
- 1SQL Server 常用函数_sql server 常见函数
- 2PyTorch、TensorFlow 和 NumPy三者之间的区别与联系是什么?_tensorflow和pytorch numpy
- 3基于51单片机的儿童安全座椅设计
- 4vue实现Element-ui省市区三级联动+市辖区修改_element-china-area-data json
- 5如何用人工智能高效选研究题目?
- 6Mybatis3.3.x技术内幕(十五):Mybatis之foreach批量insert,返回主键id列表(修复Mybatis返回null的bug)...
- 7(PYTHON)selenium+post请求批量获取小红书图片并备注_selenium 小红书
- 8html5电路模拟器,eda仿真软件
- 9助力工业产品质检,基于YOLOv5全系列参数模型【n/s/m/l/x】开发构建智能PCB电路板质检分析系统_yolo工业质检
- 10前后端分离CRUD_前后端分离列表遍历
OpenAI安全系统负责人:从头构建视频生成扩散模型
赞
踩

作者 | Lilian Weng
OneFlow编译
翻译|杨婷、宛子琳、张雪聃
题图由SiliconFlow MaaS平台生成
过去几年,扩散模型(Diffusion models)在图像合成领域取得了显著成效。目前,研究界已开始尝试更具挑战性的任务——将该技术用于视频生成。视频生成任务是图像生成的扩展,因为视频本质上是一系列连续的图像帧。相较于单一的图像生成,视频生成的难度更大,原因如下:
它要求在时间轴上各帧之间保持时间一致性,这自然意味着需要将更多的世界知识嵌入到模型中。
相较于文本或图像,收集大量高质量、高维度的视频数据难度更大,更不用说要获取文本与视频的配对数据了。
阅读要求:在继续阅读本文之前,请确保你已经阅读了之前发布的关于图像生成的“什么是扩散模型?(https://lilianweng.github.io/posts/2021-07-11-diffusion-models/)”一文。(本文作者Lilian Weng是OpenAI的AI安全与对齐负责人。本文由OneFlow编译发布,转载请联系授权。原文:https://lilianweng.github.io/posts/2024-04-12-diffusion-video/)
1
从零开始的视频生成建模
首先,我们来回顾一下从头开始设计和训练扩散视频模型的方法,这里的“从头开始”指的是我们不依赖预训练的图像生成器。
参数化与采样基础
在前一篇文章的基础上,我们对变量的定义稍作调整,但数学原理依旧不变。假设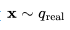 是从真实数据分布中采样的数据点。现在,我们逐步向其引入少量的高斯噪声,形成一系列x的噪声变量
是从真实数据分布中采样的数据点。现在,我们逐步向其引入少量的高斯噪声,形成一系列x的噪声变量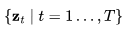 ,随着t 的增长,噪声量逐渐增大,直至最终形成
,随着t 的增长,噪声量逐渐增大,直至最终形成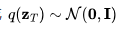 。这一逐步添加噪声的前向过程遵循高斯过程。此外,我们用
。这一逐步添加噪声的前向过程遵循高斯过程。此外,我们用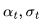 来表示高斯过程的一个可微分的噪声调度(noise schedule):
来表示高斯过程的一个可微分的噪声调度(noise schedule):
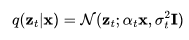
将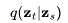 表示为
表示为 ,需要以下操作:
,需要以下操作:
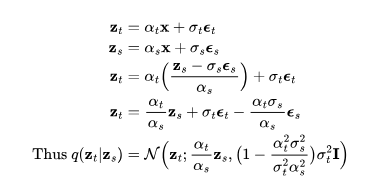
设对数信噪比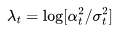 ,我们可以将DDIM(宋等人,2020年)更新表示为:
,我们可以将DDIM(宋等人,2020年)更新表示为:
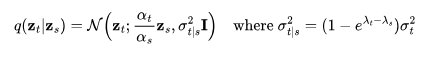
由Salimans和Ho(2022年)提出的v预测 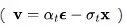 参数化,特别适用于在视频生成中避免色彩偏移,相比
参数化,特别适用于在视频生成中避免色彩偏移,相比 参数化,其效果更佳。
参数化,其效果更佳。
v参数化采用了角坐标系中的一个巧妙技巧进行推导。首先,我们定义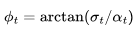 ,然后得到
,然后得到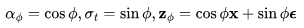 ,
