
- 1如何发布Android库到Maven中心仓库_repository oss.sonatype.org
- 2docker-compose安装部署kafka_docker-compose安装kafka
- 3c++ string类的常用方法_OpenCV常用图像拼接方法(四):基于Stitcher类拼接
- 4layer mobile使用方法_layui mobile
- 5体验了下科大讯飞星火模型的新功能,被惊艳到了!
- 6Vision Transformer鸟类图像分类:数据和代码分享_python鸟类图像分类
- 7Unity-Timeline制作动画(快来制作属于你的动画吧)_unity timeline 怎么启动动画
- 8全国职业技能大赛云计算赛项---Linux系统调优案例_oslo.messaging._drivers.impl_rabbit oserror: [errn
- 9无伤理解阻抗控制:机械臂的阻抗、导纳控制(间接力控):第一篇 思想源泉_机械臂阻抗
- 10UX与UI设计的区别及编程实践_uxjuc
《零基础实践深度学习》1.4.1飞桨产业级深度学习开源开放平台介绍
赞
踩
1.4飞桨产业级深度学习开源开放平台介绍
1.4.1 深度学习框架
近年来,深度学习在很多机器学习任务中都有着非常出色的表现,在图像识别、语音识别、自然语言处理、机器人、网络广告投放、医学自动诊断和金融等领域都有着广泛应用。面对繁多的应用场景,深度学习框架有助于建模者聚焦业务场景和模型设计本身,省去大量而繁琐的代码编写工作,其优势主要表现在如下两个方面:
- 节省编写大量底层代码的精力:深度学习框架屏蔽了底层实现,用户只需关注模型的逻辑结构,同时简化了计算逻辑,降低了深度学习入门门槛。
- 省去了部署和适配环境的烦恼:深度学习框架具备灵活的移植性,可将代码部署到CPU、GPU和AIPU等芯片上,选择具有分布式能力的深度学习框架会使模型训练更高效。
写到这里,作为一名在人工智能领域深耕多年的从业者,笔者不禁要感叹深度学习框架的出现对AI行业的影响。深度学习框架的出现,加速了AI产业应用的步伐,但同时研发工程师的“好日子”也一去不复返了!10年前,研发一个解决业务问题的神经网络模型,需要使用C++语言逐行代码完整的实现从前向计算到梯度下降的计算逻辑,一个深层神经网络模型往往需要几百到上千行的代码。但为什么说是“好日子”呢?因为研发模型的项目是按照季度排期,工程师至少需要12周的时间完成模型的研发。但今天,基于飞桨深度学习框架和产业级模型库,模型应用的研发周期被缩短到3~5天,即当周确定需求,当周完成模型的研发和上线。效率的巨大提升也带来了工作节奏的加快,可以说是工具带给人类美好生活之外的一种无奈吧!
1.4.2 深度学习框架设计思想
深度学习框架的本质是自动实现建模过程中相对通用的模块,建模者只实现模型中个性化的部分,这样可以在“节省投入”和“产出强大”之间达到一个平衡。想象一下:假设你是一个深度学习框架的创造者,你期望让框架实现哪些功能呢?
