
- 1【Quartus】Quartus18.1的安装以及使用_quartus 18.1安装
- 2java 中final修饰的变量_Java学习笔记18---final关键字修饰变量、方法及类
- 3ORACLE显示毫秒_oracle 毫秒
- 4GraphDTA | 基于图卷积网络预测药物-靶标结合亲和力
- 5AndroidSDK安装和环境配置_android sdk环境配置
- 6使用基于智能搜索和大模型打造企业下一代知识库-LangChain 集成及其在电商的应用...
- 7MySQL 超详细 学习 教程(附带有保姆级图文安装配置教程)_mysql教程
- 8字节跳动头条研发---测试开发一面面经(附答案)_字节跳动测试开发
- 9牛客网项目---2.3.查看帖子详情以及显示评论
- 10Kafka->一个好用的IntelliJ IDEA插件: kafkalytic
Python读取Excel的几种工具包(附Demo)_python读取excel文件
赞
踩
前言
处理Excel一般涉及到如下场景:
- Python web开发中的导入导出
- 爬取数据,抽取数据等
- 深度学习中的数据处理等
正常读取一个txt格式的文件,可以使用open的方法进行打开,再通过readlines进行读取!
具体如下:
path = r'test.txt'
frame = open(path, encoding='utf-8')
print(frame.readlines())
# 不用则把文件关闭
frame.close()
- 1
- 2
- 3
- 4
- 5
- 6
截图如下:(txt涉及中文需要加多一个参数 encoding='utf-8')

1. openpyxl库
-
工作表操作: 使用
openpyxl库时,可以操作工作表,读取单元格的值、设置单元格的值,以及进行各种其他工作表级别的操作 -
Excel 样式:
openpyxl设置单元格的样式,包括字体、颜色、边框等 -
写入 Excel 文件: 除了读取,
openpyxl也支持创建新的 Excel 文件、写入数据,并保存。
openpyxl 是一个处理 Excel 文件的库
使用过程中需要先安装:pip install openpyxl

示例代码如下:(使用 openpyxl 库逐行读取 Excel 文件的内容。)
from openpyxl import load_workbook
# 打开 Excel 文件
workbook = load_workbook('test.xlsx')
# 选择工作表
sheet = workbook.active
# 读取数据
for row in sheet.iter_rows(min_row=1, max_col=sheet.max_column, max_row=sheet.max_row):
for cell in row:
print(cell.value, end='\t')
print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
截图如下:

2. pandas库
-
数据结构:
pandas使用DataFrame这一数据结构表示表格形式的数据。了解如何使用 DataFrame 对象是使用 pandas 的关键 -
读取指定工作表: 如果 Excel 文件包含多个工作表,可以使用
sheet_name参数指定要读取的工作表。
例如:pd.read_excel('your_excel_file.xlsx', sheet_name='Sheet1') -
数据操作:
pandas提供了丰富的数据操作功能,例如过滤、排序、合并等,可以使用这些功能轻松处理 Excel 中的数据
对于pandas有些特殊,使用过程需要提前安装以下两个库:
pip install pandas
pip install openpyxl
- 1
- 2
示例代码如下:
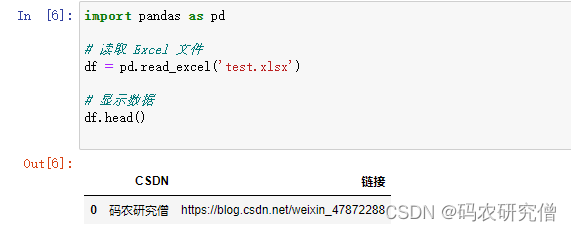
import pandas as pd
# 读取 Excel 文件
df = pd.read_excel('test.xlsx')
# 显示数据
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
截图如下:
3. xlrd库
-
数据类型:
xlrd会尝试自动推断数据类型,但在某些情况下可能需要手动处理数据类型的转换 -
只读模式:
xlrd是只读库,只能用于读取 Excel 文件。如果需要写入功能,可以使用其他库
这个库,只支持xlx,如果强行使用xlsx,会报错:(也不可直接将xlsx修改为xlx进行编译,毕竟两种excel不是改个后缀就通用了)
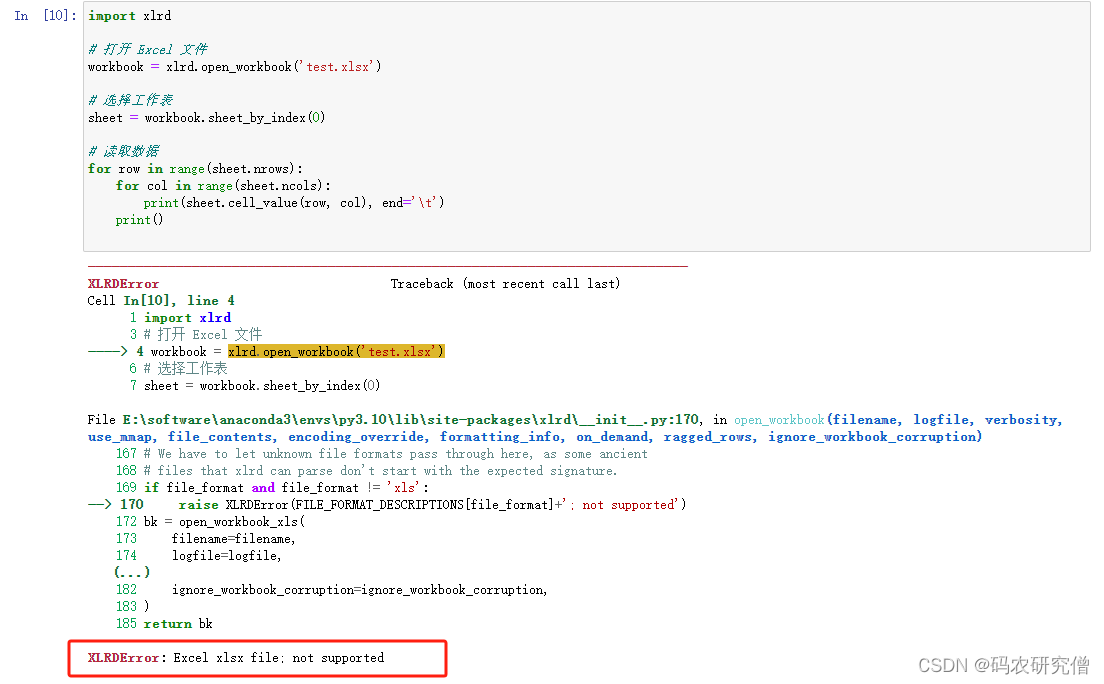
使用的前提需要安装:pip install xlrd
import xlrd
# 打开 Excel 文件
workbook = xlrd.open_workbook('test.xls')
# 选择工作表
sheet = workbook.sheet_by_index(0)
# 读取数据
for row in range(sheet.nrows):
for col in range(sheet.ncols):
print(sheet.cell_value(row, col), end='\t')
print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
截图如下:

彩蛋
一般注意事项:
-
文件路径: 确保提供正确的 Excel 文件路径或将文件放在 Jupyter Notebook 的工作目录中或者是pycharm中的工作目录中!(也可用绝对路径,但迁移项目要小心)
-
版本兼容性: 检查库的版本,确保与 Python 和其他库的版本兼容
-
异常处理: 在实际应用中,最好包含适当的异常处理,以处理可能的错误,例如文件不存在、工作表不存在等情况