,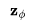 的速率可以表示为:
的速率可以表示为:
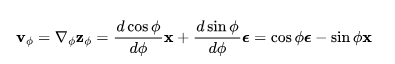
然后可以推导出:
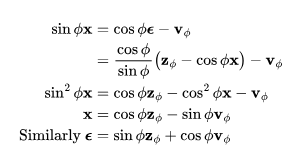
相应地,DDIM更新规则为:
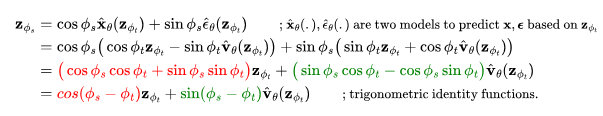
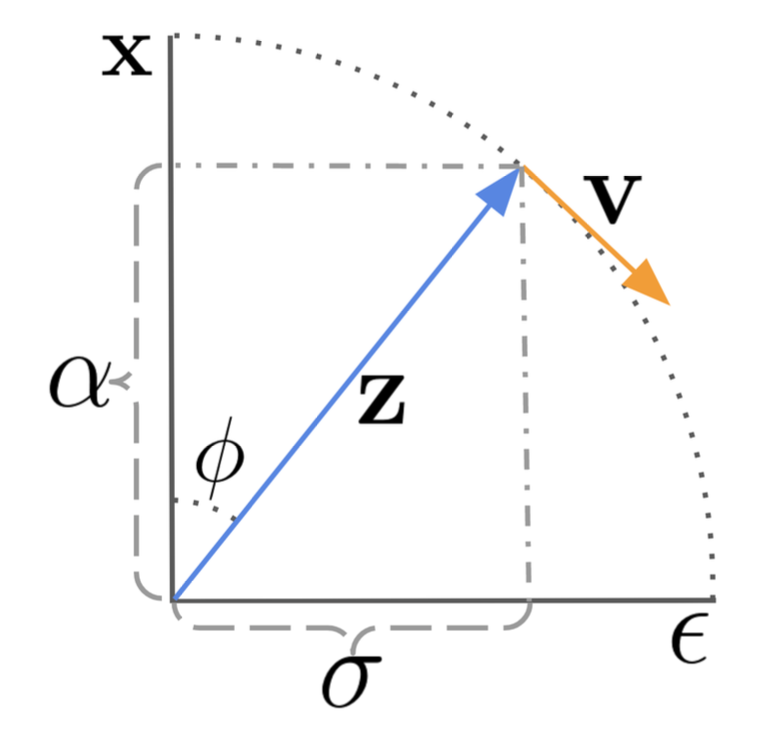
图1:扩散更新步数在角坐标中的工作原理,其中,DDIM沿着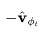 方向移动
方向移动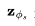 来进行演化。(图源:Salimans和Ho,2022)
来进行演化。(图源:Salimans和Ho,2022)
模型的v参数化是为了预测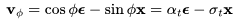 。
。
在视频生成中,我们需要扩散模型运行多个上采样步数,以延长视频长度或提高帧率。这要求模型具备根据第一个视频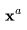 采样第二个视频
采样第二个视频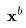 的能力,
的能力,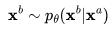 ,其
,其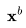 可能是
可能是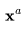 的自回归扩展,或者是低帧率视频
的自回归扩展,或者是低帧率视频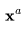 中的缺失帧。
中的缺失帧。
采样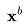 时,不仅要依赖其自身的噪声变量,还需要考虑视频
时,不仅要依赖其自身的噪声变量,还需要考虑视频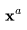 。视频扩散模型(VDM;Ho和Salimans等人,2022年)提出了一种重建引导(reconstruction guidance)方法,使用调整后的去噪模型,确保视频
。视频扩散模型(VDM;Ho和Salimans等人,2022年)提出了一种重建引导(reconstruction guidance)方法,使用调整后的去噪模型,确保视频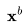 的采样能够恰当地考虑
的采样能够恰当地考虑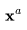 。
。
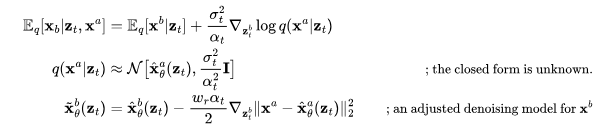
其中,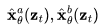 是去噪模型提供的
是去噪模型提供的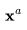 ,
,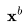 的重建。Wr是一个权重因子,Wr>1有助于提升样本质量。值得注意的是,也可以利用相同的重建引导方法,同时以低分辨率视频为条件,将样本扩展为高分辨率。
的重建。Wr是一个权重因子,Wr>1有助于提升样本质量。值得注意的是,也可以利用相同的重建引导方法,同时以低分辨率视频为条件,将样本扩展为高分辨率。
2
模型架构:3D U-Net 和 DiT
与文本到图像的扩散模型类似,U-Net和Transformer是两种常见的架构选择。Google基于U-Net架构发表了一系列关于扩散视频建模的论文,而OpenAI最近推出的Sora模型则利用了Transformer架构。
视频扩散模型(VDM;Ho和Salimans等人,2022年)采用了标准的扩散模型配置,但对架构进行了适当调整,以便更好地适用于视频建模。它将2D U-Net扩展到3D数据(Cicek 等人. 2016),使得每个特征图都表示一个4D张量(帧×高度×宽度×通道)。这种3D U-Net在空间和时间上进行了分解,即每一层只在空间或时间维度上进行操作,而不是同时处理这两个维度:
处理空间:
原先2D U-Net中的2D卷积层被扩展为仅在空间上进行的3D卷积,具体来说,原本的3x3卷积变成了1x3x3卷积。
每个空间注意力模块仍然只关注空间,其中第一帧被视为批处理维度。
处理时间:
在每个空间注意力块之后,增加了一个时间注意力块。该模块对第一帧进行注意力操作,并将空间维度视为批处理维度。时间注意力块利用了相对位置嵌入来追踪帧的顺序,这对于模型捕捉良好的时间连贯性非常关键。