相信对神经网络模型有所了解的读者都会得出如表1的设计思路,在构建模型的过程中,每一步所需要完成的任务均可以拆分成个性化和通用化两个部分。
- 个性化部分:往往是指定模型由哪些计算单元组合,由建模者完成。
- 通用部分:聚焦这些计算单元的具体实现,由深度学习框架完成。
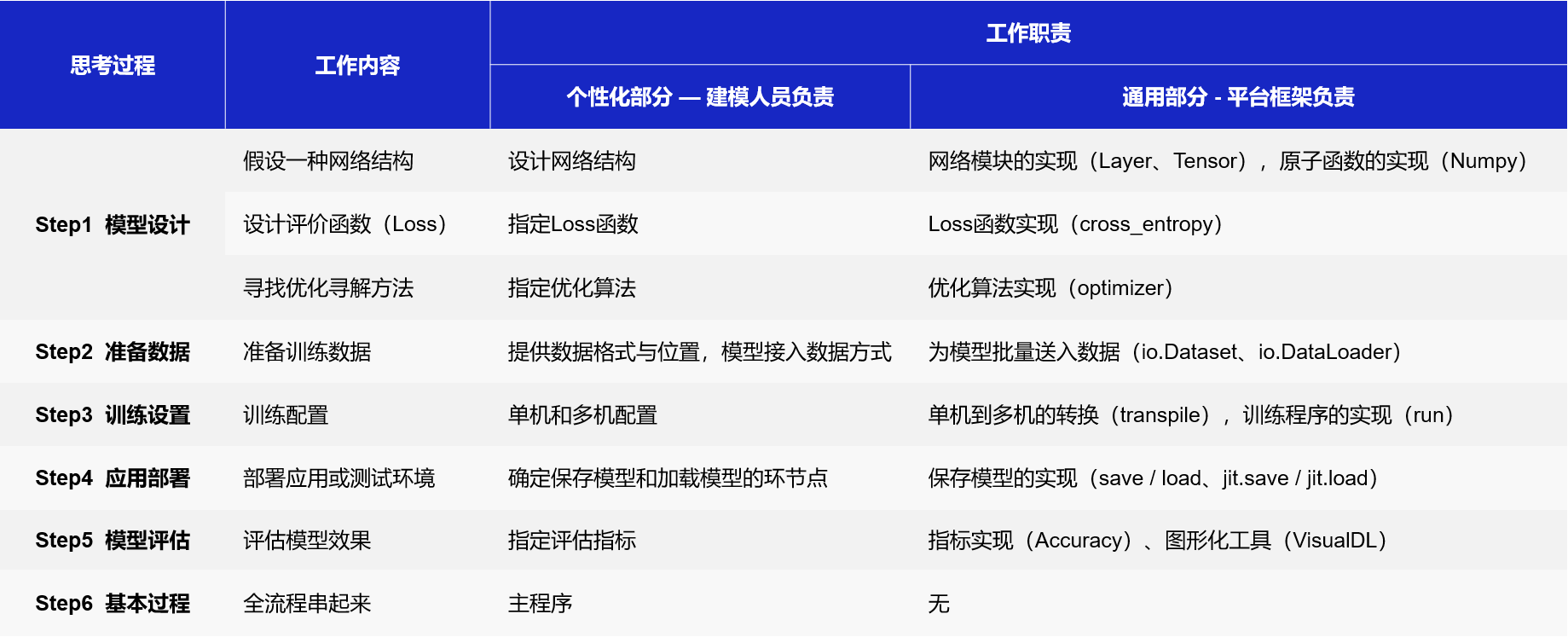
表1:深度学习框架设计示意图
无论是计算机视觉任务还是自然语言处理任务,使用的深度学习模型代码结构是类似的,只是在每个环节指定的计算单元不同。因此,多数情况下,计算单元只是相对有限的一些选择,如常见的损失函数不超过10种、常用的网络配置也就十几种、常用优化算法不超过五种等等,这些特性使得基于框架建模更像一个编写“模型配置”的过程。
1.4.3 飞桨产业级深度学习开源开放平台
飞桨(PaddlePaddle)是百度自主研发的中国首个开源开放、功能丰富的产业级深度学习平台,以百度多年的深度学习技术研究和业务应用为基础。飞桨深度学习平台集核心框架、基础模型库、端到端开发套件、丰富的工具组件于一体,于2016年正式开源,是主流深度学习框架中一款完全国产化的产品。相比国内其他产品,飞桨是一个功能完整的深度学习平台,也是唯一成熟稳定、具备大规模推广条件的深度学习开源开放平台。根据国际权威调查机构IDC报告显示,2021年飞桨已位居中国深度学习平台市场综合份额第一。
目前,飞桨已凝聚535万开发者,基于飞桨创建67万个模型,服务20万家企事业单位。飞桨助力开发者快速实现AI想法,创新AI应用,作为基础平台支撑越来越多行业实现产业智能化升级,并已广泛应用于智慧城市、智能制造、智慧金融、泛交通、泛互联网、智慧农业等领域,如图1所示。
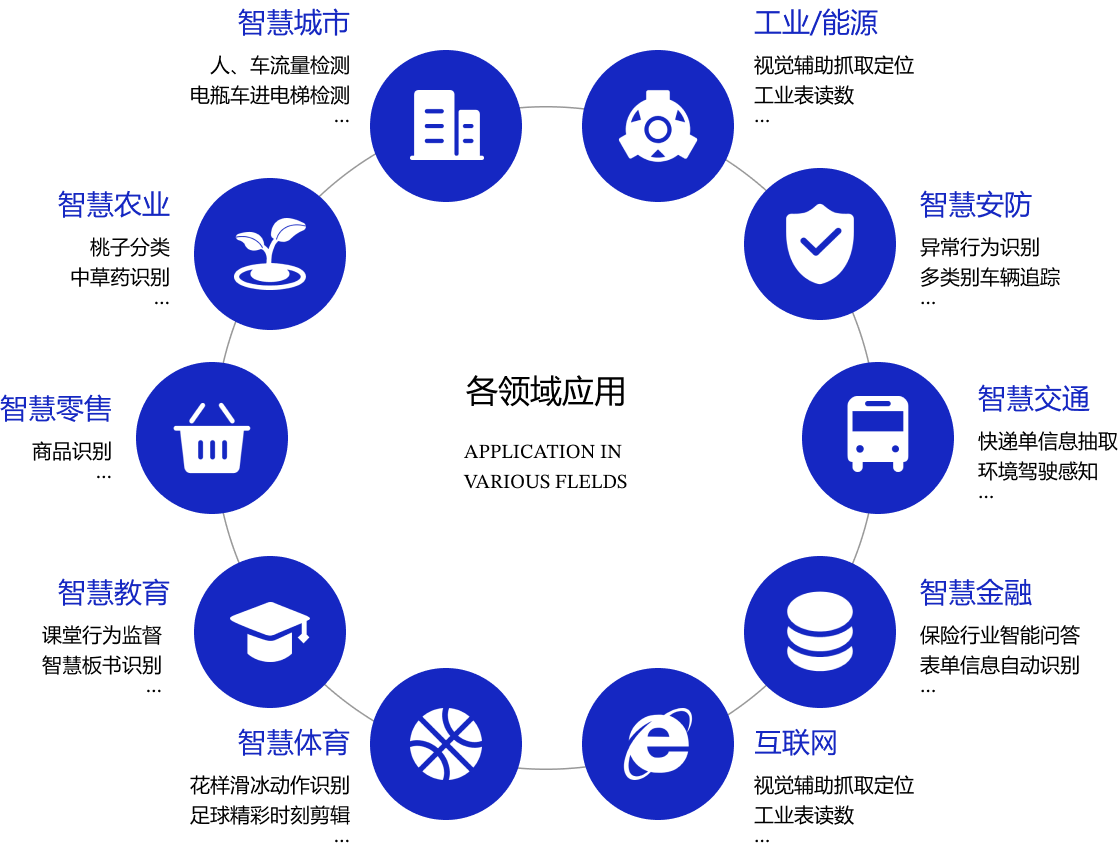
图1:飞桨在各领域的应用
飞桨产业级深度学习开源开放平台包含核心框架、基础模型库、端到端开发套件与工具组件几个部分,各组件使用场景如图图2所示。
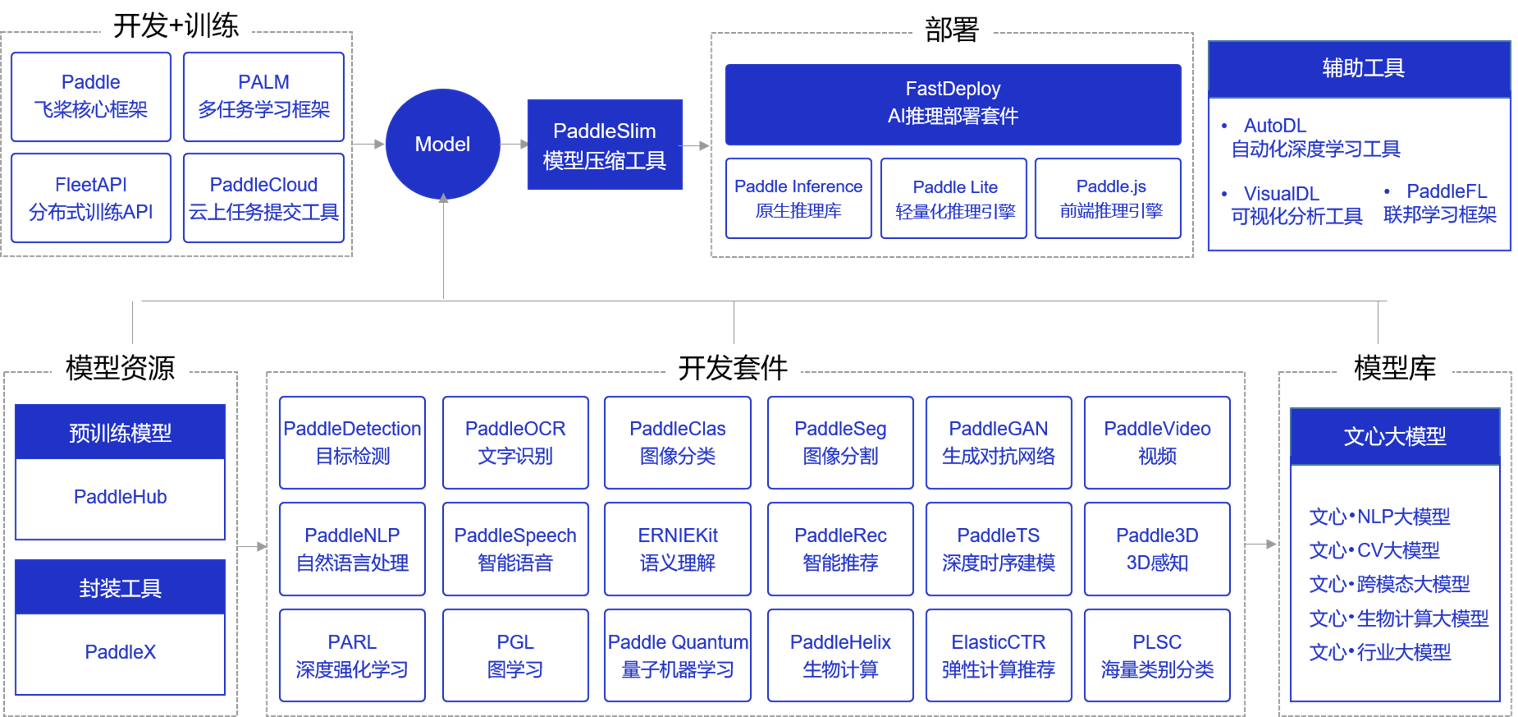
图2:飞桨开源组件使用场景概览
概览图上半部分是从开发、训练到部署的全流程工具;下半部分是预训练模型、封装工具、各领域的开发套件和模型库等模型资源,支持深度学习模型从训练到部署的全流程。
模型开发和训练组件
