
- 1百度智能云千帆AppBuilder新手指南_使用百度智能云做一个rag模型包括百度boot的实现boot的调用以及boot回答的结
- 2平衡二叉树(AVL)Java实现_java avlrotateright
- 3开发人员必备!一款轻量级 Docker 日志查看神器,快速好用【带私活源码】_针对于docker 启动的java服务的日志收集系统
- 4基于Python+Django,这款在线图书管理系统真的很清爽!_django图书管理系统
- 5推荐系统 Task02:协同过滤(知识脑图整理)_协同过滤系统程序框图
- 6人工智能建立本体库_基于本体技术的知识库构建设想
- 7linux防火墙 四表五链 语法规则_prerouting accept
- 8【Matlab算法】灰狼优化算法问题(Grey Wolf Optimization)(附MATLAB完整代码)_灰狼算法matlab
- 9揭秘6种最有效的社会工程学攻击手段及防御之策
- 10pytorch NLP自然语言处理入门一:文本表示
【数据结构】顺序表与链表的差异
赞
踩
顺序表和链表都是线性表,它们有着相似的部分,但是同时也有着很大的差异。
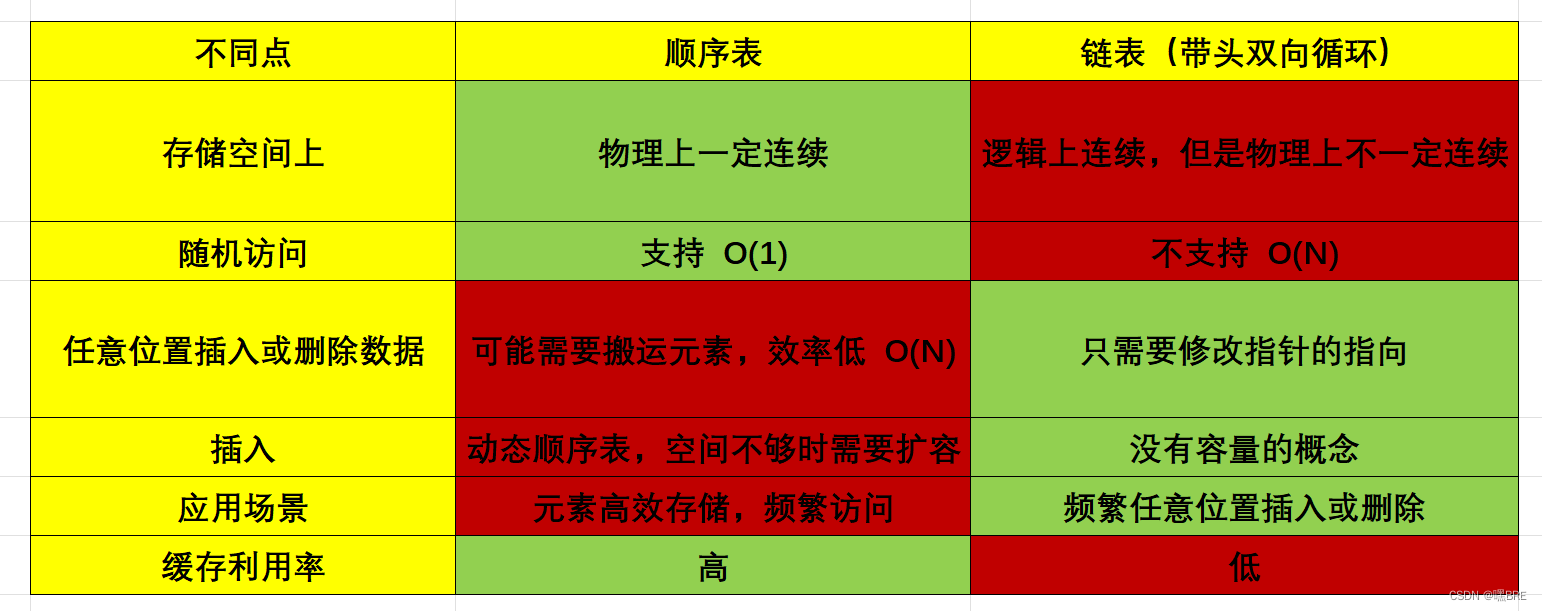
存储空间上的差异:

对于插入上的不同点,顺序表在空间不够时需要扩容,而如果在使用realloc函数去扩容,会有原地扩容和异地扩容两种情况,若申请的空间没有被使用,则会用原地扩容,消耗不会大。但是若申请被使用的话,则会用异地扩容,则会在堆区上申请一块空间,并把原来的数据拷贝过来,就会造成消耗会比较大的问题。而带头双向循环链表则不需要考虑到这些问题,只需要按需申请释放就可以了。同时,顺序表的扩容还可能存在空间浪费的问题。
