
- 1基础搜索算法篇---二分搜索_二分法查找次数怎么算
- 2Go语言操作mongodb_go mongo
- 3srp中阴影_srp shadow renderer feature
- 4平衡二叉树(AVL)【java实现+图解】_java平衡二叉树实现
- 5Rabbitmq取消预取机制配置,配置手动确认后仍然java.lang.IllegalStateException: Channel closed; cannot ack/nack的问题_rabbitmq java.lang.illegalstateexception: connecti
- 6Idea中使用Git的常用操作_git在idea中相关操作
- 7synopsys-SDC第六章——生成时钟_create generated clock
- 8记一次Spring Websocket后台服务器CPU占用率过高的问题排查过程_又服务器向应用推送cpu使用率
- 9Hadoop集群搭建教程(hadoop-3.1.3手把手教学)超详细!!!_hadoop313资料
- 10cmake———CXX_STANDARD is set to invalid value ‘17‘
百度百舸:打造业界领先的多芯混合训练AI集群
赞
踩

由于外部环境的变化,适用于大模型训练任务的GPU整体规模无法继续增长。这些存量GPU组成的集群,仍然是当前加速大模型训练的主要AI算力来源。同时,各类国产AI芯片开始大规模投入实际生产任务。在未来一段时间内,数据中心的AI算力将保持多种芯片并存的现象。
但是,当前基础大模型训练所需要的最大AI算力集群规模,已经从单一集群千卡逐步提升至万卡量级。同时,很多智算中心已经部署的GPU集群,通常是十几台至数百台服务器不等,难以满足未来行业大模型训练的需求。
所以,在已有AI算力集群的基础上,构建由GPU、昆仑芯、昇腾等不同芯片混合组成的单一集群,为大模型训练提供更大AI算力,成为了一个自然的选择。
大家都知道,成功建设一个全部由GPU芯片组成的集群,让他们作为一个整体可以高效率地跑起来,就已经足够复杂。
如果还要在GPU集群中再加上其他类型的AI芯片,他们各自讲着不同的语言,拥有完全不同的能力,让他们像同一种芯片组成的集群一样,实现多芯混合训练,加速单一大模型训练任务,那真是复杂到头了。
这里的挑战,和一个经常出现在团建中的竞技项目「多人多足」类似:大家肩并肩站成一排,人和人之间依次绑着小腿,大家齐头向前跑冲向终点。如果这个时候参赛队中有些人只会外语,有些人步子迈得很长……
1 如何建立和加速一个GPU集群
为了让大家对「如何搞定一个支持多芯混合训练的AI集群」有更清晰的理解,我们首先以GPU集群为例,简单介绍建立和加速一个AI集群的三个关键方面。
1.1 实现GPU互联互通
为了建设一个多卡集群,首先要完成GPU卡在物理层面进行连接。在单台服务器内8块GPU卡通过NVLink连接。不同服务器之间的GPU卡通过RDMA网络连接。
在完成网络的搭建后,借助NVIDIA开发的集合通信库NCCL,GPU就能通过网络实现相互通信完成数据同步,使得训练任务可以一轮一轮地往下推进,直到完成大模型的训练。
1.2 制定分布式并行策略
为了加速大模型训练任务,我们需要将这个任务拆分到集群的所有GPU中,使得这些GPU能够共同完成任务。这就是常说的分布式并行策略。分布式并行策略有很多种,比如从训练数据维度进行切分的数据并行,按照模型的不同层面进行切分的流水线并行等。
我们需要依据集群的物理拓扑和大模型的参数,找到最优的分布式并行策略,充分发挥集群效能。在任务运行过程中,集群中所有GPU步骤保持一致,同时开始计算,同时开始通信,不存在一些GPU空转等待另外一部分GPU的情况。
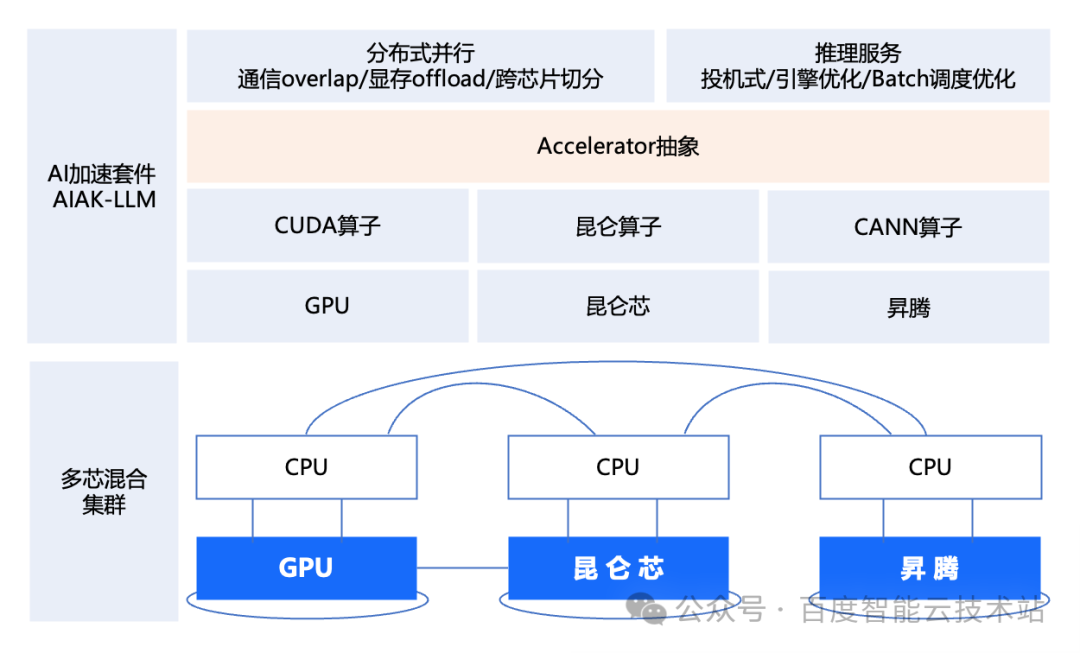
1.3 部署AI加速套件
