可根据阿里云文档查看。 |
tags.accessKeyId | string | - | 是 | MaxCompute 服务的 accessKeyId。 |
tags.accessKeySecret | string | - | 是 | MaxCompute 服务的 accessKeySecret。 |
tags.partitionSpec | string | - | 否 | MaxCompute 表的分区描述。 |
tags.numPartitions | int | 1 | 否 | MaxCompute 的 Spark 连接器在读取 MaxCompute 数据时使用的分区数。 |
tags.sentence | string | - | 否 | 查询数据源的语句。SQL 语句中的表名和上方 table 的值相同。 |
Neo4j 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.exec | string | - | 是 | 查询数据源的语句。例如match (n:label) return n.neo4j-field-0。 |
tags.server | string | "bolt://127.0.0.1:7687" | 是 | Neo4j 服务器地址。 |
tags.user | string | - | 是 | 拥有读取权限的 Neo4j 用户名。 |
tags.password | string | - | 是 | 用户名对应密码。 |
tags.database | string | - | 是 | Neo4j 中保存源数据的数据库名。 |
tags.check_point_path | string | /tmp/test | 否 | 设置保存导入进度信息的目录,用于断点续传。如果未设置,表示不启用断点续传。 |
MySQL/PostgreSQL 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.host | string | - | 是 | MySQL/PostgreSQL 服务器地址。 |
tags.port | string | - | 是 | MySQL/PostgreSQL 服务器端口。 |
tags.database | string | - | 是 | 数据库名称。 |
tags.table | string | - | 是 | 需要作为数据源的表名称。 |
tags.user | string | - | 是 | 拥有读取权限的 MySQL/PostgreSQL 用户名。 |
tags.password | string | - | 是 | 用户名对应密码。 |
tags.sentence | string | - | 是 | 查询数据源的语句。例如"select teamid, name from team order by teamid"。 |
Oracle 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.url | string | - | 是 | Oracle 数据库连接地址。 |
tags.driver | string | - | 是 | Oracle 驱动地址。 |
tags.user | string | - | 是 | 拥有读取权限的 Oracle 用户名。 |
tags.password | string | - | 是 | 用户名对应密码。 |
tags.table | string | - | 是 | 需要作为数据源的表名称。 |
tags.sentence | string | - | 是 | 查询数据源的语句。例如"select playerid, name, age from player"。 |
ClickHouse 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.url | string | - | 是 | ClickHouse 的 JDBC URL。 |
tags.user | string | - | 是 | 有读取权限的 ClickHouse 用户名。 |
tags.password | string | - | 是 | 用户名对应密码。 |
tags.numPartition | string | - | 是 | ClickHouse 分区数。 |
tags.sentence | string | - | 是 | 查询数据源的语句。 |
Hbase 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.host | string | 127.0.0.1 | 是 | Hbase 服务器地址。 |
tags.port | string | 2181 | 是 | Hbase 服务器端口。 |
tags.table | string | - | 是 | 需要作为数据源的表名称。 |
tags.columnFamily | string | - | 是 | 表所属的列族(column family)。 |
Pulsar 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.service | string | "pulsar://localhost:6650" | 是 | Pulsar 服务器地址。 |
tags.admin | string | "http://localhost:8081" | 是 | 连接 pulsar 的 admin.url。 |
tags.options.<topic|topics| topicsPattern> | string | - | 是 | Pulsar 的选项,可以从topic、topics和topicsPattern选择一个进行配置。 |
tags.interval.seconds | int | 10 | 是 | 读取消息的间隔。单位:秒。 |
Kafka 源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.service | string | - | 是 | Kafka 服务器地址。 |
tags.topic | string | - | 是 | 消息类别。 |
tags.interval.seconds | int | 10 | 是 | 读取消息的间隔。单位:秒。 |
生成 SST 时的特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
tags.path | string | - | 是 | 指定需要生成 SST 文件的源文件的路径。 |
tags.repartitionWithNebula | bool | true | 否 | 生成 SST 文件时是否要基于NebulaGraph中图空间的 partition 进行数据重分区。开启该功能可减少 DOWNLOAD 和 INGEST SST 文件需要的时间。 |
边配置¶
对于不同的数据源,边的配置也有所不同,有很多通用参数,也有部分特有参数,配置时需要配置通用参数和不同数据源的特有参数。