关于原地扩容和异地扩容的代码:
- int main()
- {
- int* p1 = (int*)malloc(8);
- printf("%p\n", p1);
-
- int p2 = (int*)realloc(p1, 800);
- printf("%p\n", p2);
- return 0;
- }
原地扩容:
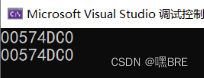
异地扩容

关于缓存利用率两种线性表也有很大的不同。
在此之前,我们首先要知道缓存(高速缓冲存储器)是什么?
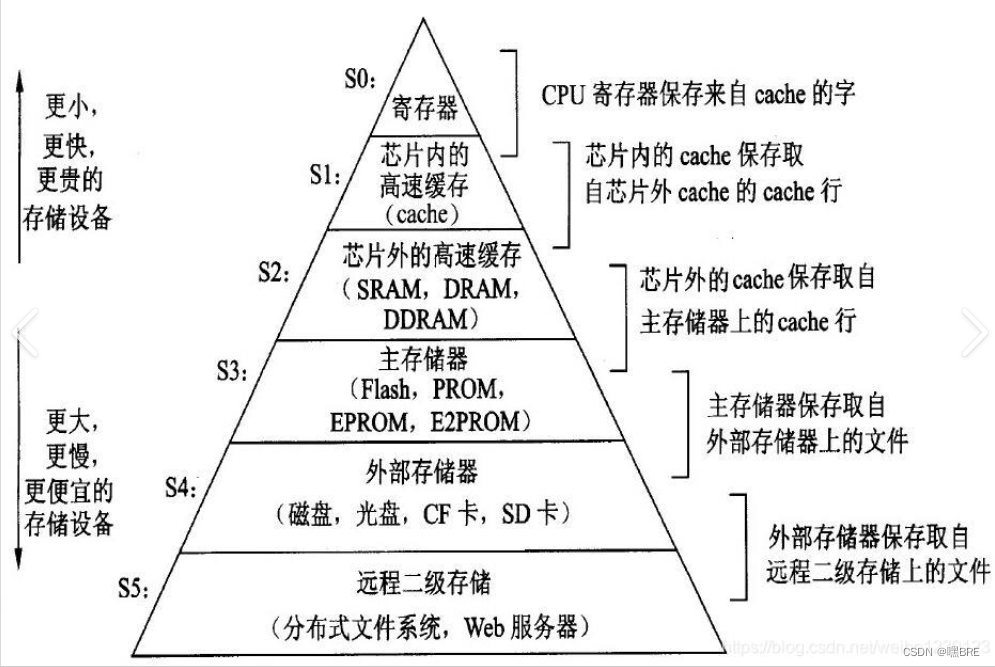
在多体并行存储系统中,由于I/O设备向主存请求的级别高于CPU访存,这就出现了CPU 等待I/0设备访存的现象,致使CPU空等一段时间,甚至可能等待几个主存周期,从而降低了CPU的工作效率。为了避免CPU与I/O设备争抢访存,可在CPU与主存之间加一级缓存(参见图4.3),这样,主存可将CPU要取的信息提前送至缓存,一旦主存在与I/O设备交换时,CPU 可直接从缓存中读取所需信息,不必空等而影响效率。
从另一角度来看,主存速度的提高始终跟不上CPU的发展。据统计,CPU的速度平均每年改进60%,而组成主存的动态RAM速度平均每年只改进7%,结果是CPU和动态RAM之间的速度间隙平均每年增大50%。例如,100MHz的Pentium处理器平均每10ns就执行一条指令,而动态RAM的典型访问时间为60~120ns。这也希望由高速缓存Cache 来解决主存与CPU速度的不匹配问题。