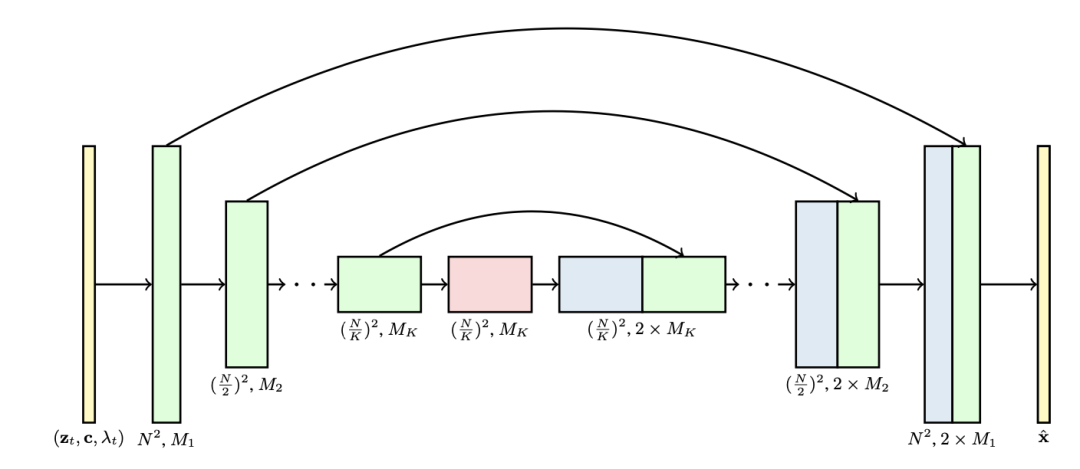
图2:3D U-Net架构图。输入到网络的包括噪声视频Zt、条件信息c和对数信噪比(log-SNR)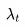 。通道乘数
。通道乘数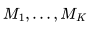 表示各层的通道数量。(图源:Salimans和Ho,2022年)
表示各层的通道数量。(图源:Salimans和Ho,2022年)
Imagen Video(Ho等人,2022年)构建在一系列扩散模型的级联之上,以提升视频生成质量,并升级至输出1280x768分辨率、每秒24帧的视频。Imagen Video的架构由以下部分构成,共包含7个扩散模型。
一个冻结的T5文本编码器,提供文本嵌入作为条件输入。
一个基础视频扩散模型。
一个由空间和时间超分辨率扩散模型交错组成的级联,包括3个TSR(时间超分辨率)和3个SSR(空间超分辨率)组件。
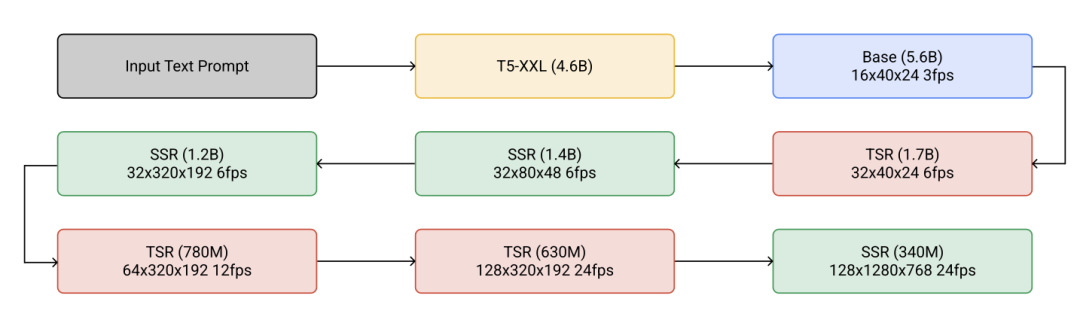
图3:Imagen Video中的级联采样流程。在实际操作中,文本嵌入被注入到所有组件中,而不仅仅是基础模型。(图源:Ho等人,2022年)
基础去噪模型使用共享参数的同时,对所有帧执行空间操作,然后时间层混合跨帧激活以更好地捕捉时间连贯性,这比帧自回归方法更有效。
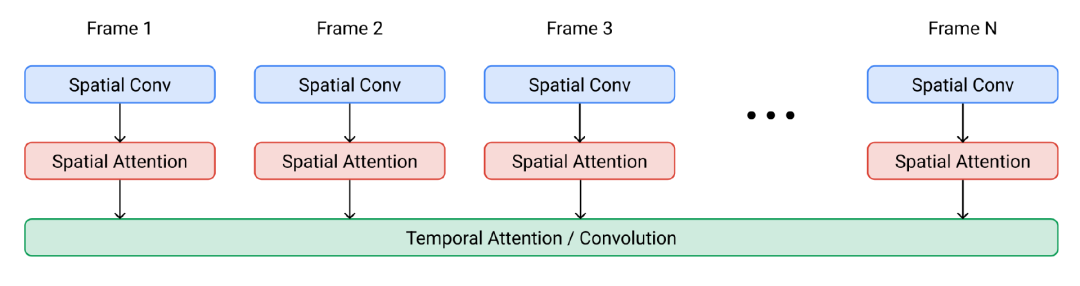
图4:Imagen Video扩散模型中一个空间-时间可分离块的架构。(图源:Ho等人,2022年)
SSR和TSR模型都基于上采样输入数据与噪声数据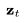 进行逐通道连接。其中,SSR模型通过双线性调整大小进行上采样,而TSR模型则通过重复帧或填充空白帧进行上采样。
进行逐通道连接。其中,SSR模型通过双线性调整大小进行上采样,而TSR模型则通过重复帧或填充空白帧进行上采样。
Imagen Video还应用了渐进蒸馏(progressive distillation)以加速采样,每次蒸馏迭代都能将所需的采样步数减半。他们的实验成功将所有7个视频扩散模型蒸馏为单个模型仅需8个采样步数,而不会在感知质量上产生明显损失。
为实现更好的扩展效果,Sora(Brooks等人,2024年)利用了DiT(Diffusion Transformer)架构,该架构在视频和图像latent code的时空块(patch)上运行。视觉输入表示为一系列的时空块,由这些块充当Transformer的输入词元。

图5:Sora是一种扩散Transformer模型。
(图源:Brooks等人,2024年)
3
将图像模型转换为视频生成模型
另一种重要的扩散视频建模方法是通过插入时间层来“扩展(nflate)”预训练的图像到文本扩散模型,然后可以选择仅在视频数据上微调新层,或完全避免额外的训练。模型继承了文本-图像对的先验知识,因此可以帮助减轻对文本-视频对数据的要求。
在视频数据上微调
Make-A-Video(Singer等人,2022年)通过增加时间维度来扩展预训练的扩散图像模型,包括以下三个关键步骤:
在文本-图像对数据上训练的基础文本到图像模型。
用于扩展网络以涵盖时间维度的时空卷积和注意力层。
用于高帧率生成的帧插值网络。
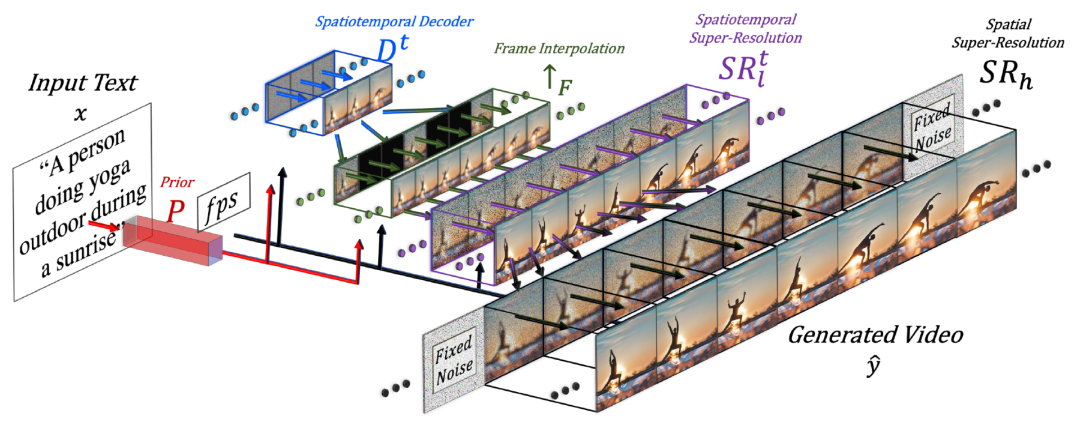
图6:Make-A-Video pipeline示意图。
(图源:Singer等人,2022年)
最终的视频推理方案可以表示为:
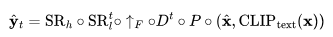
其中:
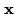 是输入文本。
是输入文本。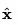 是BPE编码的文本。
是BPE编码的文本。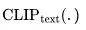 是CLIP文本编码器,
是CLIP文本编码器,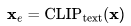
P(.)是先验知识,用于生成图像嵌入
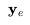 ,给定文本嵌入
,给定文本嵌入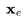 和BPE编码的文本。
和BPE编码的文本。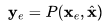 ,这一部分在文本-图像对数据上进行训练,而不是通过视频数据进行微调。
,这一部分在文本-图像对数据上进行训练,而不是通过视频数据进行微调。D^t(.)是时空解码器,用于生成一系列16帧图像,其中每一帧为低分辨率的64x64 RGB图像