飞桨核心框架支持用户完成基础的模型编写和单机训练功能。除核心框架之外,飞桨还提供了分布式训练框架FleetAPI、云上任务提交工具PaddleCloud和多任务学习框架PALM。
模型部署组件
针对不同硬件环境,飞桨提供了丰富的支持方案:
(1)FastDeploy:AI推理部署套件,面向AI模型产业落地,支持40多个主流的AI模型在8大类常见硬件上的部署能力,帮助开发者简单几步即可完成AI模型在对应硬件上的部署。
(2)Paddle Inference:飞桨原生推理库,用于服务器端模型部署,支持Python、C、C++、Go等语言,可将模型融入业务系统。
(3)Paddle Lite:飞桨轻量化推理引擎,用于Mobile、IoT等场景的部署,有着广泛的硬件支持。
(4)Paddle.js:使用JavaScript(Web)语言部署模型,用于在浏览器、小程序等环境快速部署模型。
(5)PaddleSlim:模型压缩工具,获得更小体积的模型和更快的执行性能,通常在模型部署前使用。
(6)X2Paddle:飞桨模型转换工具,将其他框架模型转换成飞桨模型,转换格式后可以方便的使用第(1)~第(5)个工具。
预训练模型和封装工具
通过低代码形式,支持企业POC快速验证、快速实现深度学习算法开发及产业部署。
- PaddleHub :飞桨预训练模型应用工具,提供超过400个开源的预训练模型,覆盖文本、图像、视频、语音、跨模态等多个AI领域。开发者可以轻松结合实际业务场景,选用预训练模型一键推理/一行代码服务化部署,快速完成模型验证与应用工作。
- PaddleX :飞桨低代码开发工具,以低代码的形式支持开发者快速实现深度学习算法开发及产业部署。提供极简Python API和可视化界面Demo两种开发模式,可一键安装。提供CPU、GPU、树莓派等通用硬件高性能部署方案,支持用户流程化串联部署任务,极大降低部署成本。
其他全研发流程的辅助工具组件
- AutoDL :飞桨自动化深度学习工具AutoDL,提供基于强化学习的神经网络结构搜索基本框架,AutoDL设计的网络相比于人类设计的网络,其精度更优,体积更小。AutoDL也可应用于风格化图像生成、科学计算等更为复杂和实用的场景。
- VisualDL :飞桨可视化分析工具VisualDL,以丰富的图表呈现训练参数变化趋势、模型结构、数据样本、高维数据分布、精度召回曲线、性能消耗数据等模型关键信息。帮助用户清晰直观地理解深度学习模型训练过程及模型结构,进而实现高效的模型调优、算法训练过程及性能分析与结果分享。
