
- 1呼吸灯的实现_led灯组实现呼吸灯效果
- 2python爬取微博用户信息_Python爬取新浪微博用户信息及内容
- 3美团前端实习面经_美团前端面经
- 4Sending build context to Docker daemon 2.048kBError response from daemon: dockerfile parse error l
- 5PiflowX新增Apache Beam引擎支持
- 6Linux疑难杂症解决方案100篇(十一)-ubuntu crontab 详细规则及不执行时的解决方法_crontab在ubuntu下不执行
- 7vue-simple-uploader上传组件_vue simple uploader
- 8图像处理:理想低通滤波器、butterworth滤波器(巴特沃斯)、高斯滤波器实现(python)_python 巴特沃斯低通滤波器
- 9操作系统---第四章文件管理---磁盘组织与管理---选择题_设某个磁带的记录密度为300字符/英寸
- 10Eclipse中Java连接sql server数据库_eclipse4.2.0,sqlserver
ChatGPT高效提问—prompt常见用法(续篇七)
赞
踩
ChatGPT高效提问—prompt常见用法(续篇七)
1.1 零样本、单样本和多样本
ChatGPT拥有令人惊叹的功能和能力,允许用户自由向其提问,无须提供任何具体的示例样本,就可以获得精准的回答。这种特性被称为零样本(zero shot)prompt。然而,如果你希望获得更具针对性的回答,可以选择向ChatGPT提供一个或者多个示例样本加以引导。根据提供示例样本的书了,可以分为单样本(one shot)prompt和多样本(multiple shot) prompt。
1.1.1 零样本
在零样本模式下,即在没有任何示例样本的前提下,直接让ChatGPT回答问题。示例如下。
输入prompt:

ChatGPT输出:
- 1

ChatGPT直接给出了对老虎的描述。
1.1.2 单样本
相较于零样本prompt,单样本prompt则要求我们提供一个明确的示例。比如,可以先以特定的格式描述大象,然后引导ChatGPT以同样的格式描述老虎,从而使回答更加精准。
输入prompt:

ChatGPT输出:

观察输出可知,ChatGPT描述老虎的格式与我们提供的关于大象的示例样本格式高度一致。这表明,ChatGPT通过我们提供的单一样本有效地掌握了任务的执行方式。
1.1.3 多样本
对于更高难度的任务,我们可以提供多更多的示例样本,这种方法被称为多样本prompt。例如,我们可以给出多个示例样本,然后让ChatGPT自行完成任务。这种方式在处理复杂任务时效果往往出奇的好。下面是一个基于情感识别的多样本示例。
输入prompt:
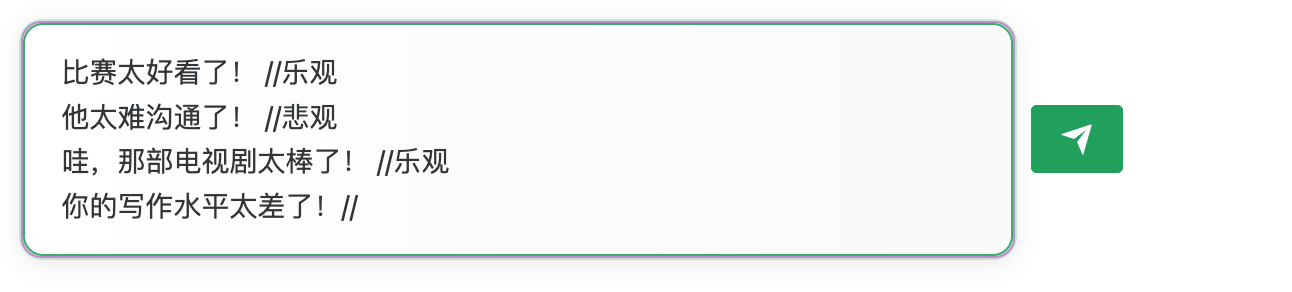
ChatGPT输出:

从上述答案可以看出,ChatGPT凭借所给的示例样本,成功判断出最后一句话所含情绪为悲观。我们还可以进一步考验它,通过随机化标签,甚至故意制造错误,来观察ChatGPT是否仍能准确地进行判断。
输入prompt:

ChatGPT输出:
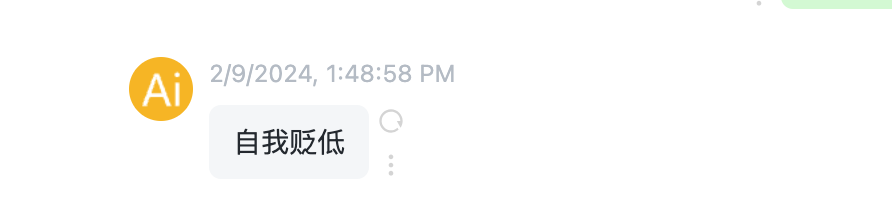
显然,尽管我们将标签进行了随机化排列,故意使得表述错误,ChatGPT仍然能够准确地进行判断。接下来继续增加难度,这次我们不提供任何样本提示,看看ChatGPT会如何应答。
输入prompt:

ChatGPT输出:

观察输出结果可以发现,即使在多论对话结束后,ChatGP也能在无须示例样本的情况下,准确地生成结果。它的反应方式与人类的思考方式高度一致,展现出了极其优秀的分析和辨别能力。
通过样本提示,我们可以获得更加规整、符合要求的回答。
1.2 思维链
思维链(chain of thought, CoT)———prompt范式进化史上的一大功臣。简单来说,思维链就是一系列中间推理步骤。使用思维链的一大好处是无须微调模型参数,仅仅改变输入即可大幅提升模型进行复杂推理时的准确率。
人类解决复杂推理问题的过程是,首先将其分解为一些中间问题,然后逐步解决,直至得到最终结论,也称“自顶向下,逐步求精”。思维链就是参考人类解决问题的方法,从输出问题开始的一系列自然语言形式的推理过程,直到输出最后的结论。和之前的提示词模式(问题,答案)不同,思维链提示词模式是:输入问题,思维链,输出结论。相较于样本提示学习,思维链提示学习有几个吸引人的性质。
- 在思维链的加持下,模型可以将需要多步推理的问题分解为一系列中间步骤,这可以分配更多的计算资源到需要推理的问题上。
- 思维链为模型的推理行为提供了一个可解释的窗口,使通过调试推理路径来探测黑盒语言模型成为可能。
- 思维链推理应用广泛,不仅可以用于数学应用题求解、常识推理和符号操作等任务,而且可能适用于任何需要通过语言解决的问题。
- 思维链的使用方式非常简单,非常容易融入语境学习(in-context learning),从而诱导大型语言模型展现出推理能力。
下面通过示例做一下对比,体会其中的区别。先看第1个示例。
输入prompt:

ChatGPT输出:

从输出结果来看,ChatGPT给出了错误回答。再看第2个示例。
输入prompt:

ChatGPT输出:
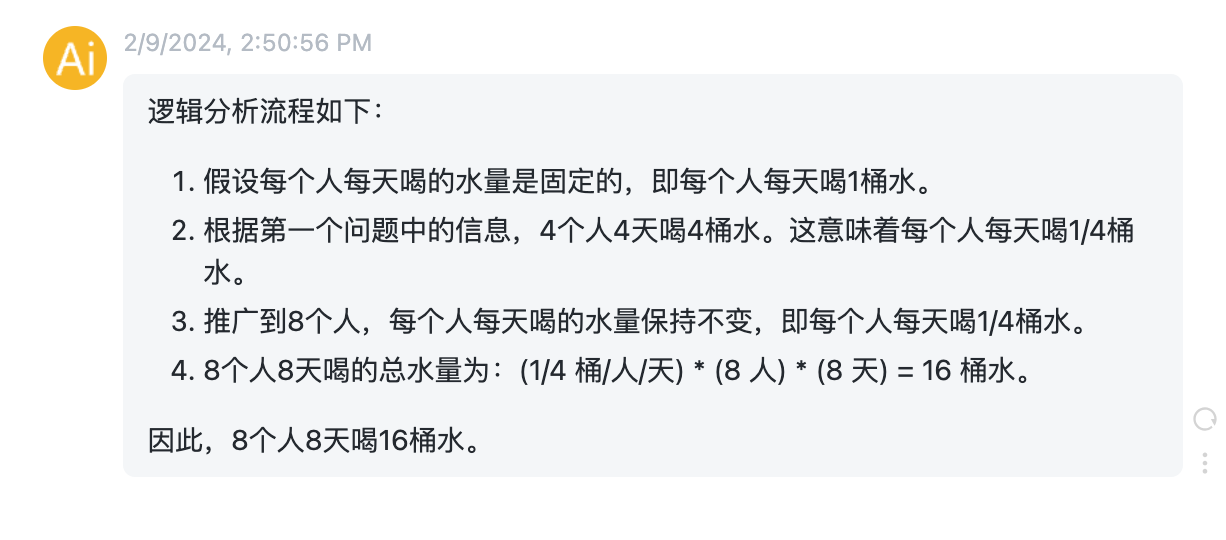
从输出结果来看,当我们给ChatGPT提供了计算推理的引导后,ChatGPT参考示例进行思考,给出了计算推理过程和正确结果,与第一个示例的错误结果形成鲜明对比。再看第3个示例。
输入prompt:

ChatGPT输出:
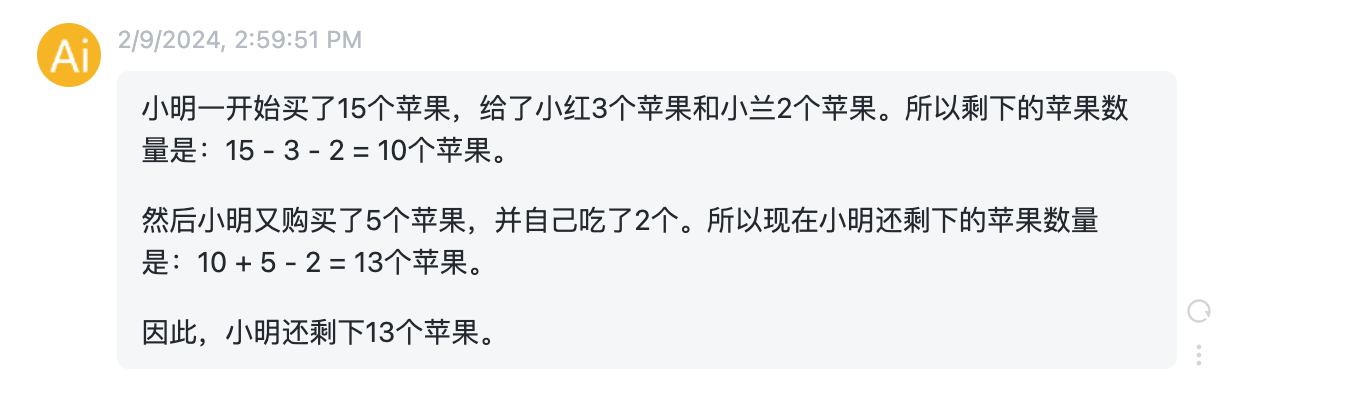
输入prompt:
这次增加了“让我们一步一步思考”,看看ChatGPT输出。

ChatGPT输出:
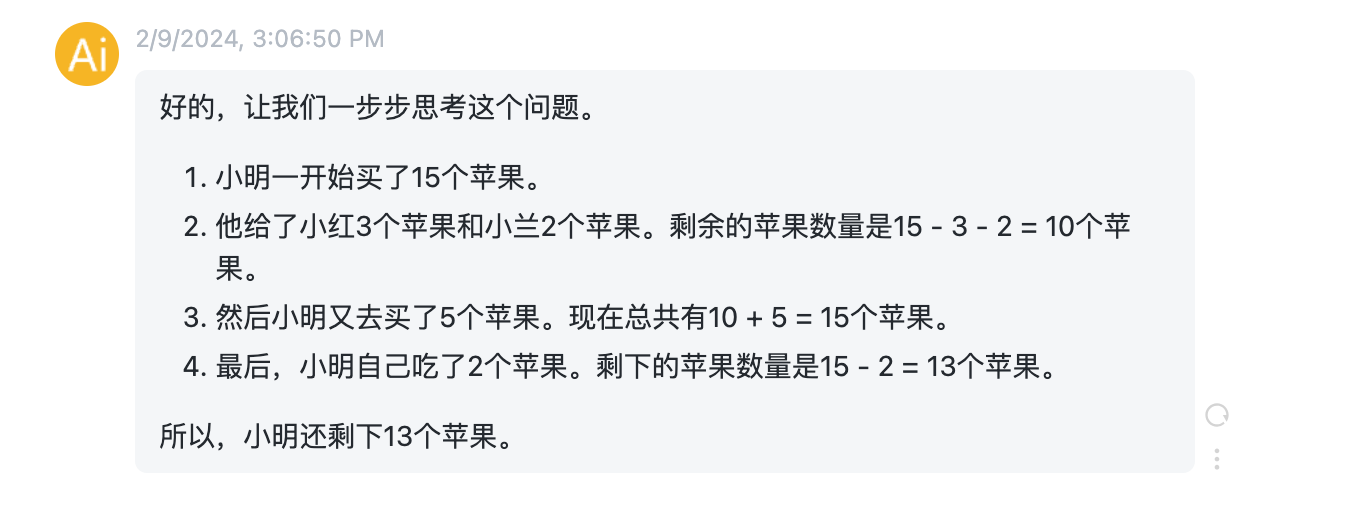
很明显,当在prompt增加“让我们一步步思考”后,ChatGPT最后没有把送出去的苹果再加上,同样给出了正确结果,但是细节分析更加清晰和符合逻辑。简单地加上这么一句话,让ChatGPT自己先思考一下,会给出更加相信而准确的结果。
最后,总结一下使用思维链范式时的两种主要方法:
- 输入一个多步推理的prompt模版,把我们的逻辑推导过程告诉ChatGPT;
- 在问题的最后添加“让我们一步步思考”,让ChatGPT思考后再给出答案。
思维链让模型能够像人一样进行思考,但是人也会犯错,更何况是模型呢。为了让模型输出更加安全、准确,需要了解对抗在其中的作用。

