
- 1【自然语言处理(NLP)】基于序列到序列的中-英机器翻译
- 2【开题报告】Springboot基于Java的网上购物系统85iuf计算机毕设_基于springboot得网上商城开题报告
- 3走进头条数据中心:高速扩张背后的“硬”实力
- 4LeetCode 最大矩形_最大矩形面积leetcode
- 5《卓有成效的管理者》——学习心得(八)_卓有成效的管理者第八章心得体会
- 6java内存泄漏
- 7无法定位程序输入点kernel32.dll的解决方法分享,一键修复kernel32.dll
- 8十句话,不黄不色,但很经典~~~~~~~~~~ _色爽黄
- 9CSDN的AI创作助手_csdn的ai功能怎么
- 10android seekbar自动动,Android使用SeekBar时动态显示进度且随SeekBar一起移动
MAE技术总结_mae csdn
赞
踩
原理解读
MAE 方法很简单:mask 输入图像的随机 patch,并重建缺失的像素。它基于两个核心设计。首先,作者开发了一种非对称编码器-解码器结构,其中的编码器仅对可见的 patch 子集(不带 mask token)进行操作,而轻量级解码器则从潜在表示和 mask token 重建原始图像。其次,作者发现对输入图像的高比例(例如 75%)进行 mask 会产生一项困难且有意义的自监督任务。将这两种设计结合起来,能够高效地训练大型模型:加快训练速度(3 倍或更多)并提高精度。
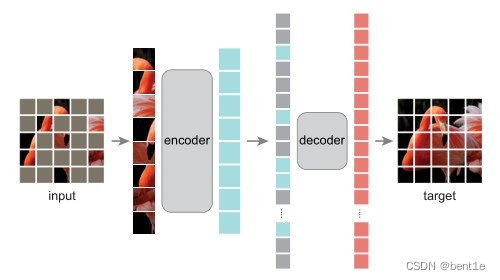
MAE 的结构如上图所示,与所有自动编码器一样,MAE 有一个编码器,将观察到的信号映射到潜在表示,还有一个解码器,从潜在表示重建原始信号。与经典的自动编码器不同,作者采用了一种非对称设计,允许编码器仅对部分观察信号(无mask token)进行操作,并采用一种轻量级解码器,从潜在表示和 mask token 重建完整信号。
具体来说,作者首先将图像划分为规则的非重叠 patch。然后,对一个子集的 patch 进行采样,并移除其余的 patch。然后将这些剩余的 patch 送入到编码器中,编码器是一个标准的 ViT 结构,由于编码器只处理很少一部分的 patch,因此可以用很少的计算和显存来训练非常大的编码器。编码器输出 token 后,作者在 mask 的位置加入了可学习的向量,组成完整的全套 token。
此外,作者向这个完整集合中的所有 token 添加位置嵌入;如果没有这一点,mask token 将没有关于其在图像中位置的信息。MAE 解码器仅在预训练期间用于执行图像重建任务(仅编码器用于生成用于识别的图像表示)。因此,可以以独立于编码器设计的方式灵活地设计解码器架构。作者用比编码器更窄、更浅的解码器进行实验。使用这种非对称设计,全套 token 仅由轻量级解码器处理,这大大减少了预训练时间。
代码实现(tiny版本)
- # MAE encoder
- class MAE_Encoder(torch.nn.Module):
- # cls_token 维度是(1,1,emb_dim)
- self.cls_token = torch.nn.Parameter(torch.zeros(1, 1, emb_dim))
- # 位置嵌入 维度是(img//patch **2,1,emb_dim)
- self.pos_embedding = torch.nn.Parameter(torch.zeros((image_size // patch_size) ** 2, 1, emb_dim))
- # 打乱Patches并按mask_ratio筛选部分patches
- self.shuffle = PatchShuffle(mask_ratio)
- #按patch_size分割patch
- self.patchify = torch.nn.Conv2d(3, emb_dim, patch_size, patch_size)
- # transformer block
- self.transformer = torch.nn.Sequential(*[Block(emb_dim, num_head) for _ in range(num_layer)])
- # LN层
- self.layer_norm = torch.nn.LayerNorm(emb_dim)
- # 参数初始化
- self.init_weight()
- # 前向传播流程(2,3,32,32):
- #1、原图分割成patch (2, 192, 16, 16)——>rearrange(256,2,192)
- #2、位置嵌入
- #3、打乱并mask部分patch,只保留没被mask的patch (64,2,192)
- #4、cls_token嵌入 (65,2,192) ————>rearrange(2,256,192)
- #5、transformer&LayerNorm ————>rearrange(65,2,192)
- def forward(self, img):
- patches = self.patchify(img)
- patches = rearrange(patches, 'b c h w -> (h w) b c')
- patches = patches + self.pos_embedding