- PaddleFL :飞桨联邦学习框架PaddleFL,支持轻松复制和比较联邦学习算 法,便捷地实现大规模分布式集群部署,并且提供丰富的横向和纵 向联邦学习策略及其在计算机视觉、自然语言处理、推荐算法等领域的应用。此外,可以基于全栈开源软件轻松部署。
飞桨产业级开源模型库
人工智能产业应用时常面临四大难点:1)很难找到合适的开源模型;2)模型不适用产业场景;3)模型优化成本高;4)部署时问题频发。
针对工程师在AI产业落地时面临的四大难题,飞桨提出了产业级开源模型库方案:支持500+个精选算法和预训练模型,全面覆盖深度学习主流应用领域,如计算机视觉、语音、自然语言处理、大模型、推荐、强化学习等;支持23个特色的PP系列模型,满足对模型精度和推理速度都有较高要求的产业应用场景;支持端到端的AI开发套件,开发者只需要修改配置文件,而不需要修改代码,即可实现各种优化策略;提供训推一体的全链条功能支持,保障飞桨模型在多种多样的应用场景中可以高效、稳定、可靠的训练和部署。
- PaddleClas :飞桨图像分类开发套件,提供超轻量图像分类方案 PULC,覆盖人、车、OCR方向九大任务高频应用;支持通用图像识别系统PP-ShiTu,可高效实现高精度车辆、商品等多种识别任务;提供44个系列243个高性能图像分类预训练模型,其中包括10万分类预训练模型、PP-LCNet等明星模型;以及支持SSLD知识蒸馏等先进算法优化策略,可被广泛应用于高阶视觉任务,辅助产业及科研领域快速解决多类别、高相似度、小样本等业界难点。
- PaddleDetection :飞桨目标检测开发套件,内置250+个主流目标检测、实例分割、跟踪、关键点检测算法,其中包括服务器端和移动端产业级SOTA模型、冠军方案和学术前沿算法,并提供行人、车辆等场景化能力、配置化的网络模块组件、10余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
- PaddleSeg :飞桨目标检测开发套件,内置250+个主流目标检测、实例分割、跟踪、关键点检测算法,其中包括服务器端和移动端产业级SOTA模型、冠军方案和学术前沿算法,并提供行人、车辆等场景化能力、配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