边配置的不同数据源特有参数请参见上方点配置内的特有参数介绍,注意区分 tags 和 edges 即可。
通用参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
edges.name | string | - | 是 | NebulaGraph中定义的 Edge type 名称。 |
edges.type.source | string | - | 是 | 指定数据源。例如csv。 |
edges.type.sink | string | client | 是 | 指定导入方式,可选值为client和SST。 |
edges.fields | list[string] | - | 是 | 属性对应的列的表头或列名。如果有表头或列名,请直接使用该名称。如果 CSV 文件没有表头,用[_c0, _c1, _c2]的形式表示第一列、第二列、第三列,以此类推。 |
edges.nebula.fields | list[string] | - | 是 | NebulaGraph中定义的属性名称,顺序必须和edges.fields一一对应。例如[_c2, _c3]对应[start_year, end_year],表示第三列为开始年份的值,第四列为结束年份的值。 |
edges.source.field | string | - | 是 | 边的起始点的列。例如_c0表示第一列的值作为边的起始点。 |
edges.target.field | string | - | 是 | 边的目的点的列。例如_c1表示第二列的值作为边的目的点。 |
edges.ranking | int | - | 否 | rank 值的列。没有指定时,默认所有 rank 值为0。 |
edges.batch | int | 256 | 是 | 单批次写入NebulaGraph的最大边数量。 |
edges.partition | int | 32 | 是 | Spark 分片数量。 |
生成 SST 时的特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
edges.path | string | - | 是 | 指定需要生成 SST 文件的源文件的路径。 |
edges.repartitionWithNebula | bool | true | 否 | 生成 SST 文件时是否要基于NebulaGraph中图空间的 partition 进行数据重分区。开启该功能可减少 DOWNLOAD 和 INGEST SST 文件需要的时间。 |
NebulaGraph源特有参数¶
| 参数 | 数据类型 | 默认值 | 是否必须 | 说明 |
|---|---|---|---|---|
edges.path | string | "hdfs://namenode:9000/path/edge" | 是 | 指定 CSV 文件的存储路径。设置的路径必须不存在,Exchange 会自动创建该路径。存储到 HDFS 服务器时路径格式同默认值,例如"hdfs://192.168.8.177:9000/edge/follow"。存储到本地时路径格式为"file:///path/edge",例如"file:///home/nebula/edge/follow"。有多个 Edge 时必须为每个 Edge 设置不同的目录。 |
edges.noField | bool | false | 是 | 当值为true时,仅导出起始点 VID、目的点 VID 和 Rank,而不导出属性数据;当值为false时导出起始点 VID、目的点 VID、Rank 和属性数据。 |
edges.return.fields | list | [] | 是 | 指定要导出的属性。例如,要导出start_year和end_year属性,需将参数值设置为["start_year","end_year"]。该参数仅在edges.noField的值为false时生效。 |
导入模板
6.2.3提交spark任务
-
首次导入
<spark_install_path>/bin/spark-submit --master "local" --class com.vesoft.nebula.exchange.Exchange <nebula-exchange-2.x.y.jar_path> -c <application.conf_path>- 1
-
导入 reload 文件
如果首次导入时有一些数据导入失败,会将导入失败的数据存入 reload 文件,可以用参数
-r尝试导入 reload 文件。<spark_install_path>/bin/spark-submit --master "local" --class com.vesoft.nebula.exchange.Exchange <nebula-exchange-2.x.y.jar_path> -c <application.conf_path>- 1
-
spark-yarn模式
spark-submit \ --class com.vesoft.nebula.exchange.Exchange \ --master yarn --deploy-mode cluster \ --conf spark.driver.extraClassPath=./ \ --conf spark.executor.extraClassPath=./ \ --conf spark.driver.extraJavaOptions=-Dfile.encoding=utf-8 \ --conf spark.executor.extraJavaOptions=-Dfile.encoding=utf-8 \ hdfs:///user/spark/nebula-exchange_spark_2.4-3.5.0.jar \ -c hdfs:///user/spark/application.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6.3 NebulaGraph Spark Connector
6.3.1下载对应的jar包并上传到hdfs
vesoft-inc/nebula-spark-connector (github.com)
6.3.2获取spark对象
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
from pyspark.sql.types import *
spark = SparkSession.builder \
.appName("mysql_to_hive") \
.master('local') \
.config('spark.sql.shuffle.partitions', '200') \
.config('spark.jars', 'hdfs:///user/cdh/jars/nebula-spark-connector-3.4.0.jar') \
.getOrCreate()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.3.3pyspark读取