缓存的命中:
在说明这两个问题之前。我们需要要解一个术语 Cache Line。缓存基本上来说就是把后面的数据加载到离自己近的地方,对于CPU来说,它是不会一个字节一个字节的加载的,因为这非常没有效率,一般来说都是要一块一块的加载的,对于这样的一块一块的数据单位,术语叫“Cache Line”,
比如:Cache Line是最小单位(64Bytes),所以先把Cache分布多个Cache Line,比如:L1有32KB,那么,32KB/64B = 512 个 Cache Line。
在计算机读取数据的时候,计算机会根据地址去访问,如果数据在缓存上,则称为命中成功,直接就可以访问数据了。如果数据在主存上,则称为命中失败,就需要将主存上的数据移到缓存上,这时就需要使用Cache来进行运输。
我们再与线性表联系起来。
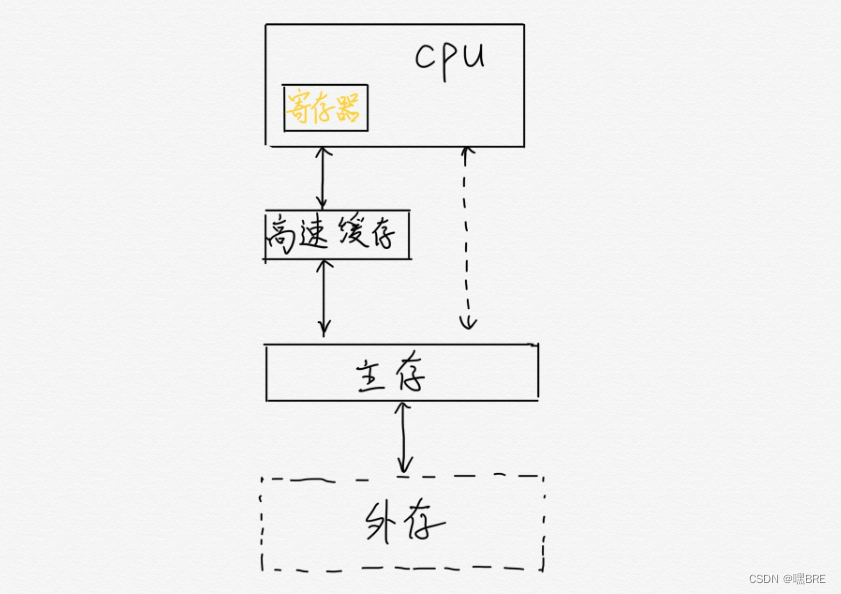
顺序表的物理结构和逻辑结构的方面上都是连续的,在数据在主存上的情况下,数据被移到cache上面。同时,因为对于CPU来说,它一般来说都是要一块一块的加载的,也就代表着加载的时候会将顺序表连带着后面的数据一并加载到cache上面,也就节省了时间,节约了空间,提高了程序的运行效率。
链表(双向带头循环链表)的逻辑结构是不连续的,但是它的物理结构却是不连续的。所以,在CPU一块一块加载数据的时候,在加载第一个数据的时候并不会连带着后面的数据去加载(参考下图),也就降低了程序运行的效率。同时,因为有大量的无用的数据加载到缓存,会造成数据的污染,影响程序的性能。
想对缓存的命中有更深的了解的话,可以参考陈皓大佬的文章《程序员相关的CPU缓存知识 》进一步了解。