按照分布式并行策略被拆分开的模型和数据,将会以一个个算子的形式部署在GPU进行计算。为了加速GPU对算子的计算过程,我们还需要一个AI加速套件。
这个AI加速套件需要包含数据加载、算子计算(各种CUDA库)、多卡通信(NCCL集合通信库)等各个方面的优化。比如采用数据预取策略,使得I/O的过程和GPU上的计算充分并行起来;使用NVIDIA优化后的GPU算子或者全新的算子加速GPU卡的计算效率;更新NCCL能力提升GPU卡相互通信的效率。
我们这里总结一下,为了建设一个能够高效训练大模型的集群,需要在卡间和机间建立高效的互联互通,将大模型训练任务按照合适的并行策略拆分到GPU卡中,最后通过各种优化方法,加速GPU对算子的计算效率,完成大模型训练。
2 建立不同芯片集群的差异
当前,在数据中心的多芯算力的运用方式上,主流仍然是采用一种芯片对应一个集群的思路,这需要根据每一种芯片的特点进行量身定制。
参照上文提到的三个方面,一起来看看基于昆仑芯和昇腾910B,建设和加速这些集群的差异。
在互联互通上,昆仑芯服务器内部通过XPU Link进行连接,服务器之间通过标准的RDMA网卡进行连接,卡和卡之间使用XCCL通信库进行相互通信。昇腾910B服务器内部通过HCCS进行连接,服务器之间通过华为自研的内置RDMA进行连接,卡和卡之间使用HCCL通信库进行相互通信。
在并行策略上,NVIDIA GPU和昆仑芯采用单机8卡的部署方式,昇腾910B则是机内16卡分为2个8卡通信组 。这意味着在AI框架下形成不同的集群拓扑,需要有针对性地制定分布式并行策略。
在AI加速套件上,由于GPU、昆仑芯、昇腾等芯片在计算能力,显存大小,I/O吞吐,通信库等均存在差异,故需要面向具体芯片进行特定优化。最后的结果,就是每一种芯片,有一个各自对应的算子库,以及相应的加速策略。
3 建立和加速多芯混合集群的挑战和方案
现在,我们回到今天本文讨论的重点:建设一个支持多芯混合训练的AI集群,并加速运行一个大模型训练任务。(这里有个背景知识:要完成一个大模型的训练任务,只能是在单一集群中完成,而不能拆分到不同集群中进行。)
为了实现这个目标,在前文提到的三个维度我们都将遇到挑战:
不同类型的卡的物理连接方式和集合通信库是完全不同的,这导致他们之间无法直接互联互通。
我们需要为跨芯片的互联互通设计一套新的物理网络架构,并配套相应的集合通信库方案,使得通信效果达到最优。
在集群建设完成后,由于不同种类卡的性能不一致,这就导致在单一芯片集群中,基于均匀切分计算量制定分布式并行策略的方法,将无法确保不同芯片可以按照相同节奏计算和通信,导致算力浪费。
我们需要为此找到一套最优的分布式并行策略,使得这些不同种类的芯片能够在计算和通信的节奏上保持一致,使得集群算力效能最大化。
由于不同卡的加速方法存在差异,生态能力和调优策略发展程度不一,这将导致集群中的各类算力效能无法充分发挥,即MFU未达到理想值(MFU名词解释详见文末)。
我们需要为所有芯片提供统一的加速抽象以便屏蔽这些差异性,同时又能提供最优的AI加速套件,确保各种芯片均可以达到MFU理想值,实现高效能运行。
3.1 跨芯片的互联互通,构建多芯混合集群
传统的观点认为,不同芯片是很难互联互通,无法支撑大模型训练。从上文可知,NVIDIA GPU、昆仑芯、昇腾910B的物理连接方式,以及使用的集合通信库都不一样。
百度百舸为了实现跨芯的互联互通,使用了CPU转发来实现跨昇腾910B子集群和GPU子集群的连接。借助百度自研的集合通信库BCCL,可以实现GPU、昆仑芯等标准RDMA设备的互联互通,使得通信效果达到最优。
3.2 自适应并行策略搜索,提升多芯混合训练任务的整体效能
传统的分布式并行策略,都是按照等分的方式将大模型和训练数据拆开。其中确保这种等分方式有效的前提,在于集群中的芯片是同型号。这样在算量相同的情况下,所有卡都可以同节奏地运行。
假设集群中存在两种以上的卡,按照等分的方式制定分布式并行策略,则存在高性能卡等待其他卡的过程,产生算力的浪费。所以在同一个多芯集群中,我们需要按照不同芯片子集群的算力对比,分配合适的算量,将过去均匀切分的分布式并行策略改成按芯片算力大小适配的非均匀分布式并行策略方式。