#type:vertex(点) or edge(边)
#spaceName: 图空间名
#label:点/边的名称
#returnCols:读取的字段
df = spark.read.format(
"com.vesoft.nebula.connector.NebulaDataSource").option(
"type", "edge").option(
"spaceName", "股权穿透-test").option(
"label", "投资").option(
"returnCols", "sha_id_type,stock_percent,total_should_capi,total_real_capi,sha_type").option(
"metaAddress", "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559").option(
"partitionNumber", 1).load()
df1 = spark.read.format("com.vesoft.nebula.connector.NebulaDataSource")\
.option("metaAddress", "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559")\
.option("user", "root")\
.option("passwd", "nebula")\
.option("partitionNumber", 1)\
.option("type", "vertex")\
.option("spaceName", "股权穿透")\
.option("label", "企业")\
.option("returnCols", "firm_name,e_type")\
.load()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
6.3.4pyspark写入
#vertex
#type:vertex(点) or edge(边)
#spaceName: 图空间名
#vidPolicy: vid处理方式 如(hash,"")
#vertexField: vid字段
#writeMode:inser delete update
#**df字段名需与schema字段名对应**
df1.write.format("com.vesoft.nebula.connector.NebulaDataSource")\
.mode("overwrite")\
.options(**{
"label": "企业",
"vidPolicy": "",
"vertexField": "_vertexId",
"user":"root",
"passwd": "nebula",
"type": "vertex",
"spaceName": "股权穿透",
"batch": 100,
"metaAddress": "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559",
"graphAddress": "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669,10.8.16.153:9669,10.8.16.152:9669",
"writeMode": "insert"
}).save()
#srcVertexField: 出点字段名
#dstVertexField: 入点字段名
#rankField: 排名字段(可为空)
df.write.format("com.vesoft.nebula.connector.NebulaDataSource")\
.mode("overwrite").options(**{
"srcPolicy": "",
"dstPolicy": "",
"user": "root",
"passwd": "nebula",
"type": "edge",
"spaceName": "股权穿透",
"label": "投资",
"srcVertexField": "_srcId",
"dstVertexField": "_dstId",
"rankField": "_rank",
"metaAddress": "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559",
"graphAddress": "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669,10.8.16.153:9669,10.8.16.154:9669",
"writeMode": "update",
"batch": "100"
}).save()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
6.3.5完整案例
#job.py
# NebulaGraph Importer从hdfs导入股权穿透-test
#使用spark导入数据到股权穿透
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark = SparkSession.builder \
.appName("ngraph") \
.config('spark.sql.shuffle.partitions', '200') \
.config('spark.jars', 'hdfs:///user/cdh/jars/nebula-spark-connector-3.4.0.jar') \
.config("spark.executor.extraJavaOptions", "-Dfile.encoding=UTF-8") \
.config("spark.driver.extraJavaOptions", "-Dfile.encoding=UTF-8") \
.getOrCreate()
# 读取nebula数据
df=spark.read.format("com.vesoft.nebula.connector.NebulaDataSource")\
.options(**{
'spaceName':"股权穿透-test",
'type':'vertex',
'label':'企业',
'returnCols':'firm_name,e_type',
"partitionNumber": 1,
"user": "root",
"passwd": "nebula",
"metaAddress": "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559",
"graphAddress": "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669,10.8.16.153:9669,10.8.16.154:9669",
"batch": "100"