- patches, forward_indexes, backward_indexes = self.shuffle(patches)
- patches = torch.cat([self.cls_token.expand(-1, patches.shape[1], -1), patches], dim=0)
- patches = rearrange(patches, 't b c -> b t c')
- features = self.layer_norm(self.transformer(patches))
- features = rearrange(features, 'b t c -> t b c')
- return features, backward_indexes
- # MAE Decoder
- class MAE_Decoder(torch.nn.Module):
- #定义mask_token,设置成全0,后续会初始化
- self.mask_token = torch.nn.Parameter(torch.zeros(1, 1, emb_dim))
- #位置嵌入
- self.pos_embedding = torch.nn.Parameter(torch.zeros((image_size // patch_size) ** 2 + 1, 1, emb_dim))
- #transfoemer block
- self.transformer = torch.nn.Sequential(*[Block(emb_dim, num_head) for _ in range(num_layer)])
- #线性层
- self.head = torch.nn.Linear(emb_dim, 3 * patch_size ** 2)
- #patch到原图的rerrange
- self.patch2img = Rearrange('(h w) b (c p1 p2) -> b c (h p1) (w p2)', p1=patch_size, p2=patch_size, h=image_size//patch_size)
-
- # 前向传播流程(2,3,32,32):
- #1、backward_indexes排序索引先增加一维(cls_token)
- #2、features增加backward_indexes-features维 (65, 2, 192)——>257, 2, 192,增加的是随机初始化的数值
- #3、按照backward_indexes重新排序features,排成原图对应位置的patch
- #4、位置嵌入————>rearrange(2,257,192)
- #5、transformer&LayerNorm ————>rearrange(257,2,192)
- #6、筛掉cls_token(256,2,192)
- #7、全连接层——>(256,2,12)
- #8、新建一个掩膜mask,被mask掉的patch位置值为1,其余是0
- #9、对这个掩膜重新排序,使得和原图对应
- #10、对patch和mask Rearrange成原图大小(2,3,32,32)
- def forward(self, features, backward_indexes):
- T = features.shape[0]
- backward_indexes = torch.cat([torch.zeros(1, backward_indexes.shape[1]).to(backward_indexes), backward_indexes + 1], dim=0)
- features = torch.cat([features, self.mask_token.expand(backward_indexes.shape[0] - features.shape[0], features.shape[1], -1)], dim=0)
- features = take_indexes(features, backward_indexes)
- features = features + self.pos_embedding
- features = rearrange(features, 't b c -> b t c')
- features = self.transformer(features)
- features = rearrange(features, 'b t c -> t b c')
- features = features[1:]
- patches = self.head(features)
- mask = torch.zeros_like(patches)
- mask[T-1:] = 1
- mask = take_indexes(mask, backward_indexes[1:] - 1)
- img = self.patch2img(patches)
- mask = self.patch2img(mask)
- return img, mask
- #损失函数部分使用MSE,但是只计算被mask掉部分的损失
- loss = torch.mean((predicted_img - img) ** 2 * mask) / args.mask_ratio

推理阶段
选取MAE的encoder部分的feature,并在图像检索过程中选取cls_token作为特征向量进行匹配

