
- 1Github 连接问题之 REMOTE HOST IDENTIFICATION HAS CHANGED!_the fingerprint for the rsa key sent by the remote
- 2torch.nn.BCEWithLogitsLoss用法介绍
- 3【头歌答案】03-3 Python程序设计入门2-基本输入输出、字符串、内置函数(EduCoder)_头歌python程序设计答案
- 4拖动条seekbar调整条的宽窄_android seekbar宽度
- 5大数据毕业设计hadoop+spark知识图谱音乐推荐系统 音乐评论情感分析 音乐爬虫可视化 音乐数据分析 大数据毕设 机器学习 深度学习 人工智能 计算机毕业设计
- 6NLP技术:基于PCFG的CYK算法统计句法分析_fish people fish tanks
- 7量化感知训练实践:实现精度无损的模型压缩和推理加速_模型部署量化 如何做到平衡模型的吞吐率和精度
- 8担心被ChatGPT取代?LMFlow让你打不过就加入!
- 9Spring Boot 接口统一前缀 path-prefix_springboot配置请求前缀
- 10“仍有5亿人坚持用QQ”登热搜第一;马斯克宣布本周开源AI聊天机器人Gok;Linux 6.8 发布|极客头条
计算机毕业设计 面向金融领域的实体关系抽取系统(源码+论文)_关系抽取软件源代码
赞
踩
0 项目说明
面向金融领域的实体关系抽取系统设计与实现
提示:适合用于课程设计或毕业设计,工作量达标,源码开放
项目分享:
https://gitee.com/asoonis/feed-neo
1 项目说明
经过大量的调研发现,有监督的机器学习方法在关系抽取的效果上要优于半监督和无监督的机器学习方法,因此本系统将使用有监督的机器学习方法来进行关系抽取。因为实体种类繁多,针对金融领域,我们只抽取机构与机构之间、人与机构之间的实体关系。基于有监督的机器学习方法来进行关系抽取,系统的开发大致分为两个部分:一是模型训练,二是应用训练好的模型进行关系抽取。主要工作内容可概括为以下几个方面:
(1)使用爬虫技术爬取新闻,搭建训练语料库;