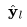 。
。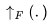 是帧插值网络,通过在生成的帧之间进行插值来增加有效帧率。这是针对预测视频上采样的掩码帧任务进行微调的模型。
是帧插值网络,通过在生成的帧之间进行插值来增加有效帧率。这是针对预测视频上采样的掩码帧任务进行微调的模型。 分别为空间模型和时空超分辨率模型,分别将图像分辨率增加到256x256和768x768。
分别为空间模型和时空超分辨率模型,分别将图像分辨率增加到256x256和768x768。 是最终生成的视频。
是最终生成的视频。
时空超分辨率层包括伪3D卷积层和伪3D注意力层:
伪3D卷积层:每个空间2D卷积层(从预训练的图像模型初始化)后跟一个时间1D层(初始化为恒等函数)。理论上讲,2D卷积层先生成多帧图像,然后这些图像帧被重塑为视频片段。
伪3D注意力层:在每个(预训练的)空间注意力层之后堆叠一个时间注意力层,并用它来近似全时空注意力层。
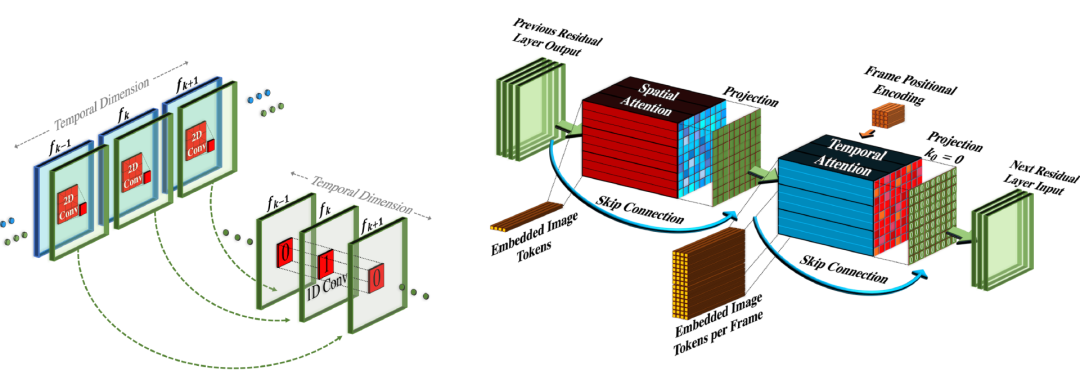
图7:伪3D卷积层(左)和注意力层(右)的工作原理。
(图源:Singer等,2022)
它们可以表示为:
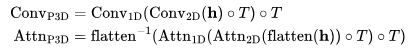
其中输入张量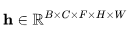 (对应批处理大小、通道数、帧数、高度和宽度);
(对应批处理大小、通道数、帧数、高度和宽度);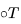 在时间和空间维度之间进行交换;
在时间和空间维度之间进行交换;  是一个矩阵运算符,用于将h转换为
是一个矩阵运算符,用于将h转换为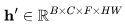 ,而
,而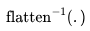 则反转该过程。
则反转该过程。
在训练过程中,Make-A-Video pipeline中的不同组件是独立训练的。
1. 解码器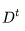 、先验函数
、先验函数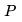 和两个超分辨率组件
和两个超分辨率组件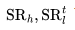 ,首先仅在图像上进行训练,不需要配对的文本数据。
,首先仅在图像上进行训练,不需要配对的文本数据。
2. 接着添加新的时间层,并被初始化为恒等函数,然后在未标注的视频数据上微调。
Tune-A-Video(吴等人,2023年)通过扩展预训练的图像扩散模型实现了一次性视频调优:给定一个包含 m 帧的视频, 表示为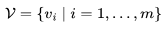 , 并配对一个描述性提示
, 并配对一个描述性提示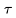 , 任务是基于经过编辑和关联的文本提示
, 任务是基于经过编辑和关联的文本提示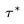 生成一个新视频
生成一个新视频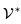 。例如,
。例如,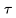 = "A man is skiing" 可以扩展为
= "A man is skiing" 可以扩展为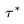 ="Spiderman is skiing on the beach". Tune-A-Video主要用于视频的对象编辑、背景更改和风格转移。
="Spiderman is skiing on the beach". Tune-A-Video主要用于视频的对象编辑、背景更改和风格转移。
除扩展2D卷积层外,Tune-A-Video的U-Net架构还融合了ST-Attention(时空注意力)模块,通过查询先前帧中的相关位置来捕捉时间一致性。给定帧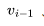 、先前帧
、先前帧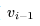 以及第一帧
以及第一帧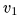 的潜在特征,将其投影为查询Q, 键K和值V, ST-attention定义为:
的潜在特征,将其投影为查询Q, 键K和值V, ST-attention定义为:
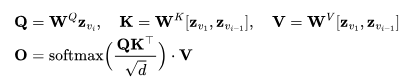