在确定了非均匀并行策略的大方针后,还需要解决的就是具体怎么分,分多少的问题,确定分布式并行策略的最优解。这个最优解包括:采用什么样组合的分布式并行策略;在不同芯片的子集群中分配多少算量,比如分配多少训练数据,多少模型层数等。
百度百舸的AI加速套件AIAK–LLM实现了针对单一任务多种芯片的自适应并行策略搜索功能,通过计算各种并行策略所需要的计算量、存储量、通信量以及不同芯片的计算和I/O效率等(这里的所有数值均源自百度基于数十年AI技术积累产生的手册:AI芯片效能矩阵图谱),从而快速计算出最优的任务切分策略,保证在各种芯片配比下的单一集群,在运行大模型多芯混合训练任务时整体效能最大化。
3.3 Accelerator抽象,屏蔽硬件差异充分发挥不同芯片的算力效能
传统的加速方案,如上文所说,均是面向特定芯片进行优化。如果同一个大模型任务,运行在多芯混合集群上,我们需要为不同芯片配置相应的加速策略。
国产化AI芯片由于生态还在不断完善过程中,调优策略仍然需要继续优化,所以导致算力没有充分发挥出来。
百度百舸基于在GPU上的长期投入与沉淀(比如,百度百舸平台的A800 MFU值达到80。该值等于A800 MFU的理想值,即百度百舸完全发挥了A800的能力),在AI加速套件AIAK-LLM中构建了「Accelerator抽象层」,使得国产化AI芯片充分发挥各自算力。
其中,「Accelerator抽象层」面向应用,屏蔽底层芯片在硬件层面的差异,将芯片算子与上层策略解耦开来,芯片厂商仅需要进行各自芯片的算子调优。百度百舸在GPU上沉淀的上层各项策略(比如通信overlap、显存offload、张量并行、数据并行等)都会平滑地迁移到各种芯片上,确保了各种国产芯片在百度百舸上能达到一个非常高的运行效率。
3.4 多芯混合训练的技术指标
在解决以上三个方面的挑战后,我们就可以开始在这个集群上进行单一大模型下的多芯混合训练任务了。目前,百度百舸的百卡和千卡规模混合训练效能最大分别达到了97%和95%。计算公式如下:

其中,芯片A集群吞吐量,为基于芯片A构建的单一集群,在训练大模型时候的能力。MFU的取值,使用的是经过「AI加速套件AIAK-LLM」加速后在该集群获得的MFU数值。
「Accelerator抽象层」使得上层的各类策略都能平滑地迁移到不同卡层面,能够有效提升各类芯片的MFU值。自适应并行策略和百度集合通信库BCCL等能够有效提升训练任务的模型吞吐量。
抛开上文提到的具体参数,关于混合训练效能指标的直观理解:假设分别有100单位算力规模的NVIDIA A800集群,80单位算力规模的由芯片B组成的AI集群,将这两种芯片融合成为一个百卡规模的多芯混合集群后,新集群的训练效能相当于180*0.97=174.6单位算力。
随着百度百舸能力的不断升级,这个多芯混合训练效能的数值将继续提升。
4 新旧算力统一融合,满足未来业务增长
百度百舸的多芯混合训练方案,屏蔽了底层复杂的异构环境,将各类芯片融合成为了一个大集群,可以实现存量不同算力的统一,整合发挥这些算力的最大效能,支持更大模型训练任务。同时,支持新增资源的快速融入,满足未来业务增长的需要。
该方案不仅通过百度智能云的公有云提供服务,同时还可以通过ABC Stack专有云进行交付。如果您的智算中心已经或者计划多种算力部署的打算,欢迎使用百度百舸的这项全新能力,打破单一算力的局限,实现算力的统一融合。
5 名词解释
MFU,Model FLOPs Utilization,MFU=(实际观测到的模型吞吐量)/(假设峰值FLOPs下的理论最大吞吐量)
一个较高的MFU值意味着GPU的浮点运算能力被高效利用,模型训练的速度更快;而较低的MFU值则表明存在资源浪费,导致GPU的实际计算能力未得到充分施展。






点击阅读原文,立即合作咨询