}).load()
df1=spark.read.format("com.vesoft.nebula.connector.NebulaDataSource")\
.options(**{
'spaceName':"股权穿透-test",
'type':'edge',
'label':'投资',
'returnCols':'sha_id_type,stock_percent,total_should_capi,total_real_capi,sha_type',
"partitionNumber":1,
"user": "root",
"passwd": "nebula",
"metaAddress": "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559",
"graphAddress": "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669,10.8.16.153:9669,10.8.16.154:9669",
"batch": "100"
}).load()
# 将df导入nebula
df.write.format("com.vesoft.nebula.connector.NebulaDataSource")\
.mode("overwrite").options(**{
'spaceName':"股权穿透spark",
"type": "vertex",
"label": "企业",
"vidPolicy": "",
"vertexField": "_vertexId",
"writeMode": "insert",
"user": "root",
"passwd": "nebula",
"metaAddress": "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559",
"graphAddress": "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669,10.8.16.153:9669,10.8.16.154:9669",
"batch": "100"
}).save()
df1.write.format("com.vesoft.nebula.connector.NebulaDataSource")\
.mode("overwrite").options(**{
'spaceName':"股权穿透spark",
"srcPolicy": "",
"dstPolicy": "",
"type": "edge",
"label": "投资",
"srcVertexField": "_srcId",
"dstVertexField": "_dstId",
"rankField": "_rank",
"writeMode": "insert",
"user": "root",
"passwd": "nebula",
"metaAddress": "10.8.16.150:9559,10.8.16.151:9559,10.8.16.152:9559",
"graphAddress": "10.8.16.150:9669,10.8.16.151:9669,10.8.16.152:9669,10.8.16.153:9669,10.8.16.154:9669",
"batch": "100"
}).save()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
6.3.6spark-submit提交
spark-submit \
--master yarn --deploy-mode cluster \
--conf spark.driver.extraJavaOptions=-Dfile.encoding=utf-8 \
--conf spark.executor.extraJavaOptions=-Dfile.encoding=utf-8 \
--queue "root.users.cdh" \
--conf "spark.network.timeout=300s" \
--jars "hdfs:///user/cdh/jars/nebula-spark-connector-3.4.0.jar" \
./job.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.4如何选择导入工具

两种Spark工具的区别
NebulaGraph Exchange和NebulaGraph Spark Connector在功能和使用方式上有一些区别。
- 功能范围:NebulaGraph Exchange是一个用于数据导入和导出的工具,它可以与多种数据源进行连接,并支持数据格式转换和数据传输。它的重点在于数据的迁移和共享。而NebulaGraph Spark Connector专注于在Apache Spark中读写NebulaGraph数据,它提供了直接在Spark应用中操作NebulaGraph数据的能力,可以利用Spark的数据处理和分析能力进行复杂的计算和分析操作。
- 应用方式:NebulaGraph Exchange通常以独立应用的形式运行,你可以使用命令行界面或配置文件来执行数据导入和导出。NebulaGraph Exchange也有一个Spark Connector版本,可以与Spark集成,利用Spark的并行计算优势。而NebulaGraph Spark Connector是作为一个Spark库(Jar包)存在,你可以在Spark应用中直接使用Spark的DataFrame和DataSet API来读写NebulaGraph数据。
- 性能和扩展性:NebulaGraph Spark Connector利用Spark的分布式计算能力,可以处理大规模数据集并实现高性能的数据读写。它支持Spark的并行处理和在集群中的扩展性,适用于对大量数据进行复杂处理和分析的场景。NebulaGraph Exchange也可以通过Spark Connector版本来提高性能,但作为独立工具,其扩展性可能没有NebulaGraph Spark Connector更强大。
总的来说,NebulaGraph Exchange适用于数据导入和导出的场景,而NebulaGraph Spark Connector适用于在Spark中进行大规模数据处理和分析的场景,并与NebulaGraph数据库进行交互。选择哪个工具取决于具体的使用场景和需求。
6.5导入数据遇到的问题
6.5.1导入数据后中文乱码
提交spark任务时加上以下配置
--conf spark.driver.extraJavaOptions=-Dfile.encoding=utf-8 \
--conf spark.executor.extraJavaOptions=-Dfile.encoding=utf-8 \
- 1
- 2
6.5.2导入数据中途失败:Blacklisting behavior can be configured via spark.blacklist.*.