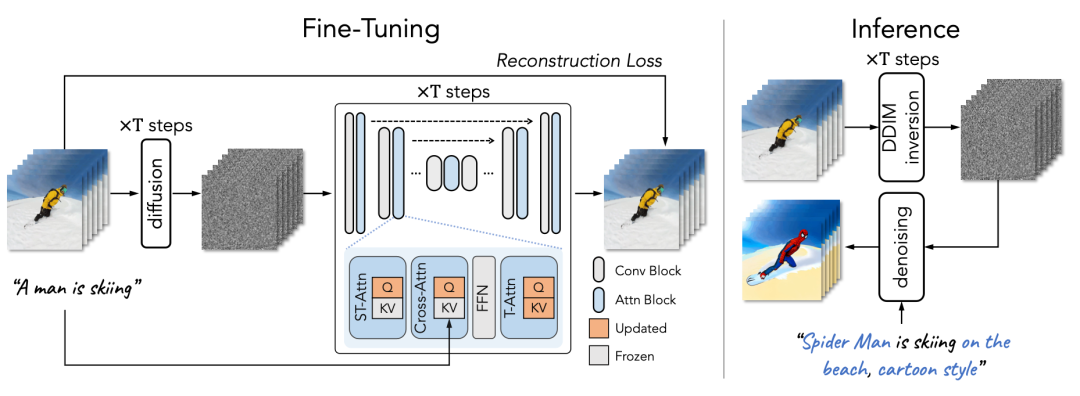
图8:Tune-A-Video架构概览。在采样前,它首先对单个视频进行了轻量级微调。需要注意的是,整个时间自注意力(T-Attn)层都进行了微调,因为它们是新添加的,但在微调过程中只更新了ST-Attn和Cross-Attn中的查询投影,以保留先前的文本到图像知识。ST-Attn提高了时空一致性,Cross-Attn则完善了文本与视频的一致性。(图源:吴等人,2023年)
Runway的Gen-1模型(Esser等人,2023年)旨在根据文本输入编辑给定的视频任务。它将视频的结构和内容设计分解为生成条件p(x|s,c)。然而,将视频的结构与内容进行清晰的分解并不容易。
Content c指视频特征(appearance)和语义, 从文本中采样进行条件编辑。帧的CLIP嵌入是内容的良好表征,并且在很大程度上与结构特征呈正交分布。
Structure s描述了视频的几何与动态特征,包括对象的形状、位置、时间变化等,s从输入视频中采样得到,可以使用深度估计(depth estimation)或其他任务特定的辅助信息(如用于人类视频合成的人体姿势或面部特征点)。
Gen-1中的架构变化相当标准,即在其残差块中每个2D空间卷积层后添加1D时间卷积层,在其注意力块中每个2D空间注意力块后添加1D时间注意力块。在训练期间,结构变量s与扩散潜变量z进行串联操作, 其中内容变量c由交叉注意力层提供。推理时,通过先验知识将CLIP嵌入转换为CLIP图像嵌入,从而将CLIP文本嵌入转换为CLIP图像嵌入。
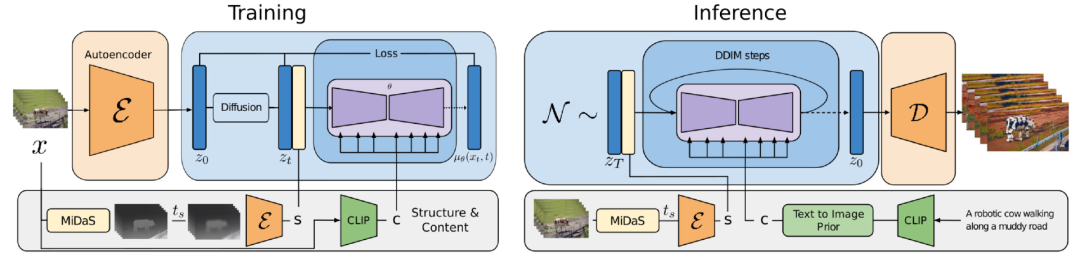
图9:Gen-1模型训练的pipeline概览。
(图源:Esser等人,2023年)
Video LDM(Blattmann等人,2023年)首先训练了一个LDM (Latent diffusion model) 图像生成器。然后微调模型,以生成具有时间维度的视频,微调仅适用于编码图像序列中新增加的时间层。Video LDM中的时间层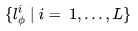 与现有保持冻结(frozen)状态的空间层
与现有保持冻结(frozen)状态的空间层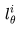 交错排列。换句话说,我们仅微调新参数
交错排列。换句话说,我们仅微调新参数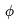 ,而不是预训练的图像骨干模型参数
,而不是预训练的图像骨干模型参数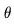 。Video LDM的pipeline首先以较低的帧率生成关键帧,然后通过两个潜在帧插值步数处理提高帧率。
。Video LDM的pipeline首先以较低的帧率生成关键帧,然后通过两个潜在帧插值步数处理提高帧率。
输入长度为T 的序列可以看做图像的批处理 (即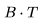 ),用于基础图像模型
),用于基础图像模型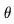 ,然后被重塑为视频格式,用于
,然后被重塑为视频格式,用于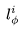 的时间层。残差连接(skip connection)将时间层
的时间层。残差连接(skip connection)将时间层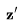 与空间输出z通过一个学习得到的合并参数
与空间输出z通过一个学习得到的合并参数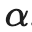 进行组合,这在实践中实现了两种类型的时间混合层:(1)时间注意力和(2)基于3D卷积的残差块。
进行组合,这在实践中实现了两种类型的时间混合层:(1)时间注意力和(2)基于3D卷积的残差块。
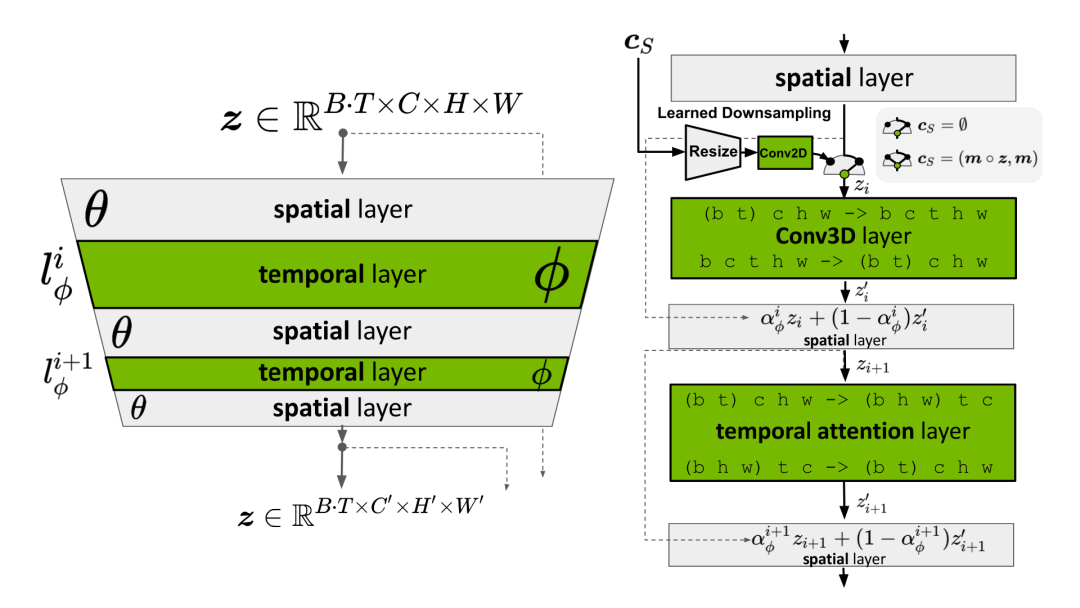
图10:一个用于图像合成的预训练LDM被扩展为视频生成器。
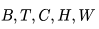 分别表示批处理大小、序列长度、通道数、高度和宽度。
分别表示批处理大小、序列长度、通道数、高度和宽度。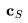 是一个可选的条件/上下文帧。(图源:Blattmann等人,2023年)
是一个可选的条件/上下文帧。(图源:Blattmann等人,2023年)
