
- 1【MATLAB第37期】 #保姆级教程 XGBOOST模型参数完整且详细介绍,调参范围、思路及具体步骤介绍_xgboost matlab
- 2redis.clients.jedis.exceptions.JedisConnectionException
- 3基于FPGA的四则运算_fpga除法的小数
- 4FebHost:什么是挪威.no域名,如何注册?
- 5c语言编程题经典100例——(1~5例)_c语言比赛题目
- 6Java 解决pdfbox转图片显示中文乱码 No glyph for 165 (CID 5752) in font STSong-Light
- 7QGraphicsView实现简易地图8『缓存视口周边瓦片』
- 8Ubuntu系统使用Docker本地部署Android模拟器并实现公网访问_ubuntu docker android
- 9使用apt-mirror做一个本地ubuntu离线apt源
- 10剖析并利用Visual Studio Code在Mac上编译、调试c#程序_怎么在mac的vscode上写c#代码
ResNet详解与CIFAR10数据集实战_resnet cifar10
赞
踩
ResNet详解与CIFAR10数据集实战
1、引言
由于神经网络深度增加而导致的参数量急剧增大使得我们对其训练越来越困难,并且随着深度增加会出现网络退化现象。这时我们就需要采取一种方法去有效地解决这个问题。在2015年,何凯明大神提出了residual nets(深度残差网络,后面简称为ResNet)能够有效地解决这个问题,同时还能有效解决梯度消失和梯度爆炸问题从而更进一步提高网络的学习效果。
2、ResNet原理
深度残差神经网络不需要去拟合底层的映射,而是去拟合相对于输入的残差。残差模块如下:
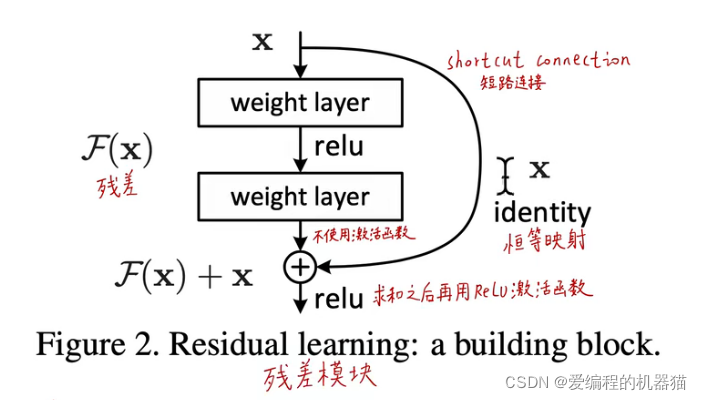
我们设
x
x
x为输入数据,设原来的底层映射为
H
(
x
)
H(x)
H(x),设相对于
x
x
x的残差为
F
(
x
)
F(x)
F(x),所以可以得到
F
(
x
)
=
H
(
x
)
−
x
F(x)=H(x)-x
F(x)=H(x)−x。经过残差模块后底层映射就是
F
(
x
)
+
x
F(x)+x
F(x)+x。从上面可以看出,在极端情况下,如果底层映射足够好,那么残差就是0,这时就不需要从残差中学习了,此时底层映射就是恒等映射。
3、ResNet解决网络退化的机理
(1)深层梯度回传顺畅
恒等映射这一条路的梯度为1,能够通过这条路很好地把深层梯度注入底层,防止梯度消失,没有像sigmoid这样中间商的层层剥夺。
(2)网络自身构建的优势
1)每次都是去拟合上一层的误差,这样会让误差更尽可能变小
2)残差类似于LSTM的遗忘门,如果某个信息有用的,则记住;如果没有用,则忘记,最后再让后面的过程去拟合。这样能高效率得到有效信息,加快模型收敛。
3)使用ReLu激活函数,不会像sigmoid这样因为多次迭代而使梯度近似0,以至于无法更加逼近更好的结果。
(3)传统的线性网络很难去拟合“恒等映射”,而ResNet可以
由于深度学习的需要,我们有时需要原封不动地保存之前的信息。ResNet的残差模块就能根据需要自动选择是否要更新那些信息。,这样就弥补了高度非线性造成的不可逆的信息损失。
4、CIFAR10数据集实战
这里我们选择构建ResNet18,具体模型结构如下:
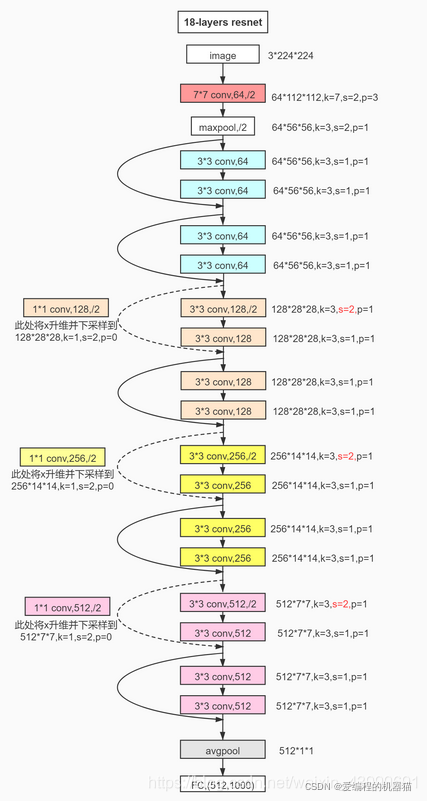
(1)导入数据
使用dataloader导入数据,并转换成tensor
# 导入训练集数据 train_data = dataloader.DataLoader( datasets.CIFAR10(root='data/', train=True, transform=transforms.Compose([ transforms.Resize(32, 32), # 重新设置图片大小 transforms.ToTensor(), # 将图片转化为tensor transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 进行归一化 ]), download=True), shuffle=True, batch_size=batch_sz ) # 导入测试集数据 train_test = dataloader.DataLoader( datasets.CIFAR10(root='data/', train=False, transform=transforms.Compose([ transforms.Resize(32, 32), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]), download=True), shuffle=True, batch_size=batch_sz )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
(2)定义网络结构
首先我们需要先定义残差的block
根据上面的残差模块图片不难写出
# 定义残差块 class ResBlk(nn.Module): def __init__(self, ch_in, ch_out, stride): super(ResBlk, self).__init__() self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1) self.bn1 = nn.BatchNorm2d(ch_out) self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1) self.bn2 = nn.BatchNorm2d(ch_out) self.extra = nn.Sequential( nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride), nn.BatchNorm2d(ch_out) ) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) out = self.extra(x) + out out = F.relu(out) return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
然后再根据上图写ResNet18网络结构,注意维度变换
# 定义ResNet18网络结构 class ResNet18(nn.Module): def __init__(self): super(ResNet18, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0), nn.BatchNorm2d(64) ) self.blk1 = ResBlk(64, 64, stride=2) self.blk2 = ResBlk(64, 128, stride=2) self.blk3 = ResBlk(128, 256, stride=2) self.blk4 = ResBlk(256, 512, stride=2) self.outlayer = nn.Linear(512*1*1, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = self.blk1(x) x = self.blk2(x) x = self.blk3(x) x = self.blk4(x) x = F.adaptive_avg_pool2d(x, [1, 1]) x = x.view(x.size(0), -1) x = self.outlayer(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
(3)定义损失函数和优化方式
损失函数使用CrossEntropyLoss(交叉熵),优化方式使用Adam。至于为什么使用交叉熵,它会使梯度变得更大,优化起来更快。如果使用sigmoid+MSE的话会比较容易出现sigmoid饱和的情况,这时会出现梯度消失情况。最后只能说根据实验交叉熵在分类问题上表现效果非常好。
# 定义损失函数和优化方式
criteon = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
- 1
- 2
- 3
(4)训练测试模型
# 训练模型 for epoch in range(1): model.train() for batch_idx, (x, label) in enumerate(train_data): x = x.to(device) label = label.to(device) logits = model(x) # 经过模型得到的数据 loss = criteon(logits, label) print('logits:', logits[0]) print('label:', label[0]) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() if batch_idx == len(train_data) - 1: print(epoch, 'loss:', loss.item()) # 进行测试 model.eval() with torch.no_grad(): total_correct = 0 total_num = 0 for x, label in train_test: x = x.to(device) label = label.to(device) logits = model(x) pred = logits.argmax(dim=1) correct = torch.eq(pred, label).float().sum().item() total_correct += correct total_num += x.size(0) acc = total_correct / total_num print(epoch, 'test acc:', acc)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
最后的分类准确率大约能达到百分之90左右。
github完整代码:ResNet源代码
小伙伴喜欢文章的话记得 点赞加关注哦,后面会更新其他深度学习的文章。
如果有什么写得有问题的地方希望大家能值出,谢谢。