- PaddleOCR: 飞桨文字识别开发套件,旨在打造一套丰富、领先且实用的OCR工具库,开源了产业级特色模型PP-OCR与PP-Structure。最新发布的PP-OCRv3包含通用超轻量中英文模型、英文模型,以及德法日韩等80种多语言OCR模型;PP-Structurev2覆盖版面分析与恢复、表格识别、DocVQA任务,提供22种训练部署方式。此外还开源了文本风格数据合成工具Style-Text、半自动文本图像标注工具PPOCRLabel和《动手学OCR》交互式电子书,目前已经成为全球知名的OCR开源项目。
- PaddleGAN :飞桨生成对抗网络开发套件,提供图像生成、风格迁移、超分辨率、影像上色、人脸属性编辑、人脸融合、动作迁移等前沿算法,其模块化设计,便于开发者进行二次研发,同时提供30+预训练模型,助力开发者快速开发丰富的应用。
- PaddleVideo :飞桨视频模型开发套件,具有高指标的模型算法、全流程可部署、更快训练速度和丰富的应用案例、保姆级教程并在体育、安防、互联网、媒体等行业有广泛应用,如足球/蓝球动作检测、乒乓球动作识别、花样滑冰动作识别、知识增强的大规模视频分类打标签、智慧安防、内容分析等。
- ERNIEKit :文心NLP大模型开发套件ERNIEKit,内置业界领先的ERNIE 3.0 (10B、1.5B、Large、XBase、Base、Medium、nano)系列大模型,在各类NLP任务上领先业界其他先进模型。此外,该套件还内置其他领域模型、任务模型、多模态模型20余个,NLP基础任务40余个、数据预处理工具20余个、模型微调工具10余个。该套件支持动静结合的组网方式以及模型压缩功能,兼顾了开发的便利性与部署的高性能需求。同时还能够支持主动学习、网格搜索、可信学习等辅助工具,为NLP工程师提供简单高效的开发工具。
- ElasticCTR :飞桨个性化推荐开发套件,可以实现分布式训练CTR预估任务和基于PaddleServing的在线个性化推荐服务。PaddleServing服务化部署框架具有良好的易用性、灵活性和高性能,可以提供端到端的CTR训练和部署解决方案。ElasticCTR具备产业实践基础、弹性调度能力、高性能和工业级部署等特点。
