
- 13、Spring之Bean生命周期~合并BeanDefinition
- 2【项目实战】十分钟学习完 Spring Boot 拦截器_springboot拦截器
- 3使用百度云智能SDK和树莓派搭建简易的人脸识别系统 Python语言版_搭建家庭人脸识别系统
- 4潘多拉开发板——6轴传感器ICM-20608学习笔记_icm20608
- 5windows下php环境搭建_windows搭建php环境
- 6关于 AssertionError: Torch not compiled with CUDA enabled 问题_comfyui assertionerror: torch not compiled with cu
- 7chatGPT陪你读源码_chatgpt阅读代码
- 8Linux SPI 驱动_linux spi驱动
- 9UE4/UE5像素流送云推流|程序不稳定、弱网画面糊怎么办?
- 10算法-贝尔曼-福特算法_bellman鈥榮 algorithm
目标检测实战:PP-YOLOv2训练自己的数据集_ppyolov2
赞
踩
前言
记录使用PP-YOLOv2训练自己的数据集的过程。详细安装文档可参考官方文档。官方文档写的十分详细,包括数据准备、环境搭建、训练过程等,这里笔者根据个人操作进行总结。
一、环境搭建
搭建PP-YOLOv2的环境,需要部署代码PaddleDetection,PaddleDetection为基于飞桨PaddlePaddle的端到端目标检测套件,内置30+模型算法及300+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向。所以首先搭建PaddlePaddle深度学习框架。
1. Requirements
Python ≥ 3.7(本实验在Ubuntu16.04下进行,使用Python3.7)
PaddlePaddle ≥ 2.2 (本实验安装PaddlePaddle 2.3)
cuda ≥ 10.1(本实验安装10.1)
cudnn ≥ 7.6(本实验安装7.6.5)
PaddleDetection2.5
2. anaconda创建环境
首先创建python3.7的python环境。
conda create -n paddle2 python=3.7
source activate paddle2
- 1
- 2
安装PaddlePaddle
最新版本的PaddleDetection2.5要求PaddlePaddle>=2.2,根据PaddlePaddle快速安装文档进行安装PaddlePaddle。
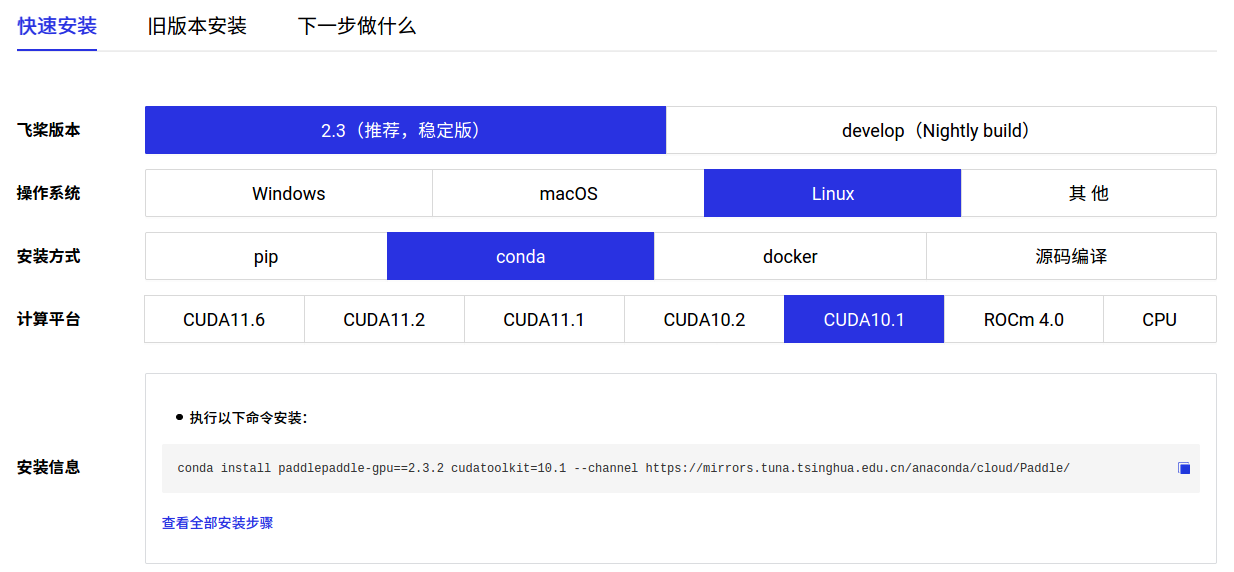
验证PaddlePaddle
安装完成后在终端输入 python 进入python解释器,输入import paddle ,再输入 paddle.utils.run_check()
>>> import paddle
>>> paddle.utils.run_check()
- 1
- 2

如果出现PaddlePaddle is installed successfully!,说明已成功安装。
安装PaddleDetection
PaddleDetection官方项目链接:
https://github.com/PaddlePaddle/PaddleDetection
# 克隆PaddleDetection仓库
git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 编译安装paddledet
cd PaddleDetection
python setup.py install
# 安装其他依赖
pip install -r requirements.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上面的安装方法是官方项目里给出的,笔者在下载项目之后,没有安装paddledet,直接安装了requirements.txt中的其他依赖项,运行程序时会报警告,但是不影响使用。如果为了严谨,最好按照官方安装方法。
二、训练过程
1.数据集准备
笔者将自己的数据集转成coco数据格式,labelImg制作的数据集包含JPEGImage图片目录和Annotationxml目录。
用脚本split_dataset.py用于划分训练集、测试集、验证集。
# -*- coding: UTF-8 -*- import os import random base_dir = '/dataset/mydata/' def split_dataset(): xmlfilepath = os.path.join(base_dir, 'annotations') saveBasePath = os.path.join(base_dir, 'ImageSets') if not os.path.exists(saveBasePath): os.makedirs(saveBasePath) test_val_percent = 0.2 train_percent = 0.8 val_percent = 0.8 temp_xml = os.listdir(xmlfilepath) total_xml = [] for xml in temp_xml: if xml.endswith(".xml"): total_xml.append(xml) num = len(total_xml) list = range(num) tv = int(num * test_val_percent) tr = int(num * train_percent) tval = int(tv * val_percent) testval = random.sample(list, tv) train = random.sample(list, tr) val = random.sample(testval, tval) print("train and val size", tv) print("traub suze", tr) ftrainval = open(os.path.join(saveBasePath, 'testval.txt'), 'w') ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w') ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w') fval = open(os.path.join(saveBasePath, 'val.txt'), 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in testval: ftrainval.write(name) if i in val: fval.write(name) else: ftest.write(name) else: ftrain.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close() if __name__ == '__main__': split_dataset()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
用PaddleDetection项目自带的tools/x2coco.py脚本生成coco格式的数据集,生成相对应的json文件。新建label_list.txt文件,写入类别的标签。