然而,LDM 的预训练自编码器存在一个问题,它只能处理图像而不能处理视频。简单地将其用于视频生成可能会导致闪烁的伪影等问题,缺乏良好的时间连贯性。因此,视频 LDM 在解码器中添加了额外的时间层,并用基于 3D 卷积构建的patch-wise时间鉴别器对视频数据进行微调,而编码器保持不变,这样我们仍然可以重用预训练的 LDM。在时间解码器微调过程中,冻结的编码器独立处理视频中的每一帧,并通过视频感知鉴别器在帧之间实现时间上的连贯重建。
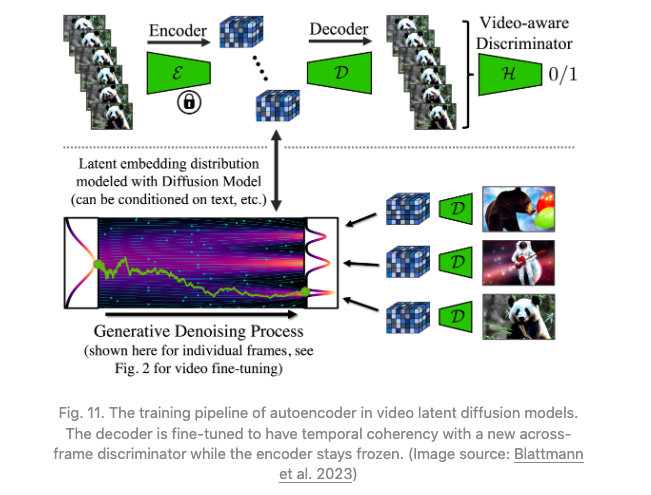
图 11:视频潜在扩散模型中自编码器的训练pipeline。解码器经过微调,以确保具有与新的跨帧鉴别器相一致的时间连贯性,而编码器保持冻结状态。(图源:Blattmann 等人,2023年)
与Video LDM类似,稳定视频扩散(SVD;Blattmann等,2023年)的架构设计也基于LDM,但在每个空间卷积和注意力层之后插入了时间层,但SVD微调了整个模型。训练视频LDM有三个阶段:
文本到图像的预训练非常重要,有助于提升质量并改善提示跟踪。
视频预训练最好分开进行,并且最好发生在一个更大规模的、精心策划的数据集上。
高质量视频微调使用视觉保真度高的较小、预标注的视频。
SVD特别强调数据集精选在模型性能中的关键作用。他们应用了一个剪切检测流程来获取每个视频更多的切割点,然后应用了三种不同的字幕模型:(1) CoCa用于中间帧,(2) V-BLIP用于视频字幕,以及(3) 基于前两个字幕的 LLM 字幕。然后他们能够继续改进视频数据集,通过移除动作较少的片段(通过在2fps计算的低光流分数进行筛选),存在过多文本的片段(应用OCR来识别包含大量文本的视频),或者普遍审美价值较低的片段(使用CLIP嵌入对每个片段的第一帧、中间和最后一帧进行标注并计算美学分数和文本-图像相似度)。实验表明,经过筛选的、更高质量的数据集会带来更好的模型质量,即使这个数据集要小得多。
保持高质量的时间一致性是先生成远程关键帧,然后再通过时间超分辨率添加插值这一过程中的关键挑战。相比之下,Lumiere(Bar-Tal等,2024年)采用了空时 U-Net(STUNet)架构,通过一次传递生成整个视频的整个时间段,消除了对TSR(时间超分辨率)组件的依赖。STUNet在时间和空间维度上对视频进行下采样,因此昂贵的计算发生在紧凑的时间-空间潜空间中。
如何保持高质量的时间一致性的关键挑战,Lumiere(Bar-Tal等,2024年)相反采用了一种称为空时 U-Net(STUNet)的架构,通过单次传递生成整个视频的整个时间持续周期,从而消除了对 TSR(时间超分辨率)组件的依赖。STUNet在时间和空间维度上对视频进行降采样,因此,在紧凑的时空潜空间中,出现了成本更高的计算。
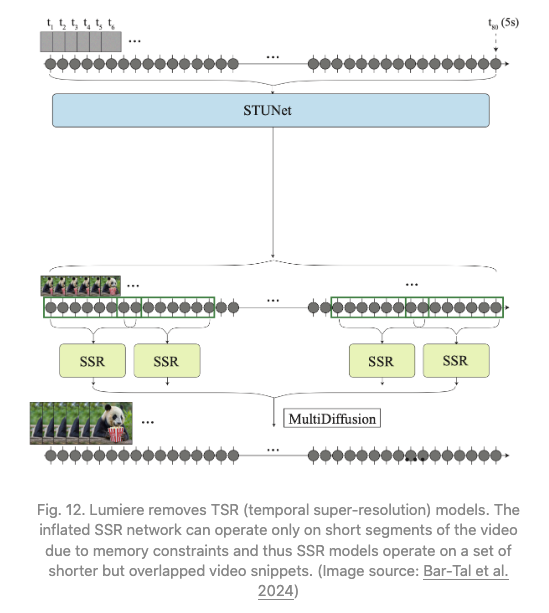
图12:Lumiere去除了TSR(时间超分辨率)模型。由于内存限制,膨胀的SSR网络只能在视频的短片段上运行,因此SSR模型在一组更短但重叠的视频片段上运行。(图片来源:Bar-Tal等人,2024年)
STUNet将预训练的文本到图像U-net进行扩展,以便能够在时间和空间维度上对视频进行下采样和上采样。基于卷积的block包括预训练的文本到图像层,然后是分解的时空卷积。在最粗糙的U-Net级别上的基于注意力的block包含预训练的文本到图像,然后是时间注意力。进一步的训练只发生在新添加的层上。
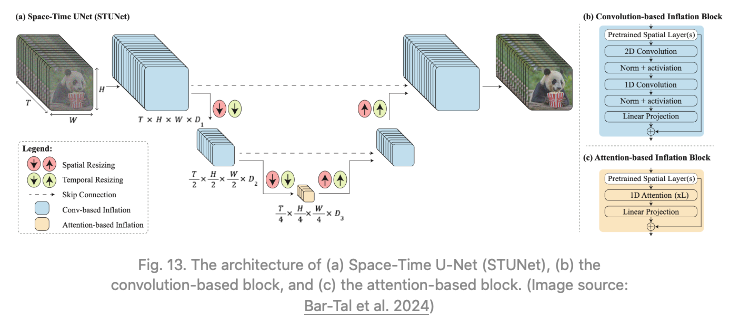
图 13:(a)Space-Time U-Net(STUNet)的架构,(b)基于卷积的块,和(c)基于注意力的块。(图片来源:Bar-Tal 等人,2024年)
令人惊讶的是,我们可以在不进行任何训练的情况下将预训练的文本到图像模型调整为输出视频 。
如果我们简单地随机采样一系列潜在代码,然后构建解码对应图像的视频,那么对象和语义在时间上的一致性是没有保证的。Text2Video-Zero(Khachatryan 等人,2023年)通过以下两个关键机制来增强预训练的图像扩散模型,以实现零训练、无需训练的视频生成,确保时间上的一致性:
使用运动动态对潜在代码序列进行采样,以保持全局场景和背景的时间一致性;
使用第一帧上每帧的新跨帧注意力来对帧级自注意力进行重新编码,以保留前景对象的上下文、外观和身份。
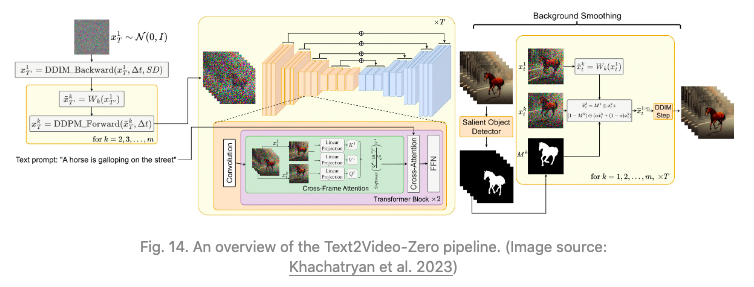
图 14:Text2Video-Zero pipeline概览。(图源:Khachatryan 等人,2023年)
对一组包含运动信息的潜在变量进行采样的过程,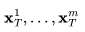 ,如下所述:
,如下所述:
1. 定义一个方向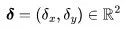 用于控制全局场景和相机运动;默认情况下,我们设为
用于控制全局场景和相机运动;默认情况下,我们设为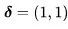 。同时,定义一个控制全局运动量的超参数
