
- 1pythonjieba情感分析步骤_基于jieba和doc2vec的中文情感语料分类
- 2《前端面试题》- TypeScript - TypeScript的优/缺点_当面面试官问为何使用typescript
- 3PCB安规设计 | 一、电气间隙和爬电距离_pcb电气间隙和爬电距离
- 4计算机视觉论文-2021-06-24_fairness for image generation with uncertain sensi
- 5托管类调用非托管类(C#,C++,CLI,传递指针数组)_托管类成员不能是非托管类类型
- 6【ARMv7-A】——处理器模式_arm svc模式
- 7android 本地存储
- 8英特尔开发套件在JAVA环境实现ADAS道路识别演示
- 9CDH集群hue继承hdfs遇到问题_hdfs权限继承无效
- 10【汽车之家注册/登录安全分析报告】
【深度学习:视觉基础模型】视觉基础模型 (VFM) 解释_视觉基础大模型
赞
踩

据雅虎财经称,计算机视觉(CV)市场正在飙升,预计年增长率为 19.5%。到 2023 年,预计其价值将达到 1004 亿美元,而 2022 年为 169 亿美元。这一增长很大程度上归功于视觉基础模型 (VFM) 的开发,该模型旨在理解和处理视觉数据的复杂性。
VFM 在各种 CV 任务中表现出色,包括图像生成、对象检测、语义分割、文本到图像生成、医学成像等。它们的准确性、速度和效率使其在企业规模上非常有用。
本指南概述了 VFM,并讨论了几种可用的重要模型。我们将列出它们的优点和应用,并重点介绍 VFM 的突出微调技术。
了解视觉基础模型
基础模型是通用的大规模人工智能 (AI) 模型,组织用它来构建下游应用程序,特别是在生成式 AI 领域。例如,在自然语言处理 (NLP) 领域,BERT、GPT-3、GPT-4 和 MPT-30B 等大型语言模型 (LLM) 是基础模型,使企业能够构建定制的聊天或语言系统特定任务并能够理解人类语言以增强客户参与度。
视觉基础模型是执行图像生成任务的基础模型。 VFM 通常包含大型语言模型的组件,以便使用基于文本的输入提示生成图像。它们需要适当的即时工程来实现高质量的图像生成结果。专有和开源 VFM 的一些著名示例包括 Stable Diffusion、Florence、Pix-2-Pix、DALL-E 等。这些模型在巨大的数据集上进行训练,使它们能够理解视觉中复杂的特征、模式和表示。数据。他们使用专注于处理视觉信息的各种架构和技术,使它们能够适应许多用例。
从 CNN 到 Transformer 的演变
传统上,计算机视觉模型使用卷积神经网络(CNN)来提取相关特征。 CNN 一次专注于图像的一部分,使它们能够在推理时有效地区分对象、边缘和纹理。
2017 年,一篇题为“Attention is All You Need”的研究论文通过引入一种新的机器学习架构来构建有效的语言模型,改变了 NLP 的格局。该架构采用文本序列并生成文本序列作为输入输出格式。其关键组件是注意力机制,它使模型能够专注于文本序列的基本部分。总体而言,Transformer 可以更好地理解较长的文本,并提供更高的速度和准确性。Transformer 架构催生了我们今天所知的基础 LLM。
尽管注意力机制最初是针对语言格式的,但研究人员很快就看到了它在计算机视觉应用中的潜力。 2020 年,一篇题为“An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”的研究论文展示了 Transformers 算法如何将图像转换为矢量化嵌入,并使用自注意力机制让模型理解图像片段之间的关系。生成的模型称为视觉变换器 (ViT)。
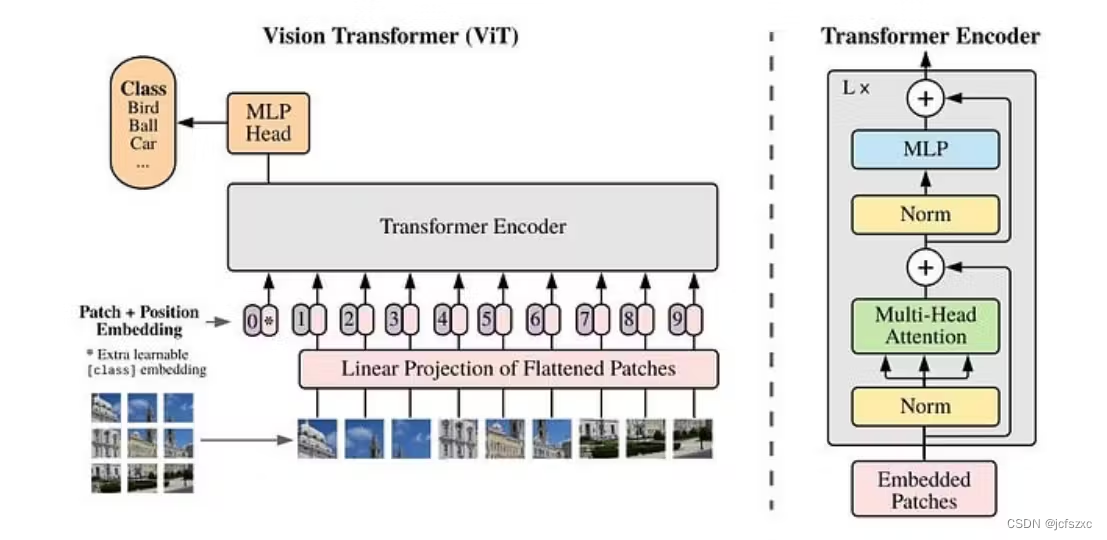
如今,ViT 被用来为许多 VFM 提供动力。此外,GPU 的日益普及使得处理视觉数据和执行大规模生成式 AI 工作负载变得更加容易。因此,不同VFM的开发和部署变得更加可行。
自我监督和适应能力
许多视觉基础模型使用自我监督技术来从未标记的数据中学习。与所有数据点都必须有标签的监督学习不同,自监督技术可以通过未标记的数据点进行模型训练。这使得企业能够快速调整它们以适应特定的用例,而不会产生高昂的数据注释成本。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Cpp五条/article/detail/677862
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