下面的例子是生成train.json的脚本例子。
python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir dataset/mydata/annotations/ \
--voc_anno_list dataset/mydata/ImageSets/train.txt \
--voc_label_list dataset/mydata/label_list.txt \
--voc_out_name dataset/mydata/Annotation/voc_train.json
- 1
- 2
- 3
- 4
- 5
- 6
voc_anno_dir :数据集注释文件的路径。
voc_anno_list:数据集中注释文件的name列表。
voc_label_list : 标签列表的路径。 每一行的内容都是一个类别。
voc_out_name : 输出json文件的路径。
用户数据集转成COCO数据后目录结构如下(注意数据集中路径名、文件名尽量不要使用中文,避免中文编码问题导致出错):
dataset/xxx/
├── annotations
│ ├── train.json # coco数据的标注文件
│ ├── val.json # coco数据的标注文件
│ ├── test.json # coco数据的标注文件
├── images
│ ├── xxx1.jpg
│ ├── xxx2.jpg
│ ├── xxx3.jpg
│ | ...
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.修改配置文件
进入PaddleDetection文件夹,打开'/configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml',可以看到需要修改的配置文件有5个:根据地址逐一修改配置文件。
_BASE_: [
'../datasets/coco_detection.yml',
'../runtime.yml',
'./_base_/ppyolov2_r50vd_dcn.yml',
'./_base_/optimizer_365e.yml',
'./_base_/ppyolov2_reader.yml',
]
snapshot_epoch: 4
weights: output/ppyolov2_r50vd_dcn_365e_coco/model_final
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
_BASE_ : 训练需要修改的配置文件。
snapshot_epoch :训练的batch_size,根据实际情况修改。
weights:模型保存地址。
文件1:数据配置文件../datasets/coco_detection.yml,主要说明了训练数据和验证数据的路径。
metric: COCO num_classes: 1 # 数据集的类别数,# 不包含背景类 TrainDataset: !COCODataSet # 图像数据路径,相对 dataset_dir 路径,os.path.join(dataset_dir, image_dir) image_dir: JPEGImages anno_path: Annotation/voc_train.json dataset_dir: dataset/mydata data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd'] EvalDataset: !COCODataSet image_dir: JPEGImages anno_path: Annotation/voc_val.json dataset_dir: dataset/mydata TestDataset: !ImageFolder anno_path: Annotation/voc_test.json # also support txt (like VOC's label_list.txt) dataset_dir: dataset/mydata # if set, anno_path will be 'dataset_dir/anno_path'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
num_classes : 数据集的类别数。
image_dir :图像数据路径,相对 dataset_dir 路径,os.path.join(dataset_dir, image_dir)。
anno_path: 标注文件路径,相对 dataset_dir 路径,os.path.join(dataset_dir, anno_path)。
dataset_dir:数据文件夹
文件2:优化器配置文件./_base_/optimizer_365e.yml,主要说明了学习率和优化器的配置。
epoch: 300 LearningRate: base_lr: 0.0001 schedulers: - !PiecewiseDecay gamma: 0.1 milestones: - 127 - !LinearWarmup start_factor: 0. steps: 1000 OptimizerBuilder: clip_grad_by_norm: 35. optimizer: momentum: 0.9 type: Momentum regularizer: factor: 0.0005 type: L2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
epoch : 总训练轮数,根据自己需要修改。
base_lr :学习率,默认为8卡学习率,根据自己GPU数量修改,本次实验设置为0.0001。
其他设置项可以参考官方文档根据需要自定义优化器策略。
文件3:数据读取配置文件./_base_/ppyolov2_reader.yml,主要说明数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等。
