
- 1数据结构:实验六(单循环链表实现链式队列)_链队用单循环链表表示
- 2Linux基础—应用程序管理(四)_execstartpre
- 3Mac M2 安卓Android模拟器BP抓包配置_模拟器搭建bp
- 4边缘计算:客户端 + 人工智能_客户端和边缘端的区别
- 5干货 | 探索大模型:视觉规化、量化、Text-to-SQL的挑战
- 6Windows(10专业版&11)使用docker安装深度学习环境 Pytorch-gpu_win11docker desktop部署深度学习
- 7Apache Doris 2.x 版本【保姆级】安装+使用教程_system has no available disk capacity or no availa
- 8布控球HDS-1300e布控球接入国标协议视频平台EasyGBS步骤介绍_华平布控球参数
- 9如何检查手机和电脑是否在一个网络中?_电脑手机怎么看是否一个网段
- 10数据结构之队(循环队列)的基本操作和实现_循环队列的基本操作实现
BM25算法浅析_bm25算法推荐
赞
踩
BM25算法浅析
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
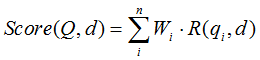
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
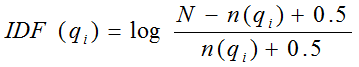
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
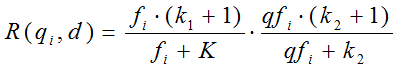
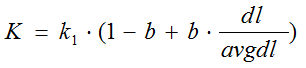
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
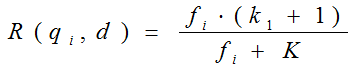
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
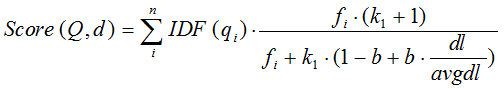
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。