降低速率,加大超时时间,提交spark任务时加上以下配置
--conf spark.blacklist.enable=true
- 1
七、Nebula数据备份
7.1NebulaGraph BR(社区版)
7.1.1安装BR-client
只安装在一台机器上
- 下载 BR。
wget https://github.com/vesoft-inc/nebula-br/releases/download/v3.5.0/br-3.5.0-linux-amd64
- 1
- 修改文件名称为
br。
sudo mv br-3.5.0-linux-amd64 br
- 1
- 授予 BR 执行权限。
sudo chmod +x br
- 1
- 执行
./br version查看 BR 版本。
[nebula-br]$ ./br version
Nebula Backup And Restore Utility Tool,V-3.5.0
- 1
- 2
7.1.2安装BR-agent
安装在集群的所有机器上
- 下载 Agent。
wget https://github.com/vesoft-inc/nebula-agent/releases/download/v3.4.0/agent-3.4.0-linux-amd64
- 1
- 修改 Agent 的名称为
agent。
sudo mv agent-3.4.0-linux-amd64 agent
- 1
- 授予 Agent 可执行权限。
sudo chmod +x agent
- 1
- 执行以下命令启动 Agent。
sudo nohup ./agent --agent="<当前服务器_ip>:8888" --meta="<当前服务器_ip>:9559" > nebula_agent.log 2>&1 &
- 1
- 查看服务状态
集群控制台输入
show hosts agent
- 1
| Host | Port | Status | Role | Git Info Sha | Version |
|---|---|---|---|---|---|
| 10.8.16.150 | 8888 | ONLINE | AGENT | 8cf348a | EMPTY |
| 10.8.16.151 | 8888 | ONLINE | AGENT | 8cf348a | EMPTY |
| 10.8.16.152 | 8888 | ONLINE | AGENT | 8cf348a | EMPTY |
7.1.3使用 BR 备份数据
-
./br backup full --meta "192.168.8.129:9559" --storage "local:///home/nebula/backup/"- 1
-
运行以下命令对 meta 服务的地址为
192.168.8.129:9559的整个集群进行全量备份操作,并将备份文件保存到兼容 s3 协议的对象存储服务br-test桶下的backup中。./br backup full --meta "192.168.8.129:9559" --s3.endpoint "http://192.168.8.129:9000" --storage="s3://br-test/backup/" --s3.access_key=minioadmin --s3.secret_key=minioadmin --s3.region=default- 1
以下列出命令的相关参数。
| 参数 | 数据类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|
-h,--help | - | 否 | 无 | 查看帮助。 |
--debug | - | 否 | 无 | 查看更多日志信息。 |
--log | string | 否 | "br.log" | 日志路径。 |
--meta | string | 是 | 无 | meta 服务的地址和端口号。 |
--spaces | stringArray | 否 | 无 | (实验性功能)指定要备份的图空间名字,未指定将备份所有图空间。可指定多个图空间,用法为--spaces nba_01 --spaces nba_02。 |
--storage | string | 是 | 无 | BR 备份数据存储位置,格式为:<Schema>://<PATH> Schema:可选值为 local 和 s3。选择 s3 时,需要填写s3.access_key、s3.endpoint、s3.region和 s3.secret_key。 PATH:存储位置的路径。 |
--s3.access_key | string | 否 | 无 | 用于标识用户。 |
--s3.endpoint | string | 否 | 无 | S3 对外服务的访问域名的 URL,指定 http 或 https。 |
--s3.region | string | 否 | 无 | 数据中心所在物理位置。 |
--s3.secret_key | string | 否 | 无 | 用户用于加密签名字符串和用来验证签名字符串的密钥,必须保密。 |
7.1.4使用 BR 恢复数据
- 用户可以使用以下命令列出现有备份信息:
./br show --storage <storage_path>
- 1
例如,可以使用以下命令列出在本地 /home/nebula/backup 路径中的备份的信息。
$ ./br show --storage "local:///home/nebula/backup"
+----------------------------+---------------------+------------------------+-------------+------------+
| NAME | CREATE TIME | SPACES | FULL BACKUP | ALL SPACES |
+----------------------------+---------------------+------------------------+-------------+------------+
| BACKUP_2022_02_10_07_40_41 | 2022-02-10 07:40:41 | basketballplayer | true | true |
| BACKUP_2022_02_11_08_26_43 | 2022-02-11 08:26:47 | basketballplayer,foesa | true | true |
+----------------------------+---------------------+------------------------+-------------+------------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
或使用以下命令列出在兼容 s3 协议的对象存储服务 br-test 桶下的backup中的备份的信息。
./br show --s3.endpoint "http://192.168.8.129:9000" --storage="s3://br-test/backup/" --s3.access_key=minioadmin --s3.secret_key=minioadmin --s3.region=default
- 1
以下列出命令的相关参数。
| 参数 | 数据类型 | 是否必需 | 默认值 | 说明 |
|---|---|---|---|---|
-h,-help | - | 否 | 无 | 查看帮助。 |
--debug | - | 否 | 无 | 查看更多日志信息。 |
--log | string | 否 | “br.log” | 日志路径。 |
--storage | string | 是 | 无 | BR 备份数据存储位置,格式为:声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】 推荐阅读 相关标签 Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。 |