。同时,定义一个控制全局运动量的超参数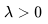 。
。
2. 首先随机抽样第一帧的潜在编码,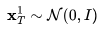 ;
;
3. 使用预训练的图像扩散模型,例如论文中的稳定扩散(SD)模型,执行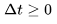 :DDIM反向更新step,并获得相应的潜在编码
:DDIM反向更新step,并获得相应的潜在编码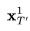 ,其中
,其中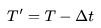 。
。
4. 对于潜在编码序列中的每一帧,我们应用相应的运动转换,并使用由以下公式定义的变形操作: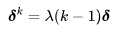
5. 最后对所有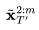 应用 DDIM 前向step,来获得
应用 DDIM 前向step,来获得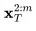 。
。
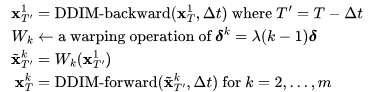
此外,Text2Video-Zero将预训练的SD模型中的自注意力层替换为一种新的跨帧注意力机制,参考第一帧。其动机是在生成的视频中保留关于前景对象的外观、形状和身份的信息。
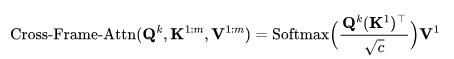
作为一个可选项,背景遮罩(mask)可以用于进一步平滑和改善背景的一致性。假设我们使用某种现有方法为第 k 帧获取相应的前景遮罩Mk,背景平滑将在扩散步数t时,相对于背景矩阵,合并实际和变形的潜在编码:
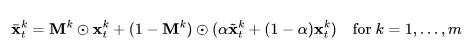
其中,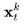 是实际的潜在编码,
是实际的潜在编码,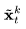 是在背景上变形的潜在编码;
是在背景上变形的潜在编码;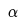 是一个超参数,文献中在实验里设定
是一个超参数,文献中在实验里设定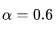 。
。
Text2Video-Zero可以与ControlNet相结合,其中ControlNet的预训练副本分支应用于每个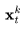 ,对于k=1,...,m在每个扩散时间步t=T,...,1,并将ControlNet分支的输出添加到主U-net的跳跃连接中。
,对于k=1,...,m在每个扩散时间步t=T,...,1,并将ControlNet分支的输出添加到主U-net的跳跃连接中。
ControlVideo(张等人,2023年)旨在根据文本提示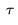 和运动序列(例如,深度或边缘图
和运动序列(例如,深度或边缘图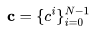 生成视频。它由ControlNet改编而成,增加了三种新机制:
生成视频。它由ControlNet改编而成,增加了三种新机制:
1. 跨帧注意力(Cross-frame attention):在自注意力模块中增加完全的跨帧交互。它通过将所有时间步的潜变量帧映射到Q,K,V矩阵中,引入了所有帧之间的交互作用,与Text2Video-Zero不同,后者只配置所有帧,以关注第一帧。
2. 交错帧平滑器(Interleaved-frame smoother)是一种机制,用于在交替帧上进行帧插值,以减少闪烁效果。在每个时间步t,平滑器对偶数或奇数帧进行插值,以平滑它们对应的三帧片段。请注意,在平滑步之后,帧数会随时间减少。
3. 利用分层采样器(Hierarchical sampler)实现在内存限制下保持时间一致性的长视频。长视频被分割成多个短片段,每个片段都选择了一个关键帧。模型预生成这些关键帧,使用完全的跨帧注意力以保持长期连贯性,并且每个相应的短片段都是在关键帧的条件下依次合成的。
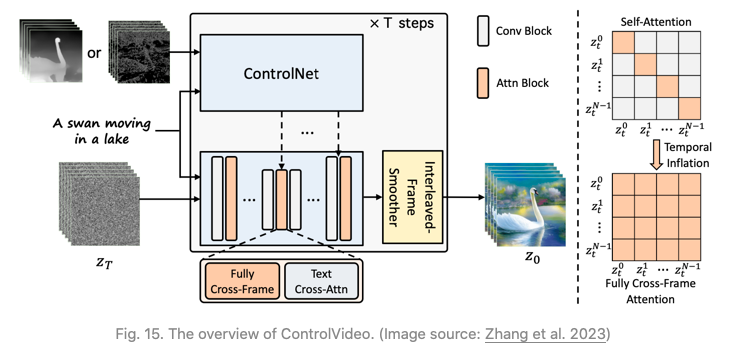
图15:ControlVideo概览。(图源:张等人,2023年)
参考文献(请上下滑动)
[1] Cicek et al. 2016. “3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation.”