- PGL :飞桨图学习框架,业界首个提出通用消息并行传递机制,支持万亿级巨图的工业级图学习框架。PGL 原生支持异构图,支持分布式图存储及分布式学习算法,支持GNNAutoScale实现单卡深度图卷积,覆盖30+ 图学习模型,并内置KDDCup 2021 PGL 冠军算法。内置图推荐算法套件Graph4Rec以及高效知识表示套件Graph4KG。历经大量真实工业应用验证,能够灵活、高效地搭建前沿的大规模图学习算法。
- PARL :飞桨深度强化学习框架,覆盖十余种主流强化学习算法,内嵌高性能分布式训练接口,数行代码即可实现上千CPU和GPU并行训练。全面适配大模型闭环训练,一站式构建奖励学习、闭环反馈、大算力推演、策略优化。
- Paddle Quantum :量桨,基于飞桨的量子机器学习工具集,提供组合优化、量子化学等前沿功能,常用量子电路模型,以及丰富的量子机器学习案例,帮助开发者便捷地搭建量子神经网络,开发量子人工智能应用。
- PaddleHelix :飞桨螺旋桨PaddleHelix,针对生命科学领域的重要问题,如药物筛选、蛋白设计、疫苗设计、精准诊疗、机理研究、分子合成等,通过构建“数据+原理”双驱动的生物计算大模型技术,及面向新药研发、疫苗设计、精准医疗等场景的产品工具,辅助生命科学领域的研究者和从业人员提升研发效率,降低AI技术的使用门槛,以更快速的推进科研成果转化和在研管线的上市。
- PaddleScience :飞桨科学计算工具组件,是飞桨面向AI for Science的工具组件,提供便于用户可组合的API模块,支持用户定义及解析物理问题的复杂计算域,如基础几何、stl等。利用飞桨框架提供的高阶自动微分、分布式并行以及编译加速等策略,可加速求解高维的数学物理方程。结合内嵌数学计算和物理数据的处理方法,提供数据驱动以及物理机理约束的深度学习求解模型,解决CFD/CAE等多物理场跨尺度模拟的难点。综合应用AI与数据结合的科学研究新范式,提升智能制造系统设计、建模仿真、分析优化等技术。
比较如上飞桨提供的工具和开发套件,PaddleHub的使用最为简易,二次研发模型源代码的灵活性最好。读者可以参考“使用PaddleHub->基于配置文件使用各领域的开发套件->二次研发原始模型代码”的顺序来使用飞桨,并在此基础上根据业务需求进行优化,即可达到事半功倍的效果。