worker_num: 2 # 每张GPU reader进程个数 TrainReader: inputs_def: num_max_boxes: 100 sample_transforms: - Decode: {} - Mixup: {alpha: 1.5, beta: 1.5} - RandomDistort: {} - RandomExpand: {fill_value: [123.675, 116.28, 103.53]} - RandomCrop: {} - RandomFlip: {} batch_transforms: - BatchRandomResize: {target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768], random_size: True, random_interp: True, keep_ratio: False} - NormalizeBox: {} - PadBox: {num_max_boxes: 100} - BboxXYXY2XYWH: {} - NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True} - Permute: {} - Gt2YoloTarget: {anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]], anchors:[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], downsample_ratios: [32, 16, 8]} # anchors:[[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]] # anchors: [[7, 8], [9, 11], [10, 14],[12, 12], [9, 16], [12, 17],[14, 15], [18, 15], [17, 21]] batch_size: 4 # 训练时batch_size shuffle: true # 读取数据是否乱序 drop_last: true # 是否丢弃最后不能完整组成batch的数据 mixup_epoch: 25000 # mixup_epoch,大于最大epoch,表示训练过程一直使用mixup数据增广 use_shared_memory: true # 是否通过共享内存进行数据读取加速,需要保证共享内存大小(如/dev/shm)满足大于1G EvalReader: sample_transforms: - Decode: {} - Resize: {target_size: [640, 640], keep_ratio: False, interp: 2} - NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True} - Permute: {} batch_size: 4 # 评估时batch_size TestReader: inputs_def: image_shape: [3, 640, 640] sample_transforms: - Decode: {} - Resize: {target_size: [640, 640], keep_ratio: False, interp: 2} - NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True} - Permute: {} batch_size: 1 # 测试时batch_size
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
这个配置文件没有太多的修改,根据实际修改batch_size。
文件4:模型配置文件./_base_/ppyolov2_r50vd_dcn.yml,主要说明模型、和主干网络的情况。
architecture: YOLOv3 pretrain_weights: ./weight/model_final.pdparams # pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet50_vd_ssld_pretrained.pdparams norm_type: sync_bn use_ema: true ema_decay: 0.9998 YOLOv3: backbone: ResNet neck: PPYOLOPAN yolo_head: YOLOv3Head post_process: BBoxPostProcess ResNet: depth: 50 variant: d return_idx: [1, 2, 3] dcn_v2_stages: [3] freeze_at: -1 freeze_norm: false norm_decay: 0. PPYOLOPAN: drop_block: true block_size: 3 keep_prob: 0.9 spp: true YOLOv3Head: anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]] # anchors: [[7, 8], [9, 11], [10, 14], # [12, 12], [9, 16], [12, 17], # [14, 15], [18, 15], [17, 21]] anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]] loss: YOLOv3Loss iou_aware: true iou_aware_factor: 0.5 YOLOv3Loss: ignore_thresh: 0.7 downsample: [32, 16, 8] label_smooth: false scale_x_y: 1.05 iou_loss: IouLoss iou_aware_loss: IouAwareLoss IouLoss: loss_weight: 2.5 loss_square: true IouAwareLoss: loss_weight: 1.0 BBoxPostProcess: decode: name: YOLOBox conf_thresh: 0.01 downsample_ratio: 32 clip_bbox: true scale_x_y: 1.05 nms: name: MatrixNMS keep_top_k: 100 score_threshold: 0.01 post_threshold: 0.01 nms_top_k: -1 background_label: -1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
pretrain_weights :预训练模型地址,可以使用默认的预训练模型,训练时会自动下载。
上述配置文件的预训练模型地址,不是源码中的默认地址,而是运行下面代码获得,在源码路径下新建代码文件changeppyolov2.py,内容如下:
import numpy as np import pickle num_class = 8 # 类别数 with open('ppyolov2_r50vd_dcn_365e_coco.pdparams','rb') as f: # 预训练模型 obj = f.read() weights = pickle.loads(obj, encoding = 'latin1') weights['yolo_head.yolo_output.0.weight'] = np.zeros([num_class*3+18,1024,1,1],dtype = 'float32') weights['yolo_head.yolo_output.0.bias'] = np.zeros([num_class*3+18],dtype = 'float32') weights['yolo_head.yolo_output.1.weight'] = np.zeros([num_class*3+18,512,1,1],dtype = 'float32') weights['yolo_head.yolo_output.1.bias'] = np.zeros([num_class*3+18],dtype = 'float32') weights['yolo_head.yolo_output.2.weight'] = np.zeros([num_class*3+18,256,1,1],dtype = 'float32') weights['yolo_head.yolo_output.2.bias'] = np.zeros([num_class*3+18],dtype = 'float32') f = open('model_final.pdparams','wb') pickle.dump(weights,f) f.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行上述代码则在相同路径下得到model_final.pdparams,并将其路径填入上述的配置文件。
两种预训练模型笔者都使用过,最后的结果相差不是很大,有时间的同学可以都试试,哪个效果好留哪个。
文件5:../runtime.yml 主要说明了公共的运行参数,比如说是否使用GPU、每多少个epoch存储checkpoint等。
# 是否使用gpu
use_gpu: true
# 日志打印间隔
log_iter: 20
# save_dir
save_dir: output
# 模型保存间隔时间
snapshot_epoch: 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.生成自适应的anchor(可选)
python tools/anchor_cluster.py -c configs/ppyolo/ppyolov2_r50vd_dcn_voc.yml -n 9 -s 640 -m v2 -i 1000
- 1
- 2
在训练之前使用tools/anchor_cluster.py得到适用于你的数据集的anchor,修改config\ppyolo\_base_\ppyolov2_r50vd_dcn.yml和configs\ppyolo\_base_\ppyolov2_reader.yml中anchor设置。
笔者在实验时有试过使用自适应的anchor,但是效果没有使用默认设置好,也可能是我的数据集不适用这个配置。有需要的同学可以修改anchor训练看看效果。
4.训练
由于笔者是单卡,所以使用单卡训练的执行指令,如果需要多卡训练,可以参考官方文档多卡的执行命令。
export CUDA_VISIBLE_DEVICES=0
python tools/train.py -c configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml --use_vdl=true \
--vdl_log_dir=vdl_dir/scalar \
--eval
- 1
- 2
- 3
- 4
--use_vdl:是否将数据记录到VisualDL。
--eval:如需要边训练边评估,添加--eval。
最后在output/ppyolov2_r50vd_dcn_voc路径下生成模型,包括best_model和model_final。
5.评估
CUDA_VISIBLE_DEVICES=0 python tools/eval.py -c configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml \
-o weights=output/ppyolov2_r50vd_dcn_365e_coco/best_model.pdparams \
--output_eval=val \
--classwise
- 1
- 2
- 3
- 4
6.推理
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml \
-o weights=output/ppyolov2_r50vd_dcn_365e_coco/best_model.pdparams \
--draw_threshold=0.25 --infer_dir=test --output_dir=output/results/ \
--save_results=Ture
- 1
- 2
- 3
- 4
-c: 参数表示指定使用的配置文件。
-o: 设置配置文件里的参数内容,设置参数weights 模型位置。
--infer_img: 参数指定预测图像路径。
--infer_dir: 参数指定预测图像文件夹路径。
--output_dir: 预测结束后会在指定文件夹中生成一张画有预测结果的同名图像,如不指定,默认为output。
--draw_threshold: 可视化分数阈值,设置为0.25。
7.日志
# 输入visualDL --logdir 日志文件路径 --port 指定端口号 --host 指定IP地址(可选)
visualDL --logdir vdl_dir/scalar --port 8080 --host 127.0.0.10
- 1
- 2
总结
以上就是笔者要讲的内容,本文介绍了如何部署PaddleDetection,使用PPYOLOV2训练自己的数据集。PaddleDetection包含了不止一种目标检测的算法,里面也包括ppyoloe等其他yolo系列,训练配置、流程相差不大。
本文参考了CSDN博主「摇曳的树」的原创文章:https://blog.csdn.net/qq_44703886/article/details/118667944
本文参考了CSDN博主「GeekPlusA」的原创文章:https://blog.csdn.net/qq122716072/article/details/127731864