[2] Ho & Salimans, et al. “Video Diffusion Models.” 2022 | webpage
[3] Bar-Tal et al. 2024 “Lumiere: A Space-Time Diffusion Model for Video Generation.”
[4] Brooks et al. “Video generation models as world simulators.” OpenAI Blog, 2024.
[5] Zhang et al. 2023 “ControlVideo: Training-free Controllable Text-to-Video Generation.”
[6] Khachatryan et al. 2023 “Text2Video-Zero: Text-to-image diffusion models are zero-shot video generators.”
[7] Ho, et al. 2022 “Imagen Video: High Definition Video Generation with Diffusion Models.”
[8] Singer et al. “Make-A-Video: Text-to-Video Generation without Text-Video Data.” 2022.
[9] Wu et al. “Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation.” ICCV 2023.
[10] Blattmann et al. 2023 “Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models.”
[11] Blattmann et al. 2023 “Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets.”
[12] Esser et al. 2023 “Structure and Content-Guided Video Synthesis with Diffusion Models.”
[13] Bar-Tal et al. 2024“Lumiere: A Space-Time Diffusion Model for Video Generation.”
【OneDiff v1.0发布(生产环境稳定加速SD&SVD)】本次更新包含以下亮点,欢迎体验新版本:github.com/siliconflow/onediff
OneDiff质量评估
重复利用编译图
改进对Playground v2.5的支持
支持ComfyUI-AnimateDiff-Evolved
支持ComfyUI_IPAdapter_plus
支持Stable Cascade
提高了VAE的性能
为OneDiff企业版提供量化工具
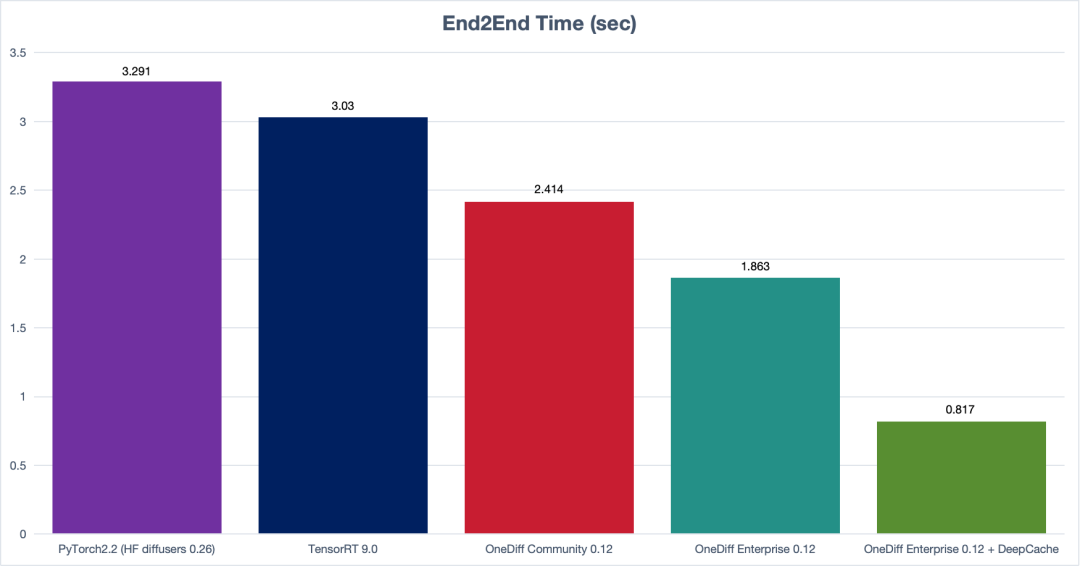
(SDXL E2E Time)
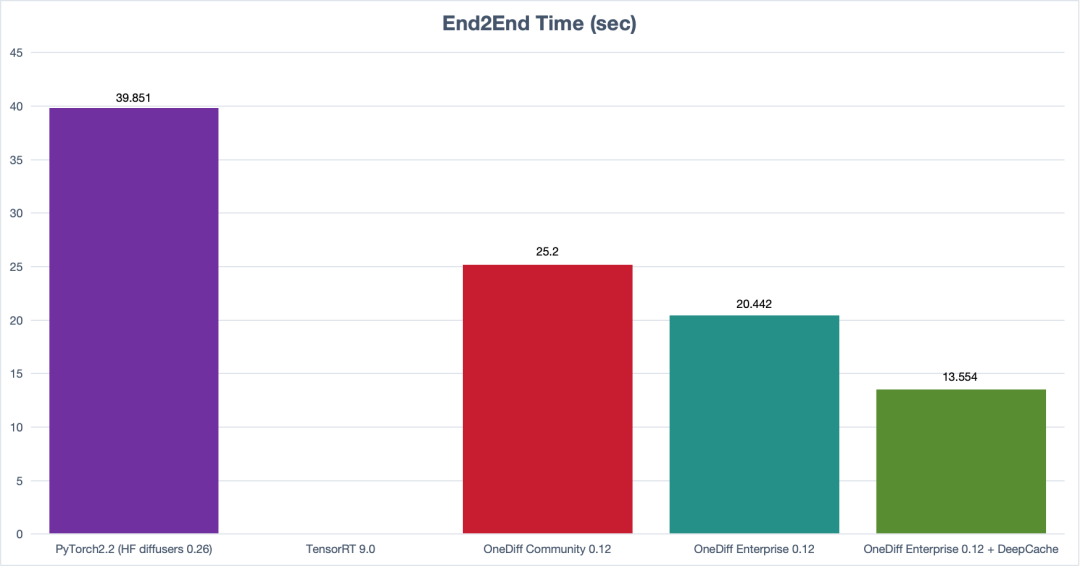
(SVD E2E Time)
(OneDiff Demo)
其他人都在看