(2)人工标注语料库;
(3)针对不同的分类算法进行调参,并选择最佳的分类算法;
(4)使用最佳的分类算法训练模型并保存模型;
(5)使用已有的模型对金融新闻进行实体关系抽取。
2 需求分析
实体关系抽取的进行是在实体识别的基础上进行的,因此系统首先应该允许用户选择需要进行关系预测的实体对,然后让系统读取描述实体间关系的新闻内容,再进行实体间关系抽取,并给出模型预测的实体间关系。
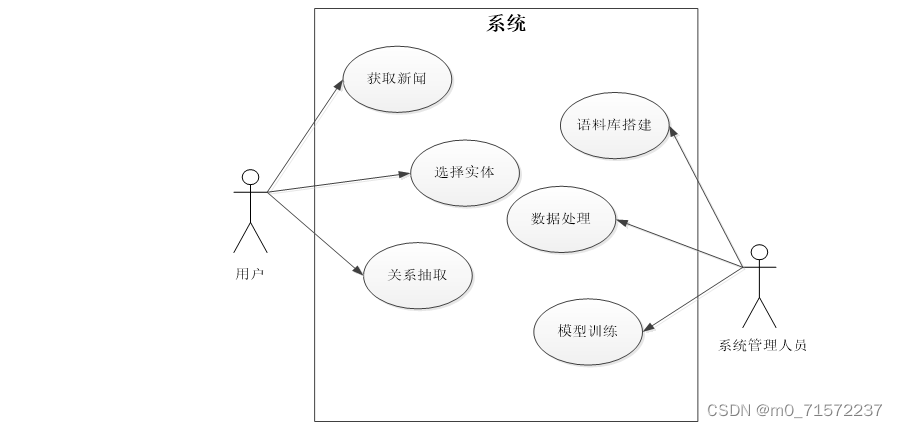
3 系统设计
本系统在特定的金融网站上采集数据,搭建语料库并进行人工标注。在标注完成后,选定分类算法进行训练,训练完完成后即可使用该模型来对新来的文本进行实体关系抽取,文本的来源可以使微信、股吧、公告和新闻网站等。将关系抽取的结果进行保存,以服务于其他应用。
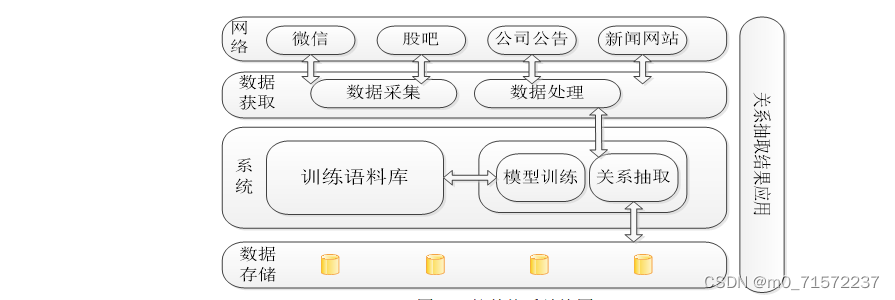
3.1 系统功能
本系统主要包括模型训练和关系抽取两个方面,关系抽取是在模型训练完成的基础上,利用已经训练好的模型来对实体关系进行抽取。模型训练模块和关系抽取模块又可以根据其处理的流程,细分为一些具体的小模块。
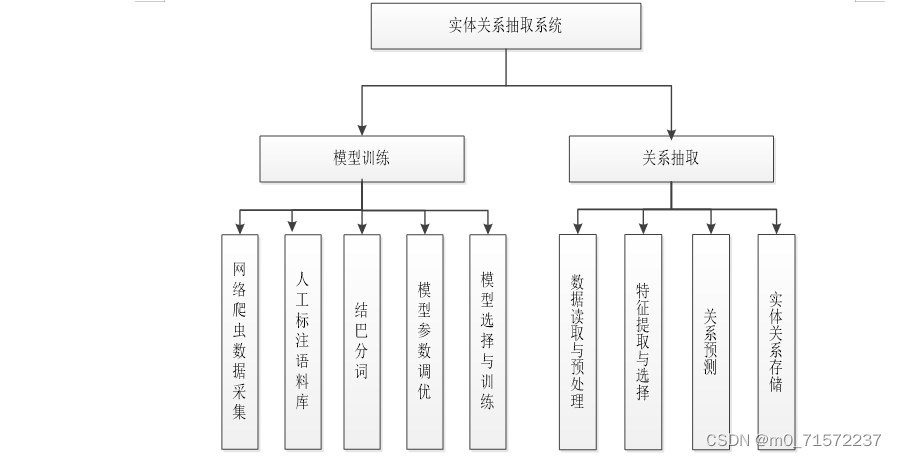
3.2 实现流程
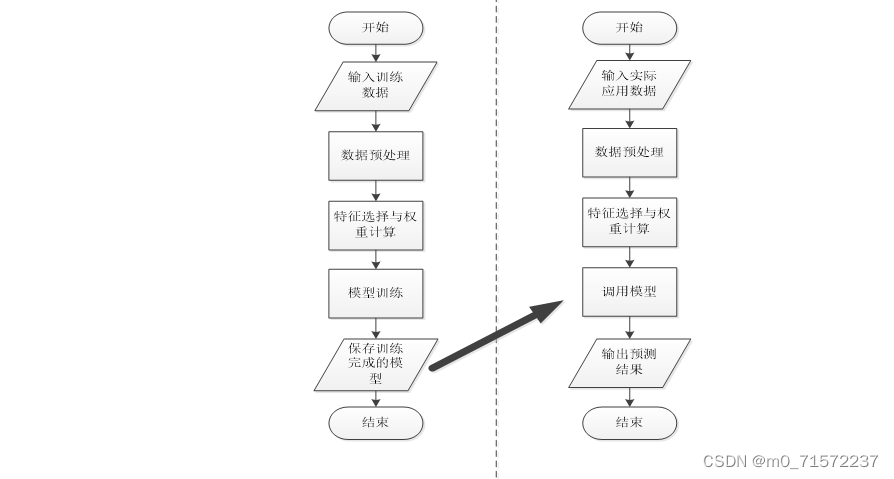
面向金融领域的实体关系抽取系统主要包含两部分,模型训练和关系抽取,关系抽取是应用模型训练完成后保存的模型来进行关系抽取活动的。下图展示了这两个部分的实现流程以及之间的交互关系。从图可以看出,两部分的实现流程基本一致。
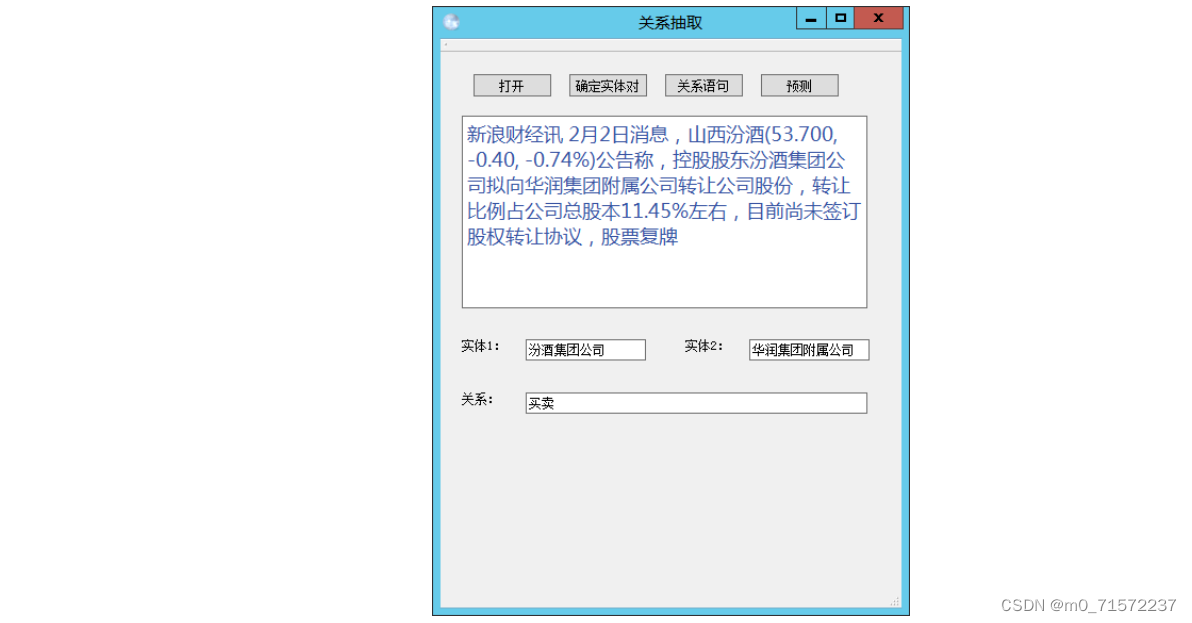
4 效果展示
(1)买卖关系
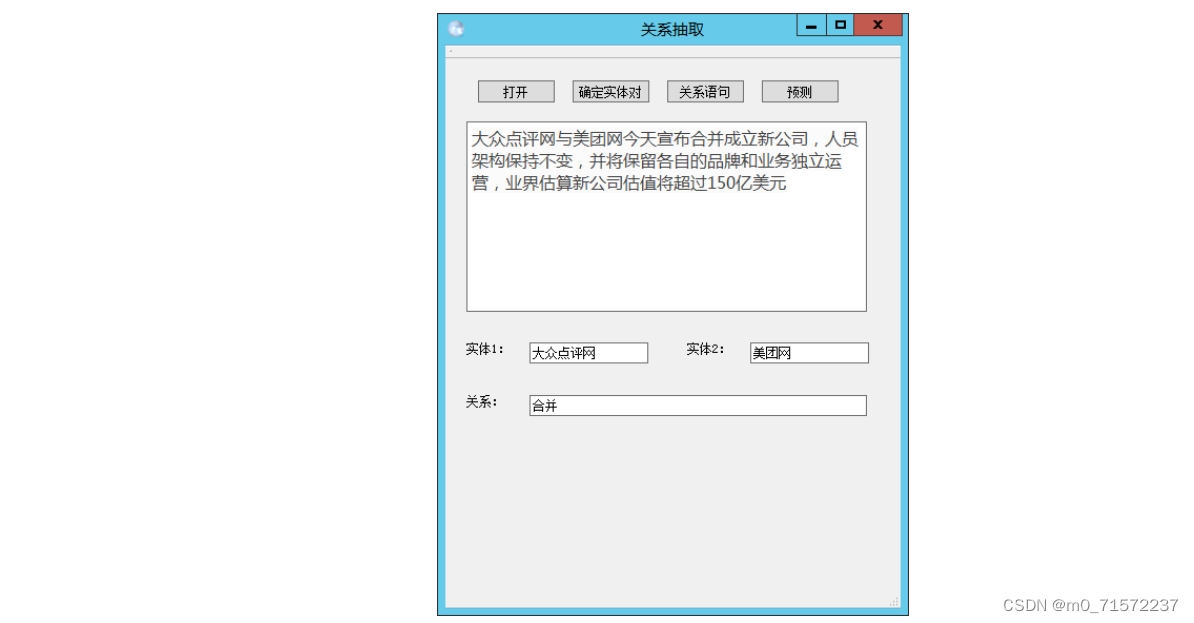
(2)合并关系
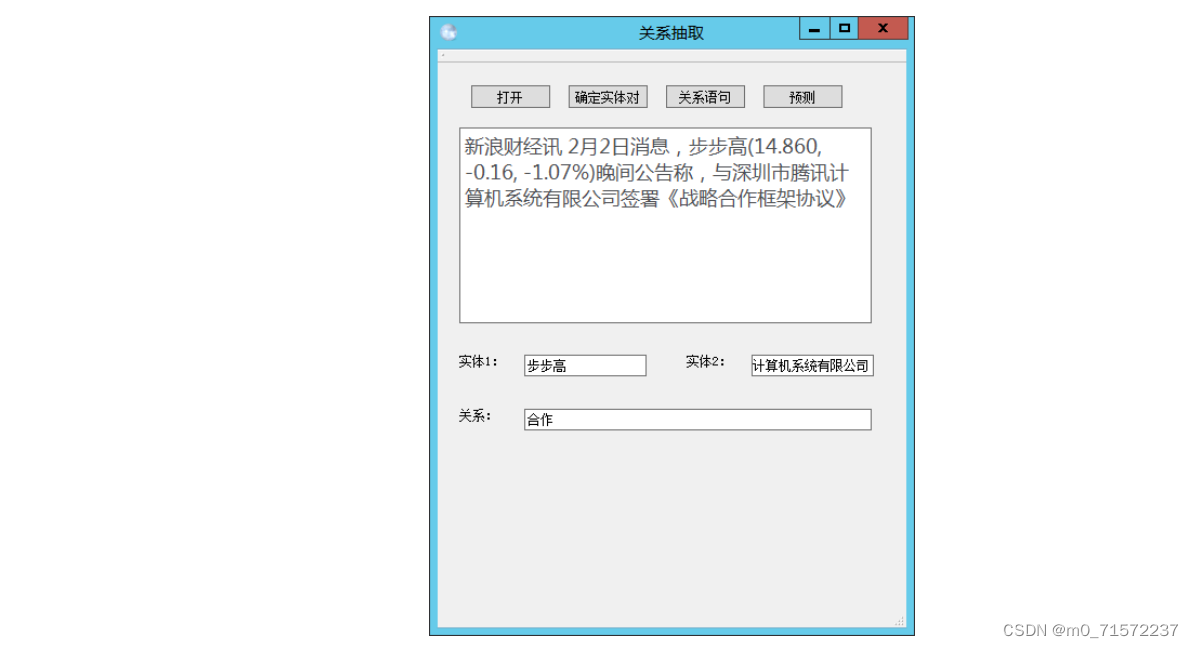
(3)合作关系
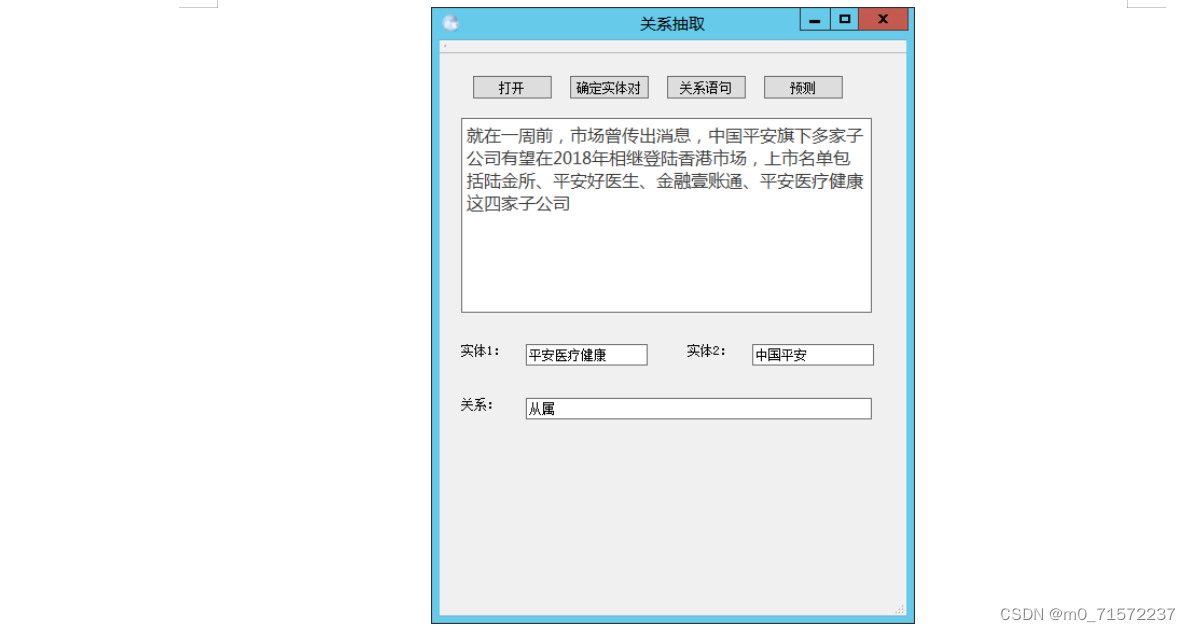
(4)从属关系
5 论文概览

项目分享:

